













Получение улучшенного генерирования (RAG) ознаменовал революционный прорыв в крупных языковых моделях (LLMs). Он объединяет творческую способность архитектур трансформеров с динамической информационной выборкой.
Эта интеграция позволяет LLMs получать доступ и включать релевантные внешние знания в процессе генерации текста, что приводит к более точным, контекстуальным и фактически согласованным результатам.
Развитие от ранних систем на основе правил до изящных нейронных моделей, таких как BERT и GPT-3, открыло путь для RAG, решая ограничения статической параметрической памяти. Также появление Мультимодального RAG расширяет эти возможности, включая различные типы данных, такие как изображения, аудио и видео. Это улучшает глубину и значимость генерируемого содержимого.
Этот Paradigm Shift не только улучшает точность и интерпретируемость результатов LLM, но и поддерживает инновационные приложения в различных областях.
Здесь мы покроем:
- Раздел 1. Введение в RAG
– 1.1 Что такое RAG? Обзор
– 1.2 Как RAG решает сложные проблемы - Глава 2. Технические основы
– 2.1 Переход от нейронных моделей полного словаря к RAG
– 2.2 Understanding RAG’s Memory:Parametric vs. Non-Parametric
– 2.3 Multimodal RAG: Интеграция нескольких типов данных - Глава 3. Основные механизмы
– 3.1 Сила комбинации информационного поиска и генерации в RAG
– 3.2 Стратегии интеграции для ретриверов и генераторов - Глава 4. Приложения и Use Cases
– 4.1 RAG на работе: от QA до творческой речи
– 4.2 RAG для языков с низким ресурсом: расширение возможностей и доступа - Глава 5. Техники оптимизации
– 5.1 Продвигающиеся методы recovery для оптимизации RAG-систем - Глава 6. Задачи и инновации
– 6.1现行的挑战和RAG未来的发展方向
– 6.2硬体加速和RAG系统的高效部署 - Глава 7. Заключительные мысли
– 7.1 Будущее RAG: заключения и размышления
Предварительные требования
Для со engagement с содержимым, сфокусированным на крупных языковых моделях (LLMs), таких как Retrieval-Augmented Generation (RAG), два необходимых предварительных требования являются:
- Основы машинного обучения: понимание основных понятий и алгоритмов машинного обучения важно, особенно когда они применяются к архитектурам нейронных сетей.
- Процессинг自然ного языка (NLP): Знание техник NLP, включая предварительную обработку текста, токенизацию и использование вкладок, важно для работы с моделями языка.
Глава 1: Введение в RAG
Retrieval-Augmented Generation (RAG) трансформирует процессинг自然ного языка, комбинируя информационный поиск и генеративные модели. RAG динамически доступит внешние знания, улучшая точность и релевантность сгенерированного текста.
В этой главе мы исследуем механизмы RAG, его преимущества и проблемы. Мы копаемся в техниках поиска, интеграции с генеративными моделями и влиянии на различные приложения.
RAG смягчает Hallucinations, включает актуальную информацию и решает сложные проблемы. Также мы обсуждаем проблемы, такие как эффективный поиск и этические соображения. Эта глава предоставляет комплексное понимание трансформационного потенциала RAG в процессинге natural language.
1.1 Что такое RAG? Общее введение
Retrieval-Augmented Generation (RAG) представляет собой сдвиг в paradigma процессинга natural language, гладко интегрируя силы информационного поиска и генеративных моделей языка. Системы RAG используют внешние источники знаний для улучшения точности, релевантности и связности сгенерированного текста, решая ограничения исключительно параметрической памяти в традиционных моделях языка. (Льюис и др., 2020)
Динамически извлекая и включая релевантную информацию в процессе генерации, RAG позволяет получать более контекстуально обоснованные и фактически последовательные выходные данные во всех областях применения, от ответов на вопросы и систем диалогов до обобщения и творческого письма. (Петрони и др., 2021)
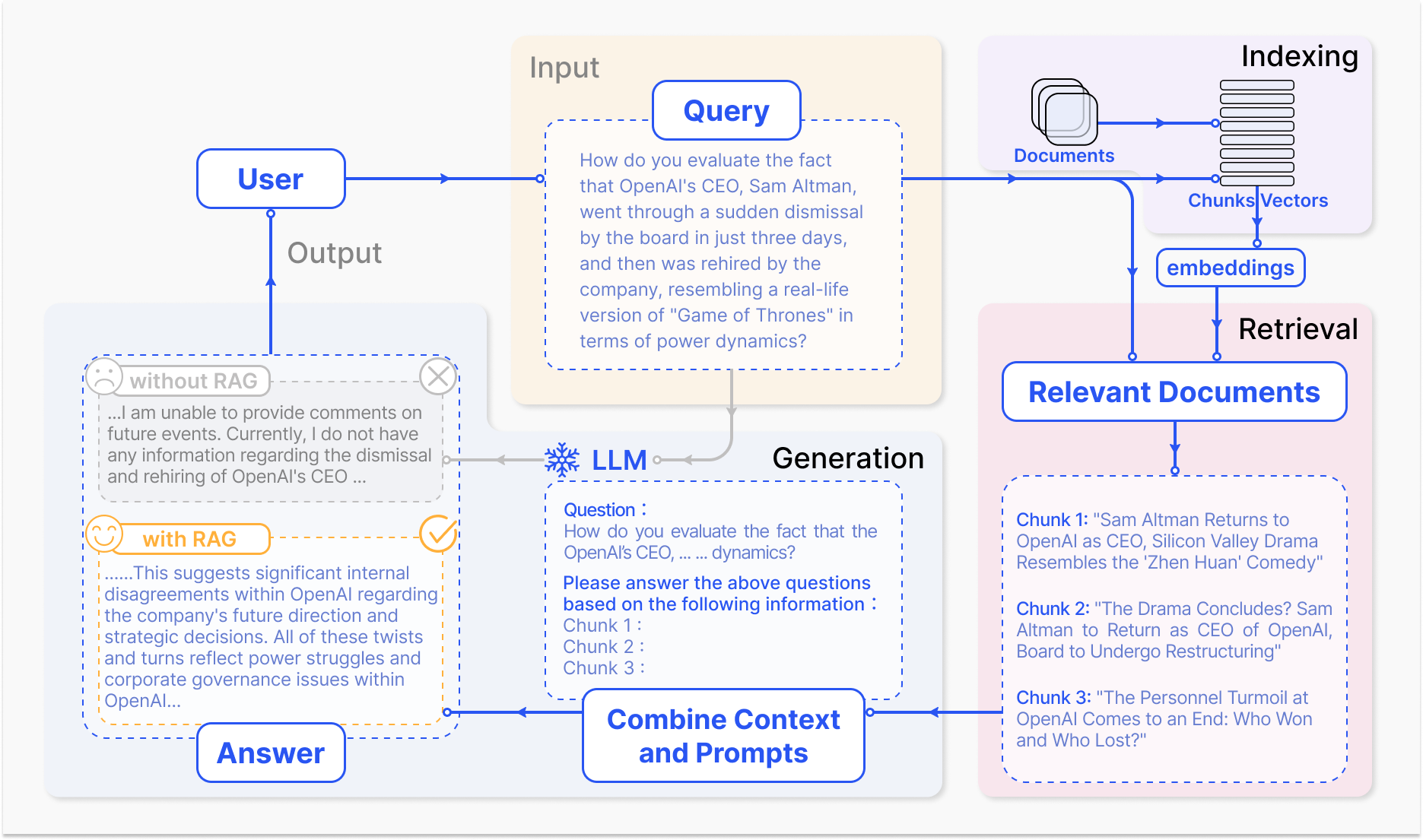
Как работает система RAG – arxiv.org
Ядро механизма RAG состоит из двух основных компонентов: извлечения и генерации.
