













介绍
每个计算机系统都受益于适当的管理和监控。密切关注系统的运行状况将有助于您发现问题并快速解决。
有许多命令行实用程序是为此目的而创建的。本指南将向您介绍一些在工具箱中最有用的应用程序。
先决条件
要按照本指南进行操作,您需要访问运行基于Linux的操作系统的计算机。这可以是您通过SSH连接的虚拟专用服务器,也可以是您的本地计算机。请注意,本教程是在运行Ubuntu 20.04的Linux服务器上进行验证的,但给出的示例应该适用于运行任何版本的任何Linux发行版的计算机。
如果您计划使用远程服务器来按照本指南操作,我们鼓励您首先完成我们的初始服务器设置指南。这样做将为您提供一个安全的服务器环境 — 包括一个具有sudo权限的非root用户和使用UFW配置的防火墙 — 您可以使用它来构建您的Linux技能。
步骤1 – 如何查看Linux中正在运行的进程
您可以使用top命令查看服务器上正在运行的所有进程:
Outputtop - 15:14:40 up 46 min, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 56 total, 1 running, 55 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1019600k total, 316576k used, 703024k free, 7652k buffers
Swap: 0k total, 0k used, 0k free, 258976k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 24188 2120 1300 S 0.0 0.2 0:00.56 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/0
6 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
7 root RT 0 0 0 0 S 0.0 0.0 0:00.03 watchdog/0
8 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 cpuset
9 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 khelper
10 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
输出的前几行提供系统统计信息,如CPU/内存负载和正在运行任务的总数。
您可以看到有1个正在运行的进程,以及55个被认为是睡眠的进程,因为它们没有在主动使用CPU周期。
显示输出的其余部分显示了正在运行的进程及其使用统计信息。默认情况下,top会自动按CPU使用率对它们进行排序,因此您可以首先看到最繁忙的进程。top会持续在您的shell中运行,直到您使用标准的键组合Ctrl+C来停止它,以退出正在运行的进程。这将发送一个kill信号,指示进程如果能够的话要优雅地停止。
一个改进版的top,名为htop,可以在大多数软件包存储库中找到。在Ubuntu 20.04上,您可以使用apt安装它:
安装完成后,htop命令将可用:
Output Mem[||||||||||| 49/995MB] Load average: 0.00 0.03 0.05
CPU[ 0.0%] Tasks: 21, 3 thr; 1 running
Swp[ 0/0MB] Uptime: 00:58:11
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
1259 root 20 0 25660 1880 1368 R 0.0 0.2 0:00.06 htop
1 root 20 0 24188 2120 1300 S 0.0 0.2 0:00.56 /sbin/init
311 root 20 0 17224 636 440 S 0.0 0.1 0:00.07 upstart-udev-brid
314 root 20 0 21592 1280 760 S 0.0 0.1 0:00.06 /sbin/udevd --dae
389 messagebu 20 0 23808 688 444 S 0.0 0.1 0:00.01 dbus-daemon --sys
407 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.02 rsyslogd -c5
408 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.00 rsyslogd -c5
409 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.00 rsyslogd -c5
406 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.04 rsyslogd -c5
553 root 20 0 15180 400 204 S 0.0 0.0 0:00.01 upstart-socket-br
htop提供了更好的多个CPU线程可视化、对现代终端的颜色支持的更好认知以及更多排序选项等功能。与top不同,htop并非总是默认安装的,但可以被视为一种即插即用的替代品。您可以像使用top一样按Ctrl+C退出htop。
以下是一些键盘快捷键,可以帮助您更有效地使用htop:
- M: Sort processes by memory usage
- P: Sort processes by processor usage
- ?:访问帮助
- k: Kill current/tagged process
- F2:配置htop。您可以在这里选择显示选项。
- /:搜索进程
您可以通过帮助或设置访问许多其他选项。这些应该是您探索htop功能的第一站。在下一步中,您将学习如何监视您的网络带宽。
步骤2 – 如何监视您的网络带宽
如果您的网络连接似乎被过度利用,并且您不确定哪个应用程序是罪魁祸首,一个叫做nethogs的程序是一个很好的选择。
在Ubuntu上,您可以使用以下命令安装nethogs:
安装后,nethogs命令将可用:
OutputNetHogs version 0.8.0
PID USER PROGRAM DEV SENT RECEIVED
3379 root /usr/sbin/sshd eth0 0.485 0.182 KB/sec
820 root sshd: root@pts/0 eth0 0.427 0.052 KB/sec
? root unknown TCP 0.000 0.000 KB/sec
TOTAL 0.912 0.233 KB/sec
nethogs将每个应用程序与其网络流量相关联。
你可以使用的命令来控制 nethogs 只有一些:
- M: Change displays between “kb/s”, “kb”, “b”, and “mb”.
