













В эпоху, характеризующуюся экспоненциальным увеличением генерации данных, организациям необходимо эффективно использовать это богатство информации, чтобы сохранить свое конкурентное преимущество. Эффективный поиск и анализ данных о клиентах — таких как выявление предпочтений пользователей для рекомендаций фильмов или анализ настроений — играют ключевую роль в принятии обоснованных решений и улучшении пользовательского опыта. Например, стриминговый сервис может использовать векторный поиск для рекомендации фильмов, адаптированных к индивидуальным историям просмотров и оценкам, в то время как розничный бренд может анализировать настроения клиентов для уточнения маркетинговых стратегий.
Как инженеры данных, мы отвечаем за внедрение этих сложных решений, обеспечивая, чтобы организации могли извлекать полезные инсайты из огромных объемов данных. Эта статья исследует тонкости векторного поиска с использованием Elasticsearch, сосредотачиваясь на эффективных техниках и лучших практиках для оптимизации производительности. Рассматривая примеры из практики по извлечению изображений для персонализированного маркетинга и текстовому анализу для кластеризации настроений клиентов, мы демонстрируем, как оптимизация векторного поиска может привести к улучшению взаимодействия с клиентами и значительному росту бизнеса.
Что такое векторный поиск?
Поисковый вектор — это мощный метод для определения сходств между данными, представляя их в виде векторов в пространстве высокой размерности. Этот подход особенно полезен для приложений, требующих быстрого извлечения похожих объектов на основе их атрибутов.
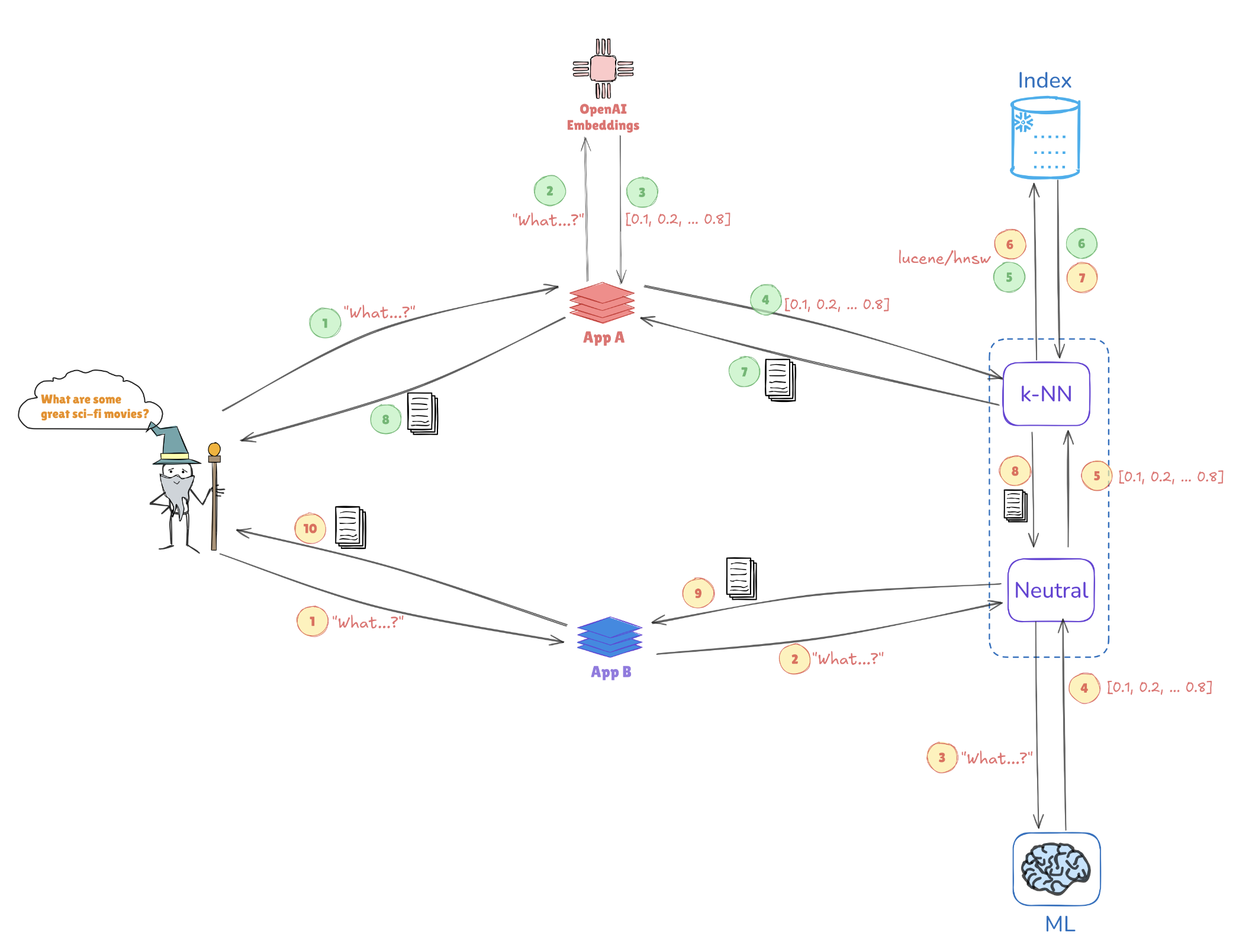
Иллюстрация поиска векторов
Рассмотрим иллюстрацию ниже, которая показывает, как векторные представления позволяют проводить поиск по сходству:
- Векторные представления запроса: Запрос “Какие отличные научно-фантастические фильмы?” преобразуется в векторное представление, например, [0.1, 0.2, …, 0.4].
