













這是地產巨頭數位轉型的一部分。為了保密,我不會透露任何業務數據,但您將會詳細了解我們的數據倉庫及其優化策略。
現在讓我們開始吧。
架構
從邏輯上,我們的數據架構可分為四個部分。
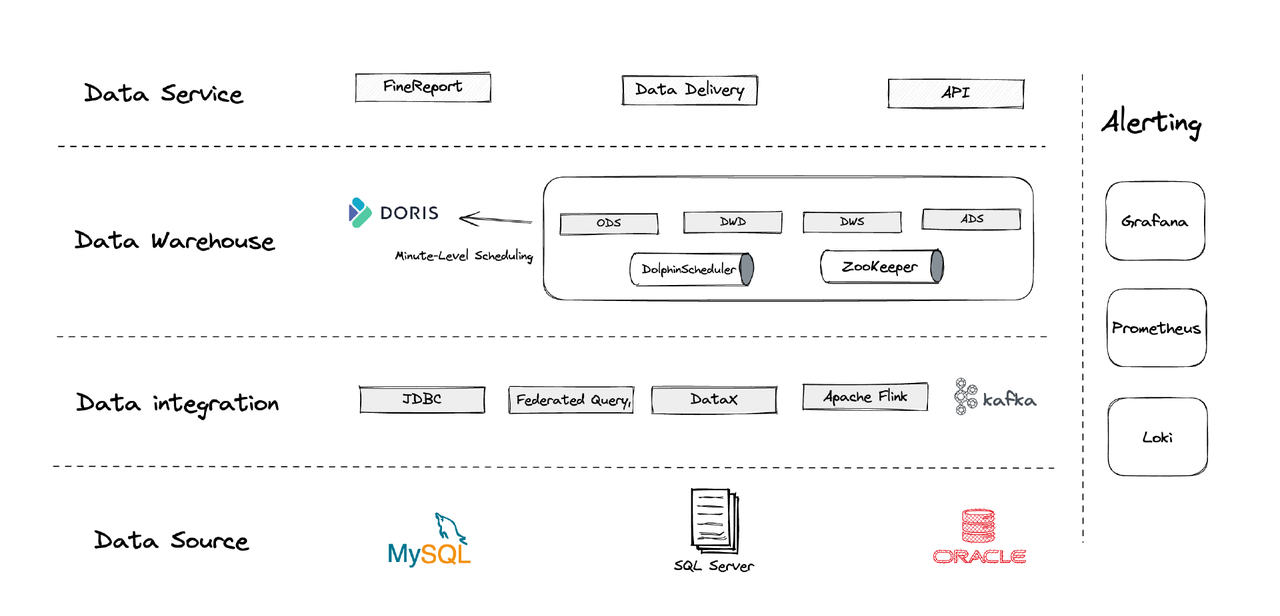
- 數據整合:這部分由Flink CDC、DataX及Apache Doris的Multi-Catalog特性支持。
- 數據管理:我們使用Apache Dolphinscheduler進行腳本生命周期管理、多租戶管理權限及數據質量監控。
- 警報系統:我們利用Grafana、Prometheus和Loki監控組件資源及日誌。
- 數據服務:此處BI工具介入用戶互動,如數據查詢與分析。
1. 表格
我們圍繞每個業務運營實體(包括客戶、房屋等)建立維度表與事實表。若一系列活動涉及同一運營實體,應由一個字段記錄。(這是從我們之前混亂的數據管理系統中吸取的教訓。)
2. 層級
我們的數據倉庫分為五個概念層。我們使用Apache Doris和Apache DolphinScheduler來調度這些層級間的DAG腳本。

每日除了增量更新外,還會進行全面更新,以防歷史狀態欄位變動或ODS表數據同步不完全。
3. 增量更新策略
(1) 設定 where >= "活動時間 -1天或-1小時" 而非where >= "活動時間"
此舉是為了避免因排程腳本的時間間隔導致的數據漂移。假設腳本執行間隔設為10分鐘,若腳本於23:58:00執行,而新數據於23:59:00到達。若設置where >= "活動時間",則當日該筆數據將被遺漏。
(2) 每次腳本執行前,提取表中最大主鍵ID,將ID存入輔助表,並設定where >= "輔助表中的ID"
這是為了避免數據重複。使用Apache Doris的Unique Key模型並指定一組主鍵時,若源表的主鍵有任何變動,變動將被記錄並加載相關數據,可能導致數據重複。此方法能解決此問題,但僅適用於源表具有自增主鍵的情況。
(3) 對表進行分區
對於如日誌表這類基於時間的自動增長數據,歷史數據及狀態變化可能較少,但數據量龐大,因此在整體更新和快照創建上可能會面臨巨大的計算壓力。因此,對這類表進行分區更為合適,這樣每次增量更新時,只需替換一個分區即可。(同時也要注意數據漂移的問題。)
4. 整體更新策略
(1) 截斷表
清空表後,再從源表導入所有數據。此方法適用於小型表及深夜無用戶活動的場景。
(2) ALTER TABLE tbl1 REPLACE WITH TABLE tbl2
這是一個原子操作,對於大型表來說是個好選擇。每次執行腳本前,我們會創建一個具有相同結構的臨時表,將所有數據加載進去,然後用它替換原表。
應用
- ETL 任務:每分鐘執行一次
- 首次部署配置:8 節點,2 前端,8 後端,混合部署
- 節點配置:32核心 * 60GB * 2TB SSD
這是我們處理 TB 級歷史數據及 GB 級增量數據的配置。您可以此為參考,在此基礎上擴展您的集群。Apache Doris 的部署簡單,無需其他組件。
1. 為整合離線數據與日誌數據,我們採用DataX,該工具支援CSV格式及多種關聯式資料庫的讀取器,並由Apache Doris提供DataX-Doris-Writer。

2. 我們使用Flink CDC來同步源表數據,並利用Apache Doris的物化視圖或聚合模型來匯總即時指標。由於只需即時處理部分指標,且不希望產生過多資料庫連接,我們使用單一Flink作業來維護多個CDC源表。此功能可透過Dinky的多源合併及全資料庫同步特性實現,或自行建立Flink DataStream的多源合併任務。值得注意的是,Flink CDC與Apache Doris均支援模式變更。
EXECUTE CDCSOURCE demo_doris WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '10000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'ods.ods_*,ods.ods_*',
'sink.connector' = 'doris',
'sink.fenodes' = '127.0.0.1:8030',
'sink.username' = 'root',
'sink.password' = '123456',
'sink.doris.batch.size' = '1000',
'sink.sink.max-retries' = '1',
'sink.sink.batch.interval' = '60000',
'sink.sink.db' = 'test',
'sink.sink.properties.format' ='json',
'sink.sink.properties.read_json_by_line' ='true',
'sink.table.identifier' = '${schemaName}.${tableName}',
'sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
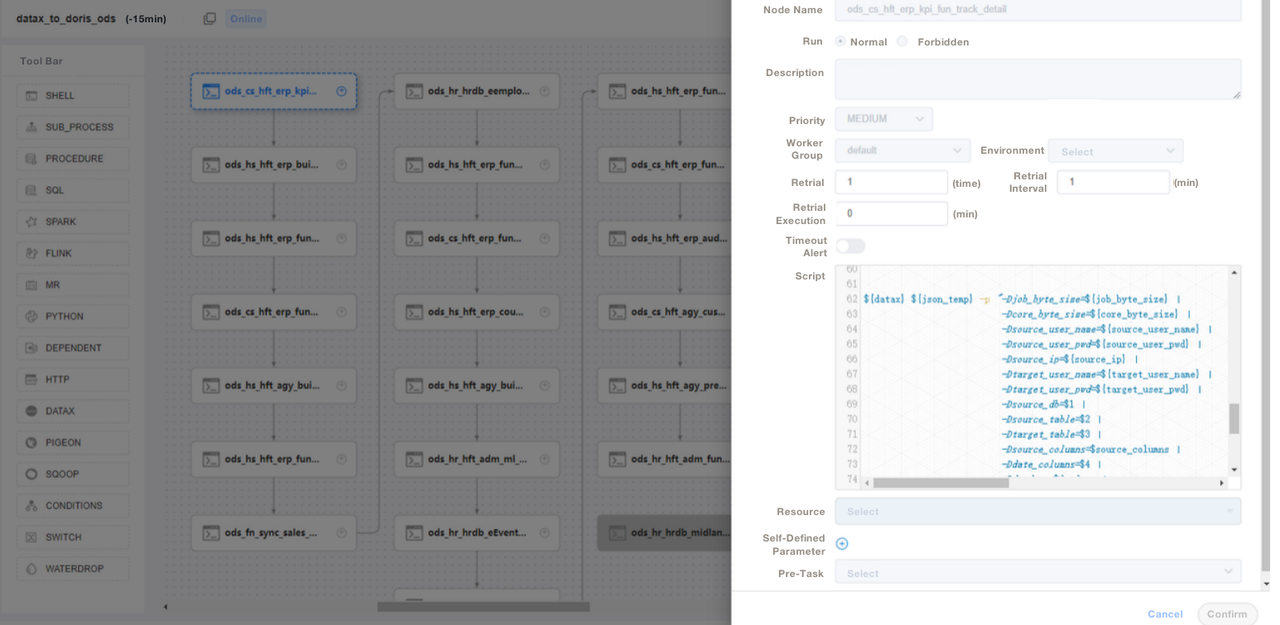
);3. 我們運用SQL腳本或”Shell + SQL”腳本,並進行腳本生命週期管理。在ODS層,我們撰寫一個通用的DataX作業檔案,並針對每個源表傳遞參數進行數據導入,而非為每個源表單獨編寫DataX作業,從而大幅簡化維護工作。我們在DolphinScheduler上管理Apache Doris的ETL腳本,並實施版本控制。若生產環境中出現錯誤,可隨時回滾。
