













VAR-As-A-Service 是一種MLOps方法,用於統一和重用統計模型及機器學習模型的部署管道。這是基於該項目的一系列文章中的第二篇,展示了對各種統計和機器學習模型、使用現有DAG工具實現的數據管道以及雲端和替代本地解決方案的存儲服務的實驗。本文專注於模型文件存儲,採用的方法同樣適用於機器學習模型。實現的存儲基於MinIO,作為與AWS S3兼容的對象存儲服務。此外,文章概述了替代存儲解決方案,並闡述了對象存儲的優勢。
該系列的第一篇文章(時間序列分析:VARMAX-As-A-Service)將統計模型和機器學習模型視為數學模型,並提供了一個基於VARMAX的統計模型用於宏觀經濟預測的端到端實現,使用了一個名為statsmodels的Python庫。該模型通過Python Flask和Apache網絡服務器部署為REST服務,打包在Docker容器中。應用程序的高層次架構如下圖所示:
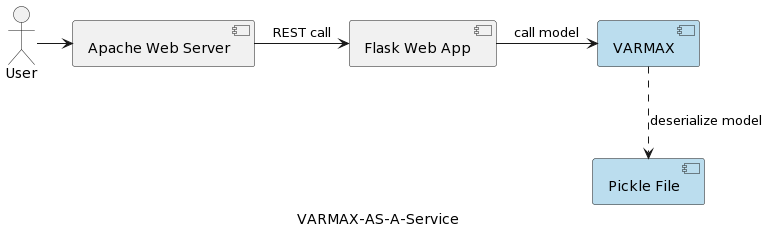
此模型以pickle檔案形式序列化,並作為REST服務套件的一部分部署於網頁伺服器上。然而,在實際專案中,模型需進行版本控制,附帶元數據資訊,並確保安全性;訓練實驗需記錄並保持可重現性。此外,從架構角度來看,將模型儲存於應用程式旁邊的檔案系統中,違背了單一職責原則。一個良好的範例便是基於微服務的架構。水平擴展模型服務意味著每個微服務實例都將擁有自己的物理pickle檔案版本,並在所有服務實例間複製。這也意味著,支援多個模型版本將需要新的發布及重新部署REST服務及其基礎設施。本文旨在將模型與網路服務基礎設施解耦,並允許使用不同版本的模型重用網路服務邏輯。
在深入實現之前,讓我們先談談統計模型以及該項目中使用的VAR模型。統計模型是數學模型,機器學習模型亦然。兩者之間的更多差異可以在系列第一篇文章中找到。統計模型通常被指定為一個或多個隨機變量與其他非隨機變量之間的數學關係。向量自回歸(VAR)是一種用於捕捉多個數量隨時間變化。VAR模型通過允許多元時間序列,擴展了單變量自回歸模型(AR)。在展示的項目中,該模型被訓練用於預測兩個變量。VAR模型常被應用於經濟學和自然科學領域。一般來說,該模型由一組方程式表示,在項目中這些方程式隱藏在Python庫statsmodels背後。
VAR模型服務應用程序的架構如下圖所示:
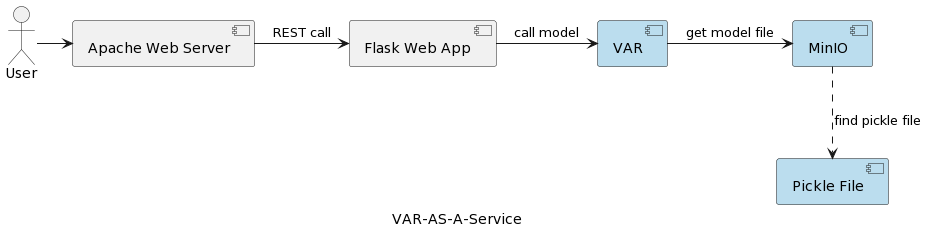
變量自動回歸(VAR)運行時組件代表基於用戶發送的參數進行的實際模型執行。它通過REST接口連接到MinIO服務,加載模型並運行預測。與第一篇文章中的解決方案相比,該方案在應用程序啟動時加載並反序列化VARMAX模型,VAR模型每次觸發預測時都會從MinIO服務器讀取。這雖然增加了加載和反序列化時間,但也帶來了每次運行都能使用部署模型的最新版本的優勢。此外,它支持模型的動態版本管理,使它們能自動對外部系統和最終用戶可用,這將在後續文章中展示。需要注意的是,由於加載開銷,所選存儲服務的性能至關重要。
但為何選擇MinIO以及一般對象存儲呢?
