













Shift-left – это подход к разработке программного обеспечения и операциям, который подчеркивает тестирование, мониторинг и автоматизацию на ранних стадиях жизненного цикла разработки программного обеспечения. Цель подхода shift-left – предотвращать проблемы до их возникновения, обнаруживая их на ранних стадиях и быстро решая.
Когда вы обнаруживаете проблему с масштабируемостью или баг на ранней стадии, ее решение оказывается быстрее и экономически более выгодным. Перемещение неэффективного кода в облачные контейнеры может быть затратным, так как это может активировать автомасштабирование и увеличить ваш ежемесячный счет. Более того, вы будете в состоянии экстренной готовности до тех пор, пока не сможете идентифицировать, изолировать и исправить проблему.
Утверждение проблемы
I would like to demonstrate to you a case where we managed to avert a potential issue with an application that could have caused a major issue in a production environment.
I was reviewing the performance report of the UAT infrastructure following the recent application change. It was a Spring Boot microservice with MariaDB as the backend, running behind Apache reverse proxy and AWS application load balancer. The new feature was successfully integrated, and all UAT test cases are passed. However, I noticed the performance charts in the MariaDB performance dashboard deviated from pre-deployment patterns.
Это хронология событий.
6 августа в 14:13 было перезапущено приложение с новым файлом jar Spring Boot, содержащим встроенный Tomcat.
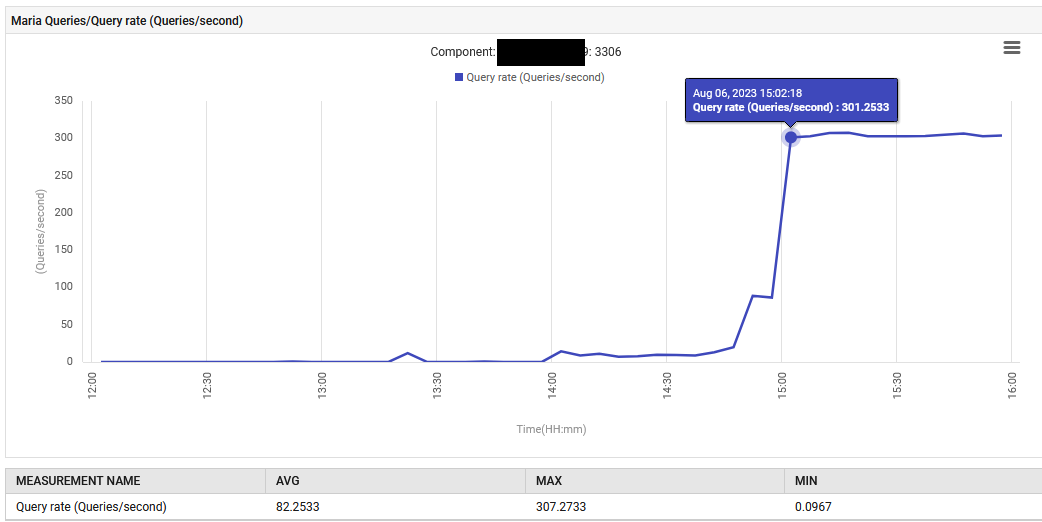
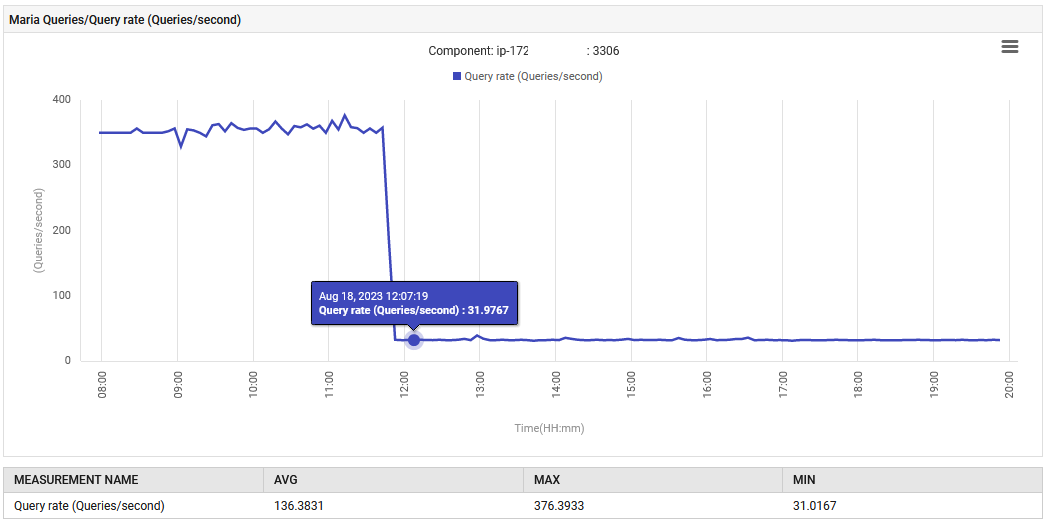
В 14:52 скорость обработки запросов MariaDB увеличилась с 0.1 до 88 запросов в секунду, а затем до 301 запроса в секунду.
