













Apache Hadoop Distributed File System (HDFS) 的出現徹底改變了企業在數據存儲、處理和分析方面的做法,加速了大數據的增長,並為整個行業帶來了變革性的變化。
起初,Hadoop 整合了存儲與計算,但隨著雲計算的興起,這兩個組件開始分離。對象存儲作為 HDFS 的替代品出現,但存在局限性。為了彌補這些限制,JuiceFS,一個開源的高性能分布式文件系統,提供了計算、分析和訓練等數據密集型場景下的經濟高效解決方案。是否採用存儲計算分離的決策取決於可擴展性、性能、成本和兼容性等因素。
本文將回顧 Hadoop 架構,討論存儲計算解耦的重要性與可行性,並探討市場上現有的解決方案,突出它們各自的優缺點。我們的目標是為正在進行存儲計算分離架構轉型的企業提供洞察與啟示。
Hadoop 架構設計特點
Hadoop 作為一體化框架
2006 年,Hadoop 作為一體化框架發布,包含三個組件:
- MapReduce 用於計算
- YARN 用於資源調度
- HDFS 用於分布式文件存儲
 Core components of Hadoop
Core components of Hadoop多元計算組件
在這三個組件中,計算層經歷了快速的發展。最初只有MapReduce,但業界很快就見證了各種計算框架如Tez和Spark的出現,Hive用於數據倉儲,以及Presto和Impala等查詢引擎。與這些組件配合的還有眾多數據傳輸工具,如Sqoop。

HDFS主導存儲系統
在大約十年的時間裡,HDFS這一分布式文件系統一直是主導的存儲系統。它幾乎是所有計算組件的默認選擇。上述大數據生態系統內的所有組件都是為HDFS API設計的。有些組件深度利用了HDFS的特定能力。例如:
這些大數據組件基於HDFS API的設計選擇,為部署數據平台到雲端帶來了潛在的挑戰。
存儲-計算耦合架構
下圖展示了一部分簡化的HDFS架構,該架構將計算與存儲相結合。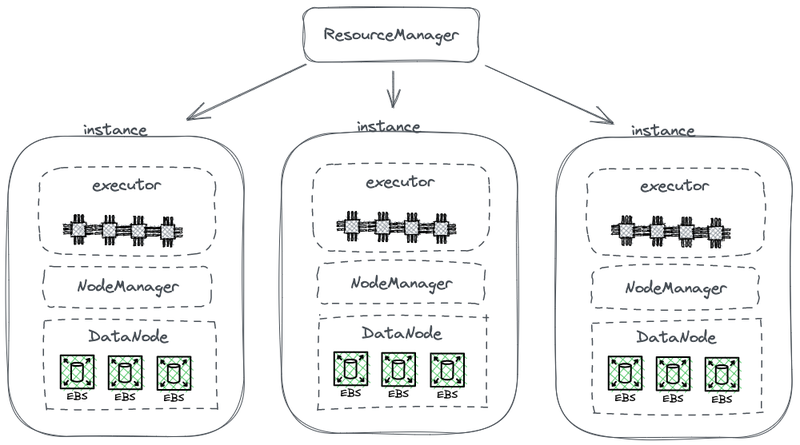
Hadoop存儲-計算耦合架構
在此圖中,每個節點作為HDFS DataNode用於存儲數據。此外,YARN在每個節點上部署一個Node Manager進程。這使得YARN能夠將該節點識別為其管理資源的一部分,用於計算任務。這種架構允許存儲和計算在同一台機器上共存,並且在計算過程中可以直接從硬盤讀取數據。
為何Hadoop要耦合存儲和計算
Hadoop耦合存儲和計算是因為在其設計階段受到網絡通信和硬件限制.
