













對於像Uber這樣的公司來說,即時數據是其面向客戶和內部服務的生命線。客戶依賴即時數據來方便地叫車和訂餐。內部團隊也依賴最新數據來支持其面向客戶應用的基礎設施,例如用於監控移動應用程式崩潰分析的內部工具。
Uber轉向使用Apache Pinot來支持這一內部工具,並體驗到相比之前的分析引擎(Elasticsearch)顯著的改進。通過遷移到Pinot,一個真正的即時分析平台,Uber獲得了以下益處:
- 基礎設施成本降低70%(每年節省超過200萬美元)
- CPU核心數量減少80%
- 數據足跡減少66%
- 頁面加載時間減少64%(從14秒降至不到5秒)
- 數據攝入延遲降低至<10毫秒
- 查詢超時減少,數據丟失問題得到解決

立即觀看
本博客內容基於一場包含Apache Pinot用戶故事的現場聚會。我們還參考了Uber工程團隊的一篇博客,該博客介紹了他們如何使用Pinot為移動應用崩潰提供即時分析。觀看聚會請點擊這裡:
或者繼續閱讀以了解Uber如何通過Apache Pinot實現這些成果。
Uber如何實現移動應用崩潰的即時分析
Uber設有自動化資料擷取管道,用以追蹤應用程式當機情況並收集調查數據。部分數據被導入Apache Flink進行轉換處理,隨後再回傳至Kafka主題供下游消費使用。Kafka中的原始及處理後事件接著由Apache Pinot消費,該系統執行分析查詢,其結果通過Grafana及內部可視化工具傳遞給內部用戶。此管道同時擷取即時與離線數據(未展示),以在Apache Pinot中建立用戶完整視圖,即所謂的混合表格。
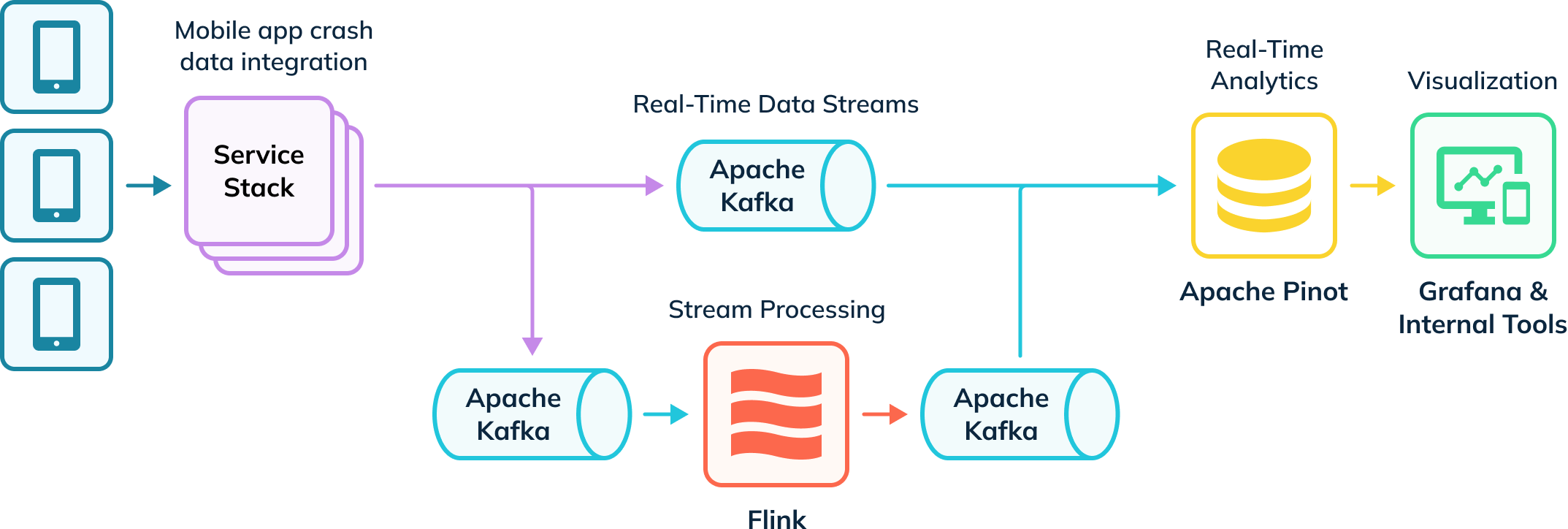
即時應用程式當機分析與Apache Pinot
Uber每週釋出約11,000項新代碼及基礎設施變更,並依賴自家工具Healthline協助偵測及解決當機問題。Healthline使Uber能更佳地衡量並達到其平均偵測時間(MTTD)。例如,他們可能推出一項新功能導致預期外的應用程式當機,必須迅速透過深入分析當機數據找出問題根源。
下方儀表板展示了一款移動應用及某版本操作系統一週的當機數據。在此範例中,會話事件每秒發生高達數十萬次,而當機事件則每秒記錄15,000至20,000次。Uber整合這些指標計算無致命錯誤率,顯示應用程式的健康狀況(目標是盡可能接近100%)。
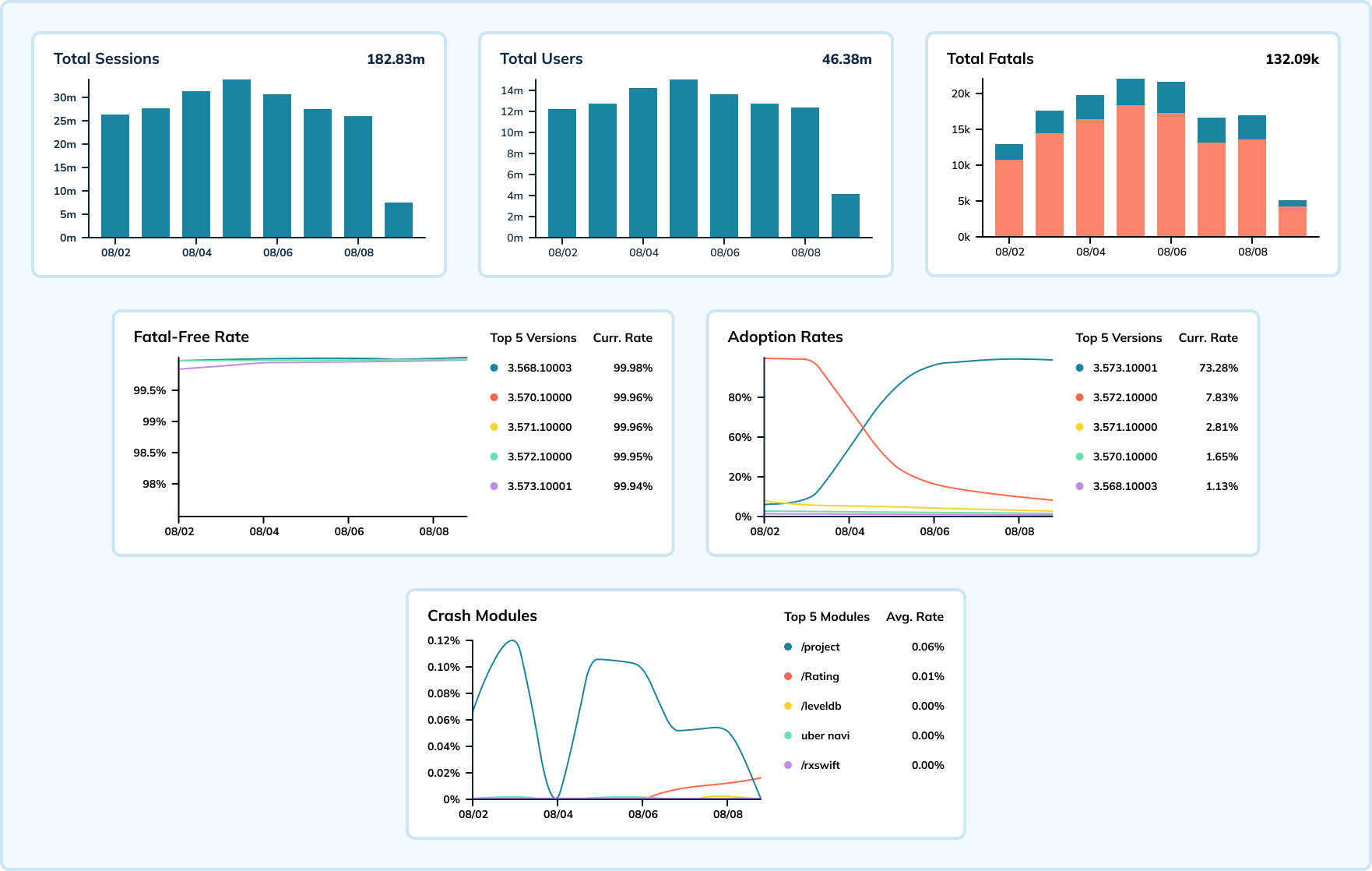
