













VAR-As-A-Service是一种MLOps方法,旨在统一和复用统计模型及机器学习模型的部署管道。本文是基于该项目的系列文章中的第二篇,展示了针对不同统计与机器学习模型的实验,以及利用现有DAG工具实现的数据管道和存储服务(包括云端与本地替代方案)。本文重点探讨了模型文件存储方法,该方法同样适用于机器学习模型,并采用MinIO作为与AWS S3兼容的对象存储服务。此外,文章还概述了其他存储解决方案,并阐述了对象存储的优势。
系列的首篇文章(时间序列分析:VARMAX-As-A-Service)对比了统计与机器学习模型,指出它们均为数学模型,并实现了一个基于VARMAX的统计模型,用于宏观经济预测,所用Python库名为statsmodels。该模型通过Python Flask和Apache网络服务器部署为REST服务,并封装在Docker容器中。应用的高层架构如下图所示:
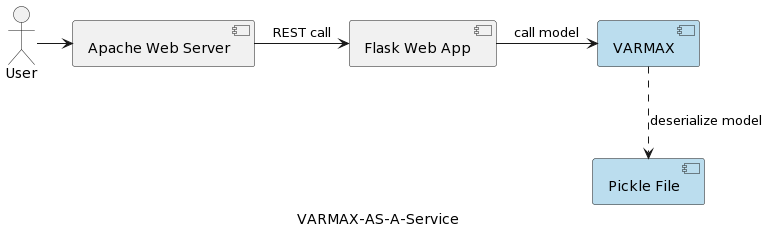
该模型被序列化为pickle文件,并作为REST服务包的一部分部署在Web服务器上。然而,在实际项目中,模型需要进行版本管理、伴随元数据信息、确保安全性,并且训练实验需要记录并保持可重现性。此外,从架构角度来看,将模型存储在与应用程序相邻的文件系统中,违反了单一职责原则。一个很好的例子是基于微服务的架构。模型服务的水平扩展意味着每个微服务实例都将拥有自己的物理pickle文件版本,并在所有服务实例中复制。这也意味着支持多个模型版本将需要发布新版本并重新部署REST服务及其基础设施。本文的目标是将模型与Web服务基础设施解耦,并使Web服务逻辑能够与不同版本的模型重复使用。
在深入实现之前,我们先简要谈谈该项目中使用的统计模型以及VAR模型。统计模型是数学模型的一种,机器学习模型亦然。关于两者差异的更多信息,可以参阅系列文章中的第一篇。统计模型通常被定义为随机变量与其它非随机变量之间的一种数学关系。向量自回归(VAR)是一种统计模型,用于捕捉多个数量随时间变化的相互关系。VAR模型通过允许多变量时间序列,扩展了单一变量自回归模型(AR)。在展示的项目中,该模型训练用于预测两个变量。VAR模型常用于经济学和自然科学领域。总体上,该模型由一组方程表示,在项目中,这些方程隐藏在Python库statsmodels背后。
VAR模型服务应用的架构如下图所示:
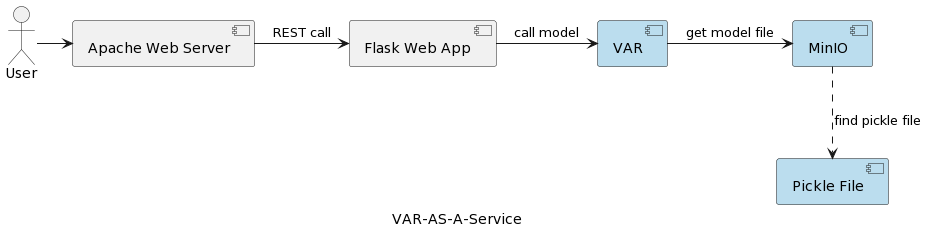
VAR运行时组件代表基于用户发送的参数实际执行模型的过程。它通过REST接口连接到MinIO服务,加载模型并执行预测。与第一篇文章中的解决方案不同,后者在应用启动时加载并反序列化VARMAX模型,而VAR模型则是每次触发预测时从MinIO服务器读取。这虽然增加了加载和反序列化的时间,但确保了每次运行都能使用部署模型的最新版本。此外,它支持模型的动态版本管理,使得模型自动对外部系统和终端用户开放,具体将在后文展示。需要注意的是,由于这种加载开销,所选存储服务的性能至关重要。
但为何选择MinIO及对象存储呢?
