













日誌通常佔據公司數據資產的大部分。日誌的例子包括業務日誌(如用戶活動日誌)以及服務器、數據庫、網絡或物聯網設備的運維日誌。
日誌是業務的守護天使。一方面,它們提供系統風險警報,並幫助工程師在故障排除中快速定位根本原因。另一方面,如果通過時間範圍將其縮小,你可能會識別出一些有幫助的趨勢和模式,更不用說業務日誌是用戶洞察的基石。
然而,日誌可能會讓人手忙腳亂,因為:
- 它們如洪水般湧入。每個系統事件或用戶點擊都會生成一條日誌。一家公司每天通常會產生數百億條新日誌。
- 它們體積龐大。日誌本應保留。它們可能直到需要時才有用。因此,一家公司可以積累高達PB級的日誌數據,其中許多很少被訪問,但佔用了巨大的存儲空間。
- 它們必須快速加載和查找。在故障排除中定位目標日誌,簡直就像大海撈針。人們渴望實時的日誌寫入和對日誌查詢的實時響應。
現在你可以清楚地看到一個理想的日誌處理系統應該是什麼樣子。它應該支持以下功能:
- 高吞吐量的實時數據攝入:它應該能夠批量寫入日誌並使其立即可見。
- 低成本存儲:它應該能夠存儲大量的日誌,而不會消耗太多資源。
- 即時文字搜尋:應具備快速文字搜尋能力。
常見解決方案:Elasticsearch 與 Grafana Loki
業界存在兩種常見的日誌處理解決方案,分別以 Elasticsearch 和 Grafana Loki 為代表。
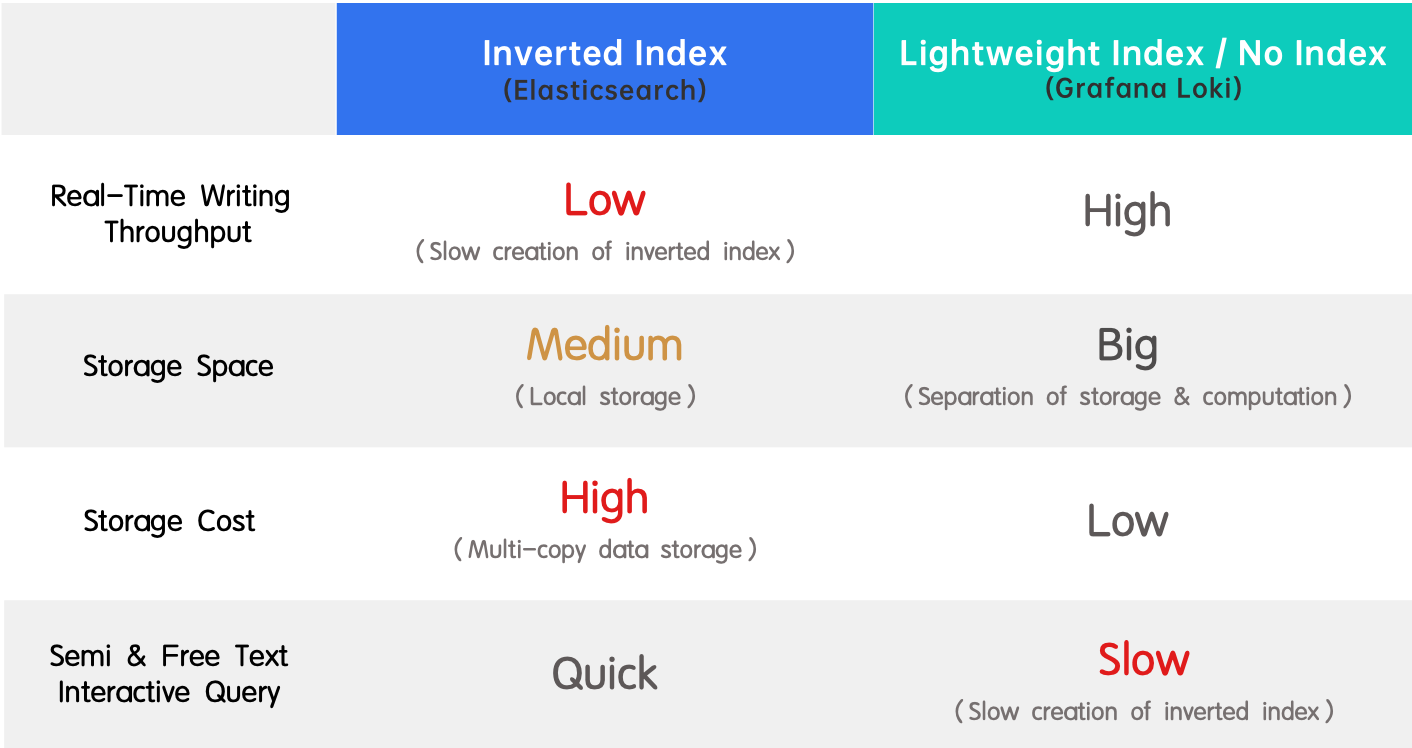
- 倒排索引(Elasticsearch):因其支援全文搜尋及高效能而廣受歡迎。缺點是即時寫入吞吐量低,且索引建立時資源消耗巨大。
- 輕量級索引 / 無索引(Grafana Loki):與倒排索引相反,它具有高即時寫入吞吐量及低儲存成本,但查詢速度較慢。
倒排索引簡介
A prominent strength of Elasticsearch in log processing is quick keyword search among a sea of logs. This is enabled by inverted indexes.
