













作者選擇了自由及開放原始碼基金作為寫作以捐贈計劃的一部分收到捐贈。
介紹
Flask是一個輕量級的Python Web框架,提供了有用的工具和功能,用於在Python語言中創建Web應用程序。SQLAlchemy是一個SQL工具包,為關聯式數據庫提供了高效和高性能的數據庫訪問。它提供了與多個數據庫引擎(如SQLite、MySQL和PostgreSQL)交互的方法。它使您能夠訪問數據庫的SQL功能。而且它還提供了一個對象關係映射器(ORM),允許您使用簡單的Python對象和方法進行查詢和處理數據。Flask-SQLAlchemy是一個Flask擴展,使使用SQLAlchemy與Flask更加容易,通過SQLAlchemy在Flask應用程序中提供工具和方法來與您的數據庫交互。
在這個教程中,您將使用 Flask 和 Flask-SQLAlchemy 創建一個具有員工表的數據庫的員工管理系統。每個員工將擁有一個唯一的ID、名字、姓氏、唯一的電子郵件、整數值代表他們的年齡、加入公司的日期和一個布林值來確定員工目前是否在職或者離職。
您將使用 Flask shell 來查詢表格,並基於列值(例如,電子郵件)獲取表格記錄。您將檢索符合某些條件的員工記錄,例如僅獲取在職員工或獲取離職員工的列表。您將按照列值對結果進行排序,並計算和限制查詢結果。最後,您將使用分頁在 Web 應用程序中每頁顯示特定數量的員工。
先決條件
-
一個本地的 Python 3 編程環境。根據您的發行版,在 如何安裝和設置本地 Python 3 編程環境 系列教程中進行操作。在本教程中,我們將將我們的項目目錄稱為
flask_app。 -
對基本的Flask概念有一定的了解,比如路由、視圖函數和模板。如果您對Flask不熟悉,請查看如何使用Flask和Python創建您的第一個Web應用程序和如何在Flask應用程序中使用模板。
-
對基本的HTML概念有一定的了解。您可以查看我們的如何使用HTML構建網站教程系列以獲得背景知識。
-
對基本的 Flask-SQLAlchemy 概念有一定的了解,比如設置數據庫、創建數據庫模型以及將數據插入到數據庫中。查看 如何在 Flask 應用程序中使用 Flask-SQLAlchemy 與數據庫交互 以獲取背景知識。
第 1 步 — 設置數據庫和模型
在此步驟中,您將安裝必要的套件,並設置您的 Flask 應用程序、Flask-SQLAlchemy 數據庫以及表示您將存儲員工數據的 employee 表的員工模型。您將在 employee 表中插入一些員工,並添加一個路由和一個頁面,在該應用程序的索引頁上顯示所有員工。
首先,啟用虛擬環境後,安裝 Flask 和 Flask-SQLAlchemy:
安裝完成後,您將收到以下行的輸出:
Output
Successfully installed Flask-2.1.2 Flask-SQLAlchemy-2.5.1 Jinja2-3.1.2 MarkupSafe-2.1.1 SQLAlchemy-1.4.37 Werkzeug-2.1.2 click-8.1.3 greenlet-1.1.2 itsdangerous-2.1.2
有了安裝所需的套件,打開您的flask_app目錄中的一個名為app.py的新文件。 這個文件將包含用於設置數據庫和您的Flask路由的代碼:
將以下代碼添加到app.py中。 這段代碼將設置一個SQLite數據庫和一個代表您將用於存儲員工數據的employee表的員工數據庫模型:
保存並關閉文件。
在這裡,您導入了os模塊,它為您提供了對雜項操作系統接口的訪問。 您將使用它來構造database.db數據庫文件的文件路徑。
從flask套件中,您導入了應用程序所需的幫助程序:使用Flask類來創建Flask應用程序實例,render_template()來渲染模板,request對象來處理請求,url_for()來構造URL,以及用於重定向用戶的redirect()函數。 有關路由和模板的更多信息,請參見如何在Flask應用程序中使用模板。
然後,您從Flask-SQLAlchemy擴展中導入了SQLAlchemy類,這使您可以訪問所有來自SQLAlchemy的功能和類,以及與SQLAlchemy集成的Flask的幫助程序和功能。 您將使用它來創建一個連接到您的Flask應用程序的數據庫對象。
為了為您的資料庫檔案建構一個路徑,您將目錄定義為當前目錄。您使用os.path.abspath() 函數來獲取當前檔案目錄的絕對路徑。特殊的__file__ 變數保存了當前app.py 檔案的路徑名。您將基礎目錄的絕對路徑存儲在名為basedir 的變數中。