Компонент извлечения эффективно ищет в огромных базах знаний, чтобы определить наиболее релевантную информацию на основе входного запроса или контекста. Техники такие как разреженное извлечение, которое использует инвертированные индексы и поиск на основе терминов, и плотное извлечение, которое применяет плотные векторные представления и семантическую подобность, применяются для оптимизации процесса извлечения. (Карпухин и др., 2020)
Извлеченная информация затем интегрируется в генеративную модель, обычно это большая языковая модель, такая как GPT или T5, которая синтезирует релевантный контент в связный и изящный ответ. (Изакар и Грэйв, 2021)
Интеграция извлечения и генерации в RAG предлагает несколько преимуществ перед традиционными языковыми моделями. За счет упрочения сгенерированного текста с помощью внешнего знания, RAG значительно уменьшает частоту возникновения галлюцинаций или фактически неверных выводов. (Шустер и др., 2021)
RAG также позволяет включать актуальную информацию, обеспечивая, чтобы сгенерированные ответы отражали последние знания и разработки в данной области. (Льюис и др., 2020) Эта адаптивность особенно важна в таких областях, как здравоохранение, финансы и научные исследования, где точность и свежесть информации являются наиболее важными. (Петрони и др., 2021)
Но разработка и внедрение систем RAG также представляет значительные вызовы. Эффективное извлечение информации из крупномасштабных баз знаний, снижение галлюцинаций и интеграция различных модальностей данных являются техническими препятствиями, которые необходимо решить. (Изакар и Грэйв, 2021)
Также важны этические соображения, такие как обеспечение беспристрастного и справедливого извлечения и генерации информации, что является crucial для ответственного внедрения систем RAG. (Bender et al., 2021) Разработка всесторонних оценочных показателей и структур, которые охватывают взаимодействие между точностью извлечения и качеством генерации, esencial для оценки эффективности систем RAG. (Lewis et al., 2020)
С развитием области RAG будущие исследовательские направления сосредотачиваются на оптимизации процессов извлечения, расширения мультимодальных возможностей, разработки модульных архитектур и установки устойчивых оценочных рамок. (Izacard & Grave, 2021) Эти усовершенствования улучшат эффективность, точность и адаптивность систем RAG, прокладывая путь для более умных и многофункциональных приложений в природном языковой обработке.
Вот пример базового Python-кода, демонстрирующий установку RAG с использованием популярных библиотек LangChain и FAISS:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. Загрузка и включение документов
loader = TextLoader('your_documents.txt') # Замените на вашу источнику документов
documents = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. Получение соответствующих документов
def retrieve_docs(query):
return vectorstore.similarity_search(query)
# 3. Настройка цепи RAG
llm = OpenAI(temperature=0.1) # Настройка температуры для творчества ответов
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 4. Использование модели RAG
def get_answer(query):
return chain.run(query)
# Пример использования
query = "What are the key features of Company X's latest product?"
answer = get_answer(query)
print(answer)
#Пример Использования Истории компании
query = "When was Company X founded and who were the founders?"
answer = get_answer(query)
print(answer)
#Пример ИспользованияFinancial Performance
query = "What were Company X's revenue and profit figures for the last quarter?"
answer = get_answer(query)
print(answer)
#Пример Использования Прогноз на будущее
query = "What are Company X's plans for expansion or new product development?"
answer = get_answer(query)
print(answer)
Используя возможности выборки и генерации, RAG обещает преобразовать способ, которым мы взаимодействуем с информацией и генерируем ее, революционизируя различные области и определяя будущее человеко-машинного взаимодействия.
1.2 Как RAG решает сложные проблемы
Ретировочное усиление генерации (RAG) предлагает мощное решение сложных проблем, с которыми стандартные крупные языковые модели (LLMs) сталкиваются, особенно в сценариях с большими объемами неструктурированных данных.
Одна такая проблема – это способность проводить значимые разговоры о конкретных документах или мультимедийном содержании, таком как YouTube-видео, без предварительной настройки или явного обучения с целью достижения цели.
Традиционные LLM, несмотря на их впечатляющие генеративные способности, ограничены их параметрической памятью, которая фиксируется во время обучения. (Lewis et al., 2020) Это意味着 что они не могут непосредственно получить доступ к или включить новые сведения за пределами их тренировочных данных, что делает трудным участие в информированных дискуссиях о невидимых документах или видео.
В результате LLM могут генерировать ответы, которые несогласованны, не связаны с темой или фактически неверны, когда их инициируют запросы, связанные с конкретным содержимым. (Petroni et al., 2021)
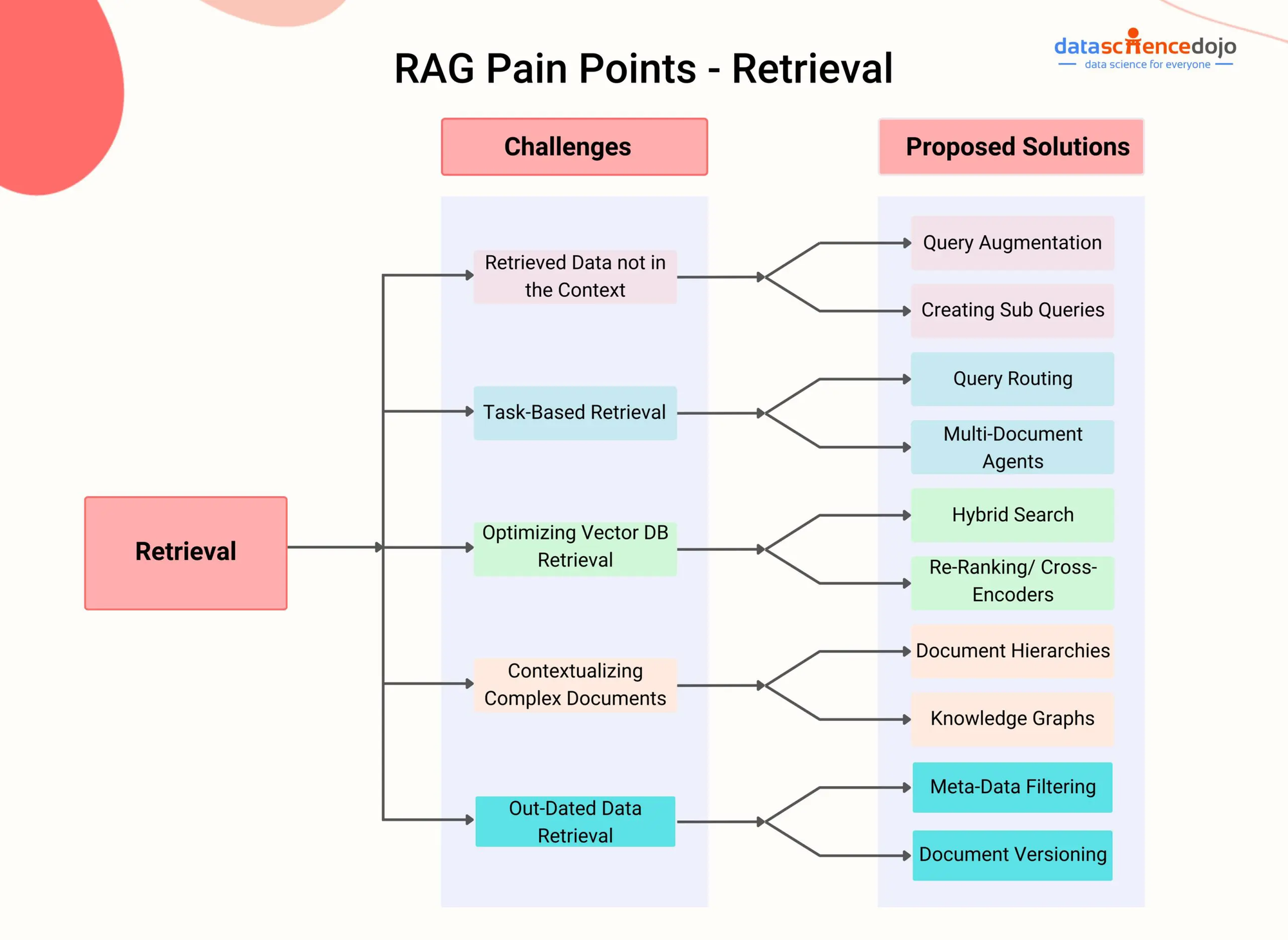
Проблемы RAG – DataScienceDojo
RAG решает эту проблему, интегрируя компонент поиска, который позволяет модели динамически получать доступ и включать соответствующие сведения из внешних источников знаний в процессе генерации.
