













在第一部分,我們涵蓋了幾個關鍵主題。我建議你閱讀它,因為下一部分是以此為基礎的。
作為快速回顧,在第一部分中,我們從宏觀的角度考慮了我們的數據,並區分了內部數據和外部數據。我們還討論了架構和數據合約,以及它們如何提供協商、變更和隨時間演變我們流的手段。最後,我們介紹了事實(狀態)和增量事件類型。事實事件最適合用於傳達狀態和解耦系統,而增量事件則更常用於內部數據,例如事件源和其他緊密耦合的用例。
正規化表格產生正規化流
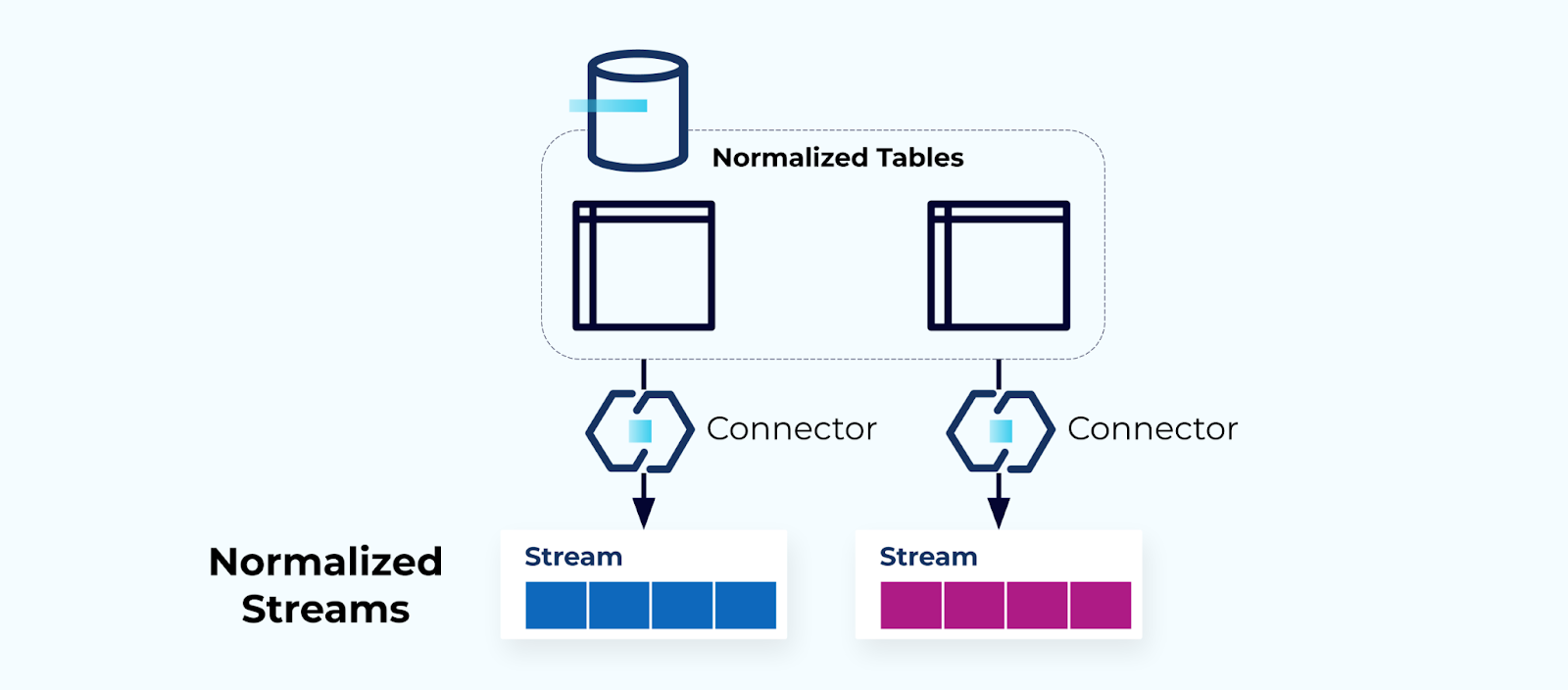
正規化的表格會導致正規化的事件流。連接器(例如,CDC)將數據直接從數據庫拉取到一組鏡像的事件流中。這並不理想,因為它在內部數據庫表和外部事件流之間創造了強耦合。
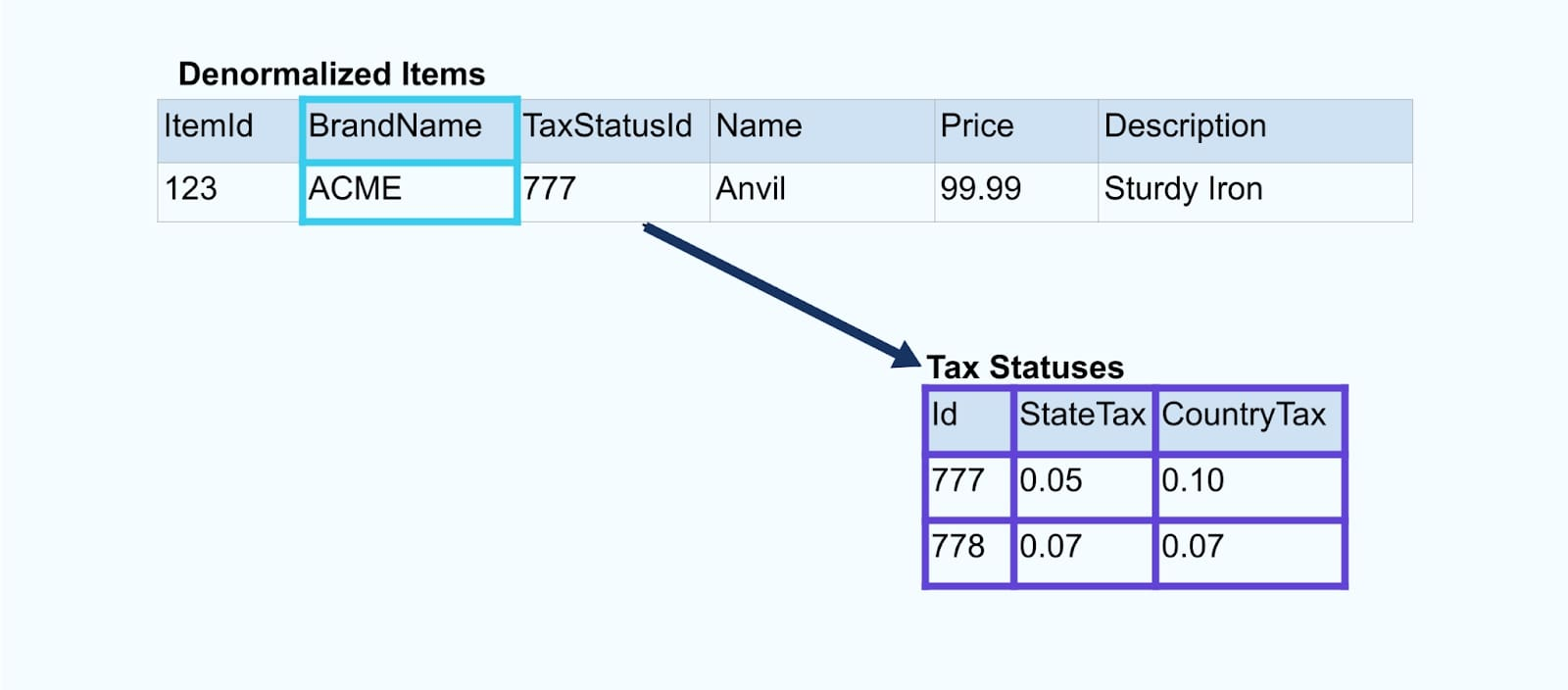
考慮一個簡單的電子商務商品及其相關的品牌和稅務狀態表格。
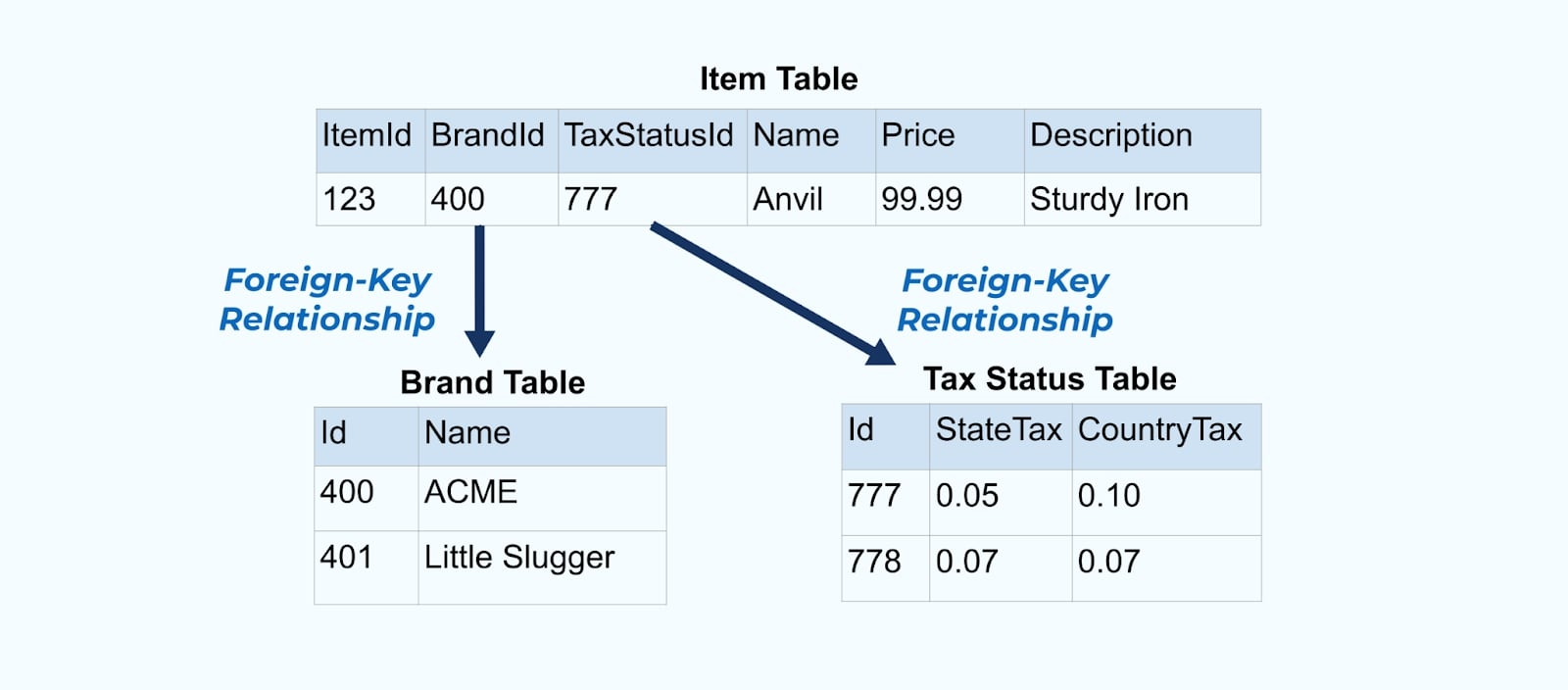
該品牌和稅務狀態表格通過外鍵關係與商品表格相關聯。雖然我們在表格中只顯示一個商品,但根據你所銷售的產品,你可能會有數千(或數百萬)個商品。
