













Amazon Simple Storage Service (S3) — это высокомасштабируемая, надежная и безопасная служба объектного хранилища, предлагаемая Amazon Web Services (AWS). S3 позволяет компаниям хранить и извлекать любой объем данных из любой точки веб-пространства, используя сервисы класса “Enterprise”. S3 разработан для высокой совместимости и интегрируется гладко с другими Amazon Web Services (AWS), а также с инструментами и технологиями сторонних разработчиков для обработки данных, хранящихся в Amazon S3. Одним из таких инструментов является Amazon EMR (Elastic MapReduce), который позволяет обрабатывать большие объемы данных с использованием открытых инструментов, таких как Spark.
Apache Spark — это открытая система распределенных вычислений, предназначенная для обработки больших объемов данных. Spark создан для обеспечения скорости и поддерживает различные источники данных, включая Amazon S3. Spark предоставляет эффективный способ обработки больших объемов данных и выполнения сложных вычислений за минимальное время.
Memphis.dev — это альтернатива следующего поколения традиционным брокерам сообщений. Простой, надежный и долговечный облачный брокер сообщений, обернутый в целостную экосистему, которая обеспечивает экономичную, быструю и надежную разработку современных очередей.
Обычная схема работы брокеров сообщений заключается в удалении сообщений после истечения определенного политики удержания, например, по времени/размеру/количеству сообщений. Memphis предлагает второй уровень хранения для более длительного, возможно бесконечного, хранения сохраненных сообщений. Каждое сообщение, которое вытесняется из станции, автоматически перемещается на второй уровень хранения, в данном случае — это AWS S3.
В этом уроке вас проведут через процесс настройки станции Memphis с 2-й классификацией хранения, подключенной к AWS S3. Среда на AWS. Затем создайте бакет S3, настройте кластер EMR, установите и настройте Apache Spark на кластере, подготовьте данные в S3 для обработки, обработайте данные с помощью Apache Spark, изучите лучшие практики и настройте производительность.
Настройка среды
Мемфис
- Для начала сначала установите Memphis.
- Включите интеграцию AWS S3 через интеграционный центр Memphis.
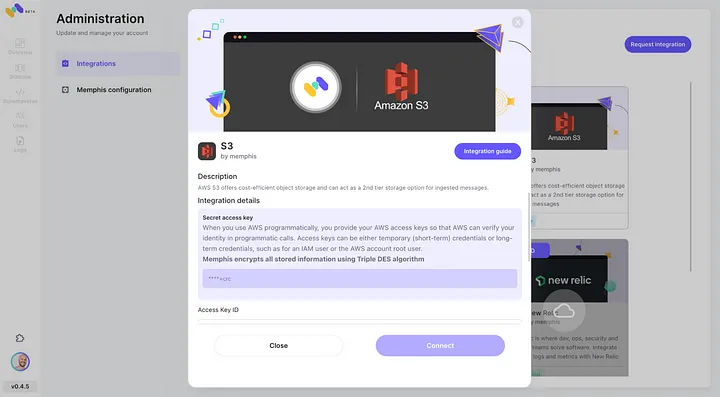
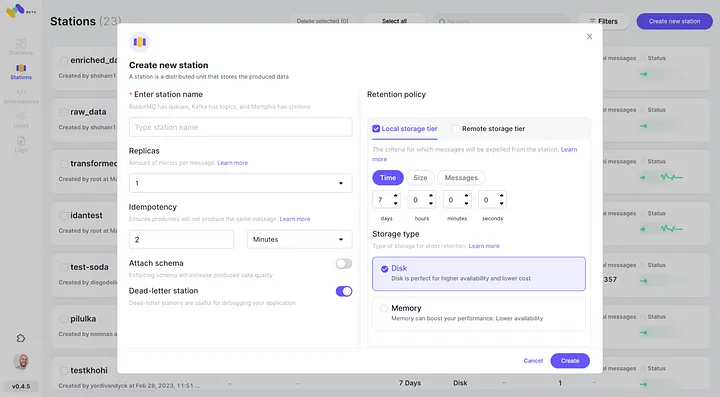
3. Создайте станцию (топик) и выберите политику удержания.
