













大数据自2000年代末开始发展以来已经显著进化。许多组织迅速适应了这一趋势,并利用Apache Hadoop等开源工具构建了它们的大数据平台。随后,这些公司开始面临管理不断发展的数据处理需求的困难。他们在处理模式级别变化、分区方案演变以及回溯数据等方面遇到了挑战。
我在2010年代为一家大型科技公司和一家医疗客户设计大规模分布式系统时也遇到了类似挑战。一些行业需要这些能力以遵守银行、金融和医疗保健法规。像Netflix这样的大数据驱动型公司也面临类似挑战。他们发明了一种名为“冰山”的表格格式,它位于现有数据文件之上,并通过利用其架构提供关键功能。随着数据社区对其表现出的迅速兴趣,它迅速成为顶级ASF项目。我将在本文中探讨Apache Iceberg的前5个关键功能,附带示例和图表。
1. 时间旅行

图1:Apache Iceberg表格格式中的时间旅行(图片由作者创建)
这一功能允许您在任意时间点查询数据的存在状态。这将为数据和业务分析师提供了解趋势以及数据随时间演变的新可能性。您可以轻松地回滚到先前状态以纠正任何错误。此功能还通过允许您在特定时间点分析数据来促进审计检查。
-- time travel to October 5th, 1978 at 07:00:00
SELECT * FROM prod.retail.cusotmers TIMESTAMP AS OF '1978-10-05 07:00:00';
-- time travel using a specific snapshot ID:
SELECT * FROM prod.retail.customers VERSON AS OF 949530903748831869;
2. 模式演变
Apache Iceberg 的模式演变允许对模式进行更改,而无需进行大量工作或昂贵的迁移。随着业务需求的发展,您可以:
- 添加和删除列而无需停机或重写表格。
- 更新列(扩展)。
- 更改列的顺序。
- 重命名现有列。
这些更改在元数据级别处理,无需重写基础数据。
-- add a new column to the table
ALTER TABLE prod.retail.customers ADD COLUMNS (email_address STRING);
-- remove an existing column from the table
ALTER TABLE prod.retail.customers DROP COLUMN num_of_years;
-- rename an existing column
ALTER TABLE prod.retail.customers RENAME COLUMN email_address TO email;
-- iceberg allows updating column types from int to bigint, float to double
ALTER TABLE prod.retail.customers ALTER COLUMN customer_id TYPE bigint;
3. 分区演变
使用 Apache Iceberg 表格格式,您可以更改表格分区策略,而无需重写基础表或将数据迁移到新表。这是因为查询不直接引用分区值,就像Apache Hadoop一样。Iceberg 为每个分区版本保留元数据信息。这使得在查询数据时轻松获得拆分。例如,在基于日期范围查询表时,表以月份作为分区列(之前)作为一个拆分,以天作为新分区列(之后)作为另一个拆分。这称为拆分计划。请参见以下示例。
-- create customers table partitioned by month of the create_date initially
CREATE TABLE local.retail.customer (
id BIGINT,
name STRING,
street STRING,
city STRING,
state STRING,
create_date DATE
USING iceberg
PARTITIONED BY (month(create_date));
-- insert some data into the table
INSERT INTO local.retail.customer VALUES
(1, 'Alice', '123 Maple St', 'Springfield', 'IL', DATE('2024-01-10')),
(2, 'Bob', '456 Oak St', 'Salem', 'OR', DATE('2024-02-15')),
(3, 'Charlie', '789 Pine St', 'Austin', 'TX', DATE('2024-02-20'));
-- change the partition scheme from month to date
ALTER TABLE local.retail.customer
REPLACE PARTITION FIELD month(create_date) WITH days(create_date);
-- insert couple more records
INSERT INTO local.retail.customer VALUES
(4, 'David', '987 Elm St', 'Portland', 'ME', DATE('2024-03-01')),
(5, 'Eve', '654 Birch St', 'Miami', 'FL', DATE('2024-03-02'));
-- select all columns from the table
SELECT * FROM local.retail.customer