При использовании передовых методов поиска, таких как глобальный поиск густого текста (Karpukhin et al., 2020) или гибридный поиск (Izacard & Grave, 2021), системы RAG эффективно идентифицируют наиболееpertinentные фрагменты или сегменты из данного документа или видео на основе контекста разговора.
Например, рассмотрим сценарий, в котором пользователь хочет пообщаться на тему конкретного видео на YouTube по научной теме. Система RAG может сначала транскрибировать аудиосодержание видео, а затем индексировать полученный текст, используя плотные векторные представления.
Затем, когда пользователь задает вопрос, связанный с видео, компонент поиска системы RAG может быстро идентифицировать наиболее релевантные отрывки из транскрипции на основе семантического сходства между запросом и индексированным содержанием.
Извлеченные отрывки затем подаются в генеративную модель, которая синтезирует связный и информативный ответ, непосредственно адресующий вопрос пользователя, при этом основывая ответ на содержании видео. (Shuster et al., 2021)
Этот подход позволяет системам RAG вести осведомленные беседы о широком спектре документов и мультимедийного контента без необходимости явной тонкой настройки. Динамически извлекая и внедряя релевантную информацию, RAG может генерировать ответы, которые более точны, контекстуально релевантны и фактически последовательны по сравнению с традиционными LLM. (Lewis et al., 2020)
Also, возможности RAG обрабатывать неструктурированные данные от различных модальностей, таких как текст, изображения и аудио, делают ее гибкой решением для сложных проблем, включающих различные источники неоднородной информации. (Izacard & Grave, 2021) CMRAG системы продолжают развиваться, их потенциал решать сложные проблемы в различных областях также увеличивается.
Использование передовых техник поиска и мультимодальной интеграции позволяет RAG создать более умных и контекстуально сознательных диалоговых агентов, персонализированных систем рекомендаций и приложений, основанных на знаниях.
Как исследования продвигаются в области эффективного индексирования, межмодальной альIGNции и интеграции поиска-generции, RAG несомненно играет ключевую роль в продвижении boundариев возможностей моделей языка и искусственного интеллекта.
Глава 2: Технические Основы
Эта глава исследует завораживающий мир мультимодального поиска с учетом генерации (RAG), которая является передовой методологией, преодолевающей ограничения традиционных текстовых моделей.
Благодаря гладкому интеграции различных модальностей данных, таких как изображения, аудио и видео, с крупными моделями языка (LLM), мультимодальная RAG наделяет системы AI способностью推理 на более ricнной информационной области.
Мы будем исследовать механизмы behind этой интеграции, такие как контрастное обучение и межмодальное внимание, и как они позволяют LLM генерировать более sublined и контекстуально значимые ответы.
Спецификации Multimodal RAG предлагают перспективные преимущества, такие как повышение точности и способность поддерживать новые случаи использования, такие как визуальные ответы на вопросы, однако они также представляют уникальные вызовы. Эти вызовы включают необходимость масштабных мультимодальных наборов данных, увеличение вычислительной сложности и потенциальный байас в извлеченной информации.
Когда мы начнем этот путь, мы не только раскроем трансформационный потенциал Multimodal RAG, но и критически рассмотрим препятствия, которые лежат впереди, проложив путь к более глубокому пониманию этого быстрорастущего поля.
2.1 Нейронные модели языка к RAG
Развитие моделей языка было отмечено постоянным прогрессом от ранних систем на основе правил к все более сложным статистическим и основанным на нейронных сетях моделям.
В ранние дни модели языка опирались на вручную созданные правила и языковое знание для генерации текста, что приводило к жестким и ограниченным выходным данным. Появление статистических моделей, таких как модели n-грамм, ввело подход, основанный на данных, который изучал шаблоны из больших корпусов, что позволяло создавать более естественные и связные тексты. (Redis)
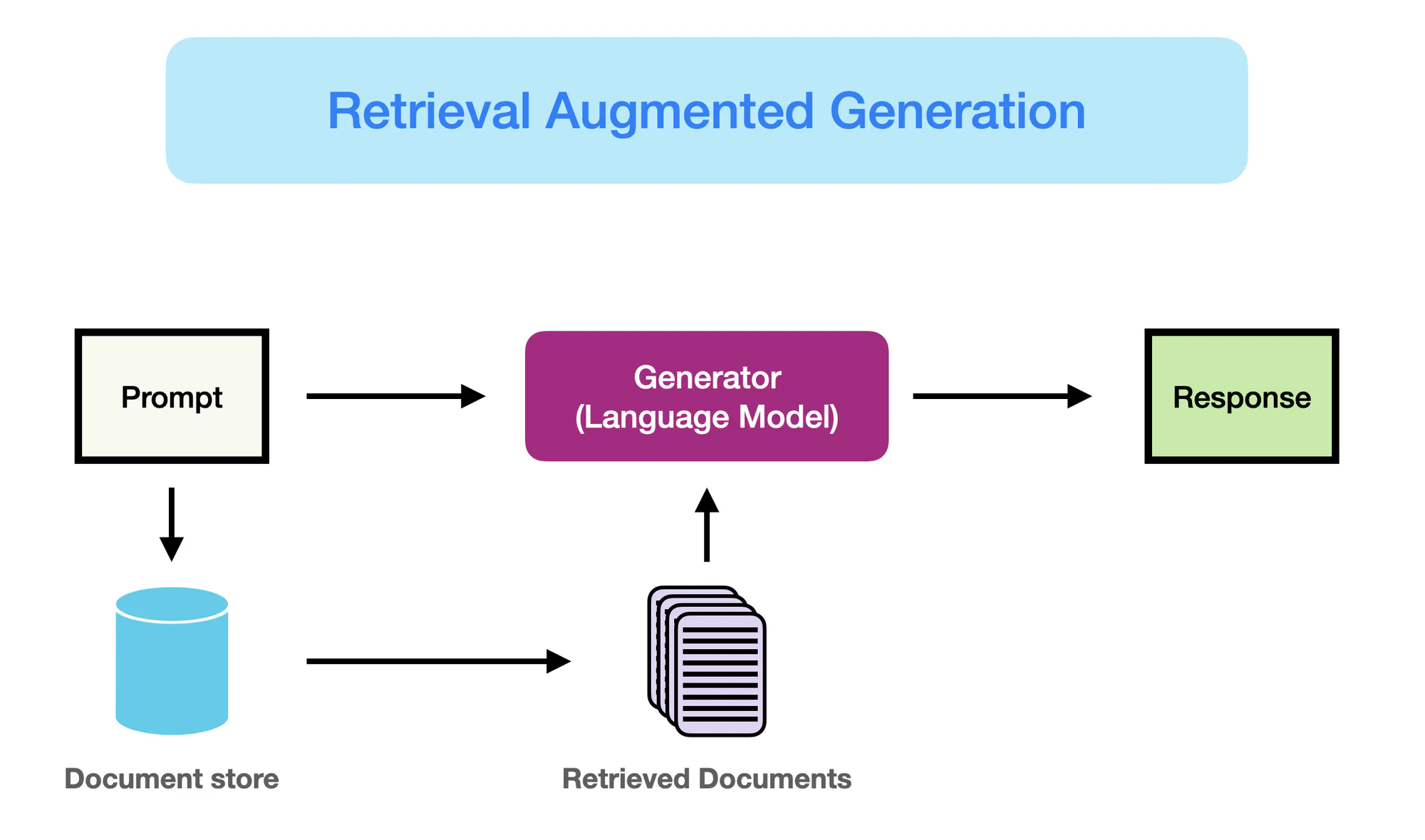
Как работает RAG – promptingguide.ai
Однако появление моделей на основе нейронных сетей, особенно архитектур трансформер, таких как BERT и GPT-3, революционизировало поле自然语言处理 (NLP).