為每個表格設置一個連接器,從表格中提取數據,將其組合成事件,並將每個表格寫入專用的事件流是很常見的做法。
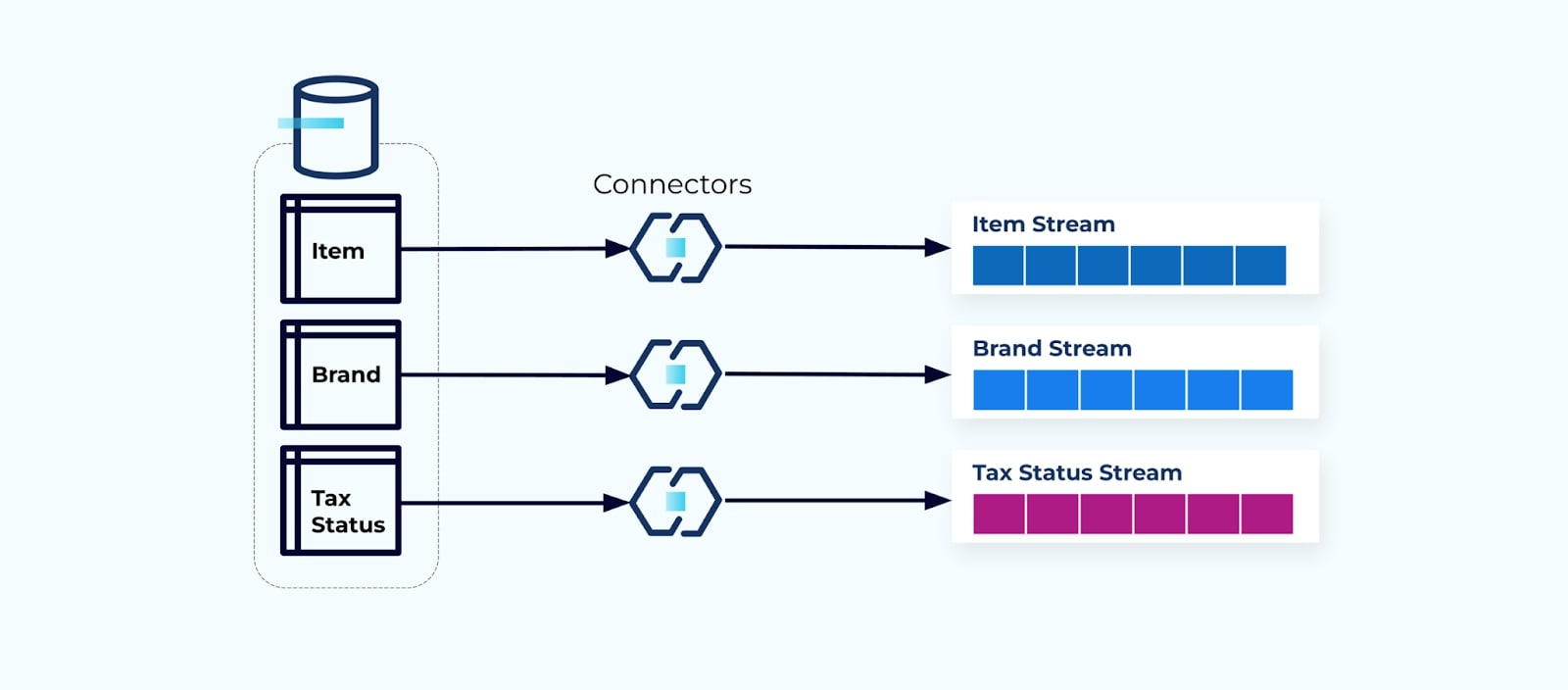
將數據庫中的底層表格暴露出來會導致每個表格對應一個事件流。雖然這樣開始很簡單,但會引發多個問題,可以總結為要麼是 耦合 問題,要麼是 成本 問題。讓我們逐一看看。
問題:消費者對內部模型的耦合
將源 項目 表格原樣暴露出來,迫使消費者直接對其進行耦合。源系統的數據模型的變更將影響下游消費者。
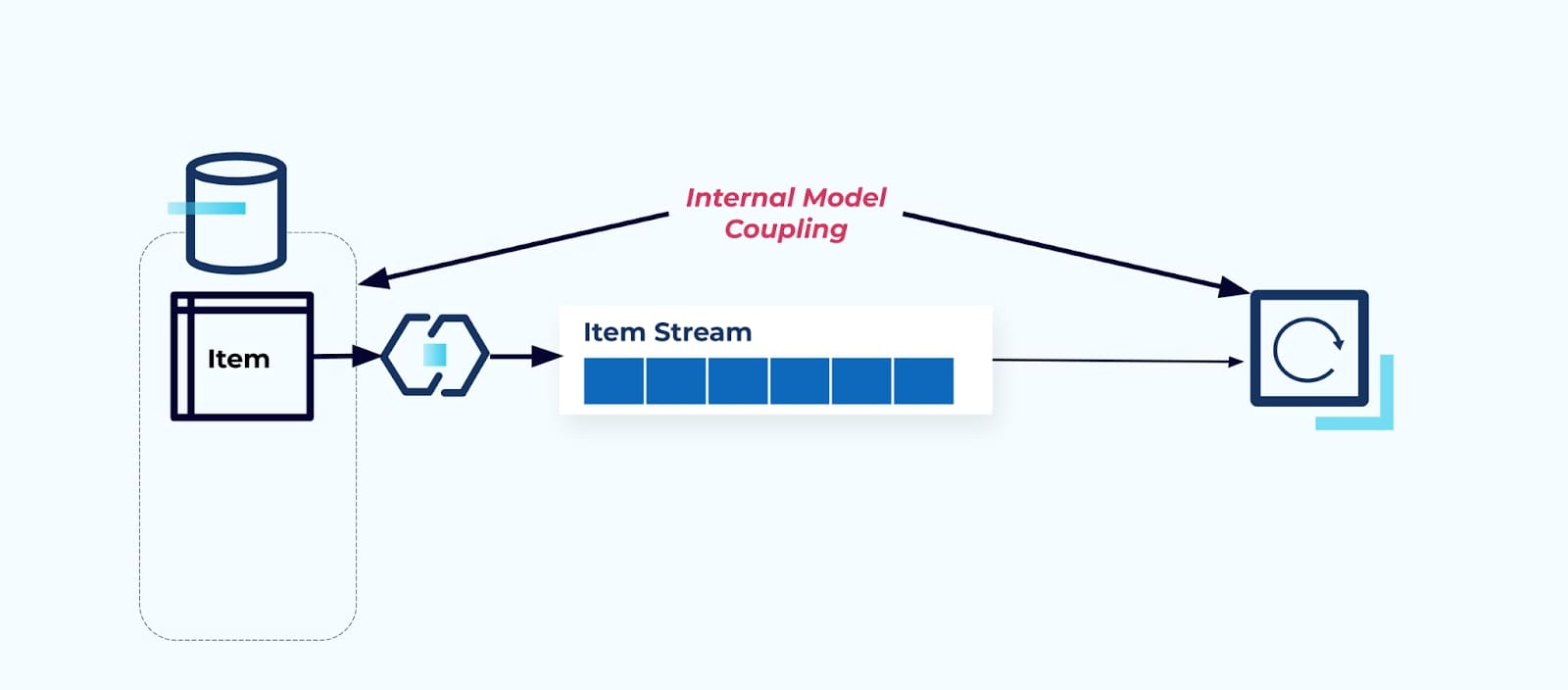
假設我們重構 項目 表格,將 定價提取到自己的表格中。
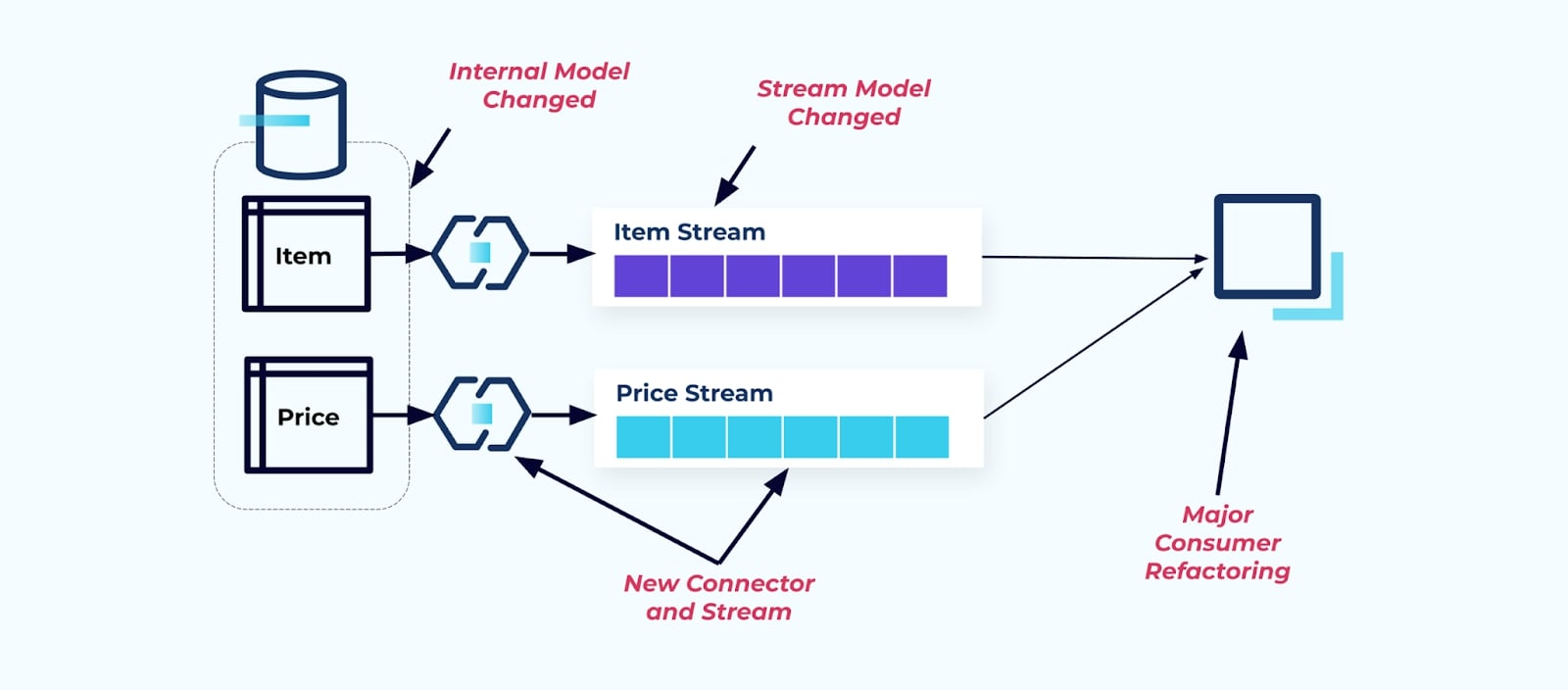
重構源表導致了破損的數據契約,使得消費者無法獲得最初預期的相同項目數據。我們還必須創建一個新的連接器——一個新的P價格流——並最終重構我們的消費者邏輯以使其重新運行。重命名列、更改默認值和更改列類型是由於內部數據模型緊密耦合而引入的其他形式的破壞性變更。