然後,您創建一個名為app 的 Flask 應用實例,用於配置兩個 Flask-SQLAlchemy配置鍵:
-
SQLALCHEMY_DATABASE_URI: 資料庫 URI 用於指定您要建立連接的資料庫。在這種情況下,URI 遵循格式sqlite:///路徑/到/資料庫.db。您使用os.path.join()函數智能地將您構建並存儲在basedir變數中的基礎目錄與database.db檔案名稱結合起來。這將連接到您的flask_app目錄中的database.db資料庫檔案。一旦您初始化資料庫,檔案將被建立。 -
SQLALCHEMY_TRACK_MODIFICATIONS:用於啟用或禁用對象修改跟踪的配置。您將其設置為False以禁用跟踪,這將使用較少的內存。有關更多信息,請參見 Flask-SQLAlchemy 文檔中的 配置頁面。
配置完 SQLAlchemy 並設置數據庫 URI 和禁用跟踪後,您使用 SQLAlchemy 類創建數據庫對象,將應用程序實例傳遞給它,以將您的 Flask 應用程序與 SQLAlchemy 連接。您將數據庫對象存儲在名為 db 的變量中,您將使用它來與數據庫交互。
在设置应用程序实例和数据库对象之后,您继承自db.Model类以创建名为Employee的数据库模型。该模型表示employee表,具有以下列:
id:员工ID,整数主键。firstname:员工的名字,字符串,最大长度为100个字符。nullable=False表示该列不应为空。lastname:员工的姓氏,字符串,最大长度为100个字符。nullable=False表示该列不应为空。email:员工的电子邮件,字符串,最大长度为100个字符。unique=True表示每个电子邮件应该是唯一的。nullable=False表示其值不应为空。age:员工的年龄,整数值。hire_date:员工入职日期。您设置db.Date作为列类型以声明它为保存日期的列。active:一个列,用于保存布尔值,指示员工当前是否在职或离职。
特殊的__repr__函数允许您为每个对象提供一个字符串表示,以便在调试时识别它。在这种情况下,您使用员工的名字来表示每个员工对象。
現在您已經設置了數據庫連接和員工模型,您將編寫一個Python程序來創建您的數據庫和employee表,並將表填充到一些員工數據中。
在您的flask_app目錄中打開一個名為init_db.py的新文件:
將以下代碼添加到刪除現有數據庫表以從乾淨的數據庫開始,創建employee表並將九名員工插入其中:
在這裡,您從datetime模塊中導入date()類以將其用於設置員工入職日期。
您導入了數據庫對象和Employee模型。 您調用db.drop_all()函數來刪除所有現有表格,以避免在數據庫中存在已經填充的employee表,這可能會導致問題。每當您執行init_db.py程序時,都會刪除所有數據庫數據。有關創建、修改和刪除數據庫表的更多信息,請參見如何使用Flask-SQLAlchemy與Flask應用程序交互。
然後,您創建了幾個Employee模型的實例,這些實例代表了您在本教程中要查詢的員工,並使用db.session.add_all()函數將它們添加到數據庫會話中。最後,您提交交易並應用更改到數據庫使用db.session.commit()。
保存並關閉文件。
執行init_db.py程序:
要查看您添加到數據庫中的數據,確保您的虛擬環境處於激活狀態,並打開Flask shell來查詢所有員工並顯示其數據:
運行以下代碼來查詢所有員工並顯示其數據:
您使用query屬性的all()方法來獲取所有員工。您遍歷結果並顯示員工信息。對於active列,您使用條件語句來顯示員工的當前狀態,即'Active'或'Out of Office'。
您將收到以下輸出:
OutputJohn Doe
Email: [email protected]
Age: 32
Hired: 2012-03-03
Active
----
Mary Doe
Email: [email protected]
Age: 38
Hired: 2016-06-07
Active
----
Jane Tanaka
Email: [email protected]
Age: 32
Hired: 2015-09-12
Out of Office
----
Alex Brown
Email: [email protected]
Age: 29
Hired: 2019-01-03
Active
----
James White
Email: [email protected]
Age: 24
Hired: 2021-02-04
Active
----
Harold Ishida
Email: [email protected]
