













亚马逊简单存储服务(S3)是亚马逊网络服务(AWS)提供的一项高度可扩展、持久且安全的对象存储服务。S3使企业能够通过利用其企业级服务,在网络上存储和检索任意数量的数据。S3设计为高度互操作,并与AWS及其他第三方工具和技术无缝集成,以处理存储在亚马逊S3中的数据。其中之一是亚马逊EMR(弹性MapReduce),它允许您使用Spark等开源工具处理大量数据。
Apache Spark是一个用于大规模数据处理的开源分布式计算系统。Spark旨在提高速度,并支持包括亚马逊S3在内的各种数据源。Spark提供了一种高效处理大量数据并在最短时间内执行复杂计算的方法。
Memphis.dev是传统消息代理的下一代替代品。它是一个简单、健壮且持久的云原生消息代理,配备了一个完整的生态系统,能够以成本效益高、快速且可靠的方式开发现代队列驱动用例。
消息代理的常见模式是在通过定义的保留策略(如时间/大小/消息数量)后删除消息。Memphis提供了一个用于长期、可能无限保留存储消息的第二存储层。从站点中逐出的每条消息将自动迁移到作为AWS S3的第二存储层。
在本教程中,您将逐步了解如何在AWS环境中设置Memphis站点,并连接第二个存储类到AWS S3。接下来将创建S3存储桶,设置EMR集群,安装和配置Apache Spark集群,准备S3中的数据以进行处理,使用Apache Spark处理数据,以及最佳实践和性能调优。
环境设置
Memphis
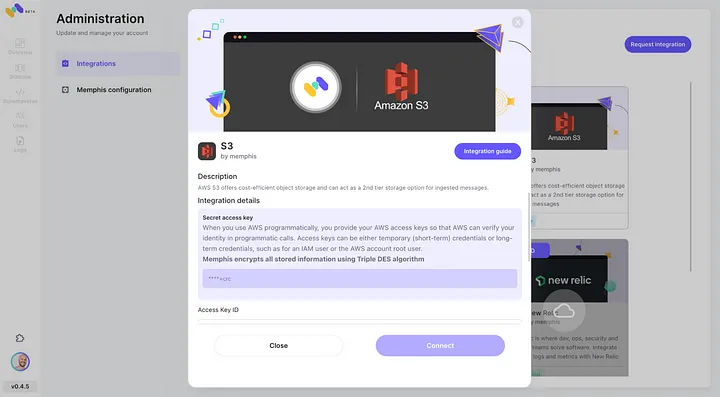
3. 创建站点(主题),并选择保留策略。
4. 每个通过配置的保留策略的消息将被卸载到一个S3存储桶。
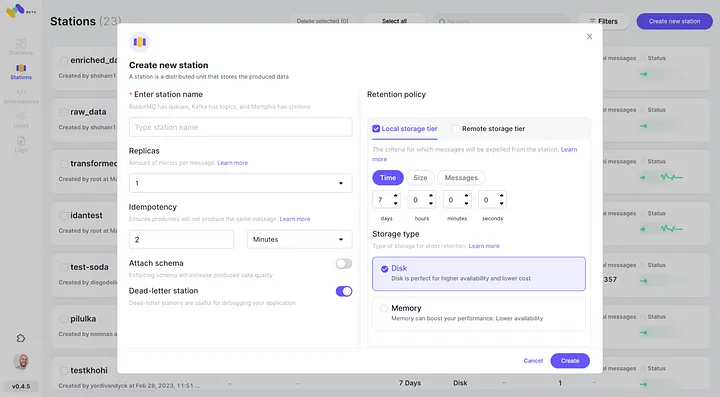
5. 点击“连接”检查新配置的AWS S3集成作为第二个存储类。
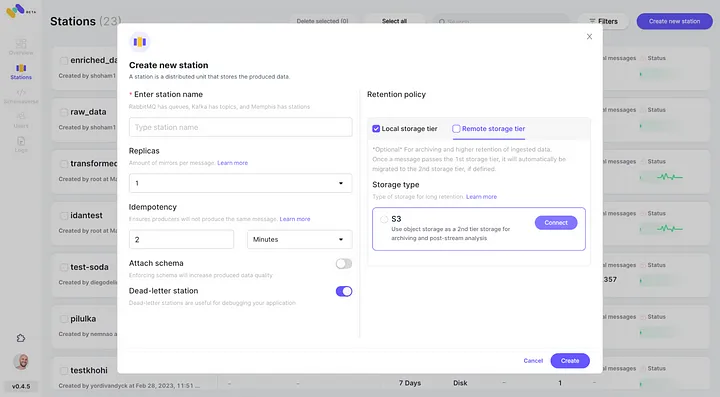
6. 开始为新创建的Memphis站点生成事件。
创建AWS S3存储桶
如果你尚未进行此操作,首先需要创建一个AWS 账户。接着,创建一个S3存储桶以存放你的数据。你可以通过AWS管理控制台、AWS CLI或SDK来创建存储桶。本教程中,你将使用AWS管理控制台。
点击“创建存储桶”。
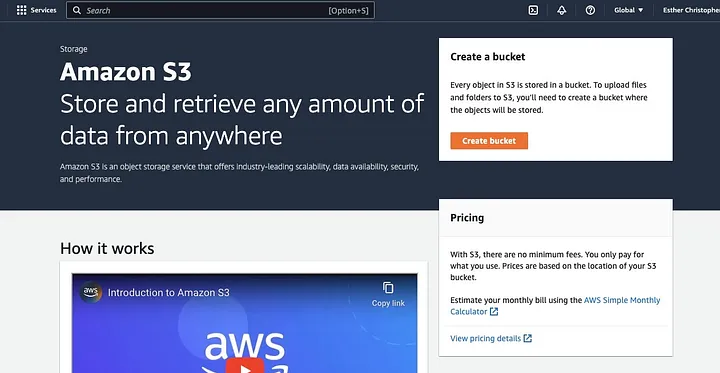
然后,按照命名规则设定存储桶名称,并选择存储桶所在区域。根据你的使用场景,配置“对象所有权”和“阻止所有公共访问”。
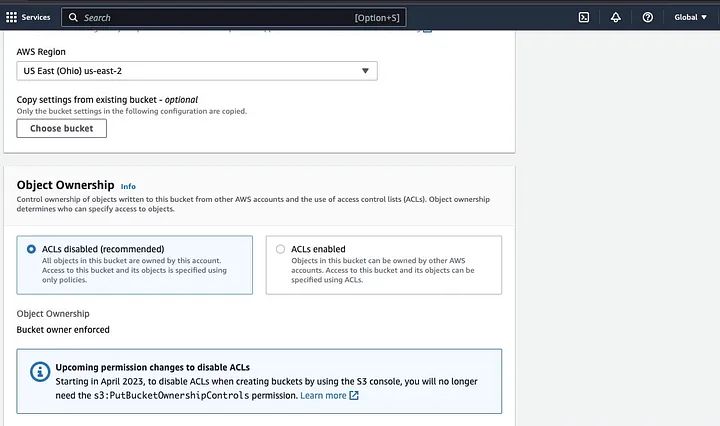
确保配置其他存储桶权限,以便你的Spark应用程序能够访问数据。最后,点击“创建存储桶”按钮完成创建。
安装了Spark的EMR集群设置
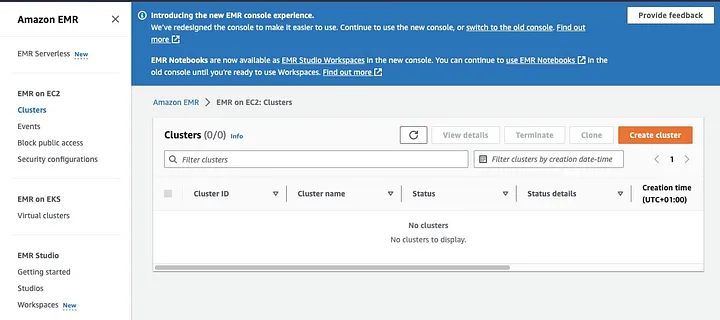