- Индексация: Этот вектор сравнивается с заранее проиндексированными векторами, хранящимися в Elasticsearch (например, из приложений AppA и AppB), чтобы найти похожие запросы или точки данных.
- Поиск k-NN: С помощью алгоритмов, таких как k-ближайшие соседи (k-NN), Elasticsearch эффективно извлекает лучшие совпадения из проиндексированных векторов, что помогает быстро определить наиболее релевантную информацию.
Этот механизм позволяет Elasticsearch преуспевать в случаях использования, таких как рекомендательные системы, поиск изображений и обработка естественного языка, где понимание контекста и сходства имеет ключевое значение.
Ключевые преимущества поиска векторов с Elasticsearch
Поддержка высокой размерности
Elasticsearch отлично справляется с управлением сложными структурами данных, что является необходимым для приложений ИИ и машинного обучения. Эта способность особенно важна при работе с многофасетными типами данных, такими как изображения или текстовые данные.
Масштабируемость
Его архитектура поддерживает горизонтальное масштабирование, позволяя организациям обрабатывать постоянно растущие наборы данных без ущерба для производительности. Это жизненно важно, поскольку объем данных продолжает расти.
Интеграция
Elasticsearch без проблем работает с Elastic stack, предоставляя комплексное решение для загрузки, анализа и визуализации данных. Эта интеграция гарантирует, что инженеры по данным могут использовать единую платформу для различных задач обработки данных.
Лучшие практики для оптимизации производительности векторного поиска
1. Сокращение размерности векторов
Снижение размерности ваших векторов может значительно улучшить производительность поиска. Техники, такие как PCA (Метод главных компонент) или UMAP (Унифицированное приближение многообразий и проекция), помогают сохранить важные характеристики при упрощении структуры данных.
Пример: Снижение размерности с помощью PCA
Вот как реализовать PCA в Python с использованием Scikit-learn:
from sklearn.decomposition import PCA
import numpy as np
# Sample high-dimensional data
data = np.random.rand(1000, 50) # 1000 samples, 50 features
# Apply PCA to reduce to 10 dimensions
pca = PCA(n_components=10)
reduced_data = pca.fit_transform(data)
print(reduced_data.shape) # Output: (1000, 10)
2. Эффективная индексация
Использование алгоритмов приближенного ближайшего соседа (ANN) может значительно ускорить время поиска. Рассмотрите возможность использования:
- HNSW (Иерархическая навигируемая маленькая вселенная): Известен своим балансом между производительностью и точностью.
- FAISS (Поиск сходства AI от Facebook): Оптимизирован для больших наборов данных и способен использовать ускорение на GPU.
Пример: Реализация HNSW в Elasticsearch
Вы можете определить настройки индекса в Elasticsearch для использования HNSW следующим образом:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.space_type": "l2",
"knn.algo": "hnsw"
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10 // Adjust based on your data
}
}
}
}
3. Пакетные запросы
Для повышения эффективности пакетная обработка нескольких запросов в одном запросе минимизирует накладные расходы. Это особенно полезно для приложений с высоким пользовательским трафиком.
Пример: Пакетная обработка в Elasticsearch
Вы можете использовать конечную точку _msearch для пакетных запросов:
POST /_msearch
{ "index": "my_vector_index" }
{ "query": { "match_all": {} } }
{ "index": "my_vector_index" }
{ "query": { "match": { "category": "sci-fi" } } }
4. Используйте кэширование
Реализуйте стратегии кэширования для часто запрашиваемых запросов, чтобы снизить вычислительную нагрузку и улучшить время отклика.
5. Мониторинг производительности
Регулярный анализ метрик производительности имеет решающее значение для выявления узких мест. Инструменты, такие как Kibana, могут помочь визуализировать эти данные, позволяя вносить обоснованные изменения в конфигурацию вашего Elasticsearch.