在2006年,雲計算尚處於起步階段,而Amazon剛剛發布其首項服務。在數據中心中,主流的網絡卡主要以100 Mbps的速度運行。用於大數據工作負載的數據磁盤達到了大約50 MB/s的吞吐量,相當於網絡帶寬的400 Mbps。
考慮到一個節點配備八塊硬碟並以最大容量運行,需要數個Gbps的網絡頻寬以實現高效數據傳輸。然而,網絡卡的最大容量僅限於1 Gbps。因此,每個節點的網絡頻寬不足以充分發揮節點內所有硬碟的潛力。結果,若計算任務位於網絡的一端,而數據存儲在另一端的数据節點上,網絡頻寬便成為了顯著的瓶頸。
為何需要存儲與計算解耦
從2006年至約2016年,企業面臨以下問題:
- 應用中對計算能力和存儲的需求不平衡,且其增長速度各異。雖然企業數據增長迅速,計算需求並未以同樣速度增長。這些由人類開發的任務並未在短時間內呈指數級增長。然而,這些任務產生的數據卻迅速積累,可能呈指數級增長。此外,某些數據可能對企業當前並無立即用途,但將來可能具有價值。因此,企業全面存儲數據以探索其潛在價值。
- 在規模擴張過程中,企業需同步擴大計算與存儲資源,常導致計算資源浪費。存儲-計算耦合架構的硬件拓撲影響了擴容能力。當存儲容量不足時,不僅需增加機器,還需升級CPU與內存,因耦合架構中的數據節點負責計算。因此,機器通常配備均衡的計算與存儲配置,提供充足的存儲容量及相當的計算能力。然而,實際計算需求並未如預期增長,導致擴大的計算能力對企業造成巨大浪費。
- 平衡計算與存儲、選擇合適機器成為挑戰。整個集群在存儲與I/O資源利用上可能極不平衡,且隨集群擴大,此不平衡加劇。此外,採購適當機器困難,機器須在計算與存儲需求間取得平衡。
- 因數據可能分布不均,難以有效調度數據所在實例的計算任務。數據局部性調度策略可能因數據分布不均而難以應對實際場景。例如,某些節點可能成為局部熱點,需更多計算能力。因此,即便大數據平台的任務被調度至這些熱點節點,I/O性能仍可能成為瓶頸。
為何解耦存儲與計算可行
2006至2016年間,硬體與軟體的進步,使得存儲與計算的分離成為可能。這些進步,包括:
網路卡
10 Gb網路卡的普及,以及數據中心和雲環境中20 Gb、40 Gb甚至50 Gb網路卡的日益增多。在AI場景中,100 GB的網路卡也被採用。這代表網路頻寬大幅提升超過100倍。
硬碟
許多企業在大數據集群中仍依賴基於硬碟的存儲解決方案。硬碟的吞吐量從50 MB/s翻倍至100 MB/s。配備10 GB網路卡的實例能支持約12個硬碟的峰值吞吐量,足以滿足大多數企業需求,從而網路傳輸不再是瓶頸。
軟體
採用如Snappy、LZ4、Zstandard等高效壓縮算法,以及Avro、Parquet、Orc等列式存儲格式,進一步緩解了I/O壓力。大數據處理的瓶頸已從I/O轉移至CPU性能。
如何實現存儲-計算分離
初步嘗試:獨立部署HDFS至雲端
HDFS的獨立部署
自2013年起,業界開始嘗試將存儲與計算分離。最初的方法相當直接,即獨立部署HDFS而不與計算節點整合。此方案並未為Hadoop生態系統引入新的組件。
如圖所示,NodeManager不再部署於DataNodes上,意味著計算任務不再派送至DataNodes。存儲形成獨立的集群,計算所需數據通過端到端10 Gb網卡在網絡上傳輸(注意,圖中未標記網絡傳輸線路)。

