













經典案例 1
許多軟體專業人士對於 TCP/IP 邏輯推理缺乏深入了解,這常常導致錯誤地將問題誤認為神秘問題。有些人因為 TCP/IP 網路文獻的複雜性而感到沮喪,而另一些人則被 Wireshark 中令人困惑的細節所誤導。例如,一位面臨性能問題的 DBA 可能會錯誤解讀 Wireshark 中的封包捕獲數據,錯誤地得出 TCP 重傳是原因的結論。

既然懷疑是重傳,就必須了解其本質。重傳基本上涉及超時重傳。要確認重傳是否真的是原因,就需要時間相關的信息,而這在上面的截圖中並未提供。在向 DBA 要求新的截圖後,時間戳信息被包含在內。

在分析網路封包時,時間戳信息對於準確的邏輯推理至關重要。兩個重複封包之間的微秒級時間差異表明可能是超時重傳或重複封包捕獲。在一個典型的局域網環境中,往返時間(RTT)約為 100 微秒,當 TCP 重傳至少需要一個 RTT 時,如果重傳僅發生在 RTT 的 1/100 時間內,這很可能表明是重複封包捕獲而非實際的超時重傳。
經典案例 2
另一個經典案例說明了邏輯推理在網路問題分析中的重要性。
有一天,一位業務開發人員匆匆趕來,表示一個使用 MySQL 數據庫中間件的定時腳本在清晨時段失敗且沒有任何響應。在聽到問題後,我檢查了 MySQL 數據庫中間件的錯誤日誌,但沒有找到有價值的線索。因此,我問開發人員他們是否能夠重現問題,因為一旦能夠重現,問題就變得更容易解決。
開發人員多次嘗試重現問題,但未成功。然而,他們做出了一個新的發現:他們發現在白天執行相同的 SQL 查詢時,與清晨相比,會產生不同的響應時間。他們懷疑當 SQL 響應緩慢時,MySQL 數據庫中間件會阻塞會話並且不向客戶端返回結果。
基於這一洞察,要求數據庫操作團隊修改腳本的 SQL 以模擬緩慢的 SQL 響應。結果,MySQL 數據庫中間件在不遇到清晨時段出現的卡住問題的情況下返回了結果。
有一段時間,無法確定根本原因,開發人員發現了 MySQL 數據庫中間件的功能問題。因此,開發人員和數據庫管理員操作團隊更加確信 MySQL 數據庫中間件正在延遲響應。實際上,這些問題與 MySQL 數據庫中間件的響應時間無關。
從第一天的事件來看,問題確實存在。所有相關人員都盡力查找原因,做出各種猜測,但真正的原因仍然難以捉摸。
隔天,開發人員報告指出早上再次發生腳本問題,但他們白天無法重現。由於腳本即將在線上使用,開發人員感到壓力重重,對這種情況感到抱怨。我的唯一建議是讓他們在白天使用腳本,以避免早上出現問題。所有懷疑都集中在MySQL數據庫中間件上,從其他角度分析問題變得困難。
作為負責MySQL數據庫中間件的開發人員,這種神秘問題不能被輕易忽視。忽略它們可能會影響後續使用MySQL數據庫中間件,領導層也對解決問題提出壓力。最終,決定實施一個低成本的封包捕獲分析解決方案:在早上執行腳本時,將在伺服器上執行封包捕獲,以分析當時的情況。目標是確定MySQL數據庫中間件是否未能發送回應,或者發送了客戶端腳本未收到的回應。一旦確認MySQL數據庫中間件確實發送了回應,問題就不會歸因於MySQL數據庫中間件的開發人員。