問題:流式聯接(通常)是昂貴的
關係數據庫是專門設計用來快速且便宜地解決聯接的。不幸的是,流式聯接則不是。
考慮兩個服務想要訪問一個項目、其稅務和其品牌信息。如果數據已經寫入其相應的流,那麼每個消費者(如下圖右側)將不得不計算相同的聯接以使Item、Brand和Tax去正規化。
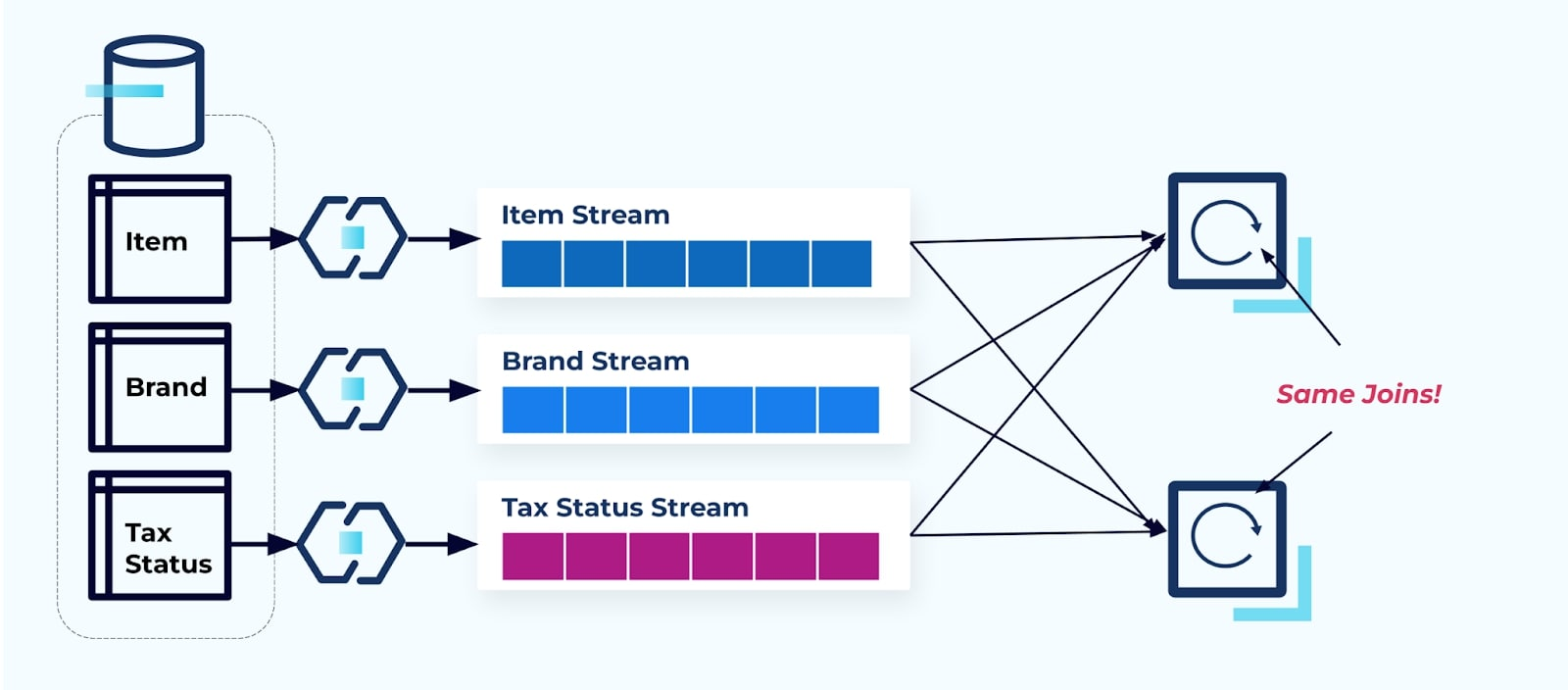
這種策略可能會產生高成本,無論是寫應用程式所需的開發工時,還是計算連接的伺服器成本。在大規模解析串流連接時可能導致大量數據洗牌,這將帶來處理能力、網絡和存儲成本。此外,並非所有串流處理框架都支持連接,特別是在外部鍵上。對於支持連接的框架,如Flink、Spark、KSQL或Kafka Streams(例如),您將發現自己被限制於一組編程語言(Java、Scala、Python)之中。
解決方案:提供去正規化數據是最佳選擇
作為一項原則,使事件流易於供消費者使用。在向消費者提供數據之前,對數據進行去正規化,使用一個抽象層並為消費者創建一個明確的外部模型數據契約(在外部的數據)以便消費者進行耦合。
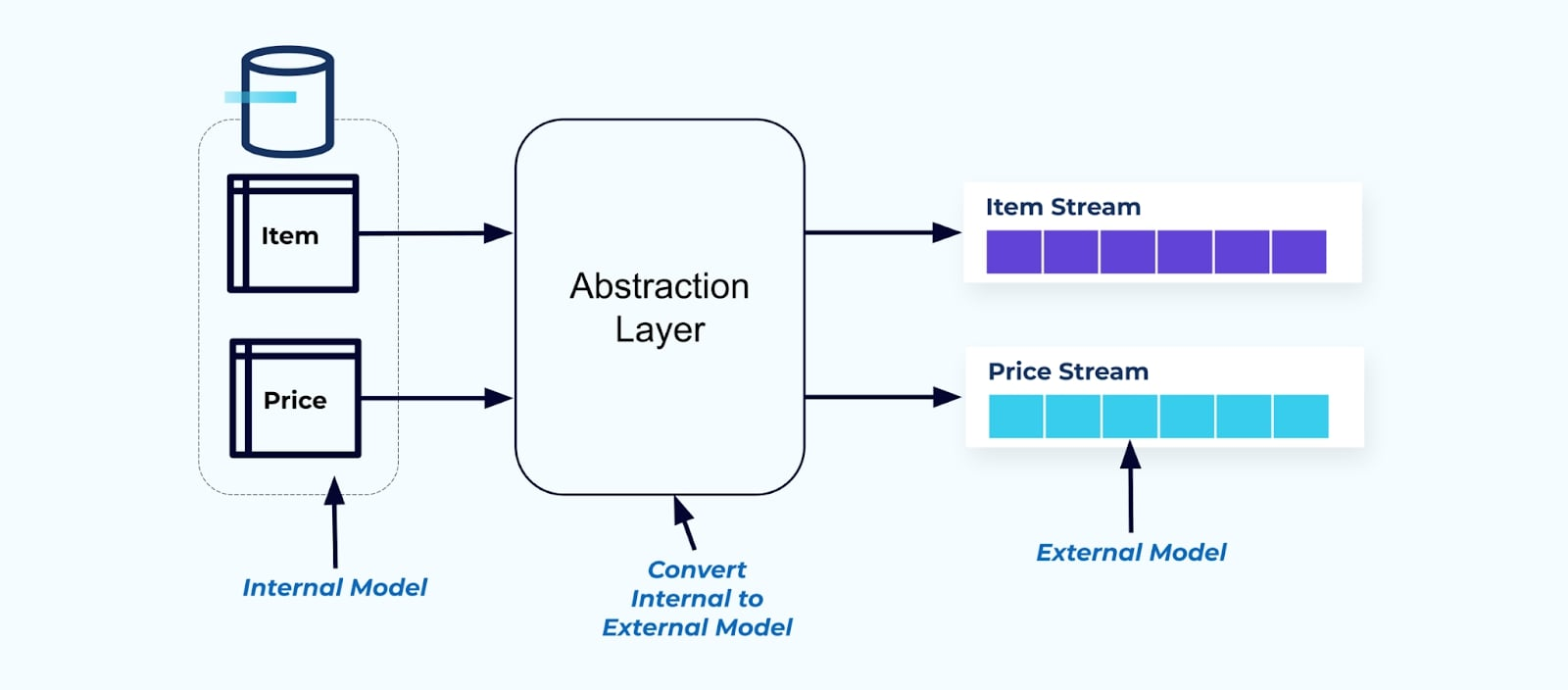