MinIO是一款高性能的对象存储解决方案,原生支持Kubernetes部署,提供与亚马逊网络服务S3兼容的API,并支持所有核心S3功能。在本项目中,MinIO采用独立模式配置,包含一个MinIO服务器和一个在Linux上使用Docker Compose的单驱动器或存储卷。对于扩展的开发或生产环境,可选择分布式模式,详细描述见文章《部署MinIO分布式模式》。
- 本地/分布式文件存储:本地文件存储是第一篇文章中实施的方案,因其最为简单。计算和存储位于同一系统上。这在概念验证阶段或对于支持单一版本的简单模型来说是可接受的。本地文件系统存储容量有限,当我们希望存储如训练数据集使用情况等额外元数据时,不适用于大型数据集。由于缺乏复制和自动扩展功能,本地文件系统无法以可用、可靠和可扩展的方式运行。为实现水平扩展,每个部署的服务都配备有自己的模型副本。此外,本地存储的安全性仅与宿主系统相当。本地文件存储的替代方案包括NAS(网络附加存储)、SAN(存储区域网络)以及分布式文件系统(如Hadoop分布式文件系统(HDFS)、Google文件系统(GFS)、Amazon弹性文件系统(EFS)和Azure文件)。相较于本地文件系统,这些解决方案具有可用性、可扩展性和弹性,但伴随而来的则是复杂性的增加。
- 关系型数据库:由于模型采用二进制序列化,关系型数据库提供了将模型作为blob或二进制数据存储在表列中的选项。软件开发者和许多数据科学家对关系型数据库都很熟悉,这使得该解决方案简单直接。模型版本可以作为单独的表行存储,并附带额外的元数据,这些信息也容易从数据库中读取。然而,一个缺点是数据库将需要更多的存储空间,这会影响备份。在数据库中存储大量二进制数据也可能影响性能。此外,关系型数据库对数据结构施加了一些约束,这可能会使存储异构数据(如CSV文件、图像和JSON文件作为模型元数据)变得复杂。
- 对象存储: 对象存储存在已久,但自2006年亚马逊推出首个AWS服务——简单存储服务(S3)后,它迎来了革命性的变革。现代对象存储天生适合云环境,其他云服务商也迅速推出了自己的产品。微软提供Azure Blob存储,谷歌则有Google Cloud Storage服务。S3 API成为开发者与云存储交互的实际标准,多家公司提供与S3兼容的存储解决方案,无论是公有云、私有云还是私有本地部署。不论对象存储位于何处,均通过RESTful接口访问。虽然对象存储消除了对目录、文件夹等复杂层级结构的需求,但它不适用于频繁变动的动态数据,因为修改数据需重写整个对象,但对于存储序列化模型及其元数据则颇为合适。
A summary of the main benefits of object storage are:
- 大规模可扩展性: 对象存储的规模几乎无限制,数据能通过简单增加新设备扩展至艾字节级别。对象存储解决方案在分布式集群中运行时性能最佳。
- 简化复杂性: 数据以扁平结构存储,无需复杂的树状结构或分区(无文件夹或目录),这使得检索文件更为简便,用户无需知晓确切位置。
- 可搜索性:元数据作为对象的一部分,使得无需借助单独的应用程序即可轻松检索和导航。用户可以为对象添加属性及信息标签,如消耗量、成本以及自动删除、保留和分层策略。由于底层存储采用扁平地址空间(每个对象仅位于一个桶中,且桶内无子桶结构),对象存储能够在数十亿对象中迅速定位特定对象。
- 弹性:对象存储能够自动复制数据,并跨多个设备及地理区域存储副本。这有助于防范宕机风险,保障数据安全,并支持灾难恢复策略的实施。
- 简洁性:通过REST API进行模型存储与检索,几乎无需学习成本,使得将其融入基于微服务架构的集成变得顺理成章。
现在,我们应关注VAR模型即服务的实现及其与MinIO的整合。通过使用Docker和Docker Compose,所提出的解决方案部署得以简化。整个项目的组织结构如下:

如同第一篇文章所述,模型的准备工作包含几个步骤,这些步骤编写在名为var_model.py的Python脚本中,该脚本位于一个专门的GitHub仓库内:
- 加载数据
- 将数据分割为训练集和测试集
- 准备内生变量
- 寻找最优模型参数p(每个变量的前p个滞后项作为回归预测因子)
- 用识别出的最优参数实例化模型
- 将实例化模型序列化为pickle文件
- 将pickle文件作为版本化对象存储在MinIO桶中
这些步骤也可作为工作流引擎(如Apache Airflow)中的任务实施,以便在需要用更新的数据训练新模型版本时触发。DAGs及其在MLOps中的应用将是另一篇文章的主题。
var_model.py中的最后一步是将序列化的模型作为pickle文件存储在S3的桶中。由于对象存储的扁平结构,所选格式为:
<桶名>/<文件名>
然而,对于文件名,允许使用正斜杠来模拟层次结构,同时保留快速线性搜索的优势。存储VAR模型的约定如下:
models/var/0_0_1/model.pkl
其中,存储桶名称是models,文件名是var/0_0_1/model.pkl,在MinIO的用户界面中,看起来如下:

这是一种非常方便的结构化各类模型及其版本的方式,同时仍保持了扁平文件存储的性能和简单性。
需要注意的是,模型版本控制作为模型名称的一部分实现。MinIO也提供了文件版本控制,但此处选择的方法具有以下优点:
- 支持快照版本和覆盖
- 采用语义版本控制(由于限制,点被’_’替换)
- 对版本控制策略有更大的控制权