Amazon Elastic MapReduce (EMR) 是一个基于Apache Hadoop的网络服务,它允许用户利用大数据技术,包括Apache Spark,以成本效益的方式处理大量数据。要创建一个安装了Spark的EMR集群,打开EMR控制台,在页面左侧的“EMR on EC2”下选择“Clusters”。
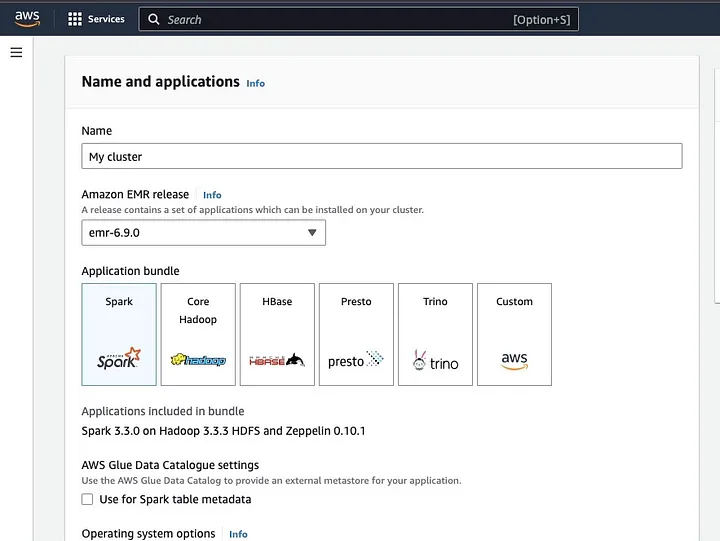
点击“创建集群”,并为集群指定一个描述性名称。在“应用程序包”下,选择Spark以安装在你的集群上。
向下滚动至“Cluster logs”部分,勾选发布集群特定日志至Amazon S3的复选框。
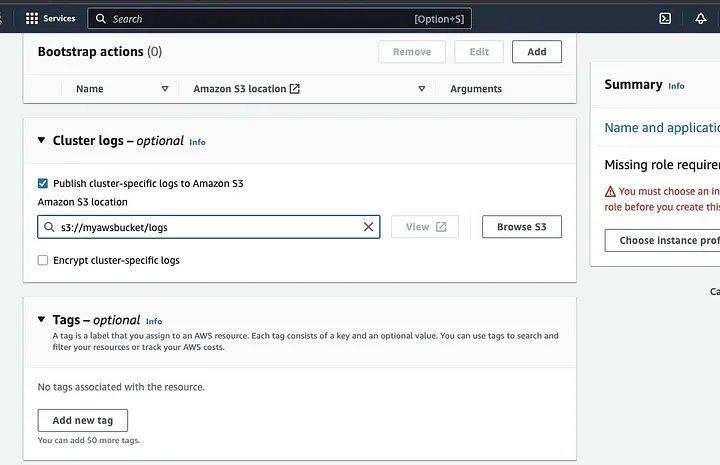
这将弹出一个提示,要求您输入在之前步骤中创建的S3存储桶名称,后接/logs,例如s3://myawsbucket/logs。/logs是亚马逊要求的,用于在您的存储桶中创建一个新文件夹,亚马逊EMR将在此处复制您的集群日志文件。
前往“安全配置和权限”部分,输入您的EC2密钥对,或选择创建一个新的密钥对。
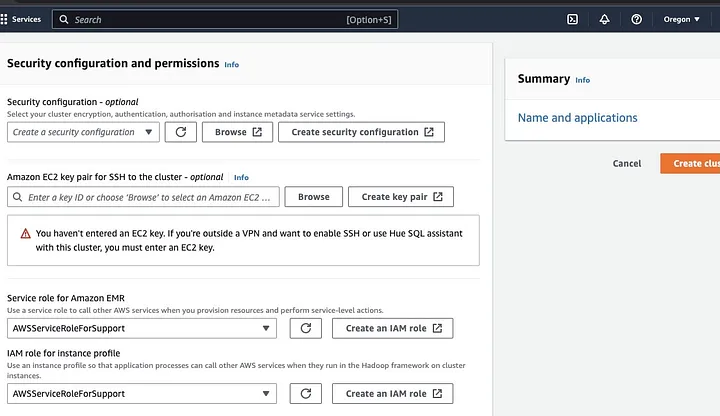
接着,点击“Amazon EMR服务角色”下拉选项,选择AWSServiceRoleForSupport。对于“实例配置文件的IAM角色”也选择相同的下拉选项。如有需要,刷新图标以显示这些下拉选项。
最后,点击“创建集群”按钮启动集群,并监控集群状态以确认其创建成功。
在EMR集群上安装与配置Apache Spark
成功创建EMR集群后,下一步是在EMR集群上配置Apache Spark。EMR集群提供了一个托管环境,用于在AWS基础设施上运行Spark应用程序,使得在云中启动和管理Spark集群变得简单。它配置Spark以适应您的数据和处理需求,并将Spark作业提交到集群以处理您的数据。
您可以通过Secure Shell (SSH)协议将Apache Spark配置到集群中。但首先,您需要授权SSH安全连接到您的集群,这通常在创建EMR集群时默认设置。关于如何授权SSH连接的指南,请参考此处。
要建立SSH连接,您需要指定创建集群时所选的EC2密钥对。然后,通过首先连接主节点,使用Spark shell连接到EMR集群。您需要先获取主节点的公共DNS名称,方法是在AWS控制台左侧导航至EMR on EC2,选择Clusters,然后选中您想要获取公共DNS名称的集群。
在您的操作系统终端中,输入以下命令。
ssh hadoop@ec2-###-##-##-###.compute-1.amazonaws.com -i ~/mykeypair.pem将ec2-###-##-##-###.compute-1.amazonaws.com替换为您的主节点公共DNS名称,将~/mykeypair.pem替换为您的.pem文件的文件名和路径(按照此指南获取.pem文件)。系统将弹出一个提示信息,您需要回答yes,输入exit以关闭SSH命令。