Настройка параметров в HNSW для повышения производительности
Оптимизация HNSW включает в себя корректировку определенных параметров для достижения лучшей производительности на больших наборах данных:
M(максимальное количество соединений): Увеличение этого значения улучшает полноту, но может потребовать больше памяти.EfConstruction(размер динамического списка во время построения): Более высокое значение приводит к более точному графу, но может увеличить время индексации.EfSearch(динамический размер списка во время поиска): Настройка этого параметра влияет на компромисс между скоростью и точностью; большее значение обеспечивает лучший охват, но требует больше времени на вычисление.
Пример: Настройка параметров HNSW
Вы можете настроить параметры HNSW при создании индекса следующим образом:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.algo": "hnsw",
"knn.hnsw.m": 16, // More connections
"knn.hnsw.ef_construction": 200, // Higher accuracy
"knn.hnsw.ef_search": 100 // Adjust for search accuracy
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10
}
}
}
}
Кейс: Влияние сокращения размерности на производительность HNSW в приложениях для работы с данными клиентов
Извлечение изображений для персонализированного маркетинга
Методы сокращения размерности играют ключевую роль в оптимизации систем извлечения изображений в приложениях для работы с данными клиентов. В одном исследовании ученые применили метод главных компонент (PCA) для сокращения размерности перед индексированием изображений с помощью иерархических навигационных малых миров (HNSW). PCA обеспечил заметный прирост скорости извлечения — что крайне важно для приложений, обрабатывающих большие объемы данных клиентов — хотя это привело к незначительной потере точности из-за уменьшения информации. Чтобы решить эту проблему, исследователи также изучили метод унифицированной аппроксимации и проекции (UMAP) в качестве альтернативы. UMAP более эффективно сохранял локальные структуры данных, сохраняя сложные детали, необходимые для рекомендаций по персонализированному маркетингу. Хотя UMAP требовал большей вычислительной мощности, чем PCA, он обеспечивал баланс между скоростью поиска и высокой точностью, что делало его жизнеспособным выбором для задач, критичных к точности.
Анализ текста для кластеризации клиентских настроений
В области анализа клиентских настроений другое исследование показало, что UMAP превосходит PCA в кластеризации похожих текстовых данных. UMAP позволил модели HNSW кластеризовать клиентские настроения с более высокой точностью — это преимущество в понимании отзывов клиентов и предоставлении более персонализированных ответов. Использование UMAP способствовало уменьшению значений EfSearch в HNSW, что улучшило скорость и точность поиска. Эта улучшенная эффективность кластеризации позволила быстрее идентифицировать соответствующие клиентские настроения, что усилило целевую маркетинговую деятельность и сегментацию клиентов на основе настроений.
Интеграция автоматизированных методов оптимизации
Оптимизация снижения размерности и параметров HNSW является важной для максимизации производительности систем клиентских данных. Автоматизированные методы оптимизации упрощают этот процесс настройки, обеспечивая эффективные конфигурации для различных приложений:
- Сеточный и случайный поиск: Эти методы предлагают широкий и систематический обзор параметров, эффективно определяя подходящие конфигурации.
- Байесовская оптимизация: Эта техника сосредотачивается на оптимальных параметрах с меньшим числом оценок, экономя вычислительные ресурсы.
- Кросс-валидация: Кросс-валидация помогает проверить параметры на различных наборах данных, обеспечивая их обобщение для различных контекстов клиентских данных.
Решение проблем в автоматизации
Интеграция автоматизации в процессы уменьшения размерности и HNSW может вызвать трудности, особенно в управлении вычислительными требованиями и предотвращении переобучения. Стратегии для преодоления этих проблем включают:
- Снижение вычислительных затрат: Использование параллельной обработки для распределения нагрузки сокращает время оптимизации, повышая эффективность рабочего процесса.
- Модульная интеграция: Модульный подход облегчает бесшовную интеграцию автоматизированных систем в существующие рабочие процессы, снижая сложность.
- Предотвращение переобучения: Надежная проверка через кросс-валидацию гарантирует, что оптимизированные параметры последовательно работают на разных наборах данных, минимизируя переобучение и повышая масштабируемость в приложениях с клиентскими данными.
Заключение
Для полного использования производительности векторного поиска в Elasticsearch важно принять стратегию, которая сочетает уменьшение размерности, эффективное индексирование и продуманную настройку параметров. Интегрируя эти методы, инженеры по данным могут создать высоко отзывчивую и точную систему извлечения данных. Автоматизированные методы оптимизации дополнительно улучшают этот процесс, позволяя постоянно уточнять параметры поиска и стратегии индексирования. Поскольку организации все больше полагаются на оперативные данные из обширных наборов данных, эти оптимизации могут значительно повысить возможности принятия решений, предлагая более быстрые и актуальные результаты поиска. Принятие этого подхода закладывает основу для будущей масштабируемости и улучшенной отзывчивости, aligning поисковые возможности с изменяющимися бизнес-требованиями и ростом данных.
Source:
https://dzone.com/articles/optimizing-vector-search-performance-with-elasticsearch