使用Elasticsearch這一通用搜尋引擎時,崩潰率的激增會導致數據攝取延遲,從而延緩團隊對問題識別的反應。轉向專為大規模實時分析設計的Apache Pinot後,團隊觀察到數據攝取延遲的數量和嚴重性均有所下降。
深入分析崩潰數據
除了崩潰數據的高層次概覽外,Uber還提供深入的崩潰級分析。他們跨多種維度聚合崩潰指標,例如每個操作系統和版本的崩潰次數,以及每個版本的崩潰分佈。此用例利用了多種Pinot索引(範圍、倒排和文本)來說明何時發生某種類型的崩潰,受影響的版本,發生次數,以及受影響的用戶和設備數量。
對於深入分析,擁有文本搜索功能以閱讀崩潰錯誤消息對Uber來說至關重要。Pinot的文本索引建立在Lucene之上,使他們能夠通過崩潰消息、類名、堆棧跟踪等進行搜索。
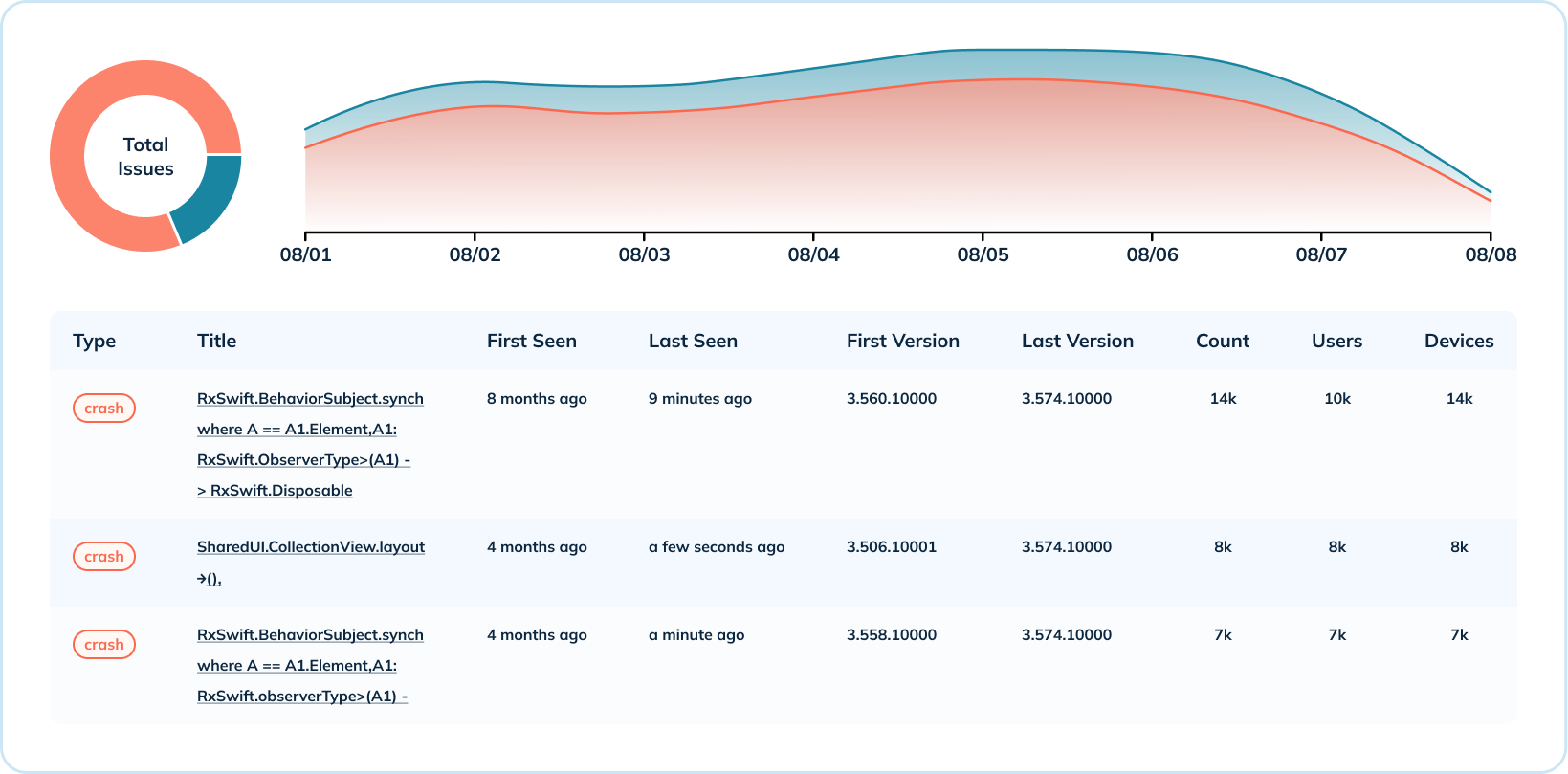
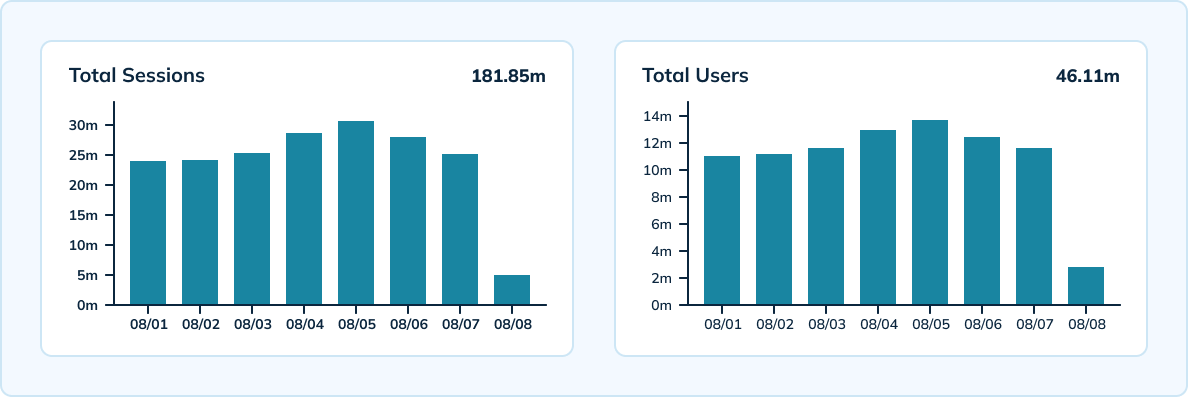
大規模測量會話
Uber還使用Pinot來測量大規模下按設備、版本、操作系統和每小時的獨特會話。Pinot提供實時處理,具有高規模吞吐量,能夠攝取Uber每秒300,000次的分析事件。團隊有一個混合設置,包括一個具有10分鐘粒度和3天數據保留的實時表,以及一個具有每小時和每日粒度及45天數據保留的離線表。
