













日志通常占据公司数据资产的大部分。日志的例子包括业务日志(如用户活动日志)以及服务器、数据库、网络或物联网设备的操作与维护日志。
日志是业务的守护天使。一方面,它们提供系统风险预警,帮助工程师在故障排查中快速定位根本原因。另一方面,如果通过时间范围进行缩放,你可能会识别出一些有用的趋势和模式,更不用说业务日志是用户洞察的基石。
然而,日志可能成为一大负担,原因如下:
- 它们如洪水般涌入。每个系统事件或用户点击都会生成一条日志。一家公司每天常常产生数十亿条新日志。
- 它们体积庞大。日志本应保留。它们可能直到被使用时才有用。因此,一家公司可以积累多达PB级的日志数据,其中许多很少被访问,但却占据了巨大的存储空间。
- 它们必须快速加载和查找。在故障排查中定位目标日志,简直就像大海捞针。人们渴望实时日志写入和实时响应日志查询。
现在,你可以清晰地看到一个理想的日志处理系统应该是什么样的。它应该支持以下功能:
- 高吞吐量实时数据摄取:它应该能够批量写入日志并使其立即可见。
- 低成本存储:它应该能够在不消耗太多资源的情况下存储大量日志。
- 实时文本搜索:应具备快速文本搜索能力。
常见解决方案:Elasticsearch与Grafana Loki
业内存在两种常见的日志处理方案,分别以Elasticsearch和Grafana Loki为代表。
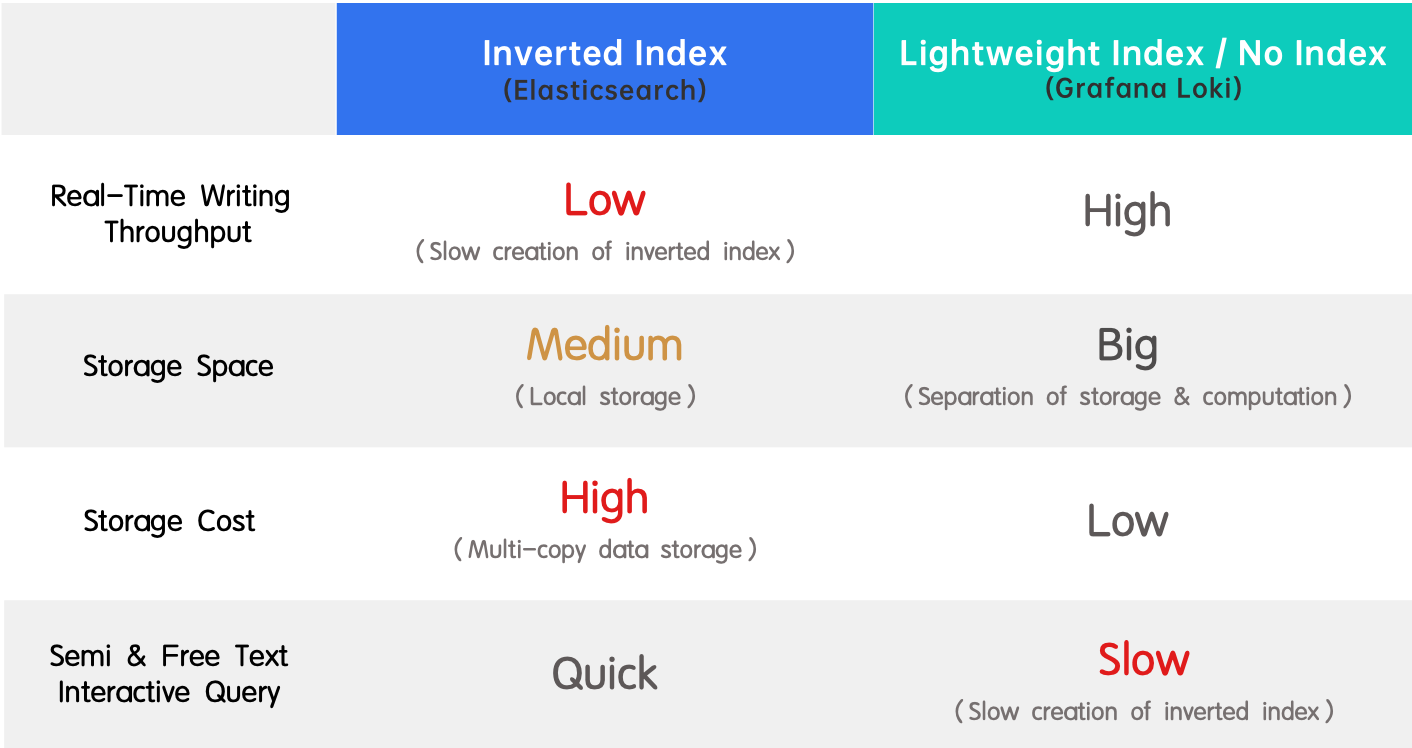
- 倒排索引(Elasticsearch):因其支持全文搜索及高性能而广受欢迎,缺点是实时写入吞吐量低,索引创建时资源消耗巨大。
- 轻量级索引/无索引(Grafana Loki):与倒排索引相反,它以高实时写入吞吐量和低存储成本为特点,但查询速度较慢。
倒排索引简介
A prominent strength of Elasticsearch in log processing is quick keyword search among a sea of logs. This is enabled by inverted indexes.