對於內部模型的更改保持在來源系統中獨立。消費者得到一個明確定義的數據契約進行耦合。只要來源系統為消費者保持數據契約,就可以自由進行對來源模型的更改。
但我們應該在哪裡進行去正規化呢?有兩個選擇:
- 通過一個特定的聯結服務在來源系統之外重建。
- 在來源系統中使用事務外匣模式創建事件時。
讓我們依次看看每個解決方案。
選項1:使用特定的聯結服務進行去正規化
在這個例子中,左側的串流與它們來自數據庫的表相對應。
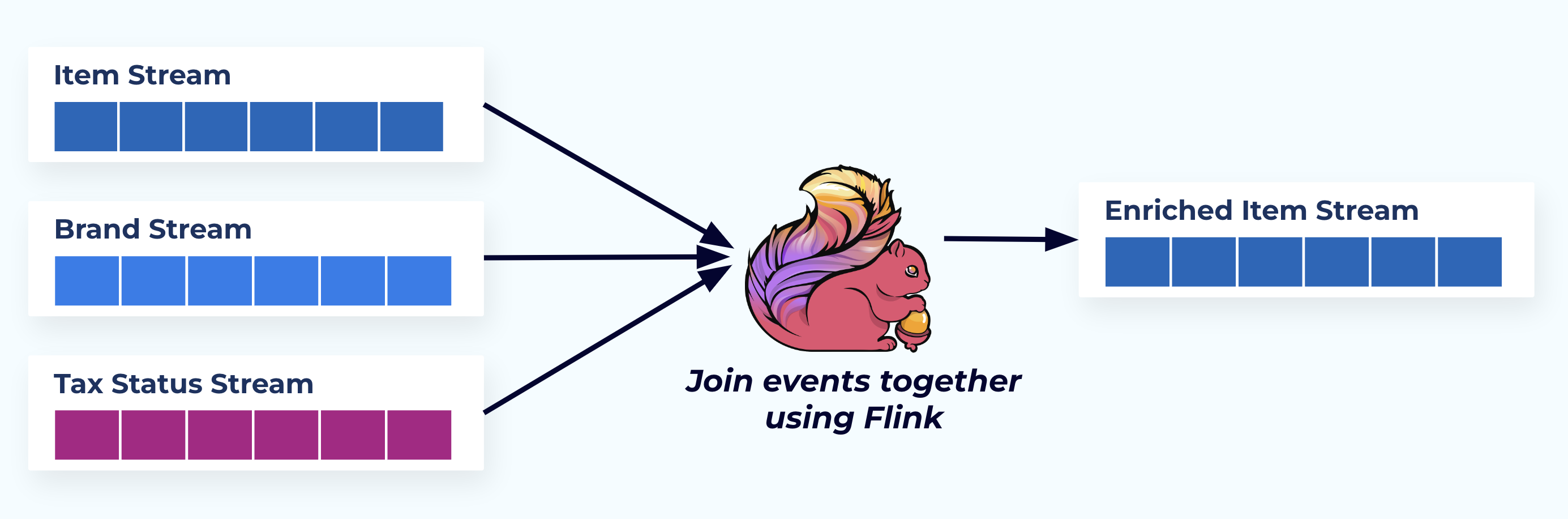
我們使用一個專門建立的應用程式(或串流 SQL 查詢)來連接事件,基於外鍵關係並發出一個豐富的項目流。

從邏輯上來說,我們正在解析關係並將數據壓縮到一個單一的去正規化行中。
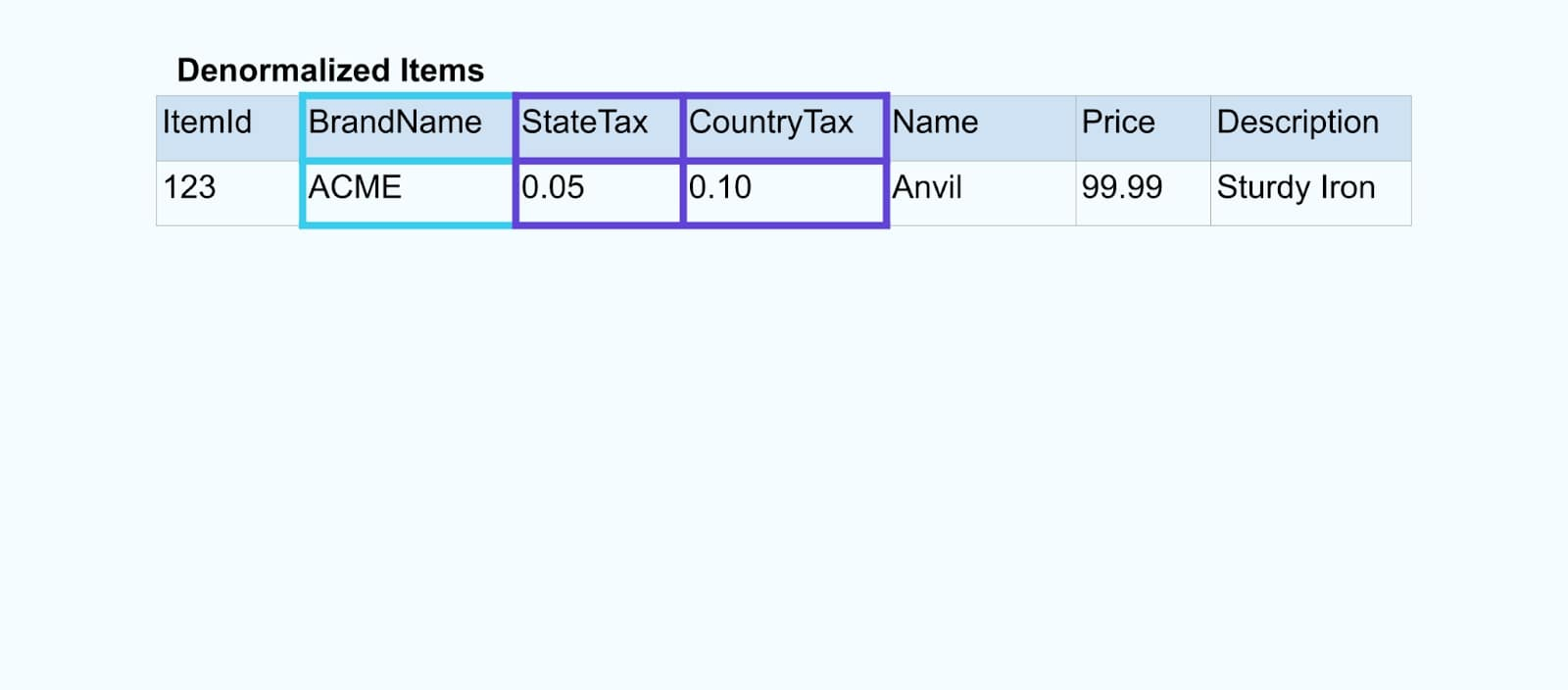
專門建立的連接器依賴於流處理框架,如Apache Kafka Streams和Apache Flink,來解析主鍵和外鍵連接。它們將流數據實體化為持久的內部表格格式,使得連接器應用程序能夠跨任何時間段連接事件,而不僅僅是受時間限制的窗口所限制的。
