













Whisper AI是由OpenAI开发的先进自动语音识别(ASR)模型,能够以令人印象深刻的准确性将音频转录为文本,并支持多种语言。虽然Whisper AI主要设计用于批处理,但可以配置为在Linux上进行实时语音转文本转录。
在本指南中,我们将逐步介绍如何在Linux系统上安装、配置和运行Whisper AI以进行实时转录。
什么是Whisper AI?
Whisper AI是一个开源语音识别模型,基于大量音频录音数据集进行训练,并基于深度学习架构,使其能够:
- 以多种语言转录语音。
- 有效处理口音和背景噪声。
- 将口语翻译成英语。
由于其设计旨在实现高准确率转录,因此广泛用于:
- 实时转录服务(例如,用于无障碍访问)。
- 语音助手和自动化。
- 转录录制的音频文件。
默认情况下,Whisper AI并未针对实时处理进行优化。然而,通过一些额外的工具,它可以处理实时音频流以实现即时转录。
Whisper AI系统要求
在Linux上运行Whisper AI之前,请确保您的系统满足以下要求:
硬件要求:
- CPU:多核处理器(Intel/AMD)。
- RAM:至少8GB(建议使用16GB或更多)。
- GPU:带有CUDA的NVIDIA GPU(可选,但可以显著加快处理速度)。
- 存储:至少10GB的空闲磁盘空间用于模型和依赖项。
软件要求:
步骤1:安装所需的依赖项
在安装Whisper AI之前,请更新软件包列表并升级现有软件包。
sudo apt update [On Ubuntu] sudo dnf update -y [On Fedora] sudo pacman -Syu [On Arch]
接下来,您需要安装Python 3.8或更高版本和Pip软件包管理器,如下所示。
sudo apt install python3 python3-pip python3-venv -y [On Ubuntu] sudo dnf install python3 python3-pip python3-virtualenv -y [On Fedora] sudo pacman -S python python-pip python-virtualenv [On Arch]
最后,您需要安装FFmpeg,这是一个用于处理音频和视频文件的多媒体框架。
sudo apt install ffmpeg [On Ubuntu] sudo dnf install ffmpeg [On Fedora] sudo pacman -S ffmpeg [On Arch]
步骤2:在Linux中安装Whisper AI
一旦所需的依赖项安装完成,您可以继续在虚拟环境中安装 Whisper AI,该环境允许您安装Python包,而不影响系统包。
python3 -m venv whisper_env source whisper_env/bin/activate pip install openai-whisper
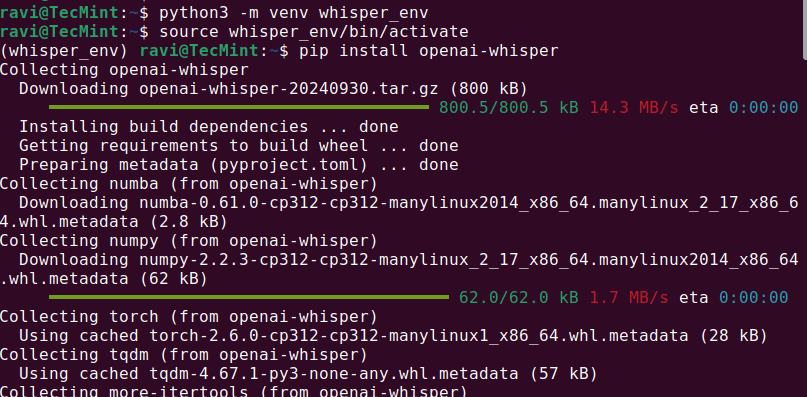
安装完成后,运行以下命令检查 Whisper AI 是否正确安装。
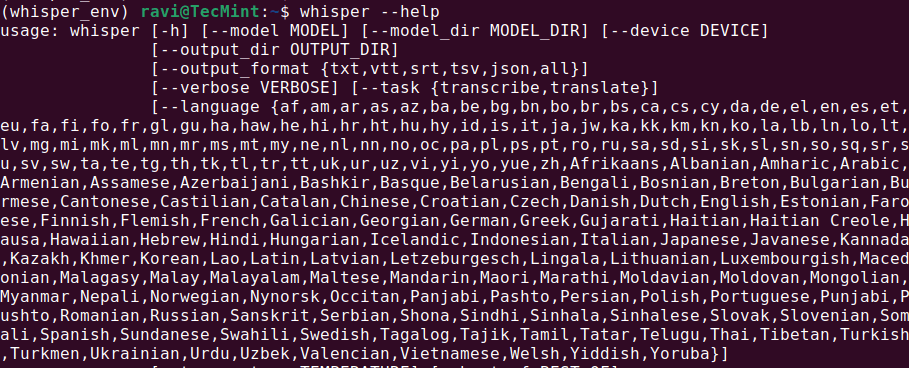
whisper --help
这应该会显示一个包含可用命令和选项的帮助菜单,这意味着 Whisper AI 已安装并准备好使用。
步骤 3:在 Linux 中运行 Whisper AI
一旦安装了 Whisper AI,您可以使用不同的命令开始转录音频文件。
转录音频文件
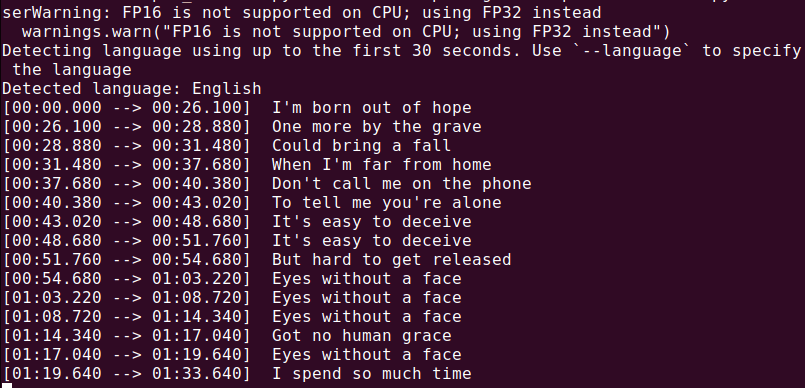