在第三天,開發人員報告稱清晨的問題未再發生,封包捕獲分析確認問題未發生。經仔細考慮後,似乎問題不太可能僅僅是 MySQL 數據庫中間件的問題:清晨頻繁發生而白天罕見的情況令人困惑。唯一的應對措施是等待問題再次發生並根據封包捕獲進行分析。
到了第四天,問題並未再次出現。
然而,到了第五天,問題終於再次出現,為解決帶來希望。
封包捕獲文件眾多。首先,請開發人員提供問題發生時的時間戳,然後搜索龐大的封包捕獲數據以確定導致問題的 SQL 查詢。最終結果如下:
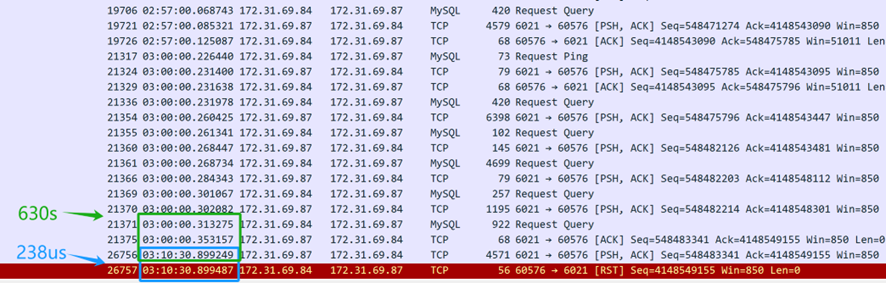
從上述的封包捕獲內容(從伺服器捕獲),看來 SQL 查詢是在凌晨 3 點發送的。MySQL 數據庫中間件花了 630 秒(03:10:30.899249-03:00:00.353157)將 SQL 回應返回給客戶端,表明 MySQL 數據庫中間件確實對 SQL 查詢作出了回應。然而,僅僅 238 微秒後(03:10:30.899487-03:10:30.899249),伺服器的 TCP 層收到了一個重置封包,速度可疑地非常快。需要注意的是,不能立即假定這個重置封包是來自客戶端。
首先,有必要确认谁发送了重置数据包 — 是客户端发送的还是沿途的中间设备发送的。由于数据包捕获仅在服务器端执行,关于客户端数据包情况的信息是不可用的。通过分析来自服务器端的数据包捕获文件并应用逻辑推理,目的是确定问题的根本原因。
如果假设客户端发送了重置,这将意味着客户端的TCP层不再识别此连接的TCP状态 — 从已建立的状态过渡到不存在的状态。这种TCP状态的变化会通知客户端应用程序存在连接问题,导致客户端脚本立即出错。然而,在现实中,客户端脚本仍在等待响应。因此,假设客户端发送了重置的假设不成立 — 客户端并未发送重置。客户端的连接仍处活动状态,但在服务器端,相应的连接已被重置终止。
那么,谁发送了重置呢?主要嫌疑人是亚马逊的云环境。根据这次数据包捕获分析,数据库管理员向亚马逊客服查询,收到以下信息:
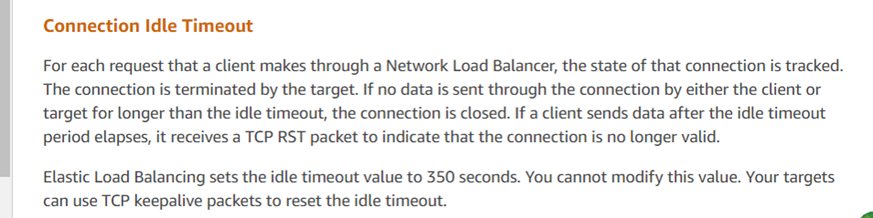
客戶服務的回應與分析結果一致,顯示亞馬遜的 ELB(彈性負載平衡器,類似於 LVS)強制終止了 TCP 會話。根據他們的反饋,如果回應超過 350 秒的閾值(在數據包捕獲中觀察到為 630 秒),亞馬遜的 ELB 設備會向回應方(在這種情況下是伺服器)發送重置。開發人員部署的客戶端腳本未收到重置,錯誤地認為伺服器連接仍然活躍。對於這類問題的官方建議包括使用 TCP keepalive 機制來減輕這些問題。
隨著官方回應的獲得,問題被視為完全解決。
這個具體案例說明了在線問題可能是非常複雜的,需要捕捉關鍵信息——在這種情況下是數據包捕獲數據——以理解情況的發生。通過邏輯推理和反證法的應用,根本原因被確定。
Source:
https://dzone.com/articles/logical-reasoning-in-network-problems