













При работе с Amazon S3 (Simple Storage Service) вы, вероятно, используете веб-консоль S3 для загрузки, копирования или выгрузки файлов в бакеты S3. Использование консоли вполне допустимо, ведь именно для этого она и предназначена.
Особенно для администраторов, которые привыкли к большему количеству мышиных кликов, чем клавиатурных команд, веб-консоль, вероятно, является самым простым способом. Однако рано или поздно администраторы столкнутся с необходимостью выполнения массовых операций с файлами в Amazon S3, например, неуправляемой загрузки файлов. Графический интерфейс не является лучшим инструментом для этого.
Для автоматизации таких требований с Amazon Web Services, включая Amazon S3, инструмент AWS CLI предоставляет администраторам возможность управления бакетами и объектами Amazon S3 с помощью командной строки.
В этой статье вы узнаете, как использовать инструмент командной строки AWS CLI для загрузки, копирования, загрузки и синхронизации файлов с Amazon S3. Вы также узнаете основы предоставления доступа к вашему бакету S3 и настройки профиля доступа для работы с инструментом AWS CLI.
Предварительные требования
Поскольку это статья-инструкция, в последующих разделах будут приведены примеры и демонстрации. Чтобы успешно следовать инструкции, вам необходимо выполнить несколько требований.
- Учетная запись AWS. Если у вас нет активной подписки AWS, вы можете зарегистрироваться для получения AWS Free Tier.
- Ведро AWS S3. Вы можете использовать существующее ведро, если хотите. Однако рекомендуется создать пустое ведро вместо этого. Пожалуйста, обратитесь к Создание ведра.
- A Windows 10 computer with at least Windows PowerShell 5.1. In this article, PowerShell 7.0.2 will be used.
- На вашем компьютере должен быть установлен инструмент AWS CLI версии 2.
- Локальные папки и файлы, которые вы будете загружать или синхронизировать с Amazon S3
Подготовка доступа к AWS S3
Предположим, что у вас уже есть все необходимые требования. Вы думаете, что теперь уже можете переходить к использованию AWS CLI с вашим ведром S3. Ведь было бы здорово, если бы все было так просто, не так ли?
Для тех, кто только начинает работать с Amazon S3 или AWS в целом, эта секция поможет вам настроить доступ к S3 и настроить профиль AWS CLI.
Полная документация по созданию IAM-пользователя в AWS может быть найдена по ссылке ниже. Создание IAM-пользователя в вашей учетной записи AWS
Создание IAM-пользователя с разрешением доступа к S3
При доступе к AWS с помощью CLI вам потребуется создать одного или нескольких IAM-пользователей с достаточным доступом к ресурсам, с которыми вы собираетесь работать. В этой секции вы создадите IAM-пользователя с доступом к Amazon S3.
Для создания IAM-пользователя с доступом к Amazon S3 сначала вам необходимо войти в консоль AWS IAM. Под группой Управление доступом нажмите на Пользователи. Затем нажмите Добавить пользователя.
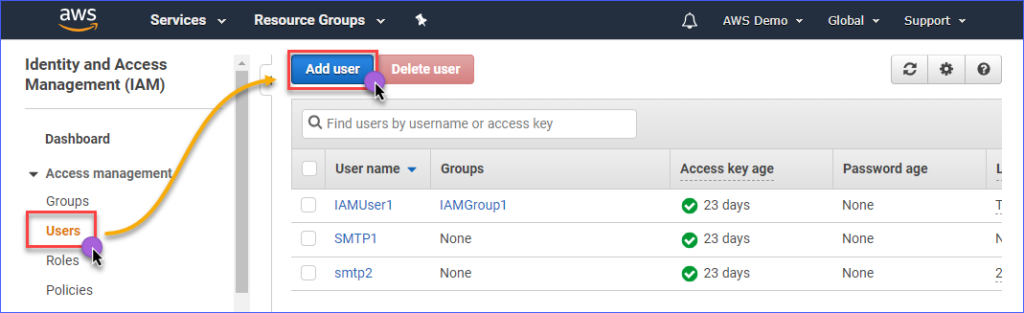
Введите имя IAM-пользователя, которого вы создаете, в поле Имя пользователя*, например, s3Admin. В разделе Тип доступа* отметьте флажок Программный доступ. Затем нажмите кнопку Далее: Разрешения.

