













retrieval 增強生成 (RAG) 是在大語言模型 (LLM) 領域中的一項革命性進展。它將變壓器結構的生成能力與动态信息检索結合在一起。
這種結合讓 LLM 能在文字生成的過程中存取和融合相關的外部知識,從而使产出的內容更加準確、符合語境且事實上一致。
從早期的規則基礎系統演變到像 BERT 和 GPT-3 這樣的複雜神经模型,已經為 RAG 开辟了道路,解決了靜態参数記憶的限制。此外,多模態 RAG 的出現通過結合如圖片、音樂和影片等不同數據類型的數據,擴大了這些功能。這提高了生成內容的豐富性和相關性。
這個 paradigmshift 不僅提高了 LLM 产出內容的準確性和解釋性,也支持在各行各業 Innovative applications。
我們將要覆蓋的是:
- 第 1 章。RAG 简介
– 1.1 RAG 是什么?概览
– 1.2 RAG 如何解決複雜問題 - 第2章 技術基礎
– 2.1 由神經LM转向RAG
– 2.2 理解RAG的記憶體:参数式對非参数式
– 2.3 多模態RAG:結合多種數據類型 - 第3章 核心機制
– 3.1 RAG中結合信息捞取和生成的力量
– 3.2 捞取器和生成器的整合策略 - 第4章 應用與案例
– 4.1 RAG在工作中的应用:從QA到創意寫作
– 4.2 RAG對於低資源語言的应用:扩展覆蓋範圍和功能 - 第五章. 優化技術
– 5.1 優化 RAG 系統的進階捞取技術 - 第六章. 挑戰與創新
– 6.1 RAG 目前面臨的挑戰與未來方向
– 6.2 RAG 系統的硬體加速與有效部署 - 第七章. 結論思考
– 7.1 RAG 的未來:結論與反思
前提知識
對於參與大型語言模型(如捞取增強生成 RAG)相關內容,兩個基本的前提知識是:
- 機器學習基礎:理解基本的機器學習概念和算法至關重要,特別是它們如何應用於神經網絡結構。
- 自然語言處理 (NLP):掌握NLP技術,包括文本預處理、分詞和嵌入的使用,對於處理語言模型至關重要。
第1章:RAG簡介
檢索增強生成 (RAG) 通過結合信息檢索和生成模型,徹底改變了自然語言處理。RAG動態訪問外部知識,提升生成文本的準確性和相關性。
本章探討RAG的機制、優勢和挑戰。我們深入研究檢索技術、與生成模型的整合以及對各種應用的影響。
RAG減少幻覺,融入最新信息,解決複雜問題。我們還討論了如高效檢索和倫理考量等挑戰。本章提供了對RAG在自然語言處理中變革潛力的全面理解。
1.1 什麼是RAG?概述
檢索增強生成 (RAG) 代表了自然語言處理中的一個範式轉變,無縫結合了信息檢索和生成語言模型的優勢。RAG系統利用外部知識來源來提升生成文本的準確性、相關性和連貫性,解決傳統語言模型中純參數記憶的局限性。(Lewis 等人,2020)
動態地擷取和融入相關資訊於生成過程中,RAG 讓更多情境基礎和事實上一致性的輸出遍及各種應用,從問答和對話系統到摘要和創作寫作。(Petroni et al., 2021)
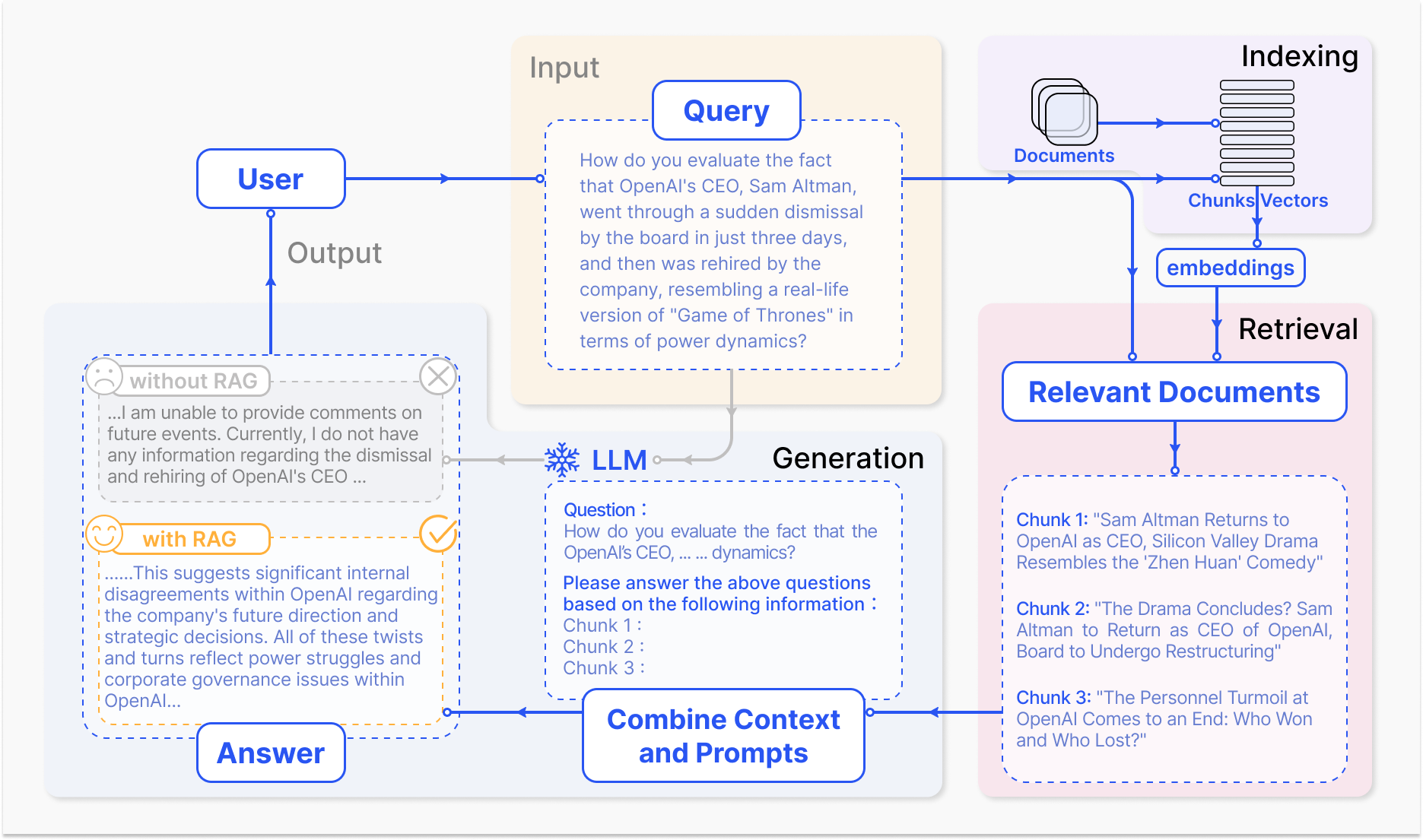
RAG 系統的操作方式 – arxiv.org
RAG 的核心機制涉及兩個主要組件:擷取和生成。
擷取組件有效率地在龐大的知識庫中搜索,以根據輸入查詢或上下文識別最相關的資訊。採用例如稀疏擷取(利用反向索引和基於詞的匹配)和密集擷取(使用密集向量表示和語義相似性)等技術來優化擷取過程。(Karpukhin et al., 2020)
然後將擷取的資訊整合到生成模型中,這通常是像 GPT 或 T5 這樣的大型語言模型,它將相關內容合成为一個連貫且流暢的回答。(Izacard & Grave, 2021)
整合搜尋與生成於 RAG 中,相比傳統語言模型具有多項優勢。透過將生成文字扎根於外部知識,RAG 明顯降低產生幻覺或事實不正確輸出的發生率。(Shuster et al., 2021)
RAG 還能讓您融入最新資訊,確保生成的回應能反映在特定領域中的最新知識和發展動態。(Lewis et al., 2020)這種適應性在醫療保健、金融和科學研究等領域特別關鍵,在這些領域中資訊的準確性和及時性至關重要。(Petroni et al., 2021)
但 RAG 系統的開發和部署也帶來了顯著的挑戰。從大規模知識庫中高效搜尋、減少幻覺發生以及整合多種數據模態等技術障礙都需要被解決。(Izacard & Grave, 2021)
此外,倫理考量,例如確保資訊檢索和生成的公平性和無偏見,對於負責任地部署RAG系統至關重要。(Bender et al., 2021) 開發全面的評估指標和框架,以捕捉檢索準確性與生成質量之間的相互作用,對於評估RAG系統的有效性至關重要。(Lewis et al., 2020)
隨著RAG領域的不斷發展,未來的研究方向將集中在優化檢索過程、擴展多模態能力、開發模塊化架構和建立健全的評估框架。(Izacard & Grave, 2021) 這些進步將提升RAG系統的效率、準確性和適應性,為自然語言處理領域的更智能和多功能應用鋪平道路。
以下是一個基本的Python代碼示例,演示了使用流行庫LangChain和FAISS設置的檢索增強生成(RAG)系統:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. 載入並嵌入文件
loader = TextLoader('your_documents.txt') # 更換為您的文件來源
documents = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. 獲取相關文件
def retrieve_docs(query):
return vectorstore.similarity_search(query)
# 3. 設置 RAG 鏈
llm = OpenAI(temperature=0.1) # 調整溫度以增強回應創造力
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 4. 使用 RAG 模型
def get_answer(query):
return chain.run(query)
# 使用示例
query = "What are the key features of Company X's latest product?"
