













你是否曾想過如何即時可視化您的網絡流量?在本教程中,您將學習如何使用Python和Streamlit構建交互式網絡流量分析儀表板。Streamlit是一個開源的Python框架,您可以用它來開發用於數據分析和數據處理的Web應用程序。
在本教程結束時,您將學會如何從計算機的網絡接口卡(NIC)捕獲原始網絡數據包,處理數據並創建美麗的可視化效果,這些效果將實時更新。
目錄
為什麼網絡流量分析很重要?
網路流量分析是企業中的一項關鍵需求,在這裡,網路幾乎是每個應用程式和服務的支柱。在核心部分,我們有網路封包的分析,涉及監控網路、捕獲所有流量(入站和出站),並解釋這些封包在網路中流動時的情況。您可以使用這種技術來識別安全模式、檢測異常,並確保網路的安全性和效率。
在本教程中,我們將進行的這個概念驗證項目尤其有用,因為它幫助您即時可視化和分析網路活動。這將使您能夠了解在企業系統中如何進行故障排除、性能優化和安全分析。
先決條件
-
您系統上安裝了Python 3.8或更新版本。
-
對計算機網路概念有基本了解。
-
熟悉Python程式語言及其廣泛使用的庫。
-
基本了解資料視覺化技術和庫。
如何設置您的專案
要開始,使用以下命令創建專案結構並使用Pip安裝必要工具:
mkdir network-dashboard
cd network-dashboard
pip install streamlit pandas scapy plotly
我們將使用Streamlit來製作儀表板視覺化,Pandas用於數據處理,Scapy用於網路封包捕獲和封包處理,最後使用Plotly繪製收集到的數據的圖表。
如何構建核心功能
我們將所有代碼放在一個名為dashboard.py的單個文件中。首先,讓我們開始導入我們將使用的所有元素:
import streamlit as st
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
from scapy.all import *
from collections import defaultdict
import time
from datetime import datetime
import threading
import warnings
import logging
from typing import Dict, List, Optional
import socket
現在讓我們透過設置基本的日誌配置來配置日誌記錄。這將用於跟踪事件並在調試模式下運行應用程序。我們目前將日誌級別設置為INFO,這意味著將顯示級別為INFO或更高的事件。如果您對Python中的日誌記錄不熟悉,我建議查看這裡的深入文檔。
# 配置日誌記錄
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
接下來,我們將構建我們的封包處理器。我們將在這個類中實現處理我們捕獲的封包的功能。
class PacketProcessor:
"""Process and analyze network packets"""
def __init__(self):
self.protocol_map = {
1: 'ICMP',
6: 'TCP',
17: 'UDP'
}
self.packet_data = []
self.start_time = datetime.now()
self.packet_count = 0
self.lock = threading.Lock()
def get_protocol_name(self, protocol_num: int) -> str:
"""Convert protocol number to name"""
return self.protocol_map.get(protocol_num, f'OTHER({protocol_num})')
def process_packet(self, packet) -> None:
"""Process a single packet and extract relevant information"""
try:
if IP in packet:
with self.lock:
packet_info = {
'timestamp': datetime.now(),
'source': packet[IP].src,
'destination': packet[IP].dst,
'protocol': self.get_protocol_name(packet[IP].proto),
'size': len(packet),
'time_relative': (datetime.now() - self.start_time).total_seconds()
}
# 添加特定於TCP的信息
if TCP in packet:
packet_info.update({
'src_port': packet[TCP].sport,
'dst_port': packet[TCP].dport,
'tcp_flags': packet[TCP].flags
})
# 添加特定於UDP的信息
elif UDP in packet:
packet_info.update({
'src_port': packet[UDP].sport,
'dst_port': packet[UDP].dport
})
self.packet_data.append(packet_info)
self.packet_count += 1
# 保留最後的10000個封包以防止內存問題
if len(self.packet_data) > 10000:
self.packet_data.pop(0)
except Exception as e:
logger.error(f"Error processing packet: {str(e)}")
def get_dataframe(self) -> pd.DataFrame:
"""Convert packet data to pandas DataFrame"""
with self.lock:
return pd.DataFrame(self.packet_data)
這個類將構建我們的核心功能,並具有幾個實用函數,將用於處理封包。
網絡封包在傳輸層分為兩類(TCP和UDP),在網絡層有ICMP協議。如果您對TCP/IP的概念不熟悉,我建議查看這裡的文章在freeCodeCamp News上。
我們的構造函數將跟踪所有被分類到我們定義的這些TCP/IP協議類型桶中的封包。我們還將記錄封包捕獲時間、捕獲的數據和封包的數量。
我們還將利用線程鎖來確保一次只處理一個封包。這可以進一步擴展以使項目具有並行封包處理。
get_protocol_name輔助函數幫助我們根據它們的協議號獲取正確類型的協議。為了讓您了解背景資料,互聯網管理局(IANA)分配標準化號碼來識別網絡封包中的不同協議。每當我們在解析的網絡封包中看到這些號碼時,我們將知道當前被攔截的封包中使用了什麼類型的協議。對於此項目的範圍,我們將僅映射到TCP、UDP和ICMP(Ping)。如果我們遇到任何其他類型的封包,我們將將其歸類為 OTHER(<protocol_num>)。
process_packet函數處理我們將處理這些單獨封包的核心功能。如果封包包含IP層,它將記錄源和目標IP地址、協議類型、封包大小以及自封包捕獲開始以來的経過時間。
對於具有特定傳輸層協議(如TCP和UDP)的封包,我們將捕獲源和目標端口以及TCP封包的TCP標誌。這些提取的詳細信息將存儲在 packet_data列表中。我們還將隨著這些封包被處理而跟踪 packet_count。
get_dataframe 函數幫助我們將 packet_data 列表轉換為一個 Pandas 數據框,然後將用於我們的可視化。
如何創建 Streamlit 可視化
