













介紹
就像任何其他設置一樣,Kubernetes 集群中的數據可能面臨丟失的風險。為了防止嚴重問題,擁有一個數據恢復計劃至關重要。一種簡單有效的方法是進行備份,確保您的數據在任何意外事件發生時都是安全的。備份可以單次運行或定期運行。定期備份是個好主意,可以確保您有最近的備份可供輕鬆回退。
Velero – 一個旨在幫助 Kubernetes 集群進行備份和還原操作的開源工具。它非常適用於災難恢復用例,以及在執行集群上的系統操作(如升級)之前對應用程序狀態進行快照。有關此主題的更多詳細信息,請訪問Velero 的工作原理官方頁面。
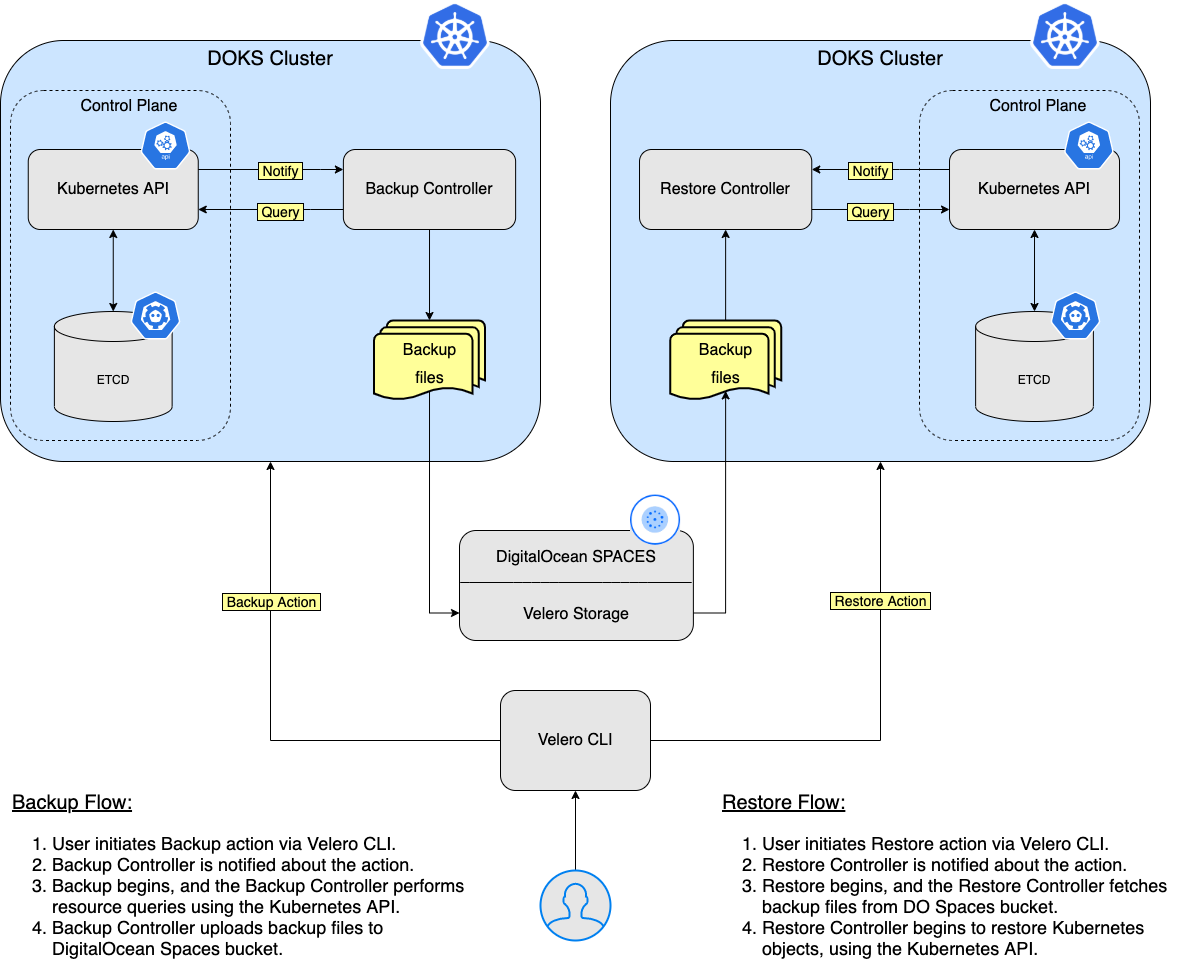
在本教程中,您將學習如何將 Velero 部署到您的 Kubernetes 集群,創建備份,並在出現問題時從備份中恢復。您可以備份整個集群,或選擇一個命名空間或標籤選擇器來備份您的集群。
目錄
先決條件
完成本教程,您需要以下東西:
- A DO Spaces Bucket and access keys. Save the access and secret keys in a safe place for later use.