Эти модели, известные как крупные языковые модели (LLMs), используют силу глубокого обучения, чтобы захватить сложные языковые модели и генерировать человекоподобный текст с невиданной ранее гладкостью и согласованностью. (Yarnit) Развитие сложности и масштаба LLMs, с моделями, такими как GPT-3, который похвастается более чем 175 миллиардами параметров, привело к поразительным способностям в таких задачах, как языковая трансляция, ответ на вопросы и создание содержания.
Несмотря на их впечатляющие показатели, традиционные LLMs страдают от ограничений из-за их зависимости от исключительно параметрической памяти. (StackOverflow) Знания, закодированные в этих моделях, статичны, их ограничивает дата окончания обучения.
Как следствие, LLMs могут генерировать результаты, которые фактически неверны или несогласованы с последней информацией. Также отсутствие явного доступа к внешним источникам знаний препятствует их способности обеспечить точные и контекстуально релевантные ответы на вопросы, требующие знаний.
РетиважAugmented Generation (RAG) появляется как революционное решение, которое addresses these limitations. Благодаря гладкому интеграции возможностей информационного поиска с генеративной силой LLMs, RAG позволяет моделям динамически доступа к и внедрять в процессе генерации соответствующие знания из внешних источников.
Fusion это объединение параметрической и непараметрической памяти, что позволяет RAG-оборудованным LLM-системам выдавать результаты, которые не только гладки и связны, но и фактически correctны и осведомлены в контексте.
RAG представляет собой значительный шаг вперед в языковой генерации, объединяя силы LLM-систем с огромными знаниями, доступными в внешних репозитариях. Используя лучшие качества обеих миров, RAG наделяет модели способностью генерировать текст, который более надежден, информативен и согласуется с реальными сведениями о мире.
Этот Paradigm Shift открывает новые возможности для NLP-приложений, от ответа на вопросы и создания содержимого до знания-насыщенных задач в областях, таких как здравоохранение, финансы и научные исследования.
2.2 Параметрическая против непараметрической памяти
Параметрическая память означает знания, сохраненные внутри параметров предварительно обученных языковых моделей, таких как BERT и GPT-4. Эти модели leaning учитывать языковые модели и взаимосвязи, запакованные в огромные количества текстовых данных в процессе обучения, закодированные этим знанием в их миллионах или миллиардах параметров.
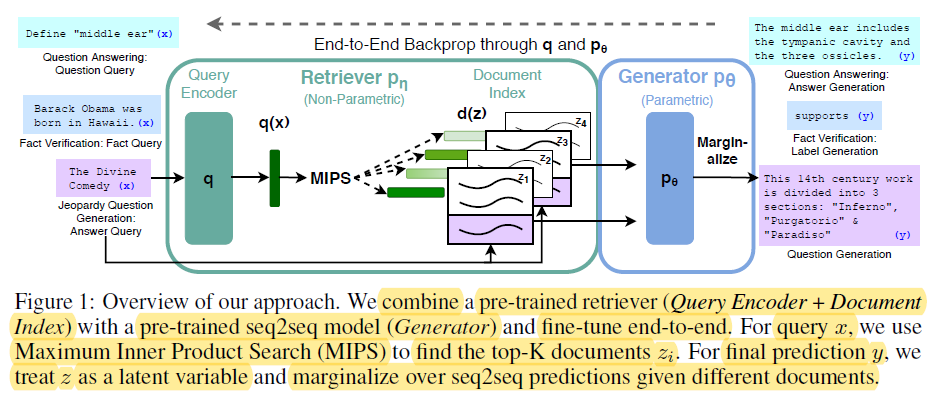
End-t-End Backprop through q and p0 – miro.medium.com
Сильные стороны параметрической памяти включают:
- Согласность: Предобученные языковые модели генерируют похожие на человеческий текст с исключительной согласностью и связностью, помечая небольшие нюансы и стиль自然语言. (Redis и Lewis и другие.)
- Общее описание: Знания, закодированные в параметрах модели, позволяют ей обобщаться на новые задачи и области, что обеспечивает способности трансферного обучения и обучения с少量 выборами. (Redis и Lewis и другие.)
Тем не менее, параметрическая память также имеет значительные ограничения:
- Фактические ошибки: Языковые модели могут генерировать результаты, которые несогласуются с реальными фактами, так как их знания ограничены данными, на которых они были тренированы.
- Застарелая информация: Знания, закодированные в параметрах модели, стареют с течением времени, так как они зафиксированы в момент тренировки и не отражают обновлений или изменений в реальном мире.
- Высокая вычислительная затрата: Тренировка крупных языковых моделей требует огромного объема вычислительных ресурсов и энергии, что делает ее дорогой и сложной в осуществлении обновления знаний.
- Общее знание: Знания, запечатанные в языковых моделях, широки и общие, недостаточно глубокие и специфичные для многих специальностных приложений.
В отличие от них непараметрическая память связана с использованием явных источников знаний, таких как базы данных, документы и знание графов, для предоставления языковым моделям актуальной и точной информации. Эти внешние источники выполняют роль дополнительной формы памяти, позволяя моделям в процессе генерации получать и извлекать необходимую информацию по требованию.
Преимущества непараметрической памяти включают:
- Актуальная информация: Внешние источники знаний могут быть легко обновлены и обслужены, что обеспечивает моделям доступ к последним и наиболее точным сведениям.
- Уменьшение иллюзий: “При извлечении соответствующей информации из внешних источников RAG значительно уменьшает частоту иллюзий или фактически неверных генерируемых выходов.” (Lewis et al. и Guu et al.)
- Домен-специфические знания: Непараметрическая память позволяет моделям использовать специализированные знания из домен-специфических источников, что обеспечивает более точные и контекстуально значимые результаты для конкретных приложений. (Lewis et al. и Guu et al.)
Ограничения параметрической памяти подрывают необходимость для смены парадигмы в языковой генерации.