Age: 52
Hired: 2002-03-06
Out of Office
----
Scarlett Winter
Email: [email protected]
Age: 22
Hired: 2021-04-07
Active
----
Emily Vill
Email: [email protected]
Age: 27
Hired: 2019-06-09
Active
----
Mary Park
Email: [email protected]
Age: 30
Hired: 2021-08-11
Active
----
您可以看到我們添加到數據庫中的所有員工都被正確顯示。
退出Flask shell:
接下來,您將創建一個Flask路由來顯示員工。打開app.py進行編輯:
在文件末尾添加以下路由:
保存並關閉文件。
這將查詢所有員工,呈現一個index.html模板,並將您獲取的員工傳遞給它。
創建一個模板目錄和一個基本模板:
將以下內容添加到base.html中:
保存並關閉文件。
在這裡,您使用標題塊並添加了一些CSS樣式。您添加了一個包含兩個項目的導航欄,一個用於首頁,一個用於非活動的關於頁面。這個導航欄將在應用程序中的模板中被重複使用,這些模板繼承自該基本模板。內容塊將被替換為每個頁面的內容。有關模板的更多信息,請查看在Flask應用程序中使用模板。
接下來,在app.py中呈現一個新的index.html模板:
將以下代碼添加到文件中:
在這裡,您遍歷員工並顯示每個員工的信息。如果員工是活動的,則添加一個(活動中)標籤,否則顯示一個(不在辦公室)標籤。
保存並關閉文件。
在啟用虛擬環境的情況下,進入您的 flask_app 目錄,告訴 Flask 關於應用程序(在本例中為 app.py)使用 FLASK_APP 環境變量。然後將 FLASK_ENV 環境變量設置為 development 以在開發模式下運行應用程序並訪問調試器。有關 Flask 調試器的更多信息,請參見 如何處理 Flask 應用程序中的錯誤。使用以下命令執行此操作:
接下來,運行應用程序:
在開發服務器運行時,使用瀏覽器訪問以下 URL:
http://127.0.0.1:5000/
您將在類似以下的頁面中看到您添加到數據庫中的員工:
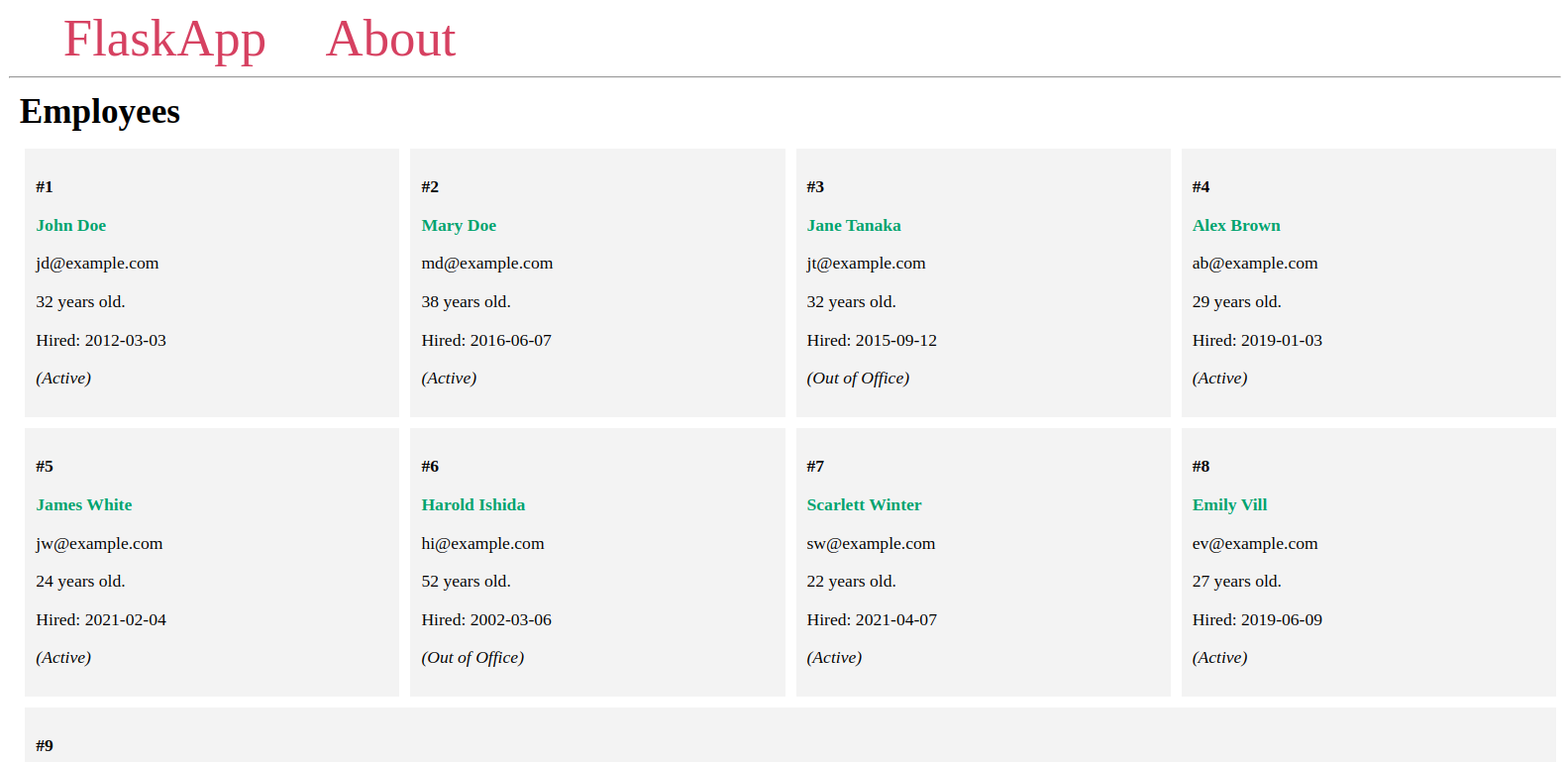
保持服務器運行狀態,打開另一個終端,並繼續進行下一步。
您已在索引頁面上顯示了數據庫中的員工。接下來,您將使用 Flask shell 使用不同的方法查詢員工。
步驟 2 — 查詢記錄
在這一步中,您將使用 Flask shell 查詢記錄,並使用多種方法和條件進行篩選和檢索結果。
在您的編程環境啟動時,設置 FLASK_APP 和 FLASK_ENV 變量,並打開 Flask shell:
導入 db 對象和 Employee 模型:
檢索所有記錄
如前一步驟所示,您可以使用 query 屬性上的 all() 方法來獲取表中的所有記錄:
輸出將是表示所有員工的對象列表:
Output
[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>, <Employee Alex Brown>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>, <Employee Emily Vill>, <Employee Mary Park>]
檢索第一條記錄
同樣,您可以使用 first() 方法來獲取第一條記錄:
輸出將是一個保存第一個員工數據的對象:
Output<Employee John Doe>
通過ID檢索記錄
在大多數數據庫表中,記錄通常使用唯一的 ID 進行標識。Flask-SQLAlchemy 允許您使用其 ID 使用 get() 方法來提取一條記錄:
Output<Employee James White> | ID: 5
<Employee Jane Tanaka> | ID: 3
通過列值檢索一條或多條記錄
要使用其中一列的值來獲取記錄,請使用filter_by()方法。例如,要使用其ID值來獲取記錄,類似於get()方法:
Output<Employee John Doe>
您使用first(),因為filter_by()可能會返回多個結果。
注意:通過ID獲取記錄,使用get()方法是一種更好的方法。
例如,您可以使用其年齡來獲取員工:
Output<Employee Harold Ishida>
在一個例子中,查詢結果包含多個匹配記錄的情況下,使用firstname列和名字Mary,這是兩位員工共享的名字:
Output[<Employee Mary Doe>, <Employee Mary Park>]
