













经典案例 1
许多软件专业人士缺乏对TCP/IP逻辑推理的深入了解,这经常导致将问题误认为是神秘问题。一些人因TCP/IP网络文献的复杂性感到沮丧,而另一些人则被Wireshark中混乱的细节所误导。例如,面临性能问题的数据库管理员可能会误解Wireshark中的数据包捕获数据,错误地得出TCP重传是问题的原因。

由于怀疑存在重传,了解其本质是至关重要的。重传基本上涉及超时重传。要确认重传是否确实是问题的原因,需要时间相关信息,而这些信息在上面的屏幕截图中没有提供。从数据库管理员那里请求了一张新的屏幕截图后,时间戳信息被包含在内。

在分析网络数据包时,时间戳信息对于准确的逻辑推理至关重要。两个重复数据包之间微秒级别的时间差表明可能是超时重传或重复数据包捕获。在典型的局域网环境中,往返时间(RTT)约为100微秒,而TCP重传至少需要一个RTT,因此在仅占RTT的1/100时发生的重传很可能是重复数据包捕获,而不是实际的超时重传。
经典案例 2
另一个经典案例展示了在网络问题分析中逻辑推理的重要性。
有一天,一名业务开发人员赶过来,说一个使用MySQL数据库中间件的定时脚本在凌晨失败了,并且没有任何响应。听到问题后,我检查了MySQL数据库中间件的错误日志,但没有找到有价值的线索。于是,我询问开发人员是否能重现这个问题,因为一旦可以重现,问题就更容易解决。
开发人员尝试多次重现问题,但没有成功。然而,他们发现了一个新发现:他们发现在白天执行相同的SQL查询时,响应时间与清晨时不同。他们怀疑当SQL响应变慢时,MySQL数据库中间件会阻塞会话,并且不向客户端返回结果。
基于这一发现,数据库操作团队被要求修改脚本的SQL以模拟缓慢的SQL响应。结果,MySQL数据库中间件在不遇到清晨时出现的挂起问题的情况下返回了结果。
一段时间内,根本原因无法确定,开发人员发现了MySQL数据库中间件的一个功能问题。因此,开发人员和数据库管理操作变得更加确信MySQL数据库中间件正在延迟响应。实际上,这些问题与MySQL数据库中间件的响应时间无关。
从第一天的事件中,问题确实出现了。所有相关人员都试图查明原因,提出各种猜测,但真正的原因仍然难以捉摸。
第二天,开发人员报告称脚本问题在清晨再次出现,然而他们在白天无法复现。由于脚本很快要在线上使用,开发人员感到压力山大,对这种情况感到抱怨。我的唯一建议是让他们在白天使用脚本,以避免在清晨出现问题。所有的怀疑都集中在MySQL数据库中间件上,从其他角度分析问题变得具有挑战性。
作为负责MySQL数据库中间件的开发人员,这种神秘问题不能轻易忽视。忽略它们可能会影响随后对MySQL数据库中间件的使用,并且还面临着领导层要求及时解决问题的压力。最终,决定实施一个低成本的数据包捕获分析解决方案:在清晨执行脚本时,在服务器上执行数据包捕获,以分析那个时候发生了什么。目标是确定MySQL数据库中间件是完全未发送响应,还是发送了客户端脚本未接收到的响应。一旦确认了MySQL数据库中间件发送了响应,问题就不会归咎于MySQL数据库中间件开发人员。
