













自2000年代末期以來,大數據已經顯著演變。許多組織迅速適應這一趨勢,利用開源工具如Apache Hadoop構建了他們的大數據平台。隨後,這些公司開始面臨管理快速演變的數據處理需求的困難。他們在處理架構級變更、分區方案演變以及回溯查看數據方面面臨挑戰。
我在2010年代為一家大型科技公司和一家醫療客戶設計大規模分散式系統時,也遇到了類似的挑戰。一些行業需要這些能力來遵守銀行、金融和醫療的法規。像Netflix這樣的重數據驅動公司也面臨類似的挑戰。他們發明了一種名為“Iceberg”的表格格式,該格式位於現有數據文件之上,並通過利用其架構提供關鍵功能。這迅速成為ASF的頂級項目,因為它在數據社群中獲得了快速的關注。本文將通過示例和圖表探討Apache Iceberg的五個主要特徵。
1. 時光旅行

圖1:Apache Iceberg表格格式中的時光旅行(圖片由作者創建)
此功能允許您查詢在任意時間點存在的數據。這將為數據和商業分析師開啟新的可能性,以理解趨勢以及數據隨時間的演變。您可以輕鬆地回滾到先前的狀態,以防出現任何錯誤。此功能還通過允許您在特定時間點分析數據來促進審計檢查。
-- time travel to October 5th, 1978 at 07:00:00
SELECT * FROM prod.retail.cusotmers TIMESTAMP AS OF '1978-10-05 07:00:00';
-- time travel using a specific snapshot ID:
SELECT * FROM prod.retail.customers VERSON AS OF 949530903748831869;
2. 架構演變
Apache Iceberg 的架構演變允許您在不需要大量努力或昂貴遷移的情況下更改架構。隨著業務需求的演變,您可以:
- 在不造成任何停機或表重寫的情況下添加和刪除列。
- 更新列(擴展)。
- 更改列的順序。
- 重新命名現有列。
這些更改在元數據層面處理,而無需重寫基礎數據。
-- add a new column to the table
ALTER TABLE prod.retail.customers ADD COLUMNS (email_address STRING);
-- remove an existing column from the table
ALTER TABLE prod.retail.customers DROP COLUMN num_of_years;
-- rename an existing column
ALTER TABLE prod.retail.customers RENAME COLUMN email_address TO email;
-- iceberg allows updating column types from int to bigint, float to double
ALTER TABLE prod.retail.customers ALTER COLUMN customer_id TYPE bigint;
3. 分區演變
使用 Apache Iceberg 表格式,您可以更改表的分區策略,而無需重寫基礎表或將數據遷移到新表。這是因為查詢不會像在 Apache Hadoop 中那樣直接引用分區值。Iceberg 對每個分區版本保持元數據信息分開。這使得在查詢數據時輕鬆獲取分割。例如,根據日期範圍查詢一個表,而該表使用月份作為分區列(之前)作為一個分割,並使用天作為新的分區列(之後)作為另一個分割。這稱為分割規劃。請參見下面的示例。
-- create customers table partitioned by month of the create_date initially
CREATE TABLE local.retail.customer (
id BIGINT,
name STRING,
street STRING,
city STRING,
state STRING,
create_date DATE
USING iceberg
PARTITIONED BY (month(create_date));
-- insert some data into the table
INSERT INTO local.retail.customer VALUES
(1, 'Alice', '123 Maple St', 'Springfield', 'IL', DATE('2024-01-10')),
(2, 'Bob', '456 Oak St', 'Salem', 'OR', DATE('2024-02-15')),
(3, 'Charlie', '789 Pine St', 'Austin', 'TX', DATE('2024-02-20'));
-- change the partition scheme from month to date
ALTER TABLE local.retail.customer
REPLACE PARTITION FIELD month(create_date) WITH days(create_date);
-- insert couple more records
INSERT INTO local.retail.customer VALUES
(4, 'David', '987 Elm St', 'Portland', 'ME', DATE('2024-03-01')),
(5, 'Eve', '654 Birch St', 'Miami', 'FL', DATE('2024-03-02'));
-- select all columns from the table
SELECT * FROM local.retail.customer
