













Elasticsearch是什么?
Elasticsearch是一个高度可扩展的分布式搜索和分析引擎,基于Apache Lucene搜索库构建。它旨在处理大量结构化、半结构化和非结构化数据,适用于多种应用场景,如搜索引擎、日志分析、电子商务和安全分析。
Elasticsearch采用分布式架构,能在集群中的多个节点上存储和处理大量数据。数据被索引并存储在分片中,这些分片分布在各个节点上,以提高可扩展性和容错性。Elasticsearch还支持实时搜索和分析,使用户能够近乎实时地查询和分析数据。
Elasticsearch的一个关键特性是其强大的搜索能力。它支持广泛的搜索查询,包括全文搜索、地理空间搜索等,并提供高级分析功能,如聚合、指标和数据可视化。
Elasticsearch常与Elastic Stack中的其他工具如Logstash(用于数据收集和处理)和Kibana(用于数据可视化和分析)结合使用,共同提供全面的搜索和分析解决方案,适用于广泛的应用和场景。
Apache Lucene是什么?
Apache Lucene 是一个开源的搜索引擎库,提供了强大的文本搜索和索引功能。它被广泛应用于开发者和组织中,用于构建从搜索引擎到电子商务平台等各种搜索应用。
Lucene 的工作原理是通过对文档的文本内容进行索引,并将索引存储在一种结构化的格式中,以便高效地进行搜索。索引由一系列倒排表组成,这些表提供了术语与包含它们的文档之间的映射。当提交搜索查询时,Lucene 利用索引快速检索匹配查询的文档。
除了核心的搜索和索引功能外,Lucene 还提供了一系列高级特性,包括模糊搜索和空间搜索的支持。它还提供了用于突出显示搜索结果和基于相关性对搜索结果进行排序的工具。
Lucene 被众多组织和项目所采用,包括 Elasticsearch。其丰富的功能、灵活性和可扩展性使其成为构建各种搜索应用的热门选择。
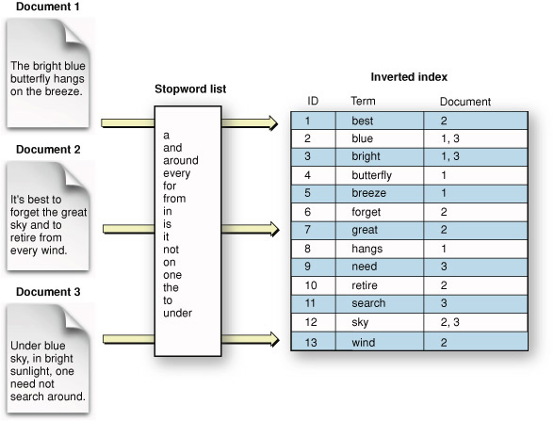
什么是倒排索引?
Lucene 的倒排索引是一种数据结构,用于从文档集合中高效地搜索和检索文本数据。倒排索引是 Lucene 的核心特性,用于存储构成索引的术语及其相关文档。
倒排索引相较于其他搜索策略具有多项优势。首先,它能够基于搜索词快速高效地检索文档。其次,它能处理大量文本数据,非常适合处理包含大量文档的使用场景。最后,它支持广泛的先进搜索功能,如模糊匹配和词干提取,这些功能能提升搜索结果的准确性和相关性。
为何选择Elasticsearch?
Elasticsearch成为构建搜索和分析应用的热门选择,原因如下:
易于扩展(分布式): Elasticsearch天生支持水平扩展。当需要增加容量时,只需添加更多节点,集群便会自动重组以利用额外的硬件资源。
一个服务器可以存储一个或多个索引的一个或多个部分,每当新的节点加入集群时,它们就像加入了聚会一样。每个这样的索引或其一部分称为分片,Elasticsearch分片可以非常容易地在集群中移动。
一切操作只需一次JSON调用(RESTful API): Elasticsearch是API驱动的。几乎任何操作都可以通过简单的RESTful API使用JSON格式通过HTTP进行。响应始终采用JSON格式。
Lucene的强大潜力: Elasticsearch内部使用Lucene构建其尖端的分布式搜索和分析功能。由于Lucene是一项稳定且经过验证的技术,并且不断添加更多特性和最佳实践,因此拥有Lucene作为支持Elasticsearch的底层引擎。
优秀的查询DSL: REST API提供了一个非常复杂且功能强大的查询DSL,使用起来非常简单。每个查询只是一个JSON对象,几乎可以包含任何类型的查询,甚至可以组合多个查询。使用过滤查询,其中一些查询表达为Lucene过滤器,有助于利用缓存,从而加快常见查询或可以重用的复杂查询部分。
多租户支持: 可以在一个Elasticsearch安装(节点或集群)上存储多个索引。好处是您可以使用一个简单的查询查询多个索引。