4. Каждое сообщение, проходящее настроенную политику удержания, будет перемещено в бакет S3.
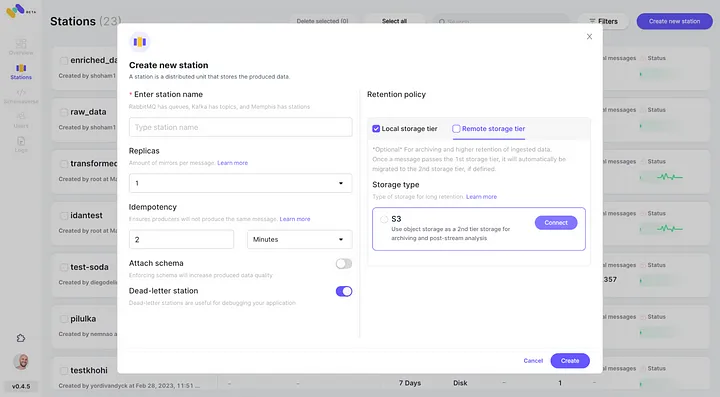
5. Проверьте недавно настроенную интеграцию AWS S3 как 2-й класс хранения, нажав “Подключить”.
6. Начните создание событий для вашей новосозданной станции Memphis.
Создание бакета AWS S3
Если вы еще этого не сделали, сначала вам нужно создать аккаунт AWS. Затем создайте бакет S3, куда вы сможете хранить свои данные. Вы можете использовать консоль управления AWS, AWS CLI или SDK для создания бакета. Для этого урока вы будете использовать консоль управления AWS.
Нажмите на “Создать бакет”.
Затем продолжайте создавать имя бакета, соответствующее правилам именования, и выберите регион, где вы хотите разместить бакет. Настройте “Владельца объектов” и “Блокировать все публичные доступы” в соответствии с вашим случаем использования.
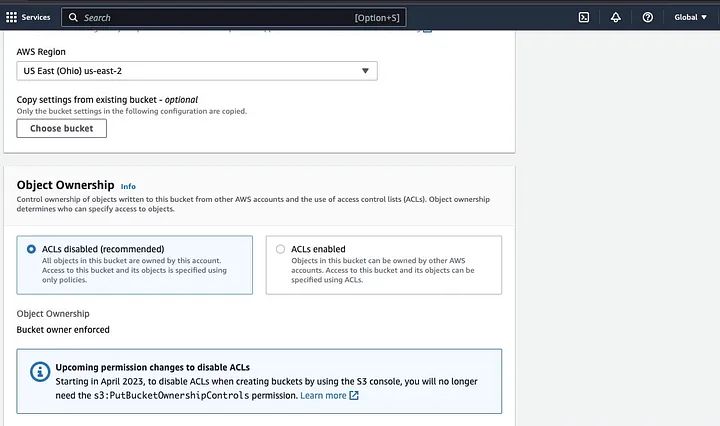
Убедитесь, что настроены другие разрешения бакета, чтобы позволить вашей Spark-приложению получить доступ к данным. Наконец, нажмите кнопку “Создать бакет” для создания бакета.
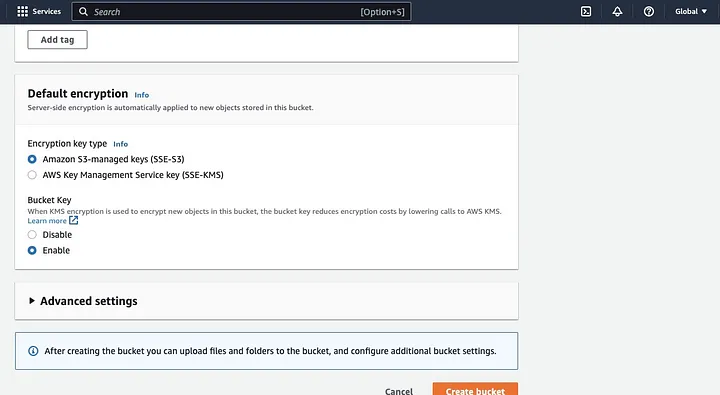
Настройка кластера EMR с установленным Spark
Amazon Elastic MapReduce (EMR) — это веб-служба на основе Apache Hadoop, которая позволяет пользователям эффективно обрабатывать огромные объемы данных с использованием технологий больших данных, включая Apache Spark. Чтобы создать кластер EMR с установленным Spark, откройте консоль EMR и выберите “Кластеры” под “EMR на EC2” в левой части страницы.