WHERE create_date BETWEEN DATE('2024-01-01') AND DATE('2024-03-31');
-- output
1 Alice 123 Maple St Springfield IL 2024-01-10
5 Eve 654 Birch St Miami FL 2024-03-02
4 David 987 Elm St Portland ME 2024-03-01
2 Bob 456 Oak St Salem OR 2024-02-15
3 Charlie 789 Pine St Austin TX 2024-02-20
-- View parition details
SELECT partition, file_path, record_count
FROM local.retail.customer.files;
-- output
{"create_date_month":null,"create_date_day":2024-03-02} /Users/rellaturi/warehouse/retail/customer/data/create_date_day=2024-03-02/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00002.parquet 1
{"create_date_month":null,"create_date_day":2024-03-01} /Users/rvellaturi/warehouse/retail/customer/data/create_date_day=2024-03-01/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00001.parquet 1
{"create_date_month":648,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-01/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00001.parquet 1
{"create_date_month":649,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-02/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00002.parquet 2
4. ACID 交易
Iceberg 在 原子性、一致性、孤立性和持久性 (ACID) 方面提供了強大的交易支持。它允許多個並發寫入操作,這將在數據密集型工作中實現高吞吐量,而不會妥協數據的一致性。
-- Start a transaction
START TRANSACTION;
-- Insert new records
INSERT INTO customers VALUES (1, 'John'), (2, 'Mike');
-- Update existing records
UPDATE customers SET column1 = 'Josh' WHERE id = 1;
-- Delete records
DELETE FROM customers WHERE id = 2;
-- Commit the transaction
COMMIT;
Iceberg 中的所有操作都是事務性的,這意味著儘管發生故障或數據被並發修改,數據仍然保持一致。
-- Atomic update across multiple tables
START TRANSACTION;
UPDATE orders SET status = 'processed' WHERE order_id = 100;
INSERT INTO orders_processed SELECT * FROM orders WHERE order_id = 100;
COMMIT;
它還支持不同的隔離級別,使您可以根據需求平衡性能和一致性。
-- Set isolation level (syntax may vary depending on the query engine)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Perform operations
SELECT * FROM customers WHERE id = 1;
UPDATE customers SET rec_status= 'updated' WHERE id = 1;
COMMIT;
以下是 Iceberg 如何處理行級更新和刪除的摘要。
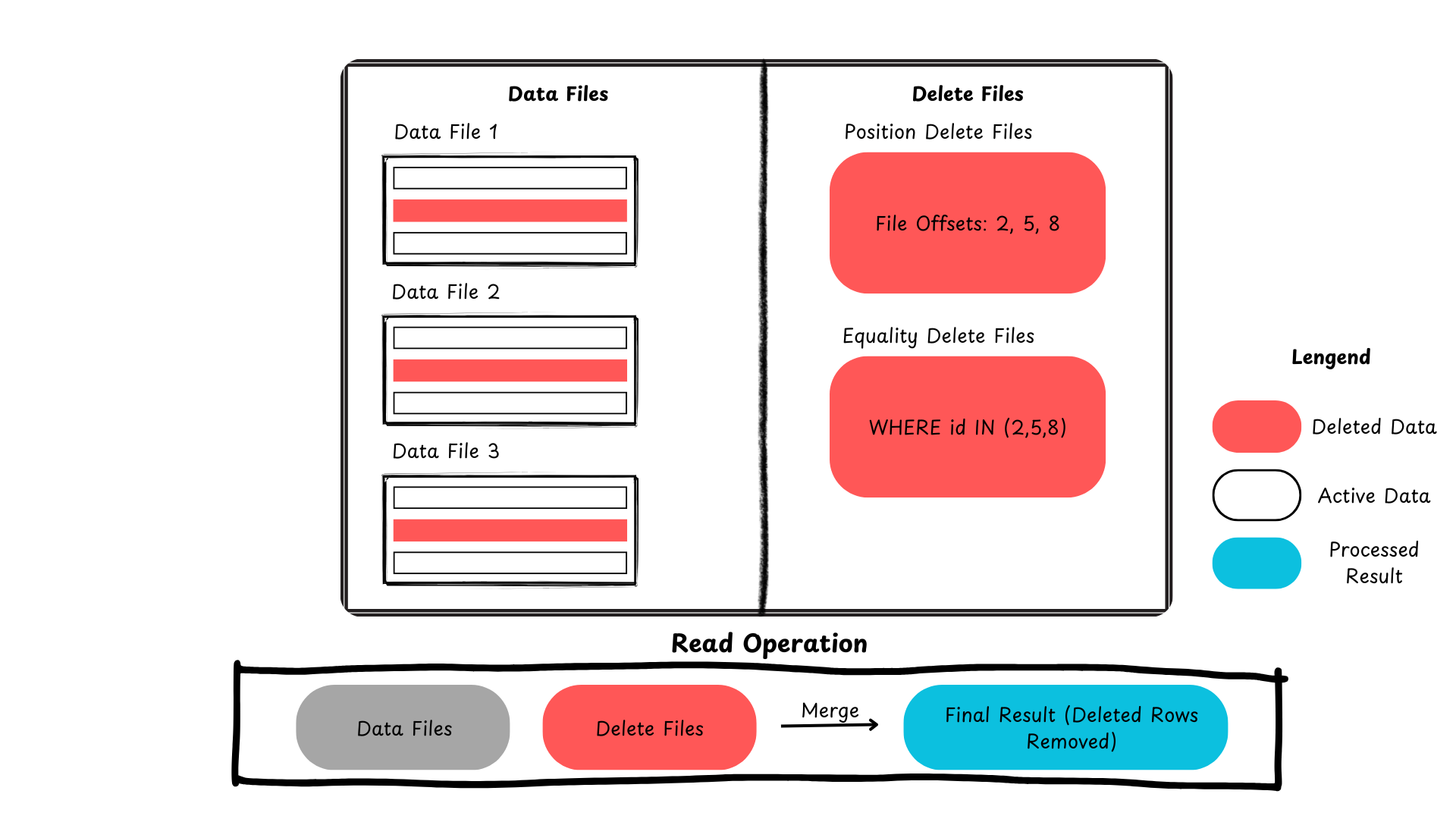
圖 2:Apache Iceberg 中刪除記錄的過程(圖片由作者創建)
5. 高級表操作
Iceberg 支持以下高級表操作:
- 創建/管理表快照:這提供了強大的版本控制能力。
- 快速查詢規劃和執行,擁有高度優化的元數據
- 內置的表維護工具,如壓縮和孤立文件清理
Iceberg 設計用於與所有主要雲存儲(如 AWS S3、GCS 和 Azure Blob Storage)一起工作。此外,Iceberg 還可輕鬆與數據處理引擎(如 Spark、Presto、Trino 和 Hive)集成。
最後的想法
這些突出的特性使公司能夠建立現代化、靈活、可擴展且高效的數據湖,這些數據湖可以進行時間旅行、輕鬆處理架構變更、支持ACID交易以及分區演變。
Source:
https://dzone.com/articles/key-features-of-apache-iceberg-for-data-lakes