Затем нажмите на Присоединить существующие политики непосредственно. Затем найдите политику с именем AmazonS3FullAccess и поставьте галочку. По завершении нажмите Далее: Теги.

Создание тегов является необязательным на странице Добавить теги, и вы можете пропустить этот шаг и нажать кнопку Далее: Ознакомление.
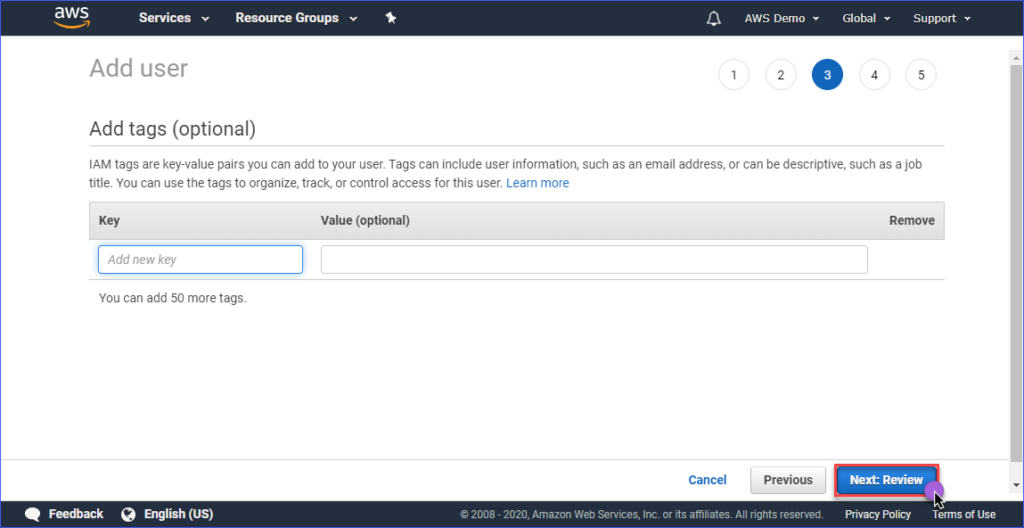
На странице Ознакомление вы увидите сводку о созданной новой учетной записи. Нажмите Создать пользователя.
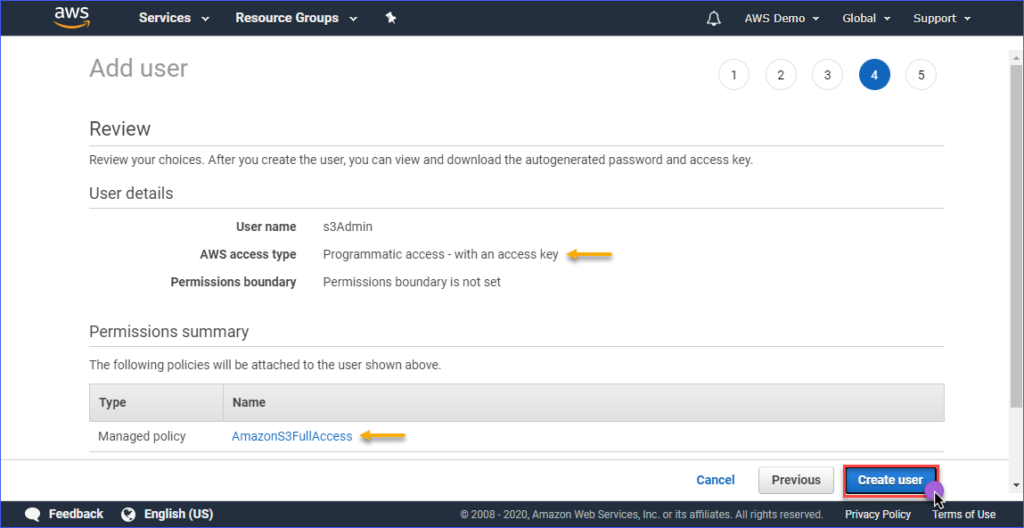
Наконец, после создания пользователя вам необходимо скопировать значения Идентификатор ключа доступа и Секретный ключ доступа и сохранить их для дальнейшего использования. Обратите внимание, что это единственный момент, когда вы можете увидеть эти значения.
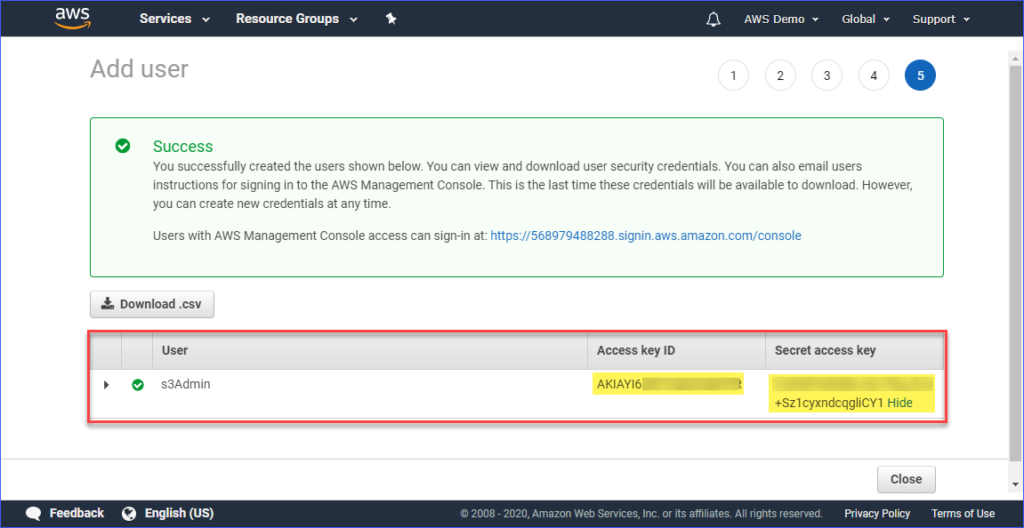
Настройка профиля AWS CLI на вашем компьютере
Теперь, когда вы создали IAM-пользователя с соответствующим доступом к Amazon S3, следующим шагом будет настройка профиля AWS CLI на вашем компьютере.
Этот раздел предполагает, что вы уже установили инструмент AWS CLI версии 2, как требуется. Для создания профиля вам понадобится следующая информация:
- Идентификатор ключа доступа IAM-пользователя.
- Секретный ключ доступа, связанный с IAM-пользователем.
- Имя региона по умолчанию, соответствующее местоположению вашего бакета AWS S3. Вы можете ознакомиться со списком точек доступа, используя эту ссылку. В данной статье бакет AWS S3 находится в регионе Азиатско-Тихоокеанский регион (Сидней), и соответствующей точкой доступа является ap-southeast-2.
- Формат вывода по умолчанию. Используйте JSON для этого.
Для создания профиля откройте PowerShell и введите следующую команду, следуя инструкциям.
Введите идентификатор ключа доступа, секретный ключ доступа, имя региона по умолчанию и имя вывода по умолчанию. См. демонстрацию ниже.

