













什麼是Elasticsearch?
Elasticsearch是一個高度可擴展的分散式搜尋和分析引擎,基於Apache Lucene搜尋庫構建。它被設計用來處理大量結構化、半結構化和非結構化數據,非常適合各種應用場景,包括搜尋引擎、日誌分析、電子商務和安全分析。
Elasticsearch採用分散式架構,允許在集群中的多個節點上存儲和處理大量數據。數據被索引並存儲在分片中,這些分片分布在各個節點上,以提高可擴展性和容錯能力。Elasticsearch還支持即時搜尋和分析,使用戶能夠幾乎即時地查詢和分析數據。
Elasticsearch的一個關鍵特性是其強大的搜尋功能。它支持廣泛的搜尋查詢,包括全文搜尋、地理空間搜尋等。它還提供對高級分析功能的支持,如聚合、指標和數據可視化。
Elasticsearch通常與Elastic Stack中的其他工具一起使用,包括用於數據收集和處理的Logstash,以及用於數據可視化和分析的Kibana。這些工具共同提供了一個全面的搜尋和分析解決方案,可用於廣泛的應用和使用案例。
什麼是Apache Lucene?
Apache Lucene 是一個開源的搜尋庫,提供強大的文字搜尋與索引功能。它廣泛被開發者和組織用於建立各種搜尋應用,從搜尋引擎到電子商務平台皆有其身影。
Lucene 透過索引文件的文字內容並將索引儲存於結構化格式中,以便高效搜尋。索引由一系列倒排列表組成,提供詞彙與包含該詞彙文件之間的對應關係。當提交搜尋查詢時,Lucene 利用索引迅速檢索出符合查詢的文件。
除了核心的搜尋與索引功能外,Lucene 還提供多項進階特性,如模糊搜尋與空間搜尋支援。它亦提供工具以高亮顯示搜尋結果並根據相關性對結果進行排序。
Lucene 被眾多組織與專案採用,包括 Elasticsearch。其豐富的功能集、靈活性及擴展性使其成為建立各類搜尋應用的熱門選擇。
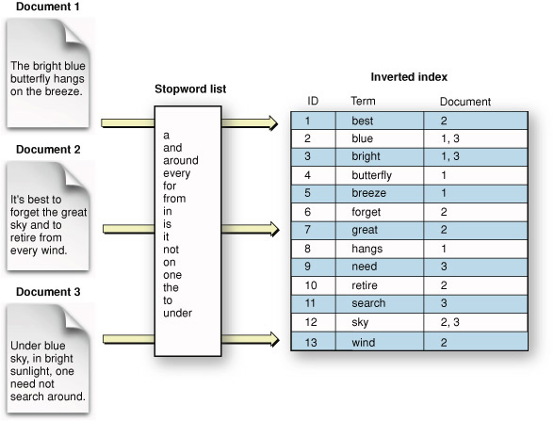
何謂倒排索引?
Lucene 的倒排索引是一種數據結構,用於從文件集合中高效搜尋與檢索文字數據。倒排索引是 Lucene 的核心特性,用於儲存構成索引的詞彙及其相關文件。
反向索引相較於其他搜尋策略,提供了多項優勢。首先,它允許基於搜尋詞快速且有效地檢索文件。其次,它能處理大量文字數據,非常適合用於擁有大量文件集合的使用案例。最後,它支援廣泛的高級搜尋功能,如模糊匹配和詞幹提取,這些功能能提升搜尋結果的準確性和相關性。
為何選擇Elasticsearch?