在這裡,您使用all()來獲取完整列表。您也可以使用first()來僅獲取第一個結果:
Output<Employee Mary Doe>
您已通過列值檢索記錄。接下來,您將使用邏輯條件查詢您的表。
第3步 – 使用邏輯條件篩選記錄
在複雜、功能完整的網絡應用程序中,您通常需要使用複雜的條件從數據庫查詢記錄,例如根據結合了他們的位置、可用性、角色和職責的條件來獲取員工。在這一步中,您將練習使用條件運算符。您將使用 query 屬性上的 filter() 方法,使用不同的運算符使用邏輯條件來過濾查詢結果。例如,您可以使用邏輯運算符來獲取員工當前是否不在辦公室的列表,或者是應該升職的員工,也許提供員工休假時間的日曆等等。
等於
您可以使用的最簡單的邏輯運算符是相等運算符 == ,它的行為方式類似於 filter_by()。例如,要獲取所有 firstname 列值為 Mary 的記錄,您可以使用以下方式使用 filter() 方法:
在這裡,您使用 Model . column == value 的語法作為 filter() 方法的參數。 filter_by() 方法是此語法的快捷方式。
結果與具有相同條件的 filter_by() 方法的結果相同:
Output[<Employee Mary Doe>, <Employee Mary Park>]
像 filter_by() 一樣,您也可以使用 first() 方法來獲取第一個結果:
Output<Employee Mary Doe>
不等於
filter() 方法允許您使用 != Python 運算符來獲取記錄。例如,要獲取一個列表,其中包含不在辦公室的員工,您可以使用以下方法:
Output[<Employee Jane Tanaka>, <Employee Harold Ishida>]
在這裡,您使用 Employee.active != True 條件來篩選結果。
小於
您可以使用 < 運算符來獲取指定列的值小於給定值的記錄。例如,要獲取年齡小於 32 歲的員工列表:
Output
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
使用 <= 運算符來獲取小於或等於給定值的記錄。例如,在上一個查詢中包含年齡為 32 歲的員工:
Output
John Doe
Age: 32
----
Jane Tanaka
Age: 32
----
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
大於
同樣地,> 運算符用於獲取指定列的值大於給定值的記錄。例如,要獲取年齡超過 32 歲的員工:
OutputMary Doe
Age: 38
----
Harold Ishida
Age: 52
----
而 >= 運算符用於大於或等於給定值的記錄。例如,您可以再次在上一個查詢中包含 32 歲的員工:
Output
John Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Harold Ishida
Age: 52
----
在
SQLAlchemy中,还提供了一种方法来获取列值匹配给定值列表的记录,使用列上的in_()方法,如下所示:
Output[<Employee Mary Doe>, <Employee Alex Brown>, <Employee Emily Vill>, <Employee Mary Park>]
在这里,您可以使用具有语法Model.column.in_(iterable)的条件,其中iterable是任何类型的可以迭代的对象。另一个示例,您可以使用range() Python函数来获取特定年龄范围内的员工。以下查询获取所有三十岁的员工。
OutputJohn Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Mary Park
Age: 30
----
不在
类似于in_()方法,您可以使用not_in()方法来获取列值不在给定可迭代对象中的记录:
Output
[<Employee John Doe>, <Employee Jane Tanaka>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>]
在这里,您获取除了names列表中具有的名字之外的所有员工。
并且
您可以使用db.and_()函数将多个条件组合在一起,其工作方式类似于Python的and操作符。
例如,假設您想獲取所有年齡為 32 歲且目前處於活動狀態的員工。首先,您可以使用 filter_by() 方法(您也可以使用 filter() 如果您想要的話)檢查誰是 32 歲:
Output<Employee John Doe>
Age: 32
Active: True
-----
<Employee Jane Tanaka>
Age: 32
Active: False
-----
在這裡,您可以看到 John 和 Jane 是年齡為 32 歲的員工。John 是活動中的,而 Jane 不在辦公室。
要獲取年齡為 32 歲且處於活動狀態的員工,您將使用兩個條件和 filter() 方法:
Employee.age == 32Employee.active == True
要將這兩個條件結合在一起,請使用 db.and_() 函數,如下所示:
Output[<Employee John Doe>]
在這裡,您使用語法 filter(db.and_(condition1, condition2))。
在查詢上使用 all() 將返回匹配兩個條件的所有記錄的列表。您可以使用 first() 方法來獲取第一個結果:
Output<Employee John Doe>
對於更複雜的示例,您可以使用 db.and_() 與 date() 函數來獲取在特定時間範圍內被聘用的員工。在這個例子中,您可以獲取在 2019 年被聘用的所有員工:
Output<Employee Alex Brown> | Hired: 2019-01-03
<Employee Emily Vill> | Hired: 2019-06-09
在這裡,您導入 date() 函數,並使用 db.and_() 函數來組合以下兩個條件:
Employee.hire_date >= date(year=2019, month=1, day=1):這對於 2019 年 1 月 1 日或之後被聘用的員工為True。Employee.hire_date < date(year=2020, month=1, day=1):對於在2020年1月1日之前入職的員工,這是True。
結合這兩個條件可獲取從2019年1月1日開始至2020年1月1日之前入職的員工。
或
類似於db.and_(),db.or_() 函數結合兩個條件,其行為類似於 Python 中的or運算符。它擷取滿足兩個條件之一的所有記錄。例如,要獲取年齡為32或52歲的員工,您可以使用db.or_() 函數結合兩個條件,如下所示:
Output<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
<Employee Harold Ishida> | Age: 52
您還可以在傳遞給filter() 方法的條件中使用字符串值的startswith()和endswith()方法。例如,要獲取所有名字以字符串'M'開頭且姓以字符串'e'結尾的員工:
Output<Employee John Doe>
<Employee Mary Doe>
<Employee James White>
<Employee Mary Park>
在此,您結合了以下兩個條件:
Employee.firstname.startswith('M'):匹配名字以'M'開頭的員工。Employee.lastname.endswith('e'):匹配姓以'e'結尾的員工。
現在,您可以在 Flask-SQLAlchemy 應用中使用邏輯條件篩選查詢結果。接下來,您將對從數據庫獲得的結果進行排序、限制和計數。
步驟 4 — 排序、限制和計算結果
在網絡應用程序中,當顯示記錄時,通常需要將它們排序。例如,您可能有一個頁面來顯示每個部門的最新僱用情況,以讓團隊其他成員了解新僱用情況,或者您可以通過首先顯示最老的僱用情況來按員工排序,以表彰長期工作的員工。在某些情況下,您還需要限制結果,例如在小側邊欄上僅顯示最新的三個僱用情況。而且,您通常需要計算查詢結果,例如顯示當前活動員工的數量。在此步驟中,您將學習如何排序、限制和計算結果。
排序結果
要使用特定列的值對結果進行排序,請使用 order_by() 方法。例如,要按員工的名字對結果進行排序:
Output[<Employee Alex Brown>, <Employee Emily Vill>, <Employee Harold Ishida>, <Employee James White>, <Employee Jane Tanaka>, <Employee John Doe>, <Employee Mary Doe>, <Employee Mary Park>, <Employee Scarlett Winter>]
正如輸出所示,結果按員工的名字按字母順序排序。
您也可以按其他列進行排序。例如,您可以使用姓來排序員工:
Output[<Employee Alex Brown>, <Employee John Doe>, <Employee Mary Doe>, <Employee Harold Ishida>, <Employee Mary Park>, <Employee Jane Tanaka>, <Employee Emily Vill>, <Employee James White>, <Employee Scarlett Winter>]
您還可以按員工的僱用日期排序:
Output
Harold Ishida 2002-03-06
John Doe 2012-03-03
Jane Tanaka 2015-09-12
Mary Doe 2016-06-07
Alex Brown 2019-01-03
Emily Vill 2019-06-09
James White 2021-02-04
Scarlett Winter 2021-04-07
Mary Park 2021-08-11
如輸出所示,此命令將結果從最早雇用到最新雇用進行排序。要反轉順序並使其按最新雇用到最早雇用的方式降序排列,請使用desc()方法,如下所示:
OutputMary Park 2021-08-11
Scarlett Winter 2021-04-07
James White 2021-02-04
Emily Vill 2019-06-09
Alex Brown 2019-01-03
Mary Doe 2016-06-07
Jane Tanaka 2015-09-12
John Doe 2012-03-03
Harold Ishida 2002-03-06
您還可以將order_by()方法與filter()方法結合使用以對排序後的結果進行篩選。以下示例獲取所有在2021年入職的員工並按年齡排序:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
Mary Park 2021-08-11 | Age 30
在這裡,您使用db.and_()函數搭配兩個條件:對於在2021年1月1日或之後入職的員工,使用Employee.hire_date >= date(year=2021, month=1, day=1),並對於在2022年1月1日之前入職的員工,使用Employee.hire_date < date(year=2022, month=1, day=1)。然後使用order_by()方法來按照員工的年齡對結果進行排序。
限制結果
在大多數實際情況下,在查詢數據庫表時,您可能會得到高達數百萬的匹配結果,有時需要將結果限制為某個數量。要在Flask-SQLAlchemy中限制結果,您可以使用limit()方法。以下示例查詢employee表並僅返回前三個匹配結果:
Output[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>]
您可以將limit()與其他方法(如filter和order_by)結合使用。例如,您可以使用limit()方法獲取在2021年入職的最後兩名員工,如下所示:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
這裡,您使用了在前一節中相同的查詢,並新增了一個額外的limit(2)方法調用。
統計結果
要計算查詢結果的數量,您可以使用count()方法。例如,要獲取目前數據庫中員工的數量:
Output9
您可以將count()方法與其他類似limit()的查詢方法結合使用。例如,要獲取2021年入職的員工數量:
Output3
這裡您使用了之前用於獲取所有2021年入職員工的相同查詢。您使用count()來檢索條目的數量,其值為3。
您已經在Flask-SQLAlchemy中對查詢結果進行了排序、限制和計數。接下來,您將學習如何將查詢結果分成多個頁面,以及如何在Flask應用程序中創建分頁系統。
步驟5 — 在多個頁面上顯示長記錄列表
在這一步中,您將修改主路由,使索引頁面在多個頁面上顯示員工,以便更輕鬆地瀏覽員工列表。
首先,您將使用 Flask shell 來演示如何在 Flask-SQLAlchemy 中使用分頁功能。如果尚未打開 Flask shell,請打開:
假設您想將表中的員工記錄分成多個頁面,每頁兩個項目。您可以使用 paginate() 查詢方法來實現:
Output<flask_sqlalchemy.Pagination object at 0x7f1dbee7af80>
[<Employee John Doe>, <Employee Mary Doe>]
您可以使用 paginate() 查詢方法的 page 參數來指定您要訪問的頁面,這在本例中是第一頁。per_page 參數指定每頁必須包含的項目數。在這種情況下,您將其設置為 2,以使每頁包含兩個項目。