answer = get_answer(query)
print(answer)
#公司歷史使用示例
query = "When was Company X founded and who were the founders?"
answer = get_answer(query)
print(answer)
#財務業績使用示例
query = "What were Company X's revenue and profit figures for the last quarter?"
answer = get_answer(query)
print(answer)
#未來展望使用示例
query = "What are Company X's plans for expansion or new product development?"
answer = get_answer(query)
print(answer)
通過利用检索和生成的能力,RAG 對於改變我們與信息互動及生成信息的方式充滿巨大潛力,將革新各個領域,塑造人機交互的未來。
1.2 RAG 如何解決複雜問題
检索增強生成(RAG)為傳統大型語言模型(LLM)在面對大量非結構化數據時難以解決的複雜問題提供了一種強大的解決方案。
這樣的一個問題是在沒有對目標材料進行先前的微調或明確訓練的情況下,能夠對特定文件或多媒體內容(如 YouTube 影片)進行有意義的對話。
傳統的 LLM(大規模語言模型)雖然具有令人印象深刻的生成能力,但其受限於Parametric Memory,該記憶在訓練時就已固定。(Lewis et al., 2020) 這意味著它們無法直接訪問或融合超出其訓練數據的新信息,這使得它們在參與關於未見文件或影片的已经有根據的討論時面臨困難。
因此,LLM 在針對特定內容的查詢被提示時,可能會產生不一致、不相關或事实錯誤的回应。(Petroni et al., 2021)
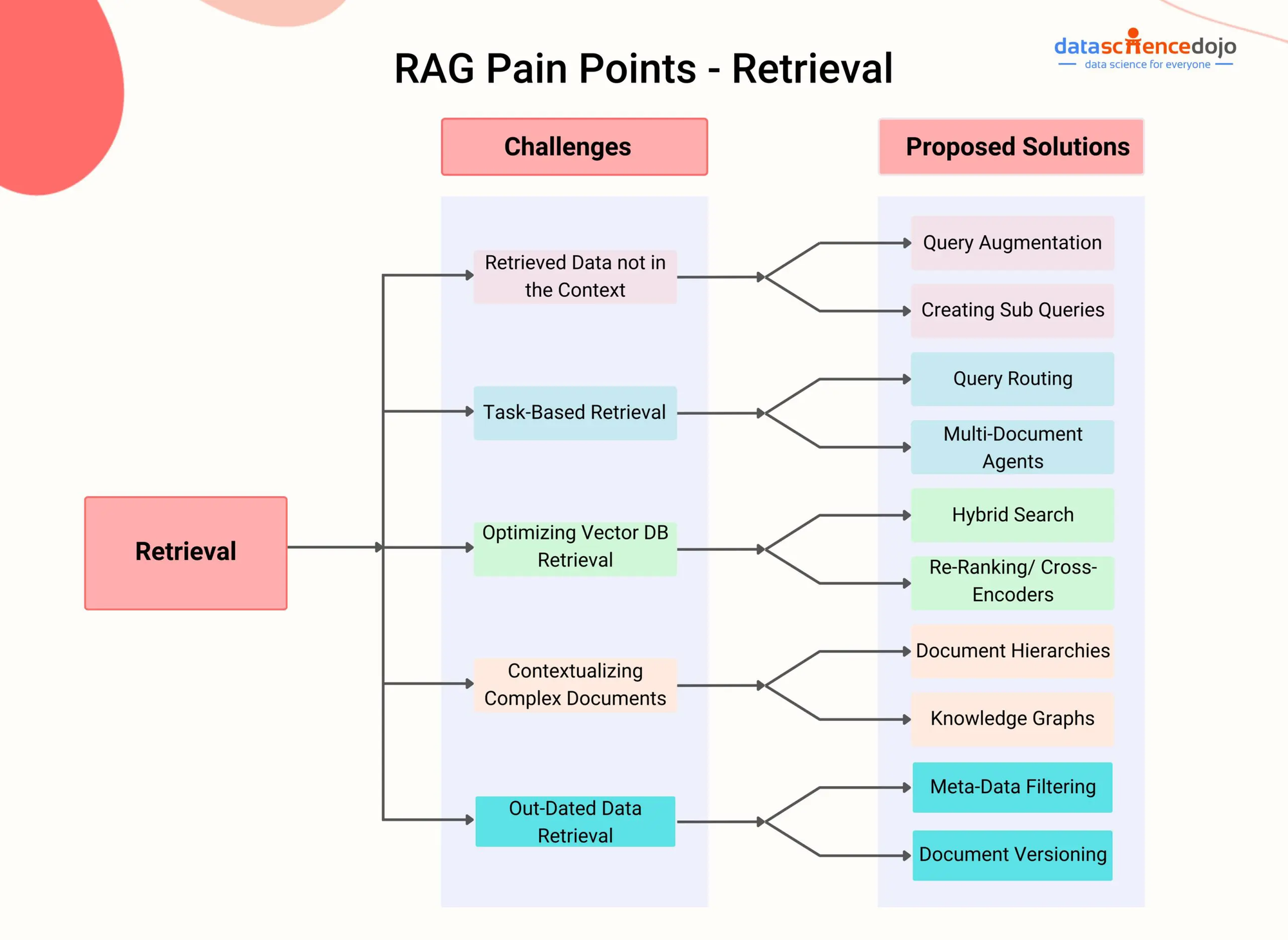
RAG 痛點 – DataScienceDojo
RAG 通過整合一個检索部件來解決這個限制,使模型能在生成的過程中動態地訪問和融合外部知識源中的相關信息。
通過運用先进的检索技術,如密集文章检索 (Karpukhin et al., 2020) 或混合搜索 (Izacard & Grave, 2021),RAG 系統能有效地根據對話情境從給定的文件或影片中識別出最相關的段落或片段。
例如,考慮一個用戶想在科學主題的YouTube影片上進行對話的情境。一個RAG系統可以首先轉錄影片的音頻內容,然後使用密集向量表示法索引這些文字。
然後,當用戶問一個與影片相關的問題時,RAG系統的捞取部件可以快速根據查詢與索引內容的語義相似性,從轉录中確定最相關的段落。
然後將這些捞取的段落送入生成模型,該模型生成了一個连貫且有益的回应,直接解決用戶的問題,並將回答扎根於影片內容中。 (Shuster等,2021)
這種方法使RAG系統能夠在不需要顯式微調的情況下,與各種文件和多媒体內容進行有知識的對話。通過动态捞取和融合相关信息,RAG生成的回应比传统的LLM更準確、相關且事实上一致。 (Lewis等,2020)
同時,RAG對於處理來自各種模態的非結構化數據,如文本、圖像和音頻等,使其成為解決涉及異質信息來源複雜問題的多功能解決方案。Izacard & Grave, 2021隨著RAG系統的不斷進化,它們解決跨多個領域複雜問題的潛力也在增長。
通過利用先進的檢索技術和多模態整合,RAG能夠實現更智能和更具上下文感知能力的對話代理、個性化推薦系統以及知識密集型應用。
隨著研究在高效索引、跨模態對齊和檢索-生成整合等領域的進展,RAG無疑將在推動語言模型和人工智能可能性的邊界上發揮關鍵作用。
第二章:技術基礎
本章节深入探究多模態檢索增強生成(RAG)的迷人世界,這是一種超越傳統文本基模型限制的尖端方法。
通過將圖像、音頻和視頻等多種數據模態與大型語言模型(LLM)無縫整合,多模態RAG賦予AI系統在更豐富的信息環境中進行推理。
我們將探索這種整合背後的機制,如對比學習和跨模態注意力,以及它們如何使LLM生成更細膩和具有上下文相關性的回應。
的多模態RAG提供了如提高準確性以及支援如視覺問答等新興使用案例等前景廣大的好處,但它也帶來了獨特的挑戰。這些挑戰包括對大型多模態數據集的需求、計算複雜性的增加,以及检索資訊中可能存在的偏見。
在我們開始這段旅程時,我們不僅將揭開多模態RAG的轉變性潛力,還將嚴格檢視前方存在的障礙,為這個快速演變的領域鋪平道路。
2.1 從神經網路語言模型到RAG
語言模型的發展以從早期基於規則的系統逐漸進步到越來越複雜的統計和基於神經網路的模型為特徵。
在早期,語言模型依賴於手動製作的規則和語言學知識來生成文本,導致產生的結果僵硬且有限。統計模型的出現,如n-gram模型,引入了一種數據驅動的方法,從大規模語料庫中學習模式,實現了更自然、更一致的語言生成。(Redis)
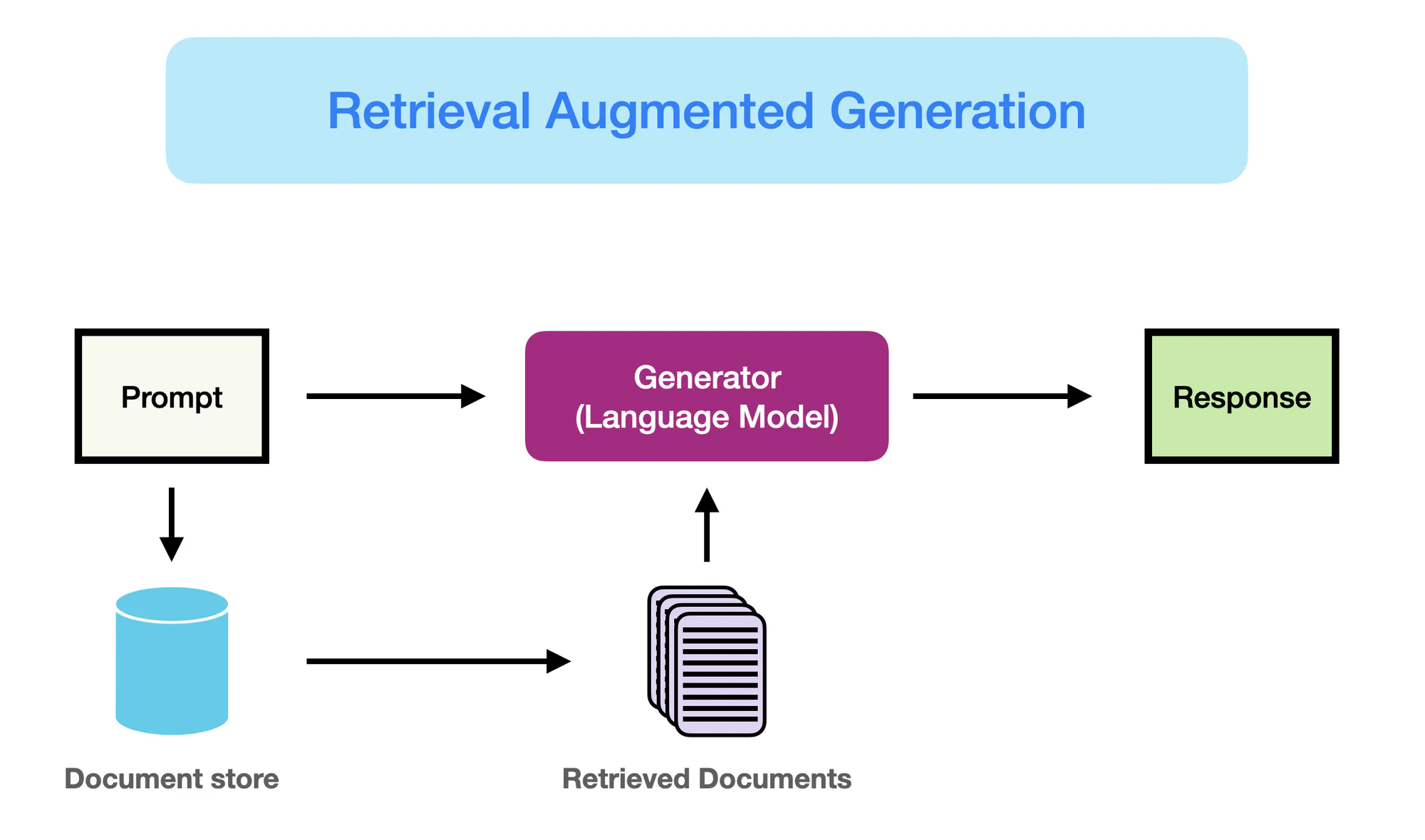
RAG是如何工作的 – promptingguide.ai
然而,基於神經網路的模型,尤其是像BERT和GPT-3這樣的轉換器架構的出現,徹底改革了自然語言處理(NLP)的領域。