要转录音频文件(audio.mp3),请运行:
whisper audio.mp3
Whisper 将处理该文件并生成文本格式的转录。
现在一切都已安装,让我们创建一个 Python 脚本,从您的麦克风捕捉音频并实时转录。
nano real_time_transcription.py
将以下代码复制并粘贴到文件中。
import sounddevice as sd
import numpy as np
import whisper
import queue
import threading
# Load the Whisper model
model = whisper.load_model("base")
# Audio parameters
SAMPLE_RATE = 16000
BUFFER_SIZE = 1024
audio_queue = queue.Queue()
def audio_callback(indata, frames, time, status):
"""Callback function to capture audio data."""
if status:
print(status)
audio_queue.put(indata.copy())
def transcribe_audio():
"""Thread to transcribe audio in real time."""
while True:
audio_data = audio_queue.get()
audio_data = np.concatenate(list(audio_queue.queue)) # Combine buffered audio
audio_queue.queue.clear()
# Transcribe the audio
result = model.transcribe(audio_data.flatten(), language="en")
print(f"Transcription: {result['text']}")
# Start the transcription thread
transcription_thread = threading.Thread(target=transcribe_audio, daemon=True)
transcription_thread.start()
# Start capturing audio from the microphone
with sd.InputStream(callback=audio_callback, channels=1, samplerate=SAMPLE_RATE, blocksize=BUFFER_SIZE):
print("Listening... Press Ctrl+C to stop.")
try:
while True:
pass
except KeyboardInterrupt:
print("\nStopping...")
使用 Python 执行该脚本,这将开始监听您的麦克风输入并实时显示转录的文本。清晰地对着麦克风说话,您应该可以在终端上看到结果。
python3 real_time_transcription.py
结论
Whisper AI 是一个强大的语音转文本工具,可以适应 Linux 上的实时转录。为了获得最佳效果,请使用 GPU 并优化您的系统以进行实时处理。
Source:
https://www.tecmint.com/whisper-ai-audio-transcription-on-linux/