這裡的 page1 變量是一個分頁對象,它提供了您用於管理分頁的屬性和方法。
您可以使用 items 屬性訪問頁面的項目。
要訪問下一頁,您可以使用分頁對象的 next() 方法,返回的結果也是一個分頁對象:
Output[<Employee Jane Tanaka>, <Employee Alex Brown>]
<flask_sqlalchemy.Pagination object at 0x7f1dbee799c0>
您可以使用 prev() 方法獲取上一頁的分頁對象。在下面的示例中,您訪問第四頁的分頁對象,然後訪問其上一頁的分頁對象,即第三頁:
Output[<Employee Scarlett Winter>, <Employee Emily Vill>]
[<Employee James White>, <Employee Harold Ishida>]
您可以使用 page 屬性來獲取當前頁碼,如下所示:
Output1
2
要获取总页数,请使用分页对象的 pages 属性。在以下示例中,page1.pages 和 page2.pages 都返回相同的值,因为总页数是一个常量:
Output5
5
要获取总项目数,请使用分页对象的 total 属性:
Output9
9
在这里,由于您查询了所有员工,所以分页中的总项目数为 9,因为数据库中有九个员工。
以下是分页对象具有的一些其他属性:
prev_num: 上一页的页码。next_num: 下一页的页码。has_next: 如果存在下一页,则为True。has_prev: 如果存在上一页,则为True。per_page: 每页的项目数。
分页对象还具有一个 iter_pages() 方法,您可以通过循环遍历访问页面号码。例如,您可以这样打印所有页面号码:
Output1
2
3
4
5
以下是使用分页对象和 iter_pages() 方法访问所有页面及其项目的演示:
Output
PAGE 1
-
[<Employee John Doe>, <Employee Mary Doe>]
--------------------
PAGE 2
-
[<Employee Jane Tanaka>, <Employee Alex Brown>]
--------------------
PAGE 3
-
[<Employee James White>, <Employee Harold Ishida>]
--------------------
PAGE 4
-
[<Employee Scarlett Winter>, <Employee Emily Vill>]
--------------------
PAGE 5
-
[<Employee Mary Park>]
--------------------
在这里,您创建了一个从第一页开始的分页对象。您使用带有 iter_pages() 分页方法的 for 循环遍历页面。您打印页面号码和页面项目,并使用 next() 方法将 pagination 对象设置为其下一页的分页对象。
您也可以使用filter()和order_by()方法与paginate()方法一起对查询结果进行分页、筛选和排序。例如,您可以获取年龄超过三十岁的员工,并按年龄排序结果,然后对结果进行分页,如下所示:
OutputPAGE 1
-
<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
--------------------
PAGE 2
-
<Employee Mary Doe> | Age: 38
<Employee Harold Ishida> | Age: 52
--------------------
现在您已经对Flask-SQLAlchemy中分页的工作原理有了扎实的了解,您将编辑应用程序的索引页面,以在多个页面上显示员工,以便更轻松地导航。
退出Flask shell:
要访问不同的页面,您将使用URL参数,也称为URL查询字符串,这是通过URL将信息传递给应用程序的一种方式。参数是在?符号之后的URL中传递给应用程序的。例如,要使用不同的值传递page参数,您可以使用以下URL:
http://127.0.0.1:5000/?page=1
http://127.0.0.1:5000/?page=3
在这里,第一个URL将值1传递给URL参数page。第二个URL将值3传递给相同的参数。
打开app.py文件:
编辑索引路由如下:
在这里,您使用request.args对象及其get()方法获取page URL参数的值。例如/?page=1将从page URL参数中获取值1。您将1作为默认值传递,并将int Python类型作为type参数的参数传递,以确保该值是一个整数。
