













学习Linux是技术行业中最具价值的技能之一。它可以帮助您更快、更高效地完成任务。世界上许多强大的服务器和超级计算机都运行在Linux上。
在学习Linux的过程中,不仅可以增强您当前的角色,还可以帮助您过渡到其他技术职业,如DevOps、网络安全和云计算。
在这本手册中,您将学习Linux命令行的基础知识,然后过渡到更高级的主题,如Shell脚本和系统管理。无论您是Linux新手还是已经使用多年的用户,这本书都有适合您的内容。
重要提示:本书中的所有示例都是在Ubuntu 22.04.2 LTS(Jammy Jellyfish)上演示的。大多数命令行工具在其他发行版上大致相同。然而,如果您在另一个Linux发行版上工作,一些GUI应用程序和命令可能会有所不同。
目录
-
第8部分:高级Linux主题
第一部分:Linux简介
1.1. 开始学习Linux
什么是Linux?
Linux是一个基于Unix操作系统的开源操作系统。它是由Linus Torvalds于1991年创建的。
开源意味着操作系统的源代码对公众开放。这使得任何人都可以修改原始代码,定制它,并将新的操作系统分发给潜在用户。
你为什么应该了解Linux?
在当今数据中心的地形中,Linux和Microsoft Windows是主要的竞争者,Linux占据了很大的份额。
以下是学习Linux的几个有力理由:
-
鉴于Linux托管的普及,你的应用程序很可能会托管在Linux上。因此,作为开发者学习Linux变得越来越有价值。
-
随着云计算成为常态,你的云实例很可能会依赖于Linux。
-
Linux为许多物联网(IoT)和移动应用程序的操作系统奠定了基础。
-
在IT领域,擅长Linux的人有很多机会。
Linux是一个开源操作系统的含义是什么?
开源软件是什么?开源软件的源代码是免费公开的,允许任何人使用、修改和分发。
每当创建源代码时,它就会自动受到版权保护,其分发受版权持有者通过软件许可来管理。
与开源相对的是专有或闭源软件,它限制了对源代码的访问。只有创建者才能查看、修改或分发。
Linux主要是开源的,这意味着其源代码是免费提供的。任何人都可以查看、修改和分发。来自世界各地的开发者可以为其改进做出贡献。这是开源软件合作的重要方面。
这种合作方式使得Linux在服务器、桌面、嵌入式系统和移动设备上得到了广泛应用。
Linux开源最有趣的是,任何人都可以根据自身特定需求定制操作系统,而不会受到专有限制的束缚。
Chromebooks所使用的Chrome OS基于Linux。全球许多智能手机的操作系统Android也是基于Linux的。
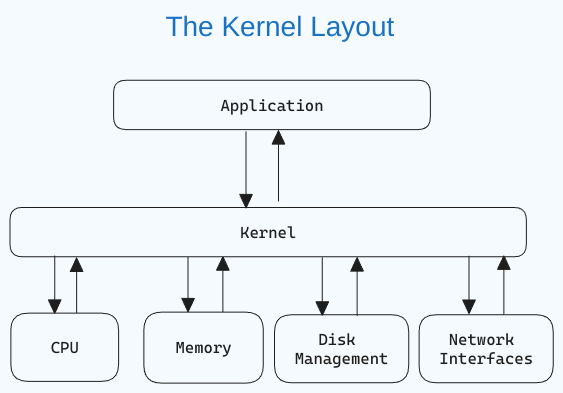
什么是Linux内核?
内核是操作系统的核心组件,负责管理计算机及其硬件操作。它处理内存操作和CPU时间。
内核作为应用程序和硬件级数据处理之间的桥梁,通过进程间通信和系统调用来处理。
当操作系统启动时,内核首先加载到内存中,并在系统关闭之前一直留在那里。它负责磁盘管理、任务管理和内存管理等工作。
如果你好奇Linux内核的样子,这里是GitHub的链接。
什么是Linux发行版?
到目前为止,你知道你可以重用Linux内核代码,修改它,并创建一个新的内核。你还可以进一步结合不同的实用工具和软件来创建一个全新的操作系统。
Linux发行版或简称distro,是包括Linux内核、系统实用工具和其他软件的Linux操作系统版本。作为一个开源项目,Linux发行版是多个独立开源开发社区协作努力的成果。
什么是发行版衍生?当你说一个发行版是“衍生”自另一个发行版时,新的发行版是基于原始发行版的基础或框架构建的。这种衍生可以包括使用相同的包管理系统(稍后再讨论),内核版本,有时甚至是相同的配置工具。
如今,有数千个Linux发行版可供选择,它们提供不同的目标和标准来选择和支持其发行版提供的软件。
不同的发行版之间有所差异,但它们通常有几个共同的特征:
-
一个发行版由Linux内核组成。
-
它支持用户空间程序。
-
一个发行版可能很小且单一用途,或者包括数千个开源程序。
-
应该提供一些安装和更新发行版及其组件的方法。
Linux发行版时间线,你会看到两个主要的发行版:Slackware和Debian。有几个发行版是从它们派生出来的。例如,Ubuntu和Kali都是从Debian派生出来的。
派生有什么优势?派生有许多优势。派生发行版可以利用父发行版的稳定性、安全性和大型软件仓库。
在现有基础上构建时,开发者可以将全部精力集中在新发行版的专业特性上。派生发行版的用户可以利用为父发行版 already available for the parent distribution.
一些流行的Linux发行版包括:
-
乌班图
: 最广泛使用和最受欢迎的Linux发行版之一。它用户友好,适合初学者。在这里了解更多关于乌班图的信息。
-
Linux Mint: 基于乌班图,Linux Mint提供了用户友好的体验,并专注于多媒体支持。在这里了解更多关于Linux Mint的信息。
-
Arch Linux: 在经验丰富的用户中很受欢迎,Arch是一个轻量级且灵活的发行版,旨在满足喜欢DIY方法的用户的需要。在这里了解更多关于Arch Linux的信息。
-
Manjaro:基于Arch Linux,Manjaro提供了预装软件和简单易用的系统管理工具,为您带来用户友好的体验。在这里了解更多关于Manjaro的信息。
-
Kali Linux:Kali Linux提供了一套全面的安全工具,主要专注于网络安全和黑客技术。在这里了解更多关于Kali Linux的信息。
如何在Linux上安装和访问
最佳的学习方法是边学边实践。在本章节中,我们将学习如何在您的计算机上安装Linux,以便您可以跟随教程进行操作。您还将学习如何在Windows计算机上访问Linux。
我建议您在本章节中选择任意一种方法来安装Linux,以便您可以跟随教程进行操作。
将Linux作为主操作系统安装
将Linux作为主操作系统安装是使用Linux最有效的方法,因为您可以充分利用计算机的性能。
在本节中,你将学习如何安装Ubuntu,这是最流行的Linux发行版之一。我暂时省略了其他发行版,因为我想保持事情的简单。一旦你熟悉了Ubuntu,你总是可以探索其他的发行版。
-
第一步 – 下载Ubuntu iso文件: 访问官方网站并下载iso文件。确保选择一个标签为“LTS”的稳定版本。LTS代表长期支持,这意味着你可以长时间(通常为5年)获得免费的安全和维护更新。
-
第二步 – 创建可启动的USB闪存盘: 有许多软件可以创建可启动的USB闪存盘。我推荐使用Rufus,因为它非常容易使用。你可以从这里下载。
- 第三步 – 从U盘启动: 一旦你的可启动U盘准备好了,插入它并从U盘启动。启动菜单取决于你的笔记本电脑。你可以谷歌搜索你的笔记本电脑型号的启动菜单。
-
第四步 – 遵循提示。 启动过程开始后,选择
尝试或安装Ubuntu。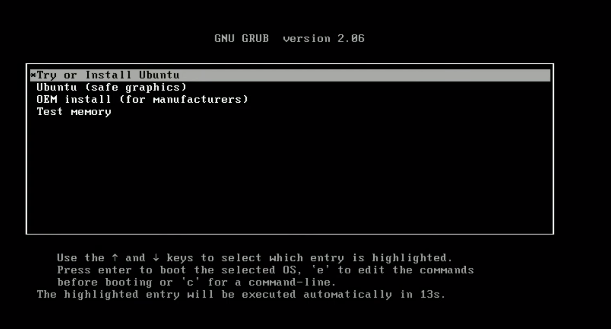
这个过程需要一些时间。一旦出现图形界面,你可以选择语言和键盘布局并继续。输入你的登录名和姓名。记住这些凭据,因为你需要它们来登录你的系统并获取完全权限。等待安装完成。
-
第五步 – 重启: 点击立即重启并移除U盘。
-
第6步 – 登录:
使用您之前输入的凭据登录。
就这样!现在您可以安装应用程序和自定义您的桌面。

对于高级安装,您可以探索以下主题:
-
磁盘分区。
-
设置交换内存以启用休眠。
访问终端
本手册的一个重要部分是了解终端,您将在那里运行所有命令并见证神奇的发生。您可以通过按“Windows”键并输入“terminal”来搜索终端。您可以将终端固定在停靠区,以便轻松访问其他应用程序的位置。
💡 打开终端的快捷键是
ctrl+alt+t
您还可以从文件夹内部打开终端。在您所在的位置右键单击,然后选择“在终端中打开”。这将打开终端并在同一路径下。
如何在Windows机器上使用Linux
有时您可能需要在Windows和Linux之间并行运行。幸运的是,有一些方法可以让您在不为每个操作系统购买不同电脑的情况下,充分利用这两个世界。
在本节中,您将探索在Windows机器上使用Linux的几种方法。其中一些是基于浏览器或云的,无需在使用之前安装任何操作系统。
选项1:“双启动”Linux + Windows通过双启动,您可以在计算机上与Windows并列安装Linux,让您在启动时选择使用哪个操作系统。
这需要对硬盘进行分区,并在另一个分区上安装Linux。采用这种方法,您一次只能使用一个操作系统。
选项2:使用Windows Subsystem for Linux (WSL)Windows Subsystem for Linux提供了一个兼容层,可以让您在Windows上本地运行Linux二进制可执行文件。
使用WSL有一些优势。WSL的设置简单且耗时短。与需要从宿主机器分配资源的虚拟机相比,它更轻量级。您不需要为Linux机器安装ISO或虚拟磁盘映像,这些通常是大型文件。您可以并行使用Windows和Linux。
如何安装WSL2
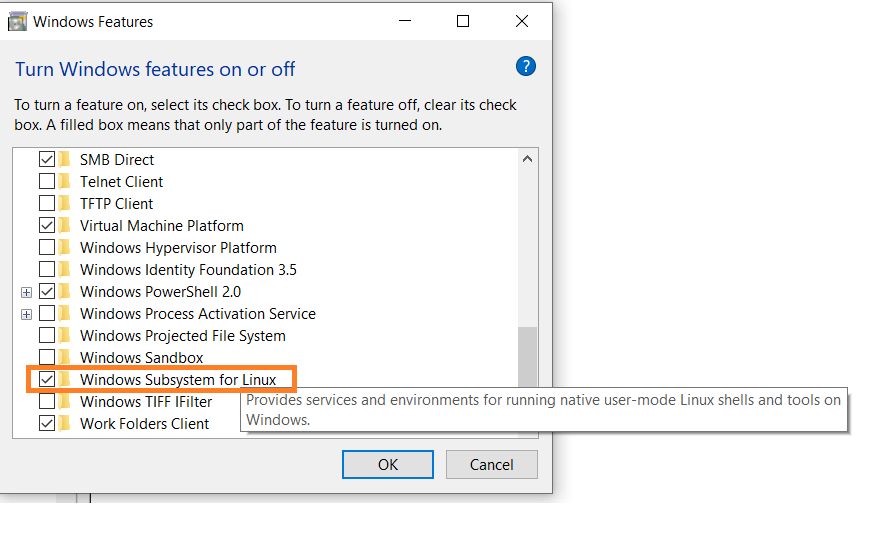
首先,在设置中启用Linux子系统。
-
点击开始菜单。搜索”打开或关闭Windows功能”。
-
如果尚未勾选,请勾选”Windows Subsystem for Linux”选项。
-
接下来,打开您的命令提示符并输入安装命令。
-
以管理员身份打开命令提示符:

-
运行以下命令:
wsl --install
这是输出结果:
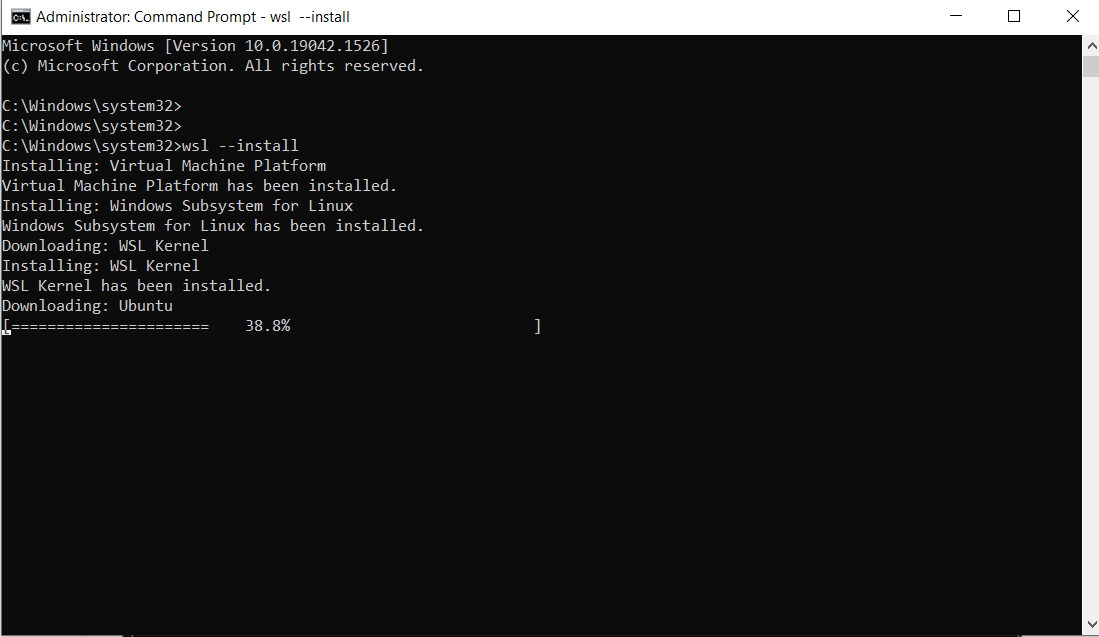
注意:默认情况下,将安装Ubuntu。
- 安装完成后,您需要重新启动Windows计算机。因此,请重新启动您的Windows计算机。
重启后,您可能会看到这样的窗口:
Ubuntu安装完成后,您将被提示输入用户名和密码。

然后,就绪!您可以使用Ubuntu了。
从开始菜单搜索以启动Ubuntu。
Ubuntu实例已启动。

选项3:使用虚拟机(VM)
虚拟机(VM)是物理计算机系统的软件模拟。它允许您在单一物理机器上同时运行多个操作系统和应用程序。
您可以使用虚拟化软件(如Oracle VirtualBox或VMware)在Windows环境中创建运行Linux的虚拟机。这使您能够在Windows旁边以访客操作系统身份运行Linux。
虚拟机软件提供了为每个虚拟机分配和管理硬件资源的选项,包括CPU核心、内存、磁盘空间和网络带宽。您可以根据客户操作系统和应用程序的需求调整这些分配。
以下是常见的虚拟化选项:
选项4:使用基于浏览器的解决方案
基于浏览器的解决方案特别适合快速测试、学习或从没有安装Linux的设备访问Linux环境。
您可以使用在线代码编辑器或基于网络的终端来访问Linux。请注意,在这些情况下,您通常没有完全的管理权限。
在线代码编辑器
在线代码编辑器提供了内置的Linux终端。尽管它们的主要目的是编程,但您也可以使用Linux终端来执行命令和完成任务。
Replit是一个在线代码编辑器的例子,您可以在其中编写代码的同时访问Linux壳。
