













作者选择了自由开源基金作为Write for Donations计划的捐赠对象。
介绍
Flask是一个轻量级的Python Web框架,提供了在Python语言中创建Web应用程序的有用工具和功能。 SQLAlchemy是一个SQL工具包,为关系型数据库提供了高效和高性能的数据库访问。它提供了与多个数据库引擎(如SQLite、MySQL和PostgreSQL)交互的方式。它使您可以访问数据库的SQL功能。它还提供了一个对象关系映射器(ORM),允许您使用简单的Python对象和方法进行查询和处理数据。Flask-SQLAlchemy是一个Flask扩展,使得在Flask应用程序中使用SQLAlchemy更加简单,为您提供通过SQLAlchemy在Flask应用程序中与数据库交互的工具和方法。
在本教程中,您将使用Flask和Flask-SQLAlchemy创建一个具有员工表的数据库的员工管理系统。每个员工将拥有一个唯一的ID、名、姓、唯一的电子邮件、年龄的整数值、加入公司的日期和一个布尔值,用于确定员工当前是否处于活动状态或办公室外。
您将使用Flask shell来查询表,并根据列值(例如,电子邮件)获取表记录。您将在特定条件下检索员工的记录,例如仅获取活动员工或获取办公室外员工的列表。您将按列值对结果进行排序,并计算和限制查询结果。最后,您将使用分页在Web应用程序中每页显示一定数量的员工。
先决条件
-
本地Python 3编程环境。请按照《如何安装和设置本地Python 3编程环境》系列中适用于您发行版的教程进行操作。在本教程中,我们将称项目目录为
flask_app。 -
对基本的 Flask 概念有一定的了解,例如路由、视图函数和模板。如果您对 Flask 不熟悉,可以查看《如何使用 Flask 和 Python 创建您的第一个 Web 应用程序》和《如何在 Flask 应用程序中使用模板》。
-
对基本的 HTML 概念有一定的了解。您可以查阅我们的《如何使用 HTML 构建网站》教程系列了解背景知识。
-
了解基本的Flask-SQLAlchemy概念,如设置数据库、创建数据库模型和向数据库插入数据。请参阅如何在Flask应用程序中使用Flask-SQLAlchemy与数据库交互以获取背景知识。
步骤1 — 设置数据库和模型
在此步骤中,您将安装必要的软件包,并设置您的Flask应用程序、Flask-SQLAlchemy数据库和表示您将存储员工数据的employee表的员工模型。您将向employee表插入一些员工,并在您的应用程序首页上添加一个路由和页面,显示所有员工。
首先,激活虚拟环境后,安装Flask和Flask-SQLAlchemy:
安装完成后,您将收到以下输出,并在最后一行看到如下内容:
Output
Successfully installed Flask-2.1.2 Flask-SQLAlchemy-2.5.1 Jinja2-3.1.2 MarkupSafe-2.1.1 SQLAlchemy-1.4.37 Werkzeug-2.1.2 click-8.1.3 greenlet-1.1.2 itsdangerous-2.1.2
安装必需的软件包后,在 flask_app 目录中打开一个名为 app.py 的新文件。此文件将包含设置数据库和Flask路由的代码:
将以下代码添加到 app.py 中。此代码将设置一个SQLite数据库和一个员工数据库模型,表示您将用于存储员工数据的 employee 表:
保存并关闭文件。
在这里,您导入了 os 模块,它为您提供了杂项操作系统接口的访问权限。您将使用它来构建 database.db 数据库文件的文件路径。
从 flask 软件包中,您导入了应用程序所需的辅助程序: Flask 类用于创建Flask应用程序实例, render_template() 用于呈现模板, request 对象用于处理请求, url_for() 用于构造URL,并使用 redirect() 函数将用户重定向。有关路由和模板的更多信息,请参见如何在Flask应用程序中使用模板。
然后,您从Flask-SQLAlchemy扩展中导入 SQLAlchemy 类,该扩展使您可以访问来自SQLAlchemy的所有函数和类,以及与SQLAlchemy集成的Flask的帮助程序和功能。您将使用它来创建一个连接到您的Flask应用程序的数据库对象。
构建数据库文件路径时,您将基本目录定义为当前目录。您使用os.path.abspath()函数获取当前文件所在目录的绝对路径。特殊的__file__变量保存当前app.py文件的路径名。您将基本目录的绝对路径存储在名为basedir的变量中。
