













介绍
就像任何其他设置一样,Kubernetes 集群中的数据可能会面临丢失的风险。为了防止严重问题,拥有一份数据恢复计划至关重要。通过制作备份是一种简单有效的方法,确保您的数据在发生意外事件时是安全的。备份可以一次性运行或按计划运行。定期备份是个不错的主意,以确保您有一个最近的备份可供轻松回退。
Velero 是一个开源工具,旨在帮助备份和恢复 Kubernetes 集群的操作。它非常适用于灾难恢复用例,以及在对集群执行系统操作之前,如升级之前对应用程序状态进行快照。有关此主题的更多详细信息,请访问Velero 工作原理官方页面。
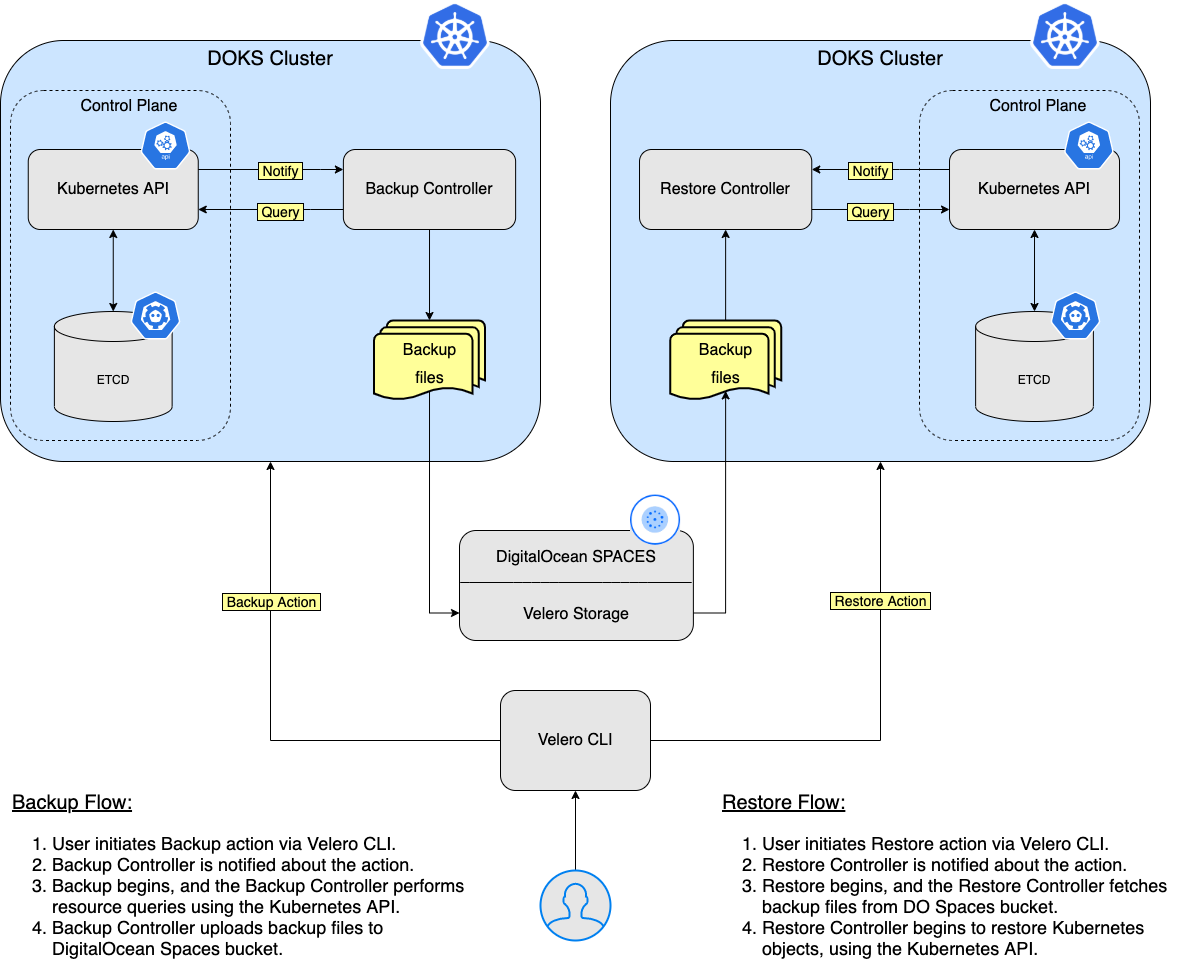
在本教程中,您将学习如何将 Velero 部署到您的 Kubernetes 集群,创建备份,并在出现问题时从备份中恢复。您可以备份整个集群,也可以选择一个命名空间或标签选择器备份您的集群。
目录
先决条件
要完成此教程,您需要以下内容:
- A DO Spaces Bucket and access keys. Save the access and secret keys in a safe place for later use.
