













Amazon Simple Storage Service (S3) 是 Amazon Web Services (AWS) 提供的高度可擴展、耐用且安全的物件儲存服務。S3 允許企業透過其企業級服務,在網路上任何地方儲存和檢索任意數量的數據。S3 設計用於高度互操作性,並能無縫整合其他 Amazon Web Services (AWS) 和第三方工具及技術,以處理儲存在 Amazon S3 中的數據。其中之一是 Amazon EMR (Elastic MapReduce),它允許您使用 Spark 等開源工具處理大量數據。
Apache Spark 是一個用於大規模數據處理的開源分布式計算系統。Spark 旨在實現速度,並支持包括 Amazon S3 在內的多種數據源。Spark 提供了一種高效的方式來處理大量數據並在極短的時間內執行複雜計算。
Memphis.dev 是傳統消息代理的下一代替代品。它是一個簡單、健壯且耐用的雲原生消息代理,配有一整套生態系統,能夠以成本效益、快速且可靠地開發現代基於隊列的使用案例。
消息代理的常見模式是在通過定義的保留策略(如時間/大小/消息數量)後刪除消息。Memphis 提供了一個第二級存儲層,用於更長時間、可能無限期的保留存儲的消息。每條從站點驅逐的消息將自動遷移到第二級存儲層,在此情況下即為 AWS S3。
在本教程中,您將學習如何設置一個連接至AWS S3的Memphis站點,並配置第二種存儲類別。接著,您將創建一個S3桶,設置EMR集群,安裝並配置Apache Spark於集群上,準備S3中的數據以供處理,使用Apache Spark處理數據,以及了解最佳實踐和性能調優。
環境設置
Memphis
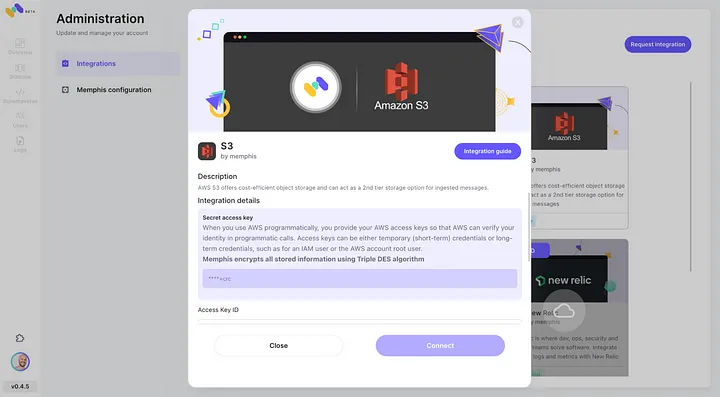
3. 創建一個站點(主題)並選擇保留策略。
4. 每條通過配置的保留策略的消息將被卸載至一個S3桶中。
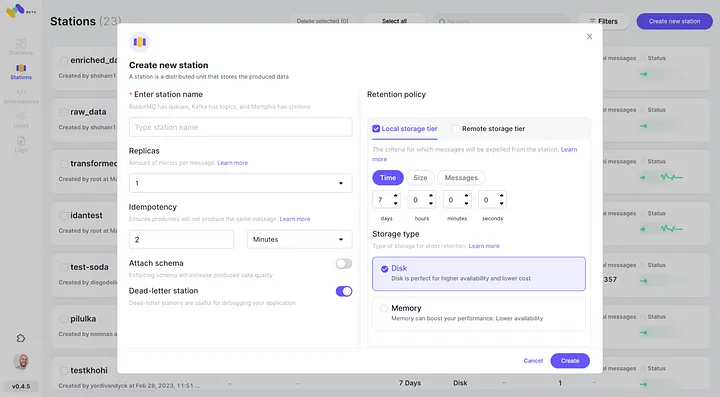
5. 通過點擊“連接”檢查新配置的AWS S3集成作為第二種存儲類別。
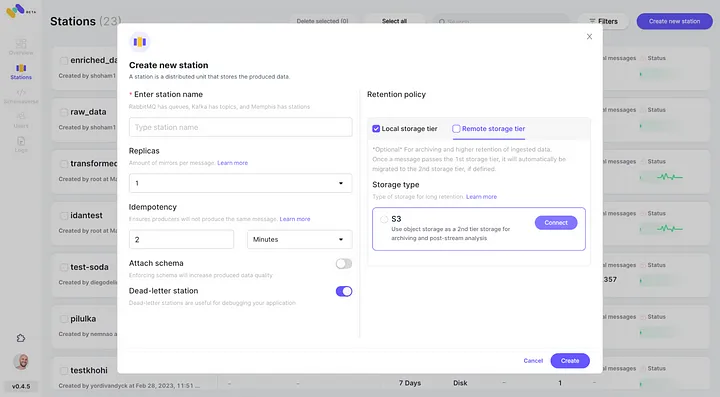
6. 開始為您新創建的Memphis站點生成事件。
創建AWS S3桶
若您尚未進行此操作,首先需建立一個AWS帳戶。接著,創建一個S3桶以存放您的數據。您可透過AWS管理主控台、AWS CLI或SDK來建立桶。本教程中,將使用AWS管理主控台
點擊“建立桶”
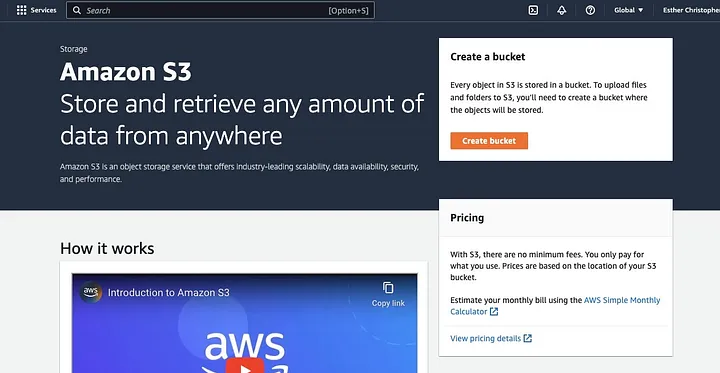
。隨後,依命名規則設定桶名稱並選擇桶所在的區域。根據使用情境配置“物件擁有權”及“封鎖所有公開存取”
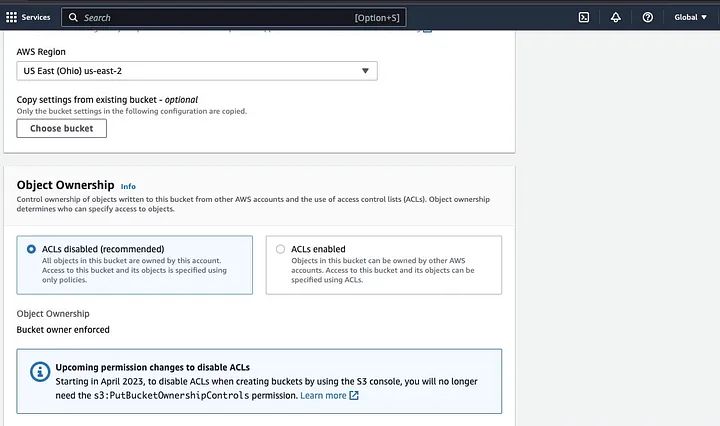
。確保其他桶權限設定允許您的Spark應用程式存取數據。最後,點擊“建立桶”按鈕以完成創建
。