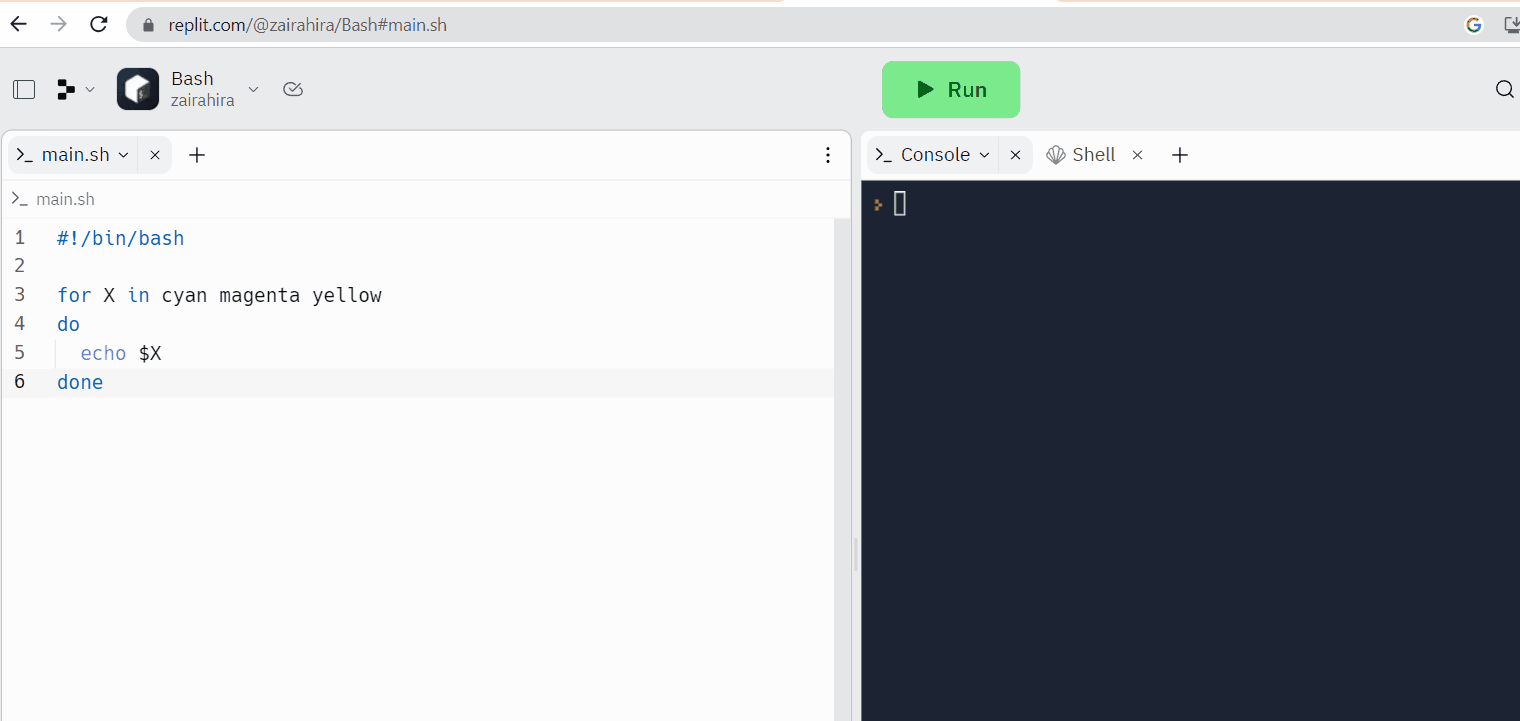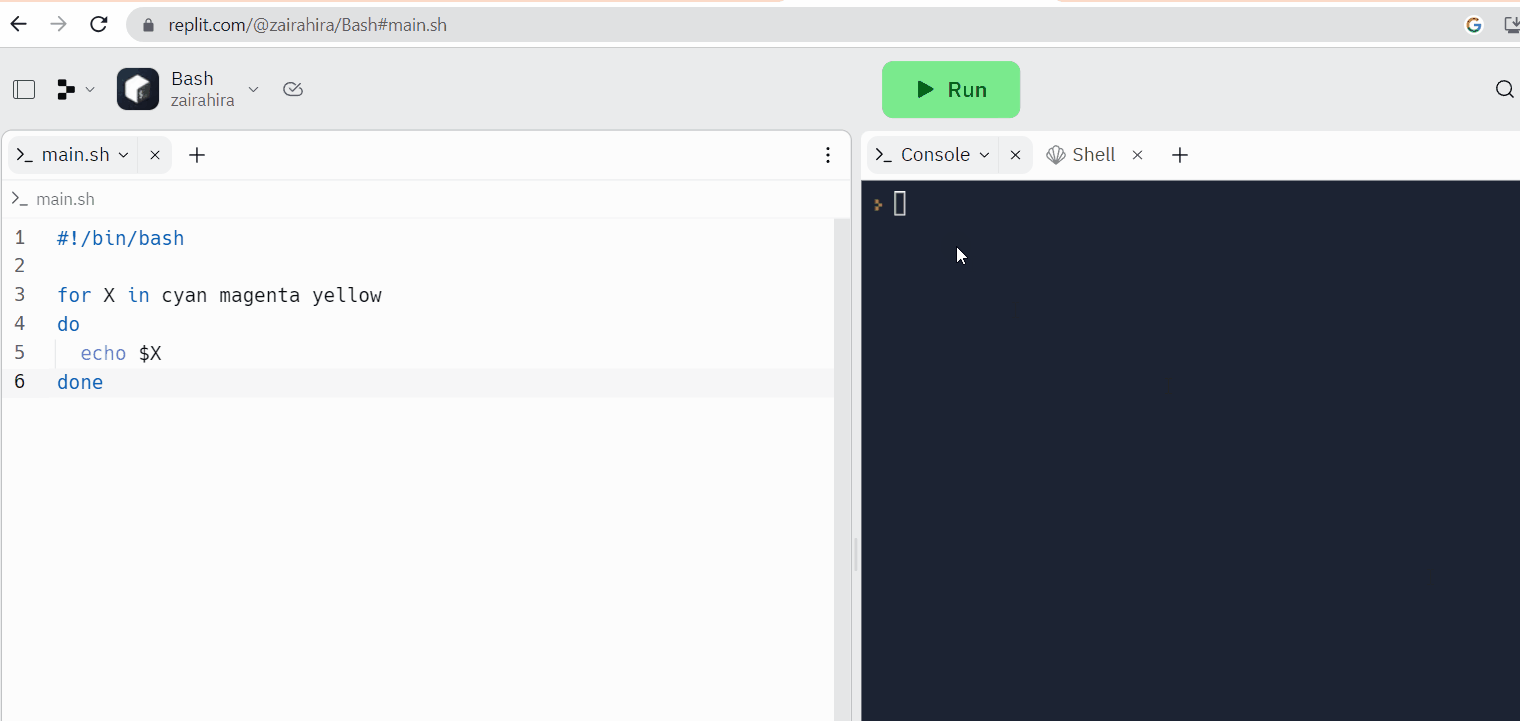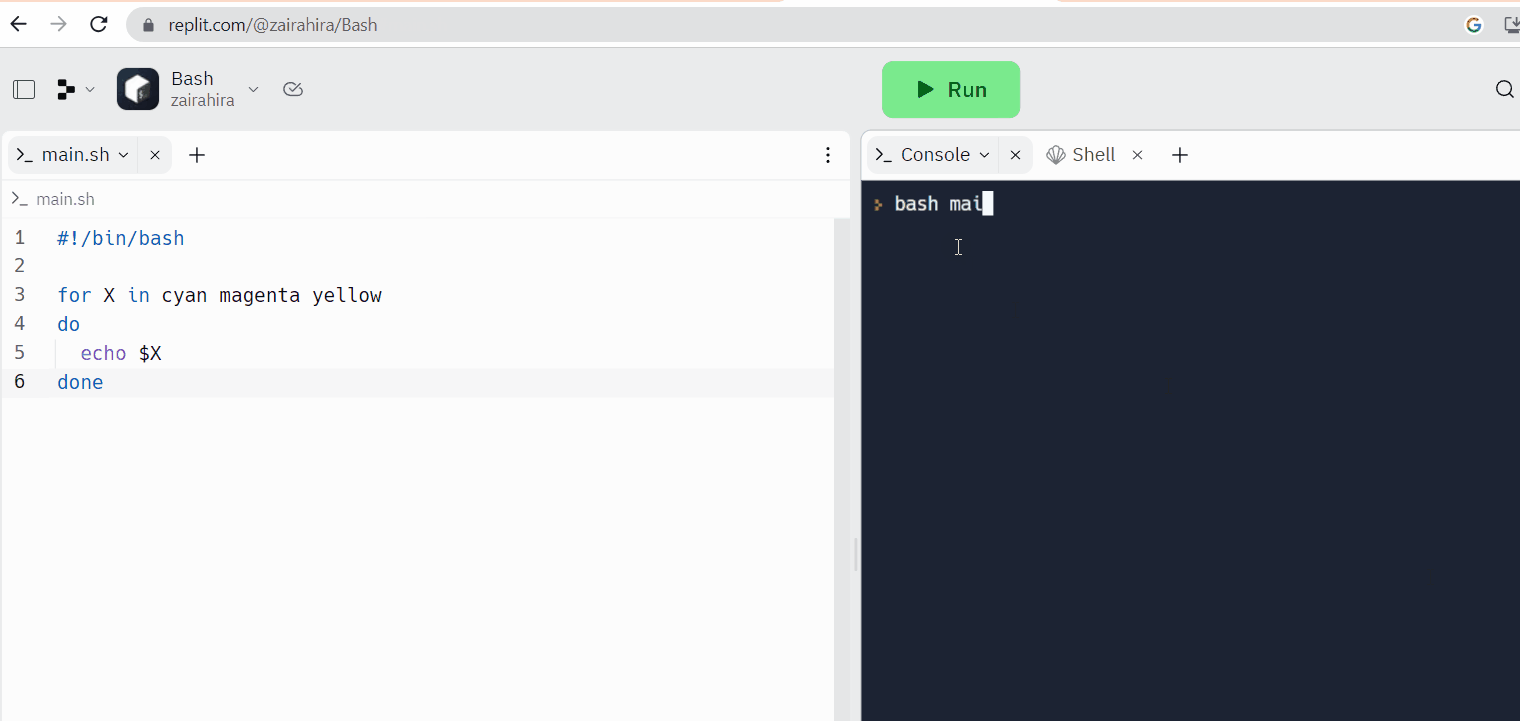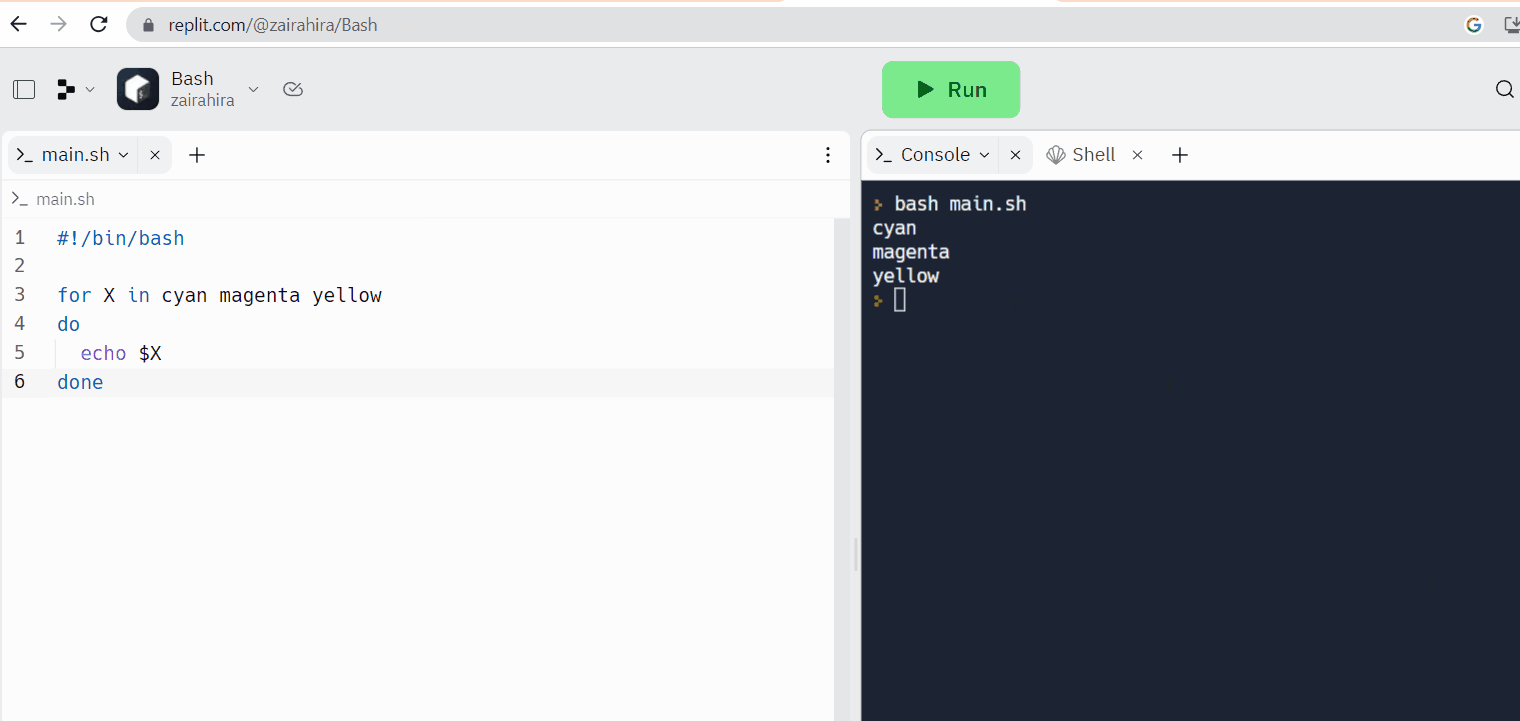
基于网页的Linux终端:
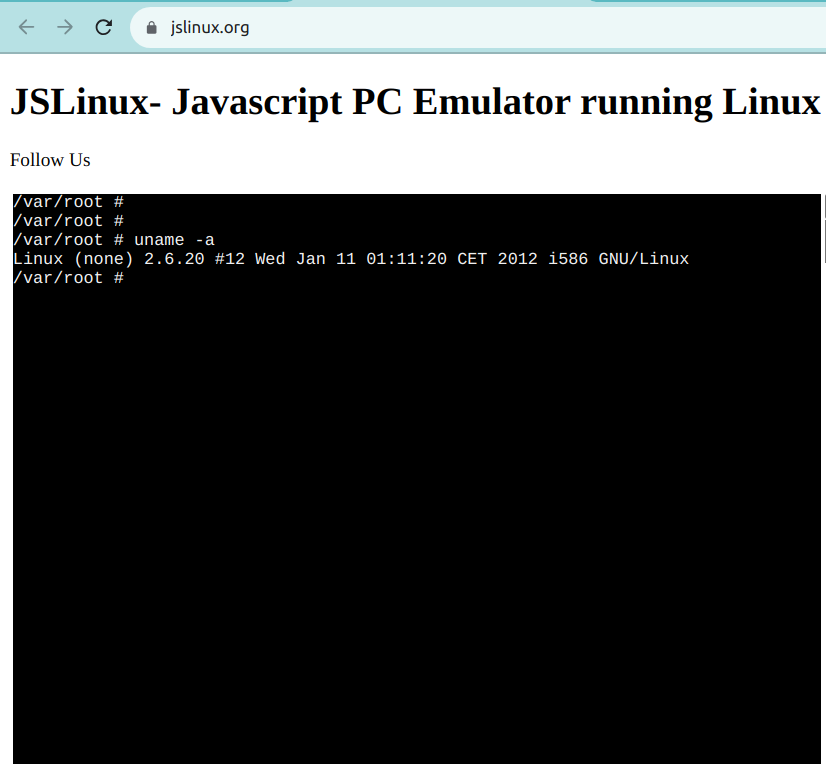
在线Linux终端允许您直接从浏览器访问Linux命令行界面。这些终端为Linux壳提供了一个基于网页的界面,使您可以执行命令并使用Linux实用程序。
一个这样的例子是JSLinux。下面的屏幕截图显示了一个准备好的Linux环境:
选项5:使用基于云的解决方案
与其直接在您的Windows机器上运行Linux,您可以考虑使用基于云的Linux环境或虚拟专用服务器(VPS)来远程访问和工作。
像Amazon EC2、Microsoft Azure或DigitalOcean这样的服务提供了您可以从您的Windows计算机连接到的Linux实例。请注意,这些服务中的一些提供免费层,但它们通常不是长期免费的。
第二部分:Bash壳和系统命令简介
2.1. Bash壳入门
Bash壳简介
Linux命令行是由一个称为shell的程序提供的。多年来,shell程序已经发展出多种版本,以满足不同选项的需求。
不同的用户可以配置使用不同的shell。但是,大多数用户更喜欢坚持使用当前的默认shell。许多Linux发行版的默认shell是GNU Bourne-Again Shell(bash)。Bash继承自Bourne shell(sh)。
要找出你当前的shell,打开你的终端并输入以下命令:
echo $SHELL
命令分解:
-
echo命令用于在终端上打印。 -
$SHELL是一个特殊变量,保存着当前shell的名称。
在我的设置中,输出是/bin/bash。这意味着我正在使用bash shell。
# 输出
echo $SHELL
/bin/bash
Bash非常强大,因为它可以简化一些通过图形用户界面(GUI)难以高效完成的操作。请记住,大多数服务器没有GUI,最好学会使用命令行界面(CLI)的力量。
终端与Shell
“终端”和“shell”这两个词经常被交替使用,但它们指的是命令行界面的不同部分。
终端是您用来与shell交互的界面。Shell是处理和执行您的命令的命令解释器。您将在手册的第6部分了解更多关于shell的知识。
提示是什么?
当shell以交互方式使用时,当等待用户命令时,它会显示一个$。这被称为shell提示。
[username@host ~]$
如果shell以root身份运行(您将在后面学到更多关于root用户的知识),提示会更改为#。
[root@host ~]#
2.2. 命令结构
命令是执行特定操作的程序。一旦您可以访问shell,您可以在$符号后输入任何命令,并在终端上看到输出。
一般来说,Linux命令遵循以下语法:
command [options] [arguments]
以下是上述语法的分解:
-
command:这是您想要执行的命令的名称。ls(列出)、cp(复制)和rm(删除)是常见的Linux命令。 -
[选项]:选项,或标志,通常前面有一个连字符(-)或双连字符(–),用于修改命令的行为。它们可以改变命令的运行方式。例如,ls -a使用-a选项在当前目录中显示隐藏文件。 -
[参数]:参数是命令需要的输入。这些可以是文件名、用户名或其他命令将对其采取行动的数据。例如,在命令cat access.log中,cat是命令,access.log是输入。因此,cat命令显示access.log文件的内容。
并非所有命令都需要选项和参数。一些命令可以不带任何选项或参数运行,而其他命令可能需要一个或两个才能正确运行。您总是可以查阅命令的手册来查看它支持哪些选项和参数。
💡小贴士:您可以使用 man 命令查看命令的手册。
您可以使用 man ls 命令访问 ls 的手册页,它会显示如下:

手册页是获取文档资料快捷的好方法。我强烈建议您阅读您最常用的命令的手册页。
2.3. Bash 命令和键盘快捷键
在终端中,您可以通过使用快捷键来加速您的任务。
以下是一些最常见的终端快捷键:
| 操作 | 快捷键 |
| 查找前一个命令 | 向上箭头 |
| 跳到上一个单词的开头 | Ctrl+左箭头 |
| 从光标位置到命令行末尾清除字符 | Ctrl+K |
| 补全命令、文件名和选项 | 按 Tab 键 |
| 跳到命令行开头 | Ctrl+A |
| 显示以前命令的列表 | history |
2.4. 标识自己:whoami 命令
您可以使用 whoami 命令获取您登录的用户名。这个命令在您切换不同用户时很有用,用于确认当前用户。
在 $ 符号后,输入 whoami 并按回车。
whoami
这是我的输出结果。
zaira@zaira-ThinkPad:~$ whoami
zaira
第3部分:了解您的Linux系统
3.1. 探索您的操作系统和规格
使用uname命令打印系统信息
您可以从uname命令获取详细的系统信息。
当你提供-a选项时,它会打印出所有的系统信息。
uname -a
# 输出
Linux zaira 6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
在上述输出中,
-
Linux:表示操作系统。 -
zaira:表示机器的主机名。 6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2:提供了关于内核版本、构建日期和其他一些详细信息。-
x86_64 x86_64 x86_64:表示系统的架构。 -
GNU/Linux:表示操作系统类型。
使用lscpu命令查找CPU架构的详细信息
在Linux中,lscpu命令用于显示CPU架构的信息。当你在终端中运行lscpu时,它会提供诸如:
-
CPU的架构(例如,x86_64)
-
CPU的操作模式(例如,32位,64位)
-
字节顺序(例如,小端)
-
CPU(s)(CPU的数量),等等
让我们试一试:
lscpu
# 输出
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 5500U with Radeon Graphics
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 1
CPU max MHz: 4056.0000
CPU min MHz: 400.0000
信息量很大,但也很有用!记得你总是可以用特定的标志快速浏览相关信息。查看命令手册,使用man lscpu。
第4部分:从命令行管理文件
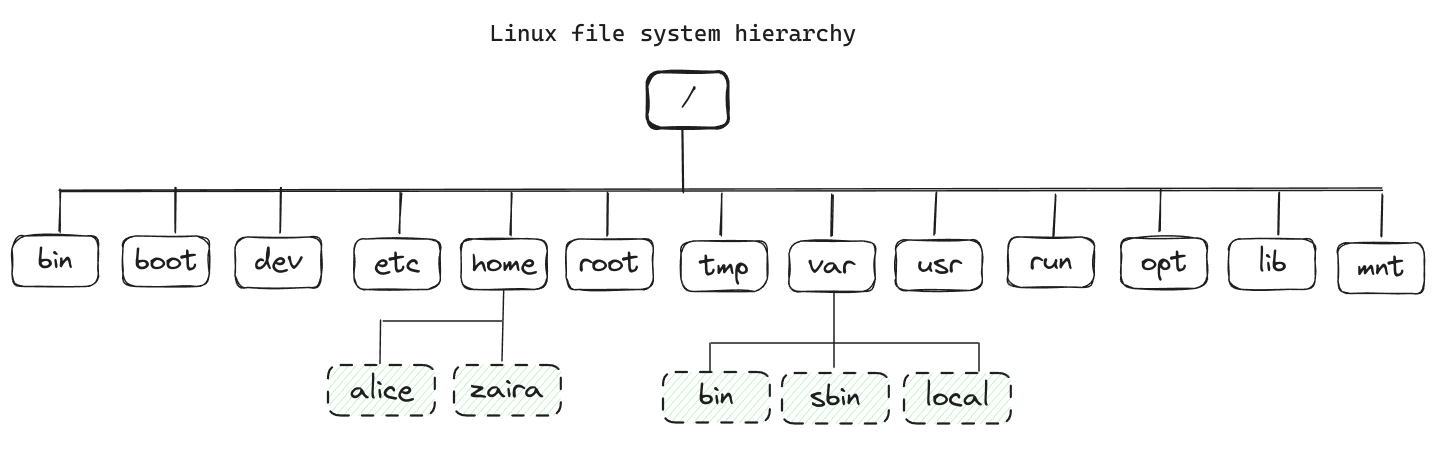
4.1. Linux文件系统层次结构
Linux中的所有文件都存储在文件系统中。它遵循一个倒置的树状结构,因为根在最顶部。
根目录/是文件系统的根目录,也是系统上所有其他目录和文件的起点。/字符也作为路径名之间的目录分隔符。例如,/home/alice形成了一个完整的路径。
以下是完整的文件系统层次结构。每个目录都有其特定的用途。
请注意,这不是一个详尽的列表,不同的发行版可能有不同的配置。
下面是一个表格,展示了每个目录的目的:
| 位置 | 用途 |
| /bin | 基本命令的二进制文件 |
| /boot | 启动加载器的静态文件,用于启动引导过程。 |
| /etc | 特定于主机的系统配置 |
| /home | 用户主目录 |
| /root | 管理员root用户的主目录 |
| /lib | 基本的共享库和内核模块 |
| /mnt | 临时挂载文件系统的挂载点 |
| /opt | 附加的应用软件包 |
| /usr | 已安装的软件和共享库 |
| /var | 在启动之间持久的变量数据 |
| /tmp | 所有用户可访问的临时文件 |
💡 提示:您可以使用 man hier 命令了解更多关于文件系统的信息。
您可以使用 tree -d -L 1 命令检查您的文件系统。您可以修改 -L 标志来改变树的结构深度。
tree -d -L 1
# 输出
.
├── bin -> usr/bin
├── boot
├── cdrom
├── data
├── dev
├── etc
├── home
├── lib -> usr/lib
├── lib32 -> usr/lib32
├── lib64 -> usr/lib64
├── libx32 -> usr/libx32
├── lost+found
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin -> usr/sbin
├── snap
├── srv
├── sys
├── tmp
├── usr
└── var
25 directories
此列表并不全面,不同的发行版和系统可能配置不同。
4.2. 浏览 Linux 文件系统
绝对路径与相对路径
绝对路径是从根目录到文件或目录的完整路径。它总是以一个 / 开始。例如,/home/john/documents。
另一方面,相对路径是从当前目录到目标文件或目录的路径。它不以 / 开始。例如,documents/work/project。
使用 pwd 命令定位当前目录
在 Linux 文件系统中,尤其是在命令行界面新手可能会迷路。您可以使用 pwd 命令来定位当前目录。
以下是示例:
pwd
# 输出
/home/zaira/scripts/python/free-mem.py
使用 cd 命令更改目录
更改目录的命令是 cd,它代表“更改目录”。您可以使用 cd 命令导航到不同的目录。
您可以使用相对路径或绝对路径。
例如,如果您想要导航下面的文件结构(沿着红色线条):
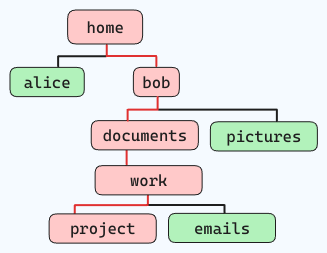
并且您现在站在 “home” 目录下,命令就像这样:
cd home/bob/documents/work/project
一些其他常用的 cd 快捷方式包括:
| 命令 | 描述 |
cd .. |
返回上一级目录 |
cd ../.. |
返回上两级目录 |
cd 或 cd ~ |
回到主页目录 |
cd - |
返回上一个路径 |
4.3. 管理文件和目录
在处理文件和目录时,您可能需要复制、移动、删除和创建新的文件和目录。以下是一些可以帮助您完成这些任务的命令。
💡提示:您可以通过查看 ls -l 输出的第一封信来区分文件和文件夹。一个'-'代表一个文件,而一个'd'代表一个文件夹。
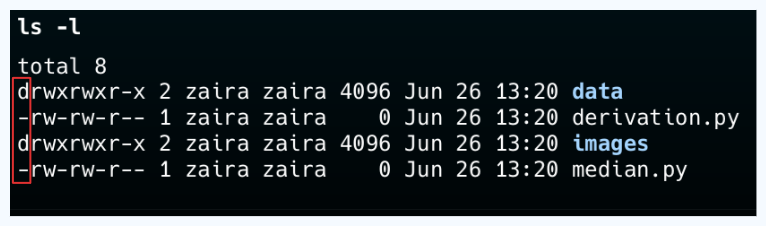
使用 mkdir 命令创建新目录
您可以使用 mkdir 命令创建一个空目录。
# 在当前文件夹中创建一个名为 "foo" 的空目录
mkdir foo
您还可以使用 -p 选项递归创建目录。
mkdir -p tools/index/helper-scripts
# tree 命令的输出
.