- A DigitalOcean API token for Velero to use.
- A Git client, to clone the Starter Kit repository.
- Helm 用于管理 Velero 发布和升级。
- Doctl 用于 DigitalOcean API 交互。
- Kubectl 用于 Kubernetes 交互。
- Velero 客户端用于管理 Velero 备份。
步骤 1 – 使用 Helm 安装 Velero
在这一步中,您将部署 Velero 及其所有必需组件,以便能够为您的 Kubernetes 集群资源(包括 PV)执行备份。备份数据将存储在先前在先决条件部分创建的 DO Spaces 存储桶中。
首先,克隆 Starter Kit Git 存储库并切换到您的本地副本目录:
接下来,添加 Helm 存储库并列出可用的图表:
输出类似于以下内容:
NAME CHART VERSION APP VERSION DESCRIPTION
vmware-tanzu/velero 2.29.7 1.8.1 A Helm chart for velero
感兴趣的图表是 vmware-tanzu/velero,它将在集群上安装 Velero。请访问velero-chart页面以了解有关此图表的更多详细信息。
然后,使用您选择的编辑器(最好支持 YAML lint)打开并检查 Starter Kit 存储库中提供的 Velero Helm values 文件。
接下来,请根据您的 DO Spaces Velero 存储桶替换<>占位符(如名称、区域和密钥)。确保您也提供了您的 DigitalOcean API 令牌(DIGITALOCEAN_TOKEN 键)。
最后,使用helm安装 Velero:
A specific version of the Velero Helm chart is used. In this case 2.29.7 is picked, which maps to the 1.8.1 version of the application (see the output from Step 2.). It’s a good practice in general to lock on a specific version. This helps to have predictable results and allows versioning control via Git.
–create-namespace \
现在,通过运行以下命令检查您的 Velero 部署:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
velero velero 1 2022-06-09 08:38:24.868664 +0300 EEST deployed velero-2.29.7 1.8.1
输出类似于以下内容(STATUS 列应显示为 deployed):
接下来,验证 Velero 是否正常运行:
NAME READY UP-TO-DATE AVAILABLE AGE
velero 1/1 1 1 67s
输出类似以下内容(部署的 Pod 必须处于 Ready 状态):
如果您有兴趣进一步了解,可以查看 Velero 的服务器端组件:
- 探索 Velero CLI 帮助页面,查看可用的命令和子命令。您可以使用
--help标志来获取每个命令的帮助: - 列出所有可用的
Velero命令:
列出 Velero 的 backup 命令选项:
Velero 使用多个 CRD(自定义资源定义)来表示其资源,如备份、备份计划等。您将在本教程的后续步骤中了解到每个资源,以及一些基本示例。
在这一步,您将学习如何对您的 DOKS 集群中的整个命名空间执行一次性备份,并在之后恢复它,确保所有资源都被重新创建。所涉及的命名空间是 ambassador。
首先,初始化备份:
接下来,检查备份是否已创建:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
ambassador-backup Completed 0 0 2021-08-25 19:33:03 +0300 EEST 29d default <none>
输出类似于:
然后,稍等片刻,您可以检查它:
Name: ambassador-backup
Namespace: velero
Labels: velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: ambassador
Excluded: <none>
...
- 输出类似于:
- 查找
Phase行。它应该显示Completed。 - 还要检查是否没有报告任何错误。
创建了一个新的 Kubernetes 备份对象:
~ kubectl get backup/ambassador-backup -n velero -o yaml
apiVersion: velero.io/v1
kind: Backup
metadata:
annotations:
velero.io/source-cluster-k8s-gitversion: v1.21.2
velero.io/source-cluster-k8s-major-version: "1"
velero.io/source-cluster-k8s-minor-version: "21"
...