雖然此方案捨棄了HDFS最具巧思的數據本地性設計,但網絡通信速度的提升大大簡化了集群配置。這一點由Davies,Juicedata的聯合創始人及其在Facebook 2013年的團隊成員進行的實驗所證實。結果確認了計算節點獨立部署與管理的可行性。
然而,這一嘗試並未進一步發展。主要原因在於將HDFS部署至雲端的挑戰。
部署HDFS至雲端的挑戰
將HDFS部署至雲端面臨以下問題:
- HDFS多副本機制增加企業雲端成本:過去企業使用裸磁盤在自家數據中心搭建HDFS系統。為降低磁盤損壞風險,HDFS採用多副本機制確保數據安全與可用性。然而,當數據遷移至雲端時,雲服務商提供的雲磁盤已內置多副本機制。因此,企業在雲端需將數據複製三次,導致成本顯著增加。
- 裸磁盤部署選擇有限:雖然雲服務商提供部分帶有裸磁盤的機型,但選擇有限。例如,在100種雲端虛擬機型中,僅有5-10種支持裸磁盤。這有限的選擇可能無法滿足企業集群的特定需求。
- 無法利用雲端獨特優勢:將HDFS部署至雲端需手動創建機器、部署、維護、監控及運營,無法享受彈性擴縮和按需付費模式帶來的便利。這些正是雲計算的關鍵優勢。因此,在雲端實現HDFS存儲與計算分離並非易事。
HDFS局限性
HDFS本身存在以下局限:
- NameNodes擴展性有限:HDFS中的NameNodes僅能垂直擴展,無法進行分布式擴展。這一限制對單一HDFS集群可管理的文件數量造成了制約。
- 儲存超過5億文件帶來高運營成本:根據我們的經驗,一般而言,操作和維護少於3億文件的HDFS是相對容易的。當文件數量超過5億時,需要實施HDFS Federation機制。然而,這引入了高昂的運營和管理成本。
- 高資源使用和NameNode重負載影響HDFS集群可用性:當NameNode占用過多資源且負載高時,可能觸發完整的垃圾回收(GC)。這影響了整個HDFS集群的可用性。系統存儲可能遭遇停機,無法讀取數據,且無法介入GC過程。系統凍結的持續時間無法確定。這在高負載的HDFS集群中一直是一個持續的問題。
公有雲 + 對象存儲
隨著雲計算的進步,企業現在可以選擇使用對象存儲作為HDFS的替代方案。對象存儲專為存儲大規模非結構化數據設計,提供了一種便於數據上傳和下載的架構。它提供了高度可擴展的存儲容量,確保成本效益。
對象存儲作為HDFS替代方案的優勢
對象存儲已經獲得認可,從AWS開始,隨後被其他雲服務提供商採用作為HDFS的替代方案。以下是一些顯著的優勢:
- 服務導向且即開即用:對象存儲無需部署、監控或維護任務,提供了一個方便且用戶友好的體驗。
- 彈性擴展與按需付費:企業根據實際使用量支付對象存儲費用,無需進行容量規劃。他們可以創建一個對象存儲桶,並存儲所需數量的數據,不必擔心存儲容量限制。
對象存儲的缺點
然而,當使用對象存儲來支持像Hadoop這樣的複雜數據系統時,會出現以下挑戰:
缺點 #1:文件列舉性能不佳
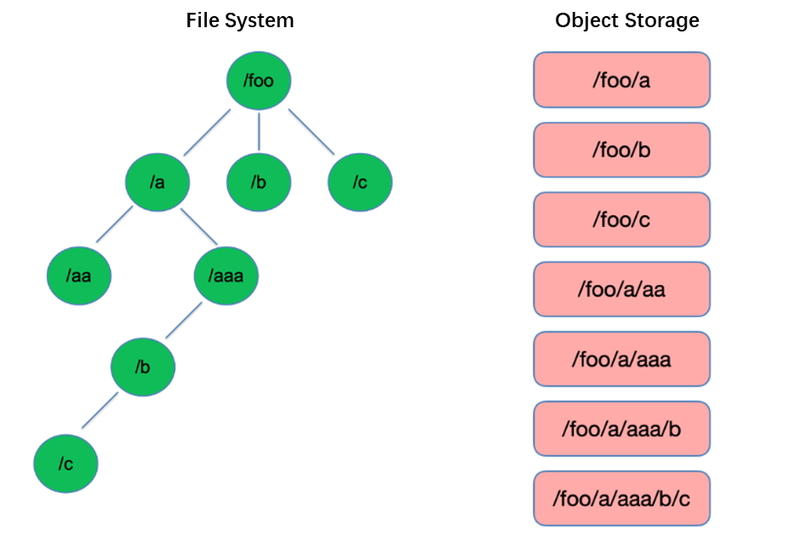
列舉是文件系統中最基本的操作之一。在HDFS這樣的樹狀結構中,它既輕量又快速。