MinIO 是一套高效能物件儲存解決方案,原生支援 Kubernetes 部署,提供與 Amazon Web Services S3 相容的 API,並支援所有核心 S3 功能。在本專案中,MinIO 採用獨立模式運行,包含一個 MinIO 伺服器和單一磁碟或儲存卷冊,於 Linux 系統上透過 Docker Compose 實現。對於擴展開發或生產環境,文章 部署 MinIO 於分散式模式 中介紹了分散式模式的選項。
在深入了解之前,我們先簡單瀏覽一些儲存替代方案,詳盡描述可見於 此處 及 此處:
- 本地/分布式文件存储:本地文件存储是第一篇文章中实施的解决方案,因其最为简单。计算与存储位于同一系统上。在概念验证阶段或对于支持单一版本的简单模型而言,这是可接受的。本地文件系统存储容量有限,当我们想要存储训练数据集等额外元数据时,对于大型数据集并不适用。由于缺乏复制或自动扩展功能,本地文件系统无法以可用、可靠和可扩展的方式运行。为实现水平扩展而部署的每个服务都带有其自身模型的副本。此外,本地存储的安全性仅与主机系统相当。替代本地文件存储的方案包括NAS(网络附加存储)、SAN(存储区域网络)、分布式文件系统(如Hadoop分布式文件系统(HDFS)、Google文件系统(GFS)、Amazon弹性文件系统(EFS)和Azure文件)。相较于本地文件系统,这些解决方案的特点在于高可用性、可扩展性和弹性,但同时也带来了复杂性的增加。
- 關聯式資料庫:由於模型採用二進制序列化,關聯式資料庫提供了將模型以blob或二進制形式存儲在表格欄位中的選項。軟體開發者和許多數據科學家對關聯式資料庫都很熟悉,這使得該方案直觀易懂。模型版本可以作為單獨的表格行存儲,並附帶額外的元數據,這也便於從資料庫中讀取。然而,一個缺點是資料庫將需要更多的存儲空間,這將影響備份。在資料庫中存儲大量二進制數據也可能影響性能。此外,關聯式資料庫對數據結構施加了一些限制,這可能會使存儲異質數據(如CSV文件、圖像和JSON文件作為模型元數據)變得複雜。
- 物件儲存:物件儲存已存在多年,但自從亞馬遜在2006年將其作為首個AWS服務推出簡單儲存服務(S3)後,它經歷了革命性的變革。現代物件儲存天生適合雲端環境,其他雲端服務提供商也迅速推出了自己的產品。微軟提供Azure Blob Storage,而Google則有Google Cloud Storage服務。S3 API成為開發者與雲端儲存互動的實際標準,多家公司提供與S3相容的儲存解決方案,適用於公有雲、私有雲及私有本地部署。不論物件儲存位於何處,都是透過RESTful介面存取。雖然物件儲存消除了對目錄、資料夾及其他複雜層次結構的需求,但它不適合經常變動的動態數據,因為修改時需重寫整個物件,但對於儲存序列化模型及其元數據來說是一個好選擇。