這些模型,被稱為大型語言模型(LLM),利用深度學習的威力捕捉複雜的語言模式,並以前所未有的流暢和一致性生成類似人類的文本。Yarnit隨著LLM的複雜性和規模不斷增加,像GPT-3這樣的模型具有超過1750億個參數,在語言翻譯、問答和內容創作等任務中展現了驚人的能力。
儘管這些傳統LLM的表現令人印象深刻的,但它們由於依賴純粹的參數記憶而存在局限性。StackOverflow這些模型中編碼的知識是靜態的,受到其訓練數據截止日期的限制。
因此,LLM可能會生成在事實上不正確或不與最新資訊一致的輸出。此外,缺乏對外部知識來源的直接訪問限制了它們對知識密集型查詢提供準確和情境相關回應的能力。
检索增強生成(RAG)作為一種改變遊戲规则的解決方案出現,以解決這些限制。通過將信息檢索功能與LLM的生成能力無縫整合,RAG使模型能在生成過程中動態訪問和融入外部來源的相关知識。
这种参数化與非参数化記憶的融合,使得配有RAG的LLM能夠產生不僅流暢一致,而且事实正確且符合上下文的輸出。
RAG在語言生成方面代表了重要的進步,它將LLM的優點與外部庫中可用的廣闊知識結合起來。通過充分利用兩者的優點,RAG賦予模型生成更可靠、信息更多、并与现实世界知識對齐的文本。
這種 paradigmshift為NLP應用敞开了新的可能性,從問題回答和內容創建到醫療、金融和科學研究等領域的知識密集型任務。
2.2 参数化與非参数化記憶
参数化記憶指的是储存在預訓練语言模型如BERT和GPT-4的参数中的知識。這些模型在訓練過程中從大量的文本數據中學習捕捉語言模式和關係,將這種知識編碼在它們的数百萬或數十億個参数中。
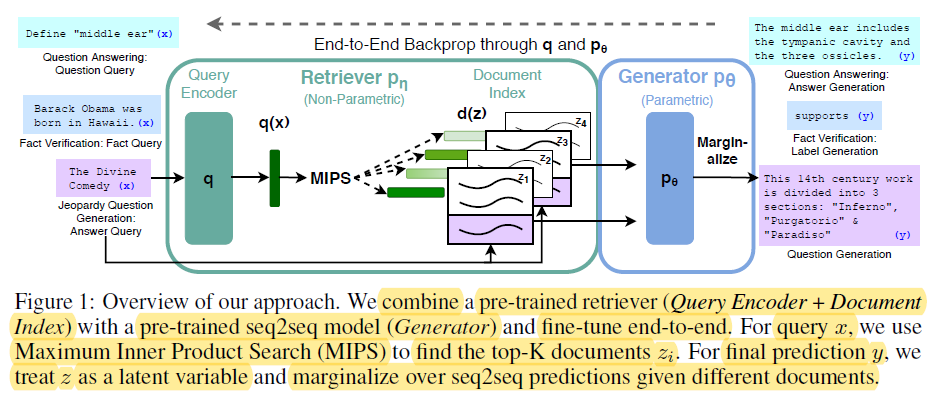
端到端反向傳播通過q和p0 – miro.medium.com
参数化記憶的優點包括:
- 流暢度:預先訓練的語言模型能夠生成類似真人的文本,具有驚人的流暢性和一致性,捕捉到自然語言的細微之處與風格。(Redis 與 Lewis 等。)
- 泛化能力:模型參數中編碼的知識使其能夠泛化到新的任務和領域,實現轉移學習和少次學習能力。(Redis 與 Lewis 等。)
然而,參數記憶也有著顯著的限制:
- 事實錯誤:語言模型可能生成與現實世界事實不一致的輸出,因為其知識僅限於訓練數據。
- 知識過時:模型參數中編碼的知識隨著時間的推移會變得陳舊,因為它固定於訓練時期,並不反映現實世界的更新或變化。
- 高計算成本:訓練大型語言模型需要大量的計算資源和能源,使得更新其知識既昂貴又耗時。
- 常識知識:語言模型捕捉到的知識廣泛而普遍,缺乏許多領域特定應用所需的深度和專精。
相比之下,非參數記憶指的是使用明確的知識來源,如數據庫、文件和知識圖,為語言模型提供最新和準確的信息。這些外部來源作為記憶的一種補充形式,使得模型能在生成過程中按需訪問和提取相關信息。
非參數記憶的好處包括:
- 即時更新的資訊:外部知識來源可以輕易地更新和維護,確保模型能夠獲取最新和最準確的資訊。
- 降低幻覺產生:”通過從外部來源提取相關信息,RAG顯著降低了幻覺或事實上不正確的生成輸出的發生率。”(Lewis等人和Guu等人)
- 特定領域知識:非參數記憶使模型能夠利用來自特定領域的專業知識,讓特定應用能夠產生更準確和符合語境的輸出。(Lewis等人。以及Guu等人。)
參數記憶的限制凸顯了在語言生成中需要進行范式轉變。
RAG通過整合信息檢索技術,提高了生成模型的性能,這在自然語言處理方面是一個重要的進展。(Redis)
以下是Python代碼,用於演示在RAG的背景下參數記憶和非參數記憶的區別,並且輸出標識清晰的區分:
from sentence_transformers import SentenceTransformer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
# 示例文件集(在真實情況中假設有更大量的文件)
documents = [
"The Large Hadron Collider (LHC) is the world's largest and most powerful particle accelerator.",
"The LHC is located at CERN, near Geneva, Switzerland.",
"The LHC is used to study the fundamental particles of matter.",
"In 2012, the LHC discovered the Higgs boson, a particle that gives mass to other particles.",
]
# 1. 非參數記憶(使用嵌入的檢索)
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. 參數記憶(帶檢索的語言模型)
llm = OpenAI(temperature=0.1) # 調整溫度以改變回應的創造力
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# --- 查詢和回應 ---
query = "What was discovered at the LHC in 2012?"
