













左移策略是一種強調在軟件開發生命周期早期進行測試、監控和自動化的軟件開發與運營方法。其目標是通過早期發現問題並迅速解決,來預防問題的發生。
當你及早發現可擴展性問題或錯誤時,解決起來更快捷且成本效益更高。將低效代碼遷移到雲容器可能代價高昂,因為這可能觸發自動擴展並增加你的月度賬單。此外,在能夠識別、隔離和修復問題之前,你將處於緊急狀態。
問題陳述
I would like to demonstrate to you a case where we managed to avert a potential issue with an application that could have caused a major issue in a production environment.
I was reviewing the performance report of the UAT infrastructure following the recent application change. It was a Spring Boot microservice with MariaDB as the backend, running behind Apache reverse proxy and AWS application load balancer. The new feature was successfully integrated, and all UAT test cases are passed. However, I noticed the performance charts in the MariaDB performance dashboard deviated from pre-deployment patterns.
以下是事件的時間線。
8月6日14:13,應用程序使用包含內嵌Tomcat的新Spring Boot jar文件重新啟動。
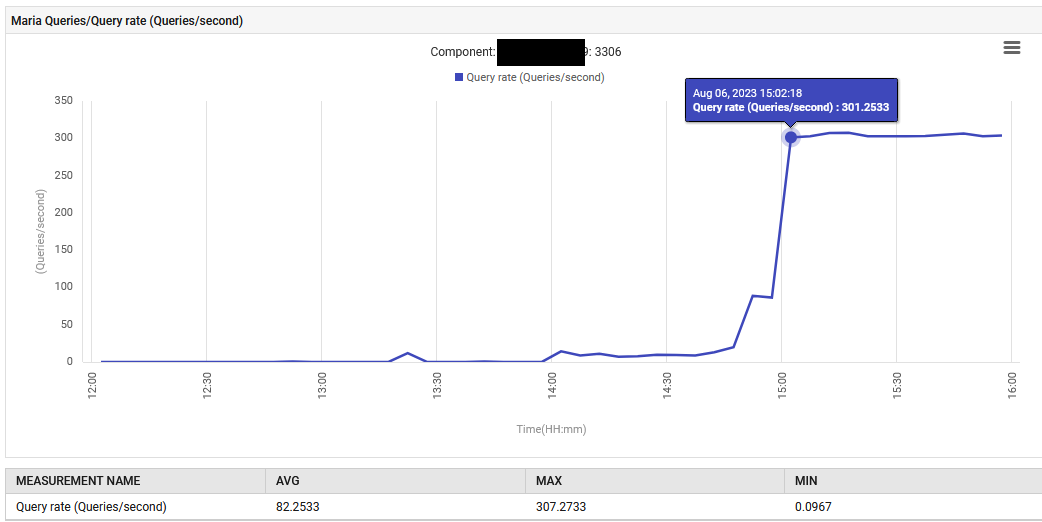
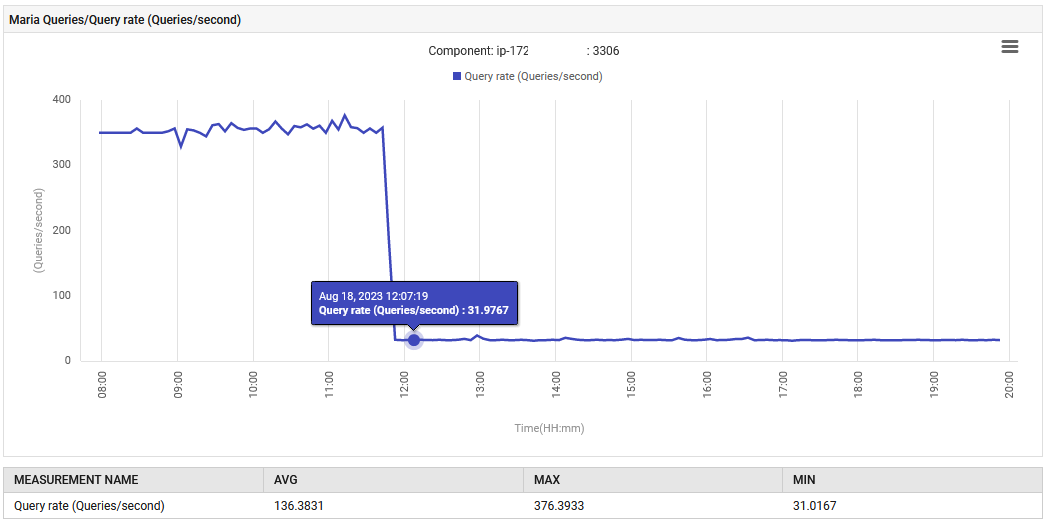
14:52,MariaDB的查詢處理速率從0.1增加到每秒88次查詢,隨後增至每秒301次查詢。
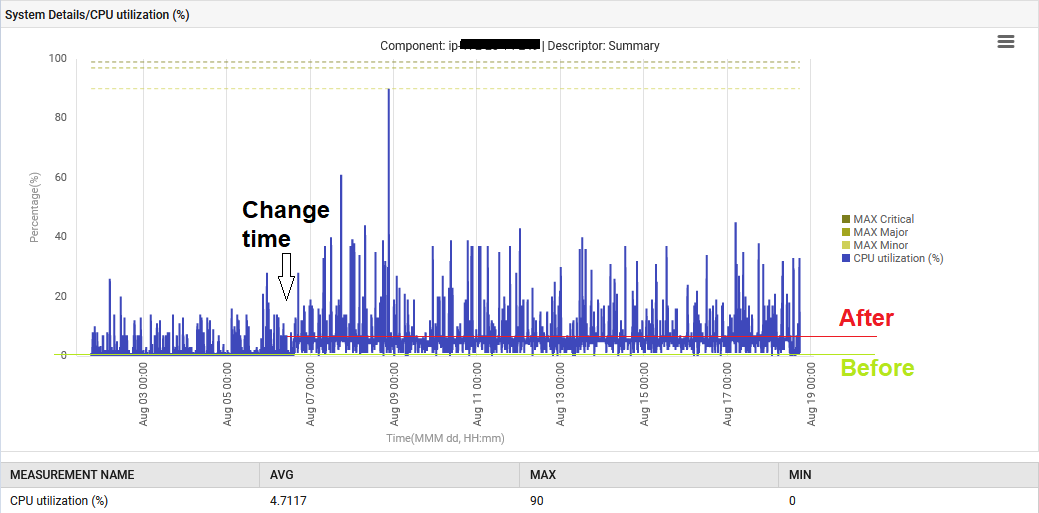
同時,系統CPU使用率從1%上升至6%。
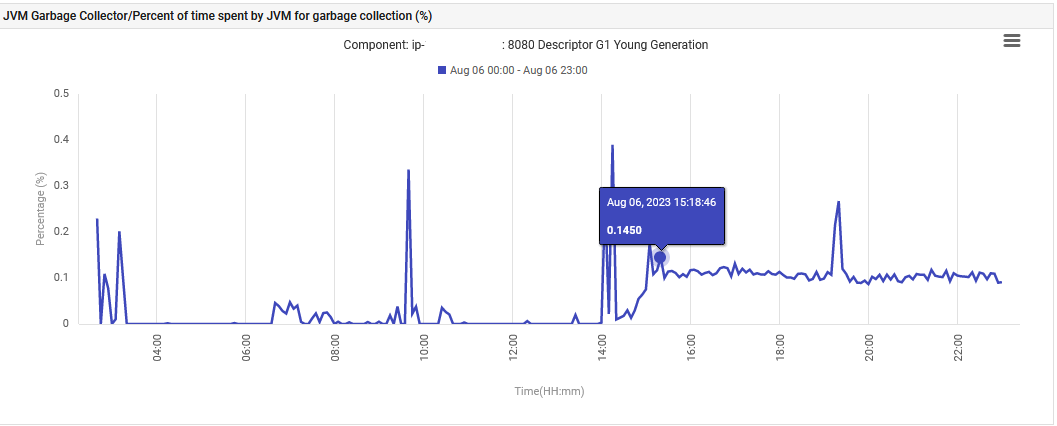
最後,JVM在G1年輕代垃圾收集上花費的時間從0%增加到0.1%,並保持在該水平。
應用程式在UAT階段出現異常,每秒發出300筆查詢,遠超過其設計容量。新功能導致資料庫連線數增加,進而造成查詢量劇增。然而,監控儀表板顯示在新版本部署前,異常指標均處於正常範圍。
