













VAR-As-A-Service представляет собой MLOps подход к унификации и повторному использованию статистических моделей и конвейеров развертывания моделей машинного обучения. Это второй из серии статей, основанных на данном проекте, демонстрирующих эксперименты с различными статистическими и машинными моделями, данными конвейерами, реализованными с использованием существующих DAG инструментов, и решениями для хранения данных, как облачными, так и альтернативными локальными вариантами. В данной статье основное внимание уделяется хранению файлов моделей с использованием подхода, также применимого и используемого для машинных моделей обучения. Реализованное хранилище основано на MinIO как на совместимом с AWS S3 сервисе объектного хранения. Кроме того, статья дает обзор альтернативных решений для хранения и очерчивает преимущества объектного хранения.
Первая статья серии (Анализ временных рядов: VARMAX-As-A-Service) сравнивает статистические и машинные модели как математические модели и предоставляет полное описание реализации статистической модели на основе VARMAX для макроэкономического прогнозирования с использованием библиотеки Python под названием statsmodels. Модель развертывается как REST-сервис с использованием Python Flask и веб-сервера Apache, упакованная в контейнер Docker. Высокоуровневая архитектура приложения представлена на следующем изображении:
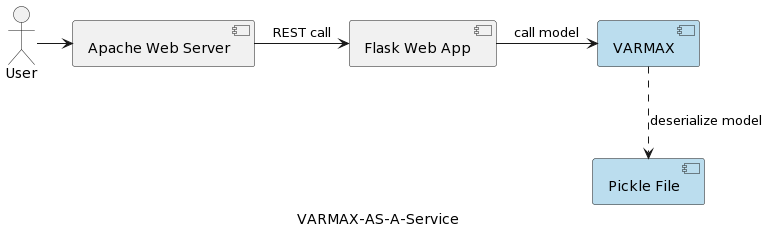
Модель сериализуется в виде файла pickle и развертывается на веб-сервере в качестве части пакета REST-сервиса. Однако на практических проектах модели должны быть пронумерованы, сопровождаться метаданными и защищены, а эксперименты по обучению должны быть зафиксированы и сохранены воспроизводимыми. Более того, с архитектурной точки зрения, хранение модели в файловой системе рядом с приложением противоречит принципу единой ответственности. Хорошим примером является архитектура на основе микросервисов. Горизонтальное масштабирование сервиса модели означает, что каждый экземпляр микросервиса будет иметь свою собственную версию физического файла pickle, копируемую на все экземпляры сервиса. Это также означает, что поддержка нескольких версий моделей потребует нового выпуска и повторного развертывания REST-сервиса и его инфраструктуры. Цель этой статьи – развязать модели от инфраструктуры веб-сервиса и позволить повторно использовать логику веб-сервиса с различными версиями моделей.
Перед тем как погрузиться в реализацию, давайте скажем несколько слов о статистических моделях и модели VAR, используемой в этом проекте. Статистические модели являются математическими моделями, как и модели машинного обучения. Более подробную информацию о различии между ними можно найти в первой статье серии. Статистическая модель обычно определяется как математическая зависимость между одной или несколькими случайными переменными и другими неслучайными переменными. Векторная авторегрессия (VAR) — это статистическая модель, используемая для описания взаимосвязи между несколькими величинами, изменяющимися во времени. Модели VAR обобщают одномерную авторегрессионную модель (AR), позволяя работать с многомерными временными рядами. В представленном проекте модель обучается для прогнозирования двух переменных. Модели VAR часто используются в экономике и естественных науках. В общем случае модель представлена системой уравнений, которая в проекте скрыта за библиотекой Python statsmodels.
Архитектура приложения сервиса модели VAR показана на следующем изображении.