answer = chain.run(query)
print("Parametric (w/ Retrieval): ", answer["answer"])
query = "Where is the LHC located?"
docs = vectorstore.similarity_search(query)
print("Non-Parametric: ", docs[0].page_content)
輸出:
Parametric (w/ Retrieval): The Higgs boson, a particle that gives mass to other particles, was discovered at the LHC in 2012.
Non-Parametric: The LHC is located at CERN, near Geneva, Switzerland.
以下是這段代碼中發生的事情:
參數記憶:
- 利用LLM的廣泛知識生成全面的答案,包括希格斯玻色子賦予其他粒子質量的關鍵事實。LLM通過其廣泛的訓練數據進行「參數化」。
非參數記憶:
- 在向量空間中執行相似性搜索,找到最相關的文件來直接回答關於LHC位置的問題。它不合成新信息,只是檢索相關事實。
關鍵差異:
| Feature | Parametric Memory | Non-Parametric Memory |
|---|---|---|
| 知識存儲 | 編碼在模型的參數(權重)中作為學習表示。 | 直接存儲為原始文本或其他格式(例如,嵌入)。 |
| 檢索 | 利用模型的生成能力,根據其學習知識生成與查詢相關的文本。 | 涉及搜索與查詢密切匹配的文件(例如,通過相似性或關鍵字匹配)。 |
| 靈活性 | 高度靈活,可以生成新的回應,但也可能產生錯誤信息。 | 靈活性較低,但因依賴現有數據而較少產生錯誤。 |
| 回應風格 | 能夠產生更詳細和細緻的回應,但可能包含更多無關信息。 | 提供直接而簡潔的答案,但可能缺乏上下文或詳細說明。 |
| 計算成本 | 生成回答可以是非常 compute 密集型,特別是對於大型的模型。 | 取回可以更快速,特別是使用有效率的索引和搜寻算法。 |
通過結合参数量化和非量化記憶的優點,RAG 解決了傳統語言模型的局限性,並使生成的回答更加準確、更新、以及相關上下文。(Redis, Lewis 等人。, 和 Guu 等人。
2.3 多模態 RAG:結合文本
多模態 RAG 通過纳入如圖像、音頻和視頻等多種數據模態,擴展了传统的基于文本的 RAG 范式,以提升大语言模型 (LLM) 的取回和生成能力。
通過 leveraging 对比学习技巧,多模態 RAG 系統學習將不同類型的數據嵌入共享向量空間,使跨模態取回變得 seamless。這使得 LLM 能夠在更豐富的背景下進行推理,結合文本信息與視覺和聽覺线索,生成的回答更加複雜且相關上下文。 (Shen 等人。)
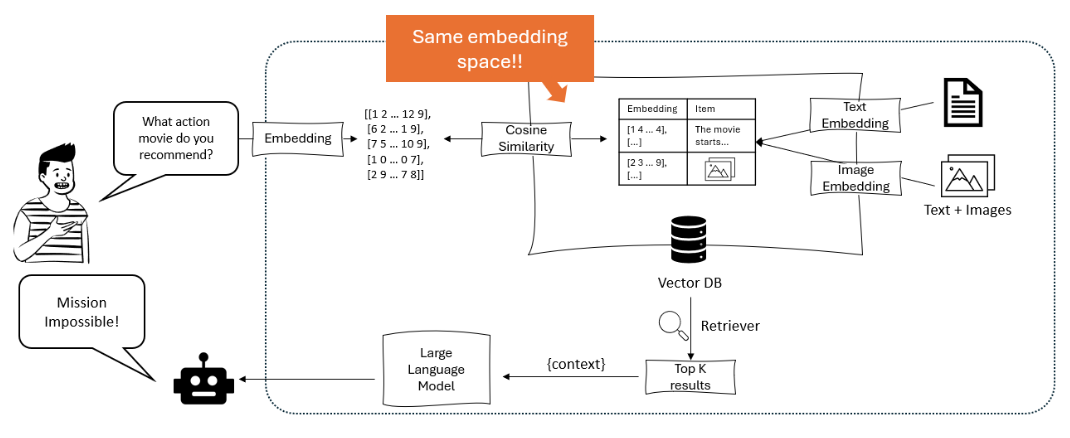
圖表展示了一個推薦系統,其中大型語言模型將用戶的查詢轉化為嵌入式表示,然後在包含文本和圖像嵌入的向量數據庫中使用餘弦相似度進行匹配,以找回並推薦最相關的项目。 – opendatascience.com
多模態RAG的一个关键方法是使用像ViLBERT和LXMERT這樣基於變壓器的模型,這些模型采用跨模態注意力機制。這些模型在生成文本時可以關注圖像中的相關區域或音頻/視頻中的特定片段,捕捉模態之間的細粒度互動。這使得生成的响应更具視覺和情境基礎。 (Protecto.ai)
在RAG管線中將文本與其他模態集成時,会遇到诸如對不同數據類型的語義表示進行對齊和處理嵌入過程中方案独特特徵等的挑戰。為了解決這些問題,使用了如模態特定編碼和跨注意力等技術。 (Zhu 等人。)