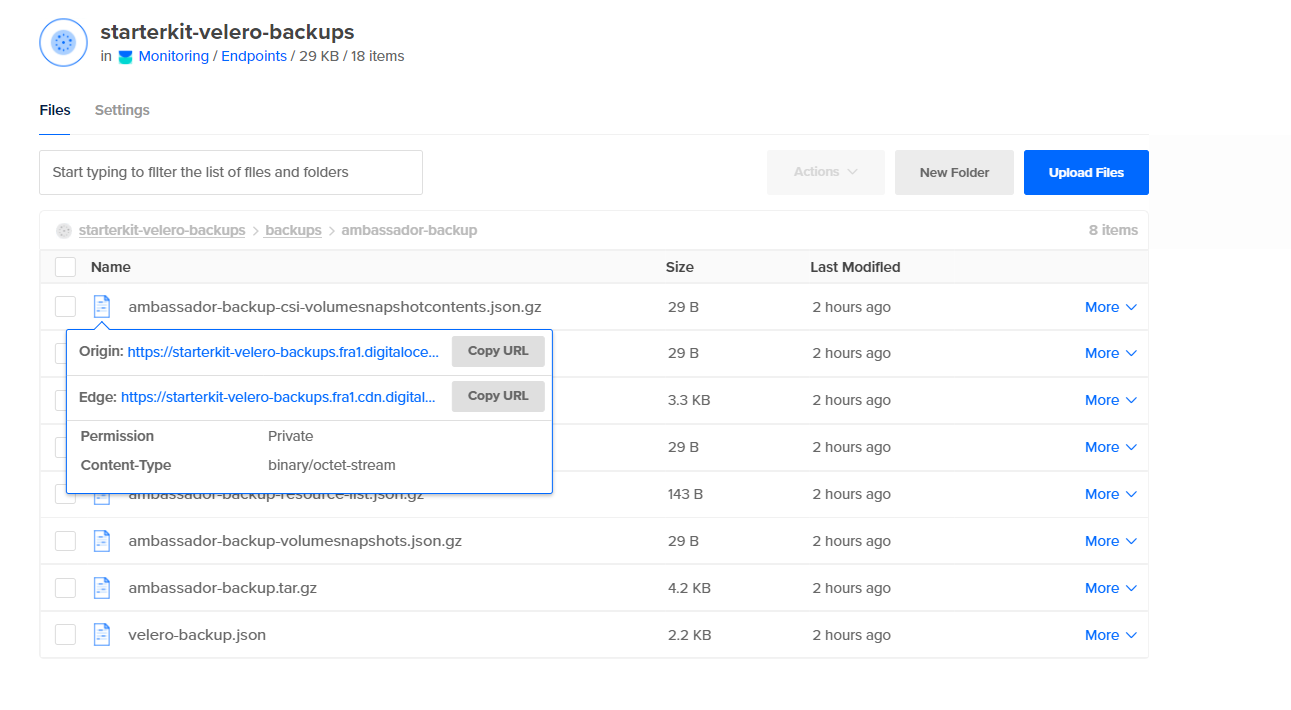
最后,查看 DO Spaces 存储桶,并检查是否有一个名为 backups 的新文件夹,其中包含为您的 ambassador-backup 创建的资产:
首先,通过有意删除ambassador命名空间来模拟灾难:
接下来,检查命名空间是否已删除(命名空间列表不应打印ambassador):
最后,请验证echo和quote后端服务的端点是否为DOWN。请参考创建大使边缘堆栈后端服务有关入门教程中使用的后端应用程序。您可以使用curl进行测试(或者您可以使用您的网络浏览器):
恢复ambassador-backup:
重要提示: 当您删除ambassador命名空间时,与ambassador服务相关的负载均衡器资源也将被删除。因此,当您恢复ambassador服务时,DigitalOcean将重新创建负载均衡器。问题在于,您将获得一个全新的负载均衡器IP地址,因此您需要调整A记录,以便将流量导入到托管在集群上的域。
要验证ambassador命名空间的恢复,请检查ambassador-backup恢复命令输出中的Phase行。它应该显示已完成(还请注意警告部分 – 它会告诉是否出现了问题):
接下来,验证所有资源是否已恢复到ambassador命名空间。查找ambassador pods、services和deployments。
NAME READY STATUS RESTARTS AGE
pod/ambassador-5bdc64f9f6-9qnz6 1/1 Running 0 18h
pod/ambassador-5bdc64f9f6-twgxb 1/1 Running 0 18h
pod/ambassador-agent-bcdd8ccc8-8pcwg 1/1 Running 0 18h
pod/ambassador-redis-64b7c668b9-jzxb5 1/1 Running 0 18h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ambassador LoadBalancer 10.245.74.214 159.89.215.200 80:32091/TCP,443:31423/TCP 18h
service/ambassador-admin ClusterIP 10.245.204.189 <none> 8877/TCP,8005/TCP 18h
service/ambassador-redis ClusterIP 10.245.180.25 <none> 6379/TCP 18h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ambassador 2/2 2 2 18h
deployment.apps/ambassador-agent 1/1 1 1 18h
deployment.apps/ambassador-redis 1/1 1 1 18h
NAME DESIRED CURRENT READY AGE
replicaset.apps/ambassador-5bdc64f9f6 2 2 2 18h
replicaset.apps/ambassador-agent-bcdd8ccc8 1 1 1 18h
replicaset.apps/ambassador-redis-64b7c668b9 1 1 1 18h
输出类似于:
获取ambassador主机:
NAME HOSTNAME STATE PHASE COMPLETED PHASE PENDING AGE
echo-host echo.starter-kit.online Ready 11m
quote-host quote.starter-kit.online Ready 11m
输出类似于:
STATE应为就绪,HOSTNAME列应指向完全合格的主机名。
获取ambassador映射:
NAME SOURCE HOST SOURCE PREFIX DEST SERVICE STATE REASON
ambassador-devportal /documentation/ 127.0.0.1:8500
ambassador-devportal-api /openapi/ 127.0.0.1:8500
ambassador-devportal-assets /documentation/(assets|styles)/(.*)(.css) 127.0.0.1:8500
ambassador-devportal-demo /docs/ 127.0.0.1:8500
echo-backend echo.starter-kit.online /echo/ echo.backend
quote-backend quote.starter-kit.online /quote/ quote.backend
输出看起来类似于(注意echo-backend被映射到echo.starter-kit.online主机和/echo/源前缀,quote-backend也是一样):