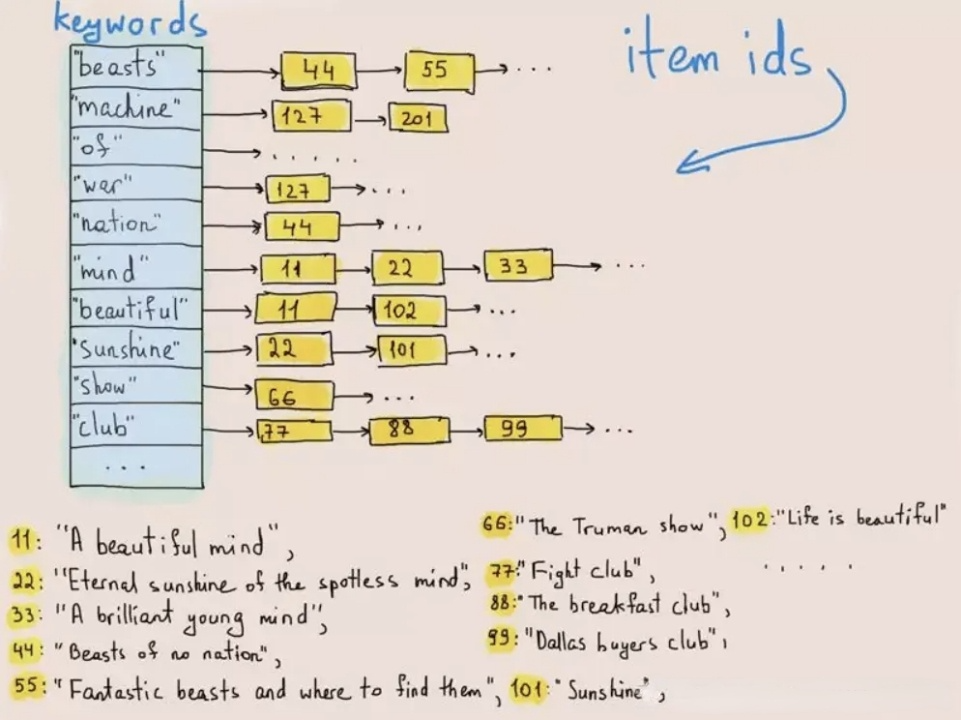
倒排索引原本用於檢索文本中的單詞或片語。下圖說明其運作方式:
在資料寫入時,系統將文本切分為詞項,並將這些詞項儲存於倒排表中,該表將詞項映射至其所在行的ID。進行文本查詢時,資料庫在倒排表中找到關鍵字(詞項)對應的行ID,並根據行ID提取目標行。如此一來,系統無需遍歷整個資料集,從而大幅提升查詢速度。
在Elasticsearch的倒排索引機制中,雖然快速檢索得益,但卻以寫入速度、寫入吞吐量及存儲空間為代價。原因何在?首先,分詞、字典排序及倒排索引的建立均屬於CPU與記憶體密集型操作。其次,Elasticsearch需保存原始數據、倒排索引,以及為加速查詢而額外存儲的列式數據副本,這無疑是三重冗餘。
然而,若無倒排索引,如Grafana Loki,則因其查詢緩慢嚴重影響用戶體驗,成為工程師進行日誌分析時的最大痛點。
簡言之,Elasticsearch與Grafana Loki體現了高寫入吞吐量、低存儲成本與快速查詢性能之間的不同權衡。若我告訴你有一種方法能兼顧三者,又將如何?我們已在Apache Doris 2.0.0中引入倒排索引,並進一步優化以實現相比Elasticsearch,查詢速度提升兩倍,而存儲空間僅需其五分之一。兩者相較,這無疑是十倍優勢的解決方案。
Apache Doris中的倒排索引
一般而言,實現索引有兩種途徑:外部索引系統或內置索引。
外部索引系統:您將一個外部索引系統連接到您的資料庫。在資料攝取過程中,資料被導入到兩個系統中。索引系統建立索引後,會在其內部刪除原始資料。當資料使用者輸入查詢時,索引系統提供相關資料的ID,然後資料庫根據這些ID查找目標資料。
建立外部索引系統較為簡單且對資料庫的侵入性較小,但伴隨著一些令人困擾的缺陷:
- 需要將資料寫入兩個系統可能導致資料不一致和存儲冗餘。