└── tools
└── index
└── helper-scripts
3 directories, 0 files
使用 touch 命令创建新文件
touch 命令用于创建一个空文件。您可以这样使用它:
# 在当前文件夹中创建一个名为 "file.txt" 的空文件
touch file.txt
如果需要一次性创建多个文件,文件名可以连锁使用。
# 在当前文件夹中创建空文件 "file1.txt"、"file2.txt" 和 "file3.txt"
touch file1.txt file2.txt file3.txt
使用 `rm` 和 `rmdir` 命令删除文件和目录
您可以使用 `rm` 命令来删除文件和非空目录。
| 命令 | 描述 |
rm file.txt |
删除文件 `file.txt` |
rm -r directory |
删除目录 `directory` 及其内容 |
rm -f file.txt |
不需确认直接删除文件 `file.txt` |
rmdir directory |
删除空目录 |
🛑 注意,您应谨慎使用 `-f` 标志,因为您在删除文件之前不会被提示。同样,当在 `root` 目录中运行 `rm` 命令时要小心,这可能会导致删除重要的系统文件。
使用 `cp` 命令复制文件
要在 Linux 中复制文件,请使用 `cp` 命令。
- 复制文件的语法:
cp source_file destination_of_file
此命令将名为 `file1.txt` 的文件复制到新文件位置 `/home/adam/logs`。
cp file1.txt /home/adam/logs
`cp` 命令也会根据提供的名称创建一个文件的副本。
此命令将一个名为file1.txt的文件复制到同一文件夹中的另一个文件file2.txt。
cp file1.txt file2.txt
使用mv命令移动和重命名文件和文件夹
mv命令用于将文件和文件夹从一个目录移动到另一个目录。
移动文件的语法:mv source_file destination_directory
示例: 将一个名为file1.txt的文件移动到一个名为backup的目录中:
mv file1.txt backup/
要移动目录及其内容:
mv dir1/ backup/
在Linux中,使用mv命令也可以重命名文件和文件夹。
重命名文件的语法:mv old_name new_name
示例: 将文件从file1.txt重命名为file2.txt:
mv file1.txt file2.txt
将目录从dir1重命名为dir2:
mv dir1 dir2
4.4 使用find命令查找文件和文件夹
find命令让您有效地搜索文件、文件夹以及字符和块设备。
以下是find命令的基本语法:
find /path/ -type f -name file-to-search
其中,
-
/path是要查找文件的路径。这是搜索文件的起点。该路径还可以是/或.,分别代表根目录和当前目录。 -type表示文件描述符。它们可以是以下任意一种:
f– 普通文件,如文本文件、图片和隐藏文件。
d– 目录。这些是要考虑的文件夹。
l– 符号链接。符号链接指向文件,类似于快捷方式。
c– 字符设备。用于访问字符设备的文件称为字符设备文件。驱动程序通过发送和接收单个字符(字节、八位组)与字符设备进行通信。例如包括键盘、声卡和鼠标。
b– 块设备。用于访问块设备的文件称为块设备文件。驱动程序通过发送和接收整个数据块与块设备进行通信。例如包括USB和CD-ROM。-name是要搜索的文件类型的名称。如何按名称或扩展名搜索文件
假设我们需要找到包含 “style” 在其名称中的文件。我们将使用以下命令:
find . -type f -name "style*"
#output
./style.css
./styles.css
现在假设我们想要找到具有特定扩展名(如 .html)的文件。我们将修改命令如下:
find . -type f -name "*.html"
# output
./services.html
./blob.html
./index.html
如何搜索隐藏文件
文件名开头的小点表示隐藏文件。它们通常是隐藏的,但在当前目录下可以使用 `ls -a` 查看。
我们可以像下面这样修改 `find` 命令来查找隐藏文件:
find . -type f -name ".*"
列出并查找隐藏文件
ls -la
# 文件夹内容
total 5
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:17 .
drwxr-x--- 61 zaira zaira 4096 Mar 26 14:12 ..
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_history
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_logout
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bashrc
find . -type f -name ".*"
# find 命令输出
./.bash_logout
./.bashrc
./.bash_history
如你所见,上面显示了我家目录下的隐藏文件列表。
如何搜索日志文件和配置文件
日志文件通常有 `.log` 的扩展名,我们可以这样找到它们:
find . -type f -name "*.log"
同样,我们也可以这样搜索配置文件:
find . -type f -name "*.conf"
如何按类型搜索其他文件
我们可以通过向 `-type` 提供 `c` 来查找字符块文件:
find / -type c
同样,我们可以通过使用 `b` 来找到设备块文件:
find / -type b
如何搜索目录
在下面的例子中,我们通过使用 `-type d` 标志来查找文件夹。
ls -l
# 列出文件夹内容
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 hosts
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:23 hosts.txt
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 images
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:23 style
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 webp
find . -type d
# find 目录输出
.
./webp
./images
./style
./hosts
如何按大小搜索文件
`find` 命令的一个非常实用的功能是基于特定大小列出文件。
find / -size +250M
这里,我们列出大小超过 `250MB` 的文件。
其他单位包括:
-
G: 吉字节(GigaBytes)。 -
M:兆字节。 -
K:千字节 -
c:字节。
只需替换为相应的单位。
find <directory> -type f -size +N<Unit Type>
如何按修改时间搜索文件
使用-mtime标志,可以根据修改时间过滤文件和文件夹。
find /path -name "*.txt" -mtime -10
例如,
-
-mtime +10 表示你要找的是10天前修改的文件。
-
-mtime -10 表示少于10天。
-
-mtime 10 如果你省略了+或–,它表示正好10天。
4.5. 文件查看的基本命令
使用cat命令连接并显示文件
在Linux中,cat命令用于显示文件的内容。它还可以用于连接文件和创建新文件。
以下是cat命令的基本语法:
cat [options] [file]
使用cat的最简单方法是不带任何选项或参数。这将会在终端上显示文件的 contents。
例如,如果您想查看一个名为file.txt的文件内容,可以使用以下命令:
cat file.txt
这将在终端上一次性显示文件的的所有内容。
使用less和more命令交互式查看文本文件
cat命令一次性显示整个文件,而less和more命令允许您交互式地查看文件内容。这在您需要滚动大型文件或搜索特定内容时非常有用。
less命令的语法如下:
less [options] [file]
more命令与less命令类似,但功能较少。它用于显示文件内容,一次显示一屏。
more命令的语法如下:
more [options] [file]
对于这两个命令,您可以使用空格键逐页滚动,使用回车键逐行滚动,以及使用q键退出查看器。
要向后移动,可以使用b键,向前移动可以使用f键。
使用tail命令显示文件的最后部分
有时您可能只需要查看文件的最后一部分而不是整个文件。Linux中的tail命令用于显示文件的末尾部分。
例如,tail file.txt命令将默认显示文件file.txt的最后10行。
如果您想要显示不同数量的行,您可以使用 `-n` 选项,后面跟着您想要显示的行数。
# 显示文件 file.txt 的最后 50 行
tail -n 50 file.txt
💡提示:`tail` 的另一种用法是它的跟随(`-f`)选项。这个选项允许您在文件内容被写入时查看文件内容。这对于实时查看和监控日志文件非常有用。
使用 `head` 命令显示文件的开头
就像 `tail` 显示文件的最后部分一样,您可以在 Linux 中使用 `head` 命令来显示文件的开头。
例如,`head file.txt` 默认会显示文件 `file.txt` 的前 10 行。
要更改显示的行数,您可以使用 `-n` 选项,后面跟着您想要显示的行数。
使用 `wc` 命令统计单词、行和字符
您可以使用 `wc` 命令在文件中统计单词、行和字符。
例如,运行 `wc syslog.log` 给了我以下输出:
1669 9623 64367 syslog.log
在上面的输出中,
-
1669代表文件 `syslog.log` 的行数。 -
9623代表文件 `syslog.log` 中的单词数。 -
64367代表文件syslog.log中的字符数量。
因此,命令 wc syslog.log 统计了文件 syslog.log 中的 1669 行、9623 个单词和 64367 个字符。
使用 diff 命令逐行比较文件
在 Linux 中,比较两个文件并找出它们之间的差异是一个常见的任务。你可以在命令行中直接使用 diff 命令来比较两个文件。
diff 命令的基本语法是:
diff [options] file1 file2
这里有两个文件,hello.py 和 also-hello.py,我们将使用 diff 命令来比较它们:
# hello.py 的内容
def greet(name):
return f"Hello, {name}!"
user = input("Enter your name: ")
print(greet(user))
# also-hello.py 的内容
more also-hello.py
def greet(name):
return fHello, {name}!
user = input(Enter your name: )
print(greet(user))
print("Nice to meet you")
- 检查文件是否相同或不同
diff -q hello.py also-hello.py
# 输出
Files hello.py and also-hello.py differ
- 看看文件之间的差异。为此,你可以使用
-u标志来查看统一输出:
diff -u hello.py also-hello.py
--- hello.py 2024-05-24 18:31:29.891690478 +0500
+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500
@@ -3,4 +3,5 @@
user = input(Enter your name: )
print(greet(user))
+print("Nice to meet you")
— hello.py 2024-05-24 18:31:29.891690478 +0500
- 在上面的输出中:
--- hello.py 2024-05-24 18:31:29.891690478 +0500指示正在比较的文件及其时间戳。+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500指示另一个正在比较的文件及其时间戳。@@ -3,4 +3,5 @@显示发生更改的行号。在这种情况下,它表示原始文件中的第3到4行已更改为修改后文件中的第3到5行。user = input(Enter your name: )是原始文件中的一行。print(greet(user))是原始文件中的另一行。
+print("Nice to meet you")是修改后文件中的附加行。
diff -y hello.py also-hello.py
要以并排格式查看差异,可以使用 -y 标志:
def greet(name): def greet(name):
return fHello, {name}! return fHello, {name}!
user = input(Enter your name: ) user = input(Enter your name: )
print(greet(user)) print(greet(user))
> print("Nice to meet you")
# 输出
- 在输出中:
- 两个文件中相同的行将并排显示。
不同的行将用>符号显示,表示该行只存在于其中一个文件中。
第五部分:Linux文本编辑的基本技巧
使用命令行的文本编辑技巧是Linux中最关键的技能之一。在本节中,您将学习如何在Linux中使用两个流行的文本编辑器:Vim和Nano。
我建议您精通您选择的任何一种文本编辑器,并坚持使用它。这将为您节省时间并提高您的效率。Vim和nano是安全的选择,因为它们存在于大多数Linux发行版中。
5.1. 精通Vim:完整指南
Vim简介
- Vim是命令行下流行的文本编辑工具。Vim具有其优势:它功能强大、可定制且速度快。以下是您应该考虑学习Vim的一些原因:
- 大多数服务器通过CLI访问,因此在系统管理中,您不一定有GUI的奢侈。但Vim将为您提供支持——它总会陪伴在您身边。
- Vim使用键盘为中心的方法,设计为无需鼠标操作,一旦掌握了键盘快捷键,可以显著加快编辑任务的速度。这也使它比GUI工具更快。
- 一些Linux实用程序(例如编辑cron作业)使用与Vim相同的编辑格式。
Vim适用于所有人-初学者和高级用户。Vim支持复杂的字符串搜索、搜索高亮等等。通过插件,Vim为开发人员和系统管理员提供了扩展功能,包括代码补全、语法高亮、文件管理、版本控制等。
Vim有两个变体:Vim(vim)和Vim Tiny(vi)。Vim Tiny是Vim的简化版本,缺少一些功能。
如何开始使用vim
vim your-file.txt
使用以下命令开始使用Vim:
your-file.txt可以是一个新文件或者您想要编辑的现有文件。
在Vim中导航:掌握移动和命令模式
在命令行界面(CLI)的早期,键盘上并没有箭头键。因此,导航是通过使用一系列可用的键来完成的,其中hjkl就是其中之一。
由于Vim是以键盘为中心的,使用hjkl键可以大大加快文本编辑任务的速度。
注意:虽然箭头键也可以完全正常工作,但你可以尝试使用hjkl键进行导航。有些人发现这种导航方式很有效。

💡提示:要记住hjkl序列,可以用这个方法:hang back,jump down,kick up,leap forward。
Vim的三个模式
- 你需要知道Vim的三个操作模式以及如何在这它们之间切换。在不同的命令模式中,键盘快捷键的行为是不同的。这三个模式如下:
- 命令模式。
- 编辑模式。
可视模式。
命令模式。 当你启动Vim时,默认会进入命令模式。这个模式允许你访问其他模式。
⚠ 要在其他模式之间切换,你首先需要处于命令模式中
编辑模式
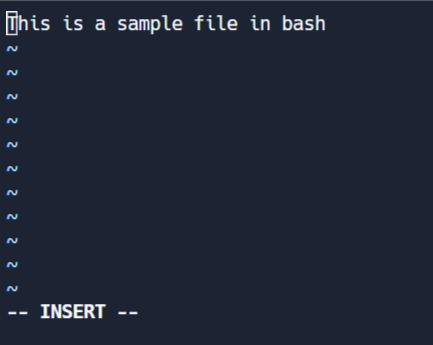
这个模式允许你修改文件。要在命令模式中进入编辑模式,请按I。请注意屏幕末尾的'-- INSERT'切换。
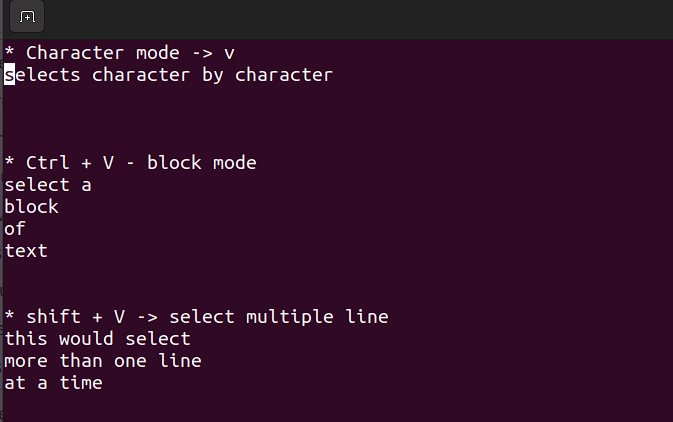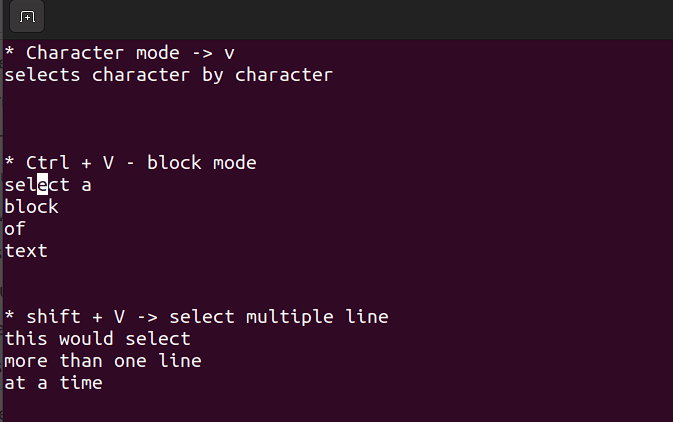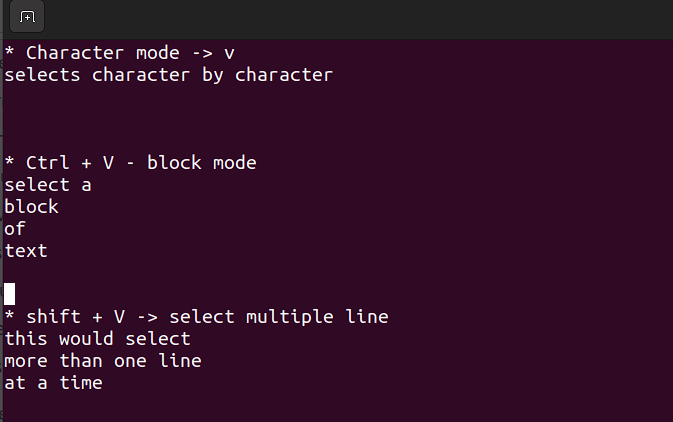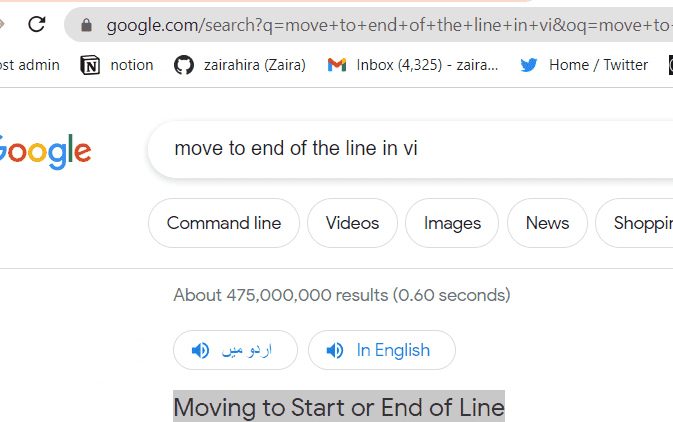
视觉模式
- 此模式允许您对单个字符、文本块或文本行进行操作。让我们将其分解为简单的步骤。记住,在命令模式下使用下面的组合。
Shift + V→ 选择多行。Ctrl + V→ 块模式
V → 字符模式
视觉模式在需要批量复制和粘贴或编辑行时非常有用。
扩展命令模式。
扩展命令模式允许您执行高级操作,如搜索、设置行号和突出显示文本。我们将在下一节介绍扩展模式。
如何保持轨道?如果您忘记当前模式,只需按两次 ESC 键,您将回到命令模式。
在 Vim 中高效编辑:复制/粘贴和搜索
1. 在 Vim 中如何复制和粘贴
- 在 Linux 术语中,复制和粘贴被称为 ‘yank’ 和 ‘put’。要复制和粘贴,请按照以下步骤操作:
- 在视觉模式下选择文本。
- 按
'y'复制/ yank。
将光标移动到所需位置并按'p'。
2. 在Vim中如何搜索文本
在Vim的命令模式下,可以使用/来搜索任何一系列字符串。要搜索,请使用/要匹配的字符串。
在命令模式下,输入:set hls并按回车。使用/要匹配的字符串进行搜索。这将高亮显示搜索结果。
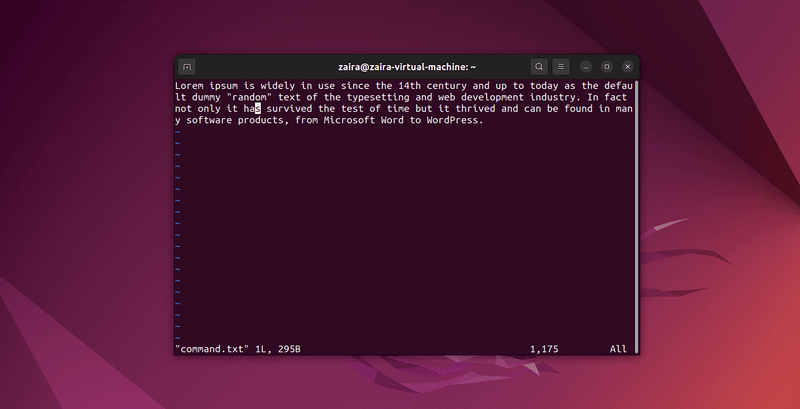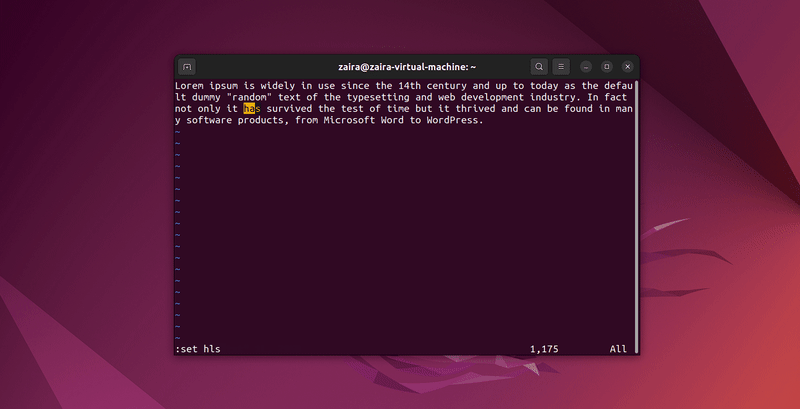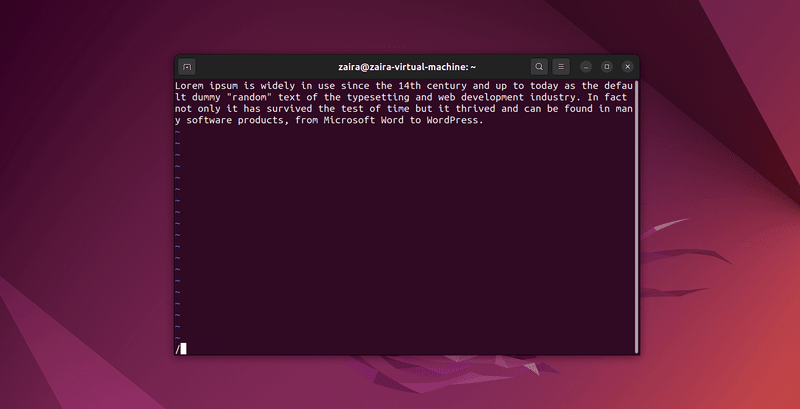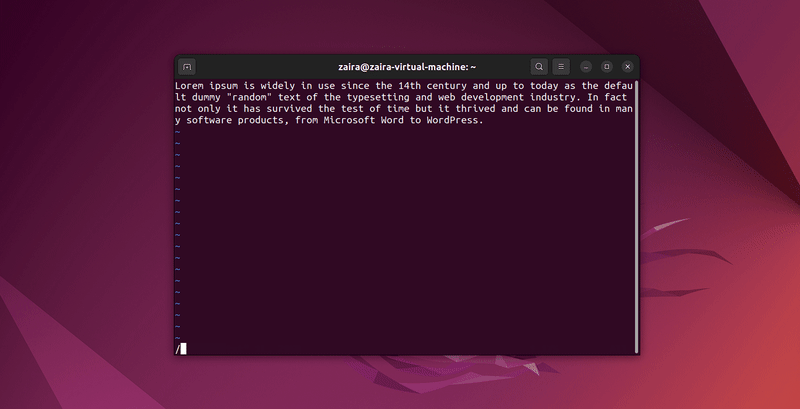
让我们搜索一些字符串:
3. 如何退出Vim
- 首先,移动到命令模式(通过按两次Esc键)然后使用以下命令:
- 不保存退出 →
:q!
保存并退出 → :wq!