- R: Sort by traffic received.
- S: Sort by traffic sent.
- Q: quit
iptraf-ng 是另一种监控网络流量的方式。它提供了多种不同的交互式监控界面。
注意:IPTraf 需要至少 80 列 x 24 行的屏幕大小。
在 Ubuntu 上,你可以使用以下命令安装 iptraf-ng:
iptraf-ng 需要以 root 权限运行,因此你应该在其前面加上 sudo:
你会看到一个使用流行命令行界面框架 ncurses 的菜单。
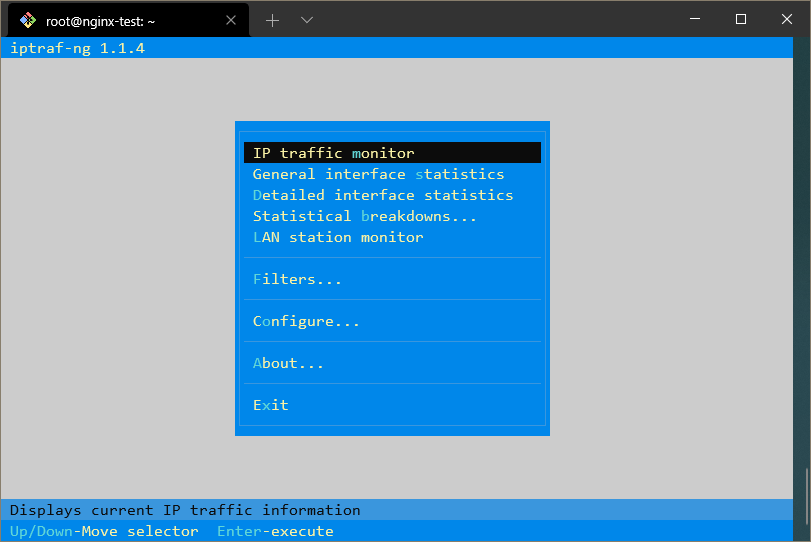
通过这个菜单,你可以选择要访问的界面。
例如,要获取所有网络流量的概览,你可以选择第一个菜单,然后选择“所有接口”。这会给你一个看起来像这样的屏幕:
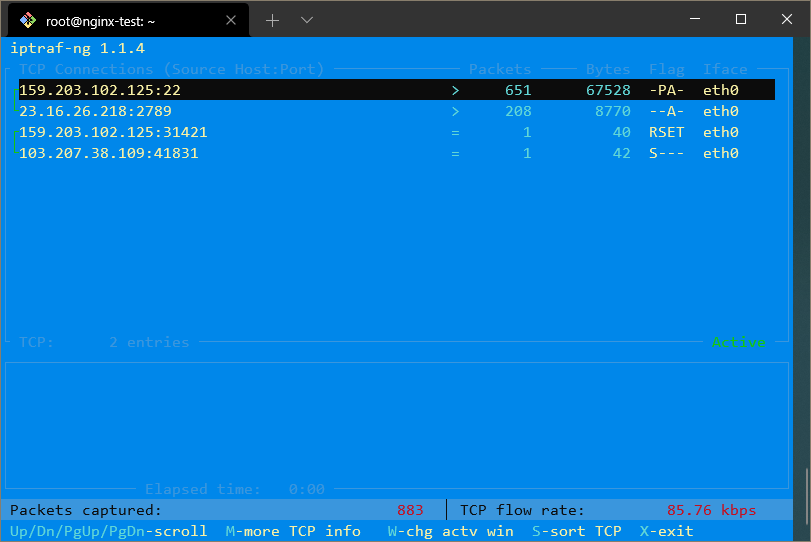
在这里,你可以看到你在所有网络接口上通信的 IP 地址。
如果你想要将这些 IP 地址解析为域名,你可以退出流量屏幕,选择 Configure 然后切换开启 Reverse DNS lookups。
你也可以启用 TCP/UDP service names 来查看服务的名称而不是端口号。
启用这两个选项后,显示可能会像这样:
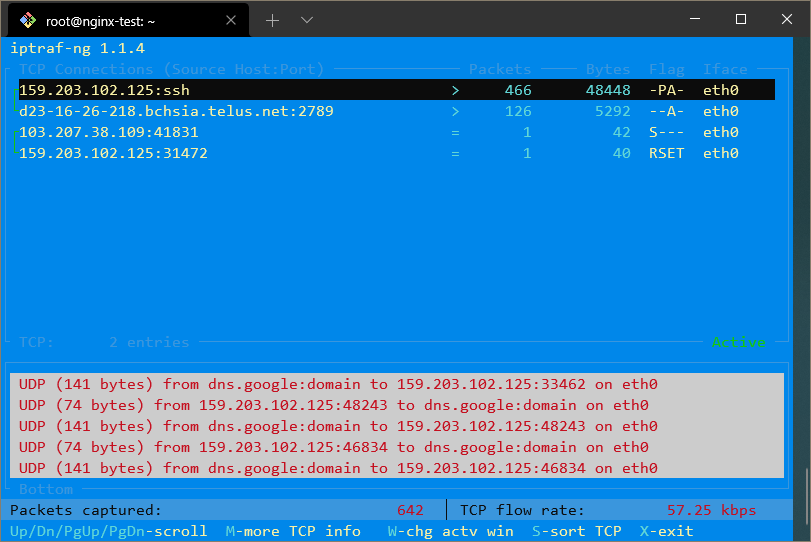
netstat 命令是另一个收集网络信息的多功能工具。
netstat 在大多数现代系统上默认安装,但您也可以通过从服务器的默认软件包存储库下载并安装它。在大多数Linux系统中,包含 netstat 的软件包是 net-tools:
默认情况下,netstat 命令本身会打印出一个开放套接字的列表:
OutputActive Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 192.241.187.204:ssh ip223.hichina.com:50324 ESTABLISHED
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
Active UNIX domain sockets (w/o servers)
Proto RefCnt Flags Type State I-Node Path
unix 5 [ ] DGRAM 6559 /dev/log
unix 3 [ ] STREAM CONNECTED 9386
unix 3 [ ] STREAM CONNECTED 9385
. . .
如果添加了 -a 选项,则会列出所有端口,包括监听和非监听的:
OutputActive Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
Active UNIX domain sockets (servers and established)
Proto RefCnt Flags Type State I-Node Path
unix 2 [ ACC ] STREAM LISTENING 6195 @/com/ubuntu/upstart
unix 2 [ ACC ] STREAM LISTENING 7762 /var/run/acpid.socket
unix 2 [ ACC ] STREAM LISTENING 6503 /var/run/dbus/system_bus_socket
. . .
如果您只想查看 TCP 或 UDP 连接,请分别使用 -t 或 -u 标志:
OutputActive Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
通过传递 “-s” 标志查看统计信息:
OutputIp:
13500 total packets received
0 forwarded
0 incoming packets discarded
13500 incoming packets delivered
3078 requests sent out
16 dropped because of missing route
Icmp:
41 ICMP messages received
0 input ICMP message failed.
ICMP input histogram:
echo requests: 1
echo replies: 40
. . .