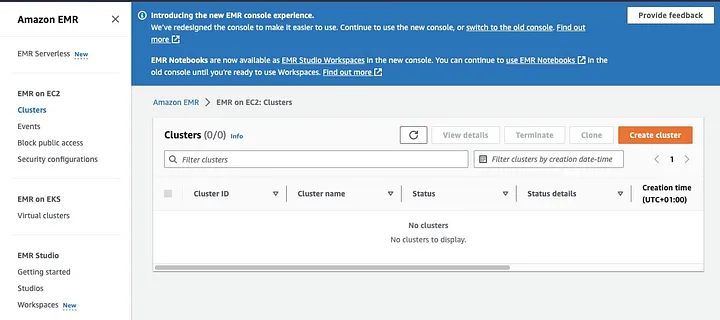
Нажмите на “Создать кластер” и дайте кластеру описательное имя. В разделе “Пакет приложений” выберите Spark для установки на вашем кластере.
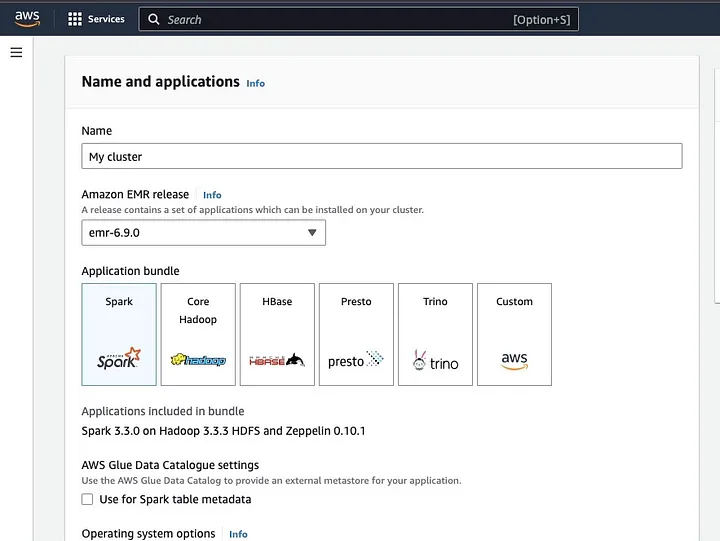
Прокрутите вниз до раздела “Логи кластера” и выберите checkbox опубликовать лог-файлы, специфичные для кластера, в Amazon S3.
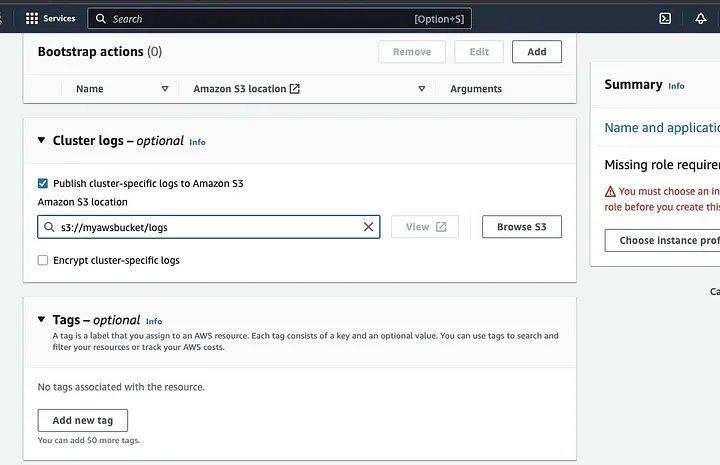
Это создаст подсказку для ввода расположения Amazon S3, используя имя S3-бакета, созданного на предыдущем шаге, за которым следует /logs, т.е. s3://myawsbucket/logs. /logs требуются Amazon для создания новой папки в вашем бакете, куда Amazon EMR может скопировать лог-файлы вашего кластера.