A summary of the main benefits of object storage are:
- 大規模擴展性:物件儲存的規模實質上是無限的,因此數據可以透過簡單地新增設備擴展到艾字節級別。物件儲存解決方案在作為分散式叢集運行時表現最佳。
- 簡化複雜性:數據以扁平結構儲存。缺乏複雜的樹狀結構或分割區(無資料夾或目錄)使得檔案的檢索更為簡便,因為使用者無需知道確切位置。
- 搜尋性:元數據是物件的一部分,使得搜尋和導航變得容易,無需使用單獨的應用程式。可以為物件添加屬性和資訊,如消耗、成本及自動刪除、保留和分層的政策。由於底層存儲的扁平地址空間(每個物件只在一個桶中,且桶內無子桶),物件存儲能夠在數十億物件中快速找到特定物件。
- 彈性:物件存儲能自動複製數據並跨多個設備和地理位置存儲,有助於防範中斷、保護數據免於丟失,並支援災難恢復策略。
- 簡易性:使用REST API進行存儲和檢索模型意味著幾乎無學習曲線,並使整合到基於微服務的架構成為自然選擇。
現在是時候探討將VAR模型作為服務的實現以及與MinIO的整合。透過使用Docker和Docker Compose,所提出解決方案的部署得以簡化。整個專案的組織結構如下:

如同第一篇文章所述,模型準備過程包含幾個步驟,這些步驟被編寫在一個名為var_model.py的Python腳本中,該腳本位於專用的GitHub倉庫:
- 載入數據
- 將數據分割成訓練集和測試集
- 準備內生變量
- 尋找最佳模型參數p(每個變量的前p個滯後作為回歸預測因子)
- 使用識別出的最佳參數實例化模型
- 將實例化模型序列化為pickle文件
- 將pickle文件作為版本化對象存儲在MinIO桶中
這些步驟也可以作為工作流引擎(如Apache Airflow)中的任務實現,並在需要使用更新的數據訓練新模型版本時觸發。DAGs及其在MLOps中的應用將是另一篇文章的主題。
var_model.py中實施的最後一步是將序列化為pickle文件的模型存儲在S3中的桶內。由於對象存儲的扁平結構,所選格式為:
<bucket name>/<file_name>
然而,對於檔案名稱,允許使用正斜線來模擬層次結構,同時保持快速線性搜尋的優勢。儲存VAR模型的慣例如下:
models/var/0_0_1/model.pkl
其中,儲存桶名稱為models,檔案名稱為var/0_0_1/model.pkl,在MinIO UI中,其呈現如下:

這是一種非常方便的方式,用於組織各種類型的模型及其版本,同時仍具有平面檔案儲存的效能和簡潔性。
請注意,模型版本控制已作為模型名稱的一部分實現。MinIO也提供檔案版本控制,但此處選擇的方法具有某些優勢:
- 支援快照版本及覆蓋
- 使用語義版本控制(由於限制,點號被替換為’_’)