最后,在重新配置负载均衡器和DigitalOcean域设置后,请验证echo和quote后端服务端点为UP。请参考创建Ambassador Edge Stack后端服务。
接下来的步骤中,您将通过有意删除DOKS集群来模拟灾难。
在这一步中,您将模拟灾难恢复场景。整个DOKS集群将被删除,然后从先前的备份中恢复。
首先,为整个DOKS集群创建备份:
接下来,请检查备份是否已创建,并且没有报告任何错误。以下命令列出所有可用的备份:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
all-cluster-backup Completed 0 0 2021-08-25 19:43:03 +0300 EEST 29d default <none>
输出类似于:
最后,请检查备份状态和日志(确保没有报告任何错误):
重要提示:每当您销毁一个 DOKS 集群而没有指定 --dangerous 标志给 doctl 命令,然后进行恢复时,相同的负载均衡器将使用相同的 IP 地址重新创建。这意味着您无需更新您的 DigitalOcean DNS A 记录。
但是,当 --dangerous 标志应用于 doctl 命令时,Velero 恢复您的入口控制器时,现有的负载均衡器将被销毁,并将创建具有新外部 IP 的新负载均衡器。因此,请确保相应更新您的 DigitalOcean DNS A 记录。
首先,删除整个 DOKS 集群(确保相应替换 <> 占位符)。
要删除 Kubernetes 集群而不销毁关联的负载均衡器,请运行:
或者要删除 Kubernetes 集群以及关联的负载均衡器:
接下来,按照设置 DigitalOcean Kubernetes中描述的步骤重新创建集群。确保新的 DOKS 集群节点数量等于或大于原始数量。
然后,按照先决条件部分和第 1 步 – 使用 Helm 安装 Velero CLI 和服务器中描述的步骤进行安装。重要的是使用相同的 Helm Chart 版本。
最后,通过运行以下命令恢复所有内容:
首先,检查all-cluster-backup恢复描述命令输出的Phase行。(相应地替换<>占位符)。它应该显示Completed。
现在,通过运行以下命令验证所有集群资源:
现在,后端应用程序应该也能够响应 HTTP 请求。有关 Starter Kit 教程中使用的后端应用程序,请参考创建 Ambassador Edge Stack 后端服务。
在下一步中,您将学习如何为您的DOKS集群应用程序执行定期(或自动)备份。
根据计划自动进行备份是一个非常有用的功能。它允许您倒回时间,并将系统恢复到之前的工作状态,如果出现问题。
创建定期备份是一个非常简单的过程。下面提供了一个示例,间隔为1分钟(选择了kube-system命名空间)。
首先,创建计划:
schedule="*/1 * * * *"
也支持Linux cronjob格式:
接下来,验证计划是否已创建:
NAME STATUS CREATED SCHEDULE BACKUP TTL LAST BACKUP SELECTOR
kube-system-minute-backup Enabled 2021-08-26 12:37:44 +0300 EEST @every 1m 720h0m0s 32s ago <none>
输出类似于:
然后,大约一分钟后检查所有备份:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
kube-system-minute-backup-20210826093916 Completed 0 0 2021-08-26 12:39:20 +0300 EEST 29d default <none>
kube-system-minute-backup-20210826093744 Completed 0 0 2021-08-26 12:37:44 +0300 EEST 29d default <none>
输出类似于:
首先,检查其中一个备份的Phase行(请相应替换<>占位符)。它应该显示Completed。
要恢复一分钟前的备份,请按照本教程之前步骤中学到的相同步骤进行操作。这是一个锻炼和测试你到目前为止积累经验的好方法。
在下一步中,您将学习如何手动或自动删除您随时间创建的特定备份。
如果您不需要旧备份,可以释放 Kubernetes 集群和 Velero DO Spaces 存储桶上的一些资源。
首先,例如选择一个一分钟的备份,并发出以下命令(请相应地替换 <> 占位符):
现在,请检查是否已从velero backup get命令的输出中删除了。它也应该从DO Spaces存储桶中删除。
接下来,您将使用selector一次删除多个备份。 velero backup delete子命令提供了一个名为--selector的标志。它允许您根据Kubernetes标签一次删除多个备份。与Kubernetes标签选择器的规则相同。
首先,列出可用的备份:
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
