













这是某房地产巨头数字化转型的一部分。出于保密考虑,我不会透露任何业务数据,但您将深入了解我们的数据仓库及优化策略。
现在让我们开始吧。
架构
从逻辑上,我们的数据架构可分为四个部分。
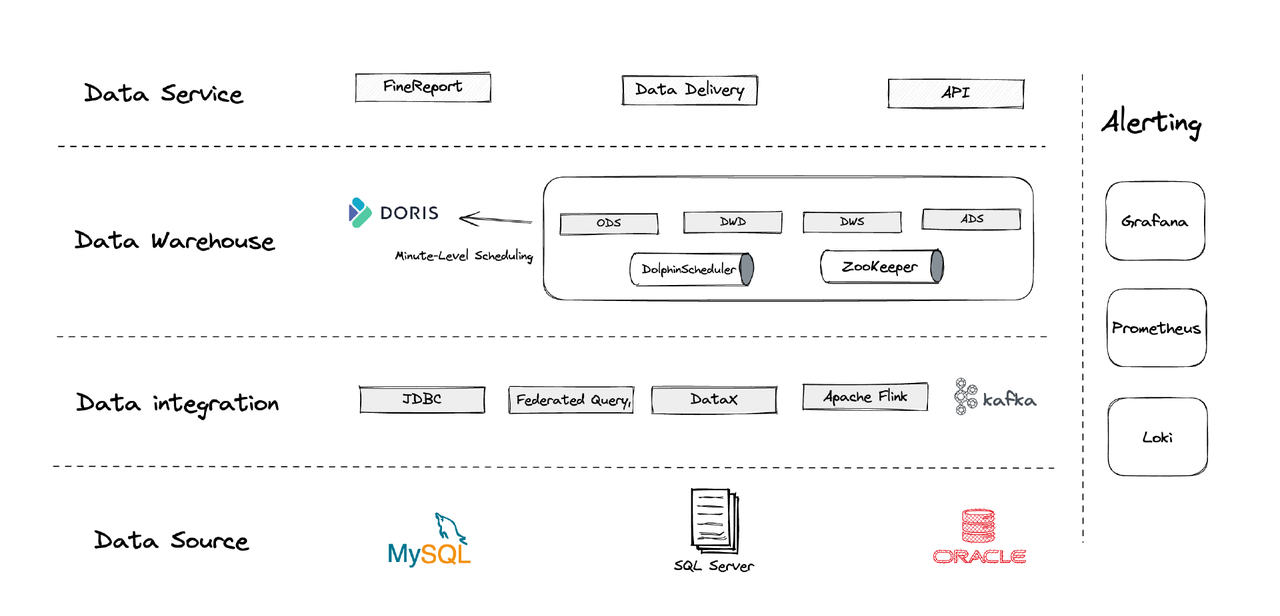
- 数据集成:采用Flink CDC、DataX以及Apache Doris的Multi-Catalog特性进行支持。
- 数据管理:利用Apache Dolphinscheduler管理脚本生命周期、多租户权限及数据质量监控。
- 告警系统:通过Grafana、Prometheus和Loki监控组件资源与日志。
- 数据服务:此处BI工具介入,提供用户交互功能,如数据查询与分析。
1. 表结构
我们围绕业务中的每个运营实体(如客户、房产等)创建维度表和事实表。若一系列活动涉及同一运营实体,应由同一字段记录。(这是从以往混乱的数据管理系统中吸取的教训。)
2. 分层
我们的数据仓库被划分为五个概念层级。我们使用Apache Doris和Apache DolphinScheduler来调度这些层级间的DAG脚本。

每日,层级除了进行增量更新外,还会进行全面更新,以防历史状态字段变动或ODS表数据同步不完整。
3. 增量更新策略
(1) 设置where >= "活动时间 -1天或-1小时"而非where >= "活动时间"
此举旨在避免因调度脚本时间差导致的数据漂移。例如,若执行间隔设为10分钟,假设脚本在23:58:00执行,而新数据在23:59:00到达。若采用where >= "活动时间",当日该数据将遗漏。
(2) 每次脚本执行前,获取表中最大主键ID,将其存入辅助表,并设置where >= "辅助表中的ID"
此法旨在防止数据重复。若使用Apache Doris的唯一键模型并指定一组主键,源表主键如有变动,变动将被记录并加载相关数据,可能导致数据重复。该方法能解决此问题,但仅适用于源表具备自增主键的情况。
(3) 对表进行分区
对于日志表这类基于时间自动增长的数据,历史数据和状态变化可能较少,但数据量庞大,因此在整体更新和快照生成时可能面临巨大的计算压力。为此,对这类表进行分区更为合适,这样每次增量更新仅需替换一个分区。(同时也要注意数据漂移的问题。)
4. 整体更新策略
(1) 清空表
先清空表,然后从源表导入所有数据。此方法适用于小型表,且在深夜无用户活动时适用。
(2)ALTER TABLE tbl1 REPLACE WITH TABLE tbl2
这是一种原子操作,推荐用于大型表。每次执行脚本前,先创建一个具有相同结构的临时表,将所有数据加载进去,然后用临时表替换原表。
应用场景
- ETL任务:每分钟执行一次
- 首次部署配置:8节点,2前端,8后端,混合部署
- 节点配置:32核*60GB*2TB SSD
这是我们处理TB级历史数据和GB级增量数据的配置。您可以此为参考,在此基础上扩展您的集群。Apache Doris的部署简单,无需其他组件。
1. 为整合离线数据与日志数据,我们采用DataX,该工具支持CSV格式及多种关系型数据库读取器,并结合Apache Doris提供的DataX-Doris-Writer实现数据写入。

2. 我们利用Flink CDC同步源表数据,并通过Apache Doris的物化视图或聚合模型来汇聚实时指标。鉴于仅需实时处理部分指标且避免产生过多数据库连接,我们采用单一Flink作业管理多个CDC源表,这一功能可通过Dinky的多源合并及全库同步特性实现,或自行构建Flink DataStream多源合并任务。值得注意的是,Flink CDC与Apache Doris均支持Schema变更。
EXECUTE CDCSOURCE demo_doris WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '10000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'ods.ods_*,ods.ods_*',
'sink.connector' = 'doris',
'sink.fenodes' = '127.0.0.1:8030',
'sink.username' = 'root',
'sink.password' = '123456',
'sink.doris.batch.size' = '1000',
'sink.sink.max-retries' = '1',
'sink.sink.batch.interval' = '60000',
'sink.sink.db' = 'test',
'sink.sink.properties.format' ='json',
'sink.sink.properties.read_json_by_line' ='true',
'sink.table.identifier' = '${schemaName}.${tableName}',
'sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
);3. 我们采用SQL脚本或“Shell + SQL”脚本,并进行脚本生命周期管理。在ODS层,我们编写通用的DataX作业文件,针对每个源表导入时传递参数,而非为每个源表单独编写DataX作业,从而极大简化维护工作。我们通过DolphinScheduler管理Apache Doris的ETL脚本,并实施版本控制,以便生产环境中出现错误时能够迅速回滚。
4. 通过ETL脚本导入数据后,我们在报表工具中创建页面,并运用SQL为不同账户分配权限,包括修改行、字段及全局字典的权限。Apache Doris的账户权限控制机制与MySQL类似,确保了权限管理的有效性。
我们也采用Apache Doris数据备份进行灾难恢复,利用Apache Doris审计日志监控SQL执行效率,通过Grafana+Loki实现集群指标告警,并使用Supervisor监控节点组件的守护进程。
优化
数据摄入
我们运用DataX进行离线数据流式加载,允许我们调整每批次的大小。流式加载方法同步返回结果,符合我们的架构需求。若通过DolphinScheduler执行异步数据导入,系统可能误认为脚本已执行,导致混乱。若采用其他方法,建议在shell脚本中执行show load,并检查正则过滤状态以确认摄入是否成功。
数据模型
我们多数表采用Apache Doris的唯一键模型,确保数据脚本的一致性,有效避免上游数据重复。
读取外部数据
我们利用Apache Doris的多目录功能连接外部数据源,允许在目录级别创建外部数据的映射。
查询优化
建议将最常用的非字符类型字段(如int和where子句)置于前36字节,以便在点查询中毫秒级过滤这些字段。
数据字典
对我们而言,创建数据字典至关重要,因为它大幅降低了人员沟通成本,这在团队规模庞大时尤为关键。我们利用Apache Doris中的information_schema来生成数据字典,借助它,我们能迅速掌握表和字段的全面信息,从而提升开发效率。
性能方面
离线数据摄取时间:仅需几分钟
查询延迟:对于包含超过1亿行的表,Apache Doris能在1秒内响应即席查询,复杂查询则在5秒内完成。
资源消耗:构建此数据仓库仅需少量服务器,且Apache Doris高达70%的压缩比为我们节省了大量存储资源。
经验与结论
实际上,在我们演进至当前数据架构之前,曾尝试使用Hive、Spark和Hadoop搭建离线数据仓库。结果发现,对于我们这类传统企业,Hadoop显得过于庞大,因为我们并无大量数据需处理。找到最适合自己的组件至关重要。
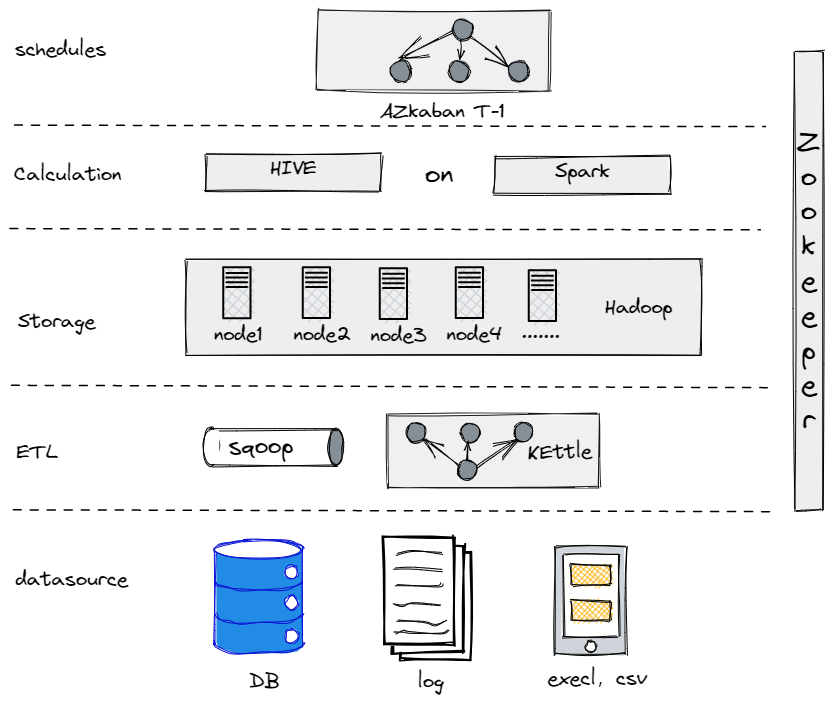
我们旧有的离线数据仓库
另一方面,为了顺利过渡到大数据环境,我们需要确保数据平台在操作和维护上都尽可能简化。因此,我们选择了Apache Doris。它兼容MySQL协议,并提供丰富的函数集,这样我们就无需自行开发UDF。此外,它仅由前端和后端两种进程组成,便于扩展和追踪。
Source:
https://dzone.com/articles/building-a-data-warehouse-for-traditional-industry