- 對版本控制策略有更大的控制權
- 在特定版本控制功能方面解耦底層儲存機制
一旦模型部署完成,接下來就是使用Flask將其作為REST服務公開,並使用docker-compose部署,同時運行MinIO和Apache Web伺服器。Docker映像以及模型程式碼可以在專門的GitHub儲存庫中找到。
最後,運行應用程式所需的步驟如下:
- 部署應用程式:
docker-compose up -d - 執行模型準備算法:
python var_model.py(需要運行的MinIO服務) - 檢查模型是否已部署:http://127.0.0.1:9101/browser
- 測試模型:
http://127.0.0.1:80/apidocs
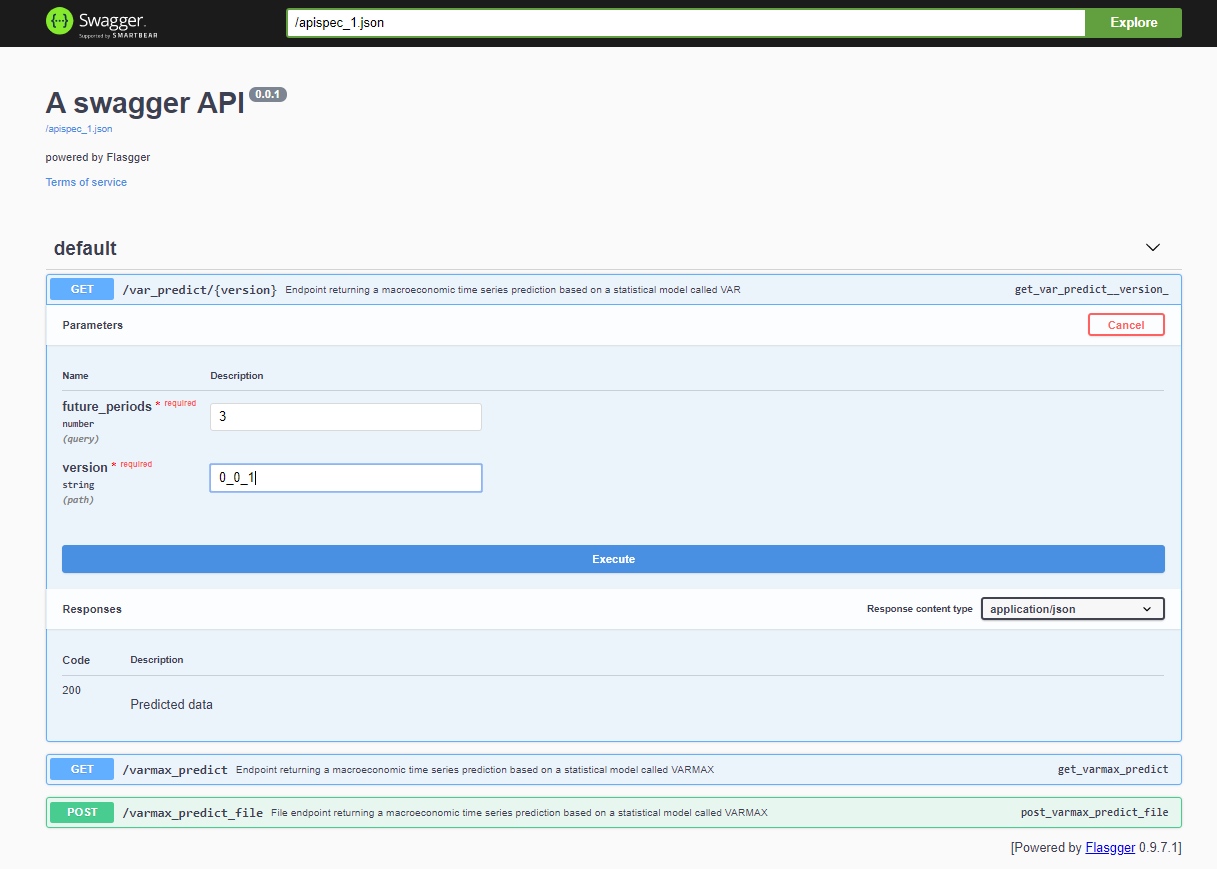
項目部署後,Swagger API 可通過 <host>:<port>/apidocs(例如 127.0.0.1:80/apidocs)訪問。VAR模型有一個端點,與其他兩個端點一起展示了VARMAX模型:
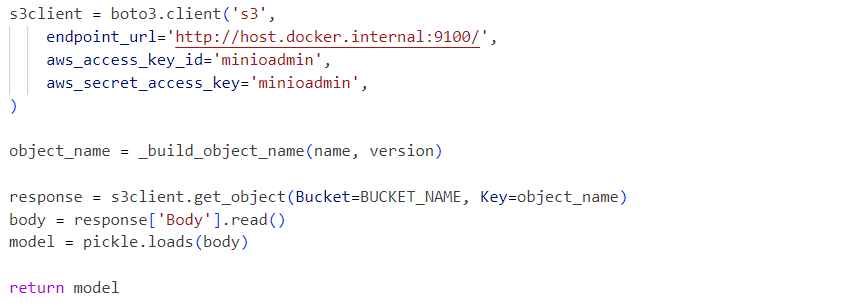
內部,服務使用從MinIO服務加載的反序列化模型pickle文件:
請求按以下方式發送到初始化模型:

本項目展示的是一個簡化的VAR模型工作流程,可以逐步擴展其他功能,例如:
- 探索標準序列化格式,並用替代方案替換pickle
- 整合時間序列數據可視化工具,如Kibana或Apache Superset
- 將時間序列數據存儲在時間序列數據庫中,如Prometheus、TimescaleDB、InfluxDB或對象存儲如S3
- 擴展管道以包括數據加載和數據預處理步驟
- 將度量報告作為管道的一部分
- 使用特定工具如Apache Airflow或AWS Step Functions或更標準的工具如Gitlab或GitHub實現管道
- 比較統計模型與機器學習模型的效能與準確度
- 實施端到端的雲整合解決方案,包括基礎設施即代碼
- 將其他統計與機器學習模型作為服務公開
- 實現一個模型儲存API,該API抽象化實際儲存機制及模型版本管理,儲存模型元數據及訓練數據
這些未來的改進將是即將發表的文章與專案的重點。本文的目標是整合一個與S3相容的儲存API,並啟用版本化模型的儲存。此功能將很快被提取到一個單獨的庫中。所展示的端到端基礎設施解決方案可以在生產環境中部署,並隨著時間的推移作為CI/CD流程的一部分進行改進,同時使用MinIO的分佈式部署選項或替換為AWS S3。
Source:
https://dzone.com/articles/time-series-analysis-var-model-as-a-service