













对于像Uber这样的公司,实时数据是其面向客户服务与内部运营的生命线。客户依赖实时数据来方便地叫车和订餐,而内部团队则依靠最新数据来支撑客户应用背后的基础设施,例如用于监控移动应用崩溃分析的内部工具。
Uber迁移至Apache Pinot以驱动这一内部工具,并在此过程中相较于之前的分析引擎(Elasticsearch)取得了显著的改进。通过转向Pinot这一真正的实时分析平台,Uber收获了以下益处:
- 基础设施成本降低70%(每年节省超过200万美元)
- CPU核心使用量减少80%
- 数据存储量减少66%
- 页面加载时间缩短64%(从14秒降至不足5秒)
- 数据摄取延迟降至10毫秒以下
- 查询超时现象减少,数据丢失问题得到解决

立即观看
本博客内容基于一场现场交流会,其中分享了Apache Pinot用户案例。我们还参考了Uber工程团队的博客文章,详细介绍了他们如何利用Pinot为移动应用崩溃提供实时分析。观看交流会请点击:
或者继续阅读,了解Uber如何通过Apache Pinot实现这些成果。
Uber如何实时分析移动应用崩溃情况
Uber拥有一个自动化的数据摄取管道,用于追踪应用崩溃并收集调查数据。部分数据被导入Apache Flink进行转换处理,随后再返回到Kafka主题供下游消费使用。Kafka中的原始及处理后的事件接着被Apache Pinot消费,后者运行分析查询,并将结果通过Grafana及内部可视化工具传递给内部用户。该管道同时摄取实时与离线数据(图中未展示),以在Apache Pinot中创建用户完整视图,称为混合表。
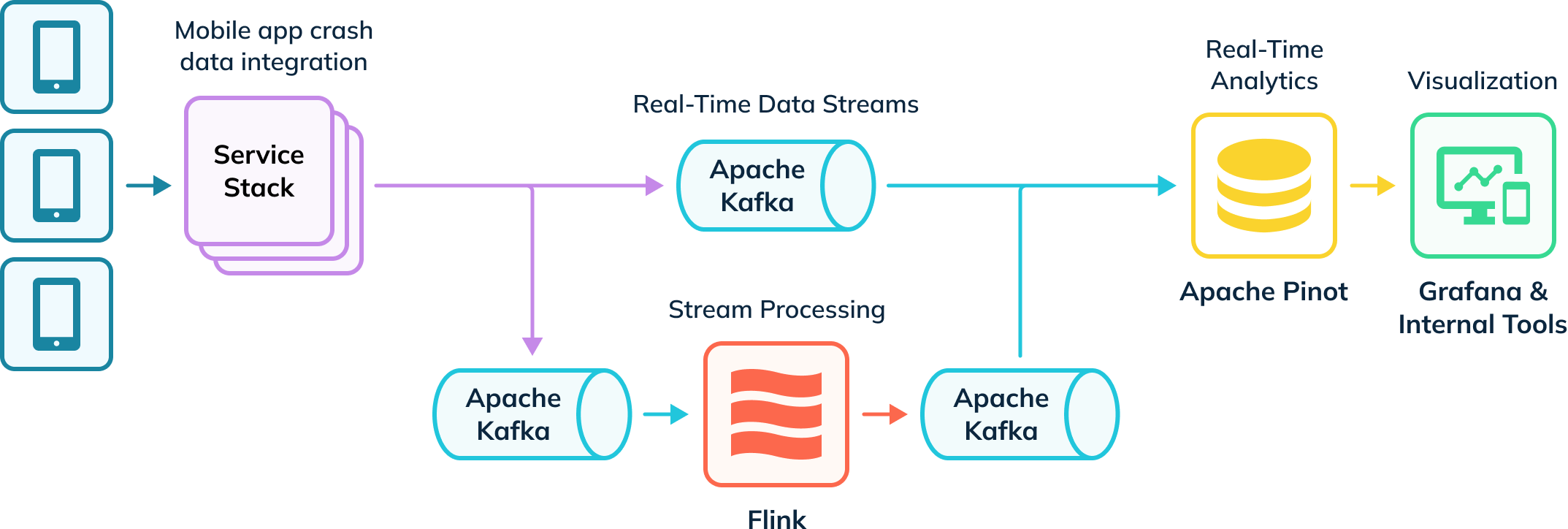
实时应用崩溃分析与Apache Pinot
Uber每周发布约11,000项新代码及基础设施变更,并依赖自家的Healthline工具来帮助检测和解决崩溃问题。Healthline使Uber能更有效地衡量并达成平均检测时间(MTTD)。例如,他们可能推出一项新功能导致意外的App崩溃,必须通过深入挖掘崩溃数据迅速定位崩溃源头。
下图展示了一款移动应用及一个操作系统版本一周的崩溃数据。在此例中,会话事件每秒发生多达数十万次,而崩溃事件每秒记录在15,000至20,000次之间。Uber结合这些指标计算无致命错误率,该指标反映了应用的健康状况(目标接近100%)。
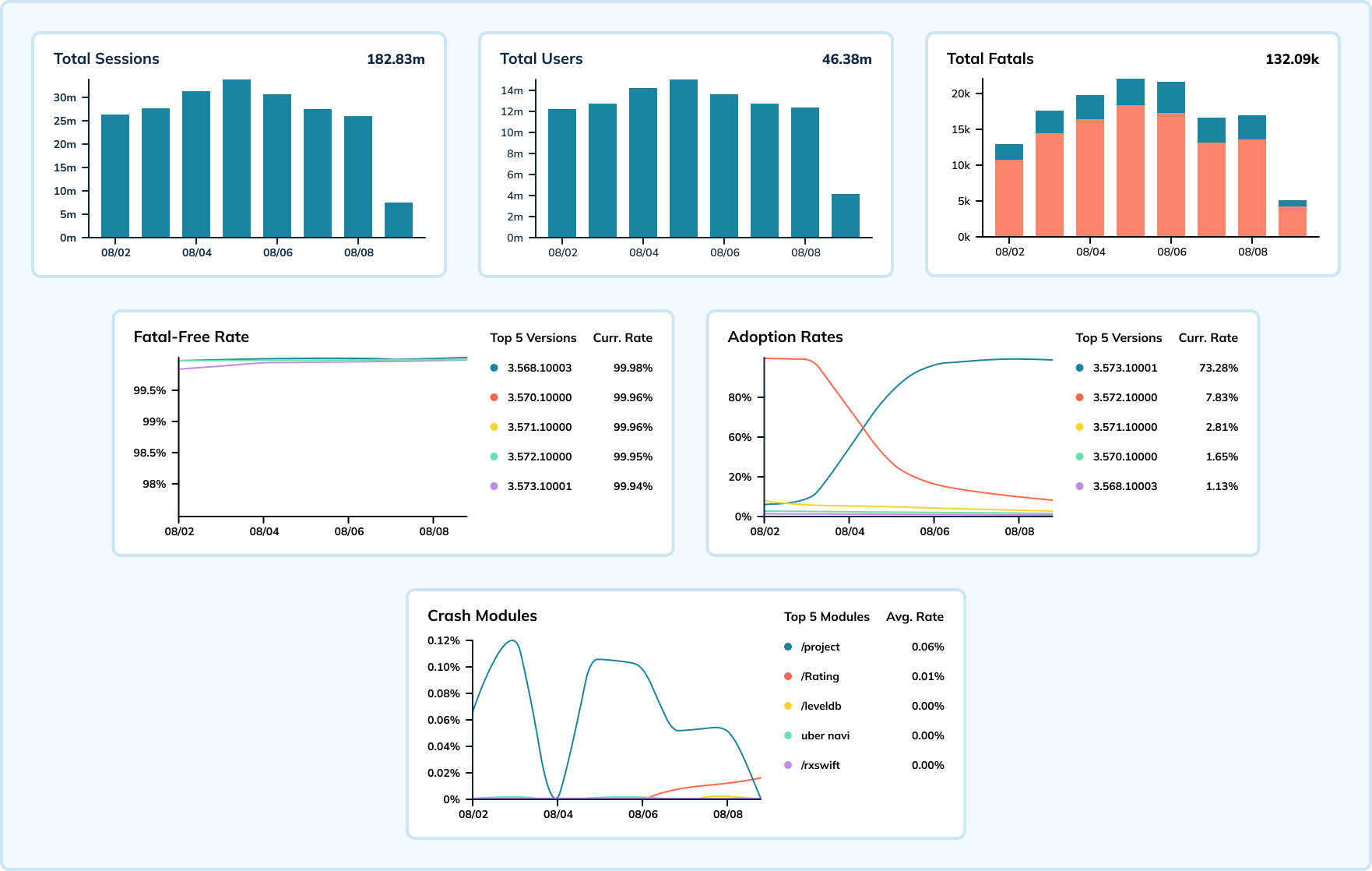