設定已安裝Spark的EMR叢集
Amazon Elastic MapReduce (EMR) 是一項基於Apache Hadoop的網路服務,允許用戶利用包括Apache Spark在內的大數據技術,以經濟高效的方式處理大量數據。要創建已安裝Spark的EMR叢集,請開啟EMR主控台,在頁面左側選擇“EMR on EC2”下的“Clusters”
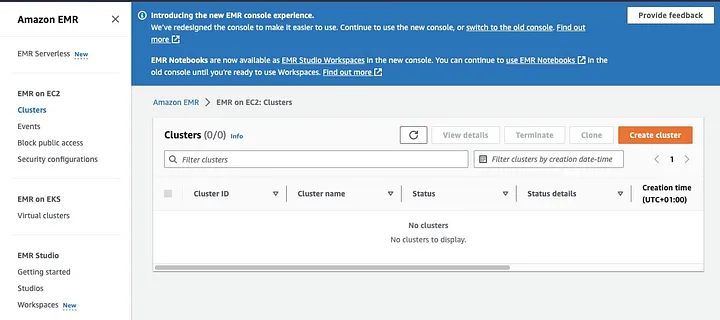
。點擊“創建叢集”並為其命名。在“應用程式套件”中選擇Spark以安裝於您的叢集上。
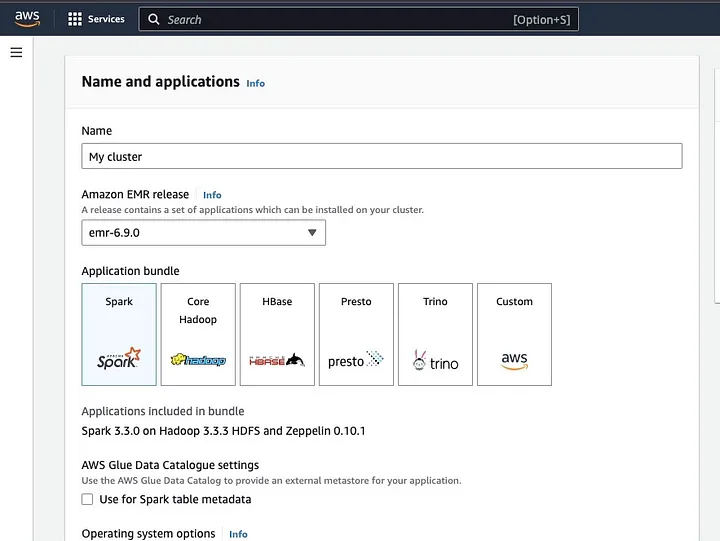
向下滾動至「Cluster logs」區段,並勾選「Publish cluster-specific logs to Amazon S3」。
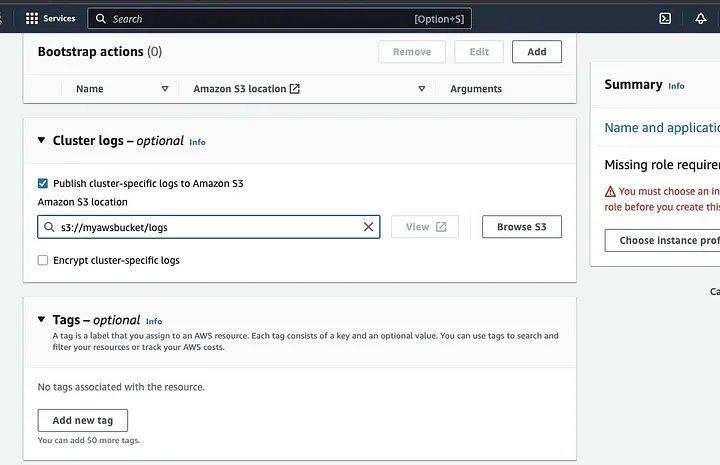
此操作將提示您輸入Amazon S3位置,使用您在前一步驟中建立的S3桶名稱,後接/logs,例如:s3://myawsbucket/logs。/logs是Amazon要求的,以便在您的桶中創建一個新資料夾,Amazon EMR可在其中複製您的集群日誌文件。
接著前往「Security configuration and permissions section」,輸入您的EC2金鑰對,或選擇創建一個新的。
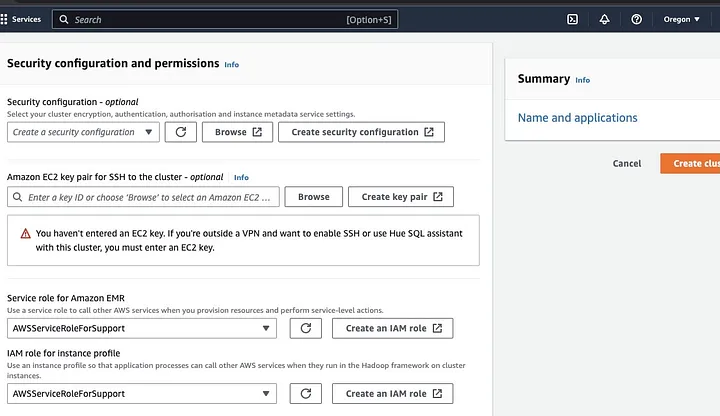
然後點擊「Service role for Amazon EMR」的下拉選項,選擇AWSServiceRoleForSupport。同樣地,在「IAM role for instance profile」下拉選項中也選擇相同的設定。如有需要,刷新圖標以獲取這些下拉選項。
最後,點擊「Create cluster」按鈕以啟動集群,並監控集群狀態以確認其已成功建立。
在EMR集群上安裝與配置Apache Spark
成功建立EMR集群後,下一步將是在EMR集群上配置Apache Spark。EMR集群提供了一個受管理的環境,用於在AWS基礎設施上運行Spark應用程序,使得在雲中啟動和管理Spark集群變得容易。它配置Spark以配合您的數據和處理需求,然後將Spark作業提交到集群以處理您的數據。
您可以透過Secure Shell (SSH) 協定將Apache Spark配置至集群。但首先,您需要授權SSH安全連接到您的集群,這在創建EMR集群時默認設置。關於如何授權SSH連接的指南可以在這裡找到。
要建立SSH連接,您需要指定創建集群時選擇的EC2金鑰對。然後通過首先連接到主節點,使用Spark shell連接到EMR集群。您首先需要通過導航到AWS控制台左側,在EC2上的EMR下,選擇Clusters,然後選擇您想要獲取公共DNS名的集群來獲取主節點的master公共DNS。
在您的操作系統終端中,輸入以下命令:
ssh hadoop@ec2-###-##-##-###.compute-1.amazonaws.com -i ~/mykeypair.pem將ec2-###-##-##-###.compute-1.amazonaws.com替換為您的master公共DNS名稱,將~/mykeypair.pem替換為您的.pem文件的文件和路徑名稱(按照此指南獲取.pem文件)。將出現一個提示消息,您應回答yes——輸入exit以關閉SSH命令。
準備數據以使用Spark進行處理並上傳到S3桶。
數據處理在上傳前需進行準備,以便以Spark能夠輕鬆處理的格式呈現數據。所使用的格式取決於您擁有的數據類型及計劃進行的分析。常用的格式包括CSV、JSON和Parquet。
建立新的Spark會話並使用相關API將數據載入Spark。例如,使用spark.read.csv()方法將CSV文件讀入Spark DataFrame。
Amazon EMR,一個管理Hadoop生態系統集群的服務,可用於數據處理。它減少了設置、調整和維護集群的需求。此外,它還具有與Amazon SageMaker等其他集成,例如,從Amazon EMR中的Spark管道啟動SageMaker模型訓練任務。
數據準備好後,使用DataFrame.write.format("s3")方法,您可以從Amazon S3桶讀取CSV文件到Spark DataFrame。您應已配置AWS憑證並具有寫入權限以訪問S3桶。
指定您希望保存數據的S3桶和路徑。例如,您可以使用df.write.format("s3").save("s3://my-bucket/path/to/data")方法將數據保存到指定的S3桶。
數據保存到S3桶後,您可以從其他Spark應用程序或工具訪問它,或者可以下載它進行進一步分析或處理。要上傳桶,創建一個文件夾並選擇您最初創建的桶。選擇“操作”按鈕,然後在下拉項目中點擊“創建文件夾”。現在您可以命名新文件夾。
要將資料檔案上傳至儲存桶,請選擇資料資料夾的名稱。
在「上傳」— 選擇「檔案精靈」並選擇「新增檔案」。
遵循Amazon S3控制台指示上傳檔案並選擇「開始上傳」。
在上傳資料至S3儲存桶前,考慮並確保實施最佳安全實踐是非常重要的。
理解資料格式與資料結構
資料格式與資料結構是資料管理中兩個相關但完全不同的重要概念。資料格式指的是資料在資料庫中的組織與結構。有多種格式用於儲存資料,如CSV、JSON、XML、YAML等。這些格式定義了資料應如何結構化,以及適用於不同類型資料和應用程式的差異。同時,資料結構是資料庫本身的結構。它定義了資料庫的布局,並確保資料被適當地儲存。資料庫結構指定了視圖、表、索引、類型及其他元素。這些概念在分析和資料庫視覺化中非常重要。
在S3中清理與預處理資料
在處理資料前,確認資料無誤是必要的。首先,訪問您在S3儲存桶中保存資料檔案的資料資料夾,並將其下載至本地機器。接著,將資料載入資料處理工具,該工具將用於清理與預處理資料。本教程使用的預處理工具是Amazon Athena,它有助於分析儲存在Amazon S3中的非結構化與結構化資料。
