













免责声明: 本博客中表达的所有观点和意见仅代表作者本人,并不一定代表作者的雇主或任何其他团体或个人。本文不是对任何云/数据管理平台的推广。所有的图像和API均可在Azure/Databricks网站上公开获取。。
什么是Databricks Lakehouse监控?
在我的其他文章中,我描述了Databricks和Unity Catalog是什么,以及如何使用脚本从头创建一个目录。在本文中,我将描述作为Databricks平台一部分的Lakehouse监控功能,以及如何使用脚本启用该功能。
Lakehouse监控为Lakehouse中的Delta Live Tables提供数据分析和数据质量相关指标。Databricks Lakehouse监控提供了对数据的全面洞察,包括数据量的变化、数值分布的变化、列中空值和零值的百分比,以及随时间推移的分类异常检测。
为什么要使用Lakehouse监控?
监控数据和ML模型性能提供定量指标,帮助您随时间跟踪和确认数据和模型性能的质量和一致性。
以下是关键功能的详细介绍:
- 数据质量和数据完整性跟踪:跟踪数据在管道中的流动,确保数据完整性,并提供数据随时间变化的可见性,如数字列的90th百分位数,空值和零值列的百分比等。
- 数据随时间的漂移:提供指标以检测当前数据与已知基准或数据连续时间窗口之间的数据漂移
- 数据的统计分布:提供数据随时间的数值分布变化,回答分类列值的分布是什么,以及与过去有何不同
- ML模型性能和预测漂移:ML模型输入、预测和性能趋势随时间的变化
工作原理
Databricks Lakehouse Monitoring提供以下类型的分析:时间序列、快照和推断。
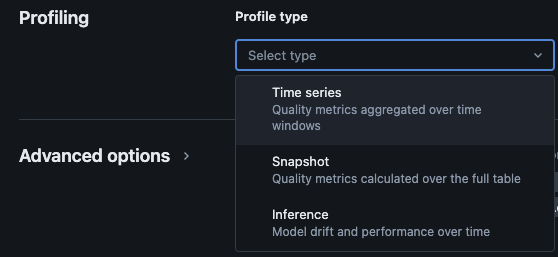
用于监控的配置文件类型
当您为 Unity Catalog 中的表启用 Lakehouse 监控时,它会在指定的监控模式下创建两个表。您可以查询这些表,并创建仪表板(Databricks 提供了一个默认的可配置仪表板)和通知,以便随着时间的推移获取有关数据的全面统计信息和概况信息。
- 漂移指标表:漂移指标表包含与数据随时间漂移相关的统计信息。它捕获的信息包括计数差异、平均值差异、% 空值和零的差异等。
- 概况指标表:概况指标表包含每列以及每个时间窗口、切片和分组列组合的汇总统计信息。对于 InferenceLog 分析,分析表还包含模型准确性指标。
如何通过脚本启用 Lakehouse 监控
先决条件
- Unity Catalog、模式和 Delta Live Tables 存在。
- 用户是 Delta Live Table 的所有者。
- 对于私有的 Azure Databricks 集群,已配置无服务器计算的私有连接。
步骤1:创建一个笔记本并安装 Databricks SDK
在Databricks工作空间中创建一个笔记本。要在工作空间中创建笔记本,请单击侧边栏中的“+”新建,然后选择笔记本。
工作空间中会打开一个空白笔记本。确保选择Python作为笔记本语言。
将下面的代码片段复制并粘贴到笔记本单元格中,并运行该单元格。
%pip install databricks-sdk --upgrade
dbutils.library.restartPython()
步骤2:创建变量
将下面的代码片段复制并粘贴到笔记本单元格中,并运行该单元格。
catalog_name = "catalog_name" #Replace the catalog name as per your environment.
schema_name = "schema_name" #Replace the schema name as per your environment.
monitoring_schema = "monitoring_schema" #Replace the monitoring schema name as per your preferred name.
refresh_schedule_cron = "0 0 0 * * ?" #Replace the cron expression for the refresh schedule as per your need.
步骤3:创建监控模式
将下面的代码片段复制并粘贴到笔记本单元格中,并运行该单元格。如果监控模式尚不存在,此代码片段将创建监控模式。
%sql
USE CATALOG `${catalog_name}`;
CREATE SCHEMA IF NOT EXISTS `${monitoring_schema}`
步骤4:创建监控
将下面的代码片段复制并粘贴到笔记本单元格中,并运行该单元格。此代码片段将为架构内所有表创建Lakehouse监控。
import time
from databricks.sdk import WorkspaceClient
from databricks.sdk.errors import NotFound, ResourceDoesNotExist
from databricks.sdk.service.catalog import MonitorSnapshot, MonitorInfo, MonitorInfoStatus, MonitorRefreshInfoState, MonitorMetric, MonitorCronSchedule
databricks_url = 'https://adb-xxxx.azuredatabricks.net/' # replace the url with your workspace url
api_token = 'xxxx' # replace the token with your personal access token for the workspace. Best practice - store the token in Azure KV and retrieve the token using key-vault scope.
w = WorkspaceClient(host=databricks_url, token=api_token)
all_tables = list(w.tables.list(catalog_name=catalog_name, schema_name=schema_name))
for table in all_tables:
table_name = table.full_name
info = w.quality_monitors.create(
table_name = table_name,
assets_dir = "/Shared/databricks_lakehouse_monitoring/", # Creates monitoring dashboards in this location
output_schema_name = f"{catalog_name}.{monitoring_schema}",
snapshot = MonitorSnapshot(),
schedule = MonitorCronSchedule(quartz_cron_expression = refresh_schedule_cron, timezone_id = "PST") # update timezone as per your need.