選擇Elasticsearch作為構建搜尋和分析應用程序的原因有幾個:
易於擴展(分散式): Elasticsearch天生設計為可水平擴展。每當需要增加容量時,只需添加更多節點,讓集群自行重新組織以利用額外的硬件。
一個伺服器可以存放一個或多個索引的一個或多個部分,每當新的節點被引入集群時,它們就像是加入了一個聚會。每個這樣的索引,或其一部分,被稱為分片,而Elasticsearch的分片可以非常容易地在集群中移動。
一切皆為一個JSON呼叫(RESTful API): Elasticsearch是API驅動的。幾乎任何操作都可以使用基於HTTP的簡單RESTful API,透過JSON來執行。回應總是以JSON格式返回。
Lucene 的強大潛力: Elasticsearch 內部使用 Lucene 來構建其尖端的分散式搜索和分析功能。由於 Lucene 是一項穩定、經過驗證的技術,並且不斷地加入更多功能和最佳實踐,因此 Lucene 作為驅動 Elasticsearch 的底層引擎。
優秀的查詢 DSL: REST API 提供了一個非常複雜且功能強大的查詢 DSL,使用起來非常簡單。每個查詢都是一個 JSON 對象,實際上可以包含任何類型的查詢,甚至可以組合多個查詢。使用過濾查詢,其中一些查詢表達為 Lucene 過濾器,有助於利用緩存,從而加快常見查詢或可以重用的複雜查詢部分。
多租戶: 可以在一個 Elasticsearch 安裝(節點或集群)上存儲多個索引。好處是可以使用一個簡單的查詢來查詢多個索引。
支援高級搜索功能(全文): Elasticsearch 在底層使用 Lucene 來提供任何開源產品中最強大的全文搜索功能。搜索功能支持多語言,強大的查詢語言,地理位置支持,上下文感知的「您是不是想找」建議,自動完成和搜索片段。過濾器和得分器中的腳本支持。
可配置和可擴展: 許多 Elasticsearch 配置可以在運行時更改,但有些將需要重新啟動(並且在某些情況下,需要重新索引)。大多數配置也可以使用 REST API 進行更改。
面向文檔: 在Elasticsearch中以結構化的JSON文檔形式存儲複雜的現實世界實體。所有字段默認都被索引,所有索引都可以在一次查詢中被使用,以驚人的速度返回結果。
無模式: Elasticsearch讓你輕鬆開始。發送一個JSON文檔,它會嘗試檢測數據結構,索引數據,並使其可搜索。
衝突管理: 在需要時可以使用樂觀版本控制,確保數據不會因為多個進程間的衝突變更而丟失。
活躍社區: 社區不僅創建了許多優秀的工具和插件,而且非常樂於助人並提供支持。整體氛圍極佳,這對任何開源軟件項目來說都是一個重要的指標。此外,社區成員正在撰寫一些書籍,網上也有許多博客文章分享經驗和知識。
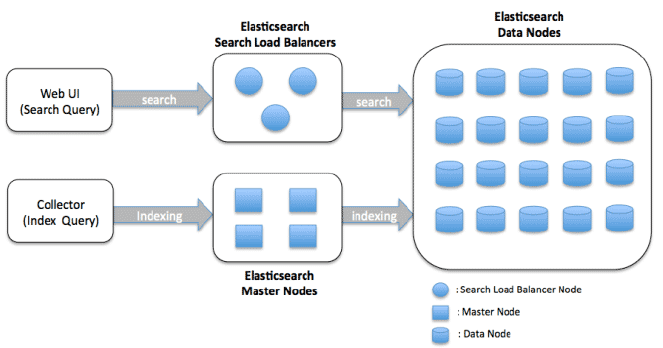