第三天,开发人员报告称,清晨的问题没有再次发生,数据包捕获分析证实问题没有发生。经过仔细考虑,似乎问题不可能仅仅出在MySQL数据库中间件上:清晨频繁发生,而白天发生很少,这让人感到困惑。唯一的处理方法是等待问题再次发生,并根据数据包捕获进行分析。
第四天,问题没有再次出现。
然而,第五天,问题最终再次出现,为解决带来了希望。
数据包捕获文件非常多。首先,要求开发人员提供问题发生时的时间戳,然后搜索大量数据包捕获数据,以确定导致问题的SQL查询。最终结果如下:
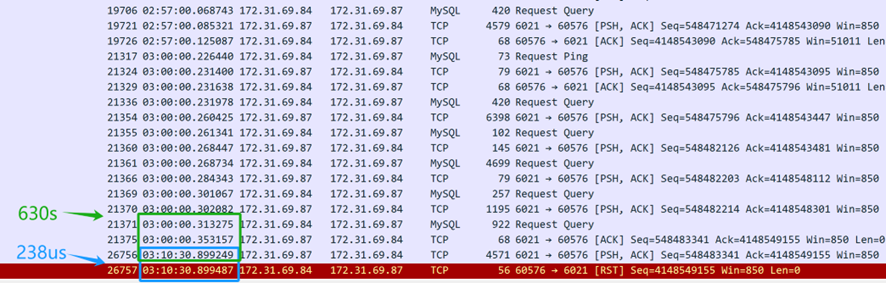
从上述的数据包捕获内容(从服务器捕获)来看,SQL查询是在凌晨3点发送的。MySQL数据库中间件花了630秒(03:10:30.899249-03:00:00.353157)将SQL响应返回给客户端,表明MySQL数据库中间件确实对SQL查询做出了响应。然而,仅仅238微秒后(03:10:30.899487-03:10:30.899249),服务器的TCP层接收到了一个复位数据包,这显得异常迅速。重要的是要注意,这个复位数据包不能立即认定是来自客户端。
首先,有必要确认是谁发送了重置数据包 — 它是由客户端发送的还是由中间设备沿途发送的。由于数据包捕获仅在服务器端执行,关于客户端数据包情况的信息不可用。通过分析服务器端的数据包捕获文件并应用逻辑推理,旨在识别问题的根本原因。
如果假设客户端发送了重置,这意味着客户端的TCP层不再识别此连接的TCP状态 — 从已建立的状态转变为不存在的状态。这种TCP状态的改变会通知客户端应用程序存在连接问题,导致客户端脚本立即出现错误。然而,在现实中,客户端脚本仍在等待响应返回。因此,假设客户端发送了重置并不成立 — 客户端并未发送重置。客户端的连接仍处于活动状态,但在服务器端,相应的连接已被重置终止。
那么,谁发送了重置呢?主要嫌疑人是亚马逊的云环境。根据这份数据包分析,数据库管理员向亚马逊客户服务查询并收到以下信息:
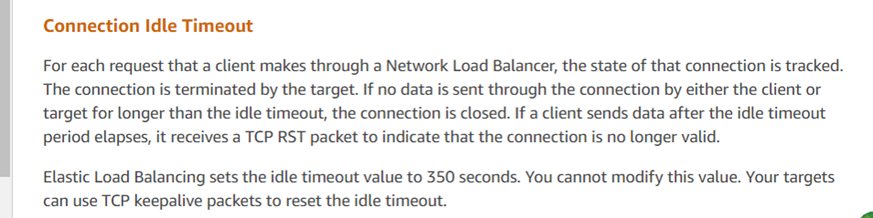
客户服务的回复与分析结果一致,表明亚马逊的ELB(弹性负载均衡器,类似于LVS)强制终止了TCP会话。根据他们的反馈,如果响应超过350秒的阈值(在数据包捕获中观察到为630秒),亚马逊的ELB设备会向响应方(在本例中为服务器)发送复位。开发人员部署的客户端脚本没有收到复位信号,并错误地认为服务器连接仍然活动。针对这类问题的官方建议包括使用TCP保活机制来缓解这些问题。
通过获得的官方回复,问题被认为已完全解决。
这个具体案例说明了在线问题可能非常复杂,需要捕获关键信息 —— 在这种情况下是数据包捕获数据 —— 以了解事情发生的情况。通过逻辑推理和归谬法的应用,找到了根本原因。
Source:
https://dzone.com/articles/logical-reasoning-in-network-problems