RAG представляет значительный прогресс в природной языковой обработке, обеспечивая улучшение производительности генеративных моделей путём интеграции техник информационного поиска. (Redis)
Далее приведён Python-код для демонстрации различия между параметрической и непараметрической памятью в контексте RAG, а также для выделения ясными выходными данными:
from sentence_transformers import SentenceTransformer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
#Sample Document Collection (assume more substantial documents in a real scenario)
documents = [
"The Large Hadron Collider (LHC) is the world's largest and most powerful particle accelerator.",
"The LHC is located at CERN, near Geneva, Switzerland.",
"The LHC is used to study the fundamental particles of matter.",
"In 2012, the LHC discovered the Higgs boson, a particle that gives mass to other particles.",
]
#1. Non-Parametric Memory (Retrieval with Embeddings)
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
vectorstore = FAISS.from_documents(documents, embeddings)
#2. Parametric Memory (Language Model with Retrieval)
llm = OpenAI(temperature=0.1) # Adjust temperature for response creativity
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
#--- Queries and Responses ---
query = "What was discovered at the LHC in 2012?"
answer = chain.run(query)
print("Parametric (w/ Retrieval): ", answer["answer"])
query = "Where is the LHC located?"
docs = vectorstore.similarity_search(query)
print("Non-Parametric: ", docs[0].page_content)
Output:
Parametric (w/ Retrieval): The Higgs boson, a particle that gives mass to other particles, was discovered at the LHC in 2012.
Non-Parametric: The LHC is located at CERN, near Geneva, Switzerland.
Из этого кода следует, что:
Параметрическая Память:
- Использует обширные знания LLM для генерации всестороннего ответа, включая ключевое фактическое утверждение о том, что Higgs-бозон придает массу другим частицам. LLM “параметризирован” своим широким обучением на данных.
Непараметрическая Память:
- Выполняет поиск сходства в векторном пространстве, находят наиболее релевантный документ, который непосредственно отвечает на вопрос о местонахождении LHC. Он не синтезирует новые данные, он просто извлекает соответствующий факт.
Ключевые различия:
| Feature | Parametric Memory | Non-Parametric Memory |
|---|---|---|
| Хранение знаний | Закодировано в параметрах модели (весах) в качестве наученных представлений. | Сохраняется прямо в качестве исходного текста или других форматов (например,嵌入). |
| Поиск | Использует генеративные способности модели для создания текста, связанного с запросом на основе наученных знаний. | Включает поиск документов, близких к запросу (например, с помощью сходства или соответствия ключевым словам). |
| Свободность | Высокая свободность и может генерировать новые ответы, но может и выдумывать (генерировать неверную информацию). | Меньшая свободность, но меньше склонности к выдумкам, так как она основывается на существующих данных. |
| Стиль ответа | Может производить более изящные и сложные ответы, но с потенциально большим количеством неважной информации. | Предоставляет прямые и краткие ответы, но может не хватать контекста или разъяснений. |
| Компьютерный расход | Генерирование ответов может быть вычислительно интенсивным, особенно для больших моделей. | Ретриевал может быть быстрее, особенно с эффективным индексированием и алгоритмами поиска. |
Комбинируя сильные стороны параметрической и неparametric memory, RAG преодолевает ограничения традиционных языковых моделей и позволяет генерировать более точные, свежие и контекстно релевантные выходные данные. (Redis, Льюис и др., и Гуу и др.)
2.3 Мультимодальный RAG: Интеграция текста
Мультимодальный RAG расширяет традиционную текстовую парадигму RAG путем включения нескольких модальностей данных, таких как изображения, аудио и видео, для усиления способности ретриевала и генерации больших языковых моделей (LLM).
Используя техники контрастного обучения, мультимодальные системы RAG учатся включать гетерогенные типы данных в общее векторное пространство, что позволяет беспроблемному кросс-модальному ретриевалу. Это позволяет LLM генерировать более изощренные и контекстно релевантные выходные данные, комбинируя текстовую информацию с визуальными и слуховыми сигналами. (Шен и др.)
Диаграмма иллюстрирует систему рекомендаций, в которой большой языковой модель обрабатывает запрос пользователя в виде представлений, которые затем сопоставляются с помощью косинусной схожести в векторной базе данных, содержащей как текстовые, так и изображения представления, для получения и рекомендации наиболее релевантных элементов. – opendatascience.com
Одна из ключевых подходов в мультимодальных RAG заключается в использовании трансформерных моделей, таких как ViLBERT и LXMERT, которые применяют механизмы кросс-модального внимания. Эти модели могут обращать внимание на соответствующие области изображений или конкретные сегменты в аудио/видео во время генерации текста,捕获 между модами тонких взаимодействий. Это позволяет формировать более визуально и контекстуально основанные ответы. (Protecto.ai)
Включение текста с другими модами в ipeline RAG встречает проблемы, такие как совмещение семантических представлений между различными типами данных и обработка уникальных особенностей каждой моды во время процесса представления. Techniques like modality-specific encoding and cross-attention are used to address these challenges. (Зhu и al.)
Однако потенциальные преимущества мультимодальных RAG значительны, включая улучшенную точность, управляемость и interpretability генерируемого содержимого, а также возможность поддерживать новые use cases, такие как визуальный вопрос-ответ и создание мультимодального содержимого.
Например, Ли и коллеги (2020) предложили многоmodalную RAG-фреймворк для вопрос-ответных систем, который ищет связанные изображения и текстуальную информацию, чтобы генерировать точные ответы, превосходяя предыдущие state-of-the-art решения по таким балансам, как VQA v2.0 и CLEVR. (MyScale)
Несмотря на впечатляющие результаты, многоmodalная RAG также introduce новые задачи, такие как увеличенная компьютерная сложность, необходимость больших multimodalных датасетов, и потенциальная предвзятость и шум в искажённой информации. (
Researchers активно исследуют техники для смягчения этих проблем, такие как эффективные структуры индексирования, стратегии data augmentation и методы адавариантного тренирования. (Sohoni et al.)
Глава 3: Корневые механизмы RAG
В этой главе мы исследуем сложные взаимоотношения между ретрайверами и генеративными моделями в системах Retrieval-Augmented Generation (RAG), выделяя их ключевую роль в индексировании, извлечении и синтезировании информации для производства точных и контекстуально значимых ответов.
Мы исследуем subtleties спarse и dense retrieval-техник, сравнивая их силы и слабости в различных ситуациях. Также мы рассматриваем различные стратегии для интеграции извлеченной информации в генеративные модели, такие как конкатенация и кросс-внимание, и discuss их влияние на общую эффективность RAG-систем.
Поняв эти стратегии интеграции, вы получите ценные сведения о том, как оптимизировать системы RAG для конкретных задач и областей, прокладывая путь к более осознанному и эффективному использованию этой мощной парадигмы.
3.1 Сила сочетания поиска и генерации информации в RAG
Retrieval-Augmented Generation (RAG) представляет собой мощную парадигму, которая легко объединяет поиск информации с генеративными моделями языка. Как видно из названия, RAG состоит из двух основных компонентов: Поиск и Генерация.
Компонент поиска отвечает за индексирование и поиск в огромном хранилище знаний, а компонент генерации использует полученную информацию для создания контекстуально релевантных и фактологически точных ответов. (Redis и Lewis et al.)