Vim中的快捷键:提高编辑速度
- 注意:所有这些快捷键仅在命令模式下有效。
Ctrl+u: 上半页滚动- 在光标上方粘贴
:%s/old/new/g: 将文件中所有old替换为new:q!:不保存退出
Ctrl+w 后跟 h/j/k/l:在分割窗口间导航
5.2. 精通 Nano
Nano 入门:用户友好的文本编辑器
Nano 是一个用户友好的文本编辑器,易于使用,非常适合初学者。它预装在大多数 Linux 发行版中。
nano
使用 Nano 创建新文件,请使用以下命令:
nano filename
使用 Nano 编辑现有文件,请使用以下命令:
Nano 中的键绑定列表
让我们学习 Nano 中最重要的键绑定。您将使用这些键绑定来执行各种操作,如保存、退出、复制、粘贴等。
写入文件并保存
一旦您使用`nano`命令打开Nano,您就可以开始编写文本。要保存文件,请按`Ctrl+O`。系统会提示您输入文件名。按`Enter`键以保存文件。
退出nano
您可以按`Ctrl+X`退出Nano。如果您有未保存的更改,Nano会在退出前提示您保存更改。
复制和粘贴
要选择一个区域,请使用`ALT+A`。会出现一个标记。使用箭头选择文本。选择后,使用`ALT+^`退出标记。
要复制选定的文本,请按`Ctrl+K`。要粘贴复制的文本,请按`Ctrl+U`。
剪切和粘贴
使用`ALT+A`选择区域。选择后,使用`Ctrl+K`剪切文本。要粘贴剪切的文本,请按`Ctrl+U`。
导航
使用`Alt \`移至文件开头。
使用`Alt /`移至文件末尾。
查看行号
使用`nano -l 文件名`打开文件时,您可以在文件的左侧查看行号。
搜索
您可以使用`ALt + G`搜索特定的行号。输入提示中的行号并按`Enter`。
您还可以通过按CTRL + W并回车来搜索字符串,如果您想反向搜索,可以在按Ctrl+W发起搜索后按Alt+W。
- Nano中的快捷键总结
Ctrl+G: 显示帮助文本Ctrl+J: justification of the current paragraphCtrl+V: 向下滚动一页Ctrl+\: 搜索并替换
Alt+E: 重做上一步撤销的操作
第六部分:Bash脚本编程
6.1. Bash脚本编程的定义
Bash脚本是一个包含由bash程序逐行执行的命令序列的文件。它允许你执行一系列动作,如导航到特定目录、创建文件夹以及使用命令行启动进程。
通过将命令保存到脚本中,您可以多次重复相同的步骤序列,并通过运行脚本来执行它们。
6.2. Bash 脚本的优势
Bash 脚本是自动化系统管理任务、管理系统资源以及在 Unix/Linux 系统中执行其他常规任务的强大而多功能的工具。
- shell 脚本的一些优势包括:
- 自动化:Shell 脚本允许您自动化重复的任务和过程,节省时间并减少手动执行时可能出现的错误风险。
- 可移植性:Shell 脚本可以在各种平台和操作系统上运行,包括 Unix、Linux、macOS,甚至通过模拟器或虚拟机在 Windows 上运行。
- 灵活性: 壳牌脚本具有很高的自定义性,可以轻松修改以适应特定需求。它们还可以与其他编程语言或实用工具结合使用,以创建更强大的脚本。
- 易用性: 壳牌脚本易于编写,不需要任何特殊工具或软件。它们可以用任何文本编辑器编辑,大多数操作系统都内置有壳牌解释器。
- 集成: 壳牌脚本可以与其他工具和应用程序集成,如数据库、网络服务器和云服务,从而实现更复杂的自动化和系统管理任务。
调试: 壳牌脚本易于调试,大多数壳牌都有内置的调试和错误报告工具,可以帮助快速识别和修复问题。
6.3 Bash壳牌和命令行界面的概述
外壳和bash经常可以互换使用。但这两个术语之间有一个微妙的区别。
“外壳”是指一个程序,它为与操作系统交互提供命令行界面。Bash(Bourne-Again SHell)是最常用的Unix/Linux外壳之一,也是许多Linux发行版中的默认外壳。
到目前为止,您输入的命令基本上都是在”外壳”中输入的。
尽管Bash是一种外壳,但还有其他外壳可用,例如Korn外壳(ksh)、C外壳(csh)和Z外壳(zsh)。每个外壳都有自己的语法和特性集,但它们都共享一个共同目标,即为与操作系统交互提供命令行界面。
ps
# output:
PID TTY TIME CMD
20506 pts/0 00:00:00 bash <--- the shell type
20931 pts/0 00:00:00 ps
您可以使用ps命令来确定您的外壳类型:
总之,”外壳”是一个广泛的术语,指的是任何提供命令行界面的程序,”Bash”是在Unix/Linux系统中广泛使用的一种特定外壳。
注意:在本节中,我们将使用”bash”外壳。
6.4. 如何创建和执行Bash脚本
脚本命名约定
按照命名约定,Bash脚本以.sh结尾。然而,Bash脚本完全可以没有sh扩展正常运行。
添加Shebang
Bash 脚本以 shebang 开头。Shebang 是 bash # 和 bang ! 的组合,后面跟着 bash 壳体的路径。这是脚本的 第一行。Shebang 告诉壳体通过 bash 壳体执行它。Shebang 只是到 bash 解释器的绝对路径。
#!/bin/bash
以下是 shebang 语句的示例。
which bash
您可以使用以下命令找到您的 bash 壳体路径(可能与上面不同):
创建您的第一个 bash 脚本
我们的第一个脚本提示用户输入一个路径。作为回应,它将列出其内容。
vim run_all.sh
使用您喜欢的任何编辑器创建一个名为 run_all.sh 的文件。
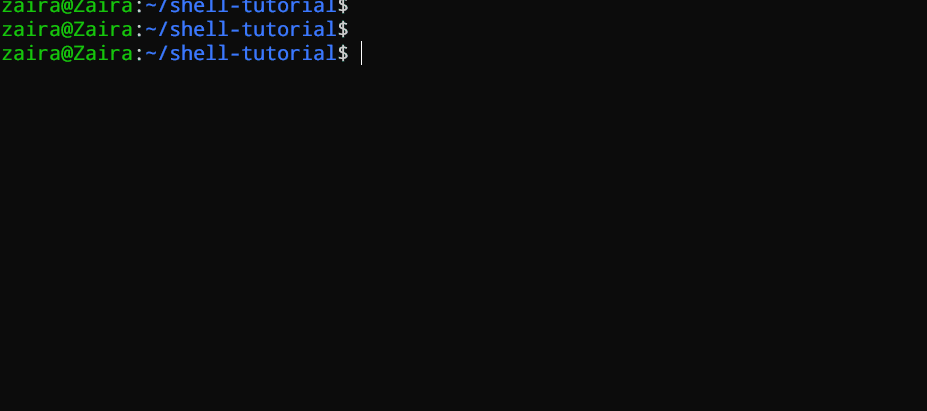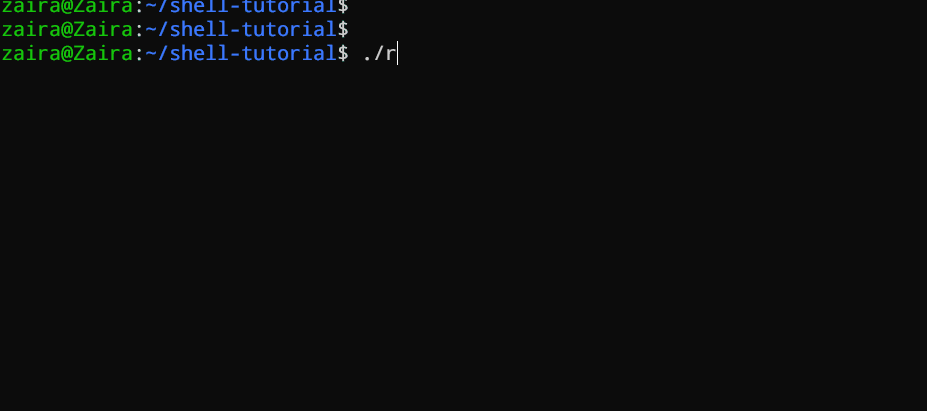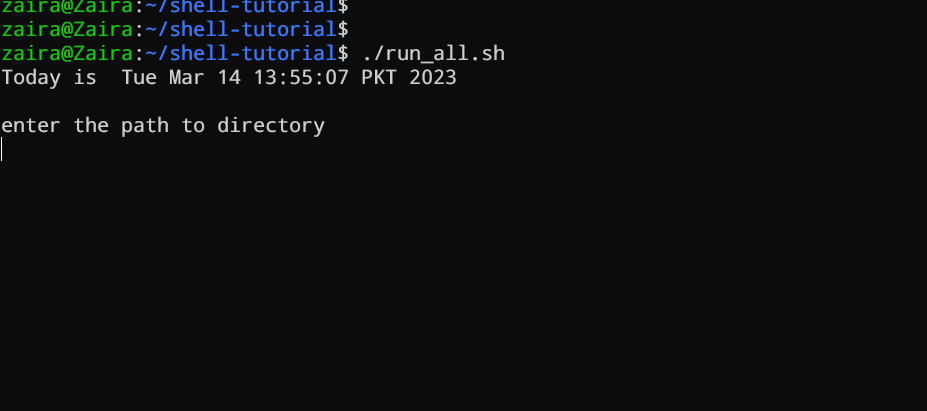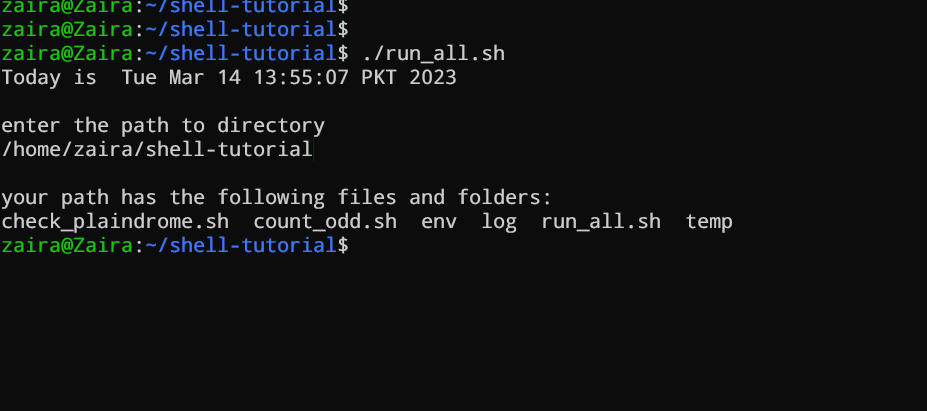
#!/bin/bash
echo "Today is " `date`
echo -e "\nenter the path to directory"
read the_path
echo -e "\n you path has the following files and folders: "
ls $the_path
在您的文件中添加以下命令并保存它:
1 让我们更深入地看看脚本逐行。我再次显示相同的脚本,但这次带有行号。
2 echo "Today is " `date`
3
4 echo -e "\nenter the path to directory"
5 read the_path
6
7 echo -e "\n you path has the following files and folders: "
8 ls $the_path
- #!/bin/bash
- 行 #1: shebang (
#!/bin/bash) 指向 bash 壳体路径。 - 行 #2:
echo命令在终端上显示当前日期和时间。注意date在反引号中。 - 行 #4: 我们希望用户输入一个有效的路径。
- 第5行:`read`命令读取输入并将其存储在变量`the_path`中。
第8行:`ls`命令取存储路径的变量并显示当前的文件和文件夹。
执行bash脚本
chmod u+x run_all.sh
为了使脚本可执行,使用以下命令为您的用户分配执行权限:
- 这里,
chmod修改文件的当前用户所有权:u。+x为当前用户添加执行权限。这意味着文件的拥有者现在可以运行脚本。
run_all.sh 是我们要运行的文件。
- 您可以通过以下任一方法运行脚本:
sh run_all.shbash run_all.sh
./run_all.sh
让我们看看它运行的效果🚀
6.5. Bash脚本基础
Bash脚本中的注释
在Bash脚本中,注释以#开头。这意味着任何以#开头的行都是注释,将被解释器忽略。
注释在文档代码方面非常有帮助,向他人添加注释以帮助他们理解代码是一个好习惯。
以下是注释的例子:
# 这是个示例注释
# 这两行都将被解释器忽略
Bash中的变量和数据类型
变量让你能够存储数据。你可以在脚本中使用变量来读取、访问和操作数据。
Bash中没有数据类型。在Bash中,变量能够存储数字值、单个字符或字符串。
- 在Bash中,你可以以以下方式使用和设置变量值:
country=Netherlands
直接赋值:
same_country=$country
2. 根据程序或命令的输出结果来赋值,使用命令替换。注意需要用$来访问现有变量的值。
这将为新变量same_country分配country的值。
country=Netherlands
echo $country
要访问变量的值,请在变量名后附加$。
Netherlands
new_country=$country
echo $new_country
# 输出
Netherlands
# 输出
上面,你可以看到一个变量赋值和打印值的示例。
变量命名约定
- 在Bash脚本中,以下是一些变量命名约定:
- 变量名应以字母或下划线(
_)开头。 - 变量名可以包含字母、数字和下划线(
_)。 - 变量名是大小写敏感的。
- 变量名不应包含空格或特殊字符。
- 使用反映变量目的的描述性名称。
避免使用保留关键字,如if、then、else、fi等作为变量名。
name
count
_var
myVar
MY_VAR
以下是一些Bash中有效的变量名示例:
以下是一些无效的变量名示例:
2ndvar (variable name starts with a number)
my var (variable name contains a space)
my-var (variable name contains a hyphen)
# 无效的变量名
遵循这些命名约定有助于使Bash脚本更具可读性且更易于维护。
Bash脚本中的输入和输出
收集输入
- 在本节中,我们将讨论一些向我们的脚本提供输入的方法。
使用read命令读取用户输入并将其存储在变量中
#!/bin/bash
echo "What's your name?"
read entered_name
echo -e "\nWelcome to bash tutorial" $entered_name
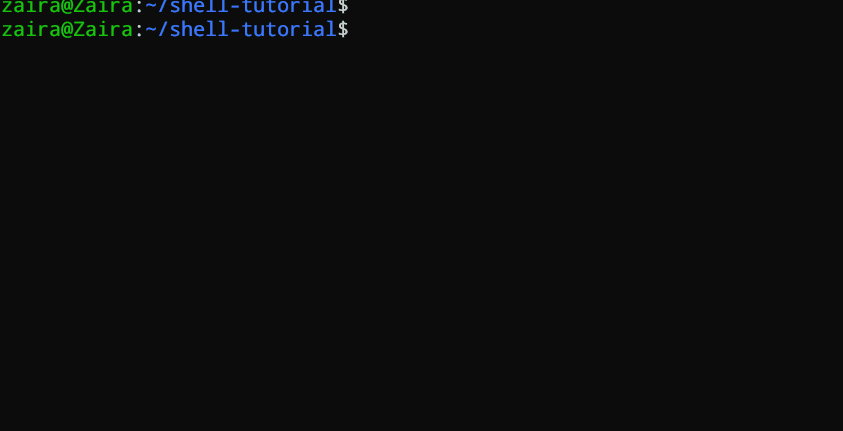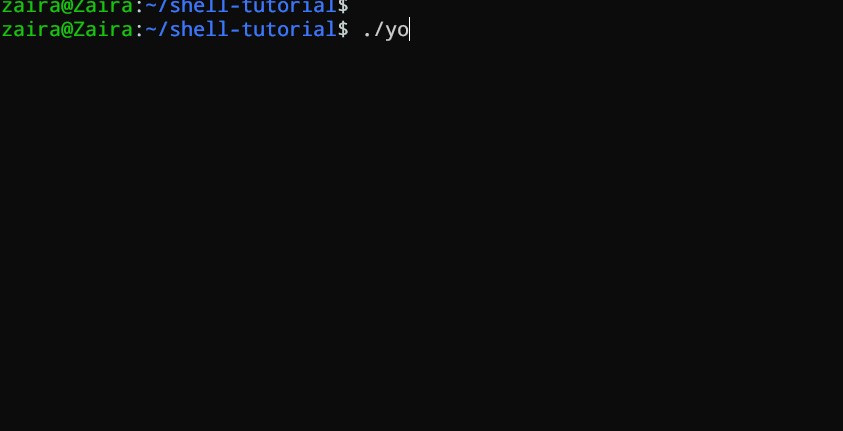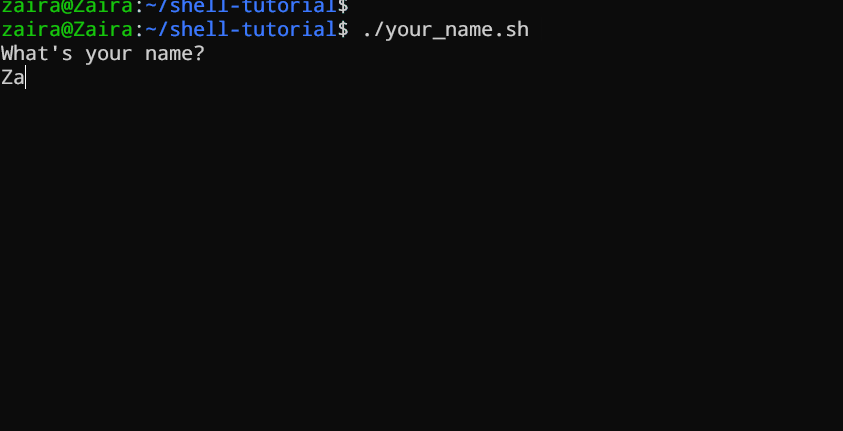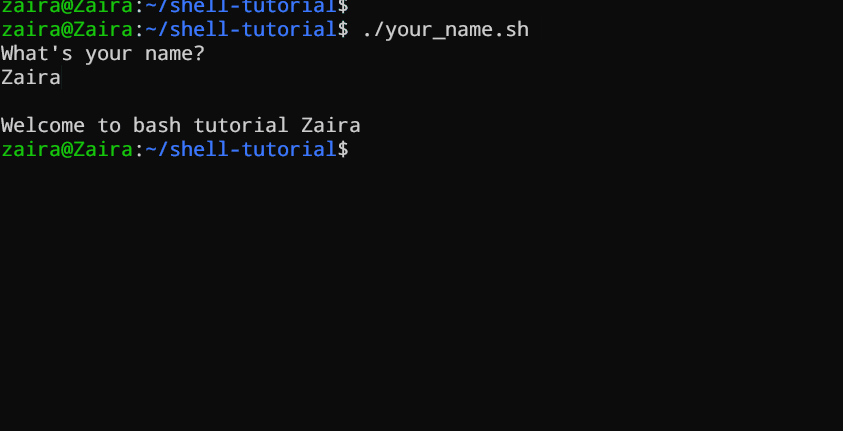
我们可以使用`read`命令读取用户输入。
2. 从文件中读取
while read line
do
echo $line
done < input.txt
此代码从名为`input.txt`的文件中读取每一行,并将其打印到终端。我们将在本节后面学习while循环。
3. 命令行参数
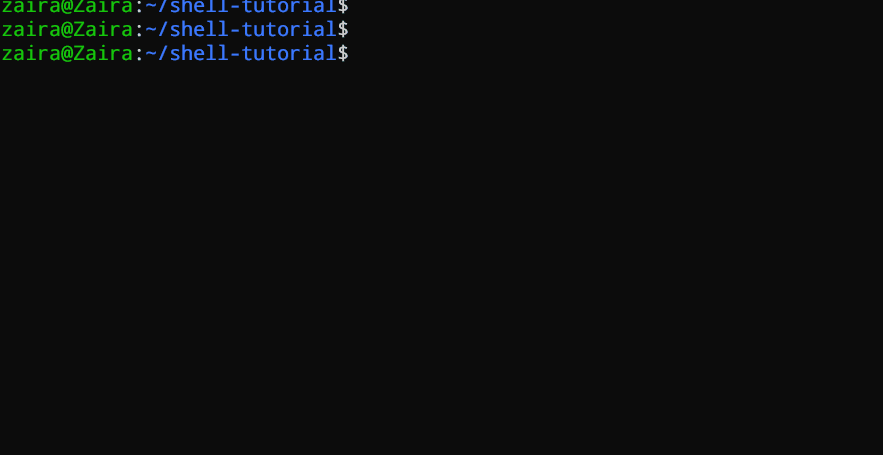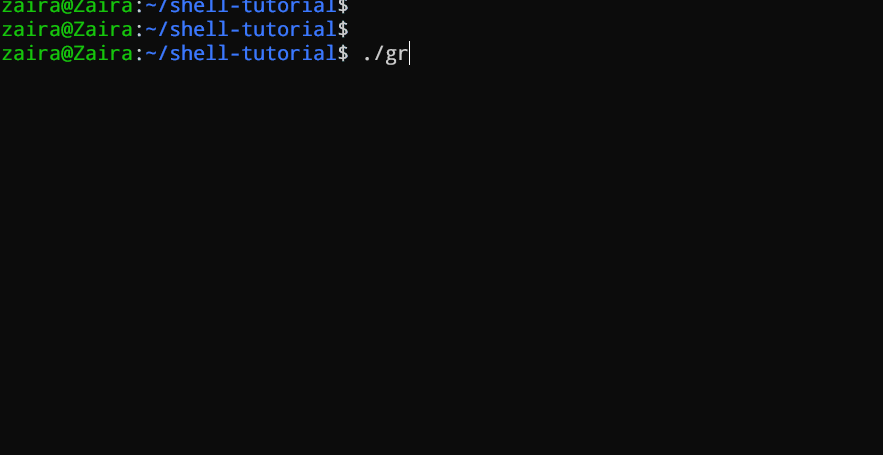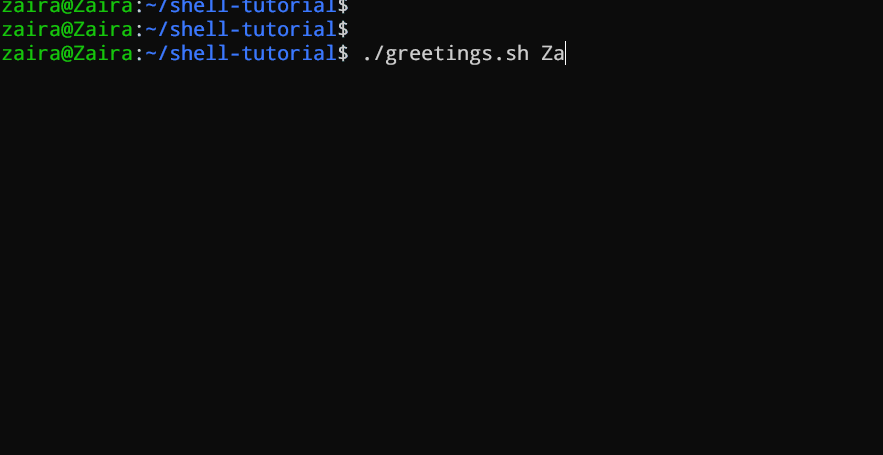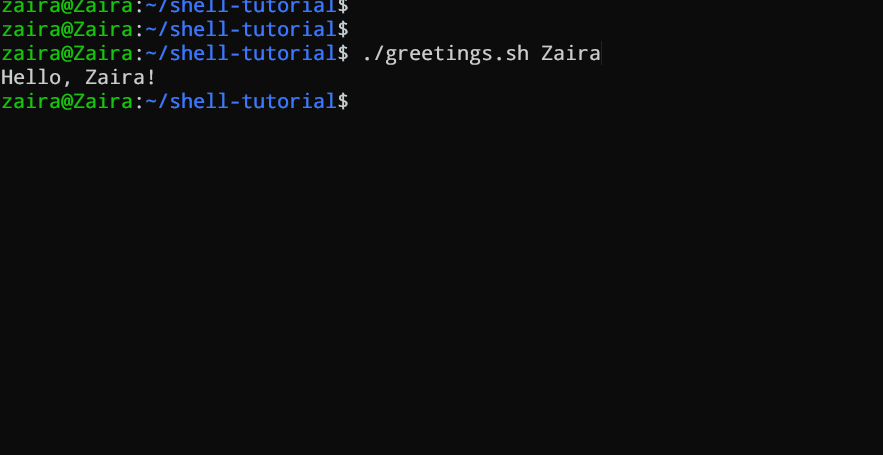
在Bash脚本或函数中,`$1`表示传递的第一个参数,`$2`表示传递的第二个参数,依此类推。
#!/bin/bash
echo "Hello, $1!"