前往AWS控制台中的Amazon Athena。
点击“创建”以创建新表,然后选择“CREATE TABLE”。
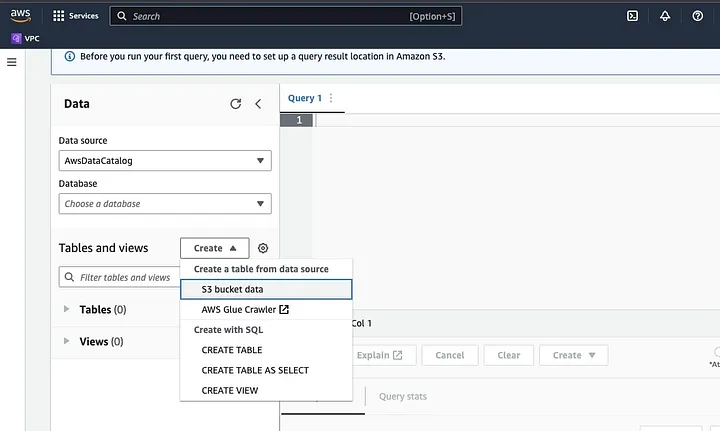
在标示为LOCATION的部分输入您的数据文件路径。
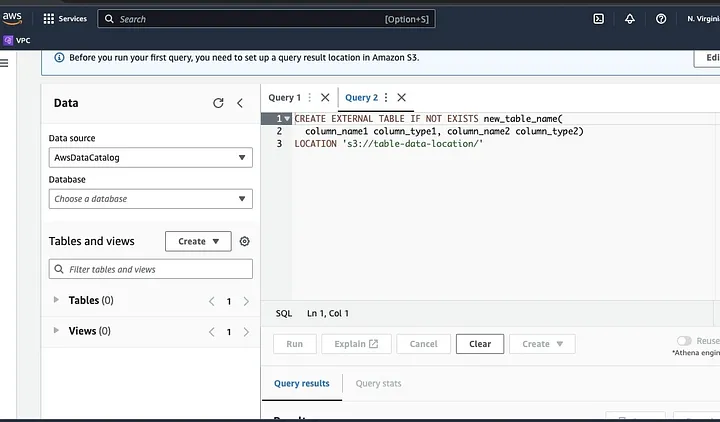
跟随提示定义数据模式并保存表。现在,您可以运行查询以验证数据是否正确加载,然后清理和预处理数据
示例:
此查询识别数据中的重复项。
SELECT row1, row2, COUNT(*)
FROM table
GROUP row, row2
HAVING COUNT(*) > 1;此示例创建一个不含重复项的新表:
CREATE TABLE new_table AS
SELECT DISTINCT *
FROM table;最后,通过导航至S3桶和上传文件的文件夹,将清理后的数据导回S3。
理解Spark框架
Spark框架是一个开源、简单且表达力强的集群计算系统,专为快速开发而设计。它基于Java编程语言,并作为其他Java框架的替代品。Spark的核心特性是其内存数据计算能力,这加速了大型数据集的处理。
配置Spark与S3协同工作
要配置Spark与S3协同工作,首先需将Hadoop AWS依赖项添加到您的Spark应用程序中。这可以通过在您的构建文件(例如Scala的build.sbt或Java的pom.xml)中添加以下行来完成:
libraryDependencies += "org.apache.hadoop" % "hadoop-aws" % "3.3.1"在您的Spark应用程序中输入AWS访问密钥ID和秘密访问密钥,方法是设置以下配置属性:
spark.hadoop.fs.s3a.access.key <ACCESS_KEY_ID>
spark.hadoop.fs.s3a.secret.key <SECRET_ACCESS_KEY>使用代码中的SparkConf对象设置以下属性:
val conf = new SparkConf()
.set("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.set("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")在您的Spark應用程式中設定S3端點URL,方法是設定以下配置屬性:
spark.hadoop.fs.s3a.endpoint s3.<REGION>.amazonaws.com將<REGION>替換為您的S3桶所在AWS區域(例如,us-east-1)。
為了讓Hadoop中的S3客戶端能夠訪問S3請求,需要一個符合DNS規範的桶名。如果您的桶名包含點或下劃線,可能需要為Hadoop中的S3客戶端啟用路徑樣式訪問,因為它使用虛擬主機樣式。設定以下配置屬性以啟用路徑訪問:
spark.hadoop.fs.s3a.path.style.access true最後,通過在Spark配置中設置spark.hadoop前綴來創建具有S3配置的Spark會話:
val spark = SparkSession.builder()
.appName("MyApp")
.config("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.config("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")
.config("spark.hadoop.fs.s3a.endpoint", "s3.<REGION>.amazonaws.com")
.getOrCreate()將<ACCESS_KEY_ID>、<SECRET_ACCESS_KEY>和<REGION>替換為您的AWS憑證和S3區域。
要在Spark中從S3讀取數據,將使用spark.read方法,然後指定S3路徑到您的數據作為輸入源。
以下是一個示例代碼,展示如何將S3中的CSV文件讀入Spark中的DataFrame:
val spark = SparkSession.builder()
.appName("ReadDataFromS3")
.getOrCreate()
val df = spark.read
.option("header", "true") // Specify whether the first line is the header or not
.option("inferSchema", "true") // Infer the schema automatically
.csv("s3a://<BUCKET_NAME>/<FILE_PATH>")在此示例中,將<BUCKET_NAME>替換為您的S3桶名稱,將<FILE_PATH>替換為桶內CSV文件的路徑。
使用Spark轉換數據
使用Spark進行數據轉換通常涉及對數據進行清洗、過濾、聚合和合併等操作。Spark提供了豐富的API用於數據轉換,包括DataFrame、Dataset和RDD API。常見的Spark數據轉換操作包括過濾、選擇列、數據聚合、數據合併和數據排序。
以下是一個數據轉換操作的示例:
數據排序:此操作涉及根據一個或多個列對數據進行排序。可以使用DataFrame或Dataset上的orderBy或sort方法根據一個或多個列對數據進行排序。例如:
val sortedData = df.orderBy(col("age").desc)最後,您可能需要將結果寫回到S3以存儲結果。
Spark提供了多種API來將數據寫入S3,例如DataFrameWriter、DatasetWriter和RDD.saveAsTextFile。