使用Flink或Kafka Streams的連接器也具有顯著的可擴展性 – 它們可以根據負載的大小進行擴展和縮減,並處理大量的流量。
提示:不要將任何業務邏輯放入連接器中。要在這種模式中取得成功,連接的數據必須準確地代表來源,就像是一個去正規化的結果一樣。讓下游的消費者應用自己的業務邏輯,使用去正規化的數據作為唯一的真相來源。
如果您不想使用下游連接器,還有其他選擇。讓我們接下來看一下事務性輸出箱模式。
選項2:事務性輸出箱模式
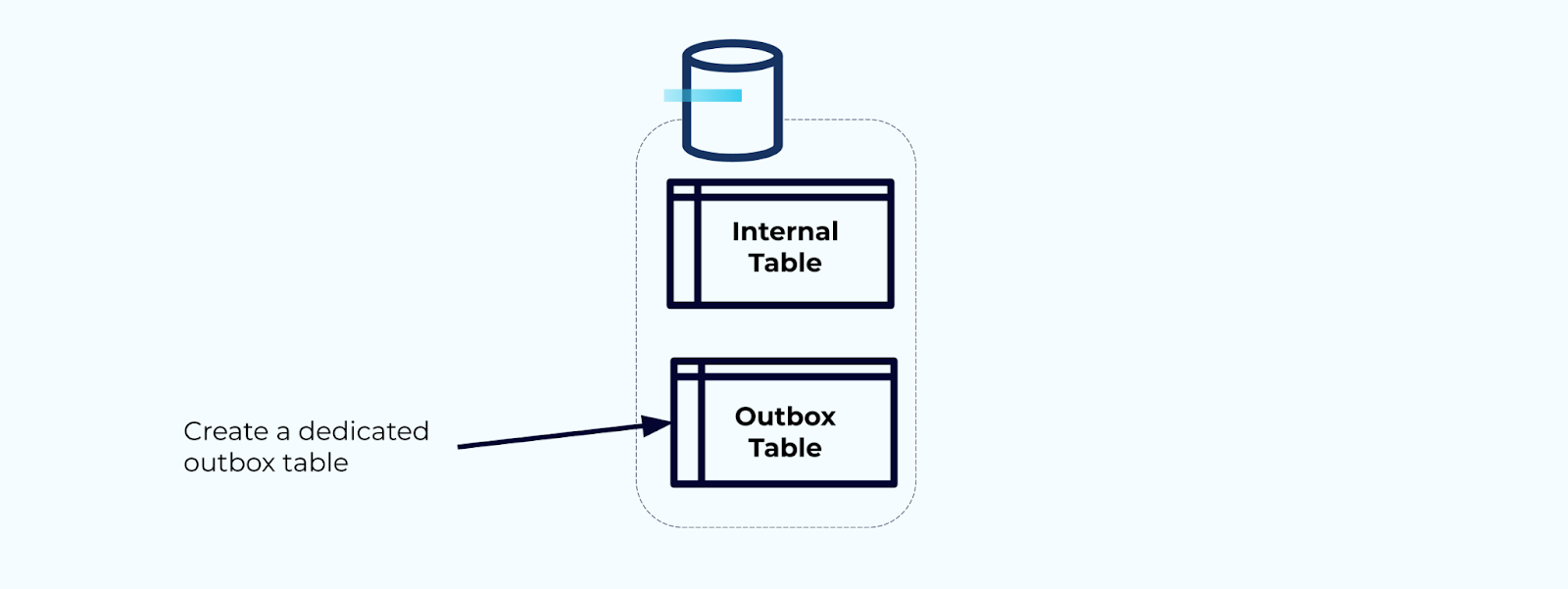
首先,為將事件寫入流的專用輸出箱表格。
其次,將所有必要的內部表更新都包裝在一個事務中。事務可以保證對內部表所做的任何更新也將被寫入到輸出表中。
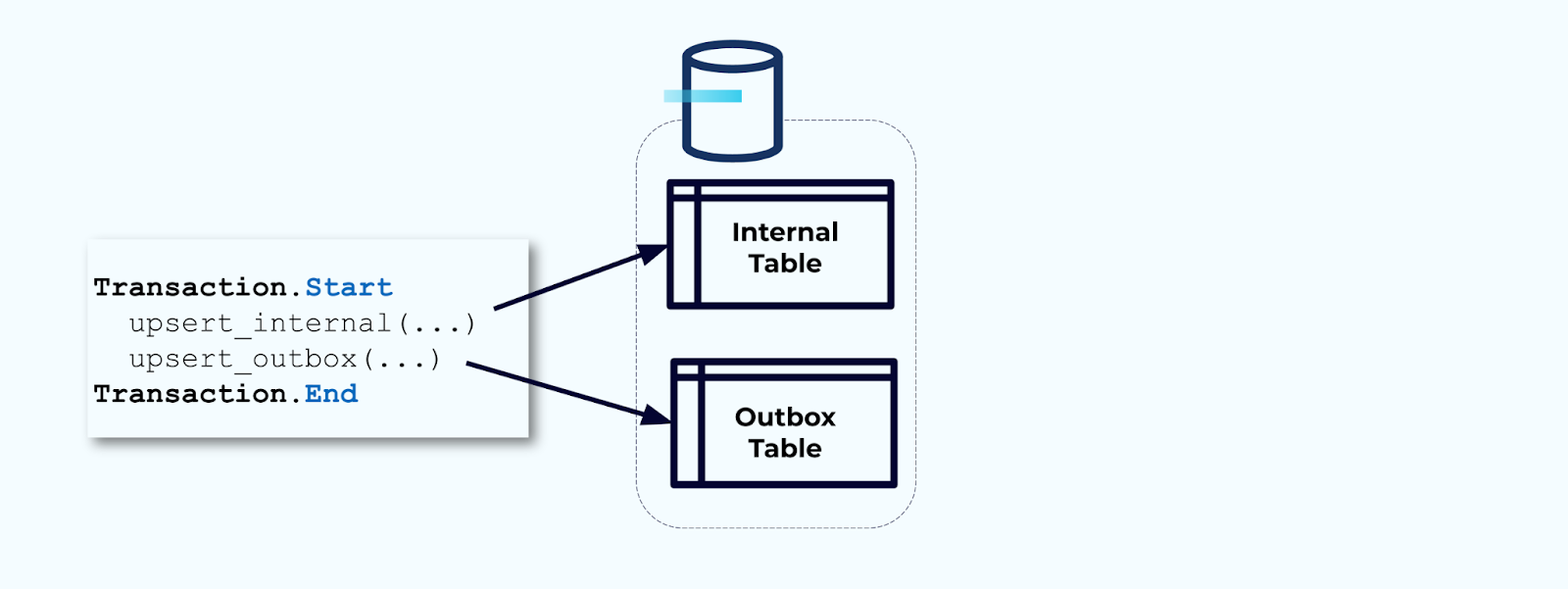
輸出表允許您隔離內部數據模型,因為您可以在將數據寫入輸出表之前對其進行連接和轉換。輸出表充當您內部數據與外部數據之間的抽象層,作為消費者的數據合同。
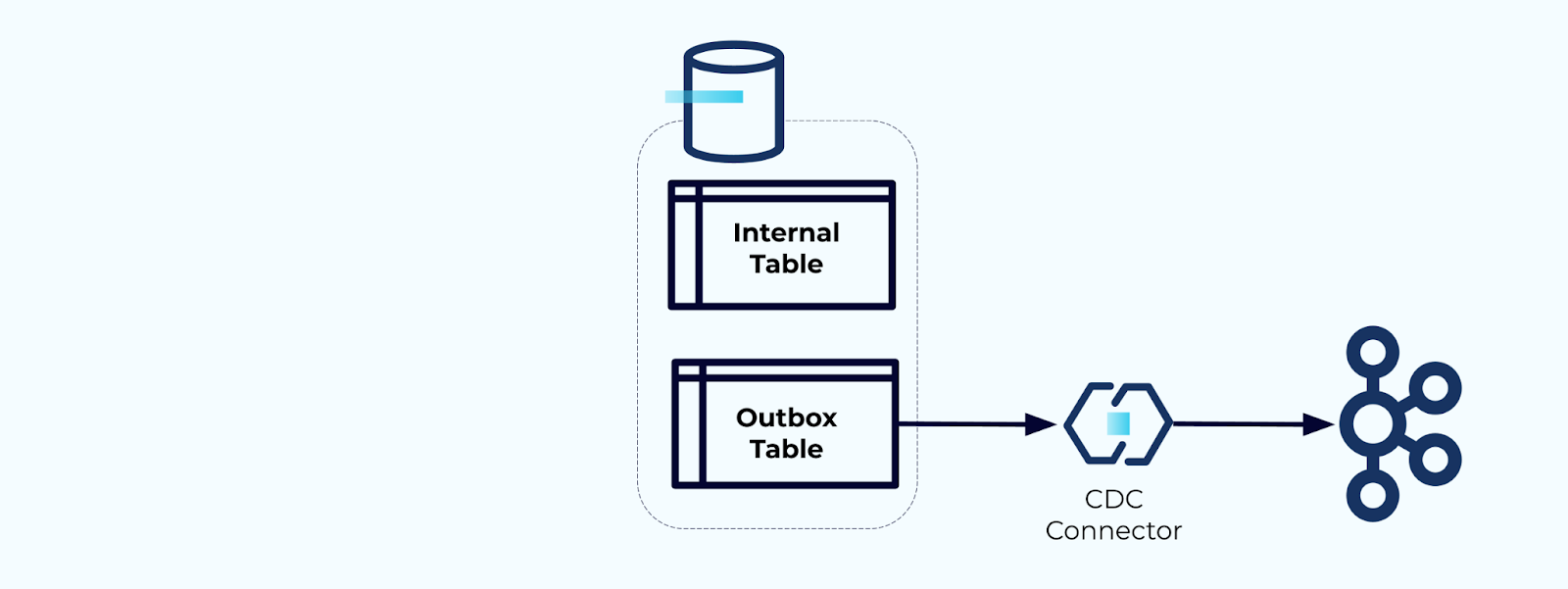