)
# Wait for monitor to be created
while info.status == MonitorInfoStatus.MONITOR_STATUS_PENDING:
info = w.quality_monitors.get(table_name=table_name)
time.sleep(10)
assert info.status == MonitorInfoStatus.MONITOR_STATUS_ACTIVE, "Error creating monitor"
验证
脚本成功执行后,您可以导航到目录 -> 架构 -> 表,并转到表中的“质量”选项卡以查看监控详情。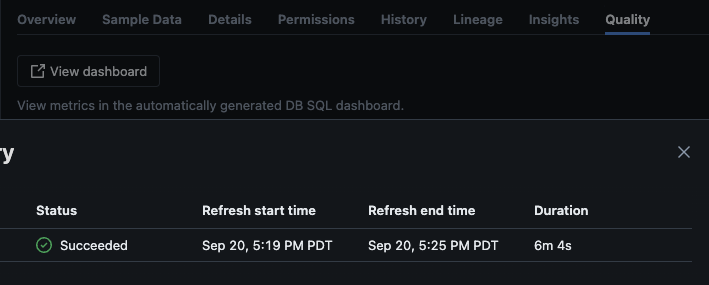
如果您点击 查看仪表板 按钮,在 监控 页面左上角,默认的监控仪表板将会打开。最初,数据将是空白的。随着监控按计划运行,随着时间的推移,它将填充所有统计、配置文件和数据质量值。
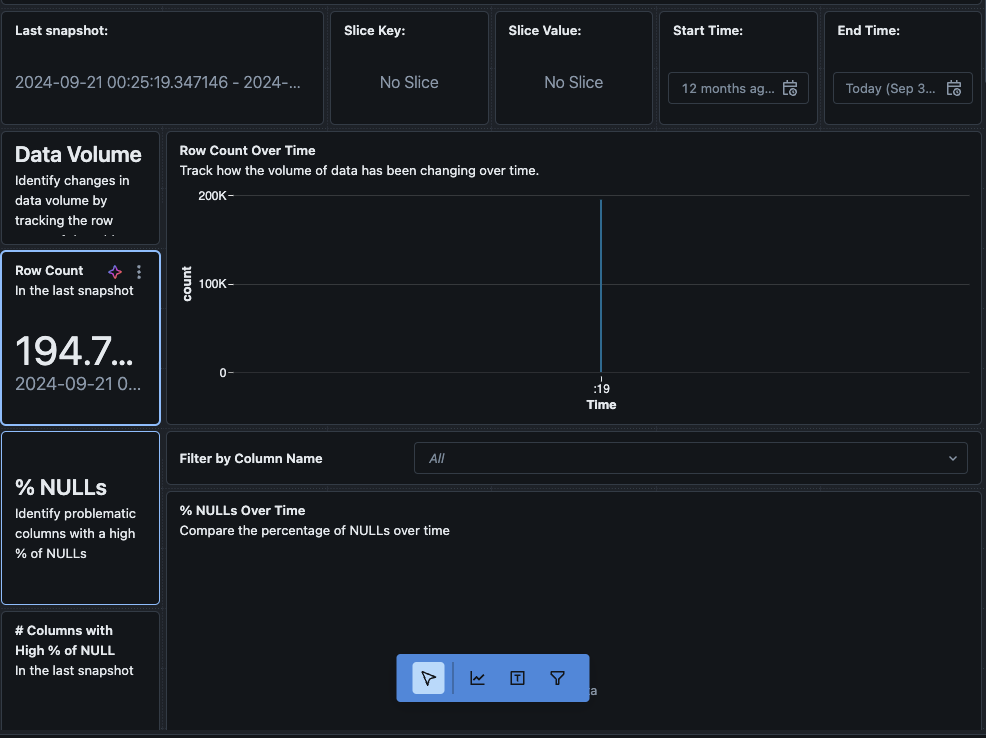
您还可以导航到仪表板中的 数据 标签。Databricks 开箱即用提供了一系列查询,以获取漂移和其他配置文件信息。您也可以根据需要创建自己的查询,以便全面了解您的数据。
结论
Databricks Lakehouse 监控提供了一种结构化方式来跟踪数据质量、配置文件指标,并检测数据漂移。通过脚本启用此功能,团队可以深入了解数据行为,并确保其数据管道的可靠性。本文中描述的设置过程为维护数据完整性和支持持续的数据分析工作奠定了基础。
Source:
https://dzone.com/articles/how-to-enable-azure-databricks-lakehouse-monitoring