- 資料庫與索引系統之間的交互帶來了額外的開銷,因此當目標資料量巨大時,跨兩個系統的查詢可能會變慢。
- 維護兩個系統是相當耗時的。
在Apache Doris中,我們選擇了另一種方式。內建的倒排索引製作起來更為困難,但一旦完成,它將更快、更用戶友好且維護無憂。
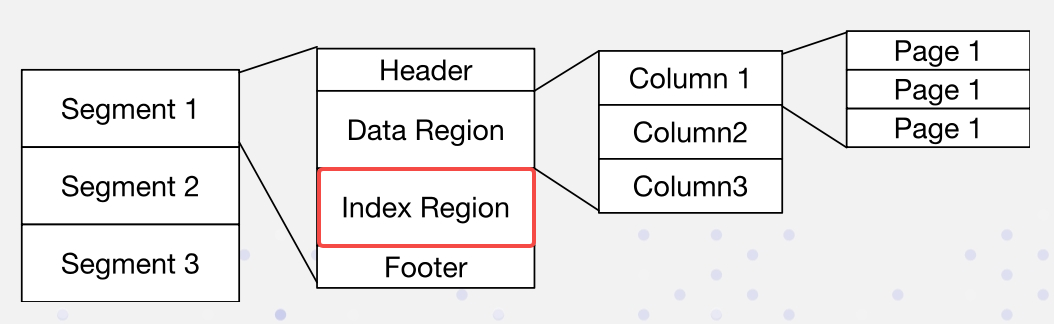
在Apache Doris中,資料以下列格式排列。索引存儲在索引區域:
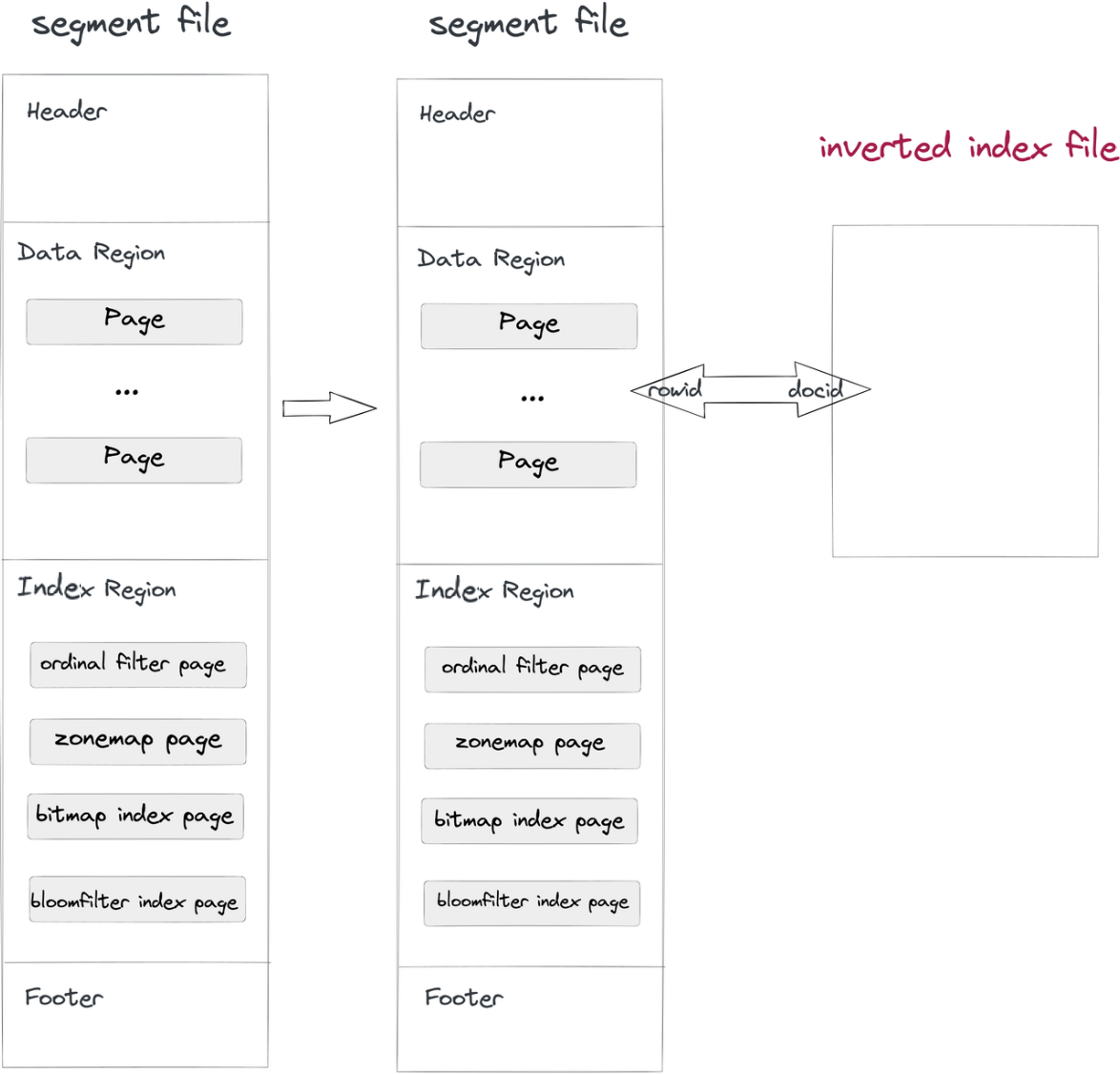
我們以非侵入性的方式實現倒排索引:
- 資料攝取與合併:當一個段文件被寫入Doris時,也會寫入一個倒排索引文件。索引文件的路徑由段ID和索引ID決定。段中的行對應於索引中的文檔,因此RowID和DocID也是如此。
- 查詢:若
WHERE子句中包含具有倒排索引的欄位,系統將在索引檔案中查找,返回一個DocID列表,並將該DocID列表轉換為RowID Bitmap。在Apache Doris的RowID過濾機制下,僅目標行會被讀取,從而加速查詢。
此種非侵入式方法將索引檔案與數據檔案區隔開來,您可以隨意修改倒排索引,無需擔心影響數據檔案本身或其他索引。
倒排索引優化
通用優化
C++ Implementation and Vectorization
與使用Java的Elasticsearch不同,Apache Doris在其存儲模塊、查詢執行引擎及倒排索引中採用C++,相較於Java,C++性能更佳,更易於向量化,且無JVM GC開銷。我們已在Apache Doris中向量化了倒排索引的每個步驟,如分詞、索引建立及查詢。舉例而言,在倒排索引中,Apache Doris每核心寫入數據速度達20MB/s,是Elasticsearch(5MB/s)的四倍。
列式存儲與壓縮
Apache Lucene為Elasticsearch中的倒排索引奠定基礎。由於Lucene本質上支持文件存儲,因此數據以行式格式存儲。