最後,您可以使用連接器將數據從輸出表中取出並放入Kafka中。
您必須確保輸出表不會無限增長-要麼在CDC捕獲數據後刪除數據,要麼定期使用計劃任務。
示例:反范式化用戶行為跟蹤事件
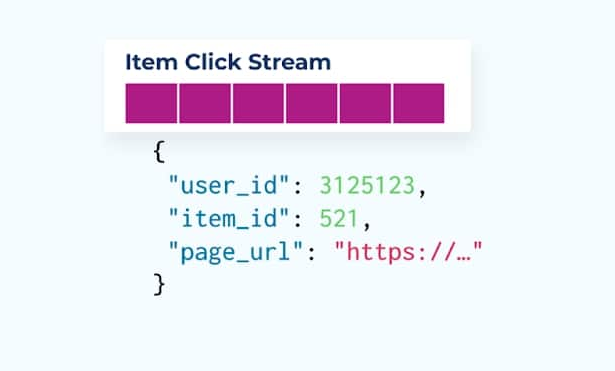
在網頁和應用程序上跟蹤用戶行為是標準化事件的常見來源- 想想Google Analytics或第一方內部選項。但我們不在事件中包含所有信息;而是在創建完成後將其限制為標識符(更快、更小、更便宜),在事實創建後反范式化。
考慮一個項目點擊事件流,詳細描述了用戶在瀏覽電子商務項目時點擊項目的時間。請注意,此項目點擊事件不包含更豐富的項目信息,如名稱、價格和描述,僅包含基本的 ids 。
許多點擊流消費者做的第一件事情是將其與商品事實流結合。由於你處理許多點擊事件,你會發現這最終將使用大量的計算資源。一個專為此目的設計的 Flink 應用程序可以將商品點擊與詳細商品數據結合並將其發送到豐富的商品點擊流中。
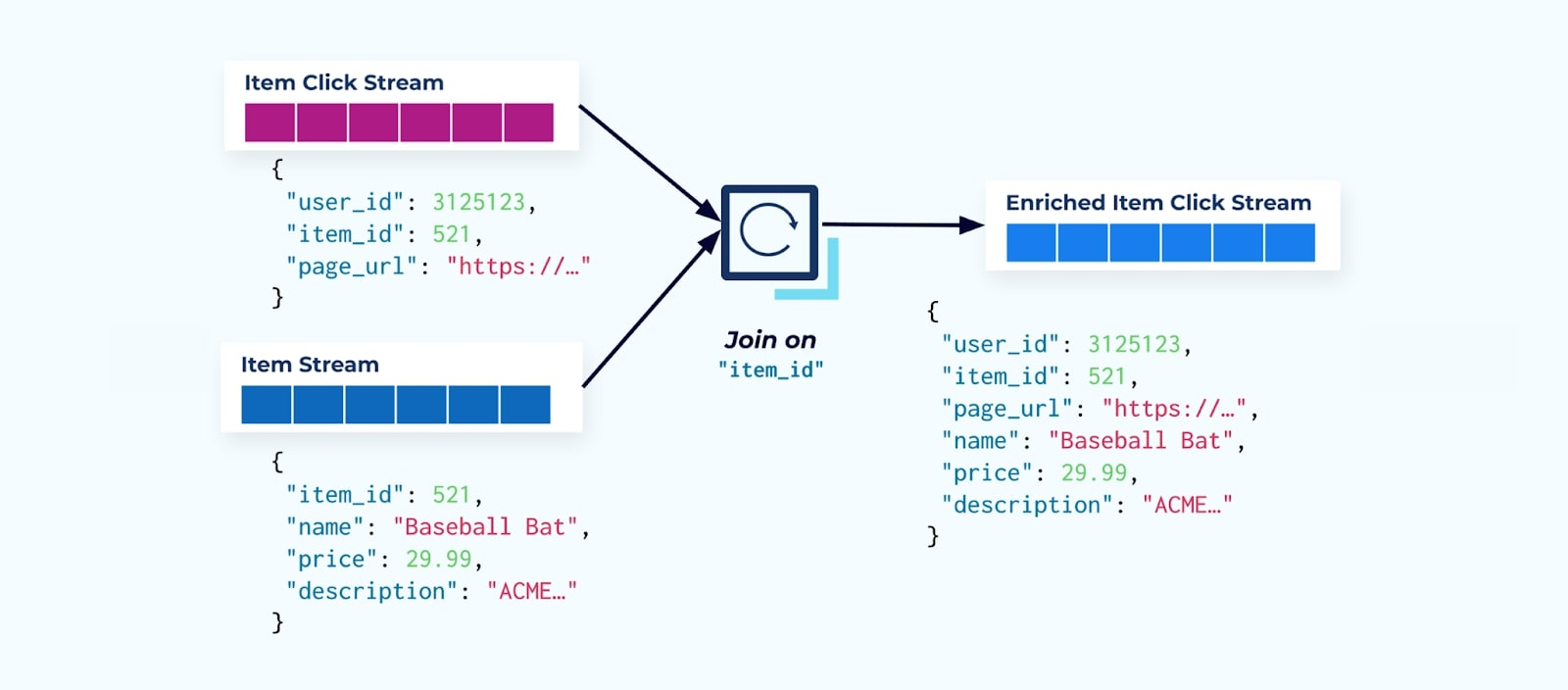
擁有多個部門(和系統)的大公司可能會從不同來源獲取其數據,並且事後使用流連接器進行連接是最可能的結果。