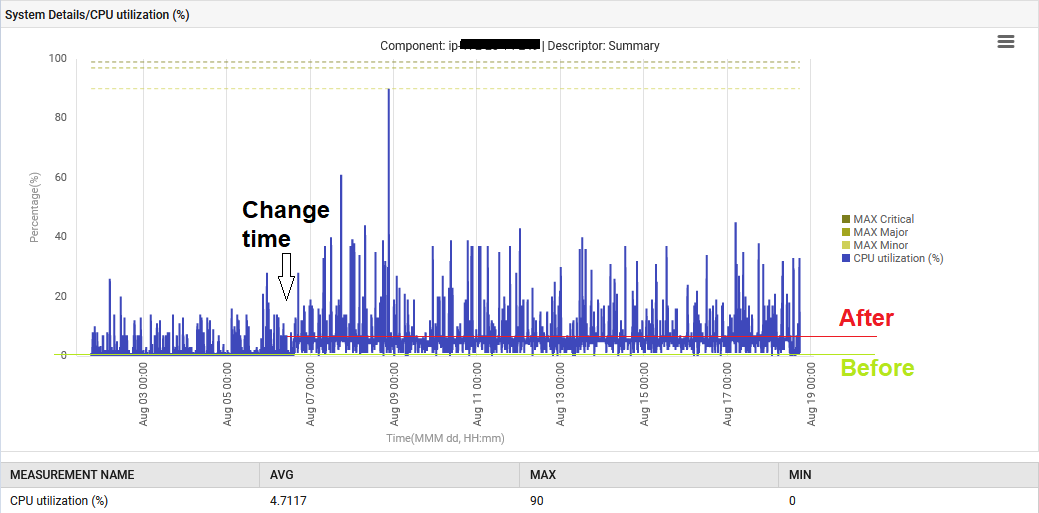
Кроме того, системный CPU повысился с 1% до 6%.
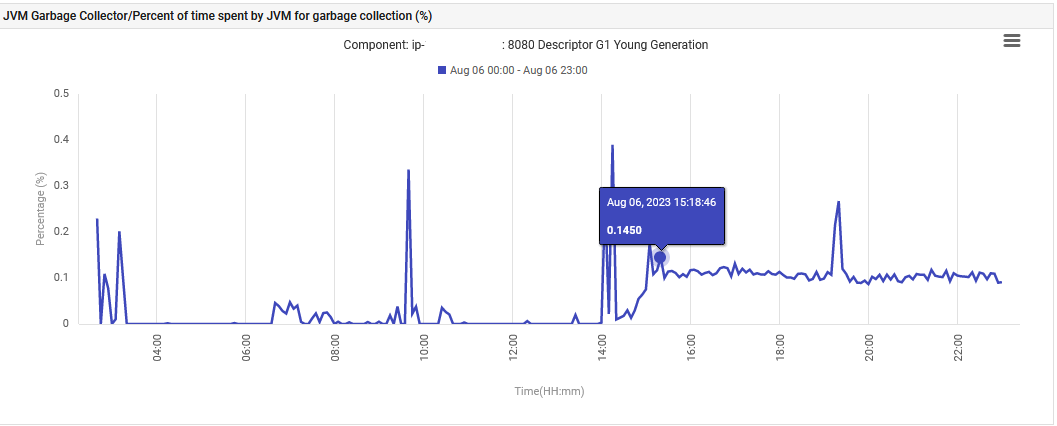
Наконец, время, затрачиваемое JVM на сборку мусора в G1 Young Generation Garbage Collection, увеличилось с 0% до 0.1% и оставалось на этом уровне.