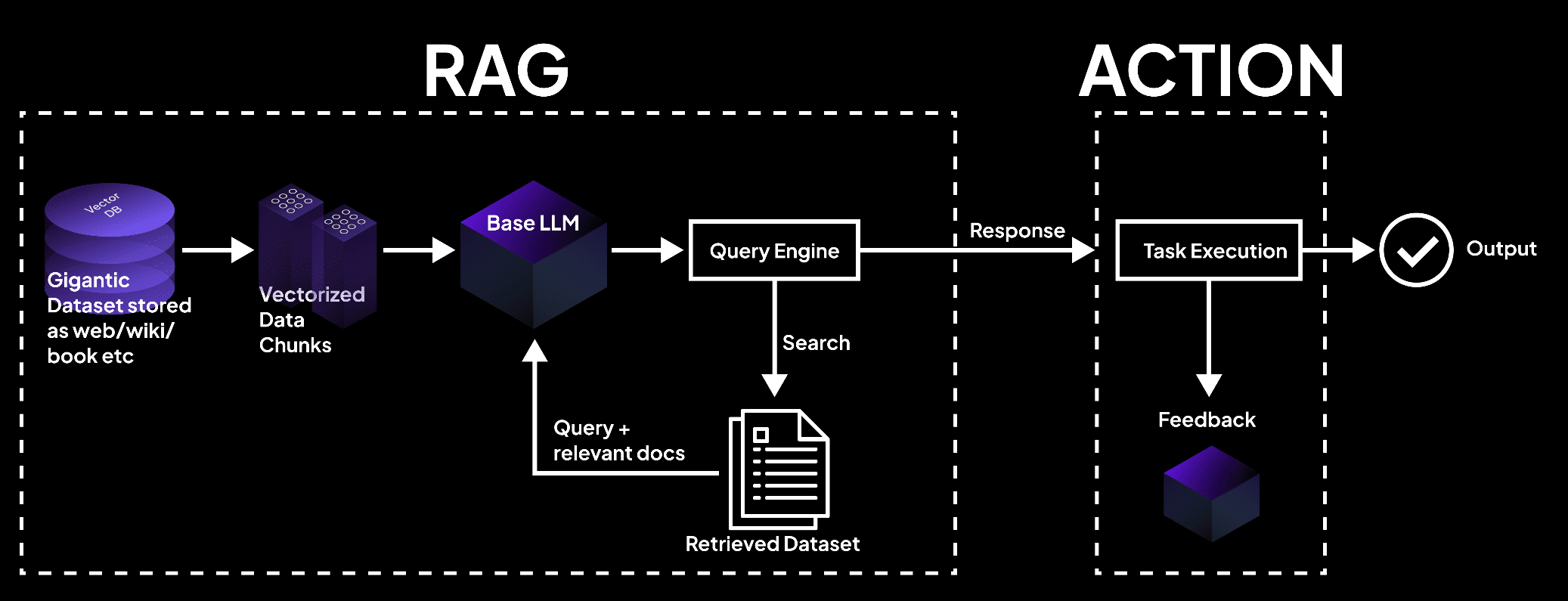
На изображении показана система RAG, в которой векторная база данных обрабатывает данные в виде фрагментов, запрашиваемых языковой моделью для получения документов для выполнения задач и получения точных результатов. – superagi.com.
Процесс выдачи информации начинается с индексации внешних знаний источников, таких как базы данных, документы и веб-страницы. (Redis и Льюис и др.)�ёт информацию в формате, содеражащем основной контекст.
После того, как для системы RAG подан запрос, он ищет в индексированной базе знаний наиболее релевантные для него куски информации на основе семантического сходства и других метрик значимости.
Когда собранная информация является релевантной, компонент генерации вступает в действие. Информация, найденная для поддержки и направления генерирующего языкового моделья, предоставляя ему необходимый контекст и фактическую основу для создания точных и информативных ответов.
Языковая модель использует передовые вference техники, такие как механизмы внимания и архитектура трансформера, чтобы синтезировать найденную информацию с ее предужедженными знаниями и генерировать текст, выдающийся как гладкий и последовательный.
Передача информации внутри системы RAG может быть представлена следующим образом:
graph LR
A[Query] --> B[Retriever]
B --> C[Indexed Knowledge Base]
C --> D[Relevant Information]
D --> E[Generator]
E --> F[Response]
Преимущества RAG многочисленны:
Эта синтез способности извлечения и генерации позволяет создавать ответы, которые не только контекстуально уместны, но и основаны на наиболее актуальной и точной информации. (Гуу и др.)
Использование внешних источников знаний позволяет RAG значительно уменьшить количество галлюцинаций или фактически неверных выводов, что является обычной проблемой исключительно генеративных моделей.
Кроме того, RAG позволяет интегрировать актуальную информацию, обеспечивая, что генерируемые ответы отражают последние знания и достижения в соответствующей области. Это особенно важно в таких областях, как здравоохранение, финансы и научные исследования, где точность и своевременность информации имеют первостепенное значение. (Гуу и др. и NVIDIA)
RAG также обладает выдающейся адаптируемостью, позволяя языковым моделям обрабатывать широкий спектр задач с улучшенной производительностью. Путем динамического извлечения соответствующей информации на основе конкретного запроса или контекста, RAG дает моделям возможность генерировать ответы, настраиваемые для уникальных требований каждой задачи, будь то ответы на вопросы, генерация контента или приложения в конкретной области.
Множество исследований демонстрировало эффективность RAG в улучшении фактичности, релевантности и адаптируемости генеративных языковых моделей.
например, Lewis и др. (2020) показали, что RAG превосходит чисто генеративные модели на ряде задач по answers to questions, достигая состояния актуальных результатов на базе данных, таких как Natural Questions и TriviaQA. (Lewis et al.)
Также Izacard и Grave (2021) продемонстрировали превосходство RAG над традиционными языковыми моделями в генерации связного и фактически согласного длинного текста.
Ретирование-усиленная генерация представляет собой трансформационный подход к языковой генерации, использующий информационную ретирацию, чтобы улучшить точность,相关性和 адаптивность генеративных моделей.
Передача внешних знаний с уже существующими языковыми способностями RAG открывает новые возможности для природного языкового процессающих и прокладывает путь для более умных и надежных систем языковой генерации.
3.2 Стратегии интеграции ретировщика-генератора
Системы ретирование-усиленной генерации (RAG) опираются на два ключевых компонента: ретировщики и генеративные модели. Ретировщики ответственны за эффективный поиск и выбор соответствующей информации из больших баз знаний.
“Он включает два основных этапа: индексирование и поиск. Индексирование организует документы для эффективного ретирования, используя либо обратные индексы для разрывного ретирования или за密集 vector encoding для гибкого ретирования.” (Redis)
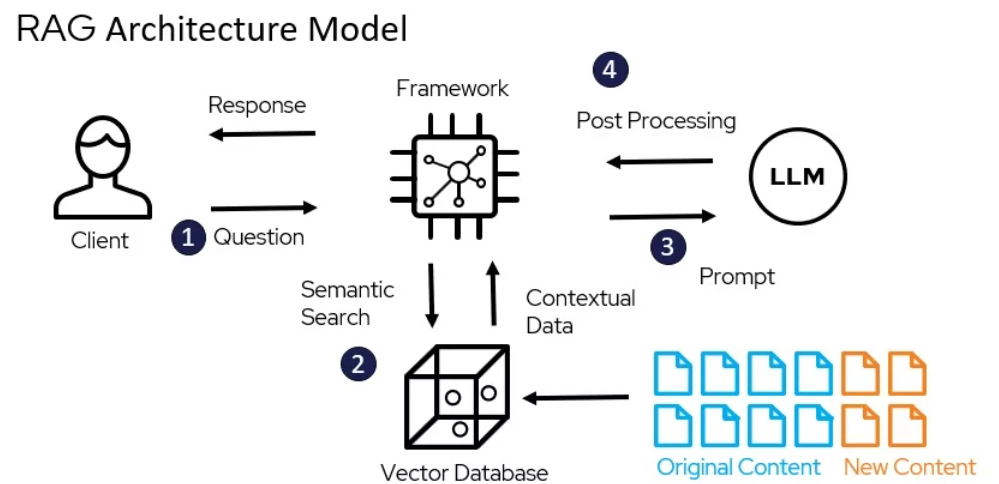
Архитектурная модель RAG – miro.medium.com
Техники разреженного поиска, такие как TF-IDF и BM25, представляют документы в виде высокоразмерных разреженных векторов, где каждое измерение соответствует уникальному термину в словаре. Релевантность документа для запроса определяется пересечением терминов, взвешенным их важностью.