對緩慢變化的維度的考量
我們已經討論了寫入包含大型數據集(例如大型文本區塊)和頻繁更改的數據域(例如商品庫存)的事件的性能考量。現在,我們將看看緩慢變化維度(SCDs),通常透過外鍵關係指示,因為這些可能是重要數據量的另一來源。
讓我們再次回到我們的商品示例。假設你有一個更新商品表的操作。我們將商品從 “Anvil” 更名為 “Iron Anvil”。
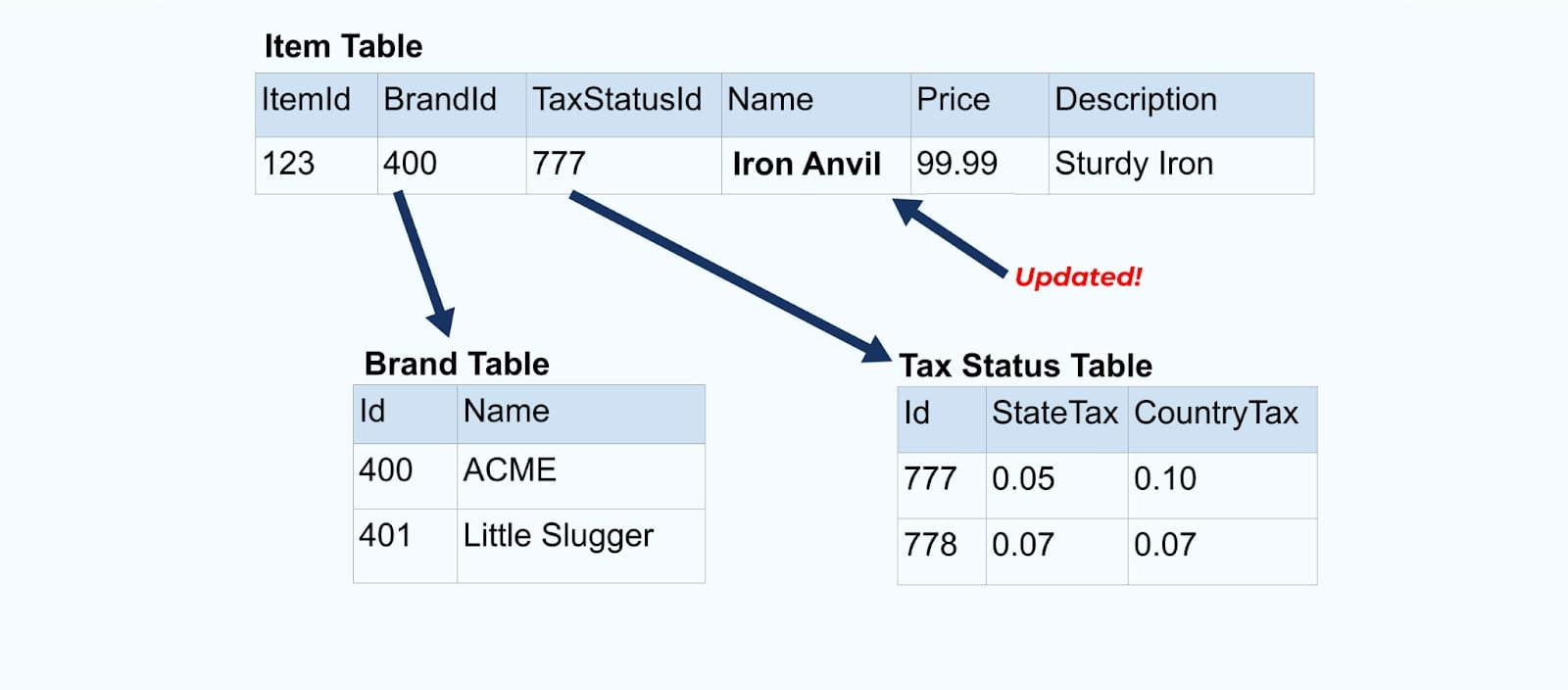
在更新數據庫中的數據時,我們還會發送更新後的商品(例如通過 outbox 模式),包括非規范化的稅收狀態和品牌表。
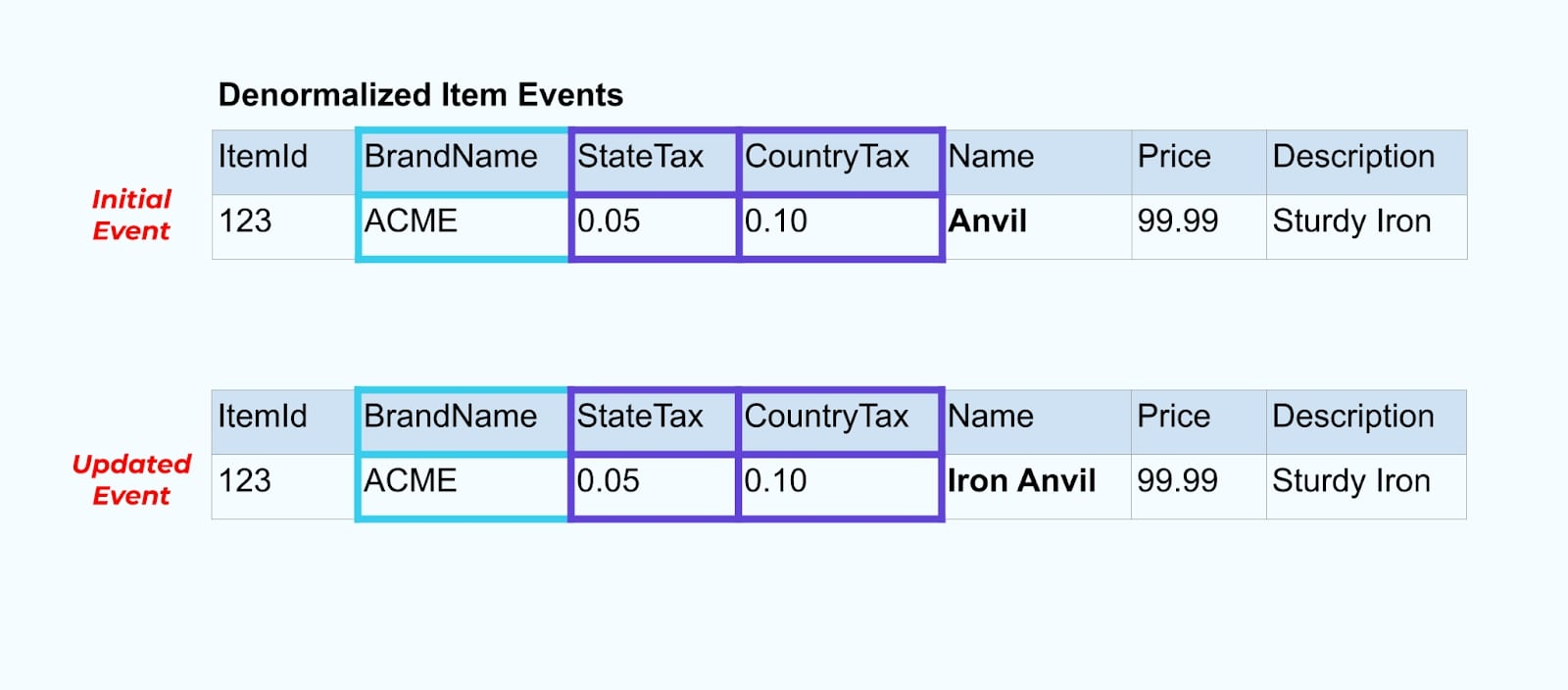
然而,我們還需要考慮當我們更改品牌或稅收表中的值時會發生什麼。更新這些緩慢變化的維度之一可能會導致受影響商品的大量更新。
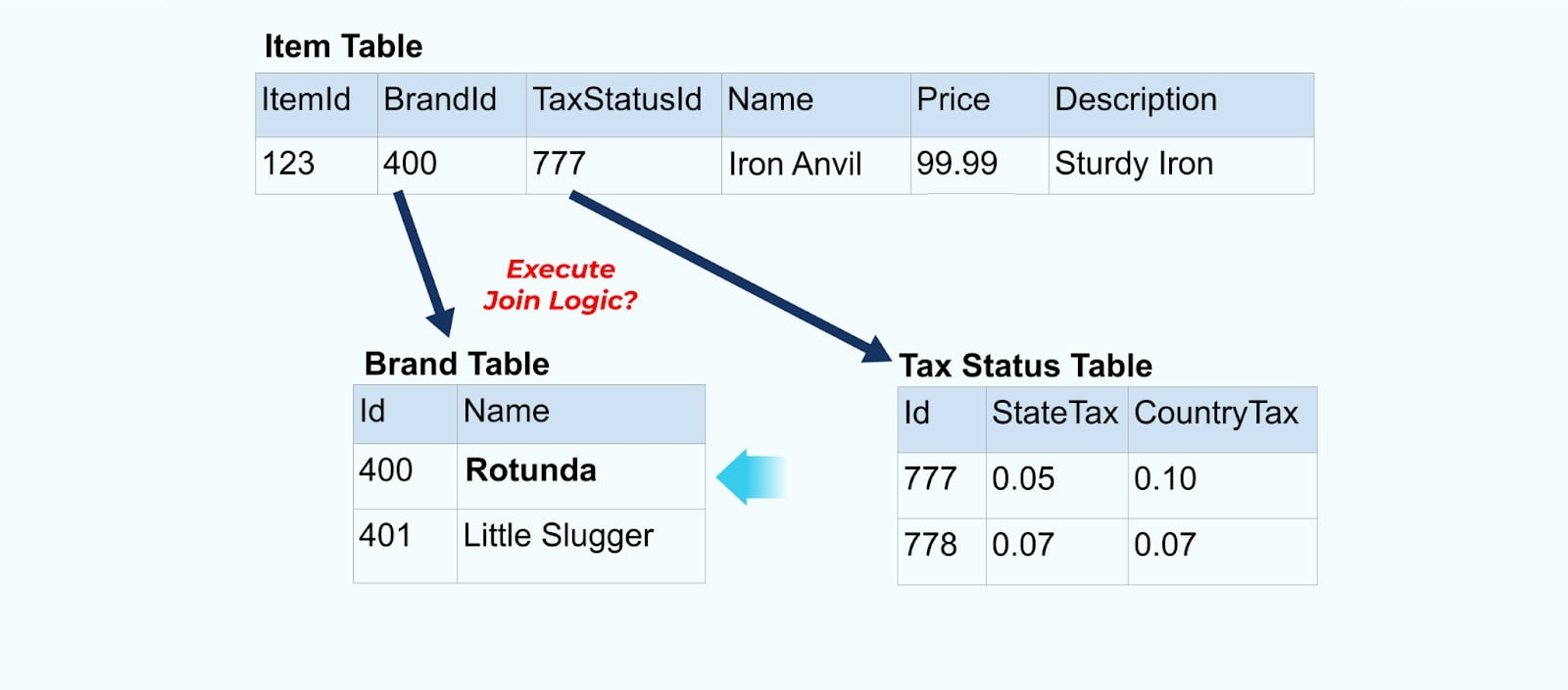
舉例來說,ACME 公司進行重新品牌並提出新的品牌名稱,從 ACME 改為 Rotunda。我們為 ItemId=123 製作另一個事件。