以下是一個代碼示例,展示如何將DataFrame以Parquet格式寫入S3:
val outputS3Path = "s3a://<BUCKET_NAME>/<OUTPUT_DIRECTORY>"
df.write
.mode(SaveMode.Overwrite)
.option("compression", "snappy")
.parquet(outputS3Path)將<BUCKET_NAME>替換為您的S3桶名稱,將<OUTPUT_DIRECTORY>替換為桶中輸出目錄的路徑。
使用mode方法指定寫入模式,可以是Overwrite、Append、Ignore或ErrorIfExists。option方法可用於指定輸出格式的各種選項,如壓縮編解碼器。
您還可以通過更改輸出格式並指定適當的選項,將數據以其他格式(如CSV、JSON和Avro)寫入S3。
了解Spark中的資料分割
簡單來說,Spark中的資料分割是指將資料集分割成更小、更易於管理的部分,分布在整個集群中。這樣做的目的是優化性能,減少可擴展性問題,並最終提高資料庫的管理性。在Spark中,資料是在多個集群上並行處理的。這得益於彈性分布式數據集(RDD),這是一種包含大量、複雜數據的集合。默認情況下,由於其大小,RDD會在各個節點上進行分割。
為了實現最佳性能,有幾種方法可以配置Spark,確保任務能夠迅速執行,並且資源得到有效管理。這些方法包括快取、內存管理、數據序列化以及使用mapPartitions()而非map()。
Spark UI是一個基於網頁的圖形用戶界面,提供了關於Spark應用程序性能和資源使用的全面信息。它包含多個頁面,如概覽、執行器、階段和任務,提供了Spark作業各個方面的信息。Spark UI是監控和調試Spark應用程序的重要工具,它幫助識別性能瓶頸和資源限制,並解決錯誤。通過檢查任務完成數量、作業持續時間、CPU和內存使用情況以及洗牌數據的寫入和讀取等指標,用戶可以優化其Spark作業,確保它們高效運行。
結論
總結來說,在AWS S3上使用Apache Spark處理數據是一種高效且可擴展的大數據分析方法。透過利用AWS S3的雲端儲存與計算資源以及Apache Spark,用戶能夠快速有效地處理數據,無需擔心架構管理。
在本教程中,我們介紹了如何在AWS EMR上設置S3桶和Apache Spark集群,配置Spark以與AWS S3協同工作,以及編寫和運行Spark應用程序來處理數據。此外,我們還探討了Spark中的數據分區、Spark UI和性能優化。
參考文獻
如需深入了解如何配置Spark以達到最佳性能,請參閱這裡。
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-ssh.html
Source:
https://dzone.com/articles/stateful-stream-processing-with-memphis-and-apache-spark