現在是時候建立我們的互動式 Streamlit 儀表板了。我們將在 dashboard.py 腳本中定義一個名為 create_visualization 的函數(在我們的封包處理類之外)。
def create_visualizations(df: pd.DataFrame):
"""Create all dashboard visualizations"""
if len(df) > 0:
# 協議分佈
protocol_counts = df['protocol'].value_counts()
fig_protocol = px.pie(
values=protocol_counts.values,
names=protocol_counts.index,
title="Protocol Distribution"
)
st.plotly_chart(fig_protocol, use_container_width=True)
# 封包時間軸
df['timestamp'] = pd.to_datetime(df['timestamp'])
df_grouped = df.groupby(df['timestamp'].dt.floor('S')).size()
fig_timeline = px.line(
x=df_grouped.index,
y=df_grouped.values,
title="Packets per Second"
)
st.plotly_chart(fig_timeline, use_container_width=True)
# 前十個源 IP
top_sources = df['source'].value_counts().head(10)
fig_sources = px.bar(
x=top_sources.index,
y=top_sources.values,
title="Top Source IP Addresses"
)
st.plotly_chart(fig_sources, use_container_width=True)
此函數將接受數據框作為輸入,並幫助我們繪製三個圖表:
-
協議分佈圖:此圖將顯示捕獲封包流量中不同協議(例如,TCP、UDP、ICMP)的比例。
-
封包時間軸圖:此圖將顯示一段時間內每秒處理的封包數量。
-
前十個源 IP 地址圖:此圖將突出顯示在捕獲流量中發送最多封包的前十個 IP 地址。
協議分佈圖表只是三種不同類型的協議計數的餅圖(以及其他)。我們使用Streamlit和Plotly Python工具來繪製這些圖表。由於我們還注意到封包捕獲開始的時間戳,我們將使用這些數據來繪製隨時間變化的封包捕獲趨勢。
對於第二張圖表,我們將對數據進行groupby操作,並獲取每秒捕獲的封包數(S代表秒),最後我們將繪製圖形。
最後,對於第三張圖表,我們將統計觀察到的不同來源IP數量,並繪製一個IP計數圖表以顯示前10個IP。
如何捕獲網絡封包
現在,讓我們構建一個功能,允許我們捕獲網絡封包數據。
def start_packet_capture():
"""Start packet capture in a separate thread"""
processor = PacketProcessor()
def capture_packets():
sniff(prn=processor.process_packet, store=False)
capture_thread = threading.Thread(target=capture_packets, daemon=True)
capture_thread.start()
return processor
這是一個簡單的函數,它實例化PacketProcessor類,然後使用scapy模塊中的sniff函數開始捕獲封包。
我們在這裡使用線程來讓我們能夠獨立地捕獲封包,不受主程序流的阻塞。這確保封包捕獲操作不會阻塞其他操作,例如實時更新儀表板。我們還返回創建的PacketProcessor實例,以便它可以在我們的主程序中使用。