利用Apache Pinot的HyperLogLog功能,團隊得以減少存儲的事件數量並減少跨事件的唯一聚合次數。Pinot還提供了極低的延遲——99.5百分位延遲低於100毫秒。
基礎設施成本節省
根據Uber的計算,通過遷移至Pinot,他們每年節省了超過200萬美元的基礎設施成本。與Elasticsearch相比,他們的Pinot配置導致基礎設施成本減少了70%。此外,他們還看到CPU核心數量減少了80%,數據足跡減少了66%。

使用Elasticsearch時,Uber使用了22,000個CPU核心。使用Pinot後,他們將這一數字減少了80%。以下是他們Pinot配置的一個快照:
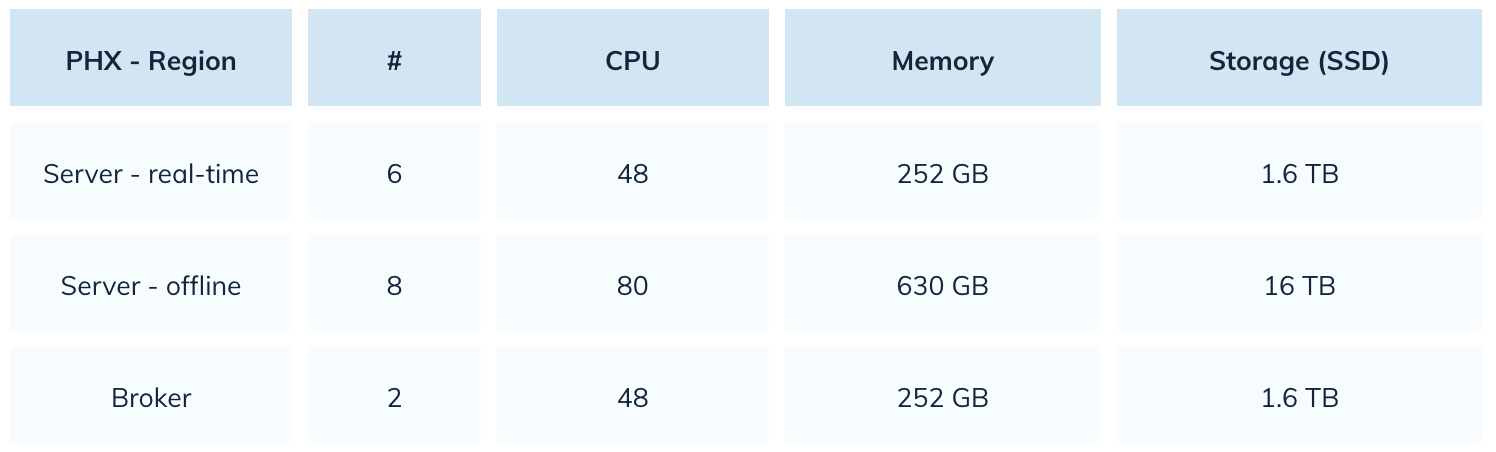
提升查詢性能與用戶體驗
通過Apache Pinot,Uber能夠提供更佳的用戶體驗,包括更快的頁面加載和更高的可靠性。遷移至Pinot使頁面加載時間減少了64%,從14秒降至不到5秒。Pinot對負載峰值的容忍度更高,從而導致更快的延遲恢復。即使團隊遇到數據攝入延遲,Pinot也能在幾分鐘內迅速恢復。
與Elasticsearch相比,Pinot在查詢超時和數據丟失方面也顯示出顯著的改進。如果使用Elasticsearch時移動應用程序發生災難,涉及該索引的查詢將會超時。Uber通過控制段大小使用Pinot解決了這個問題。與Elasticsearch在處理增加的數據攝入吞吐量時經常出現的數據問題相比,團隊在使用Pinot時沒有遇到數據丟失問題。
Uber Pinot配置的下一次迭代
接下來,Uber計劃將其移動端崩潰數據遷移至原生文本索引。由於其移動崩潰數據包含大量結構化數據,團隊認為將所有用例遷移至原生文本索引是可行的。此舉不僅能從數據存儲中節省成本,還能減少查詢數據所需時間。
不只是Uber,其他組織也通過從Elasticsearch遷移至Pinot取得了成功
Uniqode(前身為Beaconstac)通過這一轉換,整體查詢性能提升了10倍。Cisco Webex在遭遇高延遲問題後,也將其實時分析和可觀測性遷移到了Pinot。Webex團隊發現,Apache Pinot提供的延遲比Elasticsearch低5倍至150倍。
Source:
https://dzone.com/articles/real-time-app-crash-analytics-with-apache-pinot