- 在特定版本控制功能方面解耦底层存储机制
一旦模型部署完毕,接下来就是使用Flask将其作为REST服务暴露,并通过docker-compose部署,运行MinIO和Apache Web服务器。Docker镜像以及模型代码可以在专门的GitHub仓库中找到。
最后,运行应用程序所需的步骤如下:
- 部署应用:
docker-compose up -d - 执行模型准备算法:
python var_model.py(需要运行中的MinIO服务) - 检查模型是否已部署:http://127.0.0.1:9101/browser
- 测试模型:
http://127.0.0.1:80/apidocs
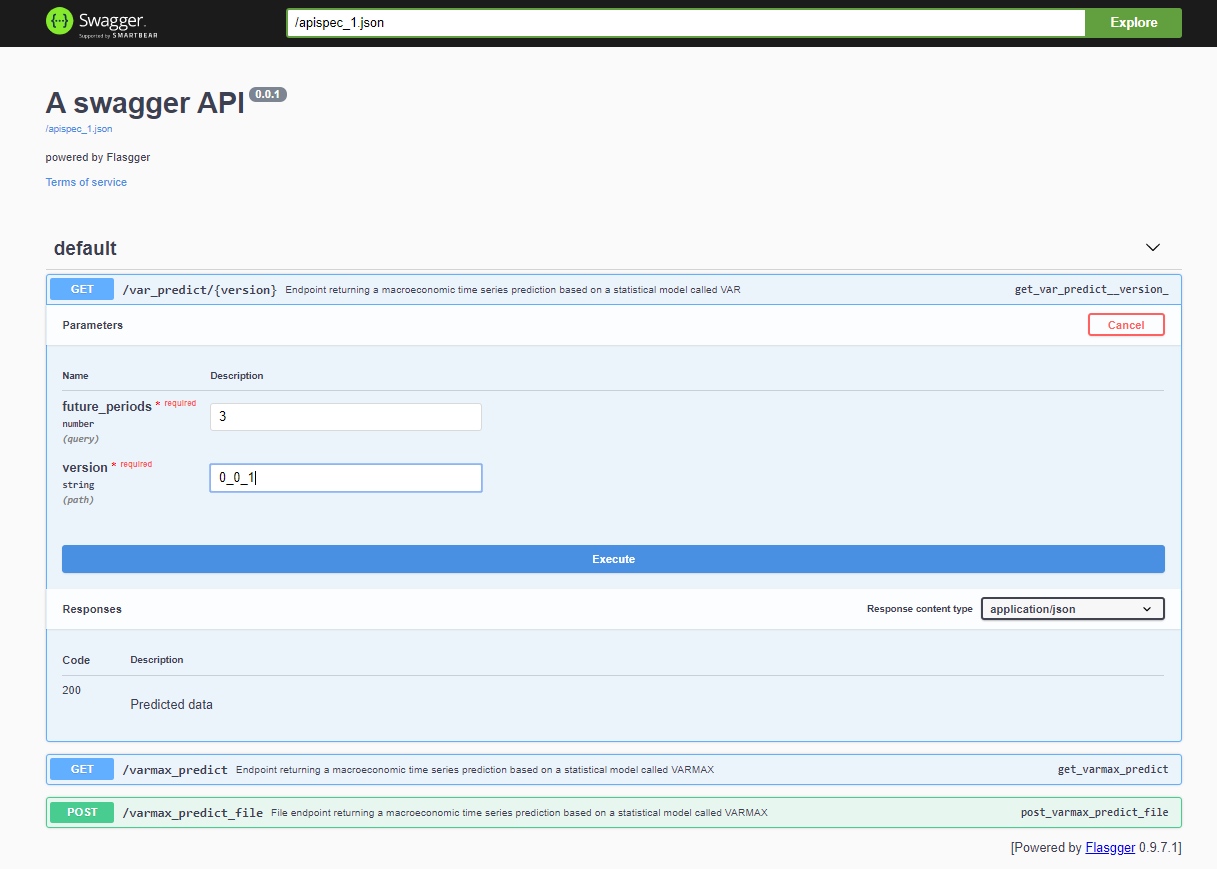
项目部署后,可通过<host>:<port>/apidocs(例如127.0.0.1:80/apidocs)访问Swagger API。VAR模型有一个端点,旁边还有另外两个端点,展示了一个VARMAX模型:
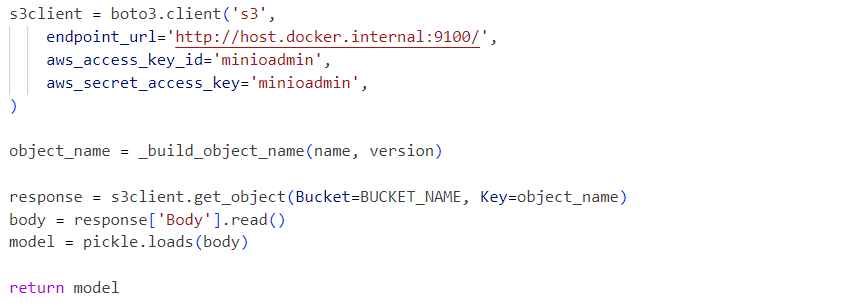
内部服务使用从MinIO服务加载的反序列化模型pickle文件:
请求按以下方式发送到初始化模型:

本项目展示了一个简化的VAR模型工作流程,可通过以下步骤逐步扩展额外功能:
- 探索标准序列化格式,并用替代方案替换pickle
- 集成时间序列数据可视化工具,如Kibana或Apache Superset
- 将时间序列数据存储在时间序列数据库中,如Prometheus、TimescaleDB、InfluxDB,或对象存储如S3
- 扩展管道以包括数据加载和数据预处理步骤
- 将度量报告作为管道的一部分
- 使用特定工具如Apache Airflow或AWS Step Functions,或更标准的工具如Gitlab或GitHub实现管道
- 比较统计模型与机器学习模型的性能和准确性
- 实施端到端云集成解决方案,涵盖基础设施即代码
- 将其他统计和机器学习模型作为服务暴露
- 实现一个模型存储API,该API抽象了实际存储机制和模型版本控制,存储模型元数据和训练数据
这些未来的改进将是即将发布的文章和项目的重点。本文的目标是集成兼容S3的存储API并实现版本化模型的存储。该功能将很快被提取到一个单独的库中。所提出的端到端基础设施解决方案可部署于生产环境中,并随着时间的推移作为CI/CD流程的一部分进行改进,同时利用MinIO的分布式部署选项或替换为AWS S3。
Source:
https://dzone.com/articles/time-series-analysis-var-model-as-a-service