此脚本接受一个作为命令行参数的名字并打印出个性化的问候语。
我们向脚本提供了`Zaira`作为我们的参数。
输出:
显示输出
- 在这里,我们将讨论一些从脚本接收输出的方法。
echo "Hello, World!"
打印到终端:
这将在终端上打印出“Hello, World!”文本。
echo "This is some text." > output.txt
2. 写入文件:
这会将文本“This is some text.”写入名为`output.txt`的文件。注意,如果文件已经有内容,`>>`运算符将覆盖文件。
echo "More text." >> output.txt
3. 追加到文件:
这个应用程序将文本“更多文本。”添加到文件output.txt的末尾。
ls > files.txt
4. 重定向输出:
这将列出当前目录中的文件,并将输出写入名为files.txt的文件中。您可以这样将任何命令的输出重定向到文件中。
您将在第8.5节中详细学习输出重定向。
条件语句(if/else)
产生布尔结果的表达式称为条件,结果为真或假。评估条件有几种方法,包括if、if-else、if-elif-else和嵌套条件。
if [[ condition ]];
then
statement
elif [[ condition ]]; then
statement
else
do this by default
fi
语法:
Bash条件语句的语法
if [ $a -gt 60 -a $b -lt 100 ]
我们可以使用逻辑运算符如AND -a 和 OR -o 来进行更具意义的比较。
这个语句检查两个条件是否都为true:a 大于 60 且 b 小于 100。
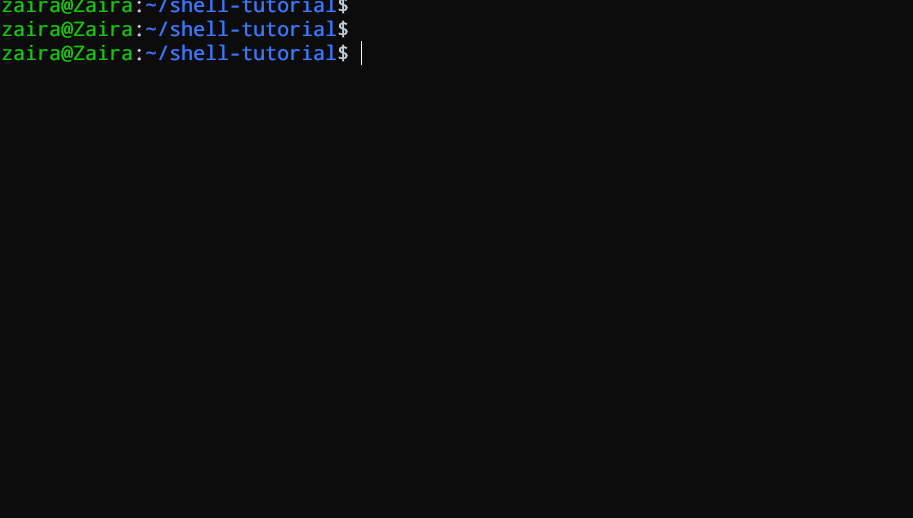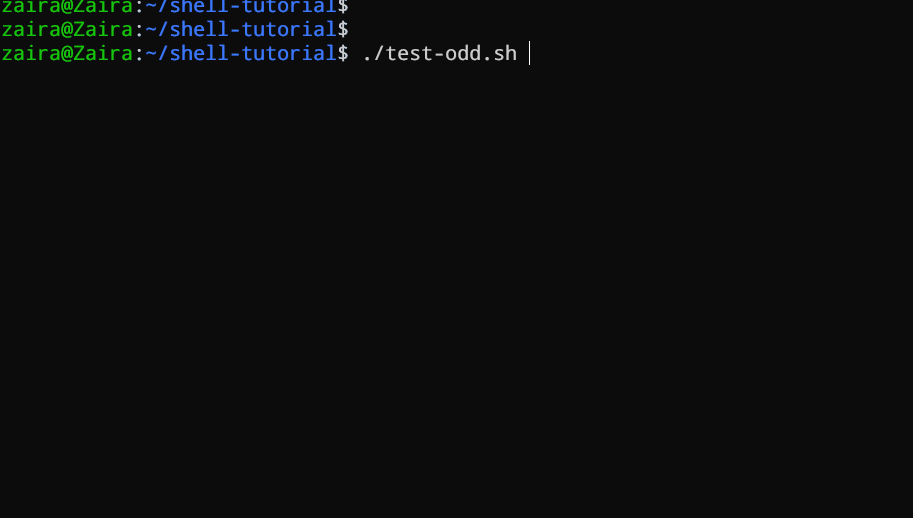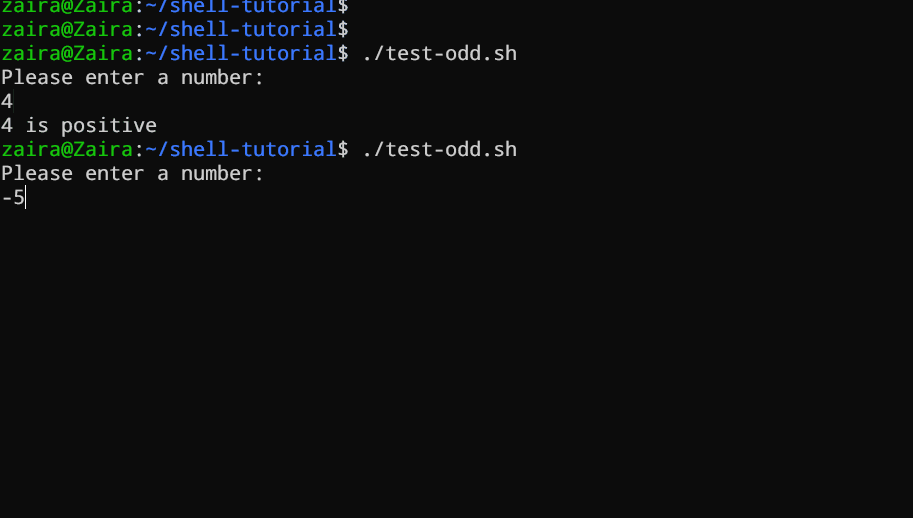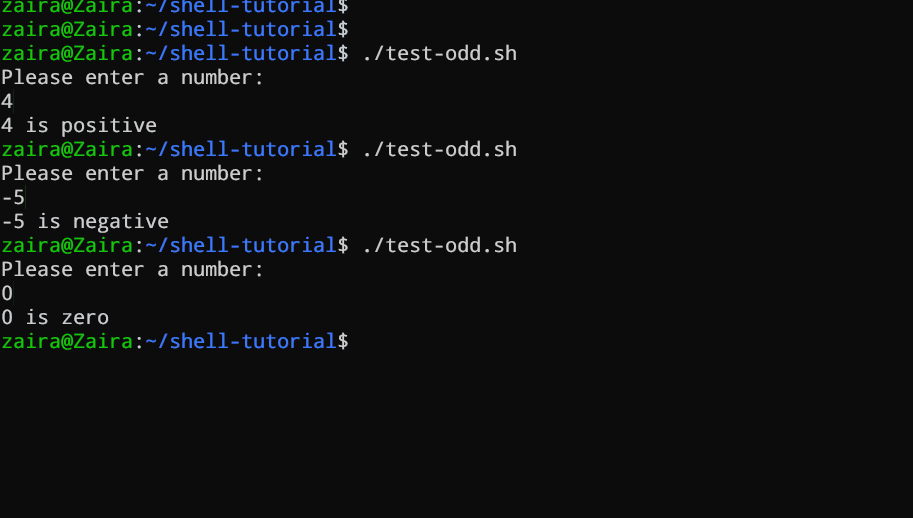
#!/bin/bash
让我们看一个使用if、if-else和if-elif-else语句来确定用户输入的数字是正数、负数还是零的Bash脚本示例:
echo "Please enter a number: "
read num
if [ $num -gt 0 ]; then
echo "$num is positive"
elif [ $num -lt 0 ]; then
echo "$num is negative"
else
echo "$num is zero"
fi
# 脚本以确定一个数字是正数、负数还是零
脚本首先提示用户输入一个数字。然后,它使用一个 `if` 语句来检查这个数字是否大于 `0`。如果是,脚本输出这个数字是正数。如果这个数字不大于 `0`,脚本继续执行下一个语句,这是一个 `if-elif` 语句。
在这里,脚本检查数字是否小于 `0`。如果是,脚本输出这个数字是负数。
最后,如果数字既不大于 `0` 也不小于 `0`,脚本使用一个 `else` 语句来输出这个数字是零。
看它的实际应用 🚀
Bash 中的循环和分支
while 循环
while 循环检查一个条件,并在条件为 `true` 时循环。我们需要提供一个计数器语句来递增计数器以控制循环执行。
#!/bin/bash
i=1
while [[ $i -le 10 ]] ; do
echo "$i"
(( i += 1 ))
done
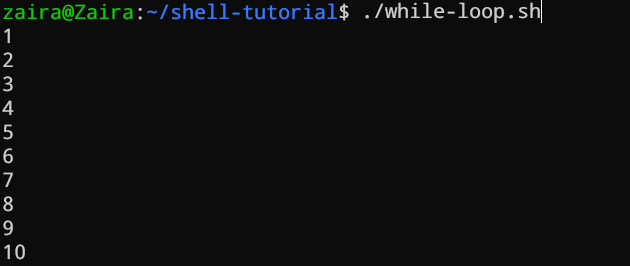
在下面的例子中,`(( i += 1 ))` 是递增计数器 i 的语句。循环将恰好运行 10 次。
for 循环
与 while 循环类似,for 循环也允许你执行特定次数的语句。每个循环在语法和用法上有所不同。
#!/bin/bash
for i in {1..5}
do
echo $i
done

在下面的例子中,循环将迭代 5 次。
情况语句
case expression in
pattern1)
在Bash中,情况语句用于将给定的值与一系列模式进行比较,并根据第一个匹配的模式执行一个代码块。Bash中情况语句的语法如下:
;;
pattern2)
# 如果表达式匹配模式1,则执行代码
;;
pattern3)
# 如果表达式匹配模式2,则执行代码
;;
*)
# 如果表达式匹配模式3,则执行代码
;;
esac
# 如果没有上述模式与表达式匹配,则执行代码
“expression”是我们想要比较的值,”pattern1″、”pattern2″、”pattern3″等是我们要与之比较的模式。
双分号”;;”用于分隔每个模式对应的代码块。星号”*”代表默认情况,如果没有任何指定的模式与表达式匹配,则执行。
fruit="apple"
case $fruit in
"apple")
echo "This is a red fruit."
;;
"banana")
echo "This is a yellow fruit."
;;
"orange")
echo "This is an orange fruit."
;;
*)
echo "Unknown fruit."
;;
esac
让我们来看一个例子:
在这个例子中,由于fruit的值是apple,第一个模式匹配,执行输出This is a red fruit.的代码块。如果fruit的值是banana,第二个模式将匹配,执行输出This is a yellow fruit.的代码块,依此类推。
如果fruit的值与所有指定的模式都不匹配,则执行默认情况,输出Unknown fruit.
第七部分:在Linux中管理软件包
Linux 自带了一些内置程序。但是,根据您的需求,您可能需要安装新的程序。您可能还需要升级现有的应用程序。
7.1. 包和包管理
什么是包?
包是一组捆绑在一起的文件。这些文件对于某个程序的运行至关重要。这些文件包含了程序的可执行文件、库和其他资源。
除了程序运行所需的文件外,包还包含安装脚本,这些脚本将文件复制到需要的地方。一个程序可能包含许多文件和依赖项。通过包,可以更轻松地一次性管理所有文件和依赖项。
源代码和二进制代码有什么区别?
程序员用编程语言编写源代码。然后将源代码编译成计算机可以理解的机器代码。编译后的代码称为二进制代码。
当你下载一个包时,你可以获得源代码或者二进制代码。源代码是人类可读的代码,可以编译成二进制代码。二进制代码是编译后的代码,计算机可以理解。
源代码包如果编译得当,可以与任何类型的机器配合使用。另一方面,二进制代码是针对特定类型机器或架构编译的代码。
uname -m
您可以使用uname -m命令来查找您的机器架构。
x86_64
# 输出
软件包依赖关系
程序经常共享文件。为了避免在每个软件包中都包含这些文件,可以单独创建一个软件包来为所有程序提供这些共享文件。
要安装需要这些文件的程序,您必须 also 安装包含这些文件的软件包。这就是所谓的软件包依赖关系。通过指定依赖关系,可以减少重复并使软件包变得更小、更简单。
当您安装一个程序时,其依赖关系也必须被安装。大多数必需的依赖关系通常已经安装,但可能还需要一些额外的依赖关系。因此,如果与您选择的软件包一起安装了几个其他软件包,请不要感到惊讶。这些都是必要的依赖关系。
软件包管理器
Linux 为安装、升级、配置和删除软件提供了一个全面的软件包管理系统。
借助软件包管理,您可以访问一个有组织的软件包基础库,并拥有解决依赖关系和检查软件更新的能力。
可以通过命令行工具或图形界面来管理软件包。这些命令行工具可以很容易地被系统管理员自动化。
软件仓库/渠道
🚨 不同的发行版有不同的软件包管理方式。在此,我们使用的是 Ubuntu。
与 Windows 和 Mac 相比,Linux 中安装软件的方式略有不同。
Linux 使用仓库来存储软件包。仓库是可以通过包管理器安装的一系列软件包的集合。
一个包管理器还存储了一个仓库中所有可用软件包的索引。有时会重新构建索引以确保其是最新的,并且知道自上次检查以来通道中有哪些软件包被升级或添加了。
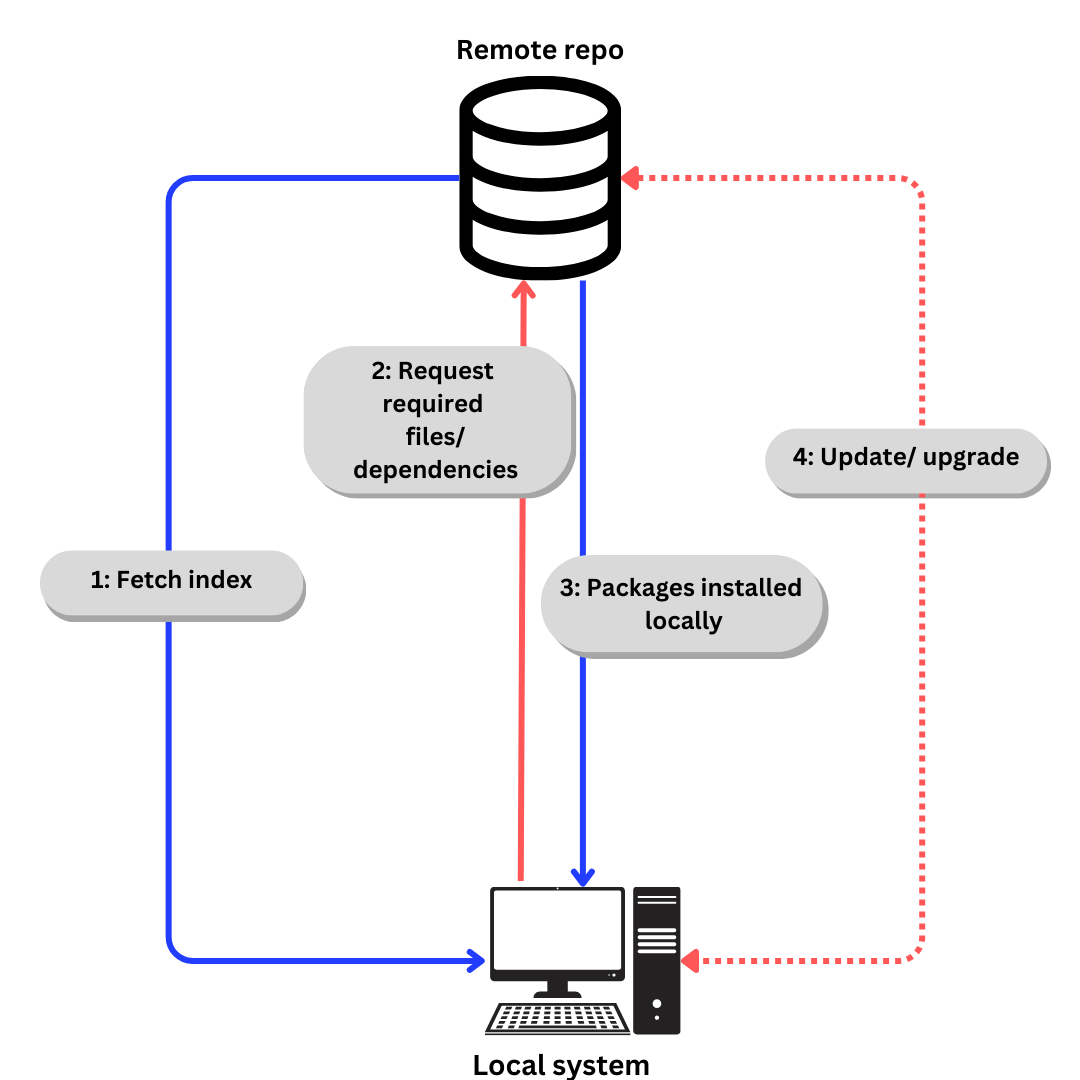
从仓库下载软件的通用流程大致如下:
- 如果我们具体谈论Ubuntu:
- 使用
apt update获取索引。(apt在下一节中解释) - 根据索引使用
apt install请求所需的文件/依赖项 - 本地安装软件包和依赖项。
在需要时使用apt update和apt upgrade更新依赖项和软件包
在基于Debian的发行版上,你可以在/etc/apt/sources.list中记录仓库(repositories)的列表。
7.2. 通过命令行安装一个软件包
apt命令是一个强大的命令行工具,它配合Ubuntu的“高级包装工具(APT)”一起工作。
apt,以及与其捆绑的命令,提供了安装新软件包、升级现有软件包、更新软件包列表索引甚至升级整个Ubuntu系统的方法。
要查看使用apt进行安装的日志,您可以查看/var/log/dpkg.log文件。
以下是apt命令的用途:
安装软件包
sudo apt install htop
例如,要安装htop软件包,可以使用以下命令:
更新软件包列表索引
sudo apt update
软件包列表索引是存储所有可用于安装的软件包的列表。要更新本地软件包列表索引,可以使用以下命令:
升级软件包
系统中已安装的软件包可能会获得包含错误修复、安全补丁和新功能的更新。
sudo apt upgrade
要升级软件包,可以使用以下命令:
删除软件包
sudo apt remove htop
要删除一个软件包,如htop,可以使用以下命令:
7.3.通过高级图形方式安装软件包- Synaptic
如果您不习惯使用命令行,可以使用图形界面应用程序来安装软件包。您可以通过图形界面实现与命令行相同的结果。
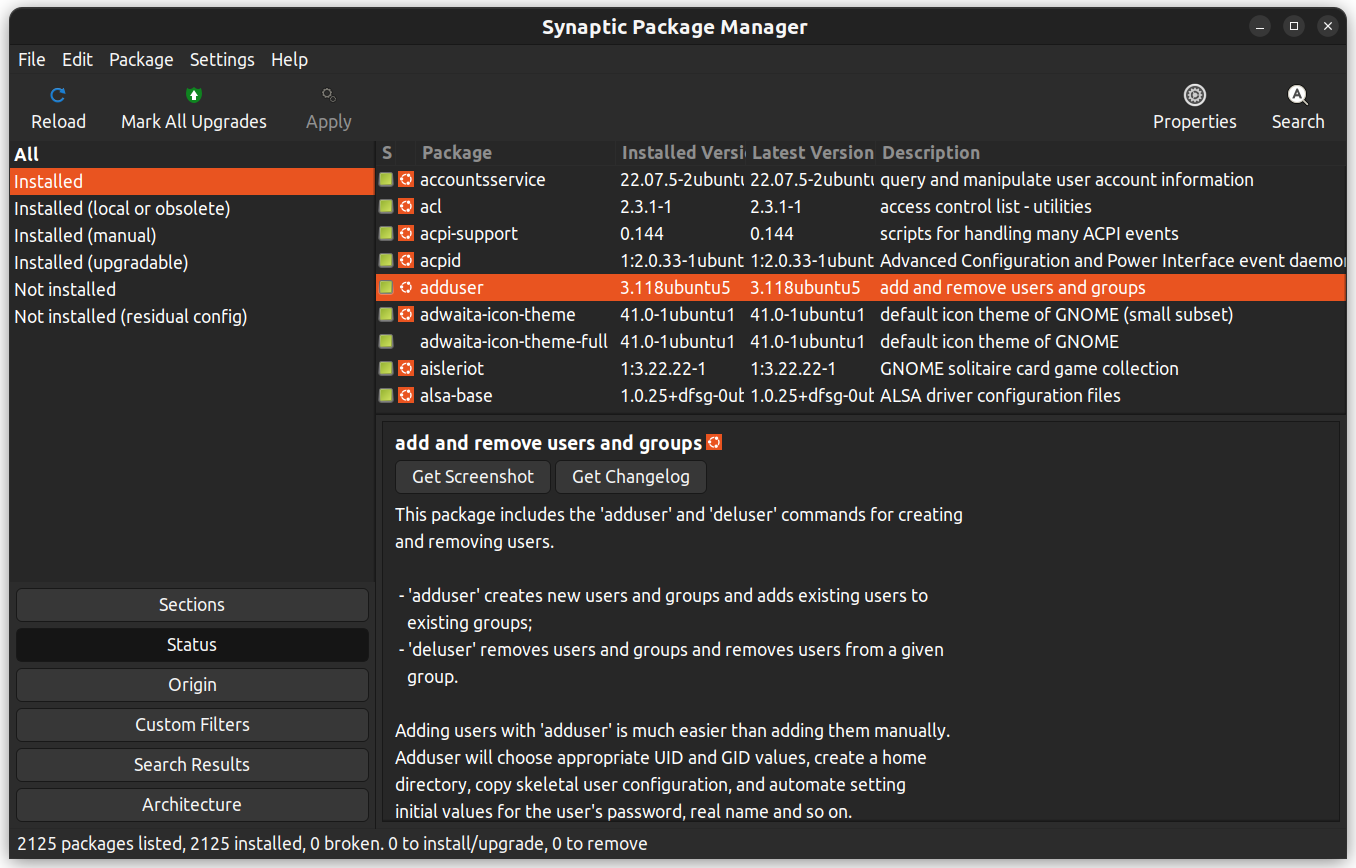
Synaptic是一个图形化的软件包管理应用程序,可以帮助列出已安装的软件包、其状态、待更新的软件包等等。它提供自定义过滤器,帮助您缩小搜索结果范围。
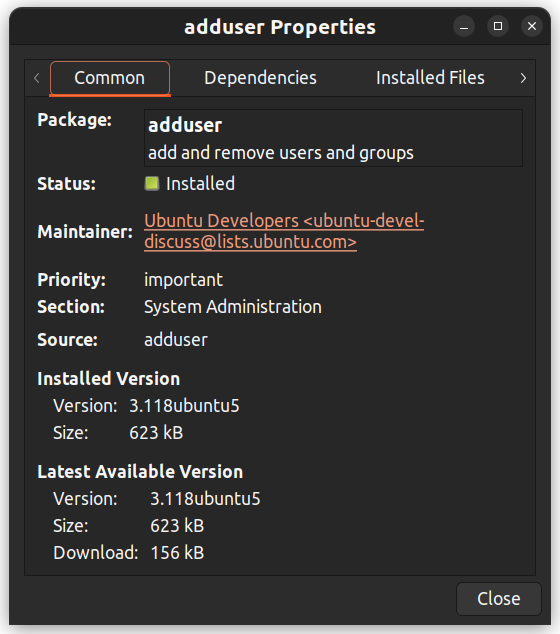
你也可以右键点击一个软件包,查看其依赖关系、维护者、大小和已安装的文件等更多信息。
7.4. 从网站安装下载的软件包
你可能想从网站而非软件仓库安装一个软件包。这些软件包被称为.deb文件。
cd directory
sudo dpkg -i package_name.deb
使用dpkg安装软件包:dpkg是一个命令行工具,用于安装软件包。要使用dpkg安装软件包,请打开终端并输入以下内容:
注意:将“directory”替换为软件包所在的目录,将“package_name”替换为软件包的文件名。
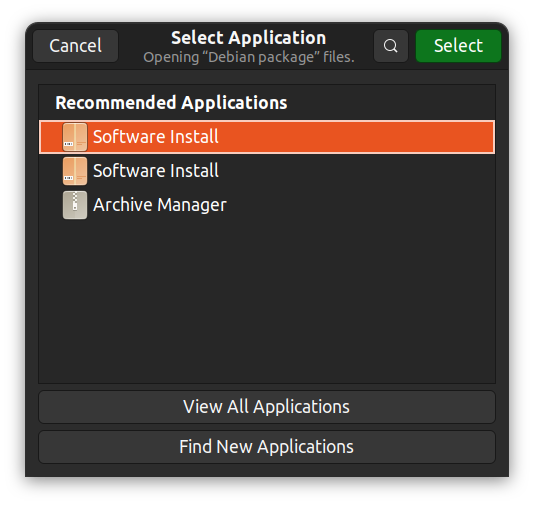
另外,你也可以右键点击,选择“用其他应用程序打开”,然后选择你喜欢的GUI应用程序。
💡 提示:在Ubuntu中,你可以使用dpkg --list查看已安装的软件包列表。
第八部分:高级Linux主题
8.1. 用户管理
系统可以有多个用户,他们的访问权限各不相同。在Linux中,root用户的访问权限最高,可以在系统上执行任何操作。普通用户则权限有限,只能执行被授权的操作。
什么是用户?