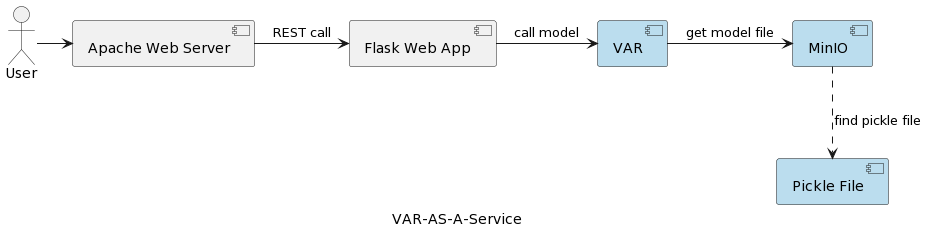
Компонент выполнения VAR представляет фактическое выполнение модели на основе параметров, отправленных пользователем. Он подключается к сервису MinIO через интерфейс REST, загружает модель и выполняет предсказание. В отличие от решения в первой статье, где модель VARMAX загружается и десериализуется при запуске приложения, модель VAR читается с сервера MinIO каждый раз при запуске предсказания. Это требует дополнительного времени для загрузки и десериализации, но также обеспечивает наличие последней версии развернутой модели при каждом запуске. Более того, это позволяет динамически управлять версиями моделей, делая их автоматически доступными для внешних систем и конечных пользователей, как будет показано далее в статье. Следует отметить, что из-за накладных расходов на загрузку, производительность выбранного хранилища данных имеет большое значение.
Но почему именно MinIO и объектное хранилище в целом?
MinIO представляет собой высокопроизводительное решение для хранения объектов с естественной поддержкой развертываний в Kubernetes, предлагающее совместимый с Amazon Web Services S3 API и поддержку всех основных функций S3. В представленном проекте MinIO работает в режиме Standalone, состоящем из одного сервера MinIO и одного диска или хранилища на Linux с использованием Docker Compose. Для расширенных разработок или производственных сред доступен распределенный режим, описанный в статье Deploy MinIO in Distributed Mode.
Давайте кратко рассмотрим некоторые альтернативы хранения, в то время как подробное описание можно найти здесь и здесь:
- Местное/распределенное файловое хранилище: Местное файловое хранилище представляет собой решение, реализованное в первой статье, так как это самый простой вариант. Вычисления и хранение данных находятся на одной системе. Это приемлемо на этапе PoC или для очень простых моделей, поддерживающих единственную версию модели. Местные файловые системы имеют ограниченную емкость хранения и не подходят для больших наборов данных, если мы хотим хранить дополнительные метаданные, такие как обучающий набор данных. Поскольку нет репликации или автомасштабирования, местная файловая система не может функционировать в доступной, надежной и масштабируемой манере. Каждый развернутый сервис для горизонтального масштабирования развертывается со своей копией модели. Кроме того, локальное хранилище столь же безопасно, насколько безопасна хост-система. Альтернативами местному файловому хранению являются NAS (Network-attached storage), SAN (Storage-area network), распределенные файловые системы (Hadoop Distributed File System (HDFS), Google File System (GFS), Amazon Elastic File System (EFS) и Azure Files). По сравнению с локальной файловой системой, эти решения характеризуются доступностью, масштабируемостью и устойчивостью, но сопряжены с увеличением сложности.
- Реляционные базы данных: Благодаря двоичной сериализации моделей, реляционные базы данных предоставляют возможность хранения моделей в виде blob или двоичных данных в столбцах таблиц. Программисты и многие специалисты по данным знакомы с реляционными базами данных, что делает это решение простым. Версии моделей могут храниться как отдельные строки таблицы с дополнительными метаданными, которые также легко читать из базы данных. Недостатком является то, что база данных потребует больше места для хранения, и это повлияет на резервное копирование. Наличие большого количества двоичных данных в базе данных также может повлиять на производительность. Кроме того, реляционные базы данных накладывают некоторые ограничения на структуры данных, что может усложнить хранение гетерогенных данных, таких как CSV-файлы, изображения и JSON-файлы в качестве метаданных моделей.