接下來,您創建一個pagination對象,按照名字的第一個字母排序查詢結果。您將page URL參數值傳遞給paginate()方法,並通過將值2傳遞給per_page參數來將結果分為每頁兩項。
最後,將您構造的pagination對象傳遞給渲染的index.html模板。
保存並關閉文件。
接下來,編輯index.html模板以顯示分頁項目:
通過添加一個h2標題來更改內容div標籤,該標題指示當前頁面,並更改for循環以循環遍歷pagination.items對象,而不是employees對象,因為它不再可用:
保存並關閉文件。
如果還沒有,請設置FLASK_APP和FLASK_ENV環境變量並運行開發服務器:
現在,使用不同的page URL參數值導航到索引頁:
http://127.0.0.1:5000/
http://127.0.0.1:5000/?page=2
http://127.0.0.1:5000/?page=4
http://127.0.0.1:5000/?page=19
您將看到每頁兩個項目的不同頁面,以及每頁不同的項目,就像您之前在Flask shell中看到的那樣。
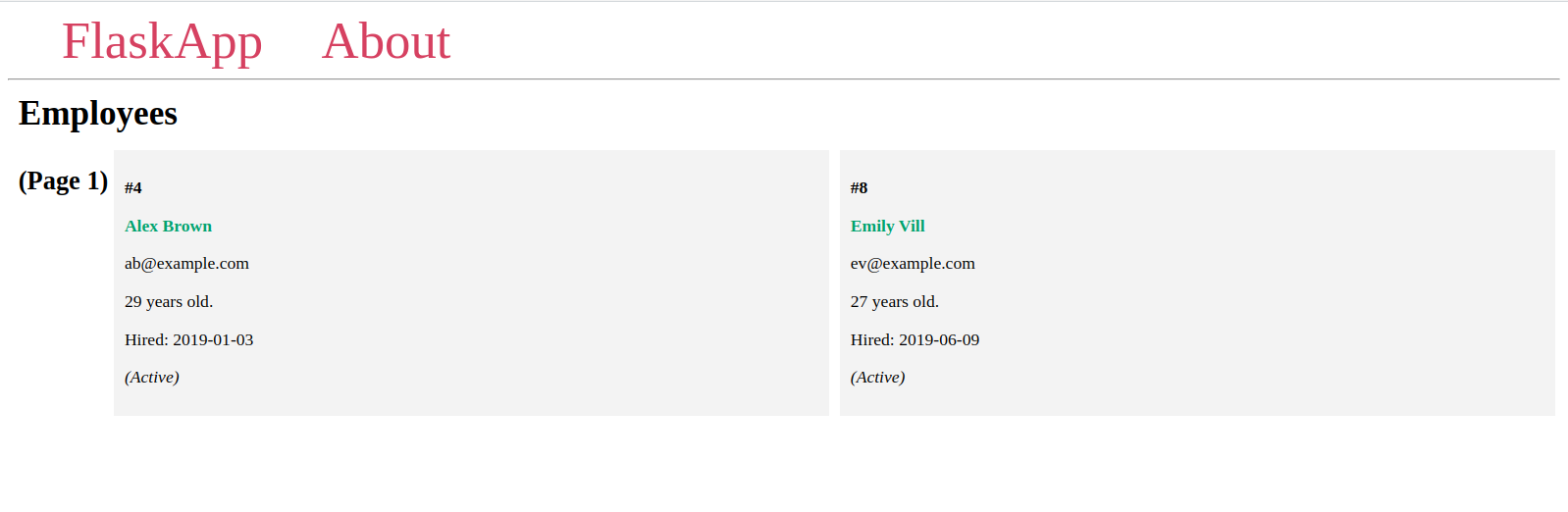
如果給定的頁碼不存在,您將收到一個404 Not Found的HTTP錯誤,這是前述URL列表中最後一個URL的情況。
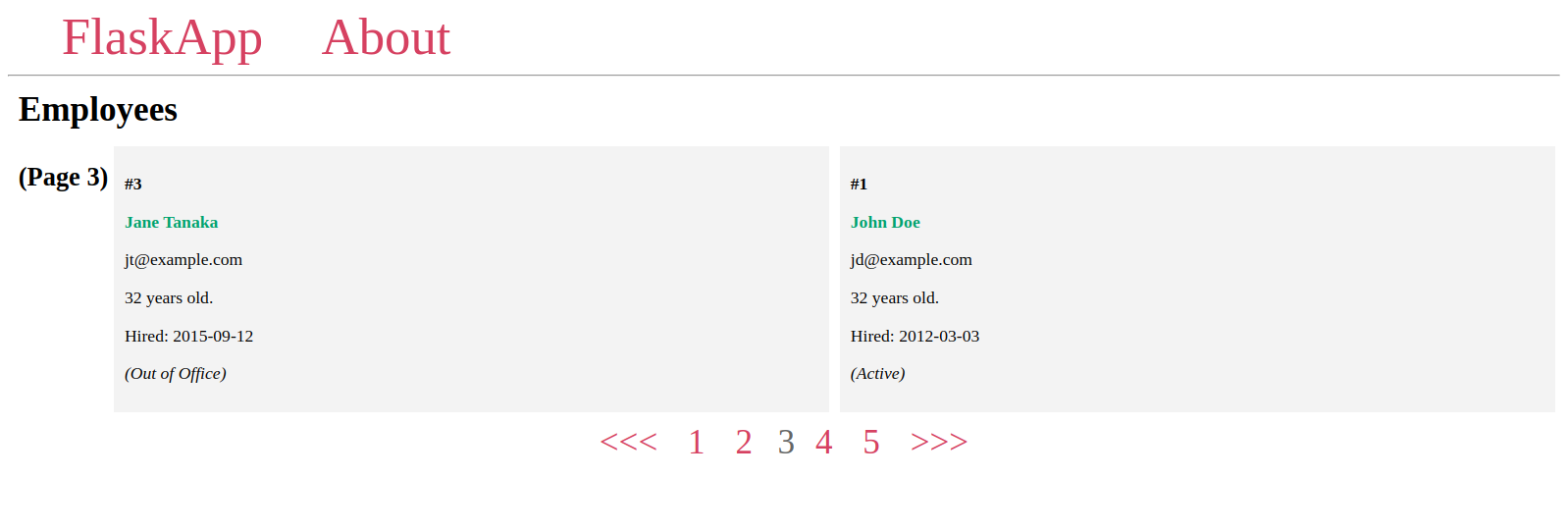
接下來,您將創建一個分頁小部件來在頁面之間進行導航,您將使用分頁對象的一些屬性和方法來顯示所有頁碼,每個頁碼都連結到其對應的頁面,如果當前頁面有前一頁,則會顯示一個 <<< 按鈕以返回,如果存在下一頁,則顯示一個 >>> 按鈕。
分頁小部件將如下所示:

要添加它,打開 index.html:
通過在內容 div 標記下方添加以下突出顯示的 div 標記來編輯文件:
保存並關閉文件。
在這裡,您使用條件 if pagination.has_prev 來添加一個 <<< 鏈接到上一頁,如果當前頁面不是第一頁。您使用 url_for('index', page=pagination.prev_num) 函數調用來鏈接到上一頁,其中您將鏈接到索引視圖函數,將 pagination.prev_num 值傳遞給 page URL 參數。
為了顯示所有可用頁碼的鏈接,您將循環遍歷 pagination.iter_pages() 方法的項目,該方法在每次循環中給出一個頁碼。
你使用if pagination.page != number條件來檢查當前頁碼是否與當前循環中的數字不同。如果條件成立,則鏈接到該頁面,以允許用戶將當前頁面更改為另一頁。否則,如果當前頁面與循環數字相同,則顯示該數字而不帶鏈接。這使用戶可以在分頁小部件中知道當前頁碼。
最後,你使用pagination.has_next條件來查看當前頁面是否有下一頁,如果有,則使用url_for('index', page=pagination.next_num)調用和>>>鏈接鏈接到它。
在瀏覽器中導航到主頁:http://127.0.0.1:5000/
你會看到分頁小部件是完全可操作的:
在這裡,你使用>>>轉到下一頁,<<<轉到上一頁,但你也可以使用任何其他你喜歡的字符,如>和<或<img>標籤中的圖像。
你已經在多個頁面上顯示了員工並學會了如何處理Flask-SQLAlchemy中的分頁。現在你可以在構建的其他Flask應用程序上使用你的分頁小部件了。
結論
您使用了Flask-SQLAlchemy來創建員工管理系統。您查詢了一個表格,並根據列值和簡單和複雜的邏輯條件篩選結果。您對查詢結果進行了排序、計數和限制。您還創建了一個分頁系統,在您的 Web 應用程序中顯示每頁一定數量的記錄,並在頁面之間導航。
您可以將本教程中學到的知識與我們其他一些 Flask-SQLAlchemy 教程中解釋的概念結合起來,為您的員工管理系統添加更多功能:
- 如何在 Flask 應用程序中使用 Flask-SQLAlchemy 與數據庫交互,以了解如何添加、編輯或刪除員工。
- 如何使用 Flask-SQLAlchemy 中的一對多數據庫關係,以了解如何使用一對多關係創建一個部門表格,將每個員工與其所屬的部門相關聯。
- 如何使用Flask-SQLAlchemy实现多对多数据库关系以学习如何使用多对多关系创建
tasks表,并将其与employee表关联,其中每个员工都有多个任务,每个任务分配给多个员工。
如果您想了解更多关于Flask的信息,请查看如何使用Flask构建Web应用程序系列中的其他教程。