用户账户在可以运行命令的不同人和程序之间提供了分隔。
人类通过名称来识别用户,因为名称易于操作。但系统通过一个称为用户ID(UID)的唯一数字来识别用户。
当人类用户使用提供的用户名登录时,他们必须使用密码来验证自己。
用户账户是系统安全的基础。文件所有权也与用户账户相关联,它执行对文件的访问控制。每个进程都有一个关联的用户账户,为管理员提供了一层控制。
- 主要有三种用户账户类型:
- 超级用户:超级用户对系统拥有完全访问权限。超级用户的用户名是
root,其UID为0。 - 系统用户:系统用户有用于运行系统服务的用户账户。这些账户用于运行系统服务,不适合人类交互。
普通用户:普通用户是具有系统访问权限的人类用户。
id
uid=1000(john) gid=1000(john) groups=1000(john),4(adm),24(cdrom),27(sudo),30(dip)... output truncated
命令id显示当前用户的用户ID和组ID。
id username
要查看另一用户的基本信息,请将用户名作为参数传递给id命令。
ps -u
要查看进程相关的用户信息,请使用带有 -u 标志的 ps 命令。
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 16968 3920 ? Ss 18:45 0:00 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 18:45 0:00 [kthreadd]
# 输出
默认情况下,系统使用 /etc/passwd 文件来存储用户信息。
root:x:0:0:root:/root:/bin/bash
以下是 /etc/passwd 文件中的一行:
/etc/passwd文件包含了每个用户的以下信息:- 用户名:
root– 用户账号的名称。 - 密码:
x– 用户账号的加密密码,出于安全原因存储在/etc/shadow文件中。 - 用户 ID (UID):
0– 用户账号的唯一数字标识。 - 组 ID (GID):
0– 用户账号的主要组标识。 - 用户信息:
root– 用户账号的真实姓名。 - 主目录:
/root– 用户账户的主目录。
Shell: /bin/bash – 用户账户的默认Shell。如果系统用户不允许交互式登录,可能会使用/sbin/nologin。
什么是组?
组是一组共享访问和资源的用户账户的集合。组有组名以便于识别。系统通过一个唯一的数字编号来标识组,称为组ID(GID)。
默认情况下,组的信息存储在/etc/group文件中。
adm:x:4:syslog,john
以下是/etc/group文件的一个条目:
- 以下是给定条目中字段的分解:
- 组名:
adm– 组的名称。 - 密码:
x– 出于安全原因,组的密码存储在/etc/gshadow文件中。密码是可选的,如果未设置则显示为空。 - 组ID(GID):
4– 该组的唯一数字标识符。
组成员:syslog,john – 组成员的用户名列表。在此案例中,组adm有两名成员:syslog和john。
在此特定条目中,组名称为adm,组ID为4,组有两个成员:syslog和john。密码字段通常设置为x,以表示组密码存储在/etc/gshadow文件中。
- 组进一步划分为主要和补充组。
- 主要组:每个用户默认分配一个主要组。此组通常与用户名相同,在创建用户账户时创建。用户创建的文件和目录通常属于这个主要组。
补充组:这些是用户可以属于的主要组之外的其他组。用户可以是多个补充组的成员。这些组允许用户对组内共享的资源拥有权限。它们帮助在不影响系统文件权限的情况下提供对共享资源的访问,同时保持安全性。尽管用户必须属于一个主要组,但加入补充组是可选的。
访问控制:查找并了解文件权限
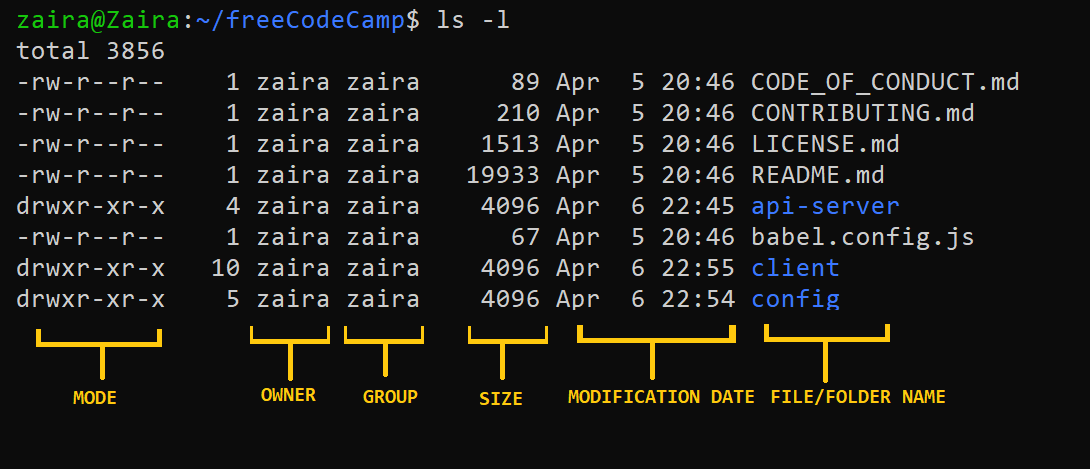
可以使用ls -l命令查看文件所有权。ls -l命令输出的第一列显示文件的权限,其他列显示文件的拥有者和文件所属的组。

让我们仔细看看mode列:
- 模式定义了两件事:
- 文件类型:文件类型定义了文件的类型。对于包含简单数据的普通文件,它是空白的
-。对于其他特殊文件类型,符号是不同的。对于一个特殊的目录文件,它是d。操作系统以不同的方式处理特殊文件。
权限类别:接下来的一组字符分别定义了用户、组和其他人的权限。
– 用户:这是文件的所有者,文件的所有者属于这个类别。
– 组:文件组的成员属于这个类别
– 其他:任何不属于用户或组类别的用户都属于这个类别。
💡提示:可以通过使用ls -ld命令来查看目录所有权。
如何阅读符号权限或rwx权限
rwx表示被称为权限的符号表示。在权限集合中,r代表读取。它显示在三字符组合的第一个字符中。w代表写入。它显示在三字符组合的第二个字符中。
x 代表执行。它显示在三字符组合的第三个字符中。
读取:
对于常规文件,读取权限允许文件仅被打开和读取。用户不能修改文件。
对于目录,读取权限允许列出目录内容,但不能在目录中进行任何修改。
写入:
当文件具有写入权限时,用户可以修改(编辑,删除)文件并保存。
对于文件夹,写入权限允许用户修改其内容(创建,删除,重命名其中的文件),并修改用户具有写入权限的文件的内容。
Linux中的权限示例
- 现在我们知道如何读取权限,让我们看看一些示例。
- `-rw-rw-r–`: 其所有者和组可以修改,但其他人不能访问的文件。
drwxrwx—
: 所有者和组可以修改的目录。
执行:
对于文件,执行权限允许用户运行可执行脚本。对于目录,用户可以访问它们以及查看目录中文件详情。
如何在Linux中使用`chmod`和`chown`更改文件权限和所有权
既然我们已经了解了所有权和权限的基本知识,让我们看看如何使用`chmod`命令来修改权限。
chmod permissions filename
`chmod`的语法:
- 其中,
-
`权限`可以是读、写、执行或它们的组合。
`filename`是需要更改权限的文件名。这个参数也可以是文件列表,以批量更改权限。
- 我们可以使用两种模式来更改权限:
- 符号模式:这种方法使用像
u、g、o这样的符号来表示用户、组和其他人。权限用r, w, x分别表示读、写和执行。您可以使用+、-和=。
绝对模式:这种方法将权限表示为从0到7的3位八进制数。
现在,让我们详细了解一下。
如何使用符号模式更改权限
| 下表总结了用户表示: | 用户表示 |
| u | 描述 |
| g | 用户/所有者 |
| o | 组 |
其他
| 我们可以使用数学运算符来添加、删除和分配权限。下表显示了总结: | 运算符 |
| 描述 | + |
| 向文件或目录添加权限 | – |
| 移除权限 | \= |
如果之前不存在权限,则设置权限。如果之前已设置,则覆盖权限。
示例:
假设我有一个脚本,我想让文件的所有者zaira可以执行它。

当前的文件权限如下:
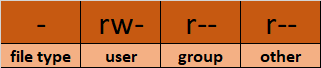
让我们这样分开权限:
chmod u+x mymotd.sh
为了给所有者(u)添加执行权限(x),我们可以使用以下的命令:
输出:
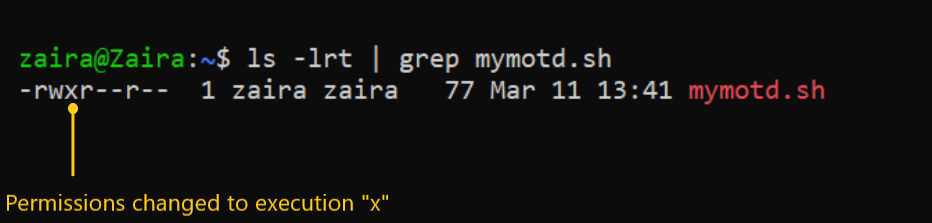
现在,我们可以看到执行权限已经被添加到所有者zaira那里。
- 使用符号方法更改权限的其他示例:
- 移除
group和others的read和write权限:chmod go-rw。 - 移除
others的read权限:chmod o-r。
给group分配write权限并覆盖现有权限:chmod g=w。
如何使用绝对模式更改权限
绝对模式使用数字来表示权限,并使用数学运算符来修改它们。
| 下面的表格展示了我们如何分配相关权限: | 权限 |
| 提供权限 | 读 |
| 加4 | 写 |
| 加2 | 执行 |
加1
| 可以使用减法来撤销权限。下面的表格展示了您可以如何移除相关权限。 | 权限 |
| 撤销权限 | 读 |
| 减4 | 写 |
| 减2 | 执行 |
减1
- 示例:
为user设置read(加4),为组设置read(加4)和execute(加1),为其他用户只设置execute(加1)。
chmod 451 file-name
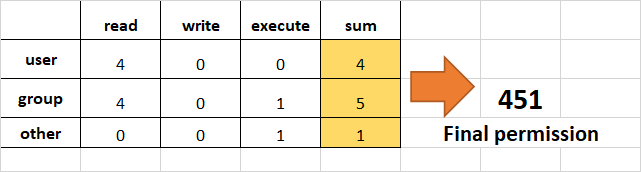
这是我们进行计算的方式:
- 注意这和
r--r-x--x是一样的。
移除other和group的执行权限。
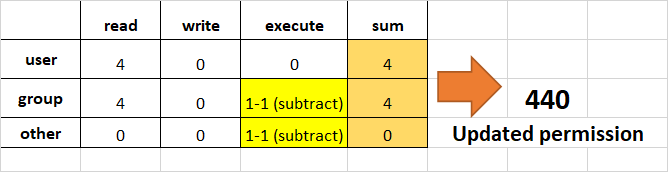
- 要移除
other和group的执行权限,只需将最后两个字节中的执行部分减1。
将read、write和execute权限分配给user,将read和execute权限分配给group,只将read权限分配给其他用户。

这等同于rwxr-xr--。
如何使用chown命令更改所属
接下来,我们将学习如何更改文件的所属。您可以使用chown命令来更改文件或文件夹的所有权。在某些情况下,更改所有权需要sudo权限。
chown user filename
chown命令的语法:
如何使用chown更改用户所属
现在,我们将把用户zaira的所有权转让给用户news。

chown news mymotd.sh
更改所有权的命令:sudo chown news mymotd.sh。

输出:
如何同时更改用户和组所属
chown user:group filename
我们也可以使用chown同时更改用户和组。
如何更改目录所属
chown -R admin /opt/script
您可以递归地更改目录中的内容的所有权。下面的例子将/opt/script文件夹的所有权更改为允许用户admin。
如何更改组所属
chown :admins /opt/script
如果我们只需要更改组所有者,我们可以使用chown,在组名前加上冒号:。
如何切换用户
[user01@host ~]$ su user02
Password:
[user02@host ~]$
您可以使用 `su` 命令在用户之间切换。
如何获得超级用户权限
超级用户或根用户在Linux系统中拥有最高级别的访问权限。根用户可以对系统执行任何操作。根用户可以访问所有文件和目录,安装和卸载软件,以及修改或覆盖系统配置。
权力越大,责任越大。如果根用户被攻破,有人可以完全控制系统。建议只在必要时使用根用户账户。
[user01@host ~]$ su
Password:
[root@host ~]如果您省略用户名,`su` 命令默认切换到根用户账户。
#
`su` 命令的另一种变体是 `su -`。`su` 命令切换到根用户账户但不更改环境变量。`su -` 命令切换到根用户账户并更改目标用户的环境变量。
使用 `sudo` 命令运行命令
要作为 `root` 用户运行命令而不切换到 `root` 用户账户,您可以使用 `sudo` 命令。`sudo` 命令允许您以提升的权限运行命令。
使用 `sudo` 命令运行命令比作为 `root` 用户运行命令更安全。这是因为,只有特定的一组用户可以被授权使用 `sudo` 命令运行命令。这定义在 `/etc/sudoers` 文件中。
此外,sudo 会记录所有使用它的命令,提供了谁运行了哪些命令以及何时运行的审计跟踪。
cat /var/log/auth.log | grep sudo
在 Ubuntu 中,您可以在以下位置找到审计日志:
user01 is not in the sudoers file. This incident will be reported.
对于没有访问 sudo 权限的用户,日志中会标记并提示如下消息:
管理本地用户账户
从命令行创建用户
sudo useradd username
添加新用户的命令是:
此命令设置用户的的主目录并创建一个以用户名命名的私有组。目前,该账户缺少有效的密码,直到创建密码用户无法登录。
修改现有用户
usermod 命令用于修改现有用户。以下是与 usermod 命令一起使用的一些常见选项:
- 以下是一些 Linux 中的
usermod命令示例: - 更改用户的登录名:
- 更改用户的主目录:
- 将用户添加到辅助组:
- 更改用户的shell:
- 锁定用户账户:
- 设置用户账户的到期日期:
- 为用户账户设置到期日期:
- 更改用户用户ID(UID):
- 更改用户的主组:
从辅助组中删除用户:
删除用户
- 使用
userdel命令可以从系统中删除用户账户和相关文件。 sudo userdel 用户名:从/etc/passwd中删除用户的详细信息,但保留用户的主目录。
使用sudo userdel -r 用户名命令可以从/etc/passwd中删除用户的详细信息,并且删除用户的主目录。
更改用户密码
- 使用
passwd命令可以更改用户的密码。
sudo passwd 用户名:设置用户名的初始密码或更改现有密码。它也可以用来更改当前登录用户的密码。
8.2 通过SSH连接到远程服务器
访问远程服务器是系统管理员的基本任务之一。您可以通过本地机器连接到不同的服务器或访问数据库,并使用SSH执行命令。
什么是SSH协议?
SSH代表安全壳层。它是一种加密网络协议,允许两台系统之间进行安全通信。
SSH的默认端口是22。
- 通过SSH通信的两方包括:
- 服务器:您想要访问的机器。
客户端:您从其访问服务器的系统。
- 连接到服务器的步骤如下:
- 发起连接:客户端向服务器发送连接请求。
- 密钥交换:服务器将其公钥发送给客户端。双方同意使用哪种加密方法。
- 会话密钥生成:客户端和服务器使用迪菲-赫尔曼密钥交换来创建共享会话密钥。
- 客户端认证:客户端使用密码、私钥或其他方法登录服务器。
安全通信:认证后,客户端和服务器使用加密进行安全通信。
如何使用SSH连接远程服务器?