然后,您创建一个名为app的Flask应用实例,用于配置两个Flask-SQLAlchemy 配置键:
-
SQLALCHEMY_DATABASE_URI:数据库URI,用于指定要建立连接的数据库。在本例中,URI遵循格式sqlite:///path/to/database.db。您使用os.path.join()函数智能地将您构造并存储在basedir变量中的基本目录与database.db文件名连接起来。这将连接到flask_app目录中的database.db数据库文件。一旦初始化数据库,该文件将被创建。 -
SQLALCHEMY_TRACK_MODIFICATIONS:配置以启用或禁用对象修改的跟踪。您将其设置为False以禁用跟踪,这样使用的内存较少。有关更多信息,请参阅Flask-SQLAlchemy文档中的配置页面。
配置SQLAlchemy后,通过设置数据库URI并禁用跟踪,您可以使用SQLAlchemy类创建一个数据库对象,将应用程序实例传递给它,以将您的Flask应用程序与SQLAlchemy连接起来。您将数据库对象存储在名为db的变量中,您将使用该变量与数据库进行交互。
在设置了应用程序实例和数据库对象之后,您可以继承db.Model类来创建一个名为Employee的数据库模型。此模型代表employee表,具有以下列:
id:员工ID,整数主键。firstname:员工的名字,字符串,最大长度为100个字符。nullable=False表示此列不应为空。lastname:员工的姓氏,字符串,最大长度为100个字符。nullable=False表示此列不应为空。email:员工的电子邮件,字符串,最大长度为100个字符。unique=True表示每个电子邮件应唯一。nullable=False表示其值不应为空。age:员工的年龄,整数值。hire_date:员工入职日期。您可以将db.Date设置为列类型以声明其为保存日期的列。active:一个列,将保存布尔值以指示员工当前是否在职或离职。
特殊的__repr__函数允许您为每个对象提供一个字符串表示,以便识别它进行调试。在这种情况下,您使用员工的名字来表示每个员工对象。
现在,您已经设置了数据库连接和员工模型,接下来将编写一个Python程序来创建数据库和employee表,并将表中填充一些员工数据。
在您的flask_app目录中打开一个名为init_db.py的新文件:
添加以下代码以删除现有数据库表以便从一个干净的数据库开始,创建employee表,并向其插入九名员工:
在这里,您从datetime模块导入date()类以将其用于设置员工入职日期。
您导入数据库对象和Employee模型。您调用db.drop_all()函数来删除所有现有表,以避免数据库中存在已填充的employee表可能导致问题的机会。这会在每次执行init_db.py程序时删除所有数据库数据。有关创建、修改和删除数据库表的更多信息,请参阅如何使用Flask-SQLAlchemy与Flask应用程序交互。
然后,创建几个Employee模型的实例,这些实例代表了在本教程中要查询的员工,并使用db.session.add_all()函数将它们添加到数据库会话中。最后,提交事务并将更改应用到数据库中,使用db.session.commit()。
保存并关闭文件。
执行init_db.py程序:
要查看您添加到数据库中的数据,请确保已激活虚拟环境,并打开Flask shell以查询所有员工并显示其数据:
运行以下代码来查询所有员工并显示其数据:
您使用query属性的all()方法来获取所有员工。您循环遍历结果,并显示员工信息。对于active列,您使用条件语句显示员工的当前状态,即'Active'或'Out of Office'。
您将收到以下输出:
OutputJohn Doe
Email: [email protected]
Age: 32
Hired: 2012-03-03
Active
----
Mary Doe
Email: [email protected]
Age: 38
Hired: 2016-06-07
Active
----
Jane Tanaka
Email: [email protected]
Age: 32
Hired: 2015-09-12
Out of Office
----
Alex Brown
Email: [email protected]
Age: 29
Hired: 2019-01-03
Active
----
James White
Email: [email protected]
Age: 24
Hired: 2021-02-04
Active
----
Harold Ishida
