













在PostgreSQL中,复制延迟发生在主服务器上进行的更改需要时间才能在副本服务器上反映出来。无论您使用流式复制还是逻辑复制,延迟都会影响性能、一致性和系统可用性。本文涵盖了复制的类型、它们之间的区别、延迟的原因、用于估算延迟的数学公式、监控技术以及减少复制延迟的策略。
PostgreSQL中的复制类型
流式复制
流式复制持续将主服务器上的Write-Ahead Log(WAL)更改实时发送到一个或多个副本服务器。副本按顺序应用收到的更改。这种方法复制整个数据库并确保副本保持同步。
优势
- 低延迟,实时同步。
- 适用于完整数据库复制。
劣势
- 副本是只读的,因此所有写事务必须发送到主节点。
- 如果网络连接中断,延迟可能会显著增加。
逻辑复制
逻辑复制传输数据级别的更改,而不是低级别的WAL数据。它实现了选择性复制,只复制特定表或数据库的部分。逻辑复制使用逻辑解码过程将WAL更改转换为类似SQL的更改。
优势
- 允许选择性复制特定表或模式。
- 支持具有冲突解决选项的可写副本。
劣势
- 由于逻辑解码开销,延迟较高。
- 对于大型数据集,效率低于流复制。
复制延迟的原因
当主服务器上更改生成的速率超过能够处理和应用到副本服务器的速率时,就会发生复制延迟。这种不平衡可能是由于各种潜在因素引起的,每个因素都会导致数据同步延迟。复制延迟最常见的原因包括:
网络延迟
网络延迟是指数据从主服务器传输到副本服务器的时间。在流复制期间,WAL(预写式日志)段持续通过网络传输。即使是网络传输中的轻微延迟也会累积,导致副本延迟。
原因
- 高网络往返时间(RTT)。
- 需要更多带宽来处理大量的WAL数据。
- 网络拥塞或数据包丢失。
如果主服务器在高峰流量期间生成重大更改,网络变慢或过载可能会导致瓶颈,阻止副本接收WAL更改。
解决方案
使用低延迟、高带宽网络连接,并启用WAL压缩(wal_compression = on)以减少传输过程中的数据大小。
I/O瓶颈
I/O瓶颈发生在副本服务器的磁盘写入速度过慢时。流式复制依赖于在应用更改之前将更改写入磁盘,因此I/O子系统中的任何延迟都可能导致滞后。
原因
- 硬盘驱动器(HDD)速度慢或过载。
- 磁盘写入吞吐量不足。
- 来自其他进程的磁盘争用。
- 如果副本服务器使用传统硬盘(HDD)而不是固态硬盘(SSD),WAL更改可能无法快速写入以跟上数据更改,导致副本落后于主服务器。
解决方案
为了优化副本的磁盘I/O,使用SSD以获得更快的写入速度,并将复制过程与其他磁盘密集型任务隔离。
CPU/内存限制
复制过程需要CPU和内存来解码、写入和应用更改。如果副本服务器缺乏足够的处理能力或内存,它可能无法跟上传入的修改,导致复制延迟。
原因
- 有限的CPU核心或慢处理器。
- WAL缓冲区内存不足。
- 其他进程占用CPU或内存资源。
- 如果副本正在处理大型事务或在复制过程中运行查询,CPU可能会饱和,从而减慢复制过程。
解决方案
为副本服务器分配更多CPU核心和内存。增加wal_buffers的大小以提高WAL处理效率。
主服务器上的繁重工作负载
当主服务器生成的更改速度过快,副本无法处理时,也会出现复制延迟。大型事务、批量插入或频繁更新都可能使复制过载。
原因
- 批量数据导入或大型事务。
- 大表的高频更新。
- 主服务器上的高并发工作负载。
- 如果主服务器同时处理多个大型事务,例如在批量数据导入期间,事务负载可能过重。WAL数据的量可能超过副本实时处理的能力,导致延迟增加。
解决方案
通过批量处理更多次要更新并避免长时间运行的事务来优化交易。如果严格的同步不是关键,可以使用异步复制来减少复制负担。
资源争用
资源争用发生在多个进程竞争相同资源(如CPU、内存或磁盘I/O)的情况下。这可能发生在主服务器或副本服务器上,并导致复制处理延迟。
原因
- 其他进程消耗磁盘I/O、CPU或内存。
- 同时运行的后台任务,如备份或分析。
- 复制流量与其他数据传输之间的网络争用。
- 如果副本服务器还在运行备份或分析查询,则CPU和磁盘资源的竞争可能会减慢复制过程。
解决方案
将复制工作负载与其他资源密集型进程隔离。在非高峰时段安排备份和分析,以防止干扰复制。
复制滞后的数学公式
使用以下公式计算复制滞后:

在逻辑复制中,逻辑解码会消耗额外时间:

监视复制滞后
流式复制监视
pg_stat_replication视图可用于监控流复制延迟。它提供了关于主服务器和副本服务器之间状态和延迟的见解。
SELECT application_name, state,
pg_size_pretty(sent_lsn - write_lsn) AS lag_bytes,
sync_state
FROM pg_stat_replication;
sent_lsn:发送到副本的最后一个WAL位置。write_lsn:在副本上写入的最后一个WAL位置。lag_bytes:两者之间的差异表示延迟。
逻辑复制监控
逻辑复制延迟可以使用pg_stat_subscription视图进行监控。
SELECT subscription_name, active,
pg_size_pretty(pg_current_wal_lsn() - replay_lsn) AS lag_bytes
FROM pg_stat_subscription;
示例:可视化复制延迟
以下Python代码片段可视化随时间变化的流复制和逻辑复制延迟。
import matplotlib.pyplot as plt
time = ['12:00', '12:10', '12:20', '12:30', '12:40', '12:50', '13:00']
streaming_lag = [0.5, 0.6, 0.4, 0.7, 1.0, 0.9, 0.6]
logical_lag = [2.0, 2.5, 3.0, 2.8, 3.5, 4.0, 3.2]
plt.plot(time, streaming_lag, label='Streaming Replication Lag', marker='o')
plt.plot(time, logical_lag, label='Logical Replication Lag', marker='s')
plt.xlabel('Time')
plt.ylabel('Lag (seconds)')
plt.title('Replication Lag Over Time')
plt.legend()
plt.grid(True)
# Save the plot as an image file
plt.savefig('replication_lag_plot.png')
print("Plot saved as replication_lag_plot.png")
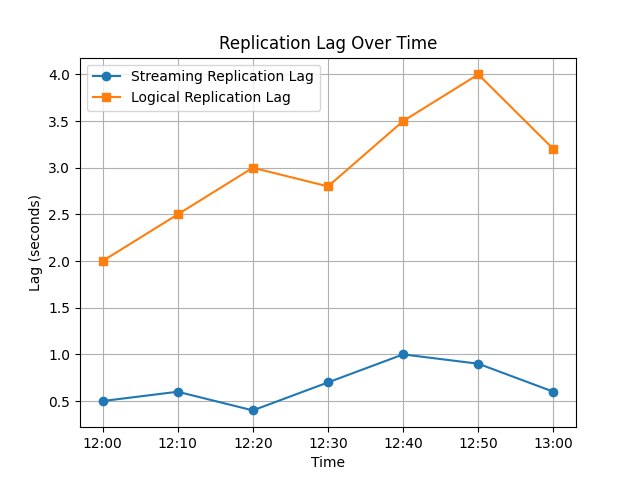
生成的图表比较了流复制和逻辑复制的性能。由于解码和处理开销,逻辑复制的延迟往往更为不稳定。
如何减少复制延迟
1. 优化WAL配置
- 增加
wal_buffers以在内存中保存更多的WAL数据。 - 将
wal_writer_delay设置为较低值(例如10ms),以更快地写入WAL数据。
wal_buffers = 64MB
wal_writer_delay = 10ms
2. 提高网络性能
- 使用主服务器和副本之间的低延迟、高带宽网络连接。
- 在传输过程中压缩WAL数据以减少传输时间:
wal_compression = on。
3. 在可能的情况下使用异步复制
-
异步复制通过不等待副本确认更改来减少延迟,但会增加数据丢失的风险。
ALTER SYSTEM SET synchronous_commit = 'off';
4. 在逻辑复制中启用并行应用
-
PostgreSQL 14+允许逻辑更改的并行应用,可减少大型事务的延迟。
ALTER SUBSCRIPTION my_subscription SET (parallel_apply = on);
5. 为副本分配更多资源
- 确保副本具有足够的CPU和内存来快速处理WAL更改。
- 在副本上使用SSD以加快磁盘I/O。
6. 批处理事务
-
将多个次要更新合并为较少的事务以减少开销。
实际示例
减少流复制延迟
某家运行高流量PostgreSQL集群的公司在高峰时段遇到了复制延迟问题。通过将wal_buffers增加到64MB并将wal_writer_delay减少到10ms,他们将复制延迟减半。切换到高速网络连接后,延迟减少到不到一秒。
减少逻辑复制延迟
一个具有多个逻辑订阅的系统在高写入工作负载期间出现了延迟。在PostgreSQL 14中启用并行应用程序将工作负载分散到多个工作进程,将复制延迟从4秒减少到不到1秒。
结论
复制延迟是影响PostgreSQL系统性能和一致性的关键问题。流复制提供低延迟,但需要整个数据库进行复制,而逻辑复制提供了灵活性但伴随着更高的开销。通过使用pg_stat_replication和pg_stat_subscription进行定期监控,管理员可以检测并缓解延迟。
优化WAL配置、提高网络性能、使用并行应用程序以及分配足够的资源可以显著减少延迟。适当的调优确保副本保持同步,并使系统保持高可用性和性能。
Source:
https://dzone.com/articles/understanding-and-reducing-postgresql-replication-lag