但多模態RAG的潛在益處是顯著的,包括提高生成的內容的準確性、可控性和可解釋性,以及支持像視覺問題回答和多模態內容創建等新興用例的能力。
例如,李等(2020)提出了一個多模態RAG框架用於視覺問答,該框架檢索相關的圖像和文字資訊以生成準確的回答,在VQA v2.0和CLEVR等基準測試中超越了之前的最佳做法。MyScale
儘管結果充滿希望,但多模態RAG也引入了新的挑戰,例如計算複雜度的增加、對大型多模態數據集的需求,以及檢索資訊中可能存在的偏差和噪音。
研究人員正在積極探索技術來緩解這些問題,例如有效的索引結構、數據增強策略和對抗性訓練方法。Sohoni等
第三章:RAG的核心機制
本章探討了在檢索增強生成(RAG)系統中,檢索器和生成模型之間的複雜互動,強調它們在索引、檢索和綜合資訊以產生準確和情境相關回應中的關鍵角色。
我們深入研究稀疏和密集檢索技術的細微差別,比較它們在不同情境下的優劣。此外,我們還考察了將檢索到的資訊整合到生成模型中的各種策略,例如串接和交叉注意力,並討論它們對RAG系統整體效能的影響。
透過理解這些整合策略,您將獲得有價值的見解,了解如何針對特定任務和領域優化RAG系統,為這種強大架構的更明智和有效使用鋪平道路。
3.1 在RAG中結合資訊检索與生成的力量
RAG(检索增強生成)代表了一種強大的架構,它將資訊检索與生成語言模型無縫整合。從其名稱可看出,RAG主要由兩個主要組件構成:检索與生成。
检索組件負責索引並搜尋廣大的知識庫,而生成組件則利用检索到的資訊來產生符合情境相關和事實準確的回應。(Redis與Lewis等)
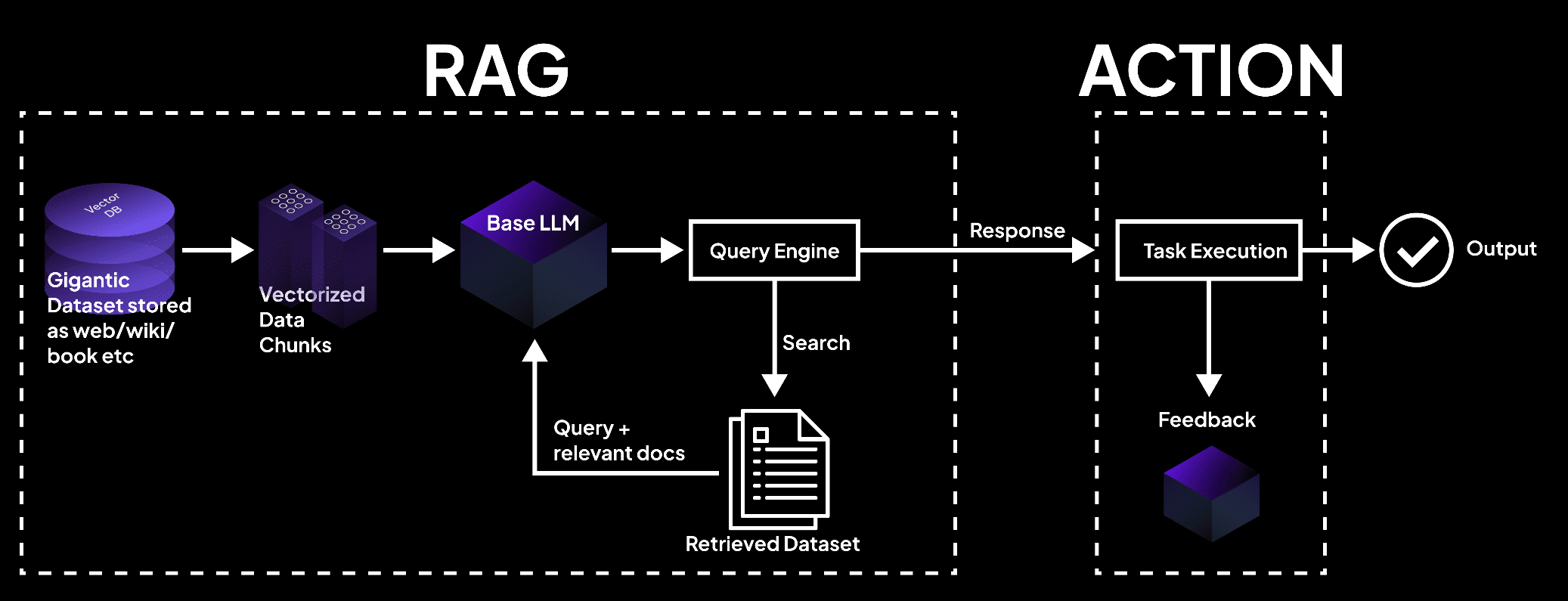
圖片展示了一個RAG系統,其中向量數據庫將數據處理成塊,語言模型進行查詢以獲取文檔以執行任務和產生精準輸出。- superagi.com
搜索流程從外部知識來源如數據庫、文件和網頁的索引開始。 (Redis 和 Lewis 等人) 搜寻器和索引器在這個過程中扮演了重要角色,有效地組織和儲存信息,使其便于快速搜索和找回。
當向 RAG 系統提出一个问题時,搜寻器會者在索引知識庫中搜索,根據語義相似度和其他相關度量标识最相关的信息。
一旦找回相關信息,生成组件接手。找回的內容用作提示和指導生成式語言模型,為它提供必要的背景和事实根據以生成準確和有益的回應。
該語言模型運用先进的推理技術,如注意力机制和變压器結構,將找回的信息與其預先存在的知識合成,並生成连贯流暢的文本。
RAG 系統內信息的流動可以如下所示:
graph LR
A[Query] --> B[Retriever]
B --> C[Indexed Knowledge Base]
C --> D[Relevant Information]
D --> E[Generator]
E --> F[Response]
RAG 的優點多種多樣:
這種提取與生成的能力提升,使得所能創造的回應不僅在情境上適切,同時也受益於最新的、準確的資訊。(Guu 等人)
通過運用外部知識來源,RAG 顯著減少了我虛構或事实錯誤的輸出,這是在纯粹生成模型中常見的陷阱。
此外,RAG 允許整合最新的資訊,確保所生成的回應反映給定領域的最新知識和发展。这在醫療、金融和科學研究等領域尤為重要,那裡信息的準確性和时效性至關重要。(Guu 等人 和 NVIDIA)
RAG 也展現出顯著的適應性,使語言模型能以提升的性能處理各種任務。通過根據特定的查詢或情境动态提取相關資訊,RAG 使模型能夠生成符合每項任務独特要求的反應,無論是問題回答、內容生成還是領域特定的應用。
許多研究已經證明了 RAG 在提高生成語言模型的事實準確性、相關性和適應性方面的有效性。
例如,Lewis 等人 (2020) 顯示 RAG 在多種問答任務中勝過純生成模型,並在 Natural Questions 和 TriviaQA 等基準上達到最先進的結果。(Lewis et al.)
