













在数字化转型的时代,企业需要提供可扩展性和可靠性的数据库解决方案。AWS Aurora,一种支持MySQL和PostgreSQL的关系型数据库,已成为寻求高性能、耐用性和成本效益的公司的热门选择。本文深入探讨了AWS Aurora的优势,并提出了一个实际案例,介绍它是如何在一个在线社交媒体平台上使用的。
AWS Aurora比较:优势与挑战
| Key Benefits | Description | Challenges | Description |
|---|---|---|---|
| High Performance and Scalability |
Aurora的设计将存储和计算功能分开,提供比MySQL高五倍、比PostgreSQL高一倍的带宽。它利用自动扩展功能,即使在高峰流量期间也能保证一致的性能。 |
Financial Implications | The complex pricing structure can lead to high costs due to charges for instance, storage, replicas, and support. |
| Durability and Availability | Data in Aurora is distributed across multiple Availability Zones (AZs), with six copies stored across three AZs to ensure data availability and resilience. Failover mechanisms are automated to facilitate durable writes, incorporating retry logic for transactional integrity. | Dependency Risks | A significant dependence on AWS services may lead to vendor lock-in, making it more challenging and costly to migrate to alternative platforms in the future. |
| Security | Aurora offers robust security with encryption for data at rest and in transit, network isolation via Amazon VPC, and precise access control through AWS IAM. | Migration Challenges | Data transfer can be lengthy and may involve downtime. Compatibility issues might require modifications to existing code. |
| Cost Efficiency | Aurora’s flexible pricing structure enables businesses to reduce database costs. The automatic scaling feature guarantees that you are charged based on the actual resources utilized, resulting in a cost-effective solution for varying workloads. | Training Requirements | Teams need to dedicate a significant amount of time and resources to acquiring the necessary knowledge of AWS-specific tools and optimal practices to effectively manage Aurora. |
| Performance Optimization | Auto-scaling and read replicas help optimize performance by dynamically adjusting resources and distributing read traffic. | Performance Impacts | Latency may be introduced due to abstraction layers and networking between Aurora instances and other AWS services, impacting latency-sensitive applications. |
实施步骤
1. 设置Aurora集群
- 访问AWS管理控制台。
- 选择Amazon Aurora,然后选择“创建数据库”。
- 选择合适的引擎(MySQL或PostgreSQL)并配置实例设置。
2. 启用自动扩展
- 为计算和存储配置自动扩展策略。
- 根据流量模式设置扩展的阈值。
3. 配置多AZ部署
- 启用多AZ部署以确保高可用性。
- 为数据保护设置自动备份和快照。
4. 创建只读副本
- 添加只读副本以分发读取流量。
- 配置应用程序端点以在副本之间平衡读取请求。
示例: 在线社交媒体平台
一个在线社交媒体平台“SocialBuzz”连接着全球数百万用户。为了满足其处理高流量、提供低延迟响应和确保数据持久性的需求,SocialBuzz需要一个可靠的数据库解决方案。AWS Aurora是满足这些需求的理想选择:
- 架构概述:SocialBuzz使用Aurora作为其核心数据库需求,利用MySQL和PostgreSQL引擎为不同组件提供支持。用户资料、帖子、评论和互动存储在Aurora中,从中获益于其高性能和可扩展性。
- 可扩展性实例:在高峰使用时段,如病毒式帖子分享时,SocialBuzz会经历流量的激增。Aurora的自动扩展功能调整计算资源以处理增加的工作负载,确保无缝的用户体验,而不会性能下降。
- 高可用性:为确保服务不间断,SocialBuzz将Aurora配置为Multi-AZ设置。即使一个AZ遇到问题,数据库仍然可用,提供了健壮的故障转移机制。Aurora的自动化备份和快照进一步增强了数据保护。
- 性能优化:SocialBuzz在Aurora中实现读取副本,以分配读取流量,减轻主实例的负载。这种设置使得数据检索快速,从而实现实时通知和即时帖子更新等功能。
- 成本管理:通过使用Aurora的按量付费模型,SocialBuzz有效地管理其运营成本。在非高峰时段,资源会缩减,从而降低成本。此外,Aurora的无服务器选项让SocialBuzz能够无需过度配置资源,就能处理不可预测的工作负载。
概览
让我们更深入地了解在线社交媒体平台SocialBuzz如何利用AWS Aurora进行可扩展和可靠的数据库管理。我们将包括一个实现示例代码、一个示例数据集和一个流程图来阐述这个过程。
架构概览
SocialBuzz利用AWS Aurora存储和管理用户资料、帖子、评论和互动。系统架构包括以下要素:
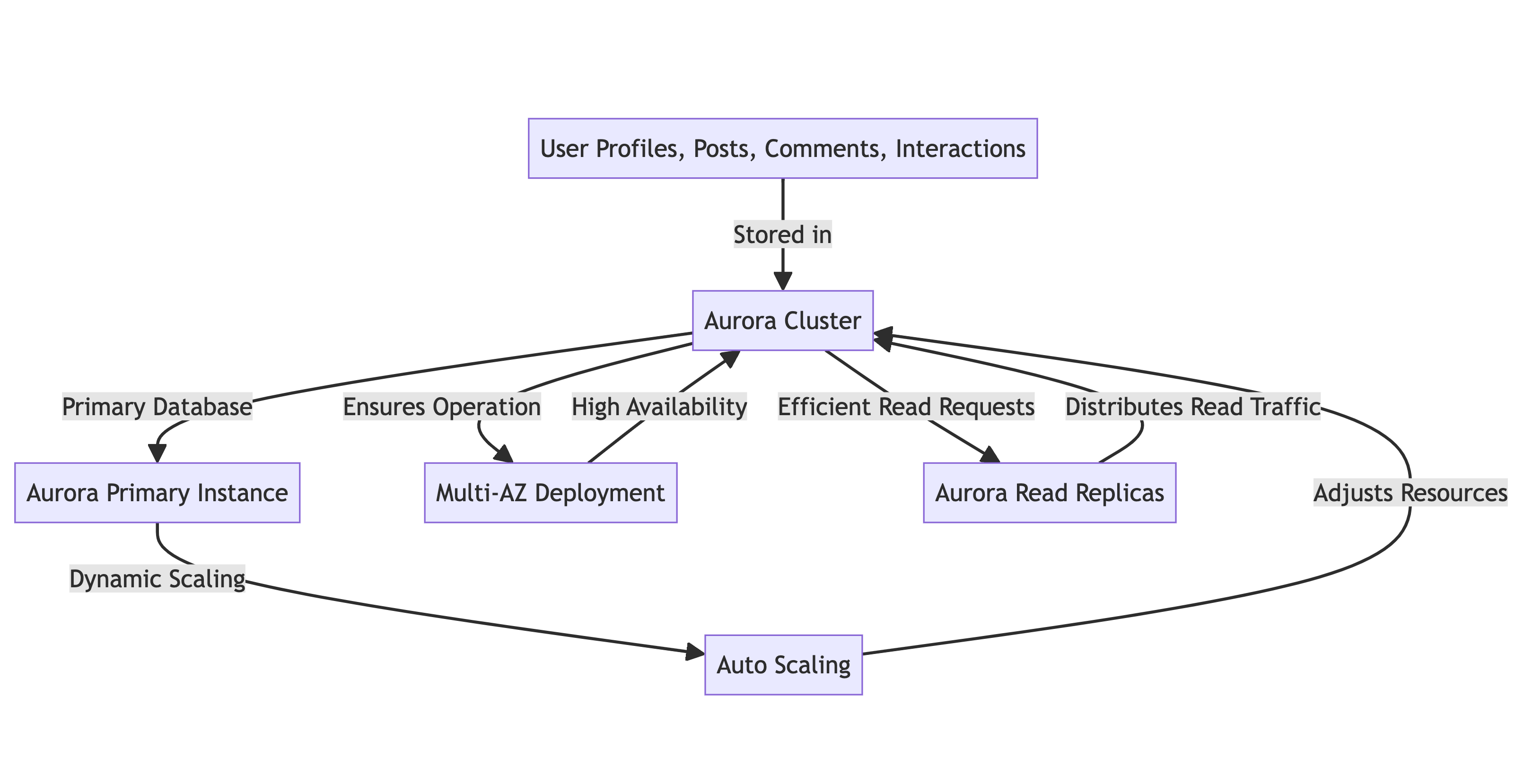
- 主数据库: Aurora集群
- 资源调整: 根据需求动态调整资源的自动扩展功能
- 高可用性: 多AZ部署以确保持续运行
- 读取流量分配: 读取副本以高效分配读取请求
流程图
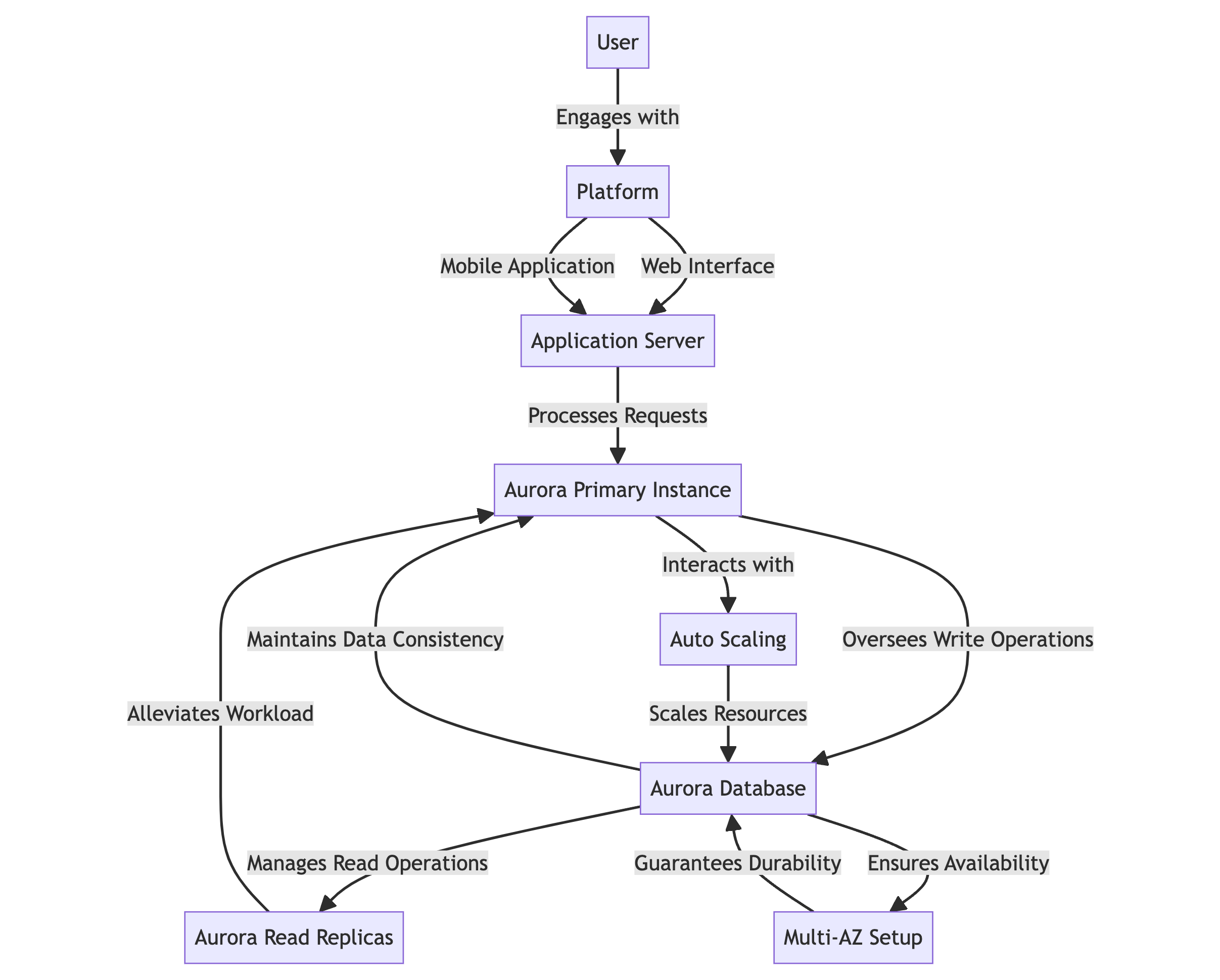
- 用户可以通过网页界面或移动应用程序与平台互动。
- 应用服务器处理请求并与Aurora数据库交互。
- Aurora主实例负责写操作并维护数据一致性。
- Aurora读取副本管理读操作,以减轻主实例的工作量。
- 自动扩展会根据流量的变化自动调整资源。
- 多AZ设置确保在多个可用区域内数据可用性和耐用性。
AWS实例
- 选择标准创建一个Aurora(MySQL)。

- 选择模板、凭据和数据库名称设置。
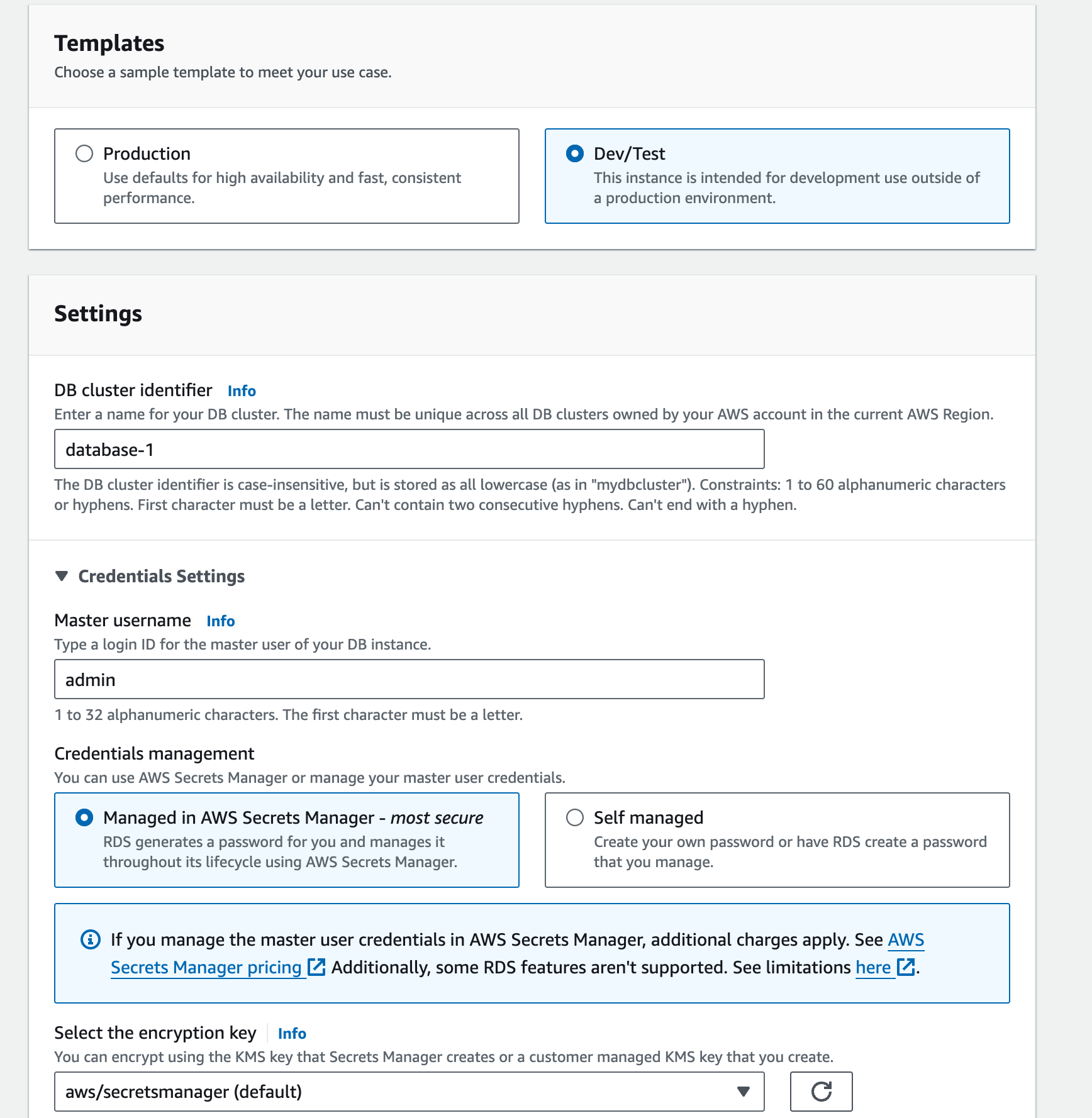
- 实例、可用性和连接配置是重要考虑因素。根据要求,我决定不连接EC2。
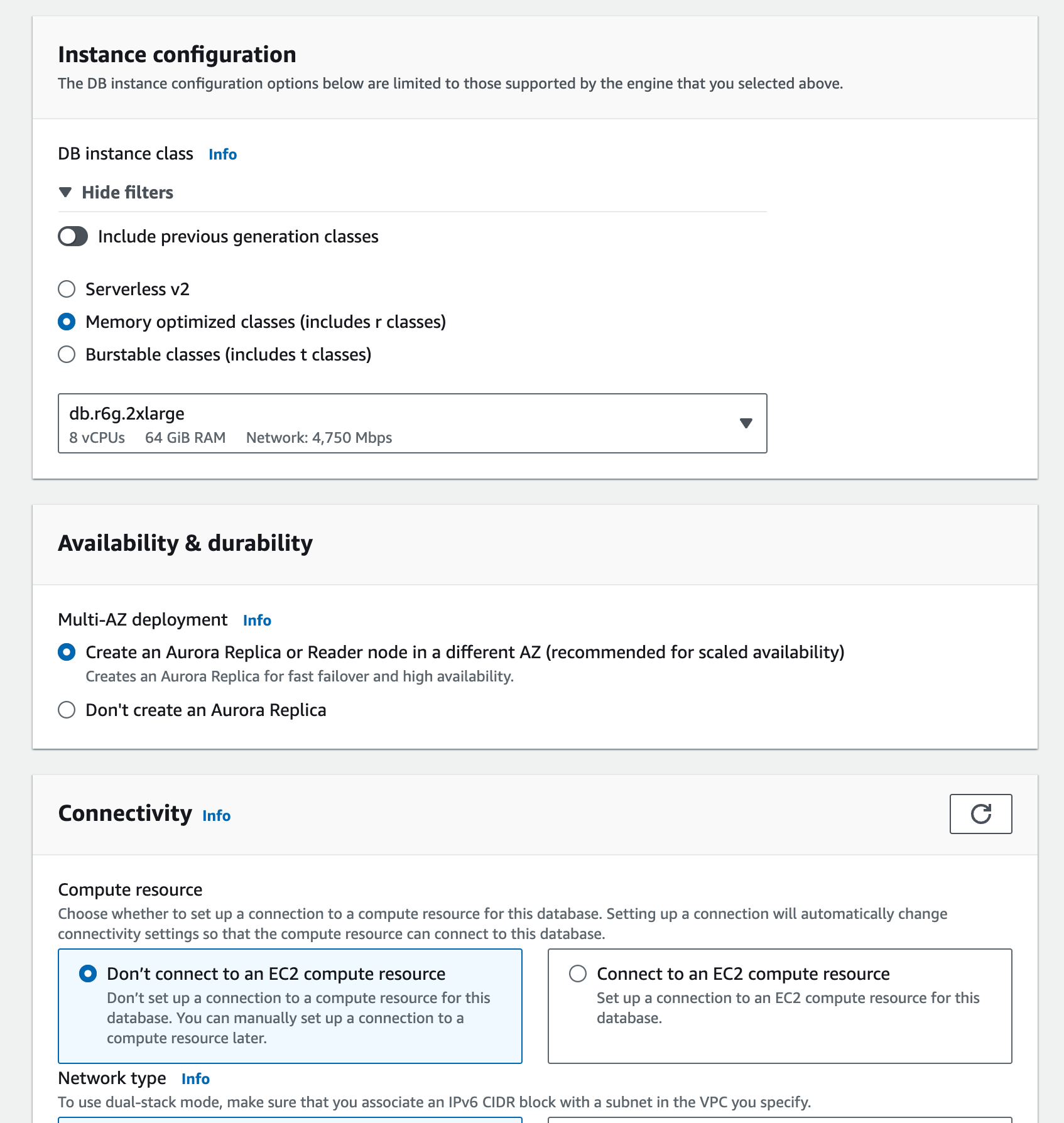
- VPC设置:开启读副本和标签以标识数据库。
- 选择数据库授权和监控,最后你会收到月度数据库成本预估。
代码示例
我们将为SocialBuzz设置Aurora集群。
设置Aurora集群
import boto3
# 使用Amazon RDS初始化一个会话
client = boto3.client('rds', region_name='us-west-2')
创建Aurora数据库集群
response = client.create_db_cluster(
DBClusterIdentifier='socialbuzz-cluster',
Engine='aurora-mysql',
MasterUsername='admin',
MasterUserPassword='password',
BackupRetentionPeriod=7,
VpcSecurityGroupIds=['sg-0a1b2c3d4e5f6g7h'],
DBSubnetGroupName='default'
)
print(response)
创建Aurora实例
response = client.create_db_instance(
DBInstanceIdentifier='socialbuzz-instance',
DBClusterIdentifier='socialbuzz-cluster',
DBInstanceClass='db.r5.large',
Engine='aurora-mysql',
PubliclyAccessible=True
)
print(response)
示例数据集
以下是一个简单的数据集,用于表示用户、帖子和建议:
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE posts (
post_id INT PRIMARY KEY,
user_id INT,
content TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
CREATE TABLE comments (
comment_id INT PRIMARY KEY,
post_id INT,
user_id INT,
comment TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (post_id) REFERENCES posts(post_id),
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
-- 插入示例数据
INSERT INTO users (user_id, username, email) VALUES
(1, 'john_doe', '[email protected]'),
(2, 'jane_doe', '[email protected]');
INSERT INTO posts (post_id, user_id, content) VALUES
(1, 1, 'Hello World!'),
(2, 2, 'This is my first post.');
INSERT INTO comments (comment_id, post_id, user_id, comment) VALUES
(1, 1, 2, 'Nice post!'),
(2, 2, 1, 'Welcome to the platform!');
读写操作的应用逻辑
import pymysql
# 数据库连接
connection = pymysql.connect(
host='socialbuzz-cluster.cluster-xyz.us-west-2.rds.amazonaws.com',
user='admin',
password='password',
database='socialbuzz'
)
# 写操作
def create_post(user_id, content):
with connection.cursor() as cursor:
sql = "INSERT INTO posts (user_id, content) VALUES (%s, %s)"
cursor.execute(sql, (user_id, content))
connection.commit()
# 读操作
def get_posts():
with connection.cursor() as cursor:
sql = "SELECT * FROM posts"
cursor.execute(sql)
result = cursor.fetchall()
for row in result:
print(row)
# 示例使用
create_post(1, 'Exploring AWS Aurora!')
get_posts()
结论
AWS Aurora提供了一个健壮、可扩展和可靠的数据库管理解决方案。社交网站案例研究展示了公司如何利用Aurora的高级功能来管理高流量、确保数据完整性和提高效率。通过遵循推荐的方法并部署适当的基础设施,企业可以充分利用AWS Aurora的功能,促进发展和创新。
Source:
https://dzone.com/articles/aws-aurora-for-scalable-and-reliable-databases