支持高级搜索功能(全文): Elasticsearch在底层使用Lucene,提供任何开源产品中最强大的全文搜索功能。搜索支持多语言,强大的查询语言,地理位置支持,上下文感知的“您是不是想找”建议,自动完成和搜索摘要。过滤器和评分器中的脚本支持。
可配置和可扩展: 许多Elasticsearch配置可以在运行时更改,但有些将需要重新启动(并且在某些情况下重新索引)。大多数配置也可以使用REST API进行更改。
面向文档: 在Elasticsearch中将复杂的现实世界实体存储为结构化的JSON文档。所有字段默认都被索引,所有索引均可用于单个查询中,以极快的速度返回结果。
无模式: Elasticsearch使得启动变得简单。发送一个JSON文档,它会尝试检测数据结构,索引数据,并使其可搜索。
冲突管理: 在需要时可以使用乐观版本控制,确保数据不会因多个进程间的冲突变更而丢失。
活跃社区: 除了创建优秀的工具和插件外,社区非常乐于助人和支持。整体氛围很好,这是任何OSS项目的重要指标。社区成员还在撰写一些书籍,并在网络上分享了许多博客文章,交流经验和知识。
Elasticsearch架构
Elasticsearch架构的主要组件包括:
节点: 节点是存储数据并提供搜索和索引功能的Elasticsearch实例。节点可以配置为既是主节点又是数据节点,或者两者之一。主节点负责集群的全局管理,而数据节点则存储数据并执行搜索操作。
集群: 集群是由一个或多个节点组成的组,共同存储和处理数据。一个集群可以包含多个索引(文档集合)和分片(一种在多个节点间分布数据的方式)。
索引: 索引是一系列具有相似结构的文档集合。每个文档以JSON对象形式表示,包含一个或多个字段。Elasticsearch默认索引所有字段,便于数据的搜索与分析。
分片: 索引可以被分割成多个分片,这些分片实质上是索引的小型子集。分片机制支持数据的并行处理及跨多节点的分布式存储。
副本: Elasticsearch能够为每个分片创建副本,以提供容错性和高可用性。副本是原始分片的拷贝,可以位于不同的节点上。
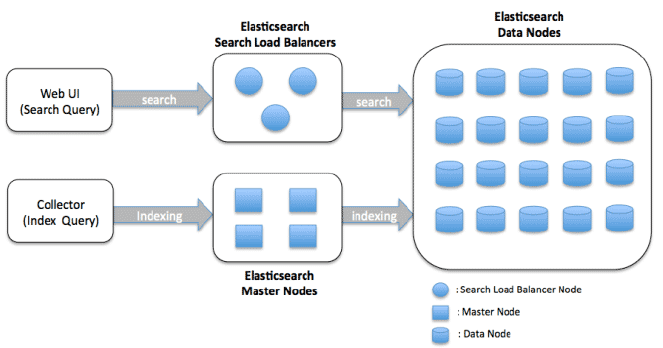
数据节点集群架构
数据节点负责存储和索引数据,同时执行搜索和聚合操作。该架构设计为可扩展和分布式,通过向集群中添加更多节点实现水平扩展。
以下是Elasticsearch数据节点集群架构的主要组成部分:
数据节点: 节点是存储数据、提供搜索和索引能力的Elasticsearch实例。在数据节点集群中,每个节点负责存储索引数据的一部分,并针对这些数据处理搜索查询。
集群状态: 集群状态是一个数据结构,包含关于集群的信息,如节点列表、索引、分片及其位置。主节点负责维护集群状态,并将其分发给集群中的所有其他节点。
发现与传输:Elasticsearch集群中的节点通过两种协议相互通信:发现协议和传输协议。发现协议负责识别加入集群的新节点或已离开集群的节点。传输协议则负责节点间的数据发送与接收。
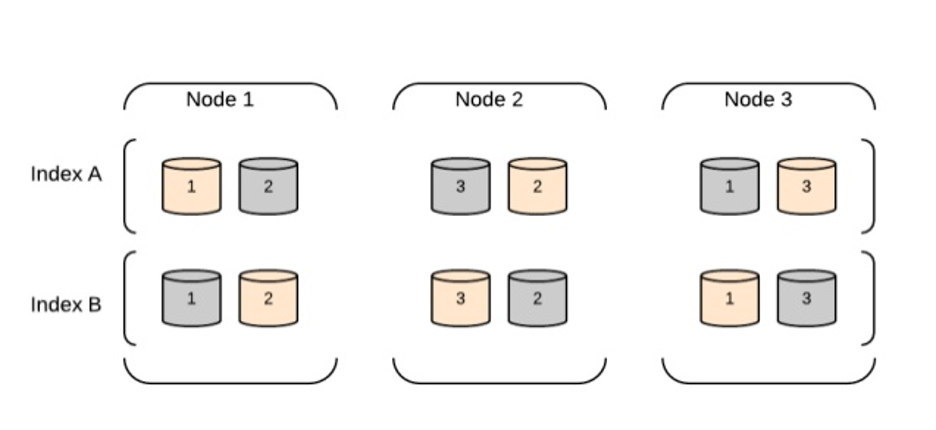
索引请求
在Elasticsearch中,索引请求的执行过程如下方框图所示。
谁在使用Elasticsearch?
使用Elasticsearch的部分公司和组织:
Netflix:Netflix利用Elasticsearch驱动其搜索和推荐引擎,使用户能快速找到想观看的内容。
GitHub:GitHub通过Elasticsearch为其代码仓库、问题和拉取请求提供快速高效的搜索功能。
Uber:Uber采用Elasticsearch为其实时分析平台提供支持,使其能够实时跟踪和分析打车服务的数据。
Wikipedia:Wikipedia使用Elasticsearch作为其搜索引擎,为用户提供快速准确的搜索结果。
Source:
https://dzone.com/articles/introduction-to-elasticsearch-1