Email: [email protected]
Age: 52
Hired: 2002-03-06
Out of Office
----
Scarlett Winter
Email: [email protected]
Age: 22
Hired: 2021-04-07
Active
----
Emily Vill
Email: [email protected]
Age: 27
Hired: 2019-06-09
Active
----
Mary Park
Email: [email protected]
Age: 30
Hired: 2021-08-11
Active
----
您可以看到我们添加到数据库中的所有员工都被正确显示。
退出Flask shell:
接下来,您将创建一个Flask路由来显示员工。打开app.py进行编辑:
在文件末尾添加以下路由:
保存并关闭文件。
这将查询所有员工,渲染一个index.html模板,并将您获取的员工传递给它。
创建一个模板目录和一个基础模板:
将以下内容添加到base.html文件中:
保存并关闭文件。
在这里,您使用标题块并添加一些CSS样式。您添加了一个带有两个项目的导航栏,一个用于首页,一个用于非活动的关于页面。这个导航栏将在从这个基础模板继承的模板中被重用。内容块将被替换为每个页面的内容。有关模板的更多信息,请查看如何在Flask应用程序中使用模板。
接下来,在app.py中渲染的新index.html模板中打开一个新的文件:
将以下代码添加到文件中:
在这里,您遍历员工并显示每个员工的信息。如果员工是活动的,则添加一个(活动)标签,否则显示一个(暂不接受约见)标签。
保存并关闭文件。
在激活虚拟环境的情况下,进入你的flask_app目录,并告诉Flask关于应用程序(在本例中是app.py)的信息,使用FLASK_APP环境变量。然后将FLASK_ENV环境变量设置为development以在开发模式下运行应用程序,并获得调试器的访问权限。有关Flask调试器的更多信息,请参见如何在Flask应用程序中处理错误。使用以下命令执行这些操作:
接下来,运行应用程序:
在开发服务器运行时,使用浏览器访问以下URL:
http://127.0.0.1:5000/
您将在类似以下的页面中看到您添加到数据库的员工:
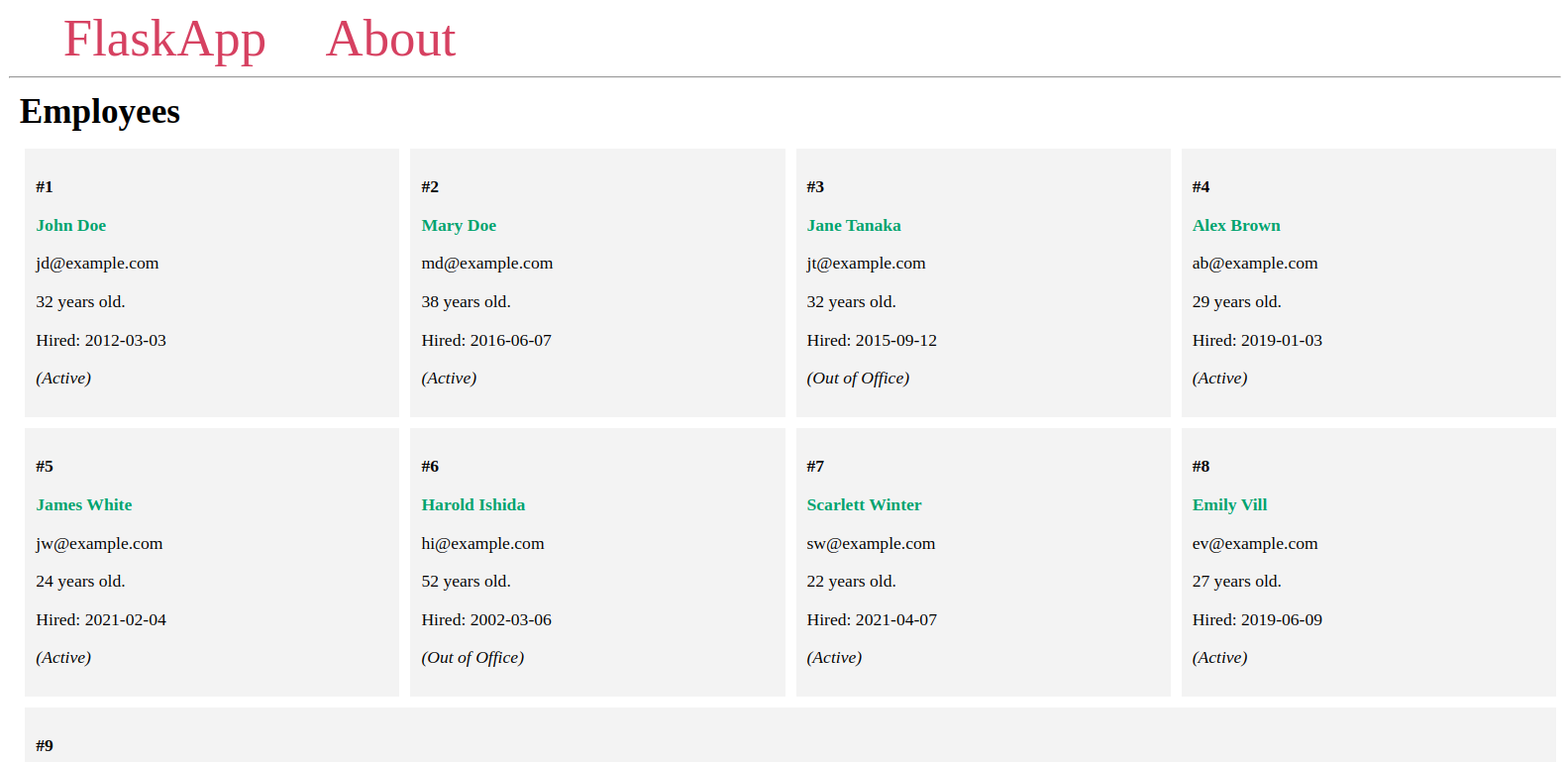
保持服务器运行状态,打开另一个终端,并继续下一步。
您已在首页显示了您数据库中的员工。接下来,您将使用Flask shell使用不同的方法查询员工。
步骤2 — 查询记录
在此步骤中,您将使用Flask shell查询记录,并使用多种方法和条件过滤和检索结果。
在你的编程环境激活状态下,设置FLASK_APP和FLASK_ENV变量,并打开Flask shell:
导入 db 对象和 Employee 模型:
检索所有记录
正如您在上一步中所见,您可以在 query 属性上使用 all() 方法来获取表中的所有记录:
输出将是一个表示所有员工的对象列表:
Output
[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>, <Employee Alex Brown>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>, <Employee Emily Vill>, <Employee Mary Park>]
检索第一条记录
同样,您可以使用 first() 方法来获取第一条记录:
输出将是一个保存第一位员工数据的对象:
Output<Employee John Doe>
通过ID检索记录
在大多数数据库表中,记录都使用唯一的ID进行标识。Flask-SQLAlchemy 允许您使用 get() 方法通过其ID获取记录:
Output<Employee James White> | ID: 5
<Employee Jane Tanaka> | ID: 3
通过列值检索记录或多个记录
要使用其列值之一获取记录,请使用filter_by()方法。例如,要使用其ID值获取记录,类似于get()方法:
Output<Employee John Doe>
您使用first()因为filter_by()可能返回多个结果。
注意:使用get()方法来按ID获取记录是一个更好的方法。
举个例子,您可以使用员工的年龄来获取他们:
Output<Employee Harold Ishida>
对于一个查询结果包含多个匹配记录的示例,请使用firstname列和名字Mary,这是两个员工共享的名字:
Output[<Employee Mary Doe>, <Employee Mary Park>]
在这里,您使用all()来获取完整列表。您也可以使用first()来获取第一个结果:
Output<Employee Mary Doe>
您已经通过列值获取了记录。接下来,您将使用逻辑条件查询您的表。
步骤 3 — 使用逻辑条件过滤记录
在复杂的、功能完整的Web应用程序中,通常需要使用复杂的条件从数据库中查询记录,例如根据考虑到他们的位置、可用性、角色和职责的组合条件来获取员工。在这一步中,您将练习使用条件运算符。您将使用query属性上的filter()方法,使用不同的运算符和逻辑条件过滤查询结果。例如,您可以使用逻辑运算符来获取当前不在办公室的员工列表,或者需要晋升的员工列表,并可能提供员工休假时间的日历等。
等于
您可以使用的最简单的逻辑运算符是相等运算符==,它的行为类似于filter_by()。例如,要获取firstname列的值为Mary的所有记录,您可以像这样使用filter()方法:
在这里,您使用Model.column == value的语法作为filter()方法的参数。filter_by()方法是此语法的快捷方式。
结果与具有相同条件的filter_by()方法的结果相同:
Output[<Employee Mary Doe>, <Employee Mary Park>]
与filter_by()类似,您也可以使用first()方法获取第一个结果:
Output<Employee Mary Doe>
不等于
filter() 方法允许您使用 != Python 操作符获取记录。例如,要获取一个离职员工列表,您可以使用以下方法:
Output[<Employee Jane Tanaka>, <Employee Harold Ishida>]
在这里,您使用 Employee.active != True 条件来过滤结果。
小于
您可以使用 < 操作符来获取给定列的值小于指定值的记录。例如,要获取年龄小于 32 岁的员工列表:
Output
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
对于小于或等于给定值的记录,请使用 <= 操作符。例如,要在上一查询中包括年龄为 32 岁的员工:
Output
John Doe
Age: 32
----
Jane Tanaka
Age: 32
----
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
大于
类似地,> 操作符获取给定列的值大于指定值的记录。例如,要获取年龄大于 32 岁的员工:
OutputMary Doe
Age: 38
----
Harold Ishida
Age: 52
----
而 >= 操作符是用于大于或等于给定值的记录。例如,您可以在上一个查询中再次包括 32 岁的员工:
Output
John Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Harold Ishida
Age: 52
----
在
SQLAlchemy还提供了一种方法,可以使用列上的in_()方法来获取列值与给定值列表中的值匹配的记录,如下所示:
Output[<Employee Mary Doe>, <Employee Alex Brown>, <Employee Emily Vill>, <Employee Mary Park>]
在这里,您可以使用语法Model.column.in_(iterable)的条件,其中iterable可以是任何类型的您可以迭代的对象。例如,您可以使用range() Python函数来获取特定年龄范围内的员工。以下查询获取所有三十多岁的员工。
OutputJohn Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Mary Park
Age: 30
----
不在
类似于in_()方法,您可以使用not_in()方法来获取列值不在给定可迭代对象中的记录:
Output
[<Employee John Doe>, <Employee Jane Tanaka>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>]
在这里,您获取除了names列表中有名字的员工以外的所有员工。
并且
您可以使用db.and_()函数将多个条件组合在一起,该函数的工作原理类似于Python的and运算符。
例如,假设您想获取所有年龄为32岁且目前处于活动状态的员工。首先,您可以使用filter_by()方法(也可以使用filter())来查找年龄为32岁的员工:
Output<Employee John Doe>
Age: 32
Active: True
-----
<Employee Jane Tanaka>
Age: 32
Active: False
-----
在这里,您可以看到John和Jane是年龄为32岁的员工。John处于活动状态,Jane正在休假。
要获取年龄为32岁且活动的员工,您将使用filter()方法来添加两个条件:
Employee.age == 32Employee.active == True
要将这两个条件组合在一起,使用db.and_()函数,如下所示:
Output[<Employee John Doe>]
在这里,您使用filter(db.and_(condition1, condition2))的语法。
在查询上使用all()会返回符合两个条件的所有记录的列表。您可以使用first()方法来获取第一个结果:
Output<Employee John Doe>
对于一个更复杂的示例,您可以使用db.and_()与date()函数来获取在特定时间范围内入职的员工。在这个示例中,您获取了所有在2019年入职的员工:
Output<Employee Alex Brown> | Hired: 2019-01-03
<Employee Emily Vill> | Hired: 2019-06-09
在这里,您导入了date()函数,并使用db.and_()函数来组合以下两个条件:
Employee.hire_date >= date(year=2019, month=1, day=1):对于2019年1月1日或之后入职的员工,这是True。Employee.hire_date < date(year=2020, month=1, day=1):这对于在2020年1月1日之前受雇的员工是True。
结合这两个条件可以获取从2019年1月1日开始受雇的员工,但在2020年1月1日之前受雇。
或者
类似于db.and_(),db.or_()函数组合两个条件,其行为类似于Python中的or运算符。它获取满足两个条件之一的所有记录。例如,要获取年龄为32岁或52岁的员工,可以使用db.or_()函数组合两个条件,如下所示:
Output<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
<Employee Harold Ishida> | Age: 52
您还可以在传递给filter()方法的条件中使用startswith()和endswith()方法。例如,要获取名字以字符串'M'开头并且姓以字符串'e'结尾的所有员工:
Output<Employee John Doe>
<Employee Mary Doe>
<Employee James White>
<Employee Mary Park>
在此处组合以下两个条件:
Employee.firstname.startswith('M'):匹配名字以'M'开头的员工。Employee.lastname.endswith('e'):匹配姓以'e'结尾的员工。
现在,您可以在Flask-SQLAlchemy应用程序中使用逻辑条件来过滤查询结果。接下来,您将对从数据库获取的结果进行排序、限制和计数。
步骤 4 —— 订购、限制和计数结果
在网络应用程序中,通常需要在显示记录时对其进行排序。例如,您可能有一个页面来显示每个部门最新的新员工,以让团队其他成员了解新员工,或者您可以按照最早入职的顺序来显示员工,以认可长期任职的员工。您还需要在某些情况下限制结果,例如,在小侧边栏上仅显示最新的三名新员工。您经常需要计算查询结果的数量,例如,显示当前活跃的员工数量。在此步骤中,您将学习如何订购、限制和计算结果。
订购结果
要使用特定列的值对结果进行排序,请使用 order_by() 方法。例如,要按员工的名字排序结果:
Output[<Employee Alex Brown>, <Employee Emily Vill>, <Employee Harold Ishida>, <Employee James White>, <Employee Jane Tanaka>, <Employee John Doe>, <Employee Mary Doe>, <Employee Mary Park>, <Employee Scarlett Winter>]
正如输出所示,结果按照员工的名字按字母顺序排序。
您还可以按其他列进行排序。例如,您可以使用姓来排序员工:
Output[<Employee Alex Brown>, <Employee John Doe>, <Employee Mary Doe>, <Employee Harold Ishida>, <Employee Mary Park>, <Employee Jane Tanaka>, <Employee Emily Vill>, <Employee James White>, <Employee Scarlett Winter>]
您还可以按入职日期对员工进行排序:
Output
Harold Ishida 2002-03-06
John Doe 2012-03-03
Jane Tanaka 2015-09-12
Mary Doe 2016-06-07
Alex Brown 2019-01-03
Emily Vill 2019-06-09
James White 2021-02-04
Scarlett Winter 2021-04-07
Mary Park 2021-08-11
如输出所示,此命令将结果从最早入职到最近入职进行排序。要反转顺序并使其从最新入职到最早入职降序排列,可以使用desc()方法,如下所示:
OutputMary Park 2021-08-11
Scarlett Winter 2021-04-07
James White 2021-02-04
Emily Vill 2019-06-09
Alex Brown 2019-01-03
Mary Doe 2016-06-07
Jane Tanaka 2015-09-12
John Doe 2012-03-03
Harold Ishida 2002-03-06
您还可以将order_by()方法与filter()方法组合以对排序后的结果进行排序。以下示例获取了所有于2021年入职的员工,并按年龄排序:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
Mary Park 2021-08-11 | Age 30
在此,您使用db.and_()函数与两个条件:Employee.hire_date >= date(year=2021, month=1, day=1)用于在2021年1月1日或之后入职的员工,以及Employee.hire_date < date(year=2022, month=1, day=1)用于在2022年1月1日之前入职的员工。然后,您使用order_by()方法按其年龄对结果员工进行排序。
限制结果
在大多数实际情况下,在查询数据库表时,可能会获得数百万个匹配结果,有时需要将结果限制为某个数量。要在Flask-SQLAlchemy中限制结果,您可以使用limit()方法。以下示例查询employee表,并仅返回前三个匹配结果:
Output[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>]
您可以将limit()与其他方法一起使用,例如filter和order_by。例如,您可以使用limit()方法获取2021年入职的最后两名员工,如下所示:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
在前面部分使用相同的查询,并额外添加了limit(2)方法调用。
计算结果
要计算查询结果的数量,您可以使用count()方法。例如,要获取当前数据库中的员工数量:
Output9
您可以将count()方法与其他类似于limit()的查询方法结合使用。例如,要获取2021年入职的员工数量:
Output3
在这里,您使用了之前用于获取所有2021年入职员工的相同查询,并使用count()来检索条目的数量,结果为3。
您已经在Flask-SQLAlchemy中对查询结果进行了排序、限制和计数。接下来,您将学习如何将查询结果拆分为多个页面,并在您的Flask应用程序中创建分页系统。
第5步 —— 在多个页面上显示长记录列表
在此步骤中,您将修改主路由以使索引页面在多个页面上显示员工,以便更轻松地浏览员工列表。
首先,您将使用Flask shell来演示如何在Flask-SQLAlchemy中使用分页功能。如果还没有打开Flask shell,请打开:
假设您想将表中的员工记录拆分成多个页面,每页两个项目。您可以使用paginate()查询方法来实现:
Output<flask_sqlalchemy.Pagination object at 0x7f1dbee7af80>
[<Employee John Doe>, <Employee Mary Doe>]
您可以使用paginate()查询方法的page参数来指定要访问的页面,这在本例中是第一页。per_page参数指定每页必须有的项目数量。在本例中,您将其设置为2,以使每页有两个项目。