同樣地,Izacard 和 Grave (2021) 證明了 RAG 在生成連貫且事實一致的長篇文本方面優於傳統語言模型。
檢索增強生成代表了一種變革性的語言生成方法,利用信息檢索的力量來增強生成模型的準確性、相關性和適應性。
通過將外部知識與現有語言能力無縫整合,RAG 為自然語言處理開啟了新的可能性,並為更智能和可靠的語言生成系統鋪平了道路。
3.2 檢索器-生成器整合策略
檢索增強生成 (RAG) 系統依賴於兩個關鍵組件:檢索器和生成模型。檢索器負責高效搜索並從大型知識庫中檢索相關信息。
「這涉及兩個主要階段,索引和搜索。索引通過反向索引進行稀疏檢索或密集向量編碼進行密集檢索來組織文檔以促進高效檢索。」(Redis)
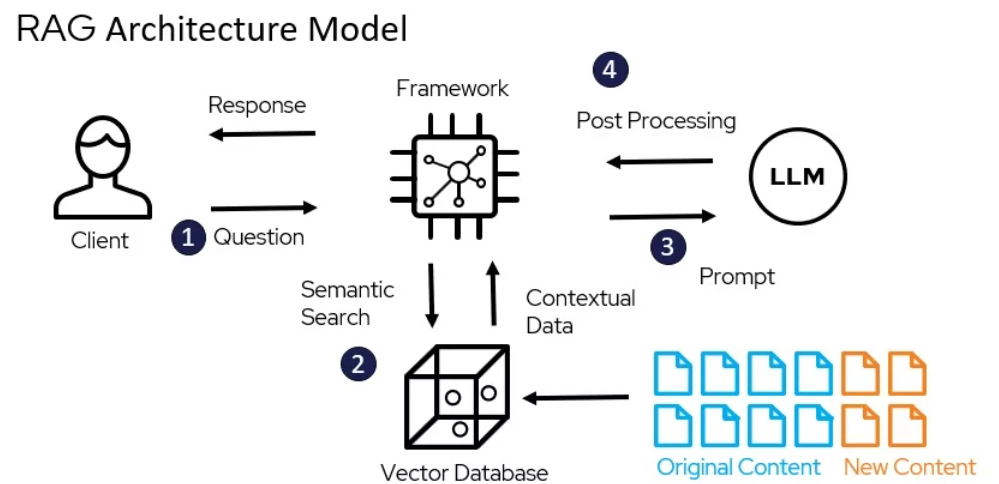
RAG的架構模型的miro.medium.com
像是TF-IDF和BM25的稀疏检索技術,將文件表示為高維度的稀疏向量,其中每個維度對應於詞彙表中的唯一詞彙。文件與查詢的相关性是由於詞彙的重叠決定,並且由它們的重要性加权。
例如,使用流行的Elasticsearch庫,基於TF-IDF的检索器可以如下實現:
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.index(index="documents", doc_type="_doc", body={"text": "This is a sample document."})
query = "sample"
results = es.search(index="documents", body={"query": {"match": {"text": query}}})
密集检索技術,如密集段落检索(DPR)和BERT基模型,將文件和查詢表示為連續嵌入空間中的密集向量。相關性是由於查詢和文件向量之間的余弦相似性決定。
DPR可以使用Hugging Face Transformers庫来实现:
from transformers import DPRContextEncoder, DPRQuestionEncoder
context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_embeddings = context_encoder(documents)
query_embedding = question_encoder(query)
scores = torch.matmul(query_embedding, context_embeddings.transpose(0, 1))
生成模型如GPT和T5,在RAG中用於根據检索到的信息生成的连贯和上下文相關的反應。对这些模型在特定領域的數據上微調,並應用提示工程技術,可以顯著提高它們在RAG系統中的性能。 (DEV Community)
整合策略確定是如何將检索到的內容纳入生成模型中。
“生成部件利用检索到的內容來制订连贯且与应用场景相關的回應,並在水龙头和推理階段中進行提示和推理。” (Redis)
兩種常見方法是串联和交叉關注。
串联涉及將检索到的段落附加到輸入查詢中,讓生成模型在解码過程中關注相關信息。
雖然實現簡單,但這種方法可能會苦於長序列和不相關信息。 (DEV 社區) 交叉關注机制,如 RAG-Token 和 RAG-Sequence,讓生成模型能夠在每個解码步驟中選擇性地關注检索到的段落。
這使得集成過程更有細粒度控制,但也帶來了 computational complexity 的增加。
例如,RAG-Token 可以使用 Hugging Face Transformers 庫来实现:
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids)
generated_output = model.generate(input_ids, retrieved_docs=retrieved_docs)
生成器、生成模型和集成策略的选择取決於 RAG 系統的具體要求,如知識庫的大小和性質、希望並在效率和效果之間的平衡,以及目標應用領域。
第四章:應用和案例
這章節探討了取回增強生成(RAG)在革命性低資源語言及多語言應用中的轉變潛力。我們深入分析如將來源文件翻譯成資源豐富的語言、利用多語言嵌入以及運用聯邦學習等策略,以克服數據限制及語言差異。
此外,我們討論了在多語言RAG系統中緩解幻覺的關鍵挑戰,以確保準確可靠的内容生成。通過探索這些創新方法,本節為利用RAG的力量實現語言處理的包容性和多樣性提供了全面指南。
4.1 RAG應用:從問答到創意寫作
取回增強生成(RAG)在多個領域中找到了許多實際應用,展現了其潛力能夠革命化我們與生成資訊的互動方式。透過利用取回與生成的力量,RAG系統在準確性、相關性及用戶參與度方面顯示了顯著改善。
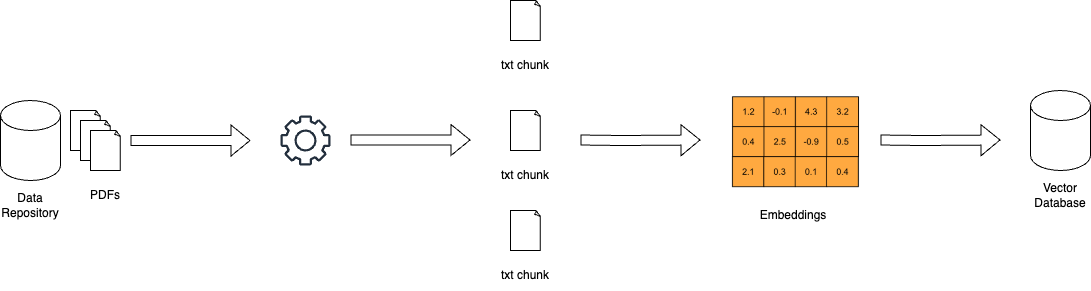
RAG的工作原理 – miro.medium.com
問答系統
RAG在問答領域證明了自己是一個游戲規則改變者。通過從外部知識源中检索相關信息並將其整合到生成過程中,RAG系統能夠為用戶查詢提供更準確和情境相關的回應。(LangChain和Django Stars)
例如,Izacard和Grave(2021)提出了一個基於RAG的模型,稱為Fusion-in-Decoder(FiD),該模型在包括Natural Questions和TriviaQA在內的幾個問答基準測試中達到了 state-of-the-art的表現。Izacard和Grave
FiD利用密集检索器抓取相關段落,並使用生成模型將检索到的信息整合成一致的回答,其表現遠超純粹的生成模型。Izacard和Grave
對話系統
RAG也在創造更具互動性和資訊性對話代理方面找到了應用。通過透過检索融入外部知識,基於RAG的對話系統可以生成不僅符合語境適宜,而且具有事實依據的回應。(LlamaIndex和MyScale)
Shuster等(2021)介紹了一個基於RAG的對話系統,名為BlenderBot 2.0,這個系統與其前身相比,展現了改善的對話能力。(Shuster等)
BlenderBot 2.0從包括維基百科、新聞文章和社交媒體在內的多種知識來源中检索相關信息,使它能在廣泛的主題上進行更具資訊性和連貫性的對話。(Shuster等)
摘要
RAG已經證明在結合多個來源相關信息的情況下,能夠提高生成摘要的質量。(Hyperight)Pasunuru等(2021)提出了一個基於RAG的摘要模型,名為PEGASUS-X,該模型检索並整合外部文件中的相關段落,以生成更具資訊性和連貫性的摘要。
PEGASUS-X 在多個摘要基準上表現優於純生成模型,展示了檢索在提高生成摘要的事實準確性和相關性方面的有效性。
創意寫作
RAG 的潛力不僅限於事實領域,還延伸到創意寫作的領域。通過從多樣化的文學作品語料庫中檢索相關段落,RAG 系統可以生成新穎且引人入勝的故事或文章。
Rashkin 等人(2020)引入了一種基於 RAG 的創意寫作模型,稱為 CTRL-RAG,該模型從大規模小說數據集中檢索相關段落並將其整合到生成過程中。CTRL-RAG 展示了生成連貫且風格一致的故事的能力,顯示出 RAG 在創意應用中的潛力。
案例研究
幾篇研究論文和項目已證明 RAG 在各個領域的有效性。
例如,Lewis 等人(2020)引入了 RAG 框架並將其應用於開放域問答,在自然問題基準上達到了最先進的性能。(Lewis et al.)他們強調了高效檢索的挑戰以及在檢索段落上微調生成模型的重要性。
在另一項案例研究中,Petroni等人(2021年)將RAG應用於事實核查任務,展示了其找回相關證據和產生準確裁決的能力。他們展示了RAG在對抗誤信息和提高信息系統可靠性的潛力。
RAG對用戶體驗和業務指標的影響是顯著的。通過提供更準確和有價值的回應,基於RAG的系統改善了用戶滿意度和參與度。 (LlamaIndex 和 MyScale)
在對話代理的案例中,RAG使互動更加自然和连貫,從而提高了用戶留存和忠誠度。 (LlamaIndex 和 MyScale) 在創意寫作領域,RAG有潛力簡化內容創建過程並生成新穎想法,為企業節省時間和資源。
正如你所見,RAG的實際應用範圍涵蓋了廣泛的領域,從問題回答和對話系統到概要和創意寫作。通過 leveraging 取回和生成的重要性,RAG已經在準確性、相關性和用戶參與度方面展示了顯著的進步。
隨著這個領域的不斷演進,我們可以期待看到更多RAG的創新應用,轉變我們在不同情境中與資訊互動和生成資訊的方式。
4.2 為低資源語言及多語言環境的RAG
在低資源語言及多語言環境中運用Retrieval-Augmented Generation (RAG)的力量,不僅是一個機會——這是一個必要。全球有超過7,000種語言被使用,其中許多語言在數位資源上嚴重缺乏,挑戰顯而易見:我們如何確保這些語言在數位時代不被遺忘?