SSH命令是Linux中的内置工具,也是默认的命令。它使得访问服务器变得非常简单和安全。
在这里,我们讨论的是客户端如何与服务器建立连接。
- 在连接服务器之前,你需要以下信息:
- 服务器的IP地址或域名。
- 服务器的用户名和密码。
你在服务器上可以访问的端口号。
ssh username@server_ip
SSH命令的基本语法是:
ssh [email protected]
例如,如果你的用户名是john,服务器IP是192.168.1.10,命令将是:
[email protected]'s password:
Welcome to Ubuntu 20.04.2 LTS (GNU/Linux 5.4.0-70-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Fri Jun 5 10:17:32 UTC 2024
System load: 0.08 Processes: 122
Usage of /: 12.3% of 19.56GB Users logged in: 1
Memory usage: 53% IP address for eth0: 192.168.1.10
Swap usage: 0%
Last login: Fri Jun 5 09:34:56 2024 from 192.168.1.2
john@hostname:~$ 之后,系统会提示你输入秘密密码。你的屏幕将看起来类似于这样:
# 开始输入命令
现在您可以在服务器192.168.1.10上执行相关命令。
ssh -p port_number username@server_ip
⚠️ SSH的默认端口是22,但它也容易受到攻击,因为黑客很可能会首先尝试这里。您的服务器可以暴露另一个端口并与您共享访问权限。要连接到不同端口,请使用-p标志。
8.3. 高级日志解析与分析
日志文件在配置后,由您的系统生成,有各种有用原因。它们可用于追踪系统事件、监控系统性能和故障排除问题。它们对于系统管理员特别有用,他们可以追踪应用程序错误、网络事件和用户活动。
以下是一个日志文件的示例:
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 DEBUG Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 WARN Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 DEBUG API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
# 示例日志文件
- 日志文件通常包含以下列:
- 时间戳:事件发生的时间和日期。
- 日志级别:事件的严重性(INFO、DEBUG、WARN、ERROR)。
- 组件:生成事件的系统组件(Startup、Config、Database、User、Security、Network、Email、API、Session、Shutdown)。
- 事件描述。
附加信息:与事件相关的额外信息。
在实时系统中,日志文件通常很长,可能包含数千行,并且每秒生成一次。它们根据配置可能会非常冗长。日志文件中的每一列都是可以用来追踪问题的信息片段。这使得日志文件难以手动阅读和理解。
这就是日志解析的作用所在。日志解析是从日志文件中提取有用信息的过程。它涉及将日志文件分解为更小、更易管理的部分,并提取相关信息。
过滤后的信息也可以用于创建警报、报告和仪表板。
在本节中,您将探索一些在Linux中解析日志文件的技术。
使用 grep 进行文本提取
Grep 是 Bash 内置工具。它的全称是 “global regular expression print”,即全局正则表达式打印。Grep 用于在文件中匹配字符串。
- 以下是一些常见的
grep使用方法: - 此命令在名为
filename的文件中搜索”search_string”。 - 此命令在指定目录及其子目录中的所有文件中搜索”
search_string"。 - 此命令在名为
filename的文件中执行大小写不敏感的搜索,搜索”search_string”。 - 此命令显示文件
filename中带有匹配行的行号。 - 此命令计算文件
filename中包含”search_string”的行数。 - 该命令显示不包含 “search_string” 的
filename文件中的所有行。 - 该命令在名为
filename的文件中搜索整个单词 “word”。
该命令允许在名为 filename 的文件中使用扩展正则表达式进行更复杂的模式匹配。
💡 提示: 如果文件夹中有多个文件,您可以使用以下命令查找包含所需字符串的文件列表。
grep -l "String to Match" /path/to/directory
# 查找包含所需字符串的文件列表
文本提取使用sed
sed代表“流编辑器”。它以流的方式处理数据,意味着它一次读取一行数据。sed允许你搜索模式并在匹配那些模式的行上执行操作。
的基础语法sed:
sed [options] 'command' file_name
sed的基本语法如下:
这里,command用于对文本数据执行诸如替换、删除、插入等操作。文件名是要处理的文件的名称。
sed用法:
1. 替换:
sed 's/old-text/new-text/' filename
使用s标志来替换文本。old-text被替换为new-text:
sed 's/error/warning/' system.log
例如,将system.log日志文件中所有的“error”更改为“warning”:
2. 打印包含特定模式的行:
sed -n '/pattern/p' filename
使用sed过滤并显示匹配特定模式的行:
sed -n '/ERROR/p' system.log
例如,查找所有包含“ERROR”的行:
3. 删除包含特定模式的行:
sed '/pattern/d' filename
你可以从输出中删除匹配特定模式的行:
sed '/DEBUG/d' system.log
例如,移除所有包含“DEBUG”的行:
4. 从日志行中提取特定字段:
sed -n 's/^\([0-9]\{4\}-[0-9]\{2\}-[0-9]\{2\}\).*/\1/p' system.log
您可以使用正则表达式来提取行的特定部分。假设每个日志行都以 “YYYY-MM-DD” 格式的日期开始。您可以只提取每行的日期:
使用 awk 进行文本解析
awk 能够轻松地将每行拆分成字段。它非常适合处理结构化文本,如日志文件。
基本的 awk 语法
awk 'pattern { action }' file_name
awk 的基本语法是:
在这里,模式 是一个必须满足的条件,只有满足这个条件时才会执行 动作。如果省略模式,动作会对每行执行。
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
- 在接下来的示例中,您将使用这个日志文件作为示例:
使用 awk 访问列
zaira@zaira-ThinkPad:~$ awk '{ print $1 }' sample.log
awk 中的字段(默认由空格分隔)可以使用 $1、$2、$3 等等来访问。
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
zaira@zaira-ThinkPad:~$ awk '{ print $2 }' sample.log
# 输出
09:00:00
09:01:00
09:02:00
09:03:00
09:04:00
09:05:00
09:06:00
09:07:00
09:08:00
09:09:00
- # 输出
awk '/ERROR/ { print $0 }' logfile.log
打印包含特定模式(例如,ERROR)的行
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
# 输出
- 这会打印包含 “ERROR” 的所有行。
awk '{ print $1, $2 }' logfile.log
提取第一个字段(日期和时间)
2024-04-25 09:00:00
2024-04-25 09:01:00
2024-04-25 09:02:00
2024-04-25 09:03:00
2024-04-25 09:04:00
2024-04-25 09:05:00
2024-04-25 09:06:00
2024-04-25 09:07:00
2024-04-25 09:08:007
2024-04-25 09:09:00
# 输出
- 这将提取每行的前两个字段,在这种情况下,将是日期和时间。
awk '{ count[$3]++ } END { for (level in count) print level, count[level] }' logfile.log
汇总每个日志级别的出现次数
1
WARN 1
ERROR 1
DEBUG 2
INFO 6
# 输出
- 输出将包含每个日志级别的出现次数摘要。
awk '{ $3="INFO"; print }' sample.log
筛选特定字段(例如,第三个字段为INFO)
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
# 输出
此命令将提取第三个字段为”INFO”的所有行。
💡 提示:在awk中,默认的分隔符是空格。如果你的日志文件使用不同的分隔符,你可以使用-F选项来指定。例如,如果你的日志文件使用冒号作为分隔符,你可以使用awk -F: '{ print $1 }' logfile.log来提取第一个字段。
使用cut解析日志文件
cut命令是一个简单而强大的命令,用于从输入的每行文本中提取文本段。由于日志文件是结构化的,每个字段由特定的字符(如空格、制表符或自定义分隔符)分隔,cut命令非常擅长提取这些特定字段。
cut [options] [file]
cut命令的基本语法是:
- cut命令的一些常用选项:
-d: 指定用作字段分隔符的分隔符。-f: 选择要显示的字段。
-c : 指定字符位置。
cut -d ' ' -f 1 logfile.log
例如,下面的命令将从日志文件的每一行中提取第一个字段(由空格分隔):
使用cut进行日志解析的例子
2024-04-25 08:23:01 INFO 192.168.1.10 User logged in successfully.
2024-04-25 08:24:15 WARNING 192.168.1.10 Disk usage exceeds 90%.
2024-04-25 08:25:02 ERROR 10.0.0.5 Connection timed out.
...
假设你有一个如下结构的日志文件,其中字段由空格分隔:
cut可以以下列方式使用:
cut -d ' ' -f 2 system.log
从每个日志条目中提取时间:
08:23:01
08:24:15
08:25:02
...
# 输出
- 此命令使用空格作为分隔符,并选择第二个字段,即每个日志条目的时间部分。
cut -d ' ' -f 4 system.log
从日志中提取IP地址:
192.168.1.10
192.168.1.10
10.0.0.5
# 输出
- 此命令提取第四个字段,即每个日志条目的IP地址。
cut -d ' ' -f 3 system.log
提取日志级别(INFO, WARNING, ERROR):
INFO
WARNING
ERROR
# 输出
- 这提取包含日志级别的第三个字段。
将cut与其他命令结合使用:
grep "ERROR" system.log | cut -d ' ' -f 1,2
其他命令的输出可以通过管道传递给 cut 命令。假设你想在剪切前过滤日志。你可以使用 grep 提取包含 "ERROR" 的行,然后使用 cut 从这些行中获取具体信息:
2024-04-25 08:25:02
# 输出
- 这个命令首先过滤掉包含”ERROR”的行,然后从这些行中提取日期和时间。
提取多个字段:
cut -d ' ' -f 1,2,3 system.log`
可以通过指定范围或用逗号分隔的字段列表一次性提取多个字段:
2024-04-25 08:23:01 INFO
2024-04-25 08:24:15 WARNING
2024-04-25 08:25:02 ERROR
...
# 输出
上述命令从每个日志条目中提取日期、时间和日志级别的前三个字段。
使用 sort 和 uniq 解析日志文件
在处理日志文件时,排序和去重是常见的操作。sort 和 uniq 命令分别用于对输入进行排序和去除重复行,它们是非常有力量的命令。
sort 命令的基本语法
sort [options] [file]
sort 命令按文本行的字母或数字顺序组织。
- sort 命令的一些关键选项:
-n:假设文件内容是数字的排序。-r:反转排序顺序。-k:指定排序的键或列号。
-u:排序并去除重复行。
`uniq` 命令用于过滤或统计并报告文件中的重复行。
uniq [options] [input_file] [output_file]
`uniq` 的语法如下:
- `uniq` 命令的一些关键选项是:
-c:在每行前加上出现的次数。-d:只打印重复的行。
-u:只打印唯一的行。
将 `sort` 和 `uniq` 一起用于日志解析的示例
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-26 ERROR Connection timed out.
- 假设以下示例日志条目用于这些演示:
sort system.log
按日期排序日志条目:
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# 输出
- 这会将日志条目按字母顺序排序,如果日期是第一个字段,这将有效地按日期排序。
sort system.log | uniq
排序并移除重复项:
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# 输出
- 这个命令会排序日志文件并通过管道传输给 `uniq`,移除重复的行。
sort system.log | uniq -c
计算每行的出现次数:
2 2024-04-25 INFO User logged in successfully.
1 2024-04-25 WARNING Disk usage exceeds 90%.
2 2024-04-26 ERROR Connection timed out.
1 2024-04-26 INFO Scheduled maintenance.
# 输出
- 排序日志条目然后统计每行的唯一行数。根据输出,行
'2024-04-25 INFO User logged in successfully.'在文件中出现了2次。
sort system.log | uniq -u
识别唯一日志条目:
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 INFO Scheduled maintenance.
# 输出
- 这个命令显示唯一的行。
sort -k2 system.log
按日志级别排序:
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-25 WARNING Disk usage exceeds 90%.
# 输出
根据第二个字段,即日志级别,对条目进行排序。
8.4. 通过命令行管理Linux进程
- 进程是程序的运行实例。一个进程包括:
- 分配内存的地址空间。
- 进程状态。
如所有权、安全属性和资源使用情况等属性。
- 进程还具有一个环境,包括:
- 局部和全局变量。
- 当前调度上下文。
分配的系统资源,如网络端口或文件描述符。
当你运行ls -l命令时,操作系统创建一个新的进程来执行该命令。该进程有一个ID、一个状态,并在命令完成后运行。
理解进程创建和生命周期。
在 Ubuntu 中,所有进程都源自于称为 systemd 的初始系统进程,这是内核在启动过程中启动的第一个进程。
systemd 进程有一个进程 ID(PID)为 1,负责初始化系统、启动和管理其他进程以及处理系统服务。系统上的所有其他进程都是 systemd 的后代。
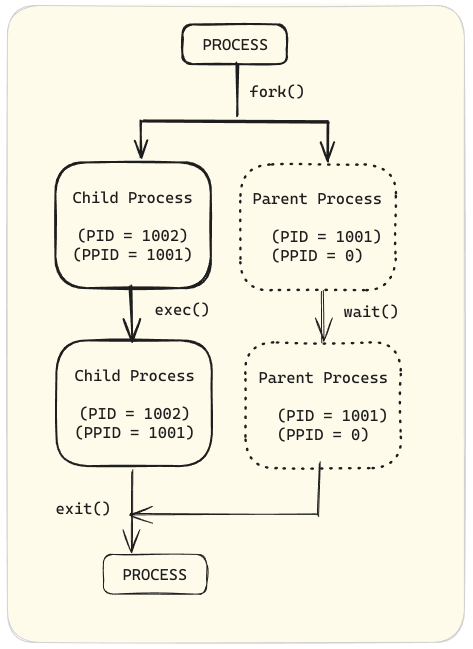
父进程通过复制自己的地址空间(fork)来创建一个新的(子)进程结构。每个新进程都被分配一个唯一的进程 ID(PID)以便于跟踪和安全目的。PID 和父进程的进程 ID(PPID)是新进程环境的一部分。任何进程都可以创建一个子进程。
通过fork例程,子进程继承了安全身份、先前和当前文件描述符、端口和资源权限、环境变量以及程序代码。然后,子进程可以执行自己的程序代码。
通常,父进程在子进程运行时休眠,设置一个请求(等待)以在子进程完成后收到通知。
退出时,子进程已经关闭或丢弃了其资源和环境。剩下的唯一资源被称为僵尸,是进程表中的一个条目。当子进程退出时,父进程被信号唤醒,清理子进程的进程表条目,从而释放子进程的最后一个资源。父进程然后继续执行自己的程序代码。
了解进程状态

Linux系统中的进程在其生命周期内会处于不同的状态。一个进程的状态表明了它目前正在做什么以及它是如何与系统交互的。进程根据它们的执行状态和系统的调度算法在状态之间进行转换。
| Linux系统中的进程可以处于以下状态之一: | 状态 |
| 描述 | (新) |
| 通过fork系统调用创建进程时的初始状态。 | 就绪(可运行)(R) |
| 进程已准备好运行,正在等待在CPU上调度。 | 运行(用户)(R) |
| 进程正在用户模式下执行,运行用户应用程序。 | 运行(内核)(R) |
| 进程正在内核模式下执行,处理系统调用或硬件中断。 | 睡眠(S) |
| 进程正在等待某个事件(例如,I/O操作)完成,并且可以很容易地被唤醒。 | 不可中断睡眠(D) |
| 进程处于不可中断的睡眠状态,等待一个特定条件(通常是I/O)完成,并且不能被信号中断。 | 磁盘睡眠(K) |
| 进程正在等待磁盘I/O操作完成。 | 空闲(I) |
| 进程空闲,没有进行任何工作,正在等待事件发生。 | 已停止(T) |
| 进程执行已被停止,通常是由一个信号引起,稍后可以恢复。 | 僵尸(Z) |
进程已完成执行,但在进程表中仍有条目,等待其父进程读取其退出状态。
| 进程在这些状态之间以下方式转换: | 转换 |
| 描述 | Fork |
| 从父进程创建一个新的进程,从(新)过渡到可运行(就绪)状态(R)。 | 调度 |
| 调度器选择一个可运行的进程,将其转换为运行中(用户)或运行中(内核)状态。 | 运行 |
| 当进程被安排执行时,从可运行(就绪)状态(R)转换为运行中(内核)状态(R)。 | 抢占或重新调度 |
| 进程可以被抢占或重新调度,将其返回为可运行(就绪)状态(R)。 | 系统调用 |
| 进程执行系统调用,从运行中(用户)状态(R)转换为运行中(内核)状态(R)。 | 返回 |
| 进程完成系统调用并返回到运行中(用户)状态(R)。 | 等待 |
| 进程等待事件,从运行中(内核)状态(R)转换到睡眠状态之一(S、D、K 或 I)。 | 事件或信号 |
| 进程由事件或信号唤醒,将其从睡眠状态恢复到可运行(就绪)状态(R)。 | 挂起 |
| 进程被挂起,从运行(内核)或可运行(就绪)状态转换为停止(T)状态。 | 恢复 |
| 进程被恢复,从停止(T)状态转换为可运行(就绪)状态(R)。 | 退出 |
| 进程终止,从运行(用户)或运行(内核)状态转换为僵尸(Z)状态。 | 收割 |
父进程读取僵尸进程的退出状态,将其从进程表中移除。
如何查看进程
zaira@zaira:~$ ps aux
您可以使用`ps`命令以及一系列选项的组合来在Linux系统上查看进程。`ps`命令用于显示有关活动进程的选择信息。例如,`ps aux`显示系统上所有运行的进程。
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 168140 11352 ? Ss May21 0:18 /sbin/init splash
root 2 0.0 0.0 0 0 ? S May21 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? I< May21 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< May21 0:00 [rcu_par_gp]
root 5 0.0 0.0 0 0 ? I< May21 0:00 [slub_flushwq]
root 6 0.0 0.0 0 0 ? I< May21 0:00 [netns]
root 11 0.0 0.0 0 0 ? I< May21 0:00 [mm_percpu_wq]
root 12 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_kthread]
root 13 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_rude_kthread]
*... output truncated ....*
# 输出
- 上述输出显示了系统上当前运行进程的快照。每一行代表一个进程,包含以下列:
USER:进程的所有者。PID:进程ID。%CPU:进程的CPU使用率。- %MEM:进程的内存使用情况。
- VSZ:进程的虚拟内存大小。
- RSS:常驻集大小,即任务已使用的未交换物理内存。
- TTY:进程的控制终端。
?表示没有控制终端。 Ss:会话领导者。这是一个启动了会话的进程,它是一组进程的领导者,可以控制终端信号。START:进程的启动时间或日期。TIME:累计CPU时间。
COMMAND:启动进程的命令。
后台和前台进程
在本节中,您将学习如何通过在后台或前台运行作业来控制它们。
作业是由shell启动的进程。当您在终端中运行命令时,它被视为一个作业。作业可以在前台或后台运行。
- 为了演示控制,您首先会创建3个进程,并将它们在后台运行。之后,您将列出进程,并在前台和后台之间切换。您将看到如何将它们挂起或完全退出。
创建三个进程
打开一个终端并启动三个长时间运行的进程。使用sleep命令,该命令使进程运行指定的秒数。
sleep 300 &
sleep 400 &
sleep 500 &
# 运行sleep命令分别为300、400和500秒
- 命令末尾的
&将进程移到后台。
显示后台作业
jobs
使用jobs命令来显示后台作业列表。
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
- 输出应该类似于这样:
将后台作业移到前台
fg %1
要将后台作业移到前台,请使用fg命令,后跟作业编号。例如,将第一个作业(sleep 300)移到前台:
- 这将把作业
1移到前台。
将前台作业再次移回后台
在前景任务运行时,您可以按Ctrl+Z将其挂起,并将其移回后台。
zaira@zaira:~$ fg %1
sleep 300
^Z
[1]+ Stopped sleep 300
zaira@zaira:~$ jobs
挂起的任务看起来像这样:
[1]+ Stopped sleep 300
[2] Running sleep 400 &
[3]- Running sleep 500 &
# 挂起的任务
现在使用bg命令将在后台恢复ID为1的任务。
# 按Ctrl+Z挂起前台任务
bg %1
- # 然后,在后台恢复它
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
再次显示任务
- 在这个练习中,您:
- 使用sleep命令启动了三个后台进程。
- 使用jobs命令显示后台任务列表。
- 使用
fg %job_number将任务调至前台。 - 使用
Ctrl+Z挂起任务,并使用bg %job_number将其移回后台。
再次使用jobs验证后台任务的状态。
现在您知道如何控制任务了。
结束进程
可以使用`kill`命令终止一个不响应或不需要的进程。`kill`命令向进程ID发送信号,请求它终止。
`kill`命令有几个可用的选项。
kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24)
...terminated
# kill命令的可选选项
- 以下是在Linux中使用`kill`命令的一些示例:
- 该命令向PID为1234的进程发送默认的`SIGTERM`信号,请求它终止。
- 该命令向所有指定名称的进程发送默认的`SIGTERM`信号。
- 此命令向PID为1234的进程发送
SIGKILL信号,强制终止它。 - 此命令向PID为1234的进程发送
SIGSTOP信号,停止它。
此命令向指定用户拥有的所有进程发送默认的SIGTERM信号。
这些例子展示了在Linux环境中使用kill命令管理进程的各种方法。
以下是关于kill命令选项和信号的表格形式的信息:此表总结了在Linux中用于管理进程的最常见的kill命令选项和信号。 |
命令/选项 | 信号 |
| 描述 | kill <pid> |
SIGTERM |
| 请求进程优雅地终止(默认信号)。 | kill -9 <pid> |
SIGKILL |
| 立即强制进程终止,无需清理。 | kill -SIGKILL <pid> |
SIGKILL |
| 立即强制进程终止,无需清理。 | kill -15 <pid> |
SIGTERM |
显式发送SIGTERM信号请求优雅终止。 |
kill -SIGTERM <pid> |
SIGTERM |
显式发送SIGTERM信号请求优雅终止。 |
kill -1 <pid> |
SIGHUP |
| 传统上意味着“挂断”;可用于重新加载配置文件。 | kill -SIGHUP <pid> |
SIGHUP |
| 传统上意味着”挂起”;可以用来重新加载配置文件。 | kill -2 |
SIGINT |
请求进程终止(与在终端中按下Ctrl+C相同)。 |
kill -SIGINT |
SIGINT |
请求进程终止(与在终端中按下Ctrl+C相同)。 |
kill -3 |
SIGQUIT |
| 导致进程终止并产生核心转储以进行调试。 | kill -SIGQUIT |
SIGQUIT |
| 导致进程终止并产生核心转储以进行调试。 | kill -19 |
SIGSTOP |
| 暂停进程。 | kill -SIGSTOP |
SIGSTOP |
| 暂停进程。 | kill -18 |
SIGCONT |
| 恢复暂停的进程。 | kill -SIGCONT |
SIGCONT |
| 恢复暂停的进程。 | killall |
变化 |
| 向具有给定名称的所有进程发送信号。 | killall -9 |
SIGKILL |
| 强制杀死所有名为给定名称的进程。 | pkill |
有所不同 |
| 根据模式匹配发送信号给进程。 | pkill -9 |
SIGKILL |
| 强制杀死所有匹配模式的进程。 | xkill |
SIGKILL |
允许点击窗口以杀死对应进程的图形实用程序。
8.5. Linux中的标准输入输出流
- 理解和掌握命令行和脚本编程,读取输入和写入输出是基本组成部分。在Linux中,每个进程都有三个默认的流:
-
stdin的文件描述符是0。 - 标准输出(
stdout):这是进程写入其输出的默认输出流。默认情况下,标准输出是终端。输出也可以重定向到文件或其他程序。stdout的文件描述符是1。
标准错误(stderr):这是进程写入错误消息的默认错误流。默认情况下,标准错误是终端,即使stdout被重定向,也能看到错误消息。stderr的文件描述符是2。
重定向与管道
重定向:你可以将错误和输出流重定向到文件或其他命令。例如:
ls > output.txt
# 将 stdout 重定向到文件
ls non_existent_directory 2> error.txt
# 将 stderr 重定向到文件
ls non_existent_directory > all_output.txt 2>&1
# 将 stdout 和 stderr 都重定向到文件
- 在最后一个命令中,
ls non_existent_directory:列出名为non_existent_directory的目录的内容。由于该目录不存在,ls将生成一个错误消息。> all_output.txt:操作符>将ls命令的标准输出(stdout)重定向到文件all_output.txt。如果该文件不存在,将被创建。如果存在,其内容将被覆盖。
2>&1::这里,2表示标准错误(stderr)的文件描述符。&1表示标准输出(stdout)的文件描述符。字符&用于指定1不是文件名而是文件描述符。
所以,`2>&1` 意味着“将 stderr (2) 重定向到 stdout (1) 当前去的地方”,在这种情况下是文件 `all_output.txt`。因此,`ls` 的输出(如果有)和错误消息都将被写入 `all_output.txt`。
管道:
ls | grep image
你可以使用管道(`|`)将一个命令的输出作为另一个命令的输入:
image-10.png
image-11.png
image-12.png
image-13.png
... Output truncated ...