ambassador-backup Completed 0 0 2021-08-25 19:33:03 +0300 EEST 23d default <none>
backend-minute-backup-20210826094116 Completed 0 0 2021-08-26 12:41:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826094016 Completed 0 0 2021-08-26 12:40:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093916 Completed 0 0 2021-08-26 12:39:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093816 Completed 0 0 2021-08-26 12:38:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093716 Completed 0 0 2021-08-26 12:37:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093616 Completed 0 0 2021-08-26 12:36:16 +0300 EEST 24d default <none>
backend-minute-backup-20210826093509 Completed 0 0 2021-08-26 12:35:09 +0300 EEST 24d default <none>
输出类似于:
接下来,假设您要删除所有backend-minute-backup-*资产。从列表中选择一个备份,并检查标签:
Name: backend-minute-backup-20210826094116
Namespace: velero
Labels: velero.io/schedule-name=backend-minute-backup
velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: backend
Excluded: <none>
...
输出类似于(注意velero.io/schedule-name标签值):
接下来,您可以删除所有匹配backend-minute-backup值的备份velero.io/schedule-name标签:
最后,请检查所有backend-minute-backup-*资产是否已从velero backup get命令的输出以及DO Spaces存储桶中消失。
- 当您创建备份时,可以使用
--ttl标志来指定TTL(生存时间)。如果Velero发现现有的备份资源已过期,它会移除: 备份资源- 云对象
存储中的备份文件 - 所有
PersistentVolume快照
所有关联的还原
TTL标志允许用户使用以小时、分钟和秒为单位的值指定备份保留期,格式为--ttl 24h0m0s。如果未指定,默认的TTL值为30天。
首先,使用3分钟的TTL值创建ambassador备份:
接下来,检查ambassador备份:
Name: ambassador-backup-3min-ttl
Namespace: velero
Labels: velero.io/storage-location=default
Annotations: velero.io/source-cluster-k8s-gitversion=v1.21.2
velero.io/source-cluster-k8s-major-version=1
velero.io/source-cluster-k8s-minor-version=21
Phase: Completed
Errors: 0
Warnings: 0
Namespaces:
Included: ambassador
Excluded: <none>
Resources:
Included: *
Excluded: <none>
Cluster-scoped: auto
Label selector: <none>
Storage Location: default
Velero-Native Snapshot PVs: auto
TTL: 3m0s
...
A new folder should be created in the DO Spaces Velero bucket as well, named ambassador-backup-3min-ttl.
输出类似于以下内容(请注意命名空间 -> 包括部分 – 应显示ambassador,并且TTL字段设置为3ms0):
最后,大约三分钟后,备份和相关资源应自动删除。您可以使用以下命令验证备份对象已被销毁:velero backup describe ambassador-backup-3min-ttl。它应该失败,并显示备份不存在的错误。DO Spaces Velero存储桶中的相应ambassador-backup-3min-ttl文件夹也将被删除。