相比之下,對象存儲採用扁平結構,需要使用鍵(唯一標識符)來存儲和檢索成千上萬甚至數十億的對象。因此,在執行列舉操作時,對象存儲只能在此索引內搜索,導致其性能遠不如樹狀結構。
缺點 #2:缺乏原子重命名能力,影響任務性能與穩定性
在提取、轉換、加載(ETL)計算模型中,每個子任務將其結果寫入臨時目錄。當整個任務完成後,可以將臨時目錄重命名為最終目錄名稱。
這些重命名操作在HDFS等檔案系統中是原子且快速的,並保證交易完整性。然而,由於物件儲存沒有原生的目錄結構,處理重命名操作是一個模擬過程,涉及大量的內部資料複製。此過程可能耗時且不提供交易保證。
當用戶使用物件儲存時,他們通常使用傳統檔案系統的路徑格式作為物件的鍵,例如 “/order/2-22/8/10/detail”。在重命名操作中,需要搜尋所有其鍵包含目錄名的物件,並使用新的目錄名作為鍵來複製所有物件。此過程涉及資料複製,導致性能顯著低於檔案系統,可能慢上一到兩個數量級。
此外,由於缺乏交易保證,過程中存在失敗風險,可能導致資料錯誤。這些看似微小的差異對整個任務管道的性能和穩定性有影響。
缺點#3:最終一致性機制影響資料正確性和任務穩定性
例如,當多個客戶端同時在一個路徑下創建檔案時,通過List API獲得的檔案列表可能不會立即包含所有創建的檔案。物件儲存的內部系統需要時間來達成資料一致性。這種存取模式常用於ETL資料處理,最終一致性可能影響資料正確性和任務穩定性。
為解決物件儲存無法保持強資料一致性的問題,AWS推出了EMRFS這一產品。其做法是利用額外的DynamoDB資料庫。例如,當Spark寫入檔案時,同時也將檔案清單的副本寫入DynamoDB。隨後建立一種機制,持續呼叫物件儲存的List API,並將取得的結果與資料庫中儲存的結果進行比對,直到兩者一致,才返回結果。然而,此機制的穩定性並不理想,因其易受物件儲存所在區域負載的影響,導致效能不穩定,因此並非完美解決方案。
缺點#4:與Hadoop元件的相容性有限
HDFS曾是Hadoop生態系統初期主要的儲存選擇,各種元件均基於HDFS API開發。物件儲存的引入改變了資料儲存結構及API。
雲端供應商需修改元件與雲端物件儲存之間的連接器,並對上層元件進行修補以確保相容性。此任務對公共雲供應商而言負擔重大。
因此,公共雲供應商提供的大數據平台所支援的計算元件數量有限,通常僅包括幾個版本的Spark、Hive及Presto。此限制對遷移大數據平台至雲端或對自有分發及元件有特定需求的使用者構成挑戰。
為了充分利用物件儲存的強大效能,同時保留檔案系統的可靠性,企業可以採用物件儲存 + JuiceFS的組合。
物件儲存 + JuiceFS
當用戶需要在物件儲存上進行複雜的數據計算、分析和訓練時,單純的物件儲存可能無法完全滿足企業的需求。這正是Juicedata開發JuiceFS的關鍵動機,旨在補充物件儲存的局限性。
JuiceFS是一個開源的高性能分散式檔案系統,專為雲環境設計。結合物件儲存,JuiceFS為計算、分析和訓練等數據密集型場景提供了經濟高效的解決方案。
JuiceFS + 物件儲存的工作原理
下圖展示了JuiceFS在Hadoop集群中的部署情況。
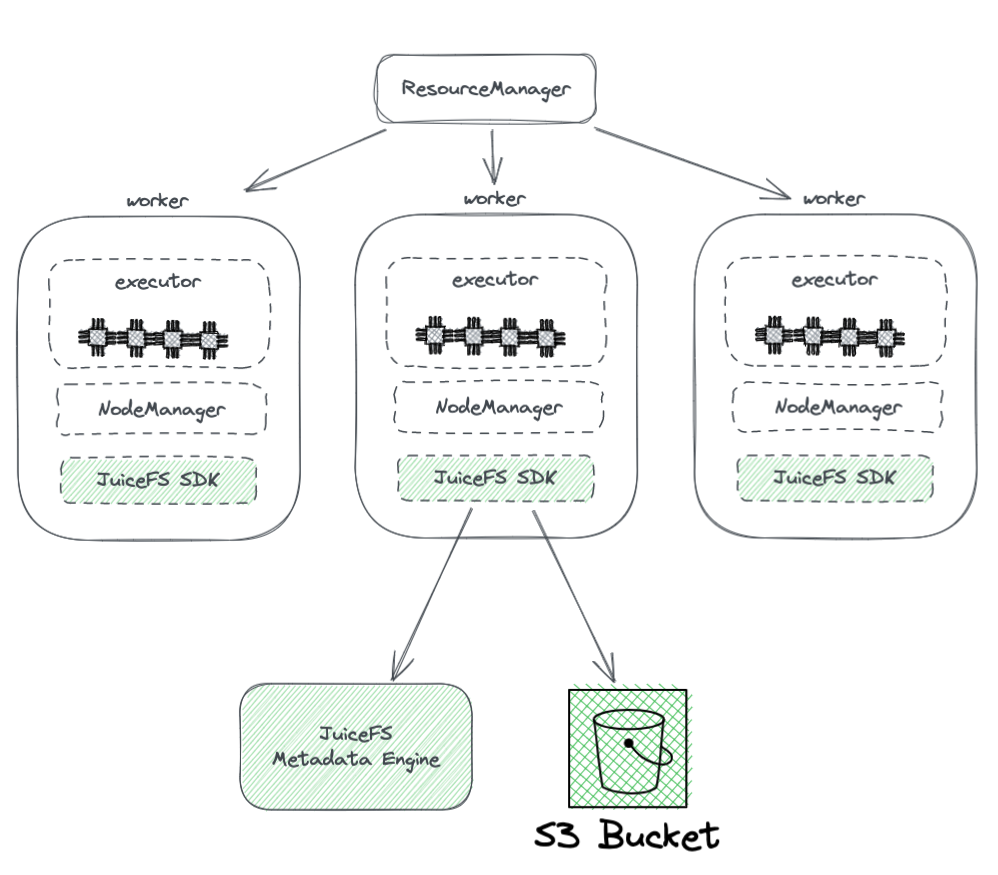
從圖中我們可以看到以下內容:
- 所有由YARN管理的worker節點都搭載了JuiceFS Hadoop SDK,這可以確保與HDFS的完全兼容性。
- SDK 存取兩個元件:
-
JuiceFS 元資料引擎:此元資料引擎相當於 HDFS 的 NameNode,負責儲存整個檔案系統的元資料,包括目錄數量、檔案名稱、權限及時間戳記,並解決 HDFS NameNode 面臨的可擴展性及 GC 挑戰。
-
S3 儲存桶:資料儲存於 S3 儲存桶中,可視為 HDFS 的 DataNode 的對應。它可作為大量磁碟使用,管理資料儲存及複製任務。
-
-
JuiceFS 包含三個元件:
- JuiceFS Hadoop SDK
- 元資料引擎
- S3 儲存桶
JuiceFS相較於直接使用物件儲存的優勢
JuiceFS相比直接使用物件儲存具有多項優勢:
- 完全兼容HDFS:這一點透過JuiceFS最初設計全面支援POSIX實現。POSIX API的覆蓋範圍和複雜性均超過HDFS。
- 能夠與現有的HDFS和物件儲存並用:得益於Hadoop系統的設計,JuiceFS可以在無需完全替換的情況下與現有的HDFS和物件儲存系統並用。在Hadoop集群中,可以配置多個檔案系統,允許JuiceFS與HDFS共存並協作。此架構消除了對現有HDFS集群進行全面替換的需求,後者涉及大量工作和風險。用戶可根據應用需求和集群情況逐步整合JuiceFS。
- 強大的元數據效能:JuiceFS將元數據引擎與S3分離,不再依賴S3的元數據效能,確保了最佳的元數據效能。使用JuiceFS時,與底層物件儲存的互動簡化為Get、Put和Delete等基本操作。此架構克服了物件儲存元數據的效能限制,並消除了與最終一致性相關的問題。
- 支援原子性重新命名:由於JuiceFS擁有獨立的元數據引擎,因此支援原子性的重新命名操作。透過快取機制提升熱數據的存取效能並提供數據本地化特性:有了快取,熱數據無需每次都透過網路從物件儲存中提取。此外,JuiceFS實現了HDFS特有的數據本地化API,使得所有支援數據本地化的上層組件能夠重新獲得數據親和性的感知。這讓YARN能夠優先在已建立快取的節點上調度任務,從而達到與存儲計算一體化HDFS相媲美的整體效能。
- JuiceFS與POSIX相容,便於整合機器學習及AI相關應用。
結論
隨著企業需求演進與技術進步,存儲與計算的架構已從一體化轉向分離。
實現存儲與計算分離有多種途徑,各有優劣。從部署HDFS到雲端,到利用與Hadoop相容的公有雲解決方案,乃至採用物件儲存+JuiceFS等適用於雲端複雜大數據計算與儲存的方案。
對企業而言,並無萬全之策,關鍵在於根據自身特定需求選擇架構。然而,無論選擇何種方案,簡潔性始終是穩妥之選。
關於作者
Rui Su,作為Juicedata的合夥人,自2017年起便以創始成員的身份深度參與JuiceFS產品的全面開發、市場推廣及開源社群建設。擁有16年業界經驗的他,在軟件、互聯網及非政府組織領域擔任過研發、產品經理及創始人等多重角色。
Source:
https://dzone.com/articles/from-hadoop-to-cloud-why-and-how-to-decouple-stora