Например, с использованием популярной библиотеки Elasticsearch, построитель на основе TF-IDF может быть реализован следующим образом:
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.index(index="documents", doc_type="_doc", body={"text": "This is a sample document."})
query = "sample"
results = es.search(index="documents", body={"query": {"match": {"text": query}}})
Техники плотного поиска, такие как плотный поиск по пассажам (DPR) и модели на основе BERT, представляют документы и запросы в виде плотных векторов в непрерывном пространстве вложений. Релевантность определяется косинусной схожестью между векторами запроса и документа.
Реализацию DPR можно выполнить с использованием библиотеки Hugging Face Transformers:
from transformers import DPRContextEncoder, DPRQuestionEncoder
context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_embeddings = context_encoder(documents)
query_embedding = question_encoder(query)
scores = torch.matmul(query_embedding, context_embeddings.transpose(0, 1))
Генеративные модели, такие как GPT и T5, используются в RAG для генерации связных и контекстуально значимых ответов на основе полученной информации. Настройка этих моделей на предметно-специфических данных и использование техник инструкций могут значительно улучшить их производительность в системах RAG. (DEV Community)
Стратегии интеграции определяют, как полученный контент включается в генеративные модели.
“Компонент поколения использует полученное содержимое, чтобы формировать согласные и контекстуально значимые ответы с помощью этапов подсказки и инferenсинга.” (Redis)
Два общепринятых подхода – это конкатенация и кросс-внимание.
Конкатенация включает вставку полученных разделов в запрос ввода, позволяя генеративной модели учитывать соответствующую информацию в процессе декодирования.
尽管这种方法实现简单,但它可能会在长序列和无关信息面前遇到困难。 (DEV Community) Механизмы кросс-внимания, такие как RAG-Token и RAG-Sequence, позволяют генеративной модели выборочно учитывать полученные разделы на каждом шаге декодирования.
Это позволяет достичь более тонкой контроли интеграционного процесса, однако это также увеличивает компьютерную сложность.
Например, RAG-Token может быть реализован с использованием библиотеки Hugging Face Transformers:
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids)
generated_output = model.generate(input_ids, retrieved_docs=retrieved_docs)
Выбор ретривера, генеративной модели и стратегии интеграции зависит от специфических требований системы RAG, таких как размер и свойства базы знаний, желаемое равновесие между эффективностью и эффективностью и область применения цели.
Глава 4: Приложения и Use Cases
Эта глава исследует потенциал трансформации, привнесенный Metodami-усиленным построением (RAG) в революционизацию приложений с низким ресурсом на языке и мультиязычных приложений. Мы исследуем стратегии, такие как перевод источников документов на языки с большим ресурсом, использование мультиязычных представлений и применение федерального обучения, чтобы преодолеть ограничения данных и языковые различия.
Кроме того, мы решаем критическую проблему смягчения halucinations в мультиязычных системах RAG, чтобы обеспечить точное и надежное создание содержимого. Исследуя这些创新方法, этот раздел предлагает комплексный путеводитель по использованию силы RAG для включения и разнообразия в обработке языка.
4.1 Приложения RAG: от вопрос-ответных систем до творческого писания
Metodami-усиленное построение (RAG) нашло множество практических применений в различных областях, показав свой потенциал революционизировать то, как мы взаимодействуем с информацией и создаем ее.利用 возможностей извлечения и генерации, системы RAG доказали значительные улучшения в точности, значимости и Engagement пользователей.
Как работает RAG – miro.medium.com
Вопрос-ответная система
РАГ оказался революционным изменением в области ответов на вопросы. Используя методы извлечения соответствующей информации из внешних источников знаний и интегрируя ее в процесс генерации, системы РАГ могут обеспечить более точные и контекстуально релевантные ответы на запросы пользователя. (LangChain и Django Stars)
Например, Izacard и Grave (2021) предложили основанный на РАГ модель под названием Fusion-in-Decoder (FiD), который достиг лучших результатов на нескольких бенчмарках ответов на вопросы, включая Natural Questions и TriviaQA. (Izacard и Grave)
FiD использует плотный агрегатор для извлечения соответствующих фрагментов и генеративную модель для синтеза извлеченной информации в удобочитаемый ответ, значительно превышая по эффективности чисто генеративные модели. (Izacard и Grave)
Системы диалоговых запросов
RAG также нашёл применения в создании более захватывающих и информативных конVERSционных агентов. Включая внешний знак посредством извлечения, диалоговые системы на основе RAG могут генерировать ответы, которые не только соответствуют контексту, но и основаны на фактах. (LlamaIndex и MyScale)
Шустер и al. (2021) представили диалоговую систему на основе RAG под названием BlenderBot 2.0, которая продемонстрировала улучшенные поведение конверсии по сравнению с предшественником. (Шустер и al.)
BlenderBot 2.0 извлекаетpertinentную информацию из различных источников знаний, включая Википедию, новостные статьи и социальные медиа, что позволяет ему вести более продуманные и последовательные диалоги по широкому кругу тем. (Шустер и al.)
Раздел
RAG продемонстрировал перспективу в улучшении качества генерируемых резюме путем включенияpertinentной информации из множества источников. (Hyperight) Пасунуру и al. (2021) предложили модель резюме на основе RAG под названием PEGASUS-X, которая извлекает и интегрируетpertinentные разделы из внешних документов для генерации более информативных и последовательных резюме.
ПЕГАСУС-X оказался лучше, чем чисто генетические модели, на нескольких бенчмарках обобщения, демонстрируя эффективность выбора для улучшения фактической точности и Relevance генерируемых резюме.
Creative Writing
потенциал RAG расширяется за пределы фактических областей и в сферу творческого письма. Благодаря выбору соответствующих разделов из различного корпуса литературных работ, системы RAG могут генерировать необычные и восхищетельные истории или статьи.
Rashkin и др. (2020) ввели RAG-основанную модель творческого письма под названием CTRL-RAG, которая выбирает соответствующие разделы из большого набора данных произведений фантастики и интегрирует их в процесс генерации. CTRL-RAG продемонстрировал способность генерировать связные и стилистически последовательные истории, демонстрируя потенциал RAG в творческих приложениях.
Case Studies
несколько научных статей и проектов продемонстрировали эффективность RAG в различных областях.
например, Lewis и др. (2020) ввели RAG-фреймворк и применили его к открытому доме вопросов и ответов, достигая состояния искусства на бенчмарке Natural Questions. (Lewis и др.) они выделили проблемы эффективного выбора и важность finetuning генетической модели на выбранных разделах.
В другом исследовании Petroni и др. (2021) применили RAG к задаче проверки фактов, продемонстрировав ее способность находить соответствующие доказательства и генерировать точные вердикты. Они продемонстрировали потенциал RAG в борьбе с дезинформацией и улучшении надежности информационных систем.
Влияние RAG на пользовательский опыт и бизнес-метрики было значительным. Благодаря提供更 точных и информативных ответов, системы на основе RAG улучшили удовлетворение пользователей и ихEngagement. (LlamaIndex и MyScale)
В случае конверсионных агентов RAG позволило обеспечить более естественные и связанные взаимодействия, что привело к увеличению удержанности пользователей и их лояльности. (LlamaIndex и MyScale) В области творческого письма RAG обладает потенциалом оптимизировать процессы создания содержания и генерировать новые идеи, экономя время и ресурсы для бизнесов.
Как вы можете видеть, практические приложения RAG охватывают широкий спектр областей, от решения вопросов и диалоговых систем до обобщения и творческого письма. Вы используете силу ретривэля и генерации, RAG продемонстрировала значительные улучшения в точности, значимости иEngagement пользователей.