# 输出
8.6 Linux 中的自动化 – 使用 Cron 作业自动化任务
Cron 是在类 Unix 操作系统中可用的强大作业调度工具。通过配置 cron,你可以设置自动化作业以每天、每周、每月或其他特定时间运行。cron 提供的自动化功能在 Linux 系统管理中扮演着至关重要的角色。
`crond` 守护进程(一种在后台运行的计算机程序)启用了 cron 功能。cron 读取 `crontab`(cron 表)以运行预定义的脚本。crontab
使用特定的语法,你可以配置 cron 作业来自动运行脚本或其他命令。
Linux 中的 cron 作业是什么?
通过 cron 安排的任何任务都称为 cron 作业。
现在,让我们来看看 cron 作业是如何工作的。
如何控制对 cron 的访问
为了使用 cron 作业,管理员需要允许在 `/etc/cron.allow` 文件中为用户添加 cron 作业。
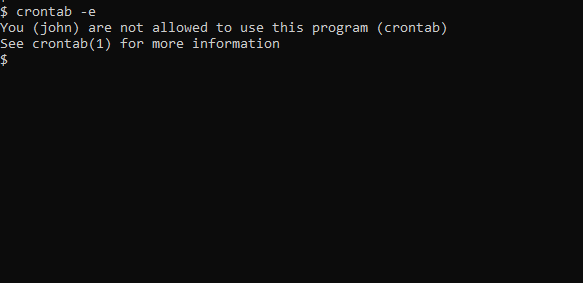
如果您收到这样的提示,意味着您没有使用cron的权限。
![]()
为了允许John使用cron,请在/etc/cron.allow文件中包含他的名字。如果这个文件不存在,请创建它。这将允许John创建和编辑cron作业。
用户也可以通过在/etc/cron.d/cron.deny文件中输入他们的用户名来禁止他们对cron作业的访问。
如何在Linux中添加cron作业
首先,为了使用cron作业,您需要检查cron服务的状态。如果cron尚未安装,您可以通过包管理器轻松下载它。只需使用这个来检查:
sudo systemctl status cron.service
# 在Linux系统上检查cron服务
Cron作业语法
- Crontabs使用以下标志来添加和列出cron作业:
crontab -e: 编辑crontab条目以添加、删除或编辑cron作业。crontab -l: 列出当前用户的全部cron作业。crontab -u 用户名 -l: 列出另一个用户的cron作业。
crontab -u 用户名 -e: 编辑另一个用户的cron作业。
当您列出cron作业并且它们存在时,您将看到类似这样的内容:
* * * * * sh /path/to/script.sh
# Cron 作业示例
- 在上面的示例中,
*分别代表分钟、小时、天、月、星期几。下面详细介绍这些值的含义: |
值 | |
| 描述 | 分钟 | 0-59 |
| 命令将在指定的分钟执行。 | 小时 | 0-23 |
| 命令将在指定的小时执行。 | 天 | 1-31 |
| 命令将在这些月份的日子里执行。 | 月 | 1-12 |
| 需要执行任务的自然月。 | 星期几 | 0-6 |
- 命令将在这些星期几运行。这里,0 是星期日。
sh表示脚本为bash脚本,应从/bin/bash运行。
/path/to/script.sh指定了脚本的路径。
* * * * * sh /path/to/script/script.sh
| | | | | |
| | | | | Command or Script to Execute
| | | | |
| | | | |
| | | | |
| | | | Day of the Week(0-6)
| | | |
| | | Month of the Year(1-12)
| | |
| | Day of the Month(1-31)
| |
| Hour(0-23)
|
Min(0-59)
以下是cron作业语法的总结:
Cron作业示例
| 以下是安排cron作业的一些示例。 | 计划 |
| 计划值 | 5 0 * 8 * |
| 在8月的第一天的凌晨00:05。 | 5 4 * * 6 |
| 在周六的凌晨04:05。 | 0 22 * * 1-5 |
每天工作周的周一至周五晚上22:00。
如果你一下不能完全理解这些,也没关系。你可以在crontab guru网站上练习并生成cron调度计划。
如何设置cron作业
- 在本节中,我们将通过一个例子来了解如何使用cron作业调度一个简单的脚本。
#!/bin/bash
echo `date` >> date-out.txt
创建一个名为date-script.sh的脚本,该脚本打印系统日期和时间,并将其追加到文件中。脚本如下所示:
chmod 775 date-script.sh
2. 通过赋予执行权限,使脚本可执行。
3. 使用crontab -e在crontab中添加脚本。
*/1 * * * * /bin/sh /root/date-script.sh
在这里,我们将其设置为每分钟运行一次。
cat date-out.txt
4. 检查文件date-out.txt的输出。根据脚本,系统日期应该会每分钟被打印到这个文件中。
Wed 26 Jun 16:59:33 PKT 2024
Wed 26 Jun 17:00:01 PKT 2024
Wed 26 Jun 17:01:01 PKT 2024
Wed 26 Jun 17:02:01 PKT 2024
Wed 26 Jun 17:03:01 PKT 2024
Wed 26 Jun 17:04:01 PKT 2024
Wed 26 Jun 17:05:01 PKT 2024
Wed 26 Jun 17:06:01 PKT 2024
Wed 26 Jun 17:07:01 PKT 2024
# 输出
如何排查cron问题
虽然cron非常有用,但它们可能并不总是按预期工作。幸运的是,有一些有效的方法可以用来排查它们。
1. 检查调度计划。
首先,你可以尝试验证为cron设置的调度计划。你可以使用我们上面章节中看到的语法来做这件事。
2. 检查cron日志。
首先,你需要检查cron是否在预期的时间运行了。在Ubuntu中,你可以从位于/var/log/syslog的cron日志中验证这一点。
如果这些日志在正确的时间有记录,这意味着cron已经按照你设置的计划运行了。
1 Jun 26 17:02:01 zaira-ThinkPad CRON[27834]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
2 Jun 26 17:02:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
3 Jun 26 17:03:01 zaira-ThinkPad CRON[28255]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
4 Jun 26 17:03:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
5 Jun 26 17:04:01 zaira-ThinkPad CRON[28538]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
以下是我们的cron作业的日志。注意第一列显示的时间戳。脚本的路径也 mention 在行的末尾。第1、3和5行显示脚本按预期运行。
3. 将cron输出重定向到文件。
你可以将cron的输出重定向到一个文件中,并检查文件中是否有任何可能的错误。
* * * * * sh /path/to/script.sh &> log_file.log
# 将cron输出重定向到文件
8.7. Linux网络基础
Linux提供了许多查看网络相关信息的命令。在本节中,我们将简要讨论一些命令。
使用ifconfig查看网络接口
ifconfig
ifconfig命令提供了网络接口的信息。以下是一个示例输出:
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::a00:27ff:fe4e:66a1 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:4e:66:a1 txqueuelen 1000 (Ethernet)
RX packets 1024 bytes 654321 (654.3 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 512 bytes 123456 (123.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 256 bytes 20480 (20.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 256 bytes 20480 (20.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 输出
ifconfig命令的输出显示了系统上配置的网络接口,以及诸如IP地址、MAC地址、数据包统计等信息。
这些接口可以是物理或虚拟设备。
要提取IPv4和IPv6地址,你可以分别使用ip -4 addr和ip -6 addr。
使用netstat查看网络活动
该netstat命令通过提供以下信息来显示网络活动和统计信息:
- 以下是一些在命令行中使用
netstat命令的示例: - 显示所有监听和非监听套接字:
- 只显示监听端口:
- 显示网络统计信息:
- 显示路由表:
- 显示TCP连接:
- 显示UDP连接:
- 显示网络接口:
- 显示连接的PID和程序名称:
- 为特定协议(例如,TCP)显示统计信息:
显示扩展信息:
使用ping检查两台设备之间的网络连通性
ping google.com
ping用于测试两台设备之间的网络连通性。它向目标设备发送ICMP数据包,并等待响应。
ping google.com
PING google.com (142.250.181.46) 56(84) bytes of data.
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=1 ttl=60 time=78.3 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=2 ttl=60 time=141 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=3 ttl=60 time=205 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=4 ttl=60 time=100 ms
^C
--- google.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3001ms
rtt min/avg/max/mdev = 78.308/131.053/204.783/48.152 ms
ping测试你是否能够在超时之前收到回应。
— 对 google.com 的 ping 统计 —
你可以使用Ctrl + C停止回应。
使用curl命令测试端点
curl命令代表”客户端URL”。它用于向服务器传输数据或从服务器接收数据。它还可以用于测试API端点,以帮助排查系统和应用程序错误。
curl http://www.official-joke-api.appspot.com/random_joke
{"type":"general",
"setup":"What did the fish say when it hit the wall?","punchline":"Dam.","id":1}
- 例如,你可以使用
http://www.official-joke-api.appspot.com/来尝试curl命令。
curl -o random_joke.json http://www.official-joke-api.appspot.com/random_joke
curl命令不带任何选项时默认使用GET方法。
curl -o将输出保存到指定的文件中。
curl -I http://www.official-joke-api.appspot.com/random_joke
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Vary: Accept-Encoding
X-Powered-By: Express
Access-Control-Allow-Origin: *
ETag: W/"71-NaOSpKuq8ChoxdHD24M0lrA+JXA"
X-Cloud-Trace-Context: 2653a86b36b8b131df37716f8b2dd44f
Content-Length: 113
Date: Thu, 06 Jun 2024 10:11:50 GMT
Server: Google Frontend
# 将输出保存到 random_joke.json
curl -I只获取头部信息。
8.8. Linux故障排除:工具和技术
使用sar的系统活动报告
sar是Linux中强大的工具,用于收集、报告和保存系统活动信息。它是sysstat包的一部分,常用于监控系统性能随时间的变化。
要使用sar,首先需要使用sudo apt install sysstat安装sysstat。
安装后,使用sudo systemctl start sysstat启动服务。
使用sudo systemctl status sysstat验证状态。
sar [options] [interval] [count]
状态激活后,系统将开始收集各种统计信息,您可以使用这些信息来获取和分析历史数据。我们很快就会详细看到。
sar -u 1 3
sar命令的语法如下:
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:09:26 CPU %user %nice %system %iowait %steal %idle
19:09:27 all 3.78 0.00 2.18 0.08 0.00 93.96
19:09:28 all 4.02 0.00 2.01 0.08 0.00 93.89
19:09:29 all 6.89 0.00 2.10 0.00 0.00 91.01
Average: all 4.89 0.00 2.10 0.06 0.00 92.95
例如,sar -u 1 3 每秒显示CPU利用率统计信息三次。
# 输出
以下是一些常见用例以及如何使用sar命令的示例。
sar可用于各种目的:
sar -r 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:10:46 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
19:10:47 4600104 8934352 5502124 36.32 375844 4158352 15532012 65.99 6830564 2481260 264
19:10:48 4644668 8978940 5450252 35.98 375852 4165648 15549184 66.06 6776388 2481284 36
19:10:49 4646548 8980860 5448328 35.97 375860 4165648 15549224 66.06 6774368 2481292 116
Average: 4630440 8964717 5466901 36.09 375852 4163216 15543473 66.04 6793773 2481279 139
1. 内存使用情况
要检查内存使用情况(免费和已使用),请使用:
此命令每秒显示三次内存统计信息。
sar -S 1 3
sar -S 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:11:20 kbswpfree kbswpused %swpused kbswpcad %swpcad
19:11:21 8388604 0 0.00 0 0.00
19:11:22 8388604 0 0.00 0 0.00
19:11:23 8388604 0 0.00 0 0.00
Average: 8388604 0 0.00 0 0.00
2. 交换空间利用率
要查看交换空间利用率统计信息,请使用:
这个命令有助于监控交换内存的使用情况,这对于物理内存不足的系统来说至关重要。
sar -d 1 3
3. I/O 设备负载
要报告块设备和块设备分区的活动情况:
这个命令提供了关于块设备之间数据传输的详细统计信息,对于诊断 I/O 瓶颈非常有用。
sar -n DEV 1 3
5. 网络统计
sar -n DEV 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:12:47 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
19:12:48 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 wlp3s0 10.00 3.00 1.83 0.37 0.00 0.00 0.00 0.00
19:12:48 br-5129d04f972f 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
.
.
.
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
...output truncated...
要查看网络统计信息,例如网络接口接收(发送)的数据包数量:
# -n DEV 告诉 sar 报告网络设备接口
这会每秒显示三次网络统计信息,帮助监控网络流量。
- 6. 历史数据
- # 会被 debconf 覆盖!
- 编辑 cron 作业配置以设置数据收集间隔。
sar -u -f /var/log/sysstat/sa04
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
15:20:49 LINUX RESTART (12 CPU)
16:13:30 LINUX RESTART (12 CPU)
18:16:00 CPU %user %nice %system %iowait %steal %idle
18:16:01 all 0.25 0.00 0.67 0.08 0.00 99.00
Average: all 0.25 0.00 0.67 0.08 0.00 99.00
用你想要查看数据的月份日替换 <DD>。
在下面的命令中,/var/log/sysstat/sa04 提供了当前月份第四天的统计数据。
sar -I SUM 1 3
7. 实时 CPU 中断
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:14:22 INTR intr/s
19:14:23 sum 5784.00
19:14:24 sum 5694.00
19:14:25 sum 5795.00
Average: sum 5757.67
要观察每秒由 CPU 服务的实时中断次数,使用此命令:
# 输出
这个命令有助于监控 CPU 处理中断的频率,这对于实时性能调优非常重要。
这些示例展示了如何使用 `sar` 命令来监控系统性能的各个方面。定期使用 `sar` 有助于识别系统瓶颈,确保应用程序能够高效运行。
8.9. 服务器的通用故障排除策略
我们为什么需要了解监控?
系统监控是系统管理的重要方面。关键应用需要高度的主动性以防止故障并减少停机影响。
Linux 提供了非常强大的工具来衡量系统健康状况。在本节中,您将了解可用于检查系统健康状况和识别瓶颈的各种方法。
[user@host ~]$ uptime 19:15:00 up 1:04, 0 users, load average: 2.92, 4.48, 5.20
查找负载平均值和系统运行时间
系统可能会重新启动,有时这可能会弄乱一些配置。要检查机器已运行多长时间,请使用命令:`uptime`。此命令除了显示运行时间外,还显示负载平均值。
负载平均值是过去1、5和15分钟的系统负载。快速查看可以判断系统负载是否随时间增加或减少。
注意:理想的 CPU 队列是 `0`。这只有在没有等待 CPU 的队列时才可能实现。
lscpu
可以通过将负载平均值除以可用的 CPU 总数来计算每个 CPU 的负载。
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
.
.
.
output omitted
要查找 CPU 数量,请使用命令 `lscpu`。
# 输出
如果负载平均值似乎在增加且不下降,说明CPU过载了。有些进程可能被卡住或者存在内存泄漏。
free -mh
计算空闲内存
total used free shared buff/cache available
Mem: 14Gi 3.5Gi 7.7Gi 109Mi 3.2Gi 10Gi
Swap: 8.0Gi 0B 8.0Gi
有时,高内存利用率可能会导致问题。要检查可用内存和使用的内存,请使用free命令。
# 输出
计算磁盘空间
df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 1.5G 2.4M 1.5G 1% /run
/dev/nvme0n1p2 103G 34G 65G 35% /
tmpfs 7.3G 42M 7.2G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
efivarfs 246K 93K 149K 39% /sys/firmware/efi/efivars
/dev/nvme0n1p3 130G 47G 77G 39% /home
/dev/nvme0n1p1 511M 6.1M 505M 2% /boot/efi
tmpfs 1.5G 140K 1.5G 1% /run/user/1000
为了确保系统健康,不要忘记检查磁盘空间。使用以下命令列出所有可用挂载点及其相应的使用百分比。理想情况下,使用的磁盘空间不应超过80%。
df命令提供了详细的磁盘空间信息。
确定进程状态
[user@host ~]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
runner 1 0.1 0.0 1535464 15576 ? S 19:18 0:00 /inject/init
runner 14 0.0 0.0 21484 3836 pts/0 S 19:21 0:00 bash --norc
runner 22 0.0 0.0 37380 3176 pts/0 R+ 19:23 0:00 ps aux
可以通过监控进程状态来查看是否有内存或CPU使用率高的卡住进程。
我们之前看到,ps命令提供了有关进程的有用信息。查看CPU和MEM列。
实时系统监控
实时监控为您提供了系统的实时状态窗口。
您可以使用的一个工具是top命令。
top命令显示系统的进程的动态视图,首先显示摘要头,然后是进程或线程列表。与静态的ps counterpart不同,top会持续刷新系统统计信息。
使用 `top`,您可以在紧凑的窗口中清晰地看到组织良好的详细信息。`top` 附带了许多标志、快捷方式和突出显示方法。
您还可以使用 `top` 来结束进程。为此,请按 `k` 键,然后输入进程 ID。
解读日志
系统和应用程序日志包含了系统正在经历的大量信息。它们包含指向错误的有用信息和错误代码。如果您在日志中搜索错误代码,可以大大减少问题识别和修复的时间。
网络端口分析
不应忽视网络方面,因为网络故障很常见,可能会影响系统和流量流动。常见的网络问题包括端口耗尽、端口拥堵、未释放的资源等。
| 要识别此类问题,我们需要了解端口状态。 | 以下简要解释了一些端口状态: |
| 状态 | 描述 |
| LISTEN | 代表等待来自任何远程 TCP 和端口的连接请求的端口。 |
| ESTABLISHED | 代表打开的连接,接收到的数据可以传送到目的地。 |
| TIME WAIT | 代表等待时间以确保其连接终止请求得到确认。 |
FIN WAIT2
代表等待来自远程 TCP 的连接终止请求。
[user@host ~]$ /sbin/sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 15000 65000
让我们探索如何在Linux中分析与端口相关的信息。
端口范围:端口范围在系统中定义,可以根据需要增加或减少范围。在下方的片段中,端口范围从15000到65000,总共有50000(65000 – 15000)个可用的端口。如果使用的端口达到或超过这个限制,那么就存在问题。
在这种情况下日志中报告的错误可能是绑定端口失败或连接过多。
识别数据包丢失
在系统监控中,我们需要确保出去和进来的通信是完整的。
[user@host ~]$ ping 10.13.6.113
PING 10.13.6.141 (10.13.6.141) 56(84) bytes of data.
64 bytes from 10.13.6.113: icmp_seq=1 ttl=128 time=0.652 ms
64 bytes from 10.13.6.113: icmp_seq=2 ttl=128 time=0.593 ms
64 bytes from 10.13.6.113: icmp_seq=3 ttl=128 time=0.478 ms
64 bytes from 10.13.6.113: icmp_seq=4 ttl=128 time=0.384 ms
64 bytes from 10.13.6.113: icmp_seq=5 ttl=128 time=0.432 ms
64 bytes from 10.13.6.113: icmp_seq=6 ttl=128 time=0.747 ms
64 bytes from 10.13.6.113: icmp_seq=7 ttl=128 time=0.379 ms
^C
--- 10.13.6.113 ping statistics ---
7 packets transmitted, 7 received,0% packet loss, time 6001ms
rtt min/avg/max/mdev = 0.379/0.523/0.747/0.134 ms
一个有帮助的命令是ping。ping击中目标系统并带回响应。注意统计信息的最后几行显示数据包丢失百分比和时间。
# ping 目标IP
也可以使用tcpdump在运行时捕获数据包。我们稍后看看。
为问题死后收集统计数据
- 收集一些在后来识别根本原因时会有用的统计数据总是好的做法。通常,在系统重启或服务重新启动后,我们会丢失先前的系统快照和日志。
以下是捕捉系统快照的一些方法。
- 日志备份
在做出任何更改之前,将日志文件复制到另一个位置。这对于了解系统在问题发生时的状态至关重要。有时,日志文件是查看过去系统状态的唯一窗口,因为其他运行时统计数据已经丢失。
sudo tcpdump -i any -w
TCP Dump
Tcpdump 是一个命令行工具,允许您捕获和分析传入和 outgoing 的网络流量。它主要用于帮助解决网络问题。如果您认为系统流量受到影响,请按照以下方式执行 tcpdump:
# 在哪里,
# -i any 捕获所有接口的流量
# -w 指定了输出文件名
# 在几分钟后停止命令,因为文件大小可能会增加
# 使用文件扩展名 .pcap
一旦捕获了 tcpdump,您可以使用 Wireshark 等工具 visually 分析流量。
结论
感谢您阅读本书至最后。如果您认为它有帮助,请考虑与他人分享。
尽管如此,本书并未结束。我将继续改进它,并在将来添加新材料。如果您发现有任何问题,或者您有任何改进建议,请随时打开一个 PR/Issue。
- 保持联系并继续您的学习之旅!
-
LinkedIn: 我会在那里分享科技文章和帖子。在LinkedIn上给我留下推荐,并对我相关的技能表示支持。
获取独家内容:一对一帮助和独家内容请点击这里。
获取独家内容:一对一帮助和独家内容请点击这里。
Source:
https://www.freecodecamp.org/news/learn-linux-for-beginners-book-basic-to-advanced/