在Apache Doris中,不同列的倒排索引相互隔離,倒排索引文件採用列式存儲,便於向量化及數據壓縮。
透過採用Zstandard壓縮技術,Apache Doris實現了從5:1至10:1的壓縮比率,壓縮速度更快,且相比GZIP壓縮節省了50%的空間使用。
數值/日期時間欄位的BKD樹
Apache Doris針對數值和日期時間欄位實施了BKD樹結構。此舉不僅提升了範圍查詢的效能,而且相比將這些欄位轉換為固定長度字串的方式更為節省空間。其優勢還包括:
- 高效的範圍查詢:能夠迅速定位數值和日期時間欄位中的目標數據範圍。
- 減少儲存空間:通過聚合和壓縮相鄰數據塊,降低了儲存成本。
- 支援多維數據:BKD樹具有可擴展性和適應性,能夠處理GEO點和範圍等多元數據類型。
除了BKD樹外,我們還對數值和日期時間欄位的查詢進行了進一步優化。
- 低基數場景的優化:針對低基數場景,我們細調了壓縮算法,使得解壓縮和反序列化大量倒排索引時消耗的CPU資源更少。
- 預取機制:在高命中率場景下,我們採用了預取策略。當命中率超過特定閾值時,Doris將跳過索引過程,直接進行數據過濾。
針對OLAP的定制優化
通常,日誌分析是一種簡單的查詢,無需高級功能(例如Apache Lucene中的相關性評分)。日誌處理工具的核心能力在於快速查詢和低存儲成本。因此,在Apache Doris中,我們優化了倒排索引結構以滿足OLAP數據庫的需求。
- 在數據攝入過程中,我們防止多個線程向同一索引寫入數據,從而避免了鎖競爭帶來的開銷。
- 我們棄用了正向索引文件和Norm文件,以清理存儲空間並減少I/O開銷。
- 我們簡化了相關性評分和排名的計算邏輯,進一步降低開銷並提升性能。
鑒於日誌按時間範圍分區且歷史日誌訪問頻率較低,我們計劃在未來版本的Apache Doris中提供更細粒度和靈活的索引管理:
- 為指定數據分區創建倒排索引:例如,為過去七天的日誌創建索引。
- 刪除指定數據分區的倒排索引:例如,刪除超過一個月前的日誌索引(以便清理索引空間)。