翻譯作為一座橋樑
一個有效的策略是在索引之前將源文件翻譯成資源更豐富的語言。這種方法利用了如英語等語言中廣泛的語料庫,大大提高了检索的準確性和相關性。
通過將文件翻譯成英語,您可以利用為高資源語言已開發的豐富資源和先進的检索技術,從而提高低資源情境中RAG系統的性能。
多語言嵌入
最近在多語言詞嵌入方面的進展提供了另一個充滿希望的解決方案。通過為多種語言創建共享的嵌入空間,即使對於資源非常有限的語言,也可以改善跨語言的性能。
研究顯示,結合具有高質量嵌入的中間語言可以彌補遠距離語言對之間的差距,提高多語言嵌入的整體質量。
此方法不僅提高了檢索準確性,還確保生成的內容在語境上相關且語言上連貫。
聯邦學習
聯邦學習提出了一種克服數據共享限制和語言差異的新方法。通過在分散的數據源上微調模型,可以在提升模型多語言性能的同時保護用戶隱私。
此方法已證明比傳統方法提高了6.9%的準確性,並將訓練參數減少了99%,使其成為多語言RAG系統的高效且有效的解決方案。
減少幻覺
在多語言環境中部署RAG系統的一個關鍵挑戰是減少幻覺,即模型生成事實上不正確或不相關信息的情況。
先進的RAG技術,如模塊化RAG,引入了新的模塊和微調策略來解決這一問題。通過不斷更新知識庫和採用嚴格的評估指標,可以顯著減少幻覺的發生,確保生成的內容既準確又可靠。
實際實施
要有效實施這些策略,可以考慮以下實際步驟:
- 利用翻譯:在索引之前,將低資源語言的文件翻譯成像英語這樣的高資源語言。
- 使用多語并向嵌入: 整合質量高的嵌入中介語言以提升跨語言性能。
- 採用聯合學習: 在他去中心化的數據來源上微調模型以提升性能同時保護隱私。
- 減輕幻覺問題: 採取進階RAG技術和持續知識庫更新來確保事實正確性。
透過采纳這些策略,您可以在資源匮乏和多語言環境中顯著提升RAG系統的性能,確保在數字革命中沒有任何語言被落後。
第五章:優化技術
這一章深入探讨支撐抽取增强生成(RAG)系統效果的進階抽取技術。我們研究如何通過片段優化、元數據整合、圖Based索引、對應技術、混合搜索和重排等技术提升資訊抽取的準確性、相關性和完整性。
透過理解這些前沿方法,您將獲得RAG系統從单纯的搜索引擎演變為理解複雜查詢並提供精準、符合上下文的相關回应的智能信息服务提供商的洞見。
5.1 優化RAG系統的進階抽取技術
抽取增強生成(RAG)系統正在革新我們访问和利用信息的方式。这些系统的核心在于它们有效地检索相关信息的能力。
深入探索進階檢索技術,這些技術讓RAG系統能夠提供準確、符合語境相關性以及全面的回應。
區塊優化:通過細粒度檢索最大化相關性
在RAG系統的世界中,大型文件可能會讓人感到不知所措。區塊優化通過將廣泛的文本分解成更小、更易管理的單元稱為區塊,來解決這一挑戰。這種粒度讓檢索系統能夠定位與查詢詞語對應的特定文本部分,提高準確性和效率。
區塊優化的藝術在於確定理想的區塊大小和重疊。區塊太小可能缺乏語境,而區塊太大可能稀釋相關性。動態區塊化是一種根據內容的結構和語義調整區塊大小的技術,確保每個區塊都是一致的並具有語境意義。
元數據整合:利用資訊標籤的力量
元數據,通常被忽視的隨文件附帶的資訊,對檢索系統來說可能是一座金山。通過整合如文件類型、作者、發表日期和主題標籤等元數據,RAG系統可以進行更精準的搜索。
自我查詢檢索,這種由元數據整合啟用的技術,讓系統能夠根據初始結果生成額外的查詢。這種迭代過程改善了搜索,確保檢索到的文件不僅與查詢匹配,而且滿足用戶特定的需求和語境需求。
進階索引結構:用於複雜查詢的圖基礎網絡
傳統的索引方法,如反向索引和密集向量編碼,在處理涉及多個實體及其關係的複雜查詢時存在限制。基於圖的索引提供了一種解決方案,通過將文件及其連接組織成圖結構。
這種類似圖形的組織方式使得即使在複雜的情況下也能有效地遍歷和檢索相關文件。分層索引和近似最近鄰搜索進一步提高了基於圖的檢索系統的可擴展性和速度。
對齊技術:確保準確性與降低幻覺
RAG系統的可信度取決於其提供準確信息的能力。對齊技術,如反事實訓練,解決了這一問題。通過讓模型接觸假設性情境,反事實訓練教導它區分現實世界的事實與生成資訊,從而降低幻覺。
在多模態RAG系統中,它整合了來自各種來源如文本和圖像的信息,對比學習扮演了關鍵角色。這種技術對齊不同數據模態的語義表示,確保檢索到的資訊具有一致性和語境整合。
混合搜索:結合關鍵詞精準度與語義理解
混合搜索結合了兩種方法的優點:關鍵詞搜索的速度與精準度以及向量搜索的語義理解。最初,基於關鍵詞的搜索快速縮小潛在文件池。
隨後,基於語義相似性進行的基於向量的搜索將對結果進行細化。當確切的關鍵字匹配至關重要時,這種方法特別有效,但對查詢意圖的深入理解也是確保準確檢索所必需的。
重新排名:為最佳響應優化相關性
在檢索的最後階段,重新排名步驟介入微調結果。機器學習模型,如交叉編碼器,重新評估檢索文檔的相關性分數。通過處理查詢和文檔,這些模型獲得了對它們之間關係的更深入理解。
這種微妙的比較確保排名靠前的文檔真正符合用戶的查詢和上下文,提供更加令人滿意和資訊豐富的搜索體驗。
RAG 系統的威力在於它們無縫檢索和呈現信息的能力。通過應用這些先進的檢索技術 – 块優化、元數據集成、基於圖的索引、對齊技術、混合搜索和重新排名 – RAG 系統變得不僅僅是搜索引擎。它們演變成智能信息提供者,能夠理解複雜查詢,識別細微差異,並提供精確、相關和可信賴的響應。
第六章:挑戰與創新
本章深入探討了檢索增強生成(RAG)系統的發展和部署中的關鍵挑戰和未來方向。
我們探讨評估 RAG 系統的複雜性,包括 comprehensive metrics 和 adaptive frameworks 的需要以準確評估其性能。我們也處理道德考慮如偏見 mitigation 和信息检索與生成中的公平性。
我們也檢查硬件加速和有效部署策略的重要性,強調使用特殊硬件和優化工具如 Optimum 以提高性能和可伸縮性。
通過了解這些挑戰並探索潛在解決方案,本章為 RAG 技術的持續進步和負責任的實施提供了全面的路线圖。
6.1 挑戰與未來方向
Retrieval-Augmented Generation (RAG) 系統已在提高生成的文本的準確性、相關性和连贯性方面展示出顯著的潛力。但 RAG 系統的開發和部署也帶來了需要解決的顯著挑戰,以充分利用其潛力。
“評估 RAG 系統因此涉及考慮許多具體组件以及整體系統評估的複雜性。” (Salemi et al.)