倒排索引最初用于检索文本中的单词或短语。下图展示了其工作原理:
在数据写入时,系统将文本分词为词项,并存储于倒排列表中,该列表将词项映射到其所在行的ID。进行文本查询时,数据库在倒排列表中找到关键词(词项)对应的行ID,并根据行ID提取目标行。通过这种方式,系统无需遍历整个数据集,从而使查询速度提升数个数量级。
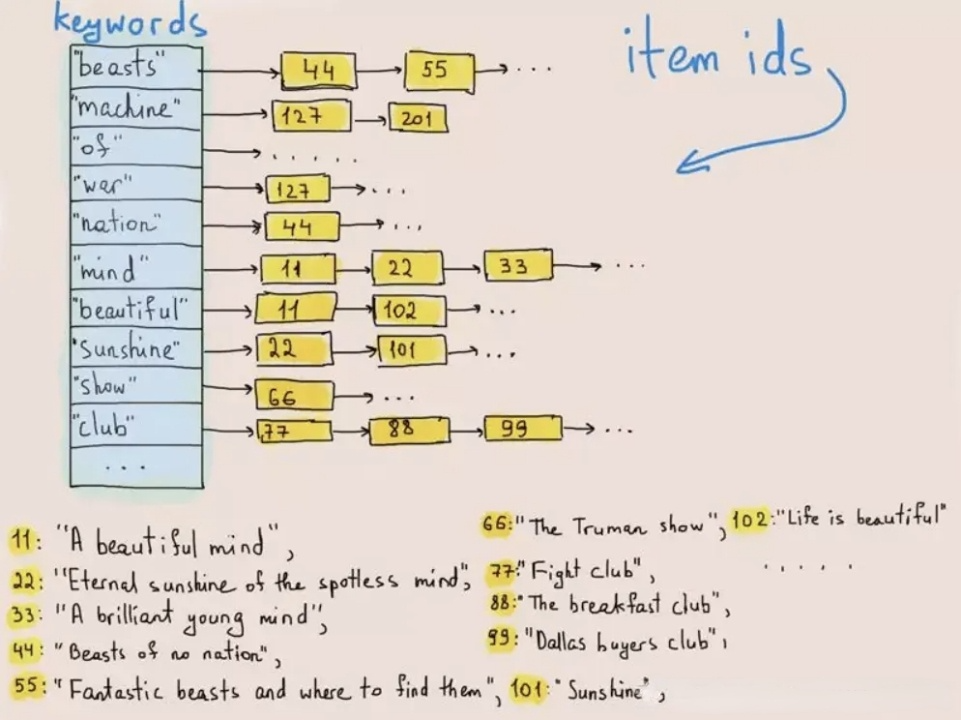
在Elasticsearch的倒排索引机制中,快速检索是以牺牲写入速度、写入吞吐量和存储空间为代价的。原因何在?首先,分词、字典排序及倒排索引的构建均为CPU和内存密集型操作。其次,Elasticsearch需存储原始数据、倒排索引以及为加速查询而额外存储的列式数据副本,这导致了三重冗余。
然而,若无倒排索引,如Grafana Loki,则会因查询缓慢而严重损害用户体验,这成为工程师进行日志分析时的最大痛点。
简而言之,Elasticsearch与Grafana Loki体现了高写入吞吐量、低存储成本与快速查询性能之间的不同权衡。若我告诉你存在一种方法能兼得三者,你是否会感到惊喜?我们在Apache Doris 2.0.0中引入了倒排索引,并对其进行了深度优化,实现了相比Elasticsearch,日志查询速度提升两倍,而存储空间仅需其五分之一。综合考量,这一方案的优越性高达十倍。
Apache Doris中的倒排索引
通常,实现索引的方式有两种:外置索引系统或内置索引。
外部索引系统: 您将外部索引系统连接到数据库。在数据摄取过程中,数据被导入到两个系统中。索引系统创建索引后,会删除其内部的原始数据。当数据用户输入查询时,索引系统提供相关数据的ID,然后数据库根据这些ID查找目标数据。
构建外部索引系统较为简便,对数据库的侵入性较小,但存在一些令人烦恼的缺陷:
- 需要向两个系统写入数据可能导致数据不一致和存储冗余。
- 数据库与索引系统之间的交互带来了开销,因此当目标数据量巨大时,跨两个系统的查询可能会很慢。
- 维护两个系统十分耗时。
在Apache Doris中,我们选择了另一种方式。内置的倒排索引虽然构建起来更为复杂,但一旦完成,其查询速度更快,用户体验更佳,且维护无忧。
在Apache Doris中,数据按以下格式排列。索引存储在索引区域:
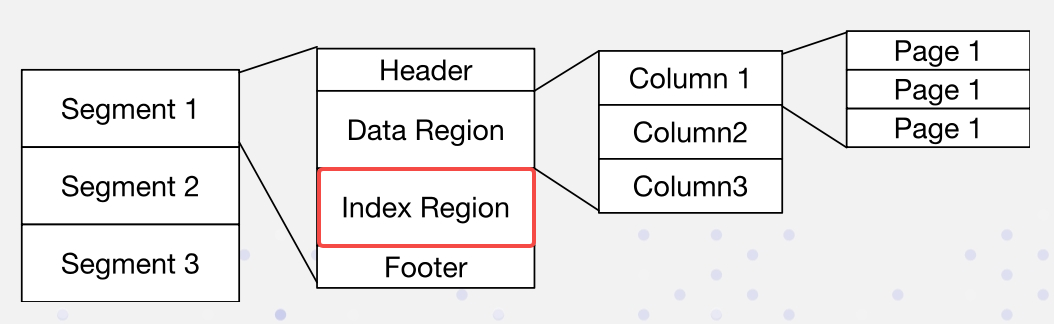
我们以非侵入方式实现倒排索引:
- 数据摄取与压缩:当一个段文件写入Doris时,也会写入一个倒排索引文件。索引文件的路径由段ID和索引ID决定。段中的行对应于索引中的文档,相应的,行ID(RowID)对应文档ID(DocID)。
- 查询:当代码>where子句中包含具有倒排索引的列时,系统会在索引文件中查找,返回一个DocID列表,并将该列表转换为RowID位图。在Apache Doris的RowID过滤机制下,仅读取目标行。这是查询加速的方式。
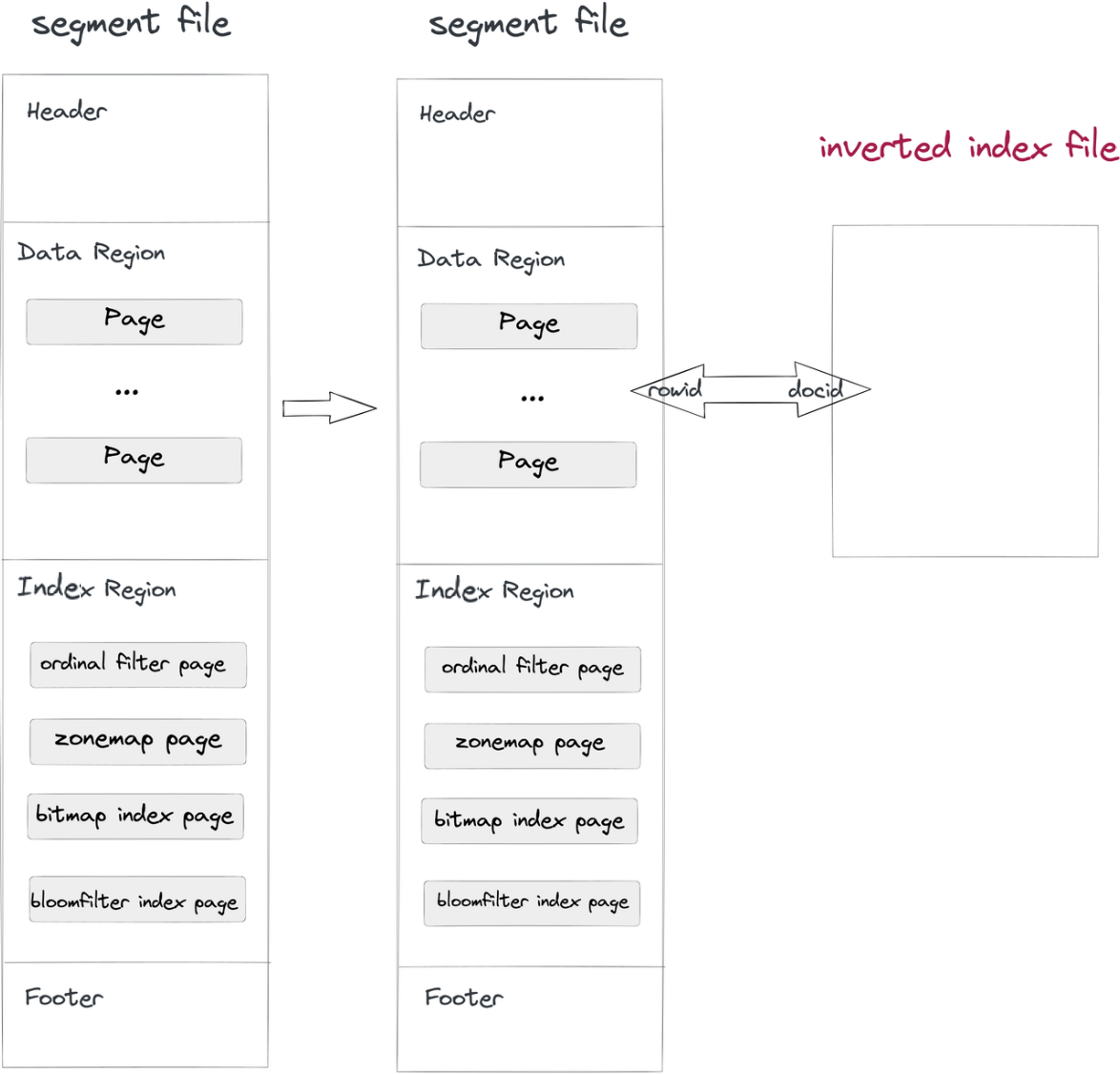
这种非侵入式方法将索引文件与数据文件分离,因此您可以对倒排索引进行任何更改,而不必担心影响数据文件本身或其他索引。
倒排索引优化
常规优化
C++ Implementation and Vectorization
与使用Java的Elasticsearch不同,Apache Doris在其存储模块、查询执行引擎和倒排索引中采用C++实现。与Java相比,C++性能更优,便于向量化,且无JVM GC开销。我们在Apache Doris中对倒排索引的每个步骤(如分词、索引创建和查询)进行了向量化。举个例子,在倒排索引中,Apache Doris每核心写入数据速度为20MB/s,是Elasticsearch(5MB/s)的四倍。
列式存储与压缩
Apache Lucene为Elasticsearch中的倒排索引奠定了基础。由于Lucene本身旨在支持文件存储,因此它以面向行的格式存储数据。
在Apache Doris中,不同列的倒排索引相互隔离,倒排索引文件采用列式存储,便于向量化和数据压缩。
通过采用Zstandard压缩技术,Apache Doris实现了从5:1到10:1的压缩比率,压缩速度更快,且相比GZIP压缩节省了50%的空间。
数值/日期时间列的BKD树
Apache Doris针对数值和日期时间列实施了BKD树结构。这不仅提升了范围查询的性能,而且相比将这些列转换为定长字符串的方法更为节省空间。其额外优势包括:
- 高效的范围查询:能快速定位数值和日期时间列中的目标数据范围。
- 减少存储空间:通过聚合和压缩相邻数据块,降低了存储成本。
- 支持多维数据:BKD树可扩展且适应于多维数据类型,如地理坐标点和范围。
除了BKD树,我们进一步优化了数值和日期时间列的查询性能。
- 低基数场景的优化:针对低基数场景,我们精细调整了压缩算法,使得解压缩和反序列化大量倒排索引时消耗的CPU资源更少。
- 预取机制:在命中率高的场景中,我们采用预取策略。若命中率超过特定阈值,Doris将跳过索引过程,直接进行数据过滤。
针对OLAP的定制优化
通常,日志分析是一种简单的查询,无需高级功能(例如Apache Lucene中的相关性评分)。日志处理工具的核心能力在于快速查询和低存储成本。因此,在Apache Doris中,我们优化了倒排索引结构,以满足OLAP数据库的需求。
- 在数据摄取过程中,我们阻止多个线程向同一索引写入数据,从而避免了锁竞争带来的开销。
- 我们舍弃了正向索引文件和Norm文件,以清理存储空间并减少I/O开销。
- 我们简化了相关性评分和排序的计算逻辑,进一步降低了开销并提升了性能。
鉴于日志按时间范围分区且历史日志访问频率较低,我们计划在未来的Apache Doris版本中提供更细粒度且灵活的索引管理:
- 为指定数据分区创建倒排索引:例如,为过去七天的日志创建索引。
- 删除指定数据分区的倒排索引:例如,删除超过一个月前的日志索引(以便清理索引空间)。
基准测试
我们在公开数据集上对Apache Doris、Elasticsearch和ClickHouse进行了测试。
为了公平比较,我们确保测试条件的一致性,包括基准测试工具、数据集和硬件。
Apache Doris与Elasticsearch的对比
- 基准测试工具:ES Rally,Elasticsearch官方测试工具
- 数据集:1998年世界杯HTTP服务器日志(ES Rally内含自包含数据集)
- 数据大小(压缩前):32G,24700万行,每行平均134字节
- 查询:共11种查询,包括关键词搜索、范围查询、聚合及排序;每种查询连续执行100次。
- 环境:3台16核64G云虚拟机
Apache Doris测试结果:
- 写入速度:550 MB/s,是Elasticsearch的4.2倍
- 压缩比:10:1
- 存储使用量:为Elasticsearch的20%
- 响应时间:为Elasticsearch的43%

Apache Doris对比ClickHouse
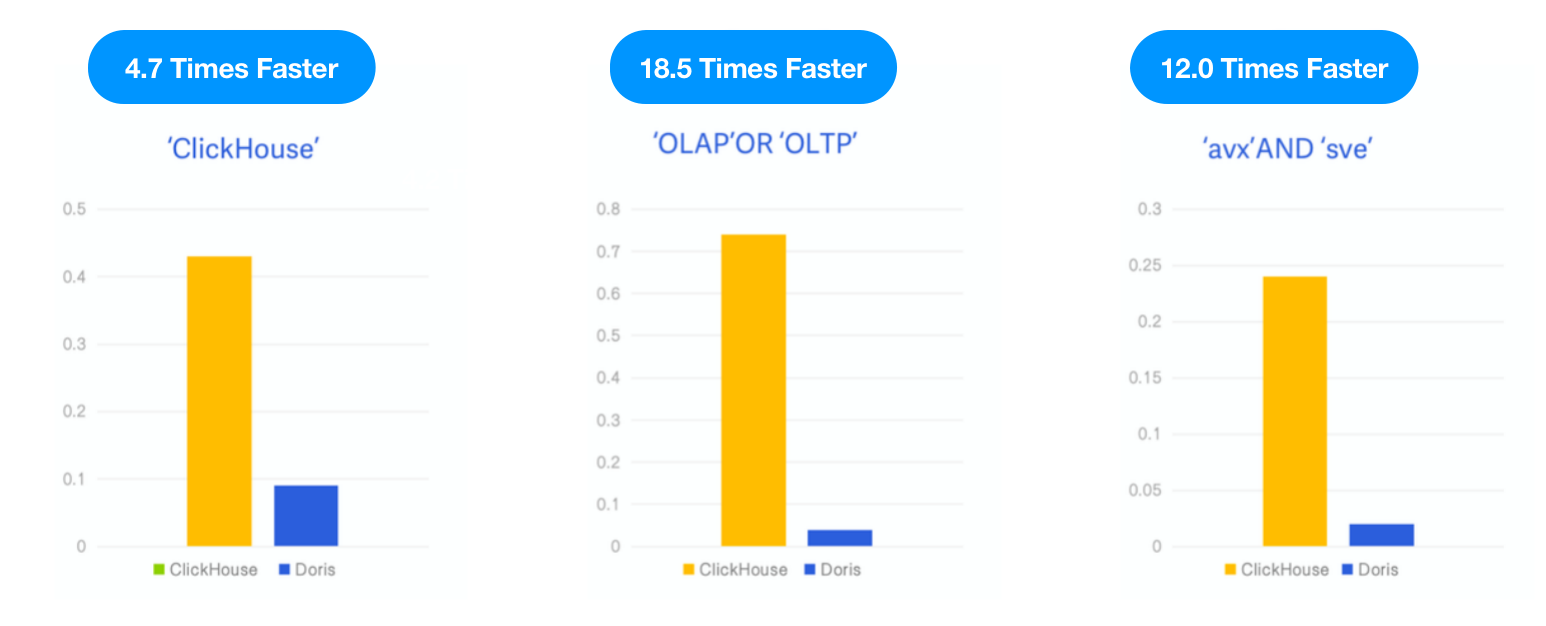
鉴于ClickHouse在v23.1版本推出了实验性的倒排索引功能,我们使用与ClickHouse博客中相同的SQL和数据集对Apache Doris进行了测试,并在相同的测试资源、案例和工具下比较了两者的性能。
- 数据:6.7G,2873万行,Hacker News数据集,Parquet格式
- 查询:3次关键词搜索,统计关键词“ClickHouse”、“OLAP”或“OLTP”以及“avx”与“sve”的频次。
- 环境:1台16核64G云虚拟机
结果:在三个查询中,Apache Doris 分别比 ClickHouse 快 4.7倍、18.5倍和12倍。
使用示例与说明
- 数据集:来自 Hacker News 的一百万条评论记录
步骤1: 在创建表时指定倒排索引给数据表。