基準測試
我們在公開可用的數據集上對Apache Doris、Elasticsearch和ClickHouse進行了測試。
為了公平比較,我們確保測試條件的一致性,包括基準測試工具、數據集和硬件。
Apache Doris對比Elasticsearch
- 基準測試工具:ES Rally,Elasticsearch官方測試工具
- 數據集:1998年世界盃HTTP伺服器日誌(ES Rally內置的獨立數據集)
- 數據大小(壓縮前):32G,2億4700萬行,每行平均134字節
- 查詢:11種查詢,包括關鍵字搜索、範圍查詢、聚合和排序;每種查詢連續執行100次。
- 環境:3台16核64GB雲虛擬機
Apache Doris的測試結果:
- 寫入速度:550 MB/s,是Elasticsearch的4.2倍
- 壓縮比:10:1
- 存儲使用量:僅為Elasticsearch的20%
- 響應時間:僅為Elasticsearch的43%

Apache Doris對比ClickHouse
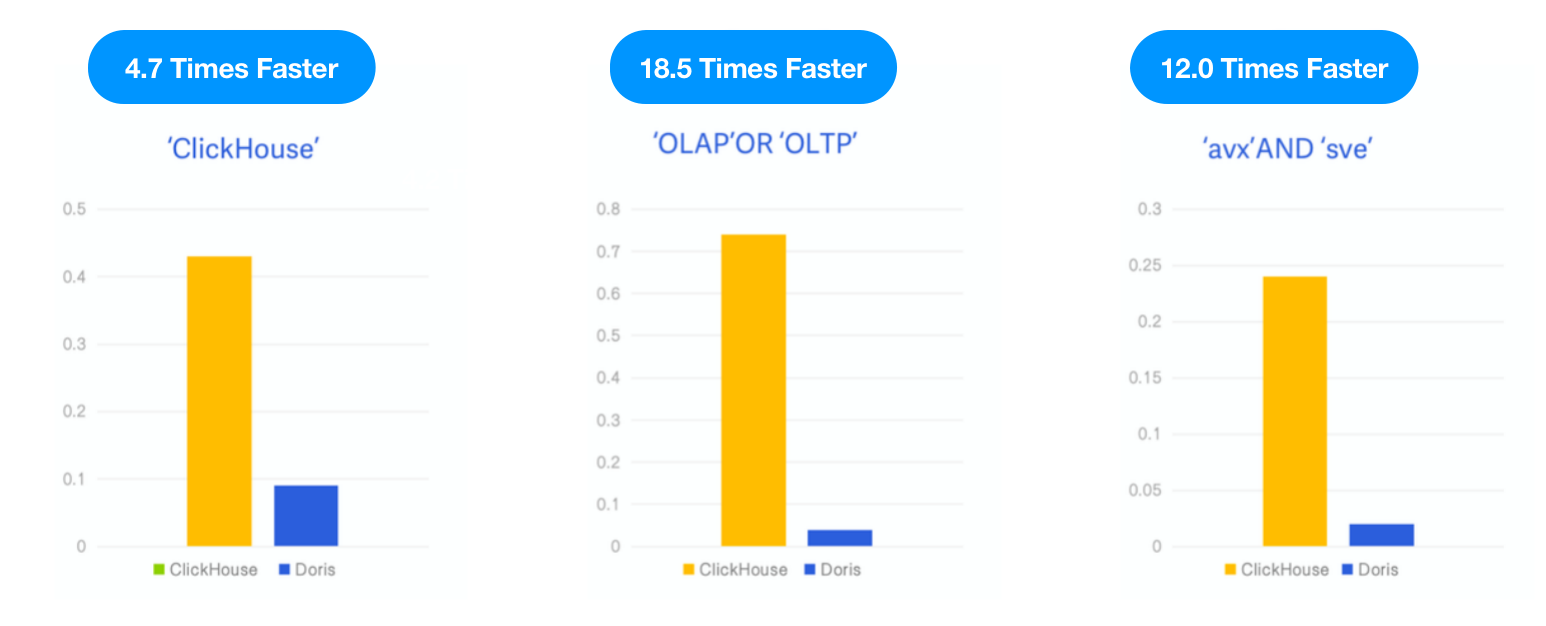
由於ClickHouse在v23.1版本中推出了倒排索引作為實驗性功能,我們使用相同的數據集和SQL對Apache Doris進行了測試,並在相同的測試資源、案例和工具下比較了兩者的性能。博客
- 數據:6.7G,2873萬行,Hacker News數據集,Parquet格式
- 查詢:3種關鍵字搜索,計算關鍵字”ClickHouse”、”OLAP”或”OLTP”以及”avx”和”sve”的出現次數。
- 環境:1台16核64GB雲虛擬機
結果: Apache Doris 在三個查詢中分別比 ClickHouse 快 4.7倍、18.5倍和12倍。
使用方法與範例
- 數據集: 來自 Hacker News 的一百萬條評論記錄
步驟1: 在創建表時指定反向索引至數據表。
參數:
- INDEX idx_comment (
comment): 為 “comment” 欄位創建名為 “idx_comment” 的索引 - USING INVERTED: 指定表的反向索引
- PROPERTIES(“parser” = “english”): 指定斷詞語言為英語
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");(注意:您可以通過 ADD INDEX idx_comment ON hackernews_1m(comment) USING INVERTED PROPERTIES("parser" = "english") 向現有表添加索引。與智能索引和二級索引不同,反向索引的創建僅涉及讀取評論欄位,因此可以快得多。)
步驟2: 使用 MATCH_ALL 在評論欄位中檢索 “OLAP” 和 “OLTP” 這兩個詞。此處的響應時間僅為硬匹配 like 的十分之一。(隨著數據量的增加,性能差距會擴大。)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.13 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)
更多功能介紹及使用指南,請參閱文檔:反向索引
總結
總而言之,Apache Doris之所以能提供比Elasticsearch高出十倍的性價比,主要歸功於其針對OLAP優化的倒排索引技術,這得益於列式存儲引擎、大規模並行處理框架、向量化查詢引擎及成本型優化器等Apache Doris的核心技術。
雖然我們對自家倒排索引方案感到自豪,但鑒於自發布的基準測試可能存在爭議,我們樂於接受反饋來自第三方測試者的意見,並觀察Apache Doris在實際案例中的表現。
Source:
https://dzone.com/articles/building-a-log-analytics-solution-10-times-more-co