这里的page1变量是一个分页对象,它使您可以访问您将用于管理分页的属性和方法。
您可以使用items属性访问页面的项目。
要访问下一页,您可以使用分页对象的next()方法,如下所示,返回的结果也是一个分页对象:
Output[<Employee Jane Tanaka>, <Employee Alex Brown>]
<flask_sqlalchemy.Pagination object at 0x7f1dbee799c0>
您可以使用prev()方法获取上一页的分页对象。在下面的示例中,您访问第四页的分页对象,然后访问其上一页的分页对象,即第3页:
Output[<Employee Scarlett Winter>, <Employee Emily Vill>]
[<Employee James White>, <Employee Harold Ishida>]
您可以使用page属性访问当前页码,如下所示:
Output1
2
要获取总页数,请使用分页对象的pages属性。在以下示例中,page1.pages和page2.pages都返回相同的值,因为总页数是一个常数:
Output5
5
要获取总项目数,请使用分页对象的total属性:
Output9
9
在这里,由于您查询所有员工,分页中的总项目数为9,因为数据库中有九名员工。
以下是分页对象具有的一些其他属性:
prev_num:上一页的页码。next_num:下一页的页码。has_next:如果存在下一页,则为True。has_prev:如果存在上一页,则为True。per_page:每页的项目数。
分页对象还有一个iter_pages()方法,您可以通过循环访问页面号码。例如,您可以这样打印所有页面号码:
Output1
2
3
4
5
以下是使用分页对象和iter_pages()方法访问所有页面及其项目的演示:
Output
PAGE 1
-
[<Employee John Doe>, <Employee Mary Doe>]
--------------------
PAGE 2
-
[<Employee Jane Tanaka>, <Employee Alex Brown>]
--------------------
PAGE 3
-
[<Employee James White>, <Employee Harold Ishida>]
--------------------
PAGE 4
-
[<Employee Scarlett Winter>, <Employee Emily Vill>]
--------------------
PAGE 5
-
[<Employee Mary Park>]
--------------------
在这里,您创建了一个从第一页开始的分页对象。您使用iter_pages()分页方法的for循环遍历页面。您打印页面号码和页面项目,并使用next()方法将pagination对象设置为其下一页的分页对象。
您还可以使用filter()和order_by()方法与paginate()方法一起对过滤和排序后的查询结果进行分页。例如,您可以获取年龄超过三十岁的员工,并按年龄排序结果,然后分页显示结果如下:
OutputPAGE 1
-
<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
--------------------
PAGE 2
-
<Employee Mary Doe> | Age: 38
<Employee Harold Ishida> | Age: 52
--------------------
现在您已经对Flask-SQLAlchemy中分页的工作原理有了扎实的了解,您将编辑应用程序的主页,以便在多个页面上显示员工,以便更轻松地导航。
退出Flask shell:
要访问不同的页面,您将使用URL参数,也称为URL查询字符串,这是通过URL将信息传递给应用程序的一种方式。参数通过URL中的?符号之后的URL传递给应用程序。例如,要使用不同的值传递page参数,您可以使用以下URL:
http://127.0.0.1:5000/?page=1
http://127.0.0.1:5000/?page=3
在这里,第一个URL将值1传递给URL参数page。第二个URL传递了相同参数的值3。
打开app.py文件:
编辑index路由如下:
在这里,您可以使用request.args对象及其get()方法获取page URL参数的值。例如/?page=1将从page URL参数获取值1。您将1作为默认值传递,并将int Python类型作为type参数的参数传递,以确保该值是一个整数。