Перейдите в раздел “Конфигурация безопасности и разрешения” и введите ваш ключ EC2 или выберите опцию для создания нового.
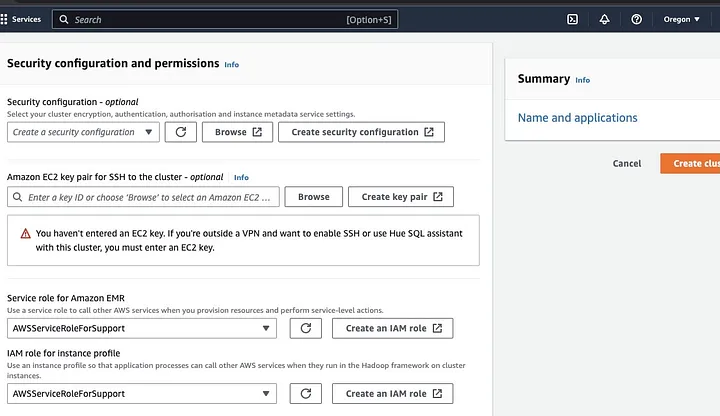
Затем нажмите на выпадающие опции для “Роль сервиса для Amazon EMR” и выберите AWSServiceRoleForSupport. Выберите ту же выпадающую опцию для “IAM роль для профиля экземпляра”. Обновите значок, если это необходимо, чтобы получить эти выпадающие опции.
Наконец, нажмите кнопку “Создать кластер” для запуска кластера и следите за статусом кластера, чтобы убедиться, что он был создан.
Установка и настройка Apache Spark на кластере EMR
После успешной создания кластера EMR следующим шагом будет настройка Apache Spark на кластере EMR. Кластеры EMR предоставляют управляемую среду для запуска приложений Spark на инфраструктуре AWS, что упрощает запуск и управление кластерами Spark в облаке. Он настраивает Spark для работы с вашими данными и потребностями в обработке, а затем отправляет задания Spark на кластер для обработки ваших данных.
Вы можете настроить Apache Spark для кластера с использованием протокола Secure Shell (SSH). Но сначала вам нужно авторизовать безопасные SSH-соединения с вашим кластером, которые были установлены по умолчанию при создании кластера EMR. Инструкция по авторизации SSH-соединений доступна здесь.
Для создания SSH-соединения вам нужно указать ключевую пару EC2, которую вы выбрали при создании кластера. Затем подключитесь к кластеру EMR с помощью оболочки Spark, сначала подключившись к основному узлу. Вам сначала нужно получить публичный DNS-адрес основного узла, перейдя в левой части консоли AWS, под EMR на EC2, выберите Кластеры, а затем выберите кластер с нужным публичным DNS-именем.
В терминале вашей операционной системы введите следующую команду.
ssh hadoop@ec2-###-##-##-###.compute-1.amazonaws.com -i ~/mykeypair.pemЗамените ec2-###-##-##-###.compute-1.amazonaws.com на имя вашего публичного DNS-адреса основного узла и ~/mykeypair.pem на имя файла и путь к вашему .pem файлу (Следуйте этой инструкции, чтобы получить .pem файл). Появится сообщение с подсказкой, на которое ваш ответ должен быть “yes” — введите “exit” для закрытия SSH-команды.
Подготовка данных для обработки с помощью Spark и загрузка в S3 Bucket
Обработка данных требует подготовки перед загрузкой для представления данных в формате, который Spark может легко обрабатывать. Формат, используемый, зависит от типа данных, которыми вы обладаете, и анализа, который вы планируете выполнить. Некоторые используемые форматы включают CSV, JSON и Parquet.
Создайте новую сессию Spark и загрузите свои данные в Spark с помощью соответствующего API. Например, используйте метод spark.read.csv() для чтения файлов CSV в DataFrame Spark.
Amazon EMR, управляемая служба для кластеров экосистемы Hadoop, может быть использована для обработки данных. Это уменьшает необходимость настройки, настройки и обслуживания кластеров. Он также предлагает другие интеграции с Amazon SageMaker, например, для запуска задания обучения модели SageMaker из конвейера Spark в Amazon EMR.