- A DigitalOcean API token for Velero to use.
- A Git client, to clone the Starter Kit repository.
- Helm 用於管理 Velero 的發行版和升級。
- Doctl 用於 DigitalOcean API 互動。
- Kubectl 用於 Kubernetes 互動。
- Velero 客戶端用於管理 Velero 備份。
步驟 1 – 使用 Helm 安裝 Velero
在此步骤中,您将部署 Velero 和所有必需的组件,以便它能够为您的 Kubernetes 集群资源(包括 PV)执行备份。备份数据将存储在先前在 先决条件 部分创建的 DO Spaces 存储桶中。
首先,克隆 Starter Kit Git 存储库并切换到本地副本的目录:
接下来,添加 Helm 存储库并列出可用的图表:
输出类似于以下内容:
NAME CHART VERSION APP VERSION DESCRIPTION
vmware-tanzu/velero 2.29.7 1.8.1 A Helm chart for velero
感兴趣的图表是 vmware-tanzu/velero,它将在集群上安装 Velero。请访问 velero-chart 页面获取有关此图表的更多详细信息。
然后,使用您选择的编辑器(最好支持 YAML 语法检查)打开并检查 Starter Kit 存储库中提供的 Velero Helm 值文件。
接下来,请相应地替换您的 DO Spaces Velero 存储桶(如名称、区域和密钥)中的 <> 占位符。确保您也提供了您的 DigitalOcean API 令牌(DIGITALOCEAN_TOKEN 键)。
最后,使用 helm 安装 Velero:
A specific version of the Velero Helm chart is used. In this case 2.29.7 is picked, which maps to the 1.8.1 version of the application (see the output from Step 2.). It’s a good practice in general to lock on a specific version. This helps to have predictable results and allows versioning control via Git.
–create-namespace \
现在,通过运行以下命令检查您的 Velero 部署:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
velero velero 1 2022-06-09 08:38:24.868664 +0300 EEST deployed velero-2.29.7 1.8.1
输出类似于以下内容(STATUS 列应显示 deployed):
接下来,验证 Velero 是否已启动并运行:
NAME READY UP-TO-DATE AVAILABLE AGE
velero 1/1 1 1 67s
輸出類似以下內容(部署的Pod必須處於Ready狀態):
如果您有興趣深入了解,您可以查看Velero的服務端組件:
- 探索Velero CLI幫助頁面,以查看可用的命令和子命令。您可以使用
--help標誌獲取每個命令的幫助: - 列出所有
Velero可用的命令:
列出Velero的backup命令選項:
Velero使用多個CRD(自定義資源定義)來表示其資源,如備份、備份計劃等。在本教程的後續步驟中,您將發現每個CRD,以及一些基本示例。
在此步骤中,您将学习如何从您的 DOKS 集群对整个命名空间执行一次性备份,然后恢复它,确保所有资源都被重新创建。所涉及的命名空间是 ambassador。
首先,初始化备份:
接下来,检查备份是否已创建:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
ambassador-backup Completed 0 0 2021-08-25 19:33:03 +0300 EEST 29d default <none>
输出类似于:
然后,等待片刻后,您可以检查它:
Name: ambassador-backup
Namespace: velero
Labels: velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: ambassador
Excluded: <none>
...
- 输出类似于:
- 查找
Phase行。它应该显示Completed。 - 同时确保没有报告任何错误。
创建了一个新的 Kubernetes 备份对象:
~ kubectl get backup/ambassador-backup -n velero -o yaml
apiVersion: velero.io/v1
kind: Backup
metadata:
annotations:
velero.io/source-cluster-k8s-gitversion: v1.21.2
velero.io/source-cluster-k8s-major-version: "1"
velero.io/source-cluster-k8s-minor-version: "21"
...