接下来,创建一个pagination对象,按照名字的顺序对查询结果进行排序。将page URL参数值传递给paginate()方法,并通过将值2传递给per_page参数来将结果分割为每页两个项目。
最后,将构建的pagination对象传递给呈现的index.html模板。
保存并关闭文件。
接下来,编辑index.html模板以显示分页项目:
通过添加一个h2标题来更改内容div标记,指示当前页面,并将for循环更改为循环遍历pagination.items对象,而不是不再可用的employees对象:
保存并关闭文件。
如果还没有设置FLASK_APP和FLASK_ENV环境变量,请设置并运行开发服务器:
现在,使用不同的page URL参数值导航到索引页面:
http://127.0.0.1:5000/
http://127.0.0.1:5000/?page=2
http://127.0.0.1:5000/?page=4
http://127.0.0.1:5000/?page=19
您将看到每页两个项目的不同页面,并且每个页面上的项目都不同,就像您在Flask shell中之前看到的那样。
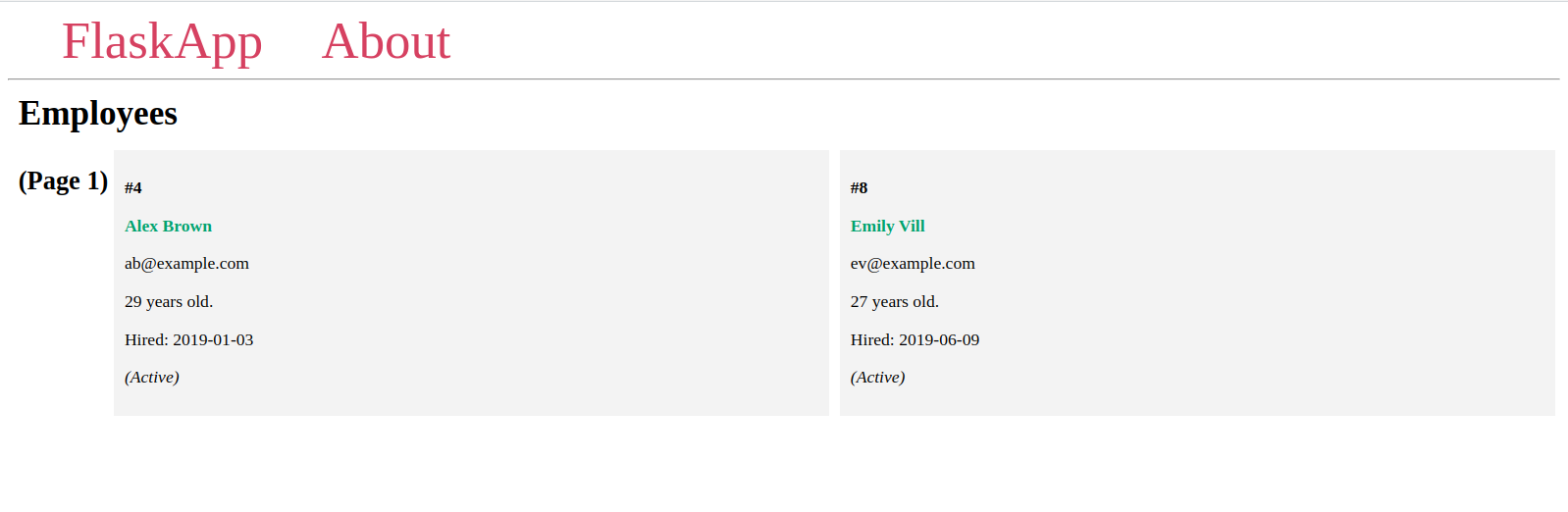
如果给定的页码不存在,则会收到404 Not Found的HTTP错误,这在前述URL列表中的最后一个URL中是这样的。
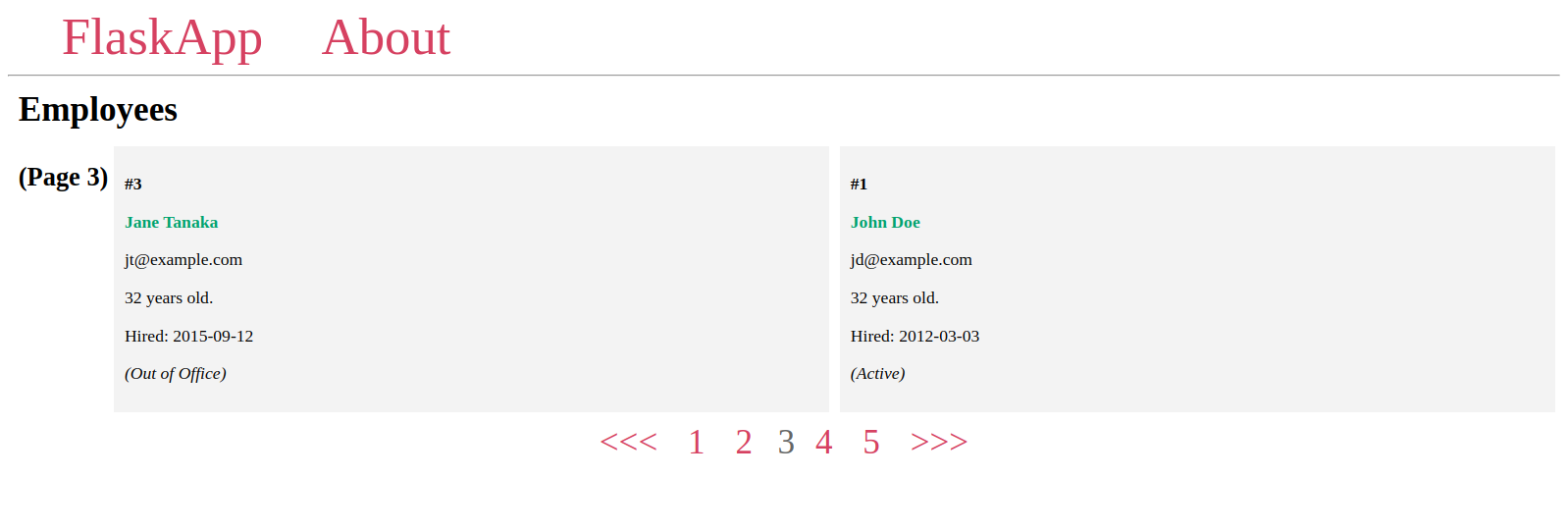
接下来,您将创建一个分页小部件来在页面之间进行导航,您将使用分页对象的一些属性和方法来显示所有页面数字,每个数字链接到其专用页面,并且如果当前页面有前一页,则会有一个<<<按钮用于返回,如果存在下一页,则会有一个>>>按钮用于转到下一页。
分页小部件将如下所示:

要添加它,请打开index.html:
通过在内容div标记下方添加以下突出显示的div标记来编辑文件:
保存并关闭文件。
在这里,您使用条件if pagination.has_prev来添加<<<链接到前一页,如果当前页面不是第一页的话。您使用url_for('index', page=pagination.prev_num)函数调用来链接到前一页,其中您链接到索引视图函数,并将pagination.prev_num值传递给page URL参数。
要显示到所有可用页面数字的链接,您需要循环遍历pagination.iter_pages()方法的项目,该方法在每个循环中为您提供一个页面编号。
你使用if pagination.page != number条件来判断当前页面编号是否与循环中的编号不同。如果条件成立,你将链接到该页面,允许用户将当前页面更改为另一页。否则,如果当前页面与循环编号相同,则显示该数字而不带链接。这使用户可以在分页小部件中了解当前页面编号。
最后,你使用pagination.has_next条件来查看当前页面是否有下一页,如果是这样,则使用url_for('index', page=pagination.next_num)调用和>>>链接进行链接。
在浏览器中导航到主页:http://127.0.0.1:5000/
你会看到分页小部件是完全可用的:
在这里,你使用>>>来跳转到下一页,<<<来跳转到上一页,但你也可以使用任何其他你喜欢的字符,比如>和<,或者在<img>标签中使用图片。
你已经在多个页面上显示了员工,并学习了如何处理Flask-SQLAlchemy中的分页。现在,你可以在构建的其他Flask应用程序中使用你的分页小部件。
结论
您使用 Flask-SQLAlchemy 创建了一个员工管理系统。您查询了一个表,并根据列值以及简单和复杂的逻辑条件对结果进行了过滤。您对查询结果进行了排序、计数和限制。并且您创建了一个分页系统,在您的 Web 应用程序中显示每页一定数量的记录,并在页面之间导航。
您可以将本教程中学到的知识与我们其他一些 Flask-SQLAlchemy 教程中解释的概念结合起来,为您的员工管理系统添加更多功能:
- 如何使用 Flask-SQLAlchemy 与 Flask 应用程序交互以操作数据库,以了解如何添加、编辑或删除员工。
- 如何使用 Flask-SQLAlchemy 创建一对多的数据库关系,以了解如何使用一对多关系创建一个部门表,将每个员工与其所属部门关联起来。
- 如何在Flask-SQLAlchemy中使用多对多数据库关系以学习如何使用多对多关系创建
tasks表,并将其与employee表关联,其中每个员工都有多个任务,每个任务分配给多个员工。
如果您想了解更多关于Flask的信息,请查看使用Flask构建Web应用程序系列中的其他教程。