После того, как ваши данные будут готовы, с помощью метода DataFrame.write.format("s3"), вы можете прочитать файл CSV из бакета Amazon S3 в DataFrame Spark. Вам следует настроить учетные данные AWS и иметь разрешения на запись для доступа к бакету S3.
Укажите бакет S3 и путь, куда вы хотите сохранить данные. Например, вы можете использовать метод df.write.format("s3").save("s3://my-bucket/path/to/data") для сохранения данных в указанном бакете S3.
После того, как данные будут сохранены в бакете S3, вы можете получить к ним доступ из других приложений Spark или инструментов, или вы можете загрузить их для дальнейшего анализа или обработки. Чтобы загрузить бакет, создайте папку и выберите бакет, который вы изначально создали. Выберите кнопку Действия и нажмите “Создать папку” в выпадающих элементах. Теперь вы можете назвать новую папку.
Для загрузки файлов данных в бакет, выберите имя папки с данными.
В окне Загрузка — Выберите “Мастер файлов” и выберите “Добавить файлы”.
Следуйте инструкциям консоли Amazon S3 для загрузки файлов и выберите “Начать загрузку”.
Важно учитывать и обеспечивать лучшие практики для защиты ваших данных перед загрузкой их в бакет S3.
Понимание Форматов и Схем Данных
Форматы и схемы данных — это два связанных, но полностью различных и важных понятия в управлении данными. Формат данных относится к организации и структуре данных в базе данных. Существует множество форматов для хранения данных, таких как CSV, JSON, XML, YAML и т.д. Эти форматы определяют, как должны быть структурированы данные вместе с различными типами данных и приложениями, применимыми к ним. В то время как схемы данных — это структура самой базы данных. Она определяет расположение базы данных и обеспечивает правильное хранение данных. Схема базы данных указывает на представления, таблицы, индексы, типы и другие элементы. Эти понятия важны в аналитике и визуализации базы данных.
Очистка и Предобработка Данных в S3
Необходимо тщательно проверять данные на наличие ошибок перед их обработкой. Для начала, доступ к папке с данными, которую вы сохранили в своем бакете S3, и скачайте ее на свое локальное устройство. Затем загрузите данные в инструмент обработки данных, который будет использоваться для очистки и предобработки данных. Для этого урока используется инструмент Amazon Athena, который помогает анализировать неструктурированные и структурированные данные, хранящиеся в Amazon S3.
Перейдите в Amazon Athena на AWS Console.
Нажмите на “Create” для создания новой таблицы, а затем на “CREATE TABLE”.
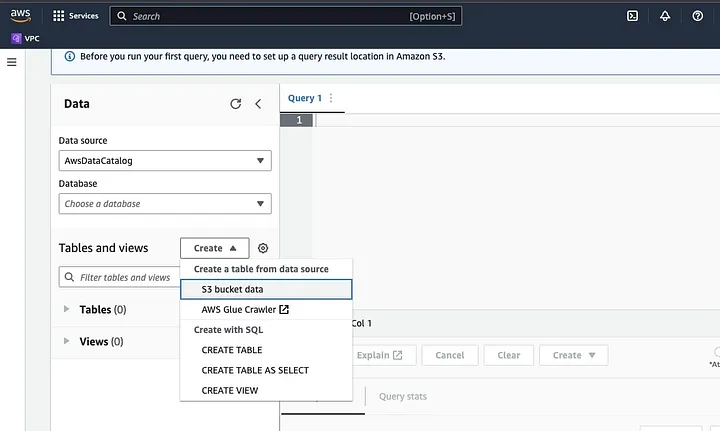
Введите путь к вашему файлу данных в части, выделенной как LOCATION.
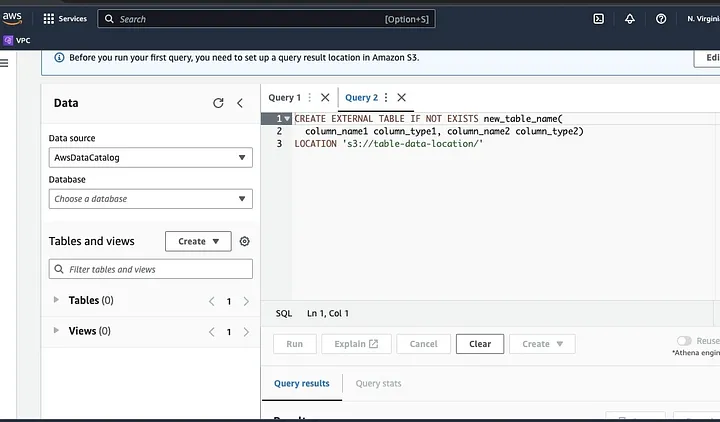
Следуйте подсказкам, чтобы определить схему для данных и сохранить таблицу. Теперь вы можете запустить запрос для проверки, загружены ли данные правильно, а затем очистить и предварительно обработать данные
Пример:
Этот запрос определяет дубликаты, присутствующие в данных.
SELECT row1, row2, COUNT(*)
FROM table
GROUP row, row2
HAVING COUNT(*) > 1;Этот пример создает новую таблицу без дубликатов:
CREATE TABLE new_table AS
SELECT DISTINCT *
FROM table;Наконец, экспортируйте очищенные данные обратно в S3, перейдя в S3 bucket и папку для загрузки файла.
Понимание Spark Framework
Фреймворк Spark – это открытый, простой и выразительный системный фреймворк для кластерного компьютинга, который был создан для быстрой разработки. Он основан на языке программирования Java и служит альтернативой другим Java-фреймворкам. Основная особенность Spark – его возможности вычислений в памяти, которые ускоряют обработку больших наборов данных.
Настройка Spark для работы с S3
Для настройки Spark на работу с S3 начните с добавления зависимости Hadoop AWS в ваше приложение Spark. Сделайте это, добавив следующую строку в ваш файл построения (например, build.sbt для Scala или pom.xml для Java):
libraryDependencies += "org.apache.hadoop" % "hadoop-aws" % "3.3.1"Введите идентификатор ключа доступа AWS и секретный ключ доступа в вашем приложении Spark, установив следующие свойства конфигурации:
spark.hadoop.fs.s3a.access.key <ACCESS_KEY_ID>
spark.hadoop.fs.s3a.secret.key <SECRET_ACCESS_KEY>Установите следующие свойства с помощью объекта SparkConf в вашем коде:
val conf = new SparkConf()
.set("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.set("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")Установите URL конечной точки S3 в вашем приложении Spark, задав следующее свойство конфигурации:
spark.hadoop.fs.s3a.endpoint s3.<REGION>.amazonaws.comЗамените <REGION> на регион AWS, где находится ваш бакет S3 (например, us-east-1).
Для предоставления доступа клиента S3 в Hadoop к запросам S3 требуется имя бакета, совместимое с DNS. Если имя вашего бакета содержит точки или подчеркивания, может потребоваться включить доступ по стилю пути для клиента S3 в Hadoop, который использует стиль виртуального хоста. Установите следующее свойство конфигурации для включения доступа по пути:
spark.hadoop.fs.s3a.path.style.access trueНаконец, создайте сессию Spark с конфигурацией S3, задав префикс spark.hadoop в конфигурации Spark:
val spark = SparkSession.builder()
.appName("MyApp")
.config("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.config("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")
.config("spark.hadoop.fs.s3a.endpoint", "s3.<REGION>.amazonaws.com")
.getOrCreate()Замените поля <ACCESS_KEY_ID>, <SECRET_ACCESS_KEY> и <REGION> на ваши учетные данные AWS и регион S3.
Чтобы прочитать данные из S3 в Spark, будет использован метод spark.read, а затем укажите путь к вашим данным в S3 в качестве источника входных данных.
Пример кода, демонстрирующий, как читать файл CSV из S3 в DataFrame в Spark:
val spark = SparkSession.builder()
.appName("ReadDataFromS3")
.getOrCreate()
val df = spark.read
.option("header", "true") // Specify whether the first line is the header or not
.option("inferSchema", "true") // Infer the schema automatically
.csv("s3a://<BUCKET_NAME>/<FILE_PATH>")В этом примере замените <BUCKET_NAME> на имя вашего бакета S3 и <FILE_PATH> на путь к вашему CSV-файлу в бакете.
Преобразование данных с помощью Spark
Преобразование данных с помощью Spark обычно относится к операциям над данными для очистки, фильтрации, агрегации и объединения данных. Spark предоставляет богатый набор API для преобразования данных. Они включают API DataFrame, Dataset и RDD. Некоторые из распространенных операций преобразования данных в Spark включают фильтрацию, выбор столбцов, агрегацию данных, объединение данных и сортировку данных.
Вот один пример операций преобразования данных:
Сортировка данных: Эта операция включает сортировку данных на основе одного или нескольких столбцов. Метод orderBy или sort для DataFrame или Dataset используется для сортировки данных на основе одного или нескольких столбцов. Например:
val sortedData = df.orderBy(col("age").desc)Наконец, может потребоваться записать результат обратно в S3 для хранения результатов.
Spark предоставляет различные API для записи данных в S3, такие как DataFrameWriter, DatasetWriter и RDD.saveAsTextFile.
Следующий код демонстрирует, как записать DataFrame в S3 в формате Parquet:
val outputS3Path = "s3a://<BUCKET_NAME>/<OUTPUT_DIRECTORY>"
df.write
.mode(SaveMode.Overwrite)
.option("compression", "snappy")
.parquet(outputS3Path)Замените поле ввода <BUCKET_NAME> на имя вашего S3-бакета и <OUTPUT_DIRECTORY> на путь к каталогу вывода в бакете.
Метод mode определяет режим записи, который может быть Overwrite, Append, Ignore или ErrorIfExists. Метод option может использоваться для указания различных опций формата вывода, таких как кодек сжатия.
Также можно записывать данные в S3 в других форматах, таких как CSV, JSON и Avro, изменяя формат вывода и указывая соответствующие опции.
Понимание разделения данных в Spark
Простыми словами, разделение данных в Spark означает разбиение набора данных на более мелкие, управляемые части по кластеру. Цель этого – оптимизировать производительность, уменьшить масштабируемость и в конечном итоге улучшить управление базами данных. В Spark данные обрабатываются параллельно на нескольких кластерах. Это становится возможным благодаря Resilient Distributed Datasets (RDD), которые представляют собой наборы больших, сложных данных. По умолчанию RDD разделены на различные узлы из-за их размера.
Для оптимальной работы существуют способы настройки Spark, чтобы обеспечить своевременное выполнение задач и эффективное управление ресурсами. Среди них – кэширование, управление памятью, сериализация данных и использование mapPartitions() вместо map().
Графический веб-интерфейс Spark UI предоставляет исчерпывающую информацию о производительности и использовании ресурсов приложения Spark. Он включает несколько страниц, таких как Обзор, Исполнители, Этапы и Задачи, которые предоставляют информацию о различных аспектах задачи Spark. Spark UI является важным инструментом для мониторинга и отладки приложений Spark, поскольку он помогает выявлять узкие места производительности и ограничения ресурсов и устранять ошибки. Исследуя такие метрики, как количество выполненных задач, продолжительность задачи, использование CPU и памяти, а также количество переписанных и прочитанных данных перемешивания, пользователи могут оптимизировать свои задачи Spark и обеспечить их эффективное выполнение.
Заключение
В целом, обработка ваших данных на AWS S3 с использованием Apache Spark является эффективным и масштабируемым способом анализа огромных наборов данных. Используя облачные хранилища и вычислительные ресурсы AWS S3 и Apache Spark, пользователи могут быстро и эффективно обрабатывать свои данные, не беспокоясь о управлении архитектурой.
В этом руководстве мы рассмотрели процесс настройки бакета S3 и кластера Apache Spark на AWS EMR, конфигурирование Spark для работы с AWS S3, а также написание и запуск приложений Spark для обработки данных. Также были рассмотрены вопросы партиционирования данных в Spark, интерфейс пользователя Spark и оптимизация производительности в Spark.
Ссылка
Для более глубокого погружения в конфигурирование Spark для оптимальной производительности, смотрите здесь.
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-ssh.html
Source:
https://dzone.com/articles/stateful-stream-processing-with-memphis-and-apache-spark