Когда как данные поля продолжают развиваться, мы можем ожидать более инновационных применений RAG, изменяя способ, как мы взаимодействуем с информацией и создаем ее в различных контекстах.
4.2 RAG для языков с ограниченными ресурсами и многоязычных сред
Об использовании возможностей Поддержки-Augmented Генерации (RAG) для языков с ограниченными ресурсами и многоязычных сред это не просто возможность – это необходимость. Благодаря тому, что в мире говорят более чем 7000 языков, многие из которых не имеют значительных дигитальных ресурсов, задача ясна: как мы можем убедиться, что эти языки не будут оставлены в эпоху цифровизации?
Перевод как мост
Одна из эффективных стратегий – это перевод источников на язык с более обильными ресурсами перед индексацией. Этот подход использует обширные корпуса, доступные в языках, таких как Английский, значительно улучшая точность и значимость поиска.
Переводя документы на Английский, вы можете воспользоваться огромными ресурсами и передовыми техниками поиска, уже разработанными для языков с высокими ресурсами, тем самым улучшая производительность систем RAG в контекстах с низким уровнем ресурсов.
Мультиязычные embeddings
Последние достижения в области мультиязычных слов embeddings предлагают другое перспективное решение. Создавая общие пространства embeddings для многих языков, вы можете улучшить кросс-лингвистические показатели даже для очень малоисследованных языков.
Исследования показали, что включение промежуточных языков с качественными embeddings может наполнить пробел между дальними языковыми парами, улучшая общее качество мультиязычных embeddings.
Этот метод не только улучшает точность поиска, но и обеспечивает контекстуальную соответствие и языковую согласованность генерируемого содержимого.
Федеративное обучение
Федеративное обучение предлагает новый подход для преодоления ограничений разделения данных и языковых различий. За счет微调 моделей на децентralзированных источниках данных можно сохранить конфиденциальность пользователей, улучшив performace модели на многих языках.
Этот метод показал 6,9% большую точность и 99% уменьшение размеров тренировочных параметров по сравнению с традиционными методами, делая его высокоэффективным и эффективным решением для мультиязычных RAG систем.
Уменьшение иллюзий
Одна из критических проблем при использовании RAG систем в мультиязычных сетях заключается в уменьшении иллюзий – экземпляры, когда модель генерирует фактически неверную или несоответствующую информацию.
Передовые RAG техники, такие как Modular RAG, вводят новые модули и стратегии для fine-tuning, чтобы решить эту проблему. Благодаря постоянному обновлению базы знаний и использованию строгих оценчивающих метрик вы можете значительно снизить частоту вспышек иллюзий и обеспечить, чтобы генерируемое содержимое было как можно более точным и надежным.
Практическое внедрение
Чтобы эффективно внедрять these стратегии, рассмотрите следующие практические шаги:
- Использование переводов: Переведите документы на языках с низким ресурсом на высоко ресурсный язык, такой как английский, перед индексацией.
- Использование мультиязычных embeddings: Включите промежуточные языки с качественными embeddings, чтобы улучшить кросс-языковые показатели.
- Внедрение федерального обучения: refined models на распределенных данных источниках, чтобы улучшить производительность, сохраняя при этом конфиденциальность.
- Ограничение halucinations: Использовать передовые техники RAG и непрерывные обновления базы знаний для обеспечения фактической точности.
Приняв эти стратегии, вы можете значительно улучшить производительность систем RAG в условиях низких ресурсов и мультиязычных сетях, обеспечивая, чтобы каждый язык не оставался за бортом цифрового перехода.
Глава 5: Техники оптимизации
В этой главе мы исследуем передовые методы ретирования, которые лежат в основе эффективности систем Retrieval-Augmented Generation (RAG). Мы исследуем, как оптимизация блоков, интеграция метаданных, графовый индекс, алгоритмы соответствия, гибридный поиск и повторное рендеринг улучшают точность, значимость и полноту информационного ретирования.
При понимании этих передовых методов вы получите замечания о том, как системы RAG развиваются от простых поисковых систем до умных информационных поставщиков, способных понимать сложные запросы и доставлять точные, контекстуально соответствующие ответы.
5.1 Передовые техники ретирования для оптимизации систем RAG
Системы Retrieval Augmented Generation (RAG) изменяют способ, которым мы доступаемся к информации и используем ее.
Давайте более глубоко заглянем в передовые техники поиска, которые позволяют системам RAG обеспечивать точные, контекстуально учитываемые и всесторонние ответы.
Оптимизация блоков: максимизация значимости через гранулярный поиск
В мире систем RAG очень большие документы могут быть затруднительны. Оптимизация блоков решает эту проблему, разбивая обширные тексты на более маленькие, более управляемые блоки, называемые блоками. Эта гранулярность позволяет системам поиска精准找准與查询词相符的特定文本部分,从而提高准确性和效率。
Искусство оптимизации блоков заключается в определении идеального размера блока и Overlap. Блок, слишком маленький, может не хватать контекста, а слишком большой может ослабить значимость. Dynamic chunking (техника, которая адаптирует размер блока на основе структуры и семантики содержимого), обеспечивает, чтобы каждый блок был cohérent и имел значение в контексте.
Интеграция метаданных: использование силы информационных метки
Метаданные, часто незамеченная информация, которая сопровождает документы, может быть золотом для систем поиска. При интеграции метаданных, таких как тип документа, автор, дата публикации и тег темы, системы RAG могут выполнять более специфические поиски.
СамоQuery поиск, техника, внедренная с помощью интеграции метаданных, позволяет системе генерировать дополнительные запросы на основе первоначальных результатов. Это итеративный процесс, который улучшает поиск, обеспечивая, чтобы извлеченные документы не только соответствовали запросу, но и соответствовали специфическим требованиям пользователя и его контекстуальным потребностям.
Продвинутые структуры индексирования: графовые сети для сложных запросов
Традиционные методы индексации, такие как обратный индекс и плотные векторные кодировки, имеют ограничения, когда дело идет о сложных запросах, включающих множество субъектов и их связи. Графовые индексы предлагают решение, организуя документы и их связи в структуру графа.
Эта графовая организация позволяет эффективно проходить по связям и извлекать связанные документы, даже в сложных сценариях.Hiermonische индексация и приблизительный поиск ближайших соседей дополняют масштабность и скорость системы графового извлечения.
Сочетания алгоритмов анализа: обеспечение точности и уменьшение иллюзорных данных
Целью RAG систем является обеспечение точной информации. Techniques such as counterfactual training address this concern. By exposing the model to hypothetical scenarios, counterfactual training teaches it to distinguish between real-world facts and generated information, thereby reducing hallucinations.
В многокомпонентных RAG системах, которые интегрируют информацию из различных источников, таких как текст и изображения, играет ключевая роль противоречивая обучение. This technique aligns the semantic representations of different data modalities, ensuring that the retrieved information is coherent and contextually integrated.
Гибридный поиск: смешение точности ключевых слов с пониманием семантики
Гибридный поиск сочетает лучшие качества обеих миров: скорость и точность ключевых слов и понимание семантики векторного поиска. Initally, a keyword-based search quickly narrows down the pool of potential documents.
Позднее, векторно-базированный поиск развивает результаты на основе семантической схожести. Этот подход особенно эффективен, когда чётких соотношений ключевых слов важно, однако также требуется более глубокое понимание намерения запроса для точного извлечения.
Переранкировка: Развитие Relevance для оптимального ответа
В заключительной стадии извлечения вступает переранкировка, чтобы тонко настроить результаты. Машинные обучающие модели, такие как кросс-энкодеры, пересматривают оценки relevance для найденных документов. Процессуя запрос и документы вместе, эти модели приобретают более глубокое понