













在第1部分,我们涵盖了一些关键主题。我建议你阅读它,因为下一部分在此基础上构建。
快速回顾一下,在第1部分,我们从宏观角度考虑了我们的数据,并区分了内部数据和外部数据。我们还讨论了模式和数据合同,以及它们如何提供协商、更改和随时间演变我们流的方法。最后,我们涵盖了事实(状态)和增量事件类型。事实事件最适合传达状态和解耦系统,而增量事件则更多地用于内部数据,例如在事件溯源和其他紧密耦合的用例中。
规范化表格造就规范化流
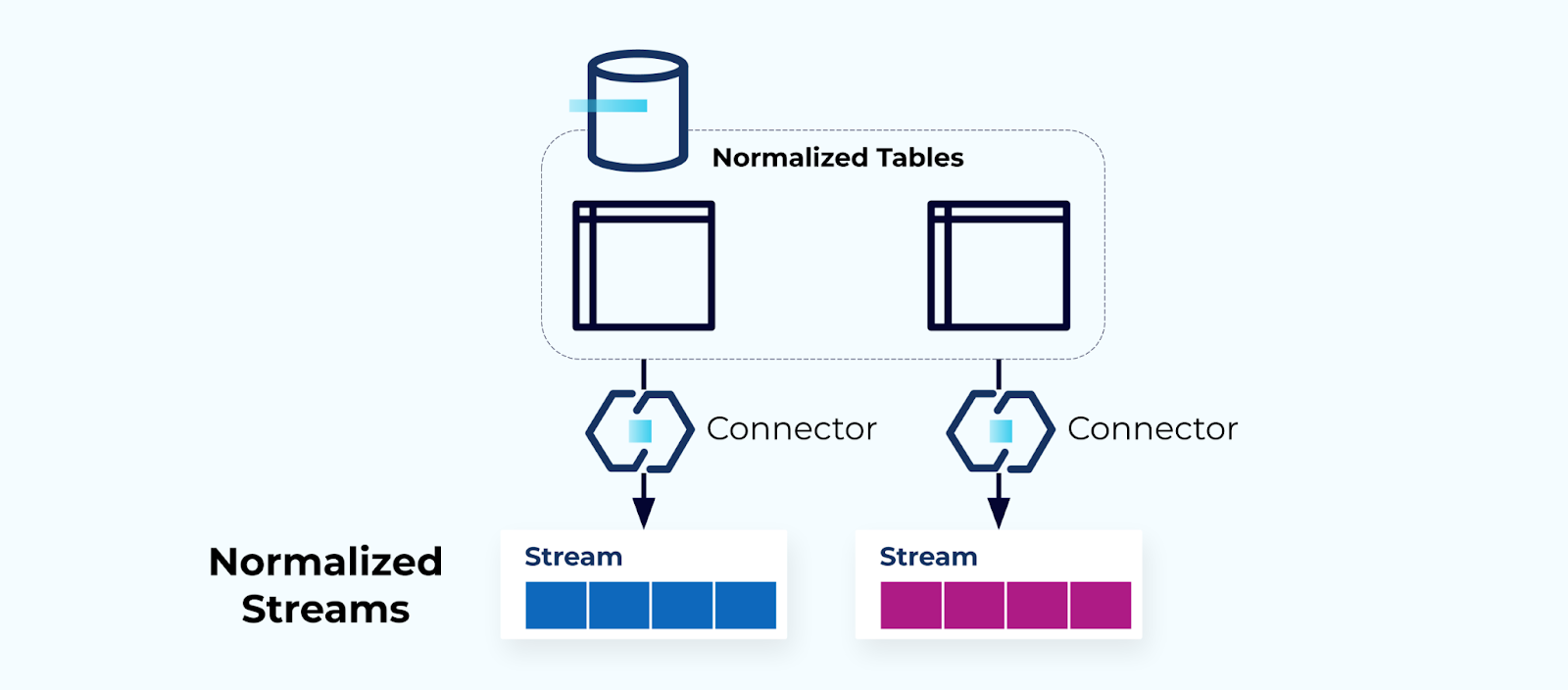
规范化表格导致规范化事件流。连接器(例如,CDC)直接从数据库中拉取数据到一组镜像的事件流中。这不是理想的做法,因为它在内部数据库表和外部事件流之间创建了强耦合。
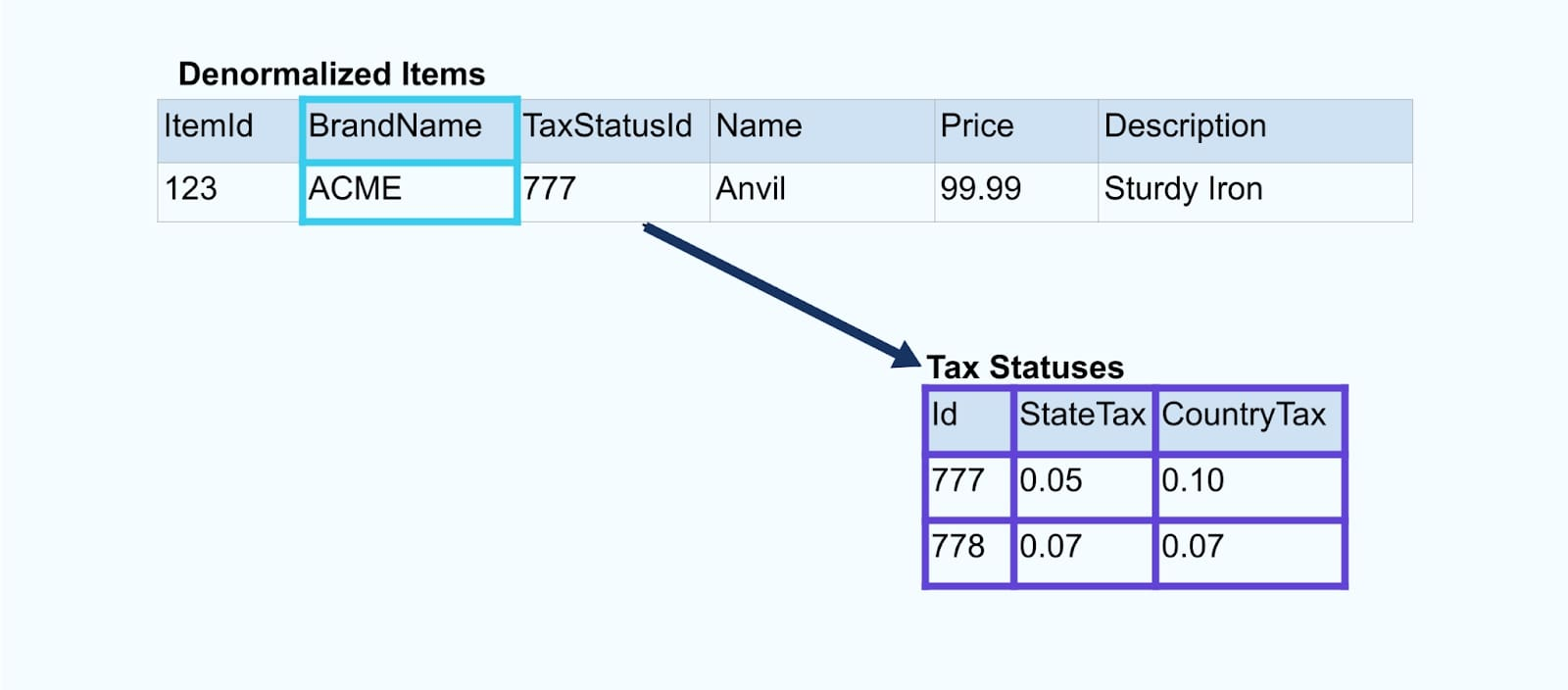
考虑一个简单的电子商务商品及其相关的品牌和税务状态表格。
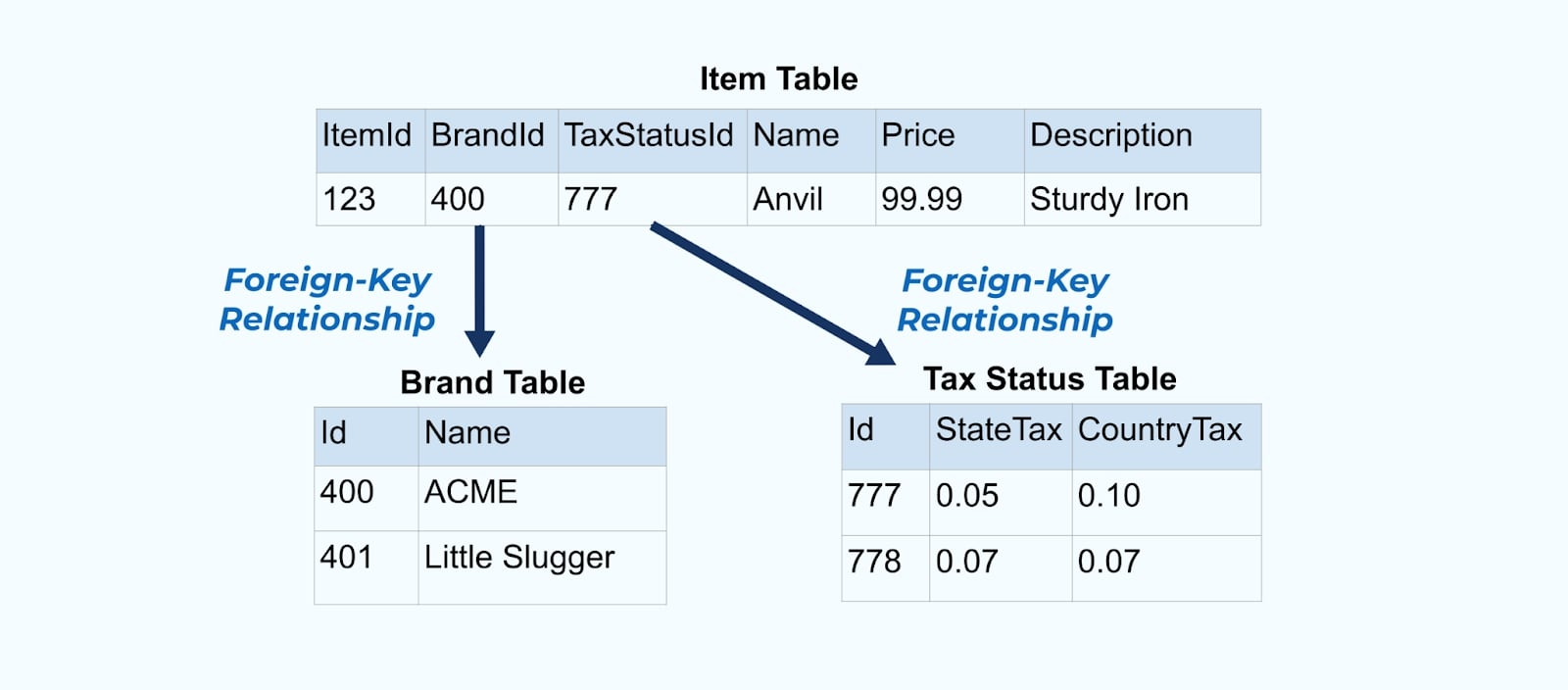
品牌和税务状态表格通过外键关系与商品表格关联。虽然我们在表格中只展示了一个商品,但根据你销售的产品,你可能会有成千上万(或数百万)个商品。
为每个表设置连接器,从表中提取数据,将其组合成事件,并将每个表写入专用的事件流是很常见的。
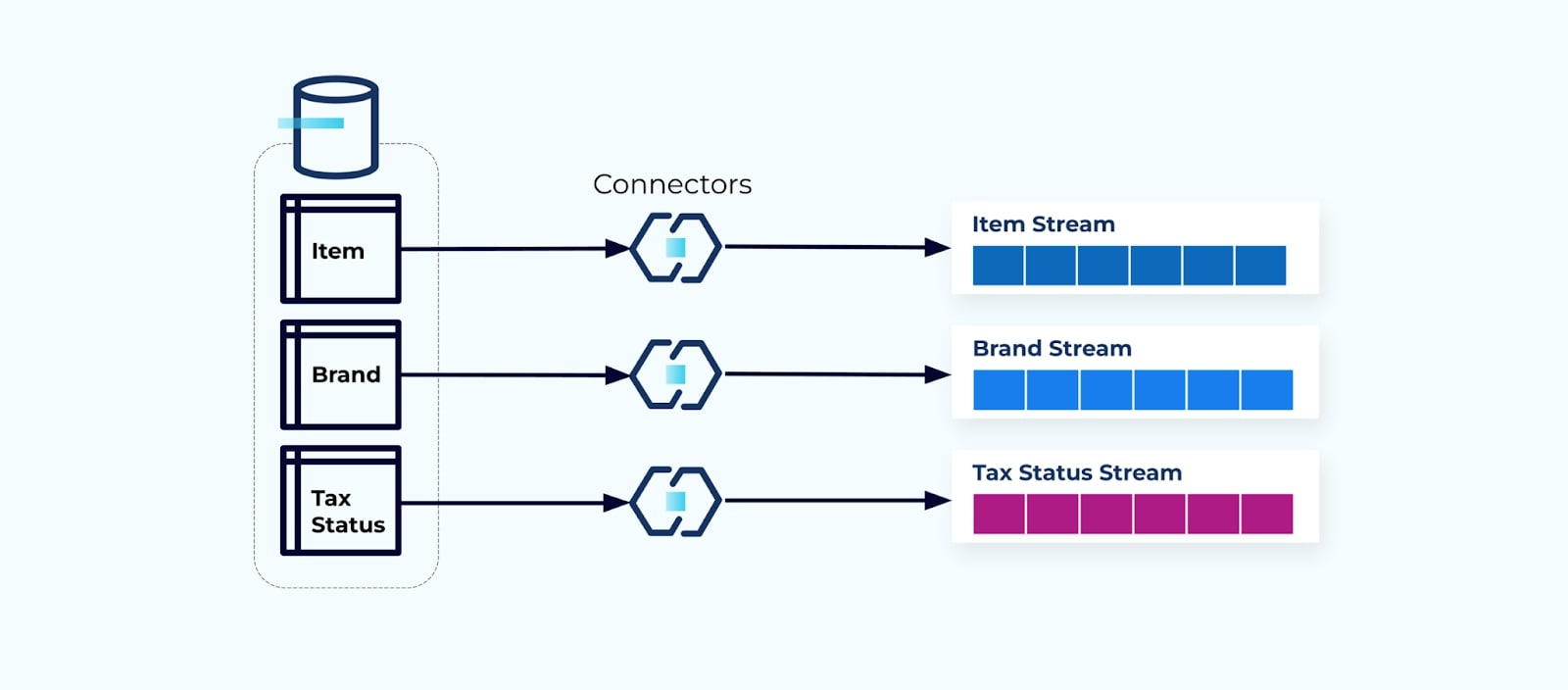
暴露数据库中的底层表会导致每个表对应一个事件流。虽然这种方式易于上手,但会导致多个问题,这些问题可以归纳为要么是耦合问题,要么是成本问题。让我们逐一看看。
问题:消费者与内部模型耦合
直接暴露源Item表会迫使消费者直接与其耦合。源系统数据模型的变更将影响下游消费者。
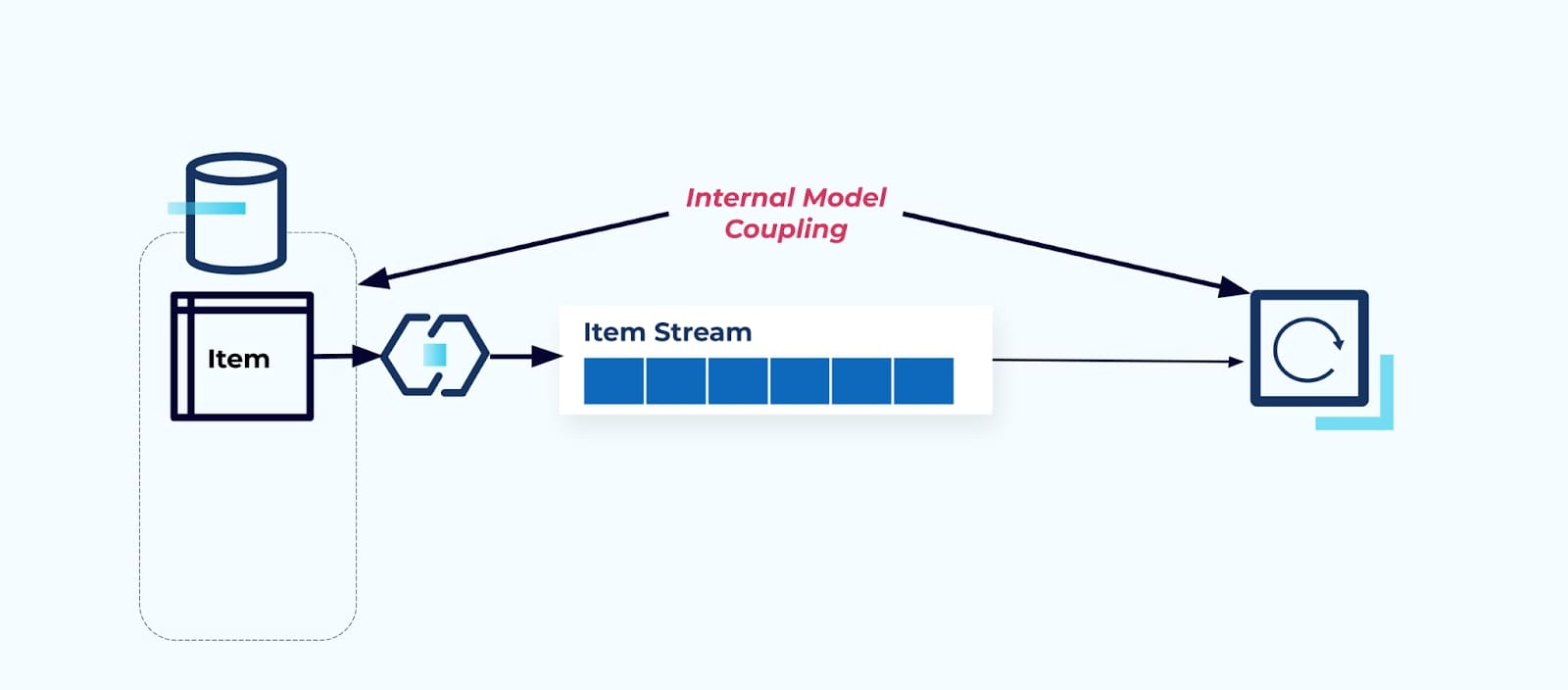
假设我们将Item表重构,以提取Pricing到其自己的表中。
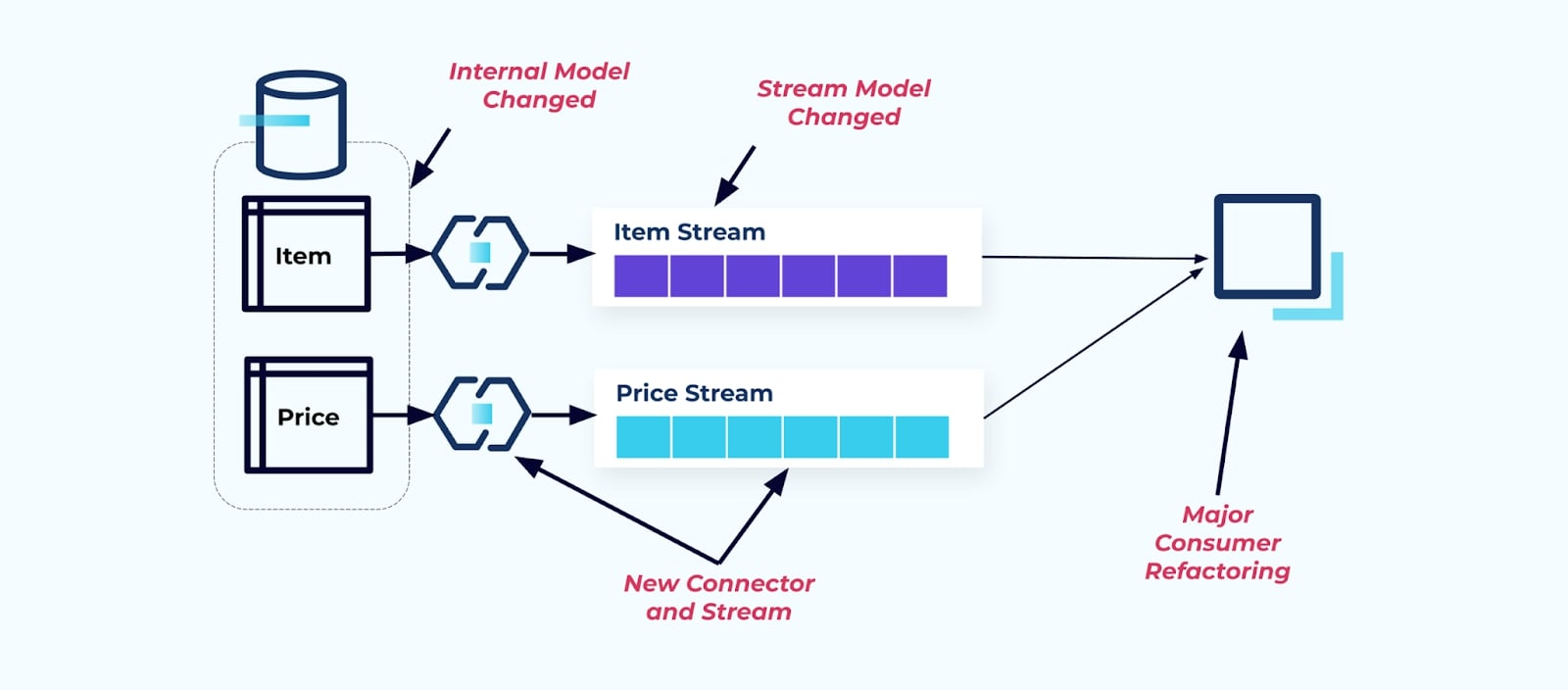
重构源表会导致数据契约破裂,对于项目流而言。消费者不再获得他们原本期望的相同项目数据。我们还必须创建一个新的连接器——一个新的P价格流,并最终重构我们的消费者逻辑以使其重新运行。重命名列、更改默认值以及更改列类型是由内部数据模型紧密耦合引入的其他形式的破坏性更改。
问题:流式连接通常成本高昂
关系型数据库专为快速且低成本地解决连接而构建。不幸的是,流式连接并非如此。
考虑两个希望访问项目、其税务和其品牌信息的服务。如果数据已经写入其对应的流,那么每个消费者(在下图右侧)将不得不计算相同的连接以非规范化I项目、B品牌和T税务。
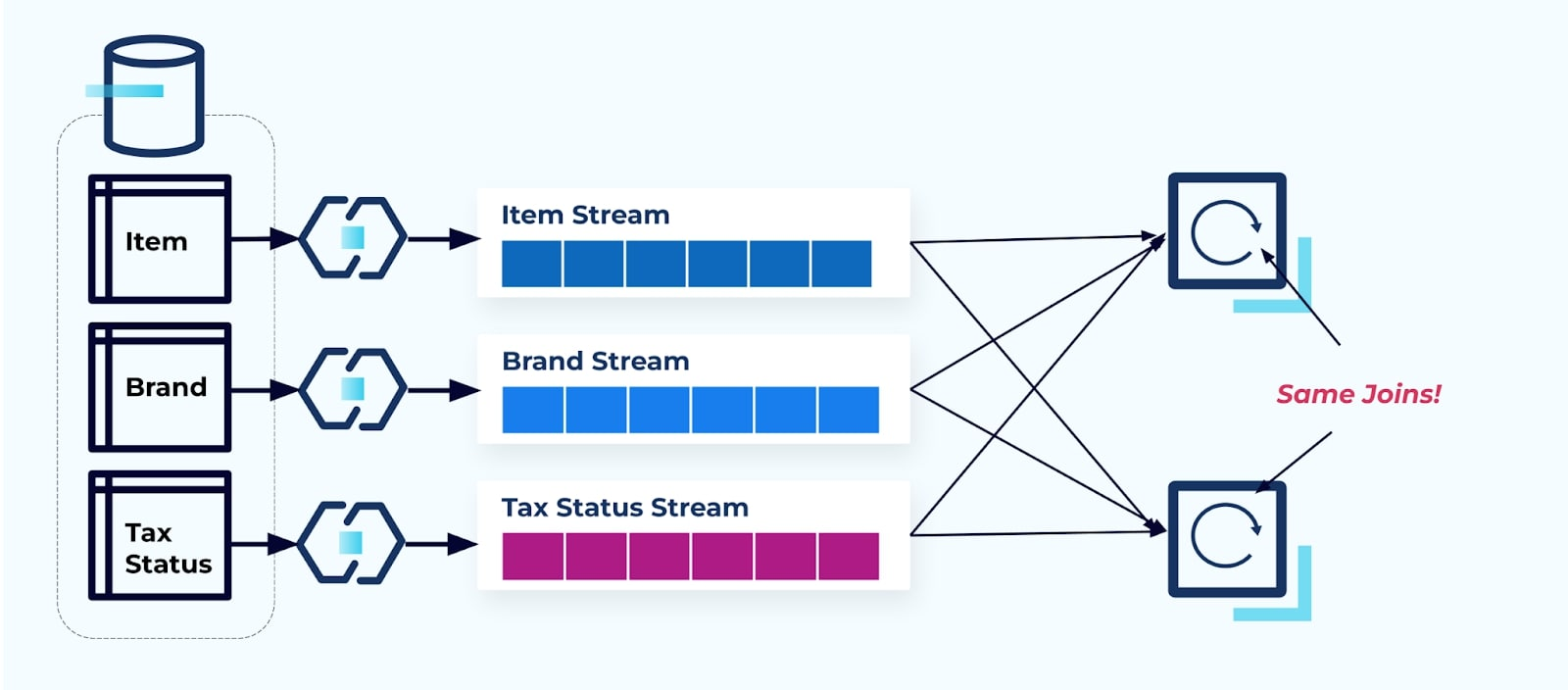
这种策略可能会产生高昂的成本,既包括编写应用程序的开发时间成本,也包括计算连接的服务器成本。大规模解决流连接可能会导致大量数据移动,这会带来处理能力、网络和存储成本。此外,并非所有的流处理框架都支持连接,特别是在外键上。在那些支持的框架中,例如Flink、Spark、KSQL或Kafka Streams(例如),你会发现自己仅限于使用子集编程语言(Java、Scala、Python)。
解决方案:提供非规范化数据最佳
作为一个原则,让事件流对消费者使用变得简单。在将数据提供给消费者之前,使用抽象层对数据进行非规范化,并为消费者创建一个明确的外部模型数据契约(外部数据)以进行耦合。
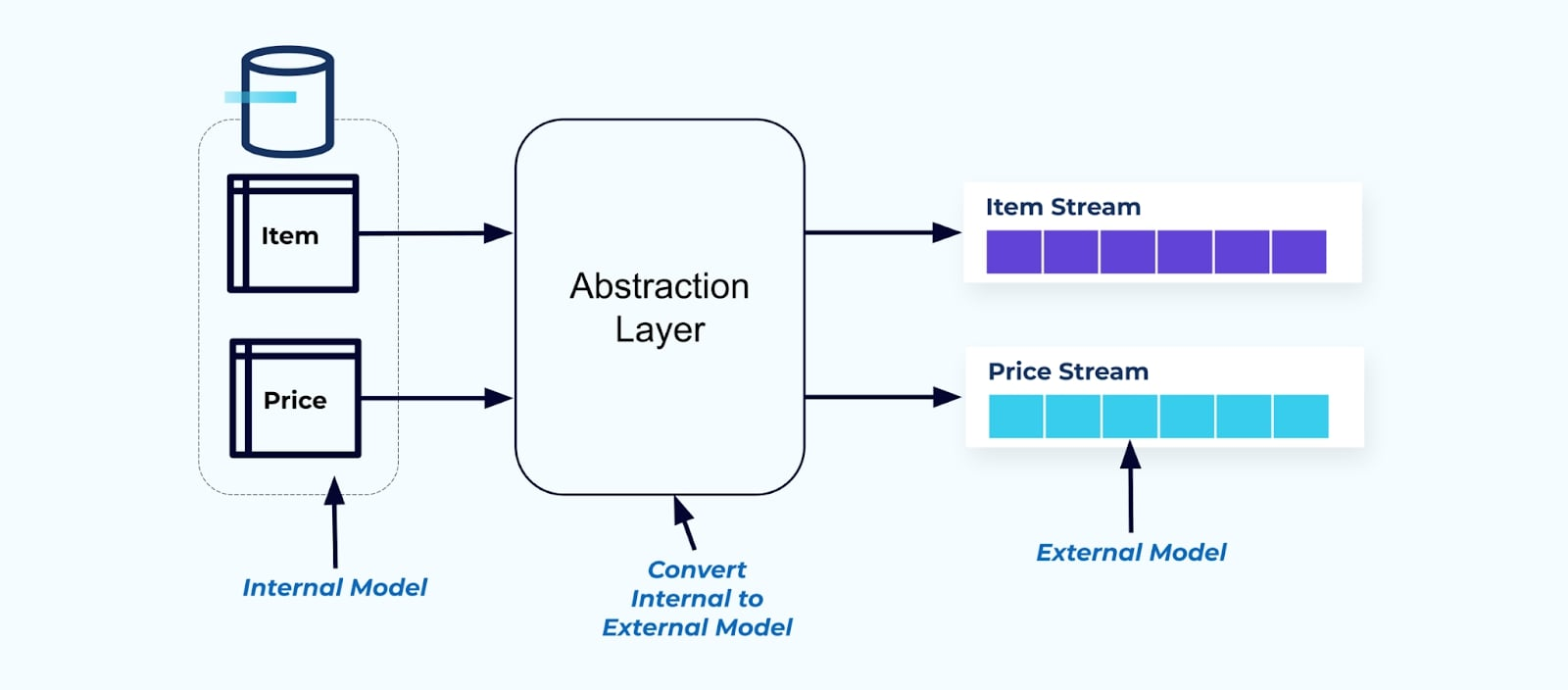
内部模型的更改仍然隔离在源系统中。消费者获得一个明确定义的数据契约以进行耦合。只要源系统维护消费者的数据契约,对源模型进行的更改可以不受阻碍地进行。
但我们应在何处进行非规范化?有两个选项:
- 通过专用的连接器服务在源系统外部重建。
- 在源系统中创建事件时使用事务性发件箱模式。
让我们依次看看每个解决方案。
选项1:使用专用连接器服务进行非规范化
在这个例子中,左侧的流反映了它们来自数据库中的表。
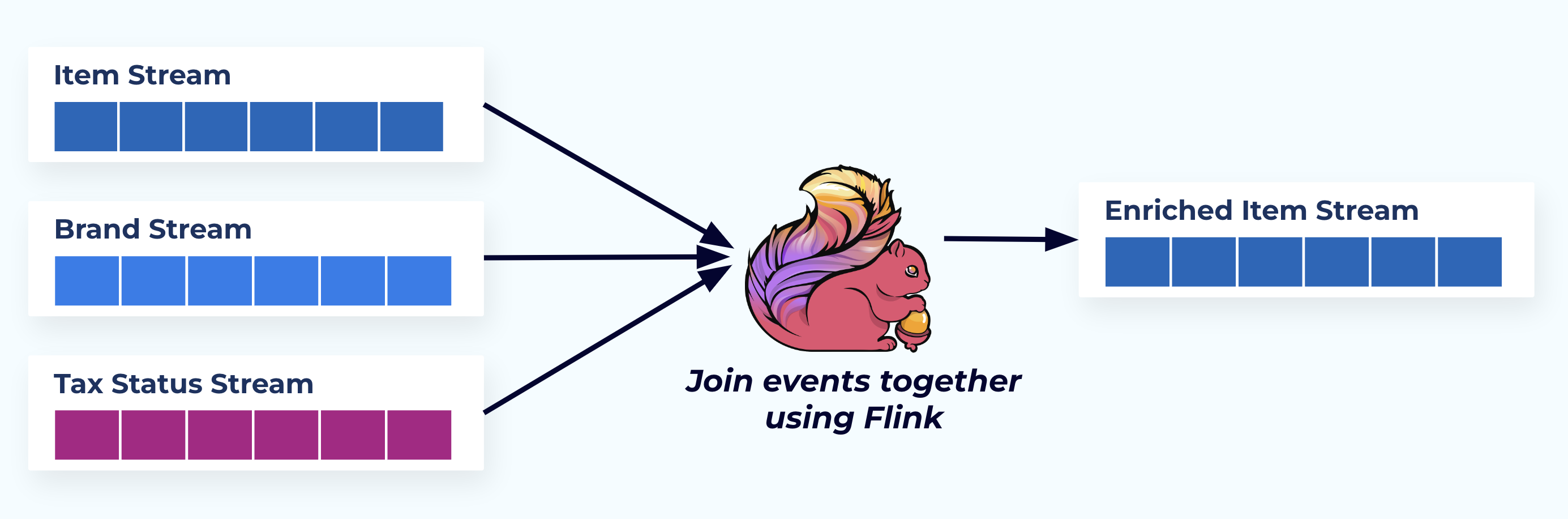
我们使用一个专门构建的应用程序(或流式SQL查询)基于外键关系来连接事件,并发出单个丰富的事项流。

从逻辑上讲,我们正在解析这些关系并将数据压缩成单个非规范化的行。
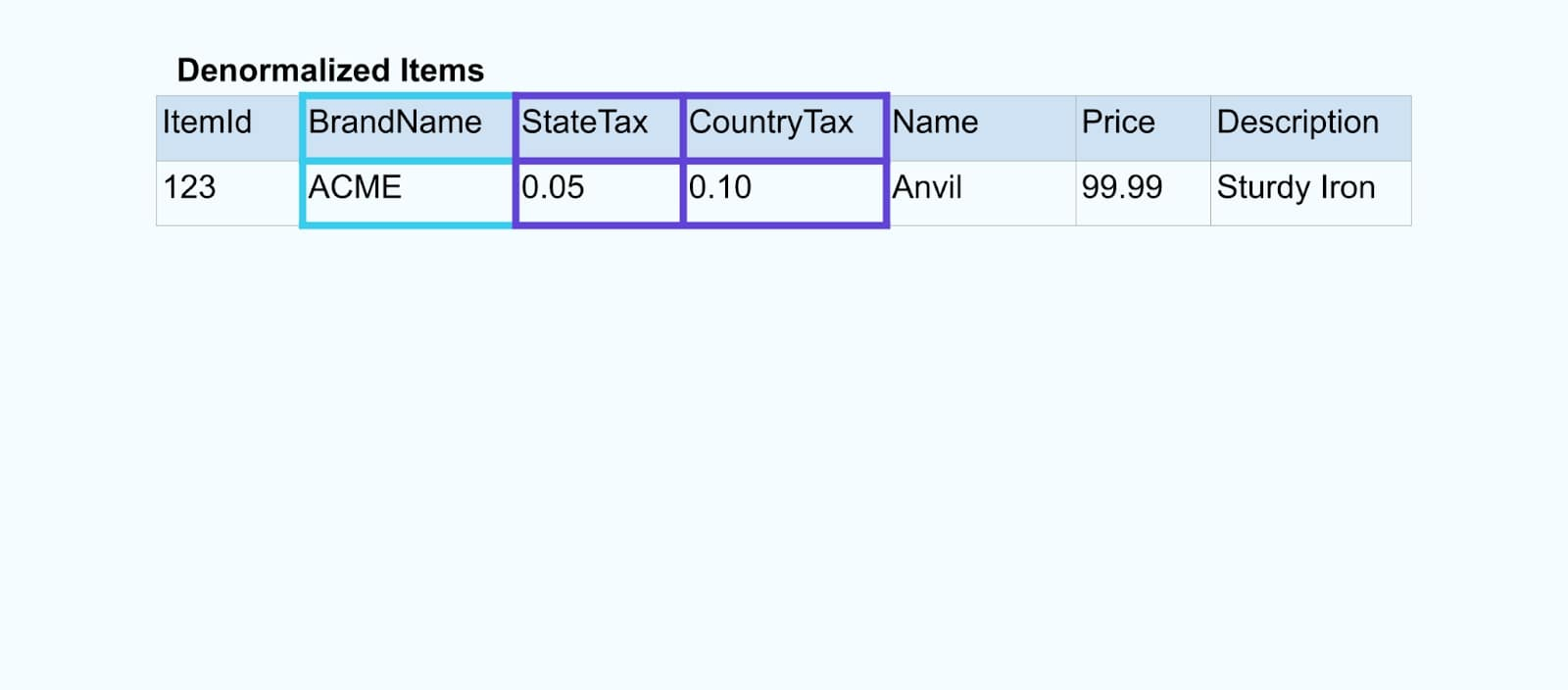
专门构建的连接器依赖于像Apache Kafka Streams和Apache Flink这样的流处理框架来解决主键和外键的连接。它们将流数据物化成持久的内部表格式,使连接器应用程序能够连接任何时间段的事件——不仅限于受时间限制窗口约束的事件。
使用Flink或Kafka Streams的连接器也具有显著的扩展性——它们可以根据负载进行扩展和缩减,并处理大量的流量。
一个小提示:不要将任何业务逻辑放入连接器中。为了在这种模式中取得成功,连接的数据必须准确代表源数据,仅作为一个非规范化的结果。让下游的消费者使用非规范化数据作为单一的真实来源,应用他们自己的业务逻辑。
如果你不想使用下游连接器,还有其他选择。接下来让我们看看事务性发件箱模式。
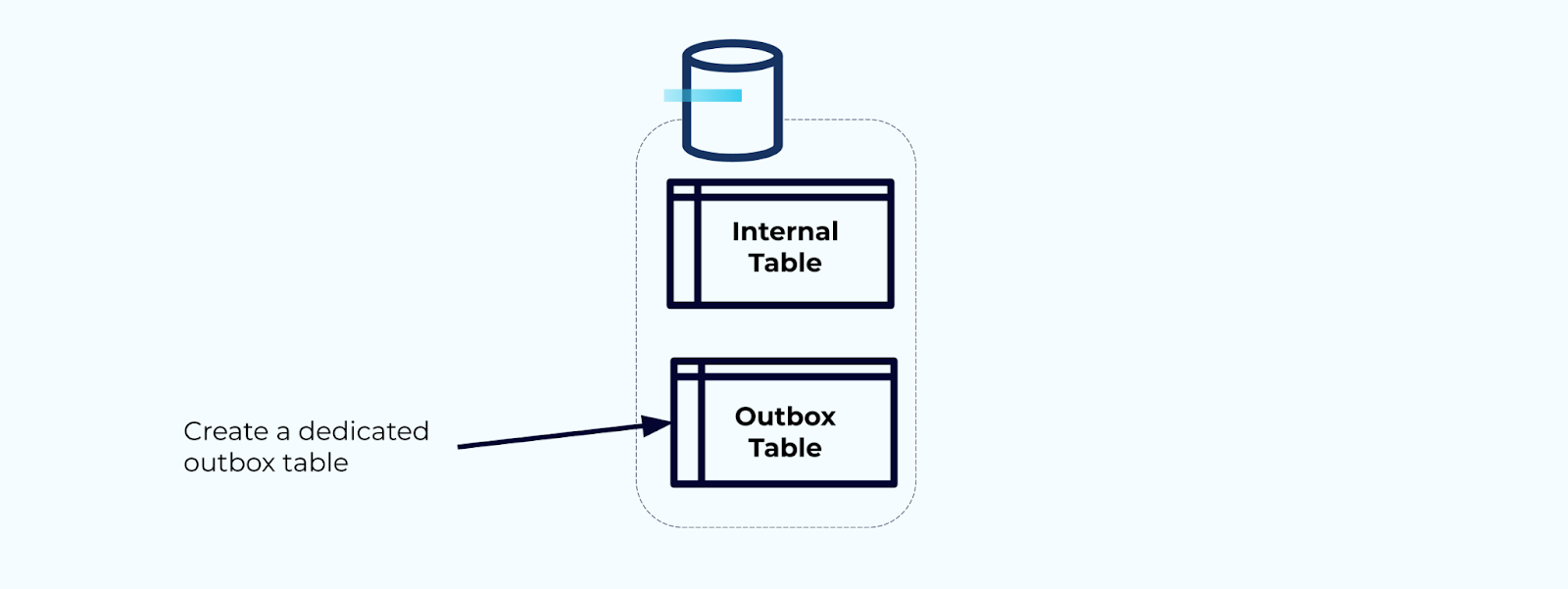
选项2:事务性发件箱模式
首先,创建一个专用的发件箱表用于将事件写入流中。
其次,将所有必要的内部表更新包装在事务中。事务保证对内部表所做的任何更新也将写入发件箱表。
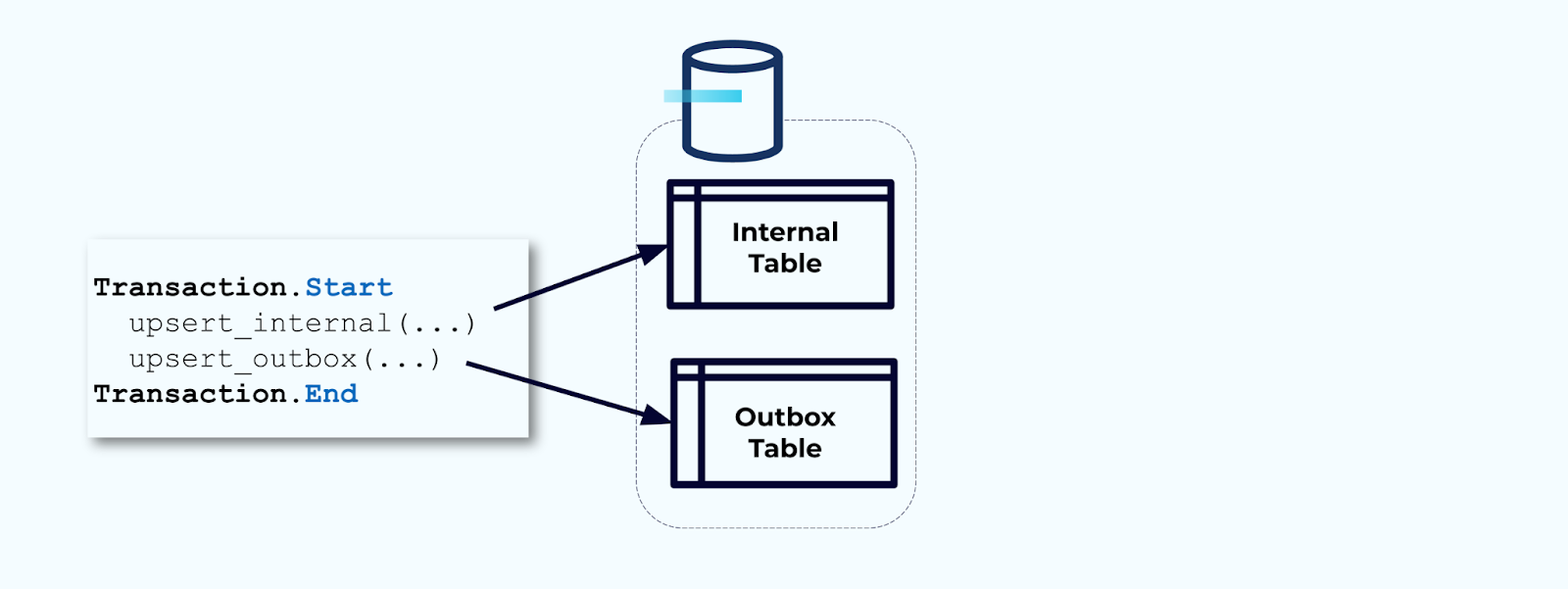
发件箱允许您隔离内部数据模型,因为您可以在将数据写入发件箱之前进行联接和转换。发件箱充当内部数据和外部数据之间的抽象层,作为消费者的数据合同。
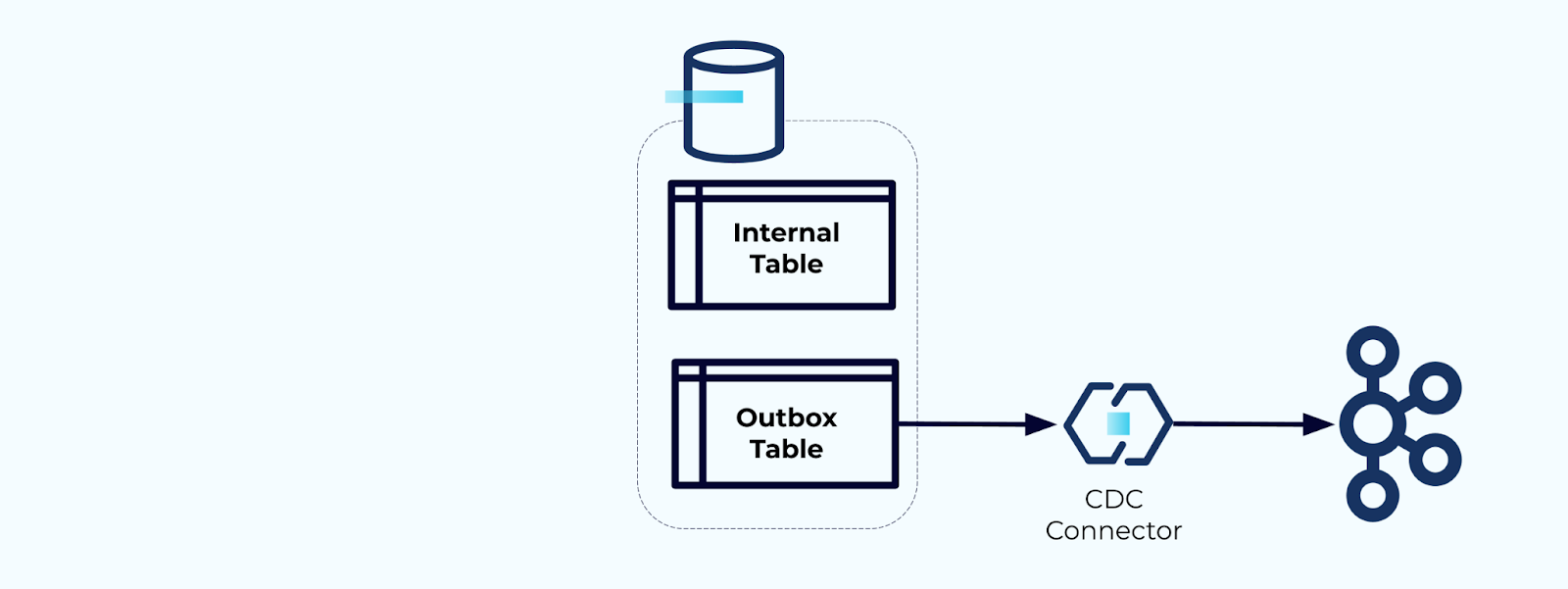
最后,您可以使用连接器将数据从发件箱提取到Kafka中。
您必须确保发件箱不会无限增长——要么在CDC捕获数据后删除数据,要么通过定期计划任务进行删除。
示例:用户行为跟踪事件去规范化
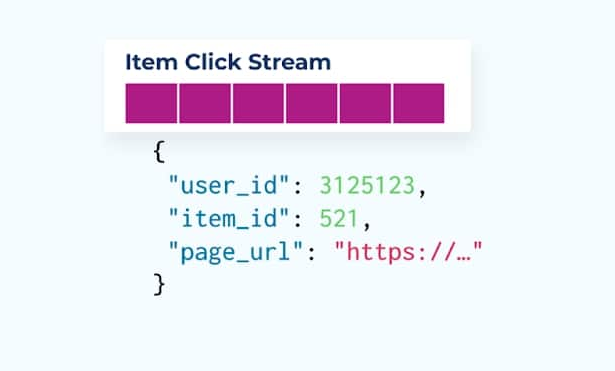
跟踪网页和应用上的用户行为是规范化事件的常见来源——想想谷歌分析或第一方内部选项。但我们并不在事件中包含所有信息;相反,我们将其限制为标识符(更快、更小、更便宜),在事实创建后进行去规范化。
考虑一个详细记录用户在浏览电子商务商品时点击商品的物品点击事件流。请注意,此物品点击事件不包含更丰富的物品信息,如名称、价格和描述,仅包含基本的ids。
许多点击流消费者首先做的是将其与项目事实流进行连接。由于你处理的是大量的点击事件,你会发现这最终会使用大量的计算资源。一个专门构建的Flink应用程序可以将项目点击与详细的项目数据连接起来,并将它们发送到丰富的项目点击流中。
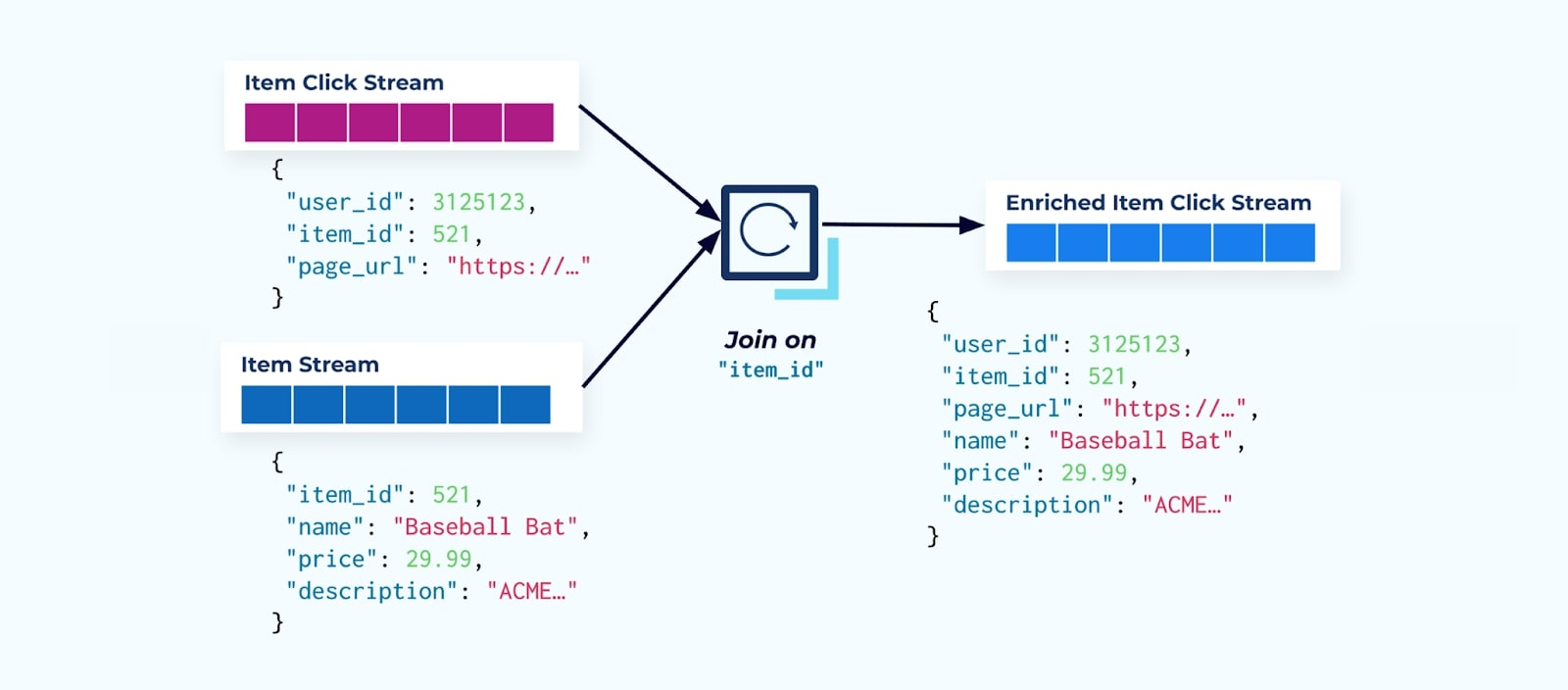
拥有多个部门(和系统)的大型公司可能会看到他们的数据来自不同的来源,使用流连接器事后进行连接是最可能的结果。
关于缓慢变化维度的考虑
我们已经讨论了写入包含大数据集(例如,大文本块)的事件的性能考虑以及频繁变化的数据域(例如,项目库存)。现在,我们将看看缓慢变化维度(SCDs),这些通常通过外键关系表示,因为它们可能是大量数据的另一个来源。
让我们再回到我们的项目示例。假设你有一个操作更新了项目表。我们将把项目从“铁砧”重命名为“铁铁砧”。
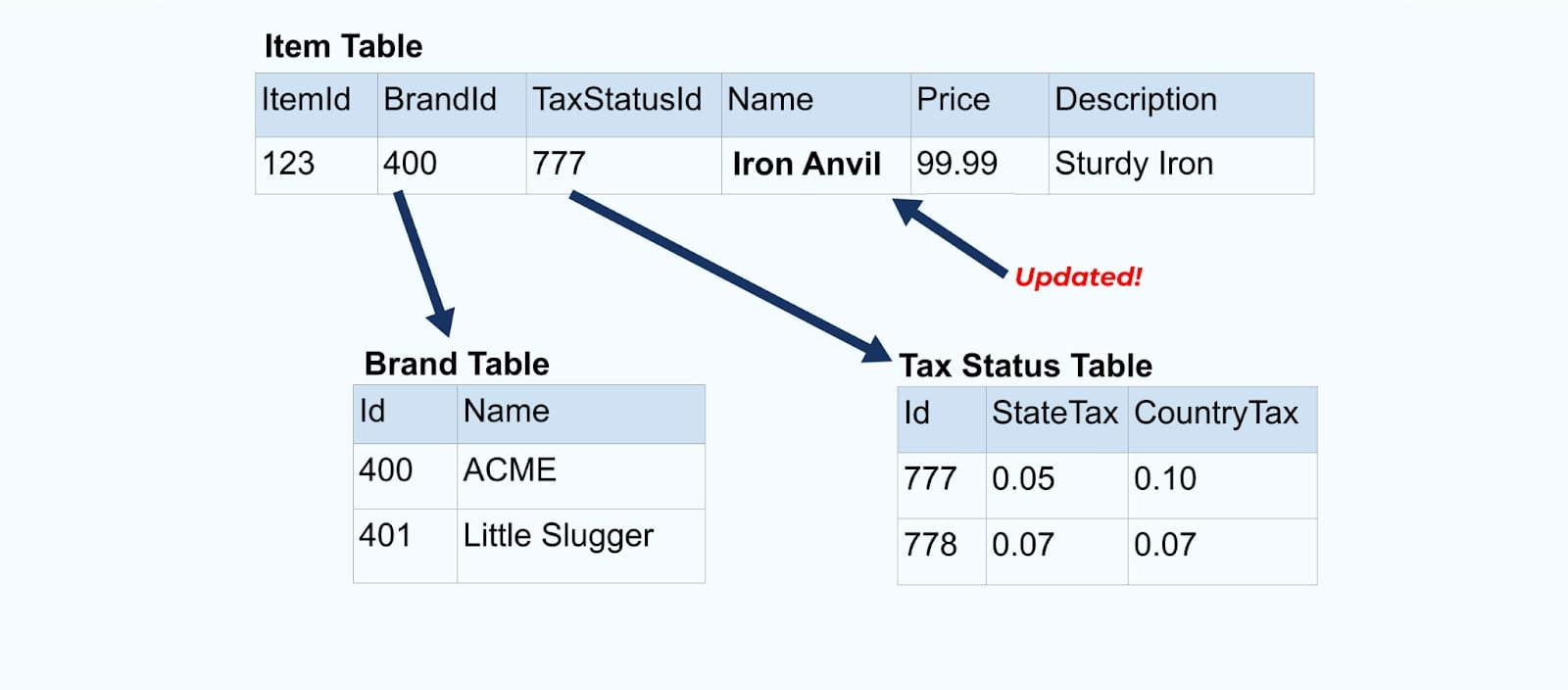
在更新数据库中的数据时,我们还会发出更新的项目(比如说通过出站模式),并附带上非规范化的税务状态和品牌表。
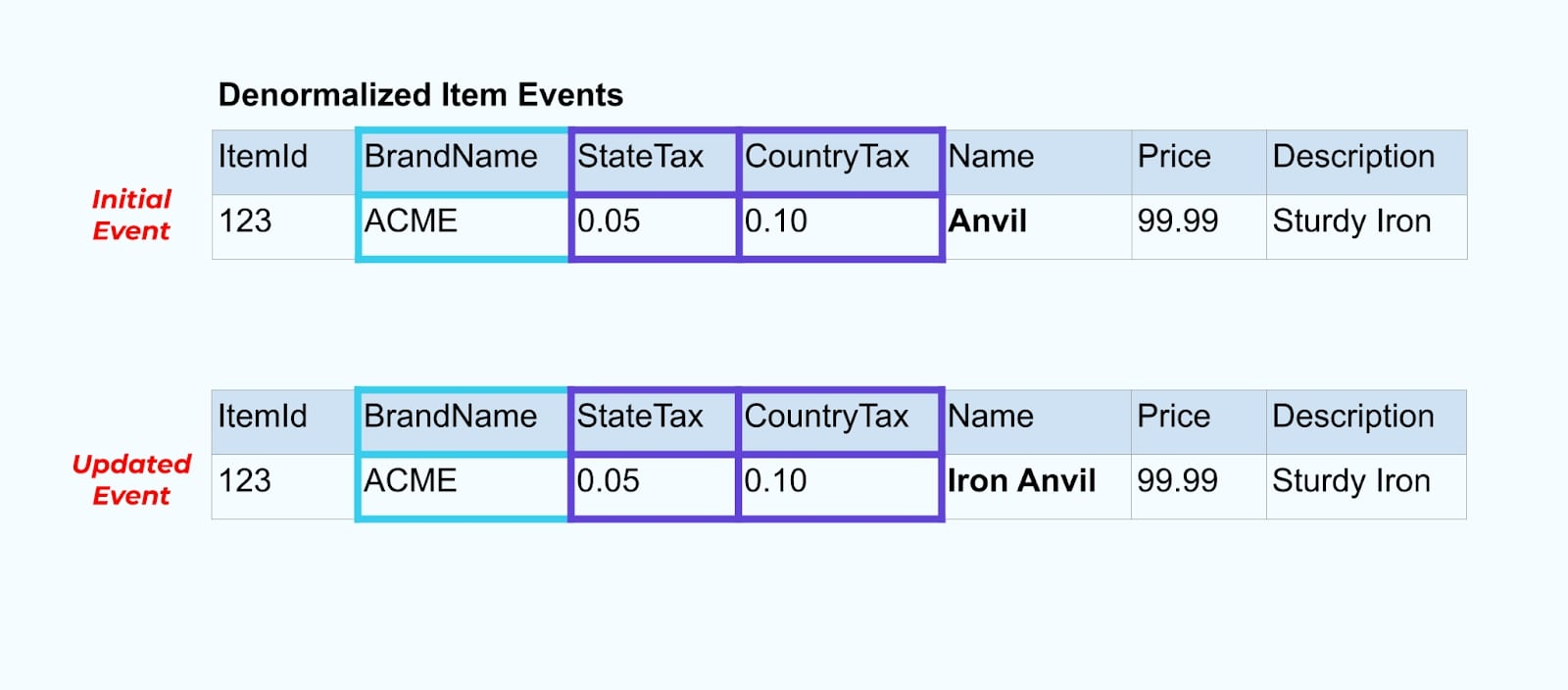
然而,我们还需要考虑当我们更改品牌或税务表中的值时会发生什么。更新这些缓慢变化维度中的一个可能会导致对所有受影响项目的显著大量更新。
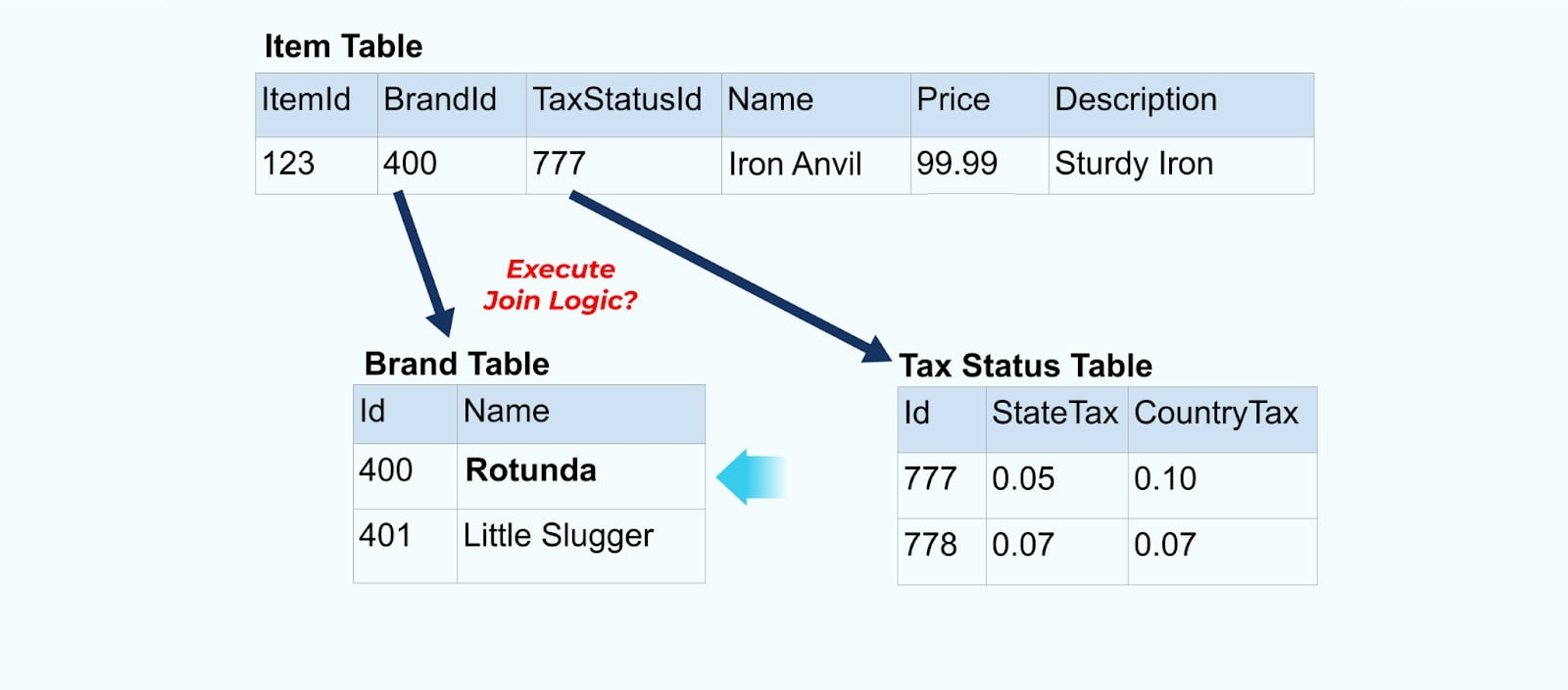
例如,ACME公司进行品牌重塑,推出了新的品牌名称,从ACME更改为Rotunda。我们为ItemId=123生成另一个事件。
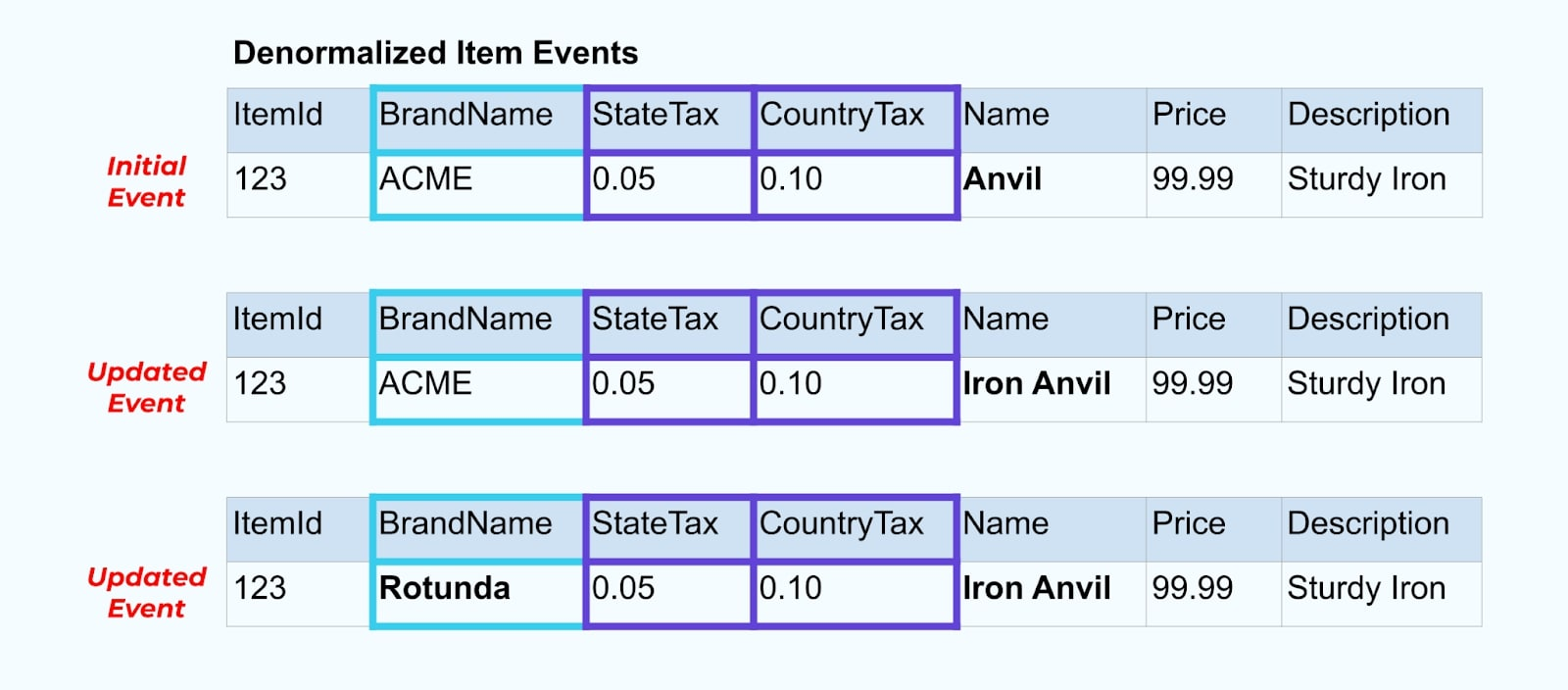
然而,Rotunda(前身为ACME)可能还有数百(或数千)个项目也会因这一变更而更新,从而导致相应数量的丰富项目事件更新。
在非规范化SCD和外部键关系时,请记住SCD的变更可能对整个事件流产生的影响。如果更改SCD会导致数百万或数十亿个更新事件,您可能会决定放弃非规范化,并将其留给消费者处理。
总结
非规范化使消费者更容易使用数据,但代价是更多的上游处理和对包含数据的谨慎选择。消费者在构建应用程序时可能会更轻松,并且可以选择更广泛的技术,包括那些不支持原生流式连接的技术。
当数据量小且更新不频繁时,上游规范化数据效果良好。较大的事件大小、频繁更新和SCD都是在确定上游非规范化什么数据以及留给消费者自行处理什么数据时需要关注的因素。
最终,选择在事件中包含哪些数据以及省略哪些数据,是在消费者需求、生产者能力和独特数据模型关系之间的平衡行为。但最好的起点是了解消费者的需求以及隔离源系统内部数据模型。
Source:
https://dzone.com/articles/how-to-design-event-streams-part-2