Elasticsearch架構
Elasticsearch架構的主要組件包括:
節點: 節點是存儲數據並提供搜索和索引能力的Elasticsearch實例。節點可以被配置為主節點或數據節點,或兩者兼有。主節點負責集群的全局管理,而數據節點則存儲數據並執行搜索操作。
集群: 集群是由一個或多個共同工作以存儲和處理數據的節點組成的群組。一個集群可以包含多個索引(文檔的集合)和分片(在多個節點間分發數據的一種方式)。
索引: 索引是一系列具有相似结构的文档集合。每个文档以JSON对象表示,并包含一个或多个字段。Elasticsearch默认索引所有字段,便于数据的搜索与分析。
分片: 索引可以分割成多个分片,这些分片实质上是索引的较小子集。分片允许数据并行处理和跨多个节点的分布式存储。
副本: Elasticsearch可以为每个分片创建副本,以提供容错性和高可用性。副本是原始分片的拷贝,并可以位于不同的节点上。
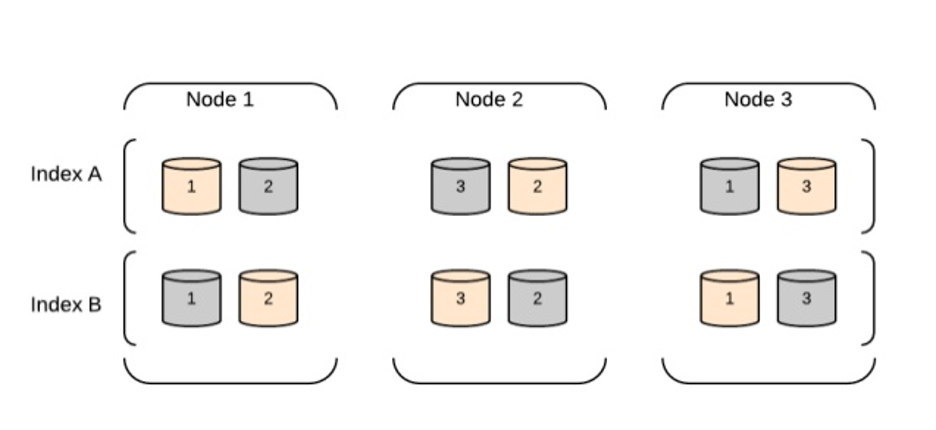
数据节点集群架构
数据节点负责存储和索引数据,以及执行搜索和聚合操作。该架构设计为可扩展和分布式的,通过向集群添加更多节点实现水平扩展。
以下是Elasticsearch数据节点集群架构的主要组件:
数据节点: 节点是存储数据并提供搜索和索引能力的Elasticsearch实例。在数据节点集群中,每个节点负责存储索引数据的一部分,并对该数据执行搜索查询。
集群状态: 集群状态是一个数据结构,包含有关集群的信息,包括节点列表、索引、分片及其位置。主节点负责维护集群状态,并将其分发给集群中的所有其他节点。
發現與傳輸:Elasticsearch 叢集中的節點透過兩種協定相互通信:發現協定和傳輸協定。發現協定負責識別加入叢集的新節點或已離開叢集的節點。傳輸協定則負責在節點之間傳送和接收數據。
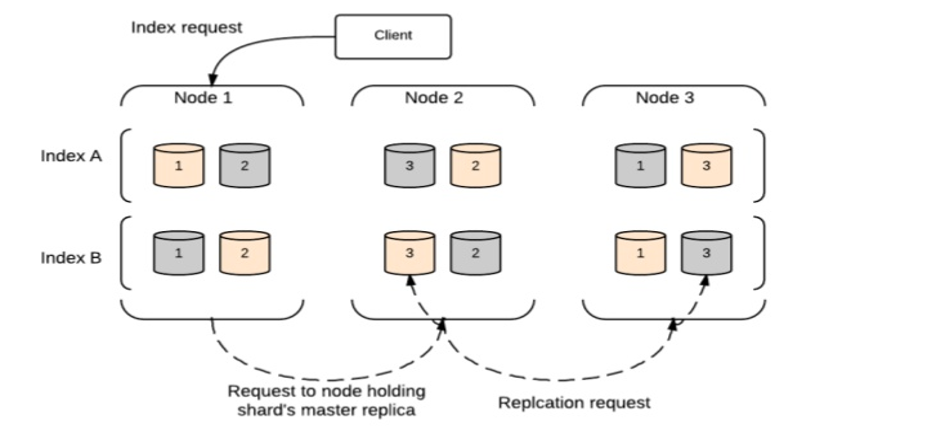
索引請求
Elasticsearch 中索引請求的執行流程如下圖所示。
哪些機構在使用 Elasticsearch?
使用 Elasticsearch 的部分公司和組織包括:
Netflix:Netflix 利用 Elasticsearch 強化其搜尋和推薦引擎,讓用戶能迅速找到觀看內容。
GitHub:GitHub 使用 Elasticsearch 在其代碼庫、問題和拉取請求中提供快速且高效的搜尋功能。
Uber:Uber 利用 Elasticsearch 驅動其即時分析平台,使其能夠即時追蹤和分析叫車服務的數據。
Wikipedia:Wikipedia 使用 Elasticsearch 來強化其搜尋引擎,為用戶提供快速且精確的搜尋結果。
Source:
https://dzone.com/articles/introduction-to-elasticsearch-1