- Хранение объектов: Хранение объектов существует уже некоторое время, но революционизировалось, когда Amazon сделал его первым сервисом AWS в 2006 году с Simple Storage Service (S3). Современное хранение объектов является естественным для облака, и другие облачные сервисы вскоре также выпустили свои предложения. Microsoft предлагает Azure Blob Storage, а Google предоставляет свой сервис Google Cloud Storage. API S3 является де-факто стандартом для разработчиков, взаимодействующих с хранилищем в облаке, и существует множество компаний, предлагающих совместимое с S3 хранилище для публичного облака, частного облака и частных локальных решений. Независимо от того, где находится хранилище объектов, оно доступно через интерфейс RESTful. Хотя хранение объектов устраняет необходимость в директориях, папках и других сложных иерархических организациях, это не лучшее решение для динамических данных, которые постоянно меняются, так как для изменения объекта потребуется переписать весь объект, но это хороший выбор для хранения сериализованных моделей и метаданных моделей.
A summary of the main benefits of object storage are:
- Масштабируемость: Размер хранилища объектов практически неограничен, поэтому данные могут масштабироваться до экзабайт, просто добавляя новые устройства. Решения по хранению объектов также работают лучше всего, когда функционируют как распределенный кластер.
- Уменьшенная сложность: Данные хранятся в плоской структуре. Отсутствие сложных деревьев или разделов (нет папок или директорий) упрощает извлечение файлов, так как не нужно знать точное расположение.
- Поисковая доступность: Метаданные являются частью объектов, что упрощает поиск и навигацию без необходимости использования отдельного приложения. Можно помечать объекты атрибутами и информацией, такой как потребление, стоимость и политики автоматического удаления, хранения и тарификации. Благодаря плоскому адресному пространству базового хранилища (каждый объект находится только в одном бакете и нет бакетов внутри бакетов), объектные хранилища могут быстро найти объект среди потенциально миллиардов объектов.
- Устойчивость: Объектное хранилище может автоматически реплицировать данные и хранить их на нескольких устройствах и в разных географических местах. Это может помочь защитить от сбоев, обезопасить от потери данных и помочь поддерживать стратегии аварийного восстановления.
- Простота: Использование REST API для хранения и извлечения моделей подразумевает практически отсутствие кривой обучения и делает интеграцию в архитектурах на основе микросервисов естественным выбором.
Пришло время рассмотреть реализацию модели VAR в качестве сервиса и интеграцию с MinIO. Развертывание представленного решения упрощается за счет использования Docker и Docker Compose. Организация всего проекта выглядит следующим образом:

Как и в первой статье, подготовка модели состоит из нескольких шагов, записанных в скрипте Python под названием var_model.py, расположенном в специальном репозитории GitHub:
- Загрузка данных
- Разделение данных на обучающий и тестовый наборы
- Подготовка эндогенных переменных
- Поиск оптимального параметра модели p (первые p лагов каждой переменной используются в качестве предикторов регрессии)
- Создание экземпляра модели с идентифицированными оптимальными параметрами
- Сериализация созданного экземпляра модели в файл pickle
- Хранение файла pickle в качестве версионированного объекта в бакете MinIO
Эти шаги также можно реализовать как задачи в движке рабочих процессов (например, Apache Airflow), которые запускаются при необходимости обучения новой версии модели с более свежими данными. DAG и их применение в MLOps будут предметом другой статьи.
Последний шаг, реализованный в var_model.py, заключается в хранении сериализованной модели в виде файла pickle в бакете S3. Из-за плоской структуры хранилища объектов используется формат:
<имя бакета>/<имя файла>
Однако для имен файлов допускается использование прямой черты для имитации иерархической структуры, сохраняя при этом преимущество быстрого линейного поиска. Соглашение о хранении моделей VAR следующее:
models/var/0_0_1/model.pkl
Где имя бакета – models, а имя файла – var/0_0_1/model.pkl и в интерфейсе MinIO выглядит следующим образом:

Это очень удобный способ структурирования различных типов моделей и версий моделей, сохраняя при этом производительность и простоту плоского хранения файлов.