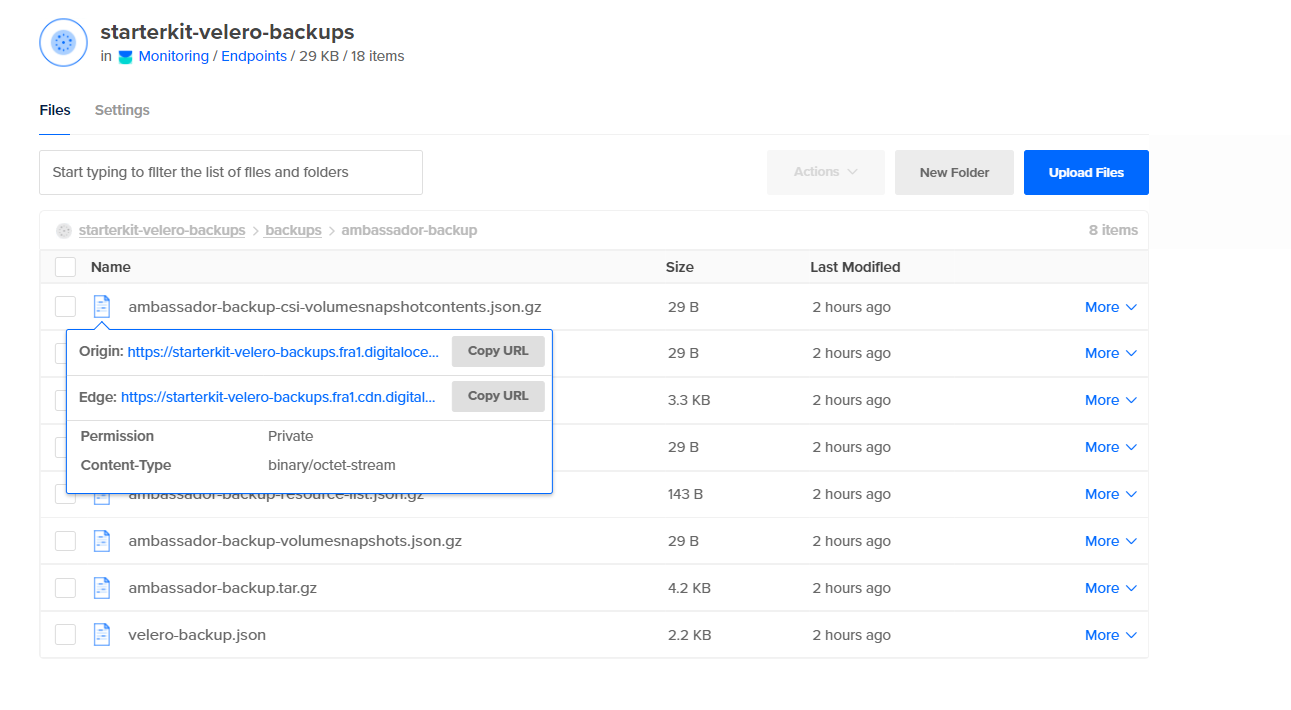
最后,查看 DO Spaces 存储桶,确保有一个名为 backups 的新文件夹,其中包含为您的 ambassador-backup 创建的资产:
首先,通過故意刪除 ambassador 命名空間來模擬一次災難:
接下來,檢查命名空間是否已被刪除(命名空間清單不應打印 ambassador):
最後,確認 echo 和 quote 後端服務端點是否為 DOWN。有關在入門套件教程中使用的後端應用程序,請參考 創建 Ambassador Edge Stack 後端服務。您可以使用 curl 進行測試(或者您可以使用您的網頁瀏覽器):
恢復 ambassador-backup:
重要:當您刪除ambassador命名空間時,與ambassador服務相關的負載均衡器資源也將被刪除。因此,當您恢復ambassador服務時,DigitalOcean將重新創建負載均衡器。問題在於,您將獲得一個全新的負載均衡器IP地址,因此您需要調整A記錄以將流量導入集群上托管的域名。
要驗證ambassador命名空間的恢復情況,請檢查ambassador-backup restore命令輸出中的Phase行。它應該顯示已完成(同時請注意警告部分-它會告知是否出現問題):
接下來,驗證ambassador命名空間的所有資源是否已恢復。查找ambassador pods、services和deployments:
NAME READY STATUS RESTARTS AGE
pod/ambassador-5bdc64f9f6-9qnz6 1/1 Running 0 18h
pod/ambassador-5bdc64f9f6-twgxb 1/1 Running 0 18h
pod/ambassador-agent-bcdd8ccc8-8pcwg 1/1 Running 0 18h
pod/ambassador-redis-64b7c668b9-jzxb5 1/1 Running 0 18h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ambassador LoadBalancer 10.245.74.214 159.89.215.200 80:32091/TCP,443:31423/TCP 18h
service/ambassador-admin ClusterIP 10.245.204.189 <none> 8877/TCP,8005/TCP 18h
service/ambassador-redis ClusterIP 10.245.180.25 <none> 6379/TCP 18h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ambassador 2/2 2 2 18h
deployment.apps/ambassador-agent 1/1 1 1 18h
deployment.apps/ambassador-redis 1/1 1 1 18h
NAME DESIRED CURRENT READY AGE
replicaset.apps/ambassador-5bdc64f9f6 2 2 2 18h
replicaset.apps/ambassador-agent-bcdd8ccc8 1 1 1 18h
replicaset.apps/ambassador-redis-64b7c668b9 1 1 1 18h
輸出類似於:
獲取ambassador主機:
NAME HOSTNAME STATE PHASE COMPLETED PHASE PENDING AGE
echo-host echo.starter-kit.online Ready 11m
quote-host quote.starter-kit.online Ready 11m
輸出類似於:
STATE應為Ready,HOSTNAME列應指向完全合格的主機名。
獲取ambassador映射:
NAME SOURCE HOST SOURCE PREFIX DEST SERVICE STATE REASON
ambassador-devportal /documentation/ 127.0.0.1:8500
ambassador-devportal-api /openapi/ 127.0.0.1:8500
ambassador-devportal-assets /documentation/(assets|styles)/(.*)(.css) 127.0.0.1:8500
ambassador-devportal-demo /docs/ 127.0.0.1:8500
echo-backend echo.starter-kit.online /echo/ echo.backend
quote-backend quote.starter-kit.online /quote/ quote.backend