將所有內容組合在一起
現在讓我們將所有這些部分連接在一起,使用我們的main函數作為程序的驅動函數。
def main():
"""Main function to run the dashboard"""
st.set_page_config(page_title="Network Traffic Analysis", layout="wide")
st.title("Real-time Network Traffic Analysis")
# 初始化会话状态中的数据包处理器
if 'processor' not in st.session_state:
st.session_state.processor = start_packet_capture()
st.session_state.start_time = time.time()
# 创建仪表板布局
col1, col2 = st.columns(2)
# 获取当前数据
df = st.session_state.processor.get_dataframe()
# 显示指标
with col1:
st.metric("Total Packets", len(df))
with col2:
duration = time.time() - st.session_state.start_time
st.metric("Capture Duration", f"{duration:.2f}s")
# 显示可视化
create_visualizations(df)
# 显示最近数据包
st.subheader("Recent Packets")
if len(df) > 0:
st.dataframe(
df.tail(10)[['timestamp', 'source', 'destination', 'protocol', 'size']],
use_container_width=True
)
# 添加刷新按钮
if st.button('Refresh Data'):
st.rerun()
# 自动刷新
time.sleep(2)
st.rerun()
此函数还将实例化Streamlit仪表板,并将所有组件整合在一起。我们首先设置Streamlit仪表板的页面标题,然后初始化我们的PacketProcessor。我们在Streamlit中使用会话状态,以确保只创建一个数据包捕获实例,并保留其状态。
现在,我们将动态从会话状态中获取数据框,每次处理数据时开始显示指标和可视化内容。我们还将显示最近捕获的数据包,以及时间戳、源和目标IP、协议和数据包大小等信息。我们还将为用户添加手动刷新仪表板上的数据的功能,同时每两秒自动刷新一次。
最后,让我们通过以下命令运行程序:
sudo streamlit run dashboard.py
請注意,由於封包捕獲功能需要管理員權限,您將需要使用sudo運行該程序。如果您使用Windows,請以管理員身份打開終端,然後運行該程序,不需要sudo前綴。
請等待程序開始捕獲封包。如果一切順利,您應該會看到類似以下內容:
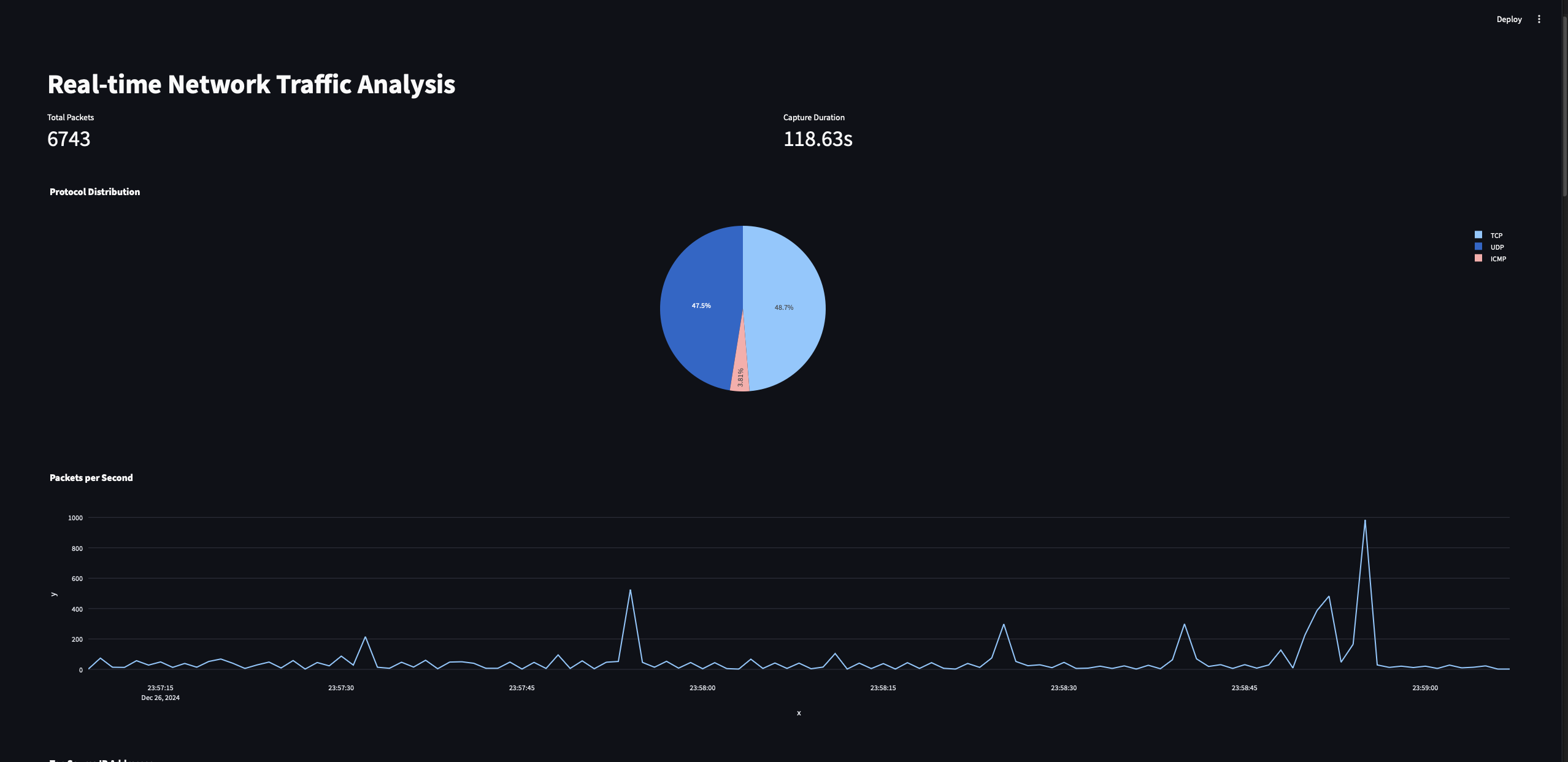
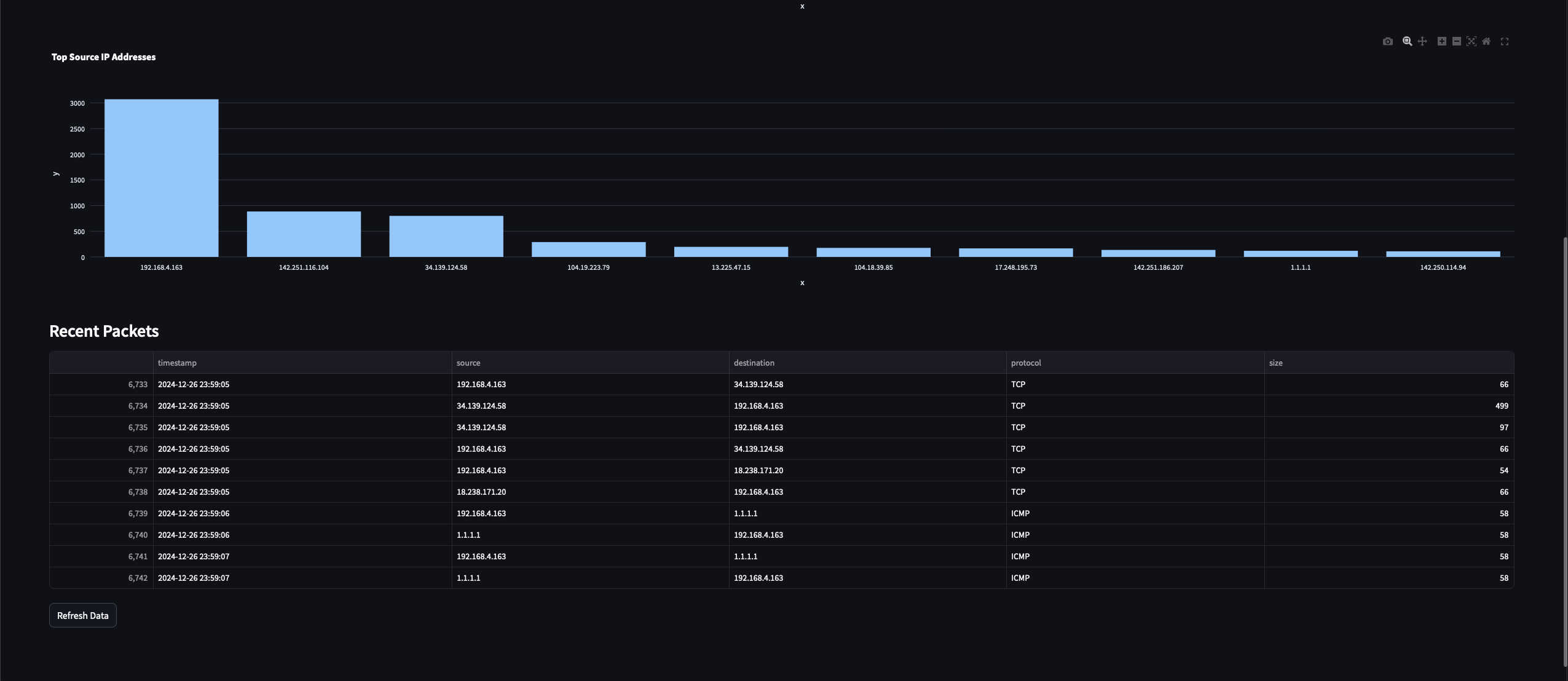
這些都是我們在Streamlit儀表板程序中剛實現的所有可視化效果。
未來的增強功能
有了這些,這裡是一些未來的增強想法,您可以用來擴展儀表板的功能:
-
為異常檢測添加機器學習功能
-
實現地理位置IP映射
-
根據流量分析模式創建自定義警報
-
添加封包有效負載分析選項
結論
恭喜!您現在已成功使用Python和Streamlit構建了一個實時網絡流量分析儀表板。該程序將為您提供有關網絡行為的寶貴見解,並可擴展用於各種用例,從安全監控到網絡優化。
希望這樣,你學到了一些關於網絡流量分析的基礎知識,以及一點點 Python 編程。感謝閱讀!