如果您想要持续更新输出,可以使用 -c 标志。netstat 还提供了许多其他选项,您可以通过查看其手册页来了解:manual page。
在下一步中,您将学习一些有用的监视磁盘使用情况的方法。
步骤 3 – 如何监视磁盘使用情况
要快速了解附加驱动器上剩余多少磁盘空间,您可以使用 df 程序。
不带任何选项时,其输出如下:
OutputFilesystem 1K-blocks Used Available Use% Mounted on
/dev/vda 31383196 1228936 28581396 5% /
udev 505152 4 505148 1% /dev
tmpfs 203920 204 203716 1% /run
none 5120 0 5120 0% /run/lock
none 509800 0 509800 0% /run/shm
这会以字节的形式输出磁盘使用情况,可能有点难以阅读。
要解决这个问题,您可以指定以人类可读的格式输出:
OutputFilesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shm
如果你想查看所有文件系统上可用的总磁盘空间,可以使用--total选项。这将在底部添加一行摘要信息:
OutputFilesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shm
total 32G 1.2G 29G 4%
df可以提供有用的概览。另一个命令du按目录进行了分解。
du将分析当前目录和任何子目录的使用情况。在几乎空的主目录中运行du的默认输出如下:
Output4 ./.cache
8 ./.ssh
28 .
再次,您可以通过传递-h来指定易读的输出:
Output4.0K ./.cache
8.0K ./.ssh
28K .
要查看文件大小以及目录,键入以下内容:
Output0 ./.cache/motd.legal-displayed
4 ./.cache
4 ./.ssh/authorized_keys
8 ./.ssh
4 ./.profile
4 ./.bashrc
4 ./.bash_history
28 .
要在底部显示总计,可以添加-c选项:
Output4 ./.cache
8 ./.ssh
28 .
28 total
如果您只对总计感兴趣而不关心具体细节,可以发出:
Output28 .
还有一个适用于du的ncurses界面,适当地称为ncdu,您可以安装:
这将以图形方式表示您的磁盘使用情况:
Output--- /root ----------------------------------------------------------------------
8.0KiB [##########] /.ssh
4.0KiB [##### ] /.cache
4.0KiB [##### ] .bashrc
4.0KiB [##### ] .profile
4.0KiB [##### ] .bash_history
您可以使用上下箭头逐步浏览文件系统,并在任何目录条目上按Enter。
在最后一节中,您将学习如何监视内存使用情况。
步骤4 – 如何监视内存使用情况
您可以使用free命令检查系统当前的内存使用情况。
当未使用选项时,输出如下:
Output total used free shared buff/cache available
Mem: 1004896 390988 123484 3124 490424 313744
Swap: 0 0 0
要以更易读的格式显示,您可以通过传递-m选项来显示以兆字节为单位的输出:
Output total used free shared buff/cache available
Mem: 981 382 120 3 478 306
Swap: 0 0 0
Mem行包括用于缓冲和缓存的内存,该内存在需要时会立即释放以供其他用途使用。Swap是已写入磁盘上的swapfile以节省活动内存的内存。
最后,vmstat命令可以输出有关您的系统的各种信息,包括内存、交换、磁盘IO和CPU信息。
您可以使用该命令来获取对内存使用情况的另一个视图:
Outputprocs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 99340 123712 248296 0 0 0 1 9 3 0 0 100 0
您可以通过使用-S标志指定单位来以兆字节为单位查看此信息:
Outputprocs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 96 120 242 0 0 0 1 9 3 0 0 100 0
要获取有关内存使用情况的一些常规统计信息,请键入:
Output 495 M total memory
398 M used memory
252 M active memory
119 M inactive memory
96 M free memory
120 M buffer memory
242 M swap cache
0 M total swap
0 M used swap
0 M free swap
. . .
要获取有关单个系统进程的缓存使用情况的信息,请键入:
OutputCache Num Total Size Pages
ext4_groupinfo_4k 195 195 104 39
UDPLITEv6 0 0 768 10
UDPv6 10 10 768 10
tw_sock_TCPv6 0 0 256 16
TCPv6 11 11 1408 11
kcopyd_job 0 0 2344 13
dm_uevent 0 0 2464 13
bsg_cmd 0 0 288 14
. . .
这将向您提供有关存储在缓存中的信息类型的详细信息。
结论
使用这些工具,您应该开始能够通过命令行监视您的服务器。有许多其他用于不同目的的监视实用程序,但这些是一个很好的起点。
接下来,您可能想学习使用ps、kill和nice进行Linux进程管理。