4. 在通過ETL腳本導入數據後,我們在報表工具中建立頁面,並透過SQL為不同帳戶分配不同權限,包括修改行、欄位及全域字典的權限。Apache Doris支援帳戶權限控制,其運作方式與MySQL相同。
我們亦運用Apache Doris資料備份進行災難復原,透過Apache Doris審計日誌監控SQL執行效率,以Grafana+Loki設定集群指標警報,並利用Supervisor監控節點組件的守護進程。
優化
數據攝入
我們採用DataX進行離線數據的Stream Load。此方式允許我們調整每批次的大小。Stream Load方法同步返回結果,符合我們架構需求。若透過DolphinScheduler執行異步數據導入,系統可能誤判腳本已執行,進而造成混亂。若使用其他方法,建議在shell腳本中執行show load,並檢查正則過濾狀態以確認攝入是否成功。
數據模型
我們大多數表採用Apache Doris的Unique Key模型。Unique Key模型確保數據腳本的冪等性,有效避免上游數據重複。
讀取外部數據
我們利用Apache Doris的Multi-Catalog功能連接外部數據源。此功能允許我們在Catalog層級建立外部數據映射。
查詢優化
建議將非字符類型(如int與where子句)中最常用的字段置於前36字節,以便在點查詢中於毫秒內過濾這些字段。
數據字典
對我們而言,建立資料字典至關重要,因為它能大幅降低人員溝通成本,尤其在團隊規模龐大時,這往往是令人頭痛的問題。我們利用Apache Doris中的information_schema來生成資料字典。有了它,我們能迅速掌握表格與欄位的全貌,進而提升開發效率。
效能
離線數據導入時間:數分鐘內完成
查詢延遲:對於包含超過一億筆記錄的表格,Apache Doris能在1秒內回應即席查詢,複雜查詢則在5秒內完成。
資源消耗:僅需少量伺服器即可搭建此數據倉庫。Apache Doris高達70%的壓縮比為我們節省了大量儲存資源。
經驗與結論
實際上,在我們演變至目前的數據架構前,曾嘗試使用Hive、Spark及Hadoop來建立離線數據倉庫。結果顯示,對於我們這樣的傳統企業,Hadoop過於龐大,因為我們並無太多數據需處理。找到最適合自己的組件至關重要。
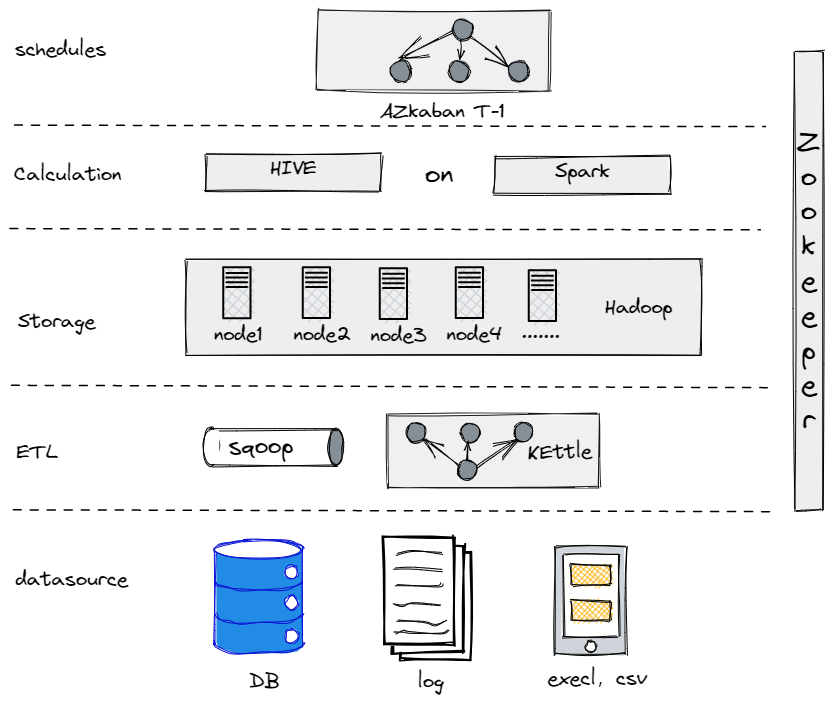
我們舊有的離線數據倉庫
另一方面,為了順利進行大數據轉型,我們需要將數據平台的使用和維護盡可能簡化。因此,我們選擇了Apache Doris。它與MySQL協議兼容,並提供豐富的功能集,這意味著我們無需開發自定義的UDF。此外,它僅由前端和後端兩種類型的進程組成,這使得擴展和追蹤變得簡單。
Source:
https://dzone.com/articles/building-a-data-warehouse-for-traditional-industry