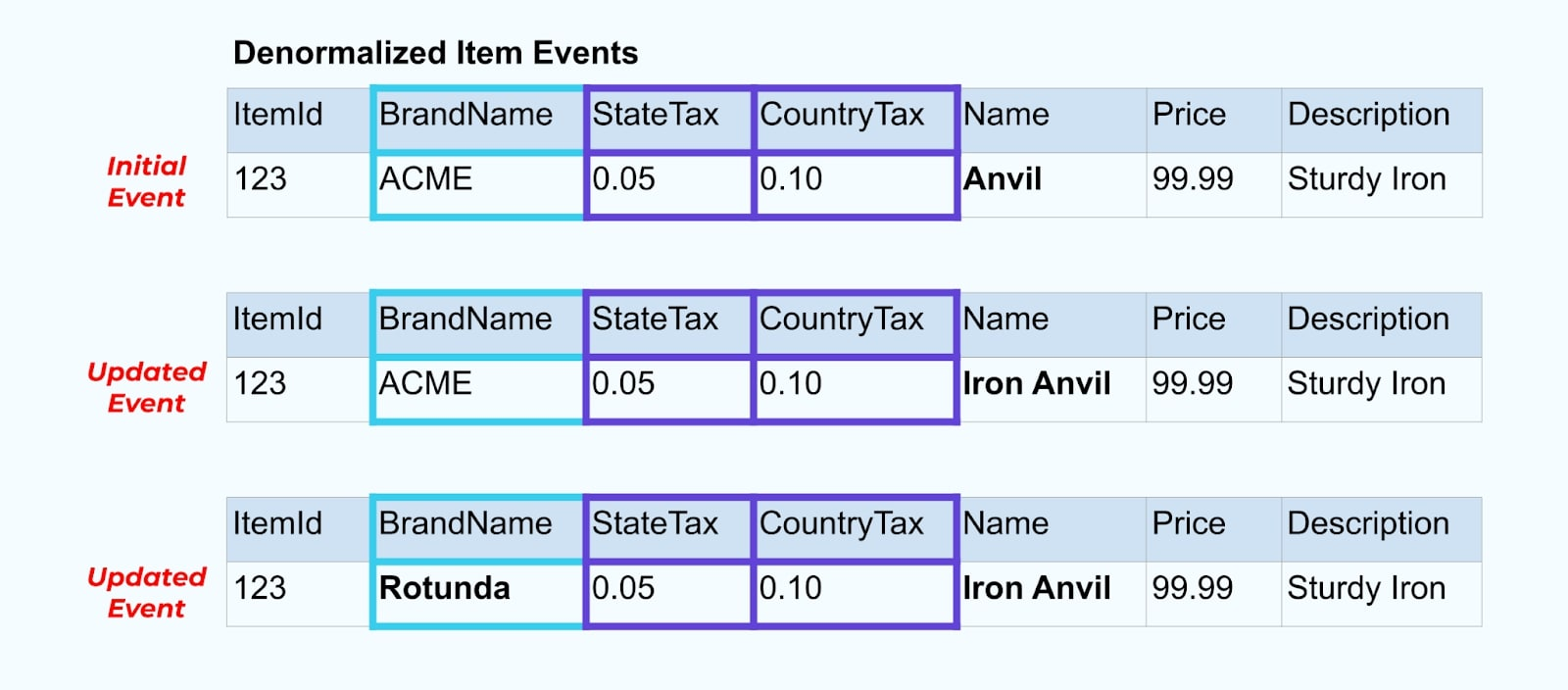
然而,Rotunda(之前是 ACME)可能有許多數百(或數千)項產品也因此更改而更新,導致相應數量的更新豐富的項目事件。
在去正規化 SCD 和外鍵關係時,請記住 SCD 變更可能對整個事件流產生的影響。您可以決定放棄去正規化,並將其留給消費者,若更改 SCD 導致數百萬或數十億的更新事件。
摘要
去正規化使消費者更容易使用數據,但代價是需要更多上游處理和謹慎選擇要包括的數據。消費者可能更容易構建應用程序,並可從更廣泛的技術範圍中選擇,包括那些不原生支持流連接的技術。
當數據較小且更新不頻繁時,上游正規化數據效果良好。請留意較大的事件大小、頻繁的更新和 SCD 等因素,以確定上游應該去正規化的內容,以及應該留給消費者自行處理的內容。
最終,選擇在事件中包含哪些數據以及哪些數據留下來,是消費者需求、製造者能力和獨特數據模型關係之間的平衡。但最好的出發點是了解您的消費者需求和隔離您源系統內部數據模型。
Source:
https://dzone.com/articles/how-to-design-event-streams-part-2