Приложение на стадии UAT аномально выдает 300 запросов/сек, что значительно превышает то, на что оно было разработано. Новая функция привела к увеличению подключений к базе данных, что и объясняет столь резкое увеличение запросов. Однако на мониторинге показали, что проблематичные показатели были нормальными до развертывания новой версии.
Решение
Это приложение на Spring Boot, использующее JPA для запросов к MariaDB. Приложение разработано для работы на двух контейнерах с минимальной нагрузкой, но способно масштабироваться до десяти.
Если один контейнер способен генерировать 300 запросов в секунду, может ли он обработать 3000 запросов в секунду, если все десять контейнеров будут работать? Достаточно ли подключений у базы данных для удовлетворения потребностей других частей приложения?
У нас не было другого выбора, кроме как вернуться к столу разработчика, чтобы проверить изменения в Git.
Новое изменение заключается в том, чтобы взять несколько записей из таблицы и обработать их. Вот что мы наблюдали в сервисном классе.
List<X> findAll = this.xRepository.findAll();
Нет, использование метода findAll() без пагинации в Spring’s CrudRepository неэффективно. Пагинация помогает уменьшить время, необходимое для извлечения данных из базы данных, ограничивая объем получаемых данных. Это то, что нам преподавали в основном курсе по СУБД. Кроме того, пагинация помогает поддерживать низкое использование памяти, чтобы предотвратить крах приложения из-за перегрузки данных, а также уменьшить усилия по сборке мусора в Java Virtual Machine, что упоминалось в вышестоящем описании проблемы.
Этот тест был проведен только с 2000 записей в одном контейнере. Если бы этот код перешел в производство, где в 10 контейнерах находится около 200 000 записей, это могло бы вызвать у команды много стресса и беспокойства в тот день.
Приложение было перестроено с добавлением WHERE условия к методу.
List<X> findAll = this.xRepository.findAllByY(Y);
Нормальная работа была восстановлена. Количество запросов в секунду уменьшилось с 300 до 30, и усилия по сборке мусора вернулись к исходному уровню. Кроме того, использование CPU системы снизилось.
Обучение и Итоги
Любой, кто работает в области Site Reliability Engineering (SRE), оценит значимость этого открытия. Мы смогли действовать, не прибегая к выставлению флажка Severity 1. Если бы этот дефектный пакет был развернут в производстве, он мог бы активировать порог автомасштабирования клиента, что привело бы к запуску новых контейнеров даже без дополнительной нагрузки пользователей.
Из этой истории можно извлечь три основных вывода.
Во-первых, лучшей практикой является включение решения для наблюдаемости с самого начала, так как оно может предоставить историю событий, которую можно использовать для выявления потенциальных проблем. Без этой истории я, возможно, не придал бы серьезного значения 0,1% проценту сборки мусора и 6% потреблению CPU, и код мог бы быть выпущен в производство с катастрофическими последствиями. Расширение области мониторинга до серверов UAT помогло команде выявить потенциальные причины проблем и предотвратить их до возникновения.
Во-вторых, в процессе тестирования должны присутствовать тесты, связанные с производительностью, и их следует проверять уполномоченным специалистом в области наблюдаемости. Это обеспечит тестирование как функциональности кода, так и его производительности.
В-третьих, методы слежения за производительностью в облачных средах хороши для получения оповещений о высоком использовании, доступности и т.д. Для достижения наблюдаемости может потребоваться наличие нужных инструментов и профессиональных знаний. Счастливого кодирования!
Source:
https://dzone.com/articles/shift-left-monitoring-approach-for-cloud-apps-in-c