Обратите внимание, что управление версиями модели реализовано как часть имени модели. MinIO также предоставляет управление версиями файлов, но выбранный здесь подход имеет некоторые преимущества:
- Поддержка снимков версий и переопределения
- Использование семантического управления версиями (точки заменены на ‘_’ из-за ограничений)
- Больший контроль над стратегией управления версиями
- Развязывание механизма базового хранения в плане конкретных функций управления версиями
Как только модель развернута, пришло время предоставлять ее как REST-службу с использованием Flask и развертывать ее с помощью docker-compose, запуская MinIO и веб-сервер Apache. Docker-образ, а также код модели можно найти на специальном репозитории GitHub.
И, наконец, шаги, необходимые для запуска приложения:
- Развернуть приложение:
docker-compose up -d - Выполнить алгоритм подготовки модели:
python var_model.py(требуется работающий сервис MinIO) - Проверить, была ли развернута модель: http://127.0.0.1:9101/browser
- Протестировать модель:
http://127.0.0.1:80/apidocs
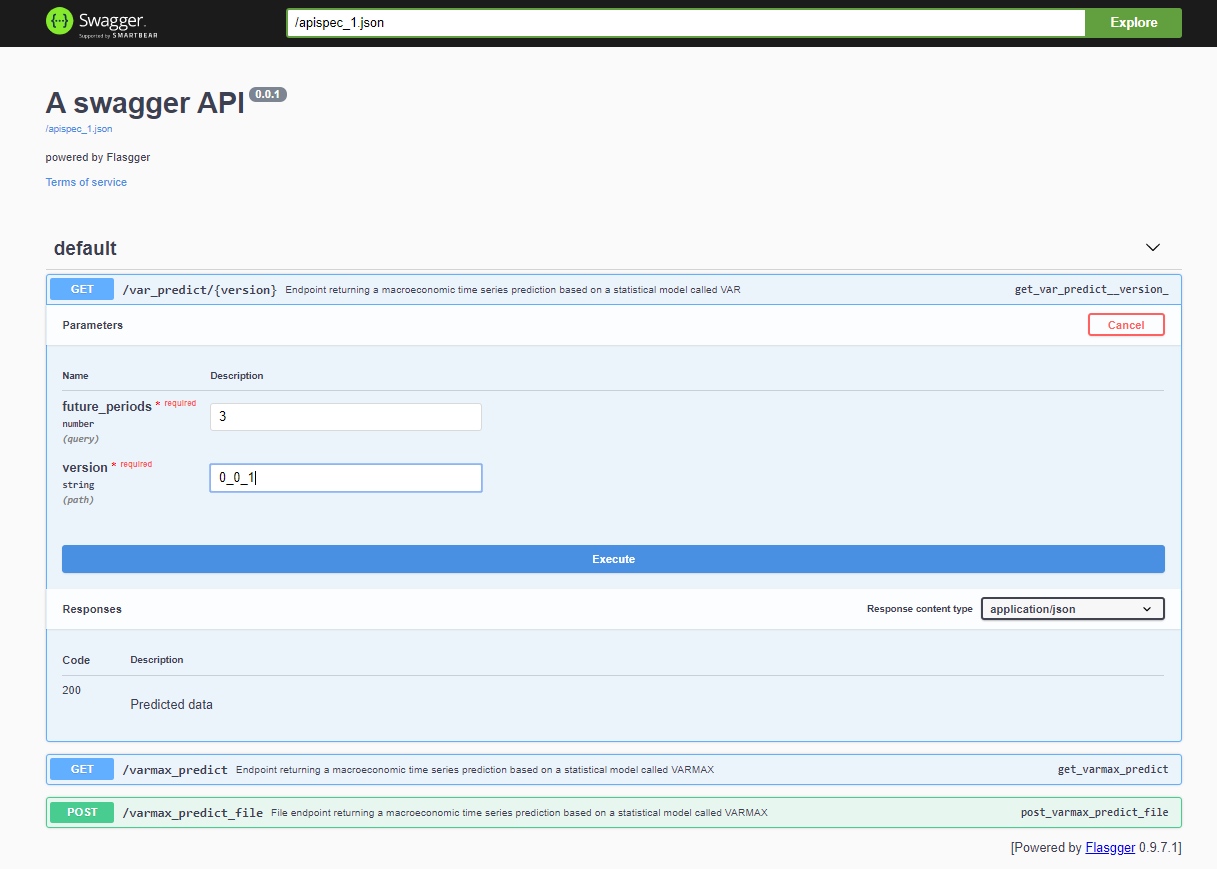
После развертывания проекта, Swagger API доступен через <host>:<port>/apidocs (например, 127.0.0.1:80/apidocs). Есть один конечный пункт для модели VAR, изображенный рядом с двумя другими, которые раскрывают модель VARMAX:
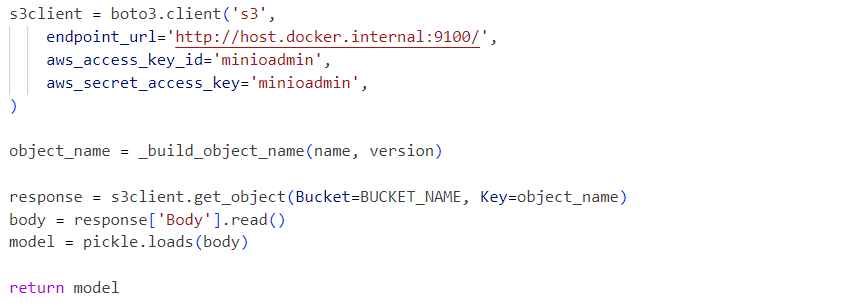
Внутренне, сервис использует десериализованный файл модели pickle, загруженный из сервиса MinIO:
Запросы отправляются в инициализированную модель следующим образом:

Представленный проект является упрощенным рабочим процессом модели VAR, который может быть расширен шаг за шагом с дополнительными функциями, такими как:
- Исследовать стандартные форматы сериализации и заменить pickle на альтернативное решение
- Интегрировать инструменты визуализации временных рядов данных, такие как Kibana или Apache Superset
- Хранить временные ряды данных в базах данных временных рядов, таких как Prometheus, TimescaleDB, InfluxDB, или в Объектном Хранилище, таком как S3
- Расширить конвейер с этапами загрузки данных и предварительной обработки данных
- Включить отчеты о метриках в качестве части конвейеров
- Реализовать конвейеры с использованием конкретных инструментов, таких как Apache Airflow или AWS Step Functions, или более стандартных инструментов, таких как Gitlab или GitHub
- Сравнить производительность и точность статистических моделей с моделями машинного обучения
- Реализовать комплексные решения для облака с интеграцией на уровне инфраструктуры, включая Infrastructure-As-Code
- Предоставлять другие статистические и ML модели в качестве сервисов
- Реализовать API для хранения моделей, которое абстрагирует механизм фактического хранения и управление версиями моделей, хранит метаданные модели и обучающие данные
Эти будущие улучшения станут предметом предстоящих статей и проектов. Цель данной статьи — интегрировать API хранения, совместимое с S3, и обеспечить хранение версионированных моделей. Эта функциональность будет выделена в отдельную библиотеку в ближайшее время. Представленное комплексное инфраструктурное решение может быть развернуто в производственной среде и улучшено в рамках процесса CI/CD со временем, также используя возможности распределенного развертывания MinIO или заменяя его на AWS S3.
Source:
https://dzone.com/articles/time-series-analysis-var-model-as-a-service