参数:
- INDEX idx_comment (
comment):为“comment”列创建名为“idx_comment”的索引 - USING INVERTED:为表指定倒排索引
- PROPERTIES(“parser” = “english”):指定分词语言为英语
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");(注意:您可以通过ADD INDEX idx_comment ON hackernews_1m(comment) USING INVERTED PROPERTIES("parser" = "english")向现有表添加索引。与智能索引和二级索引不同,倒排索引的创建仅涉及读取评论列,因此可以快得多。)
步骤2:使用MATCH_ALL在评论列中检索”OLAP”和”OLTP”这两个词。这里的响应时间是硬匹配like的十分之一。(随着数据量的增加,性能差距会进一步扩大。)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.13 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)
更多功能介绍及使用指南,请参阅文档:倒排索引
总结
总之,Apache Doris之所以能提供比Elasticsearch高出10倍的成本效益,得益于其针对OLAP优化的倒排索引技术,这包括了列式存储引擎、大规模并行处理框架、向量化查询引擎以及成本优化器等特性。
尽管我们对自身的倒排索引解决方案感到自豪,但我们也认识到自发布基准测试可能存在争议,因此我们欢迎来自任何第三方测试者的反馈,并期待看到Apache Doris在实际案例中的表现。
Source:
https://dzone.com/articles/building-a-log-analytics-solution-10-times-more-co