准备用于Spark处理的数据并上传至S3 Bucket。
数据处理在上传前需进行预处理,以确保数据格式便于Spark处理。所选格式取决于数据类型及计划进行的分析,常用格式包括CSV、JSON和Parquet。
创建新的Spark会话,并利用相应API将数据加载至Spark。例如,使用spark.read.csv()方法将CSV文件读入Spark DataFrame。
可利用Amazon EMR这一托管的Hadoop生态系统集群服务进行数据处理,它减少了集群搭建、调优和维护的需求,并支持与其他服务如Amazon SageMaker集成,实现在Amazon EMR中通过Spark管道启动SageMaker模型训练任务。
数据准备就绪后,通过DataFrame.write.format("s3")方法,可将CSV文件从Amazon S3桶读入Spark DataFrame,前提是已配置AWS凭证并拥有对S3桶的写入权限。
指定希望保存数据的S3桶及路径,例如使用df.write.format("s3").save("s3://my-bucket/path/to/data")方法将数据保存至指定的S3桶。
数据保存至S3桶后,可从其他Spark应用或工具访问,或下载以供进一步分析或处理。上传桶时,创建文件夹并选择初始创建的桶,点击“操作”按钮,在下拉菜单中选择“创建文件夹”,即可命名新文件夹。
要上传数据文件至存储桶,请先选择数据文件夹的名称。
接着在“上传”界面中,选择“文件向导”并点击“添加文件”。
遵循亚马逊S3控制台的指引上传文件,并点击“开始上传”。
在上传数据至S3存储桶前,重要的是要考虑并确保采取最佳安全实践来保护您的数据。
理解数据格式与模式
数据格式与模式是数据管理中两个相关但截然不同的重要概念。数据格式指的是数据库中数据的组织和结构方式,常见的有CSV、JSON、XML、YAML等,它们规定了数据的结构及适用的数据类型和应用。而数据模式则是数据库自身的结构,它定义了数据库的布局,确保数据得到恰当存储,包括视图、表、索引、类型等元素。这两个概念对于数据分析和数据库的可视化至关重要。
在S3中清洗与预处理数据
在处理数据前,务必仔细检查以排除错误。首先,访问您在S3存储桶中保存数据文件的文件夹,并将其下载至本地机器。随后,将数据加载至数据处理工具中进行清洗和预处理。本教程使用的是亚马逊Athena,它能够分析存储在Amazon S3中的非结构化和结构化数据。
前往AWS控制台中的Amazon Athena。
点击“创建”以新建表,然后选择“CREATE TABLE”。
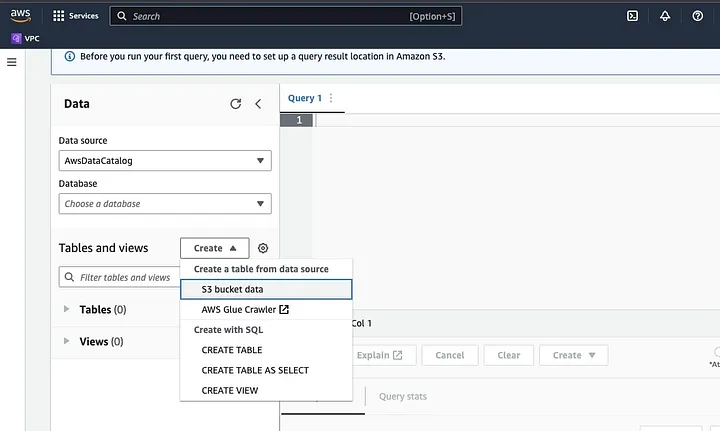
在突出显示为LOCATION的部分输入您的数据文件路径。
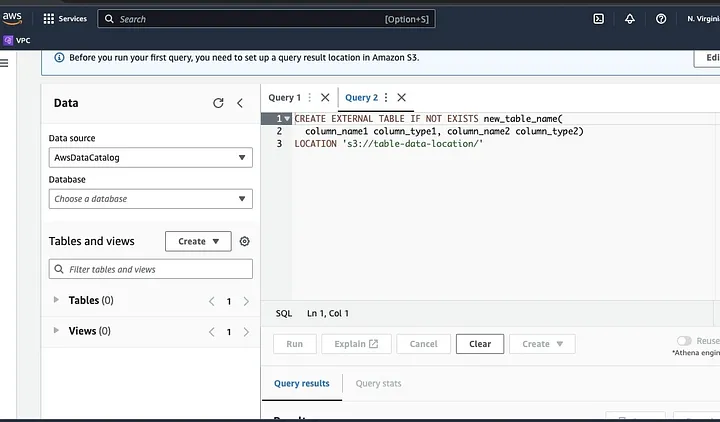
跟随提示定义数据模式并保存表。现在,您可以运行查询来验证数据是否正确加载,然后进行数据清洗和预处理
例如:
此查询识别数据中的重复项。
SELECT row1, row2, COUNT(*)
FROM table
GROUP row, row2
HAVING COUNT(*) > 1;此示例创建一个不含重复项的新表:
CREATE TABLE new_table AS
SELECT DISTINCT *
FROM table;最后,通过导航至S3桶和文件夹,将清洗后的数据导出回S3。
理解Spark框架
Spark框架是一个开源的、简单且表达力强的集群计算系统,专为快速开发而设计。它基于Java编程语言,作为其他Java框架的替代品。Spark的核心特性是其内存数据计算能力,这加快了处理大型数据集的速度。
配置Spark与S3协同工作
要配置Spark与S3协同工作,首先需将Hadoop AWS依赖项添加到您的Spark应用程序中。为此,在您的构建文件(如Scala的build.sbt或Java的pom.xml)中添加以下行:
libraryDependencies += "org.apache.hadoop" % "hadoop-aws" % "3.3.1"在Spark应用程序中输入AWS访问密钥ID和秘密访问密钥,通过设置以下配置属性实现:
spark.hadoop.fs.s3a.access.key <ACCESS_KEY_ID>
spark.hadoop.fs.s3a.secret.key <SECRET_ACCESS_KEY>使用SparkConf对象在代码中设置以下属性:
val conf = new SparkConf()
.set("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.set("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")在您的Spark应用程序中设置S3端点URL,通过设置以下配置属性:
spark.hadoop.fs.s3a.endpoint s3.<REGION>.amazonaws.com将<REGION>替换为您的S3存储桶所在AWS区域的名称(例如,us-east-1)。
为了使Hadoop中的S3客户端能够访问S3请求,需要一个符合DNS标准的存储桶名称。如果您的存储桶名称包含点或下划线,您可能需要为Hadoop中的S3客户端启用路径样式访问,该客户端使用虚拟主机样式。设置以下配置属性以启用路径访问:
spark.hadoop.fs.s3a.path.style.access true最后,通过在Spark配置中设置spark.hadoop前缀来创建具有S3配置的Spark会话:
val spark = SparkSession.builder()
.appName("MyApp")
.config("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.config("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")
.config("spark.hadoop.fs.s3a.endpoint", "s3.<REGION>.amazonaws.com")
.getOrCreate()将<ACCESS_KEY_ID>、<SECRET_ACCESS_KEY>和<REGION>替换为您的AWS凭证和S3区域。
要从S3读取数据到Spark中,将使用spark.read方法,并指定S3路径作为数据输入源。
一个示例代码,展示如何将S3中的CSV文件读入Spark中的DataFrame:
val spark = SparkSession.builder()
.appName("ReadDataFromS3")
.getOrCreate()
val df = spark.read
.option("header", "true") // Specify whether the first line is the header or not
.option("inferSchema", "true") // Infer the schema automatically
.csv("s3a://<BUCKET_NAME>/<FILE_PATH>")在此示例中,将<BUCKET_NAME>替换为您的S3存储桶名称,将<FILE_PATH>替换为存储桶内CSV文件的路径。
使用Spark进行数据转换
使用Spark进行数据转换通常涉及对数据进行清洗、筛选、聚合和连接等操作。Spark提供了一系列丰富的API用于数据转换,包括DataFrame、Dataset和RDD API。常见的Spark数据转换操作有筛选、选择列、数据聚合、数据连接和数据排序。
以下是一个数据转换操作的示例:
数据排序:这一操作涉及根据一个或多个列对数据进行排序。在DataFrame或Dataset上使用`orderBy`或`sort`方法可以基于一个或多个列对数据进行排序。例如:
val sortedData = df.orderBy(col("age").desc)最后,你可能需要将结果写回S3以存储这些结果。
Spark提供了多种API来将数据写入S3,如DataFrameWriter、DatasetWriter和RDD.saveAsTextFile。
以下是一个代码示例,展示如何将DataFrame以Parquet格式写入S3:
val outputS3Path = "s3a://<BUCKET_NAME>/<OUTPUT_DIRECTORY>"
df.write
.mode(SaveMode.Overwrite)
.option("compression", "snappy")
.parquet(outputS3Path)将输入字段`
`mode`方法用于指定写入模式,可以是`Overwrite`、`Append`、`Ignore`或`ErrorIfExists`。`option`方法可用于指定输出格式的各种选项,如压缩编解码器。
你还可以通过更改输出格式并指定适当的选项,将数据以CSV、JSON、Avro等其他格式写入S3。
理解Spark中的数据分区
简而言之,Spark中的数据分区指的是将数据集分割成更小、更易于管理的部分,分布在集群中。这样做的目的是优化性能、减少可扩展性问题,并最终提高数据库的管理效率。在Spark中,数据是在多个集群上并行处理的。这一过程得益于弹性分布式数据集(RDD),这是一种包含大量复杂数据的集合。默认情况下,由于RDD的大小,它们会被分区到不同的节点上。
为了实现最佳性能,可以通过配置Spark确保任务迅速执行,资源得到有效管理。这些配置包括缓存、内存管理、数据序列化以及使用mapPartitions()而非map()。
Spark UI是一个基于Web的图形用户界面,提供关于Spark应用程序性能和资源使用的全面信息。它包含多个页面,如概览、执行器、阶段和任务,这些页面提供了Spark作业不同方面的信息。Spark UI是监控和调试Spark应用程序的重要工具,它帮助识别性能瓶颈、资源限制并解决错误。通过检查完成任务的数量、作业持续时间、CPU和内存使用情况以及洗牌数据的读写情况等指标,用户可以优化其Spark作业,确保其高效运行。
结论
综上所述,利用Apache Spark在AWS S3上处理数据是一种高效且可扩展的大数据分析方法。通过利用AWS S3的云存储和计算资源以及Apache Spark,用户可以快速有效地处理数据,无需担心架构管理。
在本教程中,我们介绍了如何在AWS EMR上设置S3存储桶和Apache Spark集群,配置Spark以与AWS S3协同工作,以及编写和运行Spark应用程序来处理数据。我们还涵盖了Spark中的数据分区、Spark UI以及优化Spark性能的方法。
参考资料
如需深入了解配置Spark以实现最佳性能的方法,请参阅此处。
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-ssh.html
Source:
https://dzone.com/articles/stateful-stream-processing-with-memphis-and-apache-spark