解決方案
此應用程式為Spring Boot架構,使用JPA查詢MariaDB資料庫。設計上,應用程式最初在兩個容器上運行以承擔最小負載,但預計可擴展至十個容器。
若單一容器能產生每秒300筆查詢,當十個容器全數運作時,是否能處理每秒3000筆查詢?資料庫是否有足夠連線數滿足應用程式其他部分的需求?
我們別無選擇,只能回頭檢查開發者在Git上的變更。
新變更涉及從一個表中提取幾筆記錄進行處理,這是服務類別中的觀察結果。
List<X> findAll = this.xRepository.findAll();
不,在Spring的CrudRepository中不使用分頁的findAll()方法並不高效。分頁有助於通過限制獲取的數據量來減少從數據庫檢索數據所需的時間,這是我們主要關係數據庫管理系統教育所教授的。此外,分頁有助於保持低內存使用,防止應用程序因數據過載而崩潰,並減少Java虛擬機的垃圾收集工作,這在上文問題陳述中已提及。
此測試僅在單一容器中使用2,000條記錄進行。如果此代碼轉移到生產環境,其中有多達200,000條記錄分布在多達10個容器中,那可能會讓團隊在那一天感到極大的壓力和擔憂。
應用程序通過在方法中添加WHERE子句進行了重建。
List<X> findAll = this.xRepository.findAllByY(Y);
正常功能得以恢復。每秒查詢次數從300降至30,垃圾收集的努力回復到原來的水平。此外,系統的CPU使用率也有所下降。
學習與總結
任何從事網站可靠性工程(SRE)的人士都會認識到這一發現的重要性。我們能夠採取行動,而無需升級至嚴重性1級別。若此缺陷套件被部署於生產環境,可能會觸發客戶的自動擴展閾值,導致即使沒有額外用戶負載,新的容器也會被啟動。
從這個故事中,我們可以汲取三個主要教訓。
首先,從一開始就啟用可觀察性解決方案是最佳實踐,因為它能提供事件歷史,有助於識別潛在問題。若無此歷史,我可能不會對0.1%的垃圾回收率和6%的CPU消耗給予重視,代碼可能就會帶著災難性後果被釋出至生產環境。擴大監控解決方案的範圍至UAT伺服器,幫助團隊識別潛在的根本原因,並在問題發生前加以預防。
其次,測試過程中應包含與性能相關的測試案例,並應由具有可觀察性經驗的人員進行審查。這將確保代碼的功能性得到測試,同時也包括其性能。
第三,雲原生的性能追蹤技術有助於接收有關高利用率、可用性等的警報。為了實現可觀察性,您可能需要適當的工具和專業知識。快樂編碼!
Source:
https://dzone.com/articles/shift-left-monitoring-approach-for-cloud-apps-in-c