輸出看起來類似於(請注意echo-backend對應到echo.starter-kit.online主機和/echo/源前綴,quote-backend也是如此):
最後,在重新配置負載平衡器和DigitalOcean域名設置之後,請驗證echo和quote後端服務端點是否為UP。請參閱創建Ambassador Edge Stack後端服務。
在下一步中,您將通過有意刪除您的DOKS集群來模擬災難。
在此步驟中,您將模擬災難恢復方案。整個DOKS集群將被刪除,然後從之前的備份中恢復。
首先,為整個DOKS集群創建備份:
接下來,請檢查備份是否已建立且未報告任何錯誤。以下命令列出所有可用的備份:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
all-cluster-backup Completed 0 0 2021-08-25 19:43:03 +0300 EEST 29d default <none>
輸出看起來類似於:
最後,檢查備份狀態和日誌(確保沒有報告任何錯誤):
重要提示:每當您在未指定 --dangerous 標誌的情況下銷毀 DOKS 集群,然後進行還原時,相同的負載均衡器將以相同的 IP 重新創建。這意味著您不需要更新您的 DigitalOcean DNS A 記錄。
但是,當應用 --dangerous 標誌應用於 doctl 命令時,當 Velero 還原您的入口控制器時,現有的負載均衡器將被銷毀,並且將創建具有新外部 IP 的新負載均衡器。因此,請務必相應地更新您的 DigitalOcean DNS A 記錄。
首先,刪除整個 DOKS 集群(請確保相應地替換 <> 佔位符)。
要刪除 Kubernetes 集群而不銷毀相關聯的負載均衡器,請運行:
或者要刪除 Kubernetes 集群以及相關的負載均衡器:
接下來,按照設置 DigitalOcean Kubernetes中的描述重新創建集群。確保新的 DOKS 集群節點數量等於或大於原始數量。
然後,按照先決條件部分和第 1 步 – 使用 Helm 安裝 Velero中的描述安裝 Velero CLI 和 Server。重要的是使用相同的 Helm Chart 版本。
最後,運行以下命令來還原所有內容:
首先,檢查all-cluster-backup還原描述命令輸出的Phase行。(相應替換<>佔位符)。它應該顯示Completed。
現在,運行以下命令來驗證所有集群資源:
現在,後端應用程式也應該對 HTTP 請求作出回應。有關在入門套件教程中使用的後端應用程式,請參考創建 Ambassador Edge Stack 後端服務。
在下一步中,您將學習如何為您的 DOKS 集群應用程序執行定期(或自動)備份。
根據計劃自動進行備份是一個非常有用的功能。它允許您倒帶時間並將系統恢復到先前的工作狀態,如果出現問題。
創建定期備份是一個非常簡單的過程。以下是一個示例,以 1 分鐘 的間隔(選擇了 kube-system 命名空間):
首先,創建計劃:
schedule="*/1 * * * *"
還支持 Linux cron 作業格式:
接下來,驗證是否已創建計劃:
NAME STATUS CREATED SCHEDULE BACKUP TTL LAST BACKUP SELECTOR
kube-system-minute-backup Enabled 2021-08-26 12:37:44 +0300 EEST @every 1m 720h0m0s 32s ago <none>
輸出類似於:
然後,大約一分鐘後檢查所有備份:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
kube-system-minute-backup-20210826093916 Completed 0 0 2021-08-26 12:39:20 +0300 EEST 29d default <none>
kube-system-minute-backup-20210826093744 Completed 0 0 2021-08-26 12:37:44 +0300 EEST 29d default <none>
輸出類似於:
首先,檢查其中一個備份的 Phase 行(請相應地替換 <> 的占位符)。它應該顯示為 Completed。
最後,請注意上述輸出中可能的錯誤和警告,以檢查是否有任何問題。
要還原一分鐘前的備份,請按照本教程先前步驟中學到的相同步驟進行操作。這是一個很好的方式來練習和測試你到目前為止積累的經驗。
在下一步中,您將學習如何手動或自動刪除您隨時間創建的特定備份。
如果您不需要舊的備份,您可以釋放一些資源,既可以釋放 Kubernetes 叢集上的資源,也可以釋放 Velero DO Spaces 存儲桶上的資源。
首先,選擇一個一分鐘的備份,然後發出以下命令(請相應替換<>中的佔位符):
現在,檢查是否從velero backup get命令輸出中刪除了它。它應該也從DO Spaces桶中刪除。