評估 RAG 系統的挑戰
RAG 技術的主要技術挑戰之一是確保從大規模知識庫中有效检索相關信息。(Salemi 等人。 和 Yu 等人。)
隨著知識來源的大小和多样性持續增长,開發可伸缩且健壯的检索機制變得越來越重要。需要探索如分层索引、近似最近邻搜索和自适应检索策略等技術,以優化检索過程。
RAG 系統中涉及的元素 – miro.medium.com
另一個重大的挑戰是減輕模型所产生的虚构或不一致信息的問題,即避免幻覺现象。
例如,一個 RAG 系統可能會生成的歷史事件從未发生过,或者將一项科學發現誤導。雖然检索有助於使生成的文本扎根於事實知識,但確保生成输出的忠實性和一致性仍然是一個複雜的問題。
例如,一個 RAG 系統可以從像維基百科這樣的可靠來源检索有關科學發現的準確信息,但生成模型仍然可能通過混合或不存在的詳細信息來虚构。
開發有效機制以檢測和預防幻覺是研究活躍的領域。例如使用外部數據庫的事實核實和通過跨文獻參照的多源一致性檢查等技術正在被探索。這些方法旨在確保生成內容的準確性和可靠性,儘管在對齊檢索和生成過程中存在固有的挑戰。
將不同的知識來源,如結構化數據庫、非結構化文本和多模態數據整合到RAG系統中,提出了額外的挑戰。(余等。和Zilliz) 對齊不同數據模態和知識格式之間的表現和語義需要復雜的技術,如跨模態關注和知識圖嵌入。確保各種知識來源的兼容性和互操作性對於RAG系統的有效運作至關重要。Zilliz
賣米等。 以及 班afa)
開發技術以偵測和緩和偏見,例如對抗性訓練和公平意識搜尋,是重要的研究方向。班afa)
未來研究方向
為了解決評估RAG系統的挑戰,可以探索幾個潛在的解決方案和研究方向。
開發一個能夠捕捉搜尋準確性和生成質量之間相互作用的綜合評估指標是關鍵的。賣米等。
評估生成文本的相關性、连贯性及事實正確性,同時考慮检索部分的有效性,需要建立一套指標。 (Salemi等人) 這需要一種全面的方法,不僅超越傳統的BLEU和ROUGE指標,還包括人類評估和任務特定的衡量標準。
探索適應性及實時評估框架是另一個有前景的方向。
RAG系統在动态環境中運行,知識來源和用戶需求可能會随時間演變。 (Yu等人) 開發能夠 Adapt to these changes and provide real-time feedback on the system’s performance 的評估框架對於持續改進和監控至關重要。
這可能涉及如在线學習、積極學習和強化學習等技术,以根據用戶反饋和系統行為更新評估指標和模型。 (Yu等人)
研究人員、產業實務者與領域專家之間的共同努力,是推動RAG評估領域進步的必要條件。建立標準化的基準、數據集與評估協定,可以促進不同領域与应用中RAG系統之間的比較與重現性。(Salemi等。與Banafa)
與利害關係者,包括終端用戶與政策制定者的互動至關重要,這有助於確保RAG系統的開發與部署與社會價值與道德原則保持一致。(Banafa)
雖然RAG系統已經展現出巨大的潛力,但解決其評估中遇到的挑戰對於其廣泛採用與信任至關重要。通過開發全面的評估指標,探索適應性與實時評估框架,並促進合作努力,我們可以為更可靠、無偏見且有效的RAG系統鋪平道路。
隨著該領域的不斷發展,重點關注不僅推進RAG的技術能力,也確保其在實際應用中的負責任與道德部署的研究努力尤為重要。
6.2 硬體加速與RAG系統的有效部署
硬件加速的充分利用對於Retrieval-Augmented Generation (RAG)系統的高效部署至關重要。通過將計算能力強大的任務卸載到專業硬件,您可以顯著提高RAG模型的性能和可伸縮性。
利用專業硬件
Optimum的硬件專用優化工具帶來顯著的好處。例如,將RAG系統部署在Habana Gaudi处理器上可以導致推理延遲顯著減少,而Intel Neural Compressor優化可以進一步改善延遲指標。经过Optimum Neuron优化的AWS Inferentia硬件,可以增强吞吐量能力,使您的RAG系统更加响应性和高效。
優化資源運用
有效的資源運用非常關鍵。Optimum ONNX Runtime優化可以導致更有效的記憶體使用,而BetterTransformer API可以改善CPU和GPU運用。這些優化確保您的RAG系統在高峰效率運行,減少運營成本並提高性能。
可擴展性和靈活性
Optimum支持在不同硬件加速器之间的无缝过渡,实现动态可扩展性。这种多硬件支持允许您无需重大重新配置即可适应变化的计算需求。此外,Optimum中的模型量化与剪枝功能可以促进更高效的模型大小,使部署更加容易且成本效益更高。
案例研究和实际应用
在醫療資訊检索中應用Optimum。通過利用硬件特定的優化,RAG系統可以有效地處理大量數據集,提供準確及時的資訊检索。這不僅提高了醫療服務的質量,也提升了整體用戶體驗。
實施步驟
- 選擇適當的硬件:根據您的特定性能需求,選擇如Habana Gaudi或AWS Inferentia這樣的硬件加速器。
- 利用優化工具:實施Optimum的優化工具以提升延遲、吞吐量和資源利用效率。
- 確保可擴展性:利用多硬件支持動態地擴展您的RAG系統。
- 優化模型大小:使用模型量化與剪枝來減少計算開銷,並方便部署。
通過整合這些策略,您可以顯著提升RAG系統的性能、可擴展性和效率,確保它們能夠有效處理複雜的現實世界應用。
結論:RAG的轉變潛力
检索增強生成(RAG)在自然語言處理中代表了一種轉變性的範式,它將資訊检索的力量與大型語言模型的生成能力无缝整合起來。
通過利用外部知識來源,RAG 系統在生成文本的準確性、相關性和連貫性方面展示了顯著的改進,應用範圍涵蓋從問答系統和對話系統到摘要和創意寫作。
語言模型的演變,從早期的基於規則系統到 BERT 和 GPT-3 等最先進的神經架構,為 RAG 的出現鋪平了道路。傳統語言模型中純參數記憶的局限性,如知識截止日期和事實不一致性,通過檢索機制引入非參數記憶得到了有效解決。
RAG 系統的核心組件,即檢索器和生成模型,協同工作以生成上下文相關且事實可靠的輸出。
檢索器通過稀疏和密集檢索等技術,高效搜索龐大的知識庫以識別最相關的信息。生成模型利用 GPT 和 T5 等架構,將檢索到的內容綜合成連貫且流暢的文本。
整合策略,如串聯和交叉注意,決定了檢索信息如何被納入生成過程。
RAG 的實際應用遍及各種領域,展示了其革命性變革各行各業的潛力。
在問題回答方面,RAG signaling 已經顯著提高了回答的準確性和相關性,使得信息捞取更加信息性和可靠。對話系統從 RAG 受益,從而使對話更加引人入勝和连贯。通過整合來自多個來源的相關信息,摘要任務的質量和连贯性得到了提高。甚至創造性寫作也已被探索,RAG 系統生成了新穎且風格一致的故事。
但 RAG 系統的發展和評估也帶來了顯著的挑戰。有效地從大規模知識庫中捞取、缓解虚构現象以及整合多样的數據模態是亟待解決的技術难题。確保无偏見和公正的信息捞取和生成對於负责任的部署 RAG 系統至关重要。
為了充分利用 RAG 的潛力,未來研究方向必須著重於開發全面的評估指標,這些指標能夠捕捉捞取準確性和生成質量之間的互動。
能夠應對 RAG 系統动态特性的適應性和實時評估框架對於不斷改進和監控至關重要。研究人員、行業實踐者及領域專家之間的共同努力有必要建立標準化的基准、數據集和評估 protocols。
随着RAG領域的不斷演進,它對於改變我們與資訊互動及生成資訊的方式帶來了巨大的潛力。通過利用檢索與生成的力量,RAG系統有潛力革命化各個領域,從資訊檢索和對話代理到內容創建和知識發現。
檢索增強生成代表著在朝向更智能、準確和符合語境相關性的語言生成旅程中的重要里程碑。
通過橋接參數和非參數記憶之間的差距,RAG系統為自然語言處理及其應用開辟了新的可能性。
隨著研究的進展和挑戰的解決,我們可以預期RAG在塑造人機互動和知識生成的未來方面將發揮越來越重要的作用。
關於作者
這裡是Vahe Aslanyan,位於計算機科學、數據科學和人工智能的交叉點。訪問vaheaslanyan.com以查看一個展現精準與進步的作品集。我的經驗橋接了全棧開發和AI產品優化之間的差距,這是通過以新方式解決問題來驅動的。
擁有成功推出領先的數據科學訓練營以及與業界頂尖專家的合作經驗,我的重心始終在於提升科技教育至全球標準。
您如何深入探究?
在學習本指南之後,如果您渴望進行更深入的探索,且偏好結構化的學習方式,請考慮加入我們的LunarTech,我們提供數據科學、機器學習和人工智能的個體課程和訓練營。
我們提供一個全面的課程計劃,讓您深入理解理論,實際操作實踐,廣泛的實習材料,並提供量身打造的面試準備,以幫助您在適合自己的階段取得成功。
您可以查看我們的终极數據科學夏令營並加入免費試用,以親身體驗內容。這已經獲得了2023年最佳數據科學夏令營的認可,並已在Forbes、Yahoo、Entrepreneur等知名出版物上刊登。這是您成為一個在創新和知識上蓬勃發展的家園的機會。 這裡是歡迎信息!
與我聯繫

LunarTech 電子報
如果您想了解更多關於數據科學、機器學習和人工智慧的職業,以及如何獲得數據科學工作,可以下載這本免費的數據科學和人工智慧職業手冊。
Source:
https://www.freecodecamp.org/news/retrieval-augmented-generation-rag-handbook/