Проверка доступа к AWS CLI
После настройки профиля AWS CLI вы можете подтвердить, что профиль работает, запустив следующую команду в PowerShell.
Выполнение указанной выше команды должно отобразить список бакетов Amazon S3 в вашей учетной записи. Ниже приведена демонстрация этой команды. Результат показывает, что список доступных бакетов S3 указывает на успешную конфигурацию профиля.

Чтобы узнать о командах AWS CLI, специфичных для Amazon S3, вы можете посетить страницу Справочник команд AWS CLI S3.
Управление файлами в S3
С помощью AWS CLI можно выполнять типичные операции по управлению файлами, такие как загрузка файлов в S3, загрузка файлов из S3, удаление объектов в S3 и копирование объектов S3 в другое место в S3. Всё это сводится к знанию правильной команды, синтаксиса, параметров и опций.
В следующих разделах используется следующая среда.
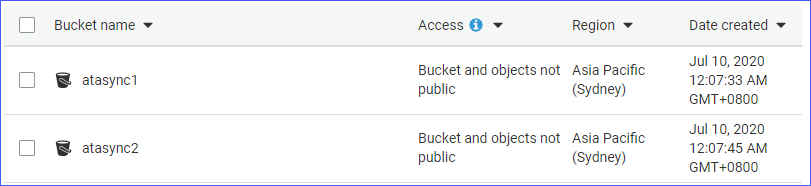
- Два бакета S3, а именно atasync1и atasync2. Скриншот ниже показывает существующие бакеты S3 в консоли Amazon S3.
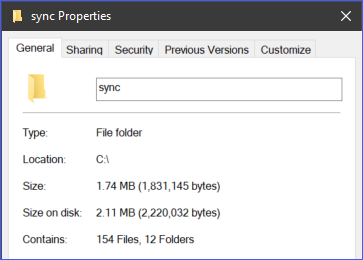
- Локальный каталог и файлы, расположенные в c:\sync.

Загрузка отдельных файлов в S3
Когда вы загружаете файлы в S3, вы можете загружать один файл за раз или загружать несколько файлов и папок рекурсивно. В зависимости от ваших требований, вы можете выбрать один из них, который считаете наиболее подходящим.
Чтобы загрузить файл в S3, вам нужно указать два аргумента (исходное и целевое местоположение) в команде aws s3 cp.
Например, чтобы загрузить файл c:\sync\logs\log1.xml в корень бакета atasync1, вы можете использовать следующую команду.
Примечание: имена бакетов S3 всегда имеют префикс S3:// при использовании AWS CLI
Запустите вышеуказанную команду в PowerShell, но сначала измените источник и назначение в соответствии с вашим окружением. Выходные данные должны выглядеть примерно так:

Вышеуказанная демонстрация показывает, что файл с именем c:\sync\logs\log1.xml был успешно загружен на S3-назначение s3://atasync1/ без ошибок.
Используйте следующую команду для перечисления объектов в корне ведра S3.
Запуск вышеуказанной команды в PowerShell приведет к аналогичному результату, как показано в демонстрации ниже. Как видно из вывода ниже, файл log1.xml присутствует в корне места нахождения S3.

Загрузка нескольких файлов и папок в S3 рекурсивно
Предыдущий раздел показал вам, как скопировать один файл в место нахождения S3. Что, если вам нужно загрузить несколько файлов из папки и подпапок? Наверняка вы не захотите запускать одну и ту же команду несколько раз для разных имен файлов, верно?
Команда aws s3 cp имеет опцию для обработки файлов и папок рекурсивно, и это опция --recursive.
В качестве примера, директория c:\sync содержит 166 объектов (файлов и подпапок).
Используя опцию --recursive, все содержимое папки c:\sync будет загружено на S3 с сохранением структуры папок. Чтобы протестировать, используйте приведенный ниже пример кода, но убедитесь, что измените источник и назначение в соответствии с вашим окружением.
Вы заметите из приведенного ниже кода, что источник находится в c:\sync, а назначение – s3://atasync1/sync. Ключ /sync, следующий за именем ведра S3, указывает AWS CLI загрузить файлы из папки /sync в S3. Если папка /sync не существует в S3, она будет автоматически создана.
Приведенный выше код приведет к следующему выводу, как показано в демонстрации ниже.

Загрузка нескольких файлов и папок в S3 выборочно
В некоторых случаях загрузка ВСЕХ типов файлов не является лучшим вариантом. Например, когда вам нужно загрузить только файлы с определенными расширениями (например, *.ps1). Еще два варианта, доступных для команды cp, это --include и --exclude.
При использовании команды из предыдущего раздела будут включены все файлы при рекурсивной загрузке, но команда ниже будет включать только файлы, соответствующие расширению файла *.ps1 и исключать все остальные файлы из загрузки.
Ниже показано, как работает приведенный выше код при выполнении.