接下來,您將使用selector一次刪除多個備份。velero backup delete子命令提供了一個名為--selector的標誌。它允許您根據Kubernetes標籤一次刪除多個備份。與Kubernetes標籤選擇器相同的規則適用。
首先,列出可用的備份:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
ambassador-backup Completed 0 0 2021-08-25 19:33:03 +0300 EEST 23d default <none>
backend-minute-backup-20210826094116 Completed 0 0 2021-08-26 12:41:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826094016 Completed 0 0 2021-08-26 12:40:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093916 Completed 0 0 2021-08-26 12:39:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093816 Completed 0 0 2021-08-26 12:38:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093716 Completed 0 0 2021-08-26 12:37:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093616 Completed 0 0 2021-08-26 12:36:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093509 Completed 0 0 2021-08-26 12:35:09 +0300 EEST 24d default <none>
輸出類似於:
接下來,說您想刪除所有backend-minute-backup-*資產。從列表中選擇一個備份,並檢查標籤:
Name: backend-minute-backup-20210826094116
Namespace: velero
Labels: velero.io/schedule-name=backend-minute-backup
velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: backend
Excluded: <none>
...
輸出類似於(注意velero.io/schedule-name標籤值):
接下來,您可以刪除所有與backend-minute-backup值匹配的備份velero.io/schedule-name標籤:
最後,檢查所有backend-minute-backup-*資產是否已從velero backup get命令輸出以及DO Spaces桶中消失。
- 當您創建備份時,可以使用
--ttl標誌來指定TTL(存活時間)。如果Velero發現現有的備份資源已經過期,它將刪除: - 備份資源
- 來自雲端物件
存儲的備份文件 - 所有
PersistentVolume快照
所有相關的還原
TTL標誌允許用戶指定以小時、分鐘和秒為單位的備份保留期,格式為--ttl 24h0m0s。如果未指定,則將應用默認的TTL值30天。
首先,使用3分鐘的TTL值創建ambassador備份:
接下來,檢查ambassador備份:
Name: ambassador-backup-3min-ttl
Namespace: velero
Labels: velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: ambassador
Excluded: <none>
Resources:
Included: *
Excluded: <none>
Cluster-scoped: auto
Label selector: <none>
Storage Location: default
Velero-Native Snapshot PVs: auto
TTL: 3m0s
...
A new folder should be created in the DO Spaces Velero bucket as well, named ambassador-backup-3min-ttl.
輸出類似於以下內容(請注意Namespaces -> Included部分 – 它應顯示ambassador,並且TTL字段設置為3ms0):
最後,大約三分鐘後,備份和相關資源應該會自動刪除。您可以使用velero backup describe ambassador-backup-3min-ttl來驗證備份物件是否已被刪除。它應該會出現一個錯誤,說明該備份不再存在。相應的ambassador-backup-3min-ttl文件夾也將從DO Spaces Velero存儲桶中刪除。