













自主智能体的崛起激发了人们对能够自主执行任务、提供建议以及执行复杂工作流程的智能体的热情,这些工作流程将人工智能与传统计算相结合。但在现实世界的以产品为驱动的环境中创建这样的智能体面临的挑战超出了人工智能本身的范畴。
如果没有精心的架构,组件之间的依赖关系可能会造成瓶颈,限制可扩展性,并在系统演变时使维护变得复杂。解决方案在于解耦工作流程,使智能体、基础设施和其他组件能够流畅地交互,而不受严格依赖的限制。
这种灵活、可扩展的集成需要共享的数据交换“语言”——由事件流驱动的强大事件驱动架构(EDA)。通过围绕事件组织应用程序,智能体可以在一个响应式的、解耦的系统中工作,每个部分独立完成其任务。团队可以自由做出技术选择,单独管理扩展需求,并在组件之间保持清晰的边界,从而实现真正的敏捷性。
为了检验这些原则,我开发了PodPrep AI,一个人工智能驱动的研究助手,帮助我为《软件工程日报》和《软件聚会》的播客访谈做准备。在这篇文章中,我将深入探讨PodPrep AI的设计和架构,展示EDA和实时数据流如何驱动一个有效的自主系统。
注意:如果您只想查看代码,请跳转到我的GitHub仓库 这里。
为什么选择事件驱动架构用于人工智能?
在现实世界的人工智能应用中,紧密耦合的、单片式设计不具备持久性。虽然概念验证或演示通常使用单一统一系统以简化流程,但这种方法在生产中很快变得不切实际,尤其是在分布式环境中。紧密耦合的系统会导致瓶颈,限制可伸缩性,并减慢迭代速度,这些都是AI解决方案发展过程中必须避免的关键挑战。
考虑一个典型的AI代理。
它可能需要从多个来源提取数据,处理提示工程和RAG工作流,并直接与各种工具交互以执行确定性工作流。所需的编排是复杂的,依赖于多个系统。如果代理需要与其他代理通信,复杂性只会增加。如果没有灵活的架构,这些依赖关系会使扩展和修改几乎成为不可能。

在生产中,通常不同团队处理堆栈的不同部分:MLOps和数据工程负责管理RAG流水线,数据科学选择模型,应用开发人员构建界面和后端。紧密耦合的设置会导致这些团队之间产生依赖关系,从而减慢交付速度并使扩展变得困难。理想情况下,应用层不应该需要了解AI的内部工作;它们只需在需要时简单地使用结果即可。
此外,人工智能应用不能孤立运行。为了实现真正的价值,人工智能洞察需要在客户数据平台(CDP)、客户关系管理(CRM)、分析等之间无缝流动。客户互动应实时触发更新,直接反馈到其他工具中以便采取行动和分析。如果没有统一的方法,跨平台整合洞察将变得支离破碎,难以管理且无法扩展。
基于事件驱动架构(EDA)的人工智能解决了这些挑战,创造了数据的“中央神经系统”。通过EDA,应用程序广播事件,而不是依赖于链式命令。这使得组件解耦,允许数据在需要的地方异步流动,使每个团队能够独立工作。EDA促进无缝数据集成、可扩展增长和韧性,使其成为现代人工智能驱动系统的强大基础。
设计一个可扩展的人工智能驱动研究代理
在过去两年中,我在《软件工程日报》、《软件聚会》和《部分编辑》中主持了数百个播客。
为了准备每个播客,我进行深入的研究过程,以准备一份包含我的想法、嘉宾和主题背景以及一系列潜在问题的播客简报。为了构建这个简报,我通常会研究嘉宾及其工作的公司,收听他们可能出现在的其他播客,阅读他们撰写的博客文章,并了解我们将要讨论的主要主题。
我尝试将我主持的其他播客或与主题或类似主题相关的个人经验联系起来。这整个过程需要相当大的时间和精力。大型播客运营有专门的研究人员和助手为主持人做这些工作。我在这里并不运营那种规模的业务。我必须自己完成这一切。
为了解决这个问题,我想建立一个代理,可以为我完成这项工作。在高层次上,这个代理看起来像下面的图像。

我提供基本的来源材料,比如嘉宾姓名、公司、我想要关注的主题、一些参考网址,比如博客文章和现有播客,然后一些AI魔法发生,我的研究就完成了。
这个简单的想法促使我创建了PodPrep AI,我的AI驱动研究助手,成本仅仅是代币。
本文的其余部分讨论了PodPrep AI的设计,从用户界面开始。
构建代理用户界面
我将代理的界面设计为一个网络应用程序,我可以轻松输入研究过程中的来源材料。这包括嘉宾的姓名、他们的公司、访谈主题、任何额外的背景信息,以及与相关博客、网站和之前播客访谈的链接。
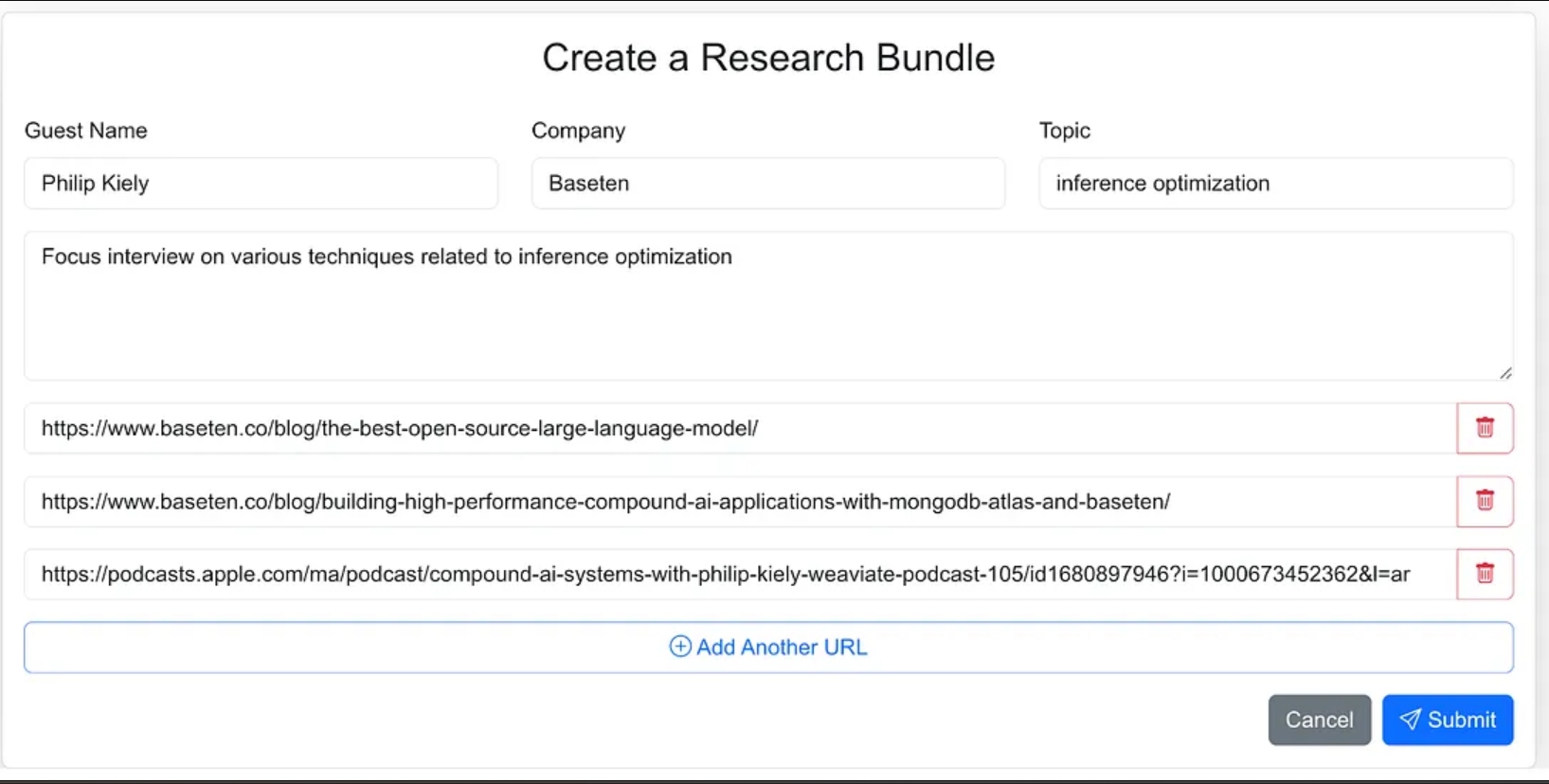
我本可以给代理更少的指示,并作为代理工作流程的一部分让它去寻找来源材料,但在1.0版本中,我决定提供来源网址。
该网络应用是一个使用Next.js和MongoDB构建的标准三层应用程序,用于应用数据库。它不知道任何关于人工智能的知识。它只是允许用户输入新的研究包,并在代理进程完成工作流程并在应用数据库中填充研究简报之前,这些包会显示为处理状态。
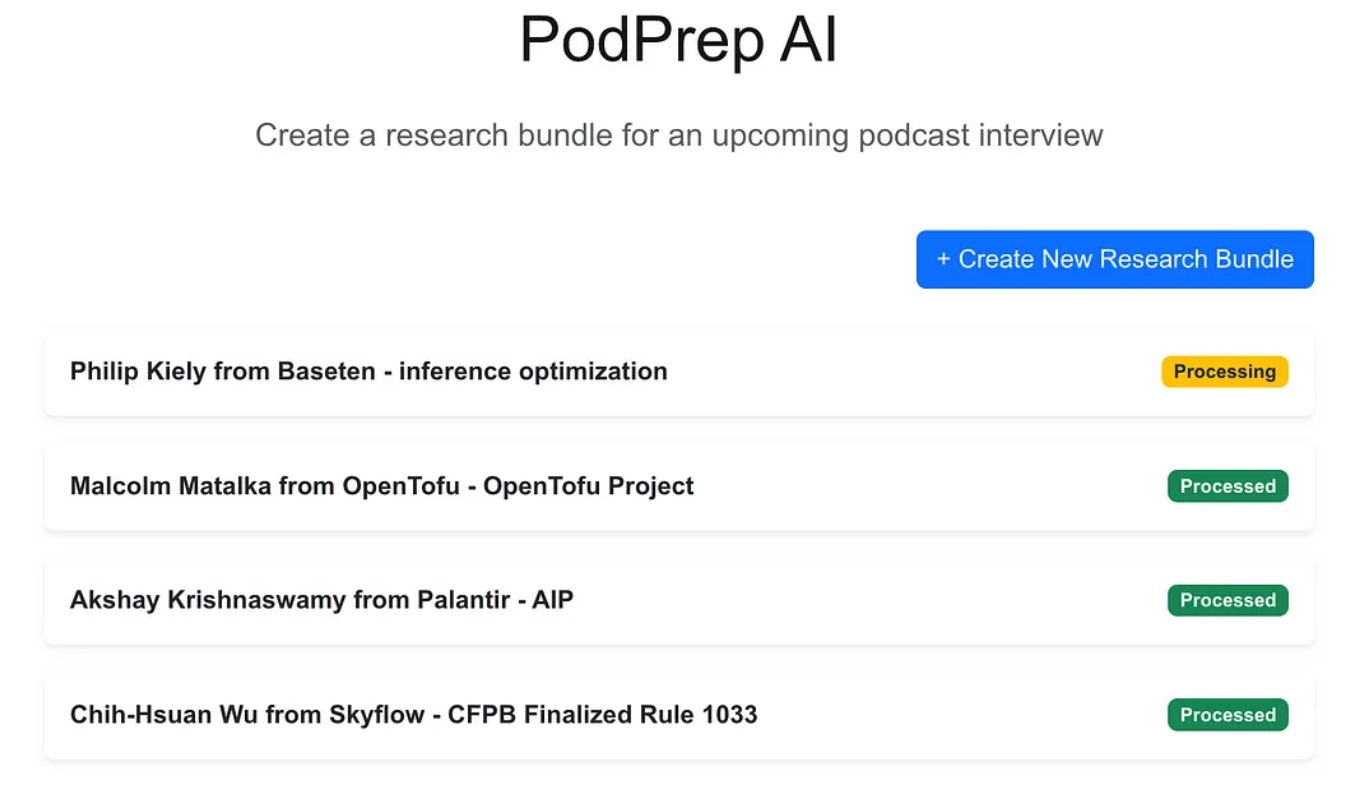
一旦人工智能完成,我就可以访问条目的简报文档,如下所示。

创建代理工作流程
对于版本1.0,我希望能够执行三个主要操作来构建研究简报:
- 对于任何网站URL、博客文章或播客,检索文本或摘要,将文本分块成合理大小,生成嵌入并存储向量表示。
- 从研究来源URL提取的所有文本中,提取最有趣的问题,并存储这些问题。
- 生成一个播客研究简报,结合基于嵌入的最相关内容,先前提出的最佳问题,以及包输入中的任何其他信息。
下面的图片显示了从网络应用到代理工作流程的架构。
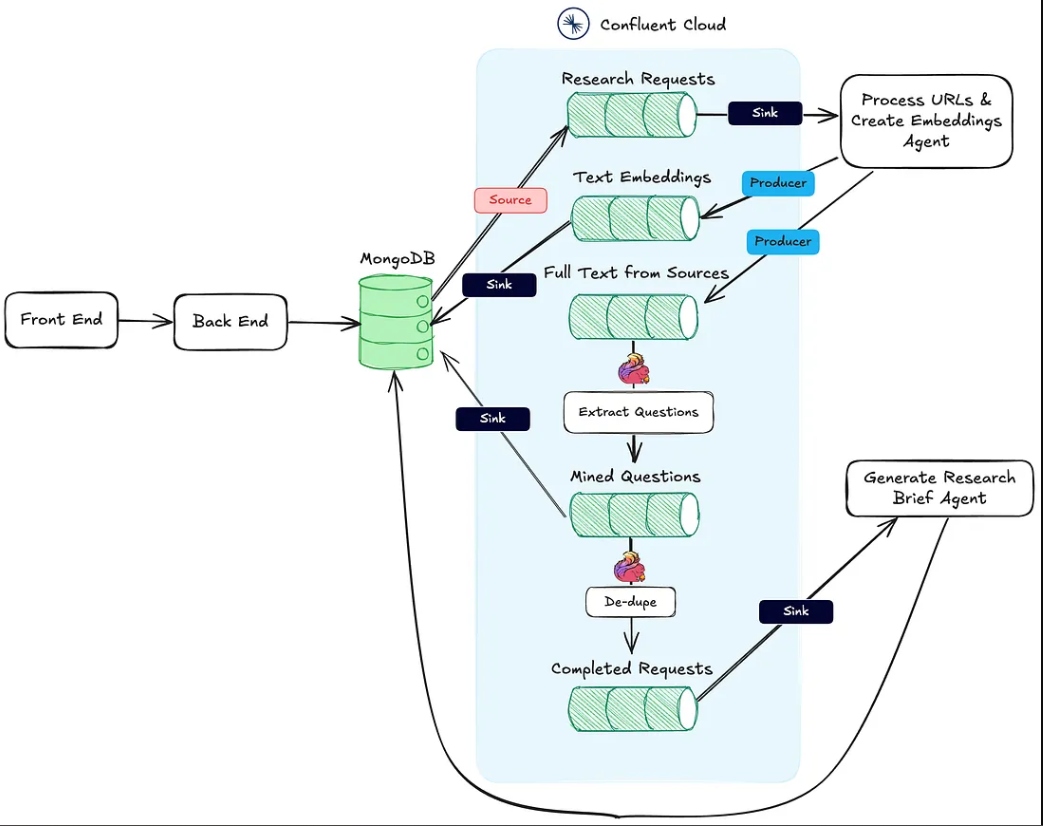
上述操作中的动作#1由处理URL和创建嵌入代理HTTP接收端点支持。
操作#2使用Flink和Confluent Cloud中内置的AI模型支持进行。
最后,动作#3由生成研究简报代理执行,这也是一个HTTP接收端点,仅在前两个动作完成后调用。
在接下来的部分中,我会详细讨论每个动作。
处理URL并创建嵌入代理
此代理负责从研究来源URL和向量嵌入流水线中提取文本。以下是幕后处理研究材料时正在发生的高级流程。

一旦用户创建并将研究捆绑保存到MongoDB,MongoDB源连接器会向名为research-requests的Kafka主题生成消息。这启动了代理工作流。
每个对HTTP端点的post请求包含来自研究请求的URL和MongoDB研究捆绑集合中的主键。
代理循环遍历每个URL,如果不是Apple播客,则提取完整页面HTML。由于我不知道页面的结构,无法依赖HTML解析库来查找相关文本。相反,我使用下面的提示将页面文本发送到gpt-4o-mini模型,并将温度设置为零以获取所需内容。
`Here is the content of a webpage:
${text}
Instructions:
- If there is a blog post within this content, extract and return the main text of the blog post.
- If there is no blog post, summarize the most important information on the page.`
对于播客,我需要做更多的工作。
逆向工程Apple Podcast URLs
为了从播客剧集中提取数据,我们首先需要使用Whisper模型将音频转换为文本。但在此之前,我们必须定位每个播客剧集的实际MP3文件,下载它,并将其分割成不超过25MB的块(Whisper的最大大小)。
挑战在于苹果不提供其播客剧集的直接MP3链接。然而,MP3文件可以在播客的原始RSS源中找到,并且我们可以通过苹果播客ID来以编程方式找到此源。
例如,在下面的URL中,/id后面的数字部分是播客的唯一苹果ID:
https://podcasts.apple.com/us/podcast/deep-dive-into-inference-optimization-for-llms-with/id1699385780?i=1000675820505
使用苹果的API,我们可以查找播客ID并检索包含RSS源URL的JSON响应:
https://itunes.apple.com/lookup?id=1699385780&entity=podcast
一旦我们有了RSS源XML,我们就可以在其中搜索特定剧集。由于我们只有来自苹果的剧集URL(而不是实际标题),我们使用URL中的标题slug来定位源中的剧集并检索其MP3 URL。
async function getMp3DownloadUrl(url) {
let podcastId = extractPodcastId(url);
let titleToMatch = extractAndFormatTitle(url);
if (podcastId) {
let feedLookupUrl = `https://itunes.apple.com/lookup?id=${podcastId}&entity=podcast`;
const itunesResponse = await axios.get(feedLookupUrl);
const itunesData = itunesResponse.data;
// Check if results were returned
if (itunesData.resultCount === 0 || !itunesData.results[0].feedUrl) {
console.error("No feed URL found for this podcast ID.");
return;
}
// Extract the feed URL
const feedUrl = itunesData.results[0].feedUrl;
// Fetch the document from the feed URL
const feedResponse = await axios.get(feedUrl);
const rssContent = feedResponse.data;
// Parse the RSS feed XML
const rssData = await parseStringPromise(rssContent);
const episodes = rssData.rss.channel[0].item; // Access all items (episodes) in the feed
// Find the matching episode by title, have to transform title to match the URL-based title
const matchingEpisode = episodes.find(episode => {
return getSlug(episode.title[0]).includes(titleToMatch);
}
);
if (!matchingEpisode) {
console.log(`No episode found with title containing "${titleToMatch}"`);
return false;
}
// Extract the MP3 URL from the enclosure tag
return matchingEpisode.enclosure[0].$.url;
}
return false;
}
现在,有了来自博客文章、网站和MP3的文本,代理程序使用LangChain的递归字符文本拆分器将文本拆分为块,并从这些块生成嵌入。这些块被发布到text-embeddings主题并被传输到MongoDB。
- 注意:我选择将MongoDB用作我的应用程序数据库和向量数据库。但是,由于我采取的EDA方法,这两者可以轻松分开成为不同的系统,只需将Text Embeddings主题的传输连接器进行交换即可。
除了创建和发布嵌入向量外,代理还会将文本从来源发布到名为full-text-from-sources的主题。发布到该主题会启动动作#2。
使用 Flink 和 OpenAI 提取问题
Apache Flink是一个开源的流处理框架,专为实时处理大量数据而构建,非常适用于高吞吐量、低延迟的应用程序。通过将 Flink 与 Confluent 配合使用,我们可以将 OpenAI 的 GPT 等语言模型直接引入流处理工作流中。这种集成实现了实时的 RAG 工作流,确保问题提取过程与最新可用数据一起运行。
在流中保留原始来源文本还使我们能够在以后引入使用相同数据的新工作流程,增强研究简报生成过程或将其发送到下游服务,如数据仓库。这种灵活的设置使我们能够随时间逐步叠加额外的人工智能和非人工智能功能,而无需彻底改变核心流程。
在 PodPrep AI 中,我使用 Flink 从源 URL 中提取问题。
设置 Flink 调用 LLM 需要通过 Confluent 的 CLI 进行连接配置。以下是一个设置 OpenAI 连接的示例命令,但也有多个选项可供选择。
confluent flink connection create openai-connection \
--cloud aws \
--region us-east-1 \
--type openai \
--endpoint https://api.openai.com/v1/chat/completions \
--api-key <REPLACE_WITH_OPEN_AI_KEY>
一旦连接建立,我可以在 Cloud 控制台或 Flink SQL shell 中创建一个模型。对于问题提取,我会相应地设置模型。
-- Creates model for pulling questions from research source material
CREATE MODEL `question_generation`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'openai.connection'='openai-connection',
'provider'='openai',
'task'='text_generation',
'openai.model_version' = 'gpt-3.5-turbo',
'openai.system_prompt' = 'Extract the most interesting questions asked from the text. Paraphrase the questions and seperate each one by a blank line. Do not number the questions.'
);
有了准备好的模型,我会使用 Flink 内置的 ml_predict 函数从源材料生成问题,并将输出写入一个名为 mined-questions 的流,它会与 MongoDB 同步以供以后使用。
-- Generates questions based on text pulled from research source material
INSERT INTO `mined-questions`
SELECT
`key`,
`bundleId`,
`url`,
q.response AS questions
FROM
`full-text-from-sources`,
LATERAL TABLE (
ml_predict('question_generation', content)
) AS q;
Flink 还帮助跟踪所有研究材料何时被处理完毕,触发研究简报的生成。这是通过在 mined-questions 中的 URL 与全文来源流中的 URL 相匹配时向一个名为 completed-requests 的流写入来完成的。
-- Writes the bundleId to the complete topic once all questions have been created
INSERT INTO `completed-requests`
SELECT '' AS id, pmq.bundleId
FROM (
SELECT bundleId, COUNT(url) AS url_count_mined
FROM `mined-questions`
GROUP BY bundleId
) AS pmq
JOIN (
SELECT bundleId, COUNT(url) AS url_count_full
FROM `full-text-from-sources`
GROUP BY bundleId
) AS pft
ON pmq.bundleId = pft.bundleId
WHERE pmq.url_count_mined = pft.url_count_full;
当消息被写入 completed-requests 时,研究捆绑的唯一 ID 将被发送到生成研究简报代理。
生成研究简报代理
此代理会获取所有最相关的研究材料,并使用 LLM 创建研究简报。以下是创建研究简报所涉及的事件的高级流程。

生成研究简报代理的流程图
让我们逐步分解其中的一些步骤。为了构建 LLM 的提示,我会将挖掘出的问题、话题、嘉宾姓名、公司名称、系统提示以及与播客话题最语义相似的向量数据库中存储的上下文结合起来。
由于研究包的上下文信息有限,直接从向量存储中提取最相关的上下文非常具有挑战性。为了解决这个问题,我让大型语言模型生成一个搜索查询,以找到最佳匹配的内容,如图中的“创建搜索查询”节点所示。
async function getSearchString(researchBundle) {
const userPrompt = `
Guest:
${researchBundle.guestName}
Company:
${researchBundle.company}
Topic:
${researchBundle.topic}
Context:
${researchBundle.context}
Create a natural language search query given the data available.
`;
const systemPrompt = `You are an expert in research for an engineering podcast. Using the
guest name, company, topic, and context, create the best possible query to search a vector
database for relevant data mined from blog posts and existing podcasts.`;
const messages = [
new SystemMessage(systemPrompt),
new HumanMessage(userPrompt),
];
const response = await model.invoke(messages);
return response.content;
}
利用大型语言模型生成的查询,我创建一个嵌入并通过向量索引在MongoDB中搜索,按bundleId过滤,以限制搜索到与特定播客相关的材料。
确定最佳上下文信息后,我构建一个提示并生成研究简报,将结果保存到MongoDB,以供Web应用程序显示。
实施时需注意的事项
我为PodPrep AI编写了前端应用程序和代理,使用的是Javascript,但在实际场景中,代理很可能使用Python等其他语言。此外,为了简单起见,处理URL和创建嵌入代理和生成研究简报代理都在同一个项目中运行于同一Web服务器。在真正的生产系统中,这些可以是无服务器功能,独立运行。
最后思考
构建PodPrep AI突显了事件驱动架构如何使实际AI应用能够平稳扩展和适应。借助Flink和Confluent,我创建了一个实时处理数据的系统,为基于AI的工作流提供动力,而无需严格的依赖关系。这种解耦的方法允许组件独立运作,但通过事件流保持连接 — 这对于不同团队管理堆栈的各个部分的复杂、分布式应用至关重要。
在当今的AI驱动环境中,跨系统访问新鲜实时数据至关重要。EDA作为数据的“中枢神经系统”,使系统在扩展时能够实现无缝集成和灵活性。
Source:
https://dzone.com/articles/build-a-research-assistant-with-kafka-flink