Другой пример – если вы хотите включить несколько разных расширений файлов, вам нужно будет указать опцию --include несколько раз.
Приведенная ниже команда будет включать только файлы *.csv и *.png в команду копирования.
Если вы запустите приведенный выше код в PowerShell, вы получите аналогичный результат, как показано ниже.

Загрузка объектов из S3
Исходя из приведенных в этом разделе примеров, вы также можете выполнять операции копирования в обратном порядке. Это означает, что вы можете загружать объекты из местоположения ведра S3 на локальную машину.
Для копирования из S3 на локальную машину необходимо поменять местами источник и место назначения. Источником является расположение S3, а местом назначения является локальный путь, как показано ниже.
Обратите внимание, что те же параметры, используемые при загрузке файлов в S3, также применимы при загрузке объектов из S3 на локальную машину. Например, загрузка всех объектов с использованием следующей команды с параметром --recursive.
Копирование объектов между местоположениями S3
Помимо загрузки и загрузки файлов и папок с использованием AWS CLI, вы также можете копировать или перемещать файлы между двумя расположениями ведра S3.
Обратите внимание, что команда ниже использует одно местоположение S3 в качестве источника и другое местоположение S3 в качестве места назначения.
В приведенном ниже примере демонстрируется копирование исходного файла в другое местоположение S3 с использованием указанной команды.

Синхронизация файлов и папок с S3
Вы уже узнали, как загружать, скачивать и копировать файлы в S3 с помощью команд AWS CLI. В этом разделе вы узнаете о еще одной команде для работы с файлами, доступной в AWS CLI для S3, это команда sync. Команда sync обрабатывает только обновленные, новые и удаленные файлы.
Есть случаи, когда вам нужно поддерживать актуальность и синхронизацию содержимого хранилища S3 с локальным каталогом на сервере. Например, вам может потребоваться поддерживать синхронизацию журналов транзакций на сервере с хранилищем S3 с определенной периодичностью.
С помощью следующей команды, файлы журналов с расширением *.XML, расположенные в папке c:\sync на локальном сервере, будут синхронизированы с расположением S3 s3://atasync1.
Приведенная ниже демонстрация показывает, что после выполнения вышеуказанной команды в PowerShell все файлы с расширением *.XML были загружены в S3-назначение s3://atasync1/.

Синхронизация новых и обновленных файлов с S3
В следующем примере предполагается, что содержимое файла журнала Log1.xml было изменено. Команда sync должна обнаружить это изменение и загрузить изменения, внесенные в локальный файл, в S3, как показано на демонстрации ниже.
Команда для использования остается такой же, как и в предыдущем примере.

Как видно из вывода выше, так как локально был изменен только файл Log1.xml, он является единственным файлом, синхронизированным с S3.
Синхронизация удалений с S3
По умолчанию команда sync не обрабатывает удаления. Любой файл, удаленный из исходного расположения, не удаляется в пункте назначения. Но это можно изменить с помощью опции --delete.
В следующем примере файл с именем Log5.xml был удален из исходного расположения. Команда для синхронизации файлов будет дополнена опцией --delete, как показано в коде ниже.
При выполнении вышеуказанной команды в PowerShell также должен быть удален файл с именем Log5.xml в месте назначения S3. Пример результата показан ниже.

Резюме
Amazon S3 – отличный ресурс для хранения файлов в облаке. С помощью инструмента AWS CLI расширяются возможности использования Amazon S3 и открывается возможность автоматизации процессов.
В этой статье вы узнали, как использовать инструмент AWS CLI для загрузки, загрузки и синхронизации файлов и папок между локальными местоположениями и корзинами S3. Вы также узнали, что содержимое корзин S3 также можно копировать или перемещать в другие местоположения S3.
Существует множество других сценариев использования инструмента AWS CLI для автоматизации управления файлами с помощью Amazon S3. Вы даже можете попробовать объединить его с сценариями PowerShell и создать свои собственные инструменты или модули, которые можно повторно использовать. Вам предоставляется возможность найти такие возможности и продемонстрировать свои навыки.