













Whisper AI – это передовая модель автоматического распознавания речи (ASR), разработанная OpenAI, которая может транскрибировать аудио в текст с впечатляющей точностью и поддерживает несколько языков. Хотя Whisper AI в первую очередь предназначен для пакетной обработки, его можно настроить для реального транскрибирования речи в текст в реальном времени на Linux.
В этом руководстве мы рассмотрим пошаговый процесс установки, настройки и запуска Whisper AI для живой транскрипции на системе Linux.
Что такое Whisper AI?
Whisper AI – это модель распознавания речи с открытым исходным кодом, обученная на огромном наборе аудиозаписей, и основанная на архитектуре глубокого обучения, что позволяет ей:
- Транскрибировать речь на нескольких языках.
- Эффективно обрабатывать акценты и фоновой шум.
- Выполнять перевод устной речи на английский язык.
Поскольку он разработан для высокоточной транскрипции, его широко используют в:
- Службах живой транскрипции (например, для доступности).
- Голосовых помощниках и автоматизации.
- Транскрибировании записанных аудиофайлов.
По умолчанию Whisper AI не оптимизирован для обработки в реальном времени. Однако с помощью дополнительных инструментов он может обрабатывать потоковое аудио в режиме реального времени для мгновенной транскрипции.
Требования к системе Whisper AI
Перед запуском Whisper AI на Linux убедитесь, что ваша система соответствует следующим требованиям:
Аппаратные требования:
- ЦП: Многоядерный процессор (Intel/AMD).
- ОЗУ: Как минимум 8 ГБ (рекомендуется 16 ГБ или более).
- Графический процессор (GPU): NVIDIA GPU с CUDA (необязательно, но значительно ускоряет обработку).
- Хранилище: Минимум 10 ГБ свободного места на диске для моделей и зависимостей.
Требования к программному обеспечению:
- Дистрибутив Linux, такой как Ubuntu, Debian, Arch, Fedora и т. д.
- Python версии 3.8 или выше.
- Менеджер пакетов Pip для установки пакетов Python.
- FFmpeg для обработки аудиофайлов и потоков.
Шаг 1: Установка необходимых зависимостей
Перед установкой Whisper AI обновите свой список пакетов и обновите существующие пакеты.
sudo apt update [On Ubuntu] sudo dnf update -y [On Fedora] sudo pacman -Syu [On Arch]
Затем вам необходимо установить Python 3.8 или более новую версию и менеджер пакетов Pip, как показано ниже.
sudo apt install python3 python3-pip python3-venv -y [On Ubuntu] sudo dnf install python3 python3-pip python3-virtualenv -y [On Fedora] sudo pacman -S python python-pip python-virtualenv [On Arch]
Наконец, вам нужно установить FFmpeg, который является мультимедийным фреймворком, используемым для обработки аудио- и видеофайлов.
sudo apt install ffmpeg [On Ubuntu] sudo dnf install ffmpeg [On Fedora] sudo pacman -S ffmpeg [On Arch]
Шаг 2: Установка Whisper AI в Linux
После установки необходимых зависимостей вы можете приступить к установке Whisper AI в виртуальной среде, которая позволяет устанавливать пакеты Python, не затрагивая системные пакеты.
python3 -m venv whisper_env source whisper_env/bin/activate pip install openai-whisper
После завершения установки проверьте, правильно ли установился Whisper AI, запустив.
whisper --help
Это должно отобразить меню помощи с доступными командами и опциями, что означает, что Whisper AI установлен и готов к использованию.
Шаг 3: Запуск Whisper AI в Linux
После установки Whisper AI вы можете начать транскрибировать аудиофайлы, используя различные команды.
Транскрибирование аудиофайла
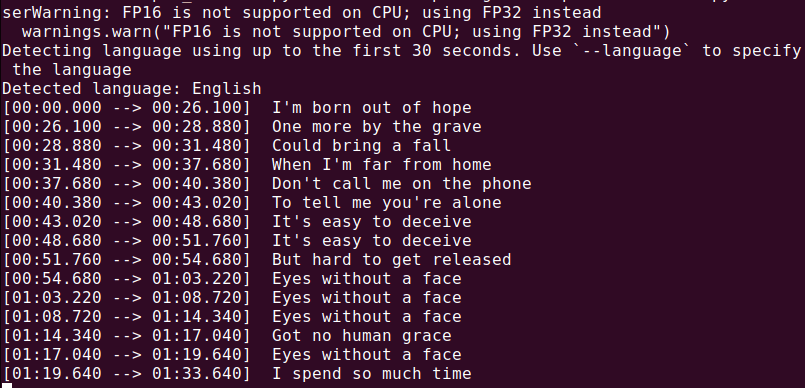
Чтобы транскрибировать аудиофайл (audio.mp3), выполните:
whisper audio.mp3
Whisper обработает файл и сгенерирует текстовый транскрипт.
Теперь, когда все установлено, давайте создадим скрипт на Python для захвата аудио с вашего микрофона и его транскрибирования в реальном времени.
nano real_time_transcription.py
Скопируйте и вставьте следующий код в файл.
import sounddevice as sd
import numpy as np
import whisper
import queue
import threading
# Load the Whisper model
model = whisper.load_model("base")
# Audio parameters
SAMPLE_RATE = 16000
BUFFER_SIZE = 1024
audio_queue = queue.Queue()
def audio_callback(indata, frames, time, status):
"""Callback function to capture audio data."""
if status:
print(status)
audio_queue.put(indata.copy())
def transcribe_audio():
"""Thread to transcribe audio in real time."""
while True:
audio_data = audio_queue.get()
audio_data = np.concatenate(list(audio_queue.queue)) # Combine buffered audio
audio_queue.queue.clear()
# Transcribe the audio
result = model.transcribe(audio_data.flatten(), language="en")
print(f"Transcription: {result['text']}")
# Start the transcription thread
transcription_thread = threading.Thread(target=transcribe_audio, daemon=True)
transcription_thread.start()
# Start capturing audio from the microphone
with sd.InputStream(callback=audio_callback, channels=1, samplerate=SAMPLE_RATE, blocksize=BUFFER_SIZE):
print("Listening... Press Ctrl+C to stop.")
try:
while True:
pass
except KeyboardInterrupt:
print("\nStopping...")
Запустите скрипт с помощью Python, который начнет прослушивание вашего микрофонного ввода и отображение транскрибированного текста в реальном времени. Говорите четко в микрофон, и вы должны увидеть результаты, напечатанные в терминале.
python3 real_time_transcription.py
Заключение
Whisper AI — мощный инструмент преобразования речи в текст, который можно адаптировать для транскрибирования в реальном времени на Linux. Для достижения наилучших результатов используйте GPU и оптимизируйте вашу систему для обработки в реальном времени.
Source:
https://www.tecmint.com/whisper-ai-audio-transcription-on-linux/