













免责声明: 博客中表达的所有观点和意见均属于作者个人,不一定代表作者的雇主或其他任何团体或个人。本文 纯属 作者个人意见,不是对任何云/数据管理平台的推广。所有图片和代码片段均来自Azure/Databricks网站,并非宣传。
在我的其他DZone文章中,我已经讨论了什么是Databricks Unity Catalog,Unity Catalog中权限模型的工作原理,模式级别,以及自动化管理目录和模式级别权限的脚本。
在本文中,我旨在提供一个脚本,用于自动化管理Unity Catalog表级别的权限。
Unity Catalog表级别权限
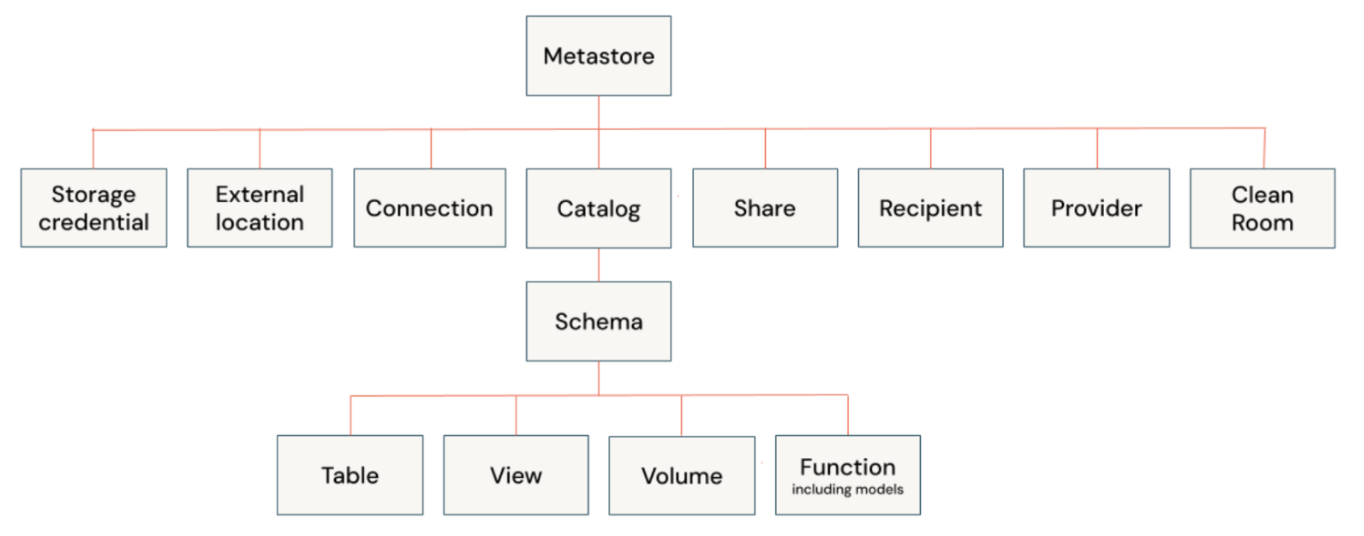
在Unity Catalog(Databricks)中,对表级别应用权限是必要的,当您希望控制对特定表或视图的访问权限,而不是将权限应用于模式中的所有对象时。表级权限在以下情况下非常有用:
1. 细粒度访问控制
当您需要授予或限制对特定表或视图的访问权限,而不影响整个模式时。
这在架构包含敏感数据并且您想允许访问某些表同时限制访问其他表时尤为重要。
2. 保护敏感数据
如果架构中的某些表包含机密或受限数据(例如个人可识别信息、财务数据),您可以应用表级权限,确保只有经授权的用户可以查看或查询这些表。
例如,您可以允许访问某些摘要或汇总数据表,但限制访问包含敏感信息的原始详细表。
3. 将访问权限委派给特定团队/用户,如果架构包含供多个团队使用的表
当不同用户或团队需要访问同一架构中的不同表时。例如,销售团队可能需要访问与客户相关的表,而财务团队需要访问收入表。
在表级应用权限可确保每个团队只能访问与其工作相关的表。
4. 符合数据治理规定
在执行严格的数据治理政策时,您可能需要以更细粒度的方式控制访问(甚至到个别表)。表级权限有助于通过仅授予用户或角色授权处理的数据来确保合规。
5. 处理架构内的混合访问需求
在包含具有不同敏感性或机密级别的表的架构中,对架构级别应用权限可能过于宽泛。表级权限允许您根据特定需求分别管理每个表的访问权限。
可应用于表级别的权限
- SELECT:授予对表的读取权限,允许用户查询它。
- MODIFY:赋予添加、删除和修改数据到对象的能力。
- APPLY TAG:赋予对对象应用标签的能力。
- ALL PRIVILEGES:赋予所有权限。
自动化脚本
先决条件
- Unity Catalog 已设置好。
- 主体与 Databricks 工作区相关联。
- 运行权限脚本的用户在表、架构和目录上具有适当的权限。
步骤 1:创建笔记本并声明变量
在 Databricks 工作区中创建一个笔记本。要在工作区中创建笔记本,请单击边栏中的“+”新建,然后选择笔记本。
工作区中打开一个空白笔记本。确保选择Python作为笔记本语言。
复制并粘贴以下代码片段到笔记本单元格中,并运行单元格。
catalog = 'main' # Specify your catalog name
schema = 'default' # Specify your schema name
tables_arr= 'test1,test2' # Specify the Comma(,) seperated values of table name
tables = tables_arr.split(',')
principals_arr = '' # Specify the Comma(,) seperated values for principals in the blank text section (e.g. groups, username)
principals = principals_arr.split(',')
privileges_arr = 'SELECT,APPLY TAG' # Specify the Comma(,) seperated values for priviledges in the blank text section (e.g. SELECT,APPLY TAG)
privileges = privileges_arr.split(',')
步骤 2: 设置目录和模式
复制、粘贴并运行下面的代码块到一个新的或现有的单元格中,并运行该单元格。
query = f"USE CATALOG `{catalog}`" #Sets the Catalog
spark.sql(query)
query = f"USE SCHEMA `{schema}`" #Sets the Schema
spark.sql(query)
步骤 3: 遍历主体和权限,并在目录、模式和表上应用授权
复制、粘贴并运行下面的代码块到一个新的或现有的单元格中,然后运行该单元格以应用权限。
for principal in principals:
query = f"GRANT USE_CATALOG ON CATALOG `{catalog}` TO `{principal}`" # Use catalog permission at Catalog level
spark.sql(query)
query = f"GRANT USE_SCHEMA ON SCHEMA `{schema}` TO `{principal}`" # Use schema permission at Schema level
spark.sql(query)
for table in tables:
for privilege in privileges:
query = f"GRANT `{privilege}` ON `{table}` TO `{principal}`" # Grant priviledges on the tables to the pricipal
print(query)
spark.sql(query)
验证
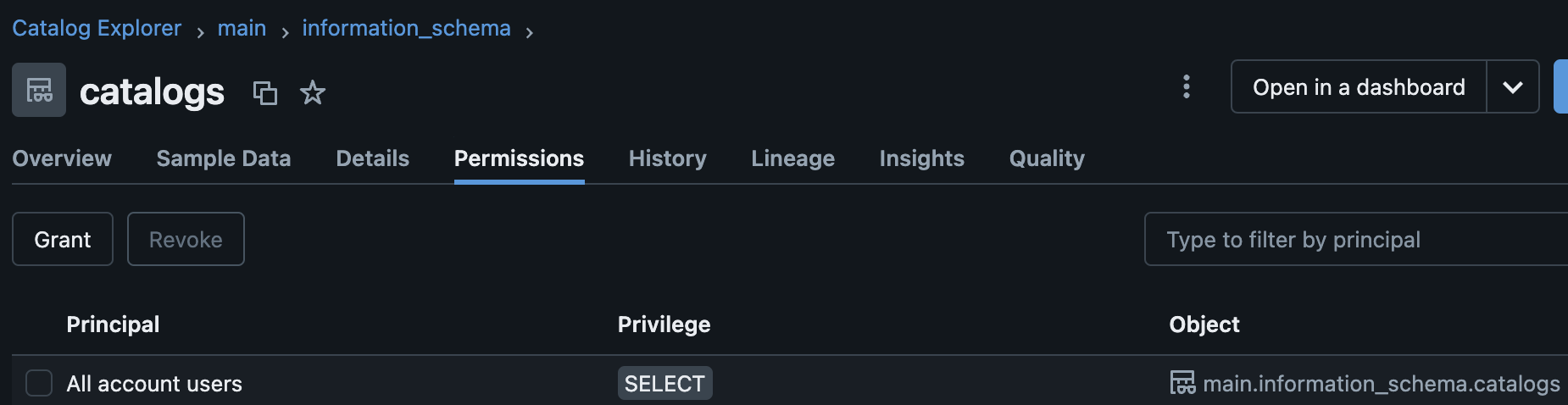
您可以通过打开 Databricks UI 并导航到“目录”中的数据浏览器来验证权限。一旦目录出现在数据部分中,点击目录,然后展开模式并选择应用权限的模式内的表,进入“权限”选项卡。现在你可以看到应用到表上的所有权限。以下是主目录和 information_schema 模式内的开箱即用目录表上应用的权限的截图。
您还可以在笔记本中运行下面的 SQL 脚本来显示作为验证一部分的表的所有权限。
SHOW GRANTS ON TABLE table_name;
结论
在 Databricks Unity Catalog 中对表级别进行特权管理有助于确保在 Unity Catalog 中以一致和高效的方式应用权限。所提供的代码演示了一种实际的方法,可以在单个目录和架构中为多个主体和表分配多个表级别的特权。在一个包含数百张表的目录中,需要为不同的主体提供不同的权限时,上述自动化显著减少了手动错误和工作量。
Source:
https://dzone.com/articles/automate-databricks-unity-catalog-permissions-at-table-level