使用Elasticsearch作为通用搜索引擎时,崩溃率的激增会导致数据摄取延迟,进而延缓团队识别问题的响应速度。转向专为大规模实时分析设计的Apache Pinot后,团队观察到数据摄取延迟的数量和严重性均有所下降。
深入分析崩溃数据
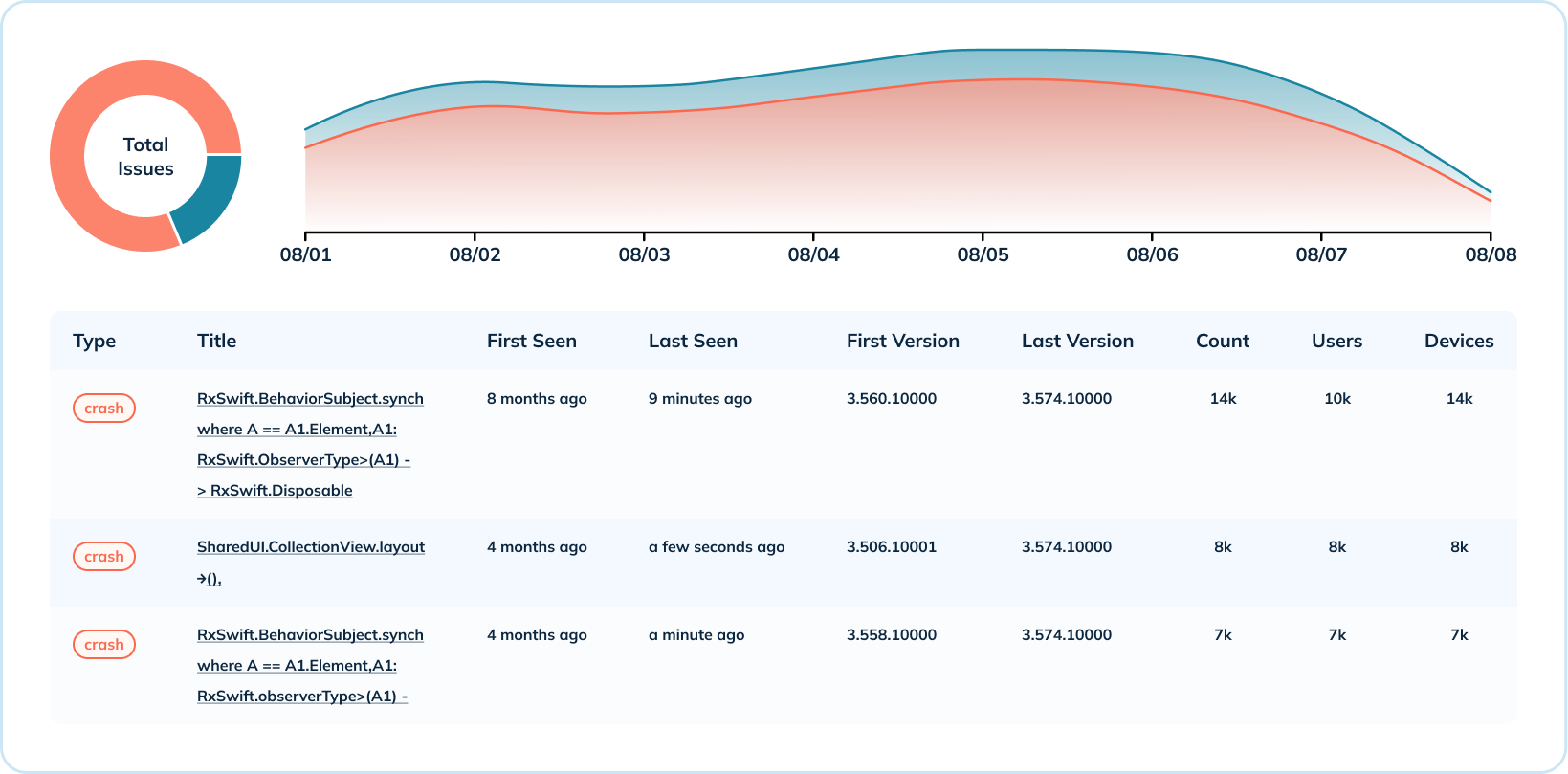
除了崩溃数据的高层次概览,Uber还提供深入的崩溃级别分析。他们跨多个维度聚合崩溃指标,例如按操作系统及版本统计的崩溃次数,以及按版本分布的崩溃情况。此用例利用了Pinot的几种索引(范围、倒排和文本),以共享特定类型的崩溃发生时间、受影响的版本、发生次数,以及受影响的用戶和设备数量。
对于深入分析而言,Uber具备文本搜索能力以解读崩溃错误信息至关重要。Pinot的文本索引基于Lucene构建,使他们能够通过崩溃信息、类名、堆栈跟踪等进行崩溃搜索。
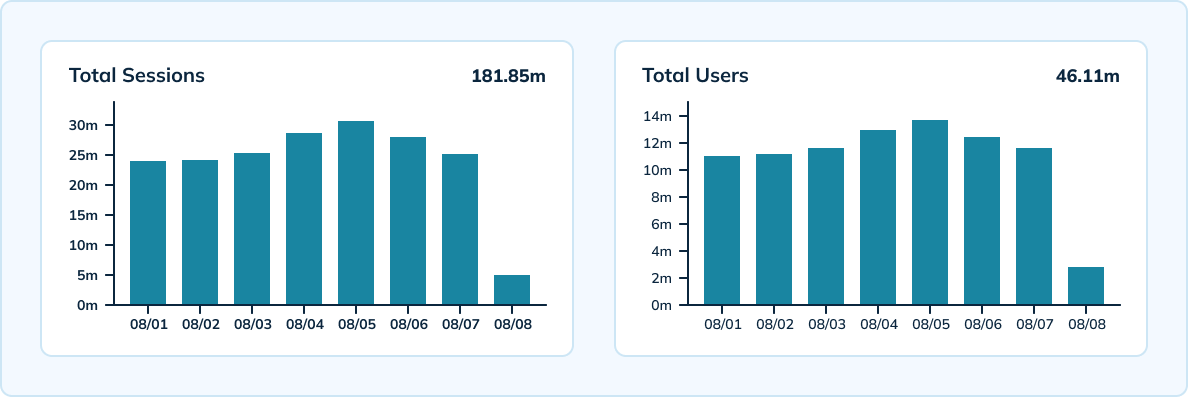
大规模测量会话
Uber还利用Pinot来大规模测量按设备、版本、操作系统及小时统计的独立会话。Pinot提供实时处理能力,具备高吞吐量,能处理Uber每秒300,000次的分析事件。团队采用混合设置,包括一个具有10分钟粒度和3天数据保留期的实时表,以及一个具有小时和日粒度且数据保留期为45天的离线表。