WHERE create_date BETWEEN DATE('2024-01-01') AND DATE('2024-03-31');
-- output
1 Alice 123 Maple St Springfield IL 2024-01-10
5 Eve 654 Birch St Miami FL 2024-03-02
4 David 987 Elm St Portland ME 2024-03-01
2 Bob 456 Oak St Salem OR 2024-02-15
3 Charlie 789 Pine St Austin TX 2024-02-20
-- View parition details
SELECT partition, file_path, record_count
FROM local.retail.customer.files;
-- output
{"create_date_month":null,"create_date_day":2024-03-02} /Users/rellaturi/warehouse/retail/customer/data/create_date_day=2024-03-02/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00002.parquet 1
{"create_date_month":null,"create_date_day":2024-03-01} /Users/rvellaturi/warehouse/retail/customer/data/create_date_day=2024-03-01/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00001.parquet 1
{"create_date_month":648,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-01/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00001.parquet 1
{"create_date_month":649,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-02/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00002.parquet 2
4. ACID事务
Iceberg在原子性、一致性、隔离性和持久性(ACID)方面提供了强大的事务支持。它允许多个并发写操作,使得在数据密集型工作中能够实现高吞吐量而不影响数据一致性。
-- Start a transaction
START TRANSACTION;
-- Insert new records
INSERT INTO customers VALUES (1, 'John'), (2, 'Mike');
-- Update existing records
UPDATE customers SET column1 = 'Josh' WHERE id = 1;
-- Delete records
DELETE FROM customers WHERE id = 2;
-- Commit the transaction
COMMIT;
Iceberg中的所有操作都是事务性的,这意味着尽管发生故障或对数据进行并发修改,数据仍然保持一致。
-- Atomic update across multiple tables
START TRANSACTION;
UPDATE orders SET status = 'processed' WHERE order_id = 100;
INSERT INTO orders_processed SELECT * FROM orders WHERE order_id = 100;
COMMIT;
它还支持不同的隔离级别,使您能够根据需求在性能和一致性之间取得平衡。
-- Set isolation level (syntax may vary depending on the query engine)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Perform operations
SELECT * FROM customers WHERE id = 1;
UPDATE customers SET rec_status= 'updated' WHERE id = 1;
COMMIT;
以下是Iceberg如何处理行级更新和删除的总结。
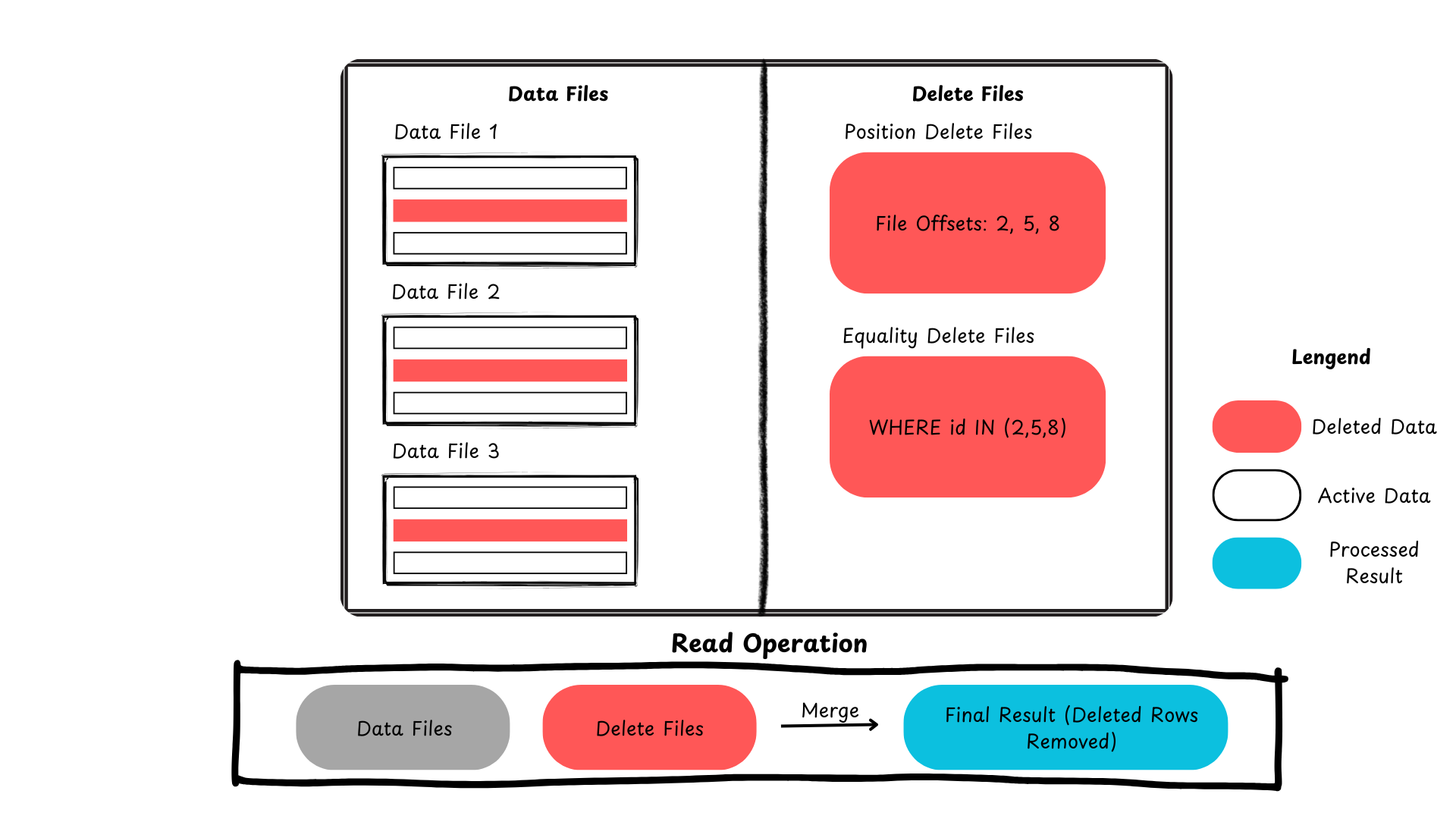
图2:Apache Iceberg中的删除记录过程(图像由作者创建)
5. 高级表操作
Iceberg支持以下高级表操作:
- 创建/管理表快照:这使得能够实现强大的版本控制。
- 通过高度优化的元数据实现快速查询规划和执行
- 内置表维护工具,如压缩和孤立文件清理
Iceberg旨在与所有主要云存储(如AWS S3、GCS和Azure Blob Storage)配合使用。此外,Iceberg还可以轻松与数据处理引擎(如Spark、Presto、Trino和Hive)集成。
最后思考
这些突出的功能使公司能够构建现代化、灵活、可扩展和高效的数据湖,可以进行时间旅行,轻松处理模式更改,支持ACID事务,并进行分区演化。
Source:
https://dzone.com/articles/key-features-of-apache-iceberg-for-data-lakes