利用Apache Pinot的HyperLogLog,团队得以减少存储的事件数量,并在事件间进行更少的唯一聚合。Pinot还提供了极低的延迟——99.5分位的延迟低于100毫秒。
基础设施成本节约
根据Uber的计算,通过迁移至Pinot,他们每年节省了超过200万美元的基础设施成本。与Elasticsearch相比,他们的Pinot配置使得基础设施成本降低了70%。同时,CPU核心数减少了80%,数据存储量减少了66%。

在使用Elasticsearch时,Uber使用了22,000个CPU核心。迁移至Pinot后,这一数字减少了80%。以下是他们Pinot配置的快照:
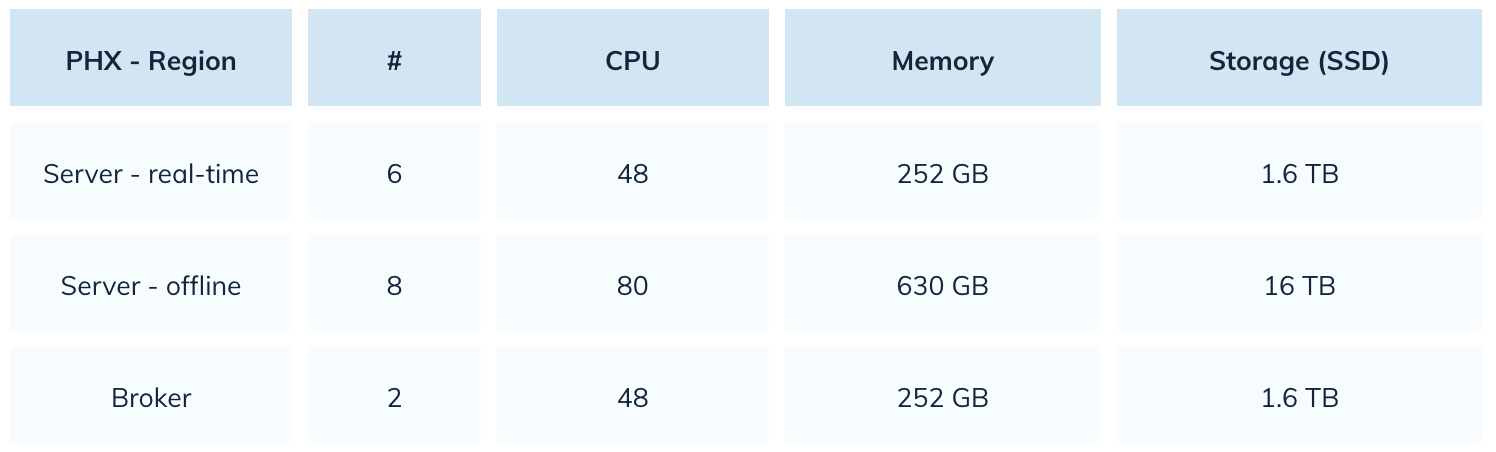
查询性能与用户体验提升
通过Apache Pinot,Uber能够提供更快的页面加载速度和更高的可靠性,从而改善用户体验。迁移至Pinot使得页面加载时间减少了64%,从14秒降至不足5秒。Pinot对于负载峰值的容忍度更高,使得延迟恢复更快。即便团队遇到数据摄取延迟,Pinot也能在几分钟内迅速恢复。
与Elasticsearch相比,Pinot在查询超时和数据丢失方面也显示出显著改进。如果在使用Elasticsearch时移动应用发生灾难性事件,相关索引的查询会超时。Uber通过控制Pinot中的分段大小解决了这一问题。与Elasticsearch在处理增加的数据摄取吞吐量时频繁出现数据问题不同,团队在使用Pinot时没有遇到数据丢失问题。
Uber Pinot配置的下一迭代
接下来,Uber计划将其移动端崩溃数据迁移至原生文本索引。这些移动端崩溃数据包含大量结构化信息,使得团队能够将所有用例迁移至原生文本索引。这一转变将节省数据存储成本,并缩短数据查询时间。
不仅Uber,其他组织也从Elasticsearch迁移到Pinot中获益匪浅
Uniqode(前身为Beaconstac)通过这一转换,整体查询性能提升了10倍。Cisco Webex在遭遇高延迟问题后,也将其实时分析和监控系统迁移至Pinot。Webex团队发现,Apache Pinot提供的延迟比Elasticsearch低5倍至150倍。
Source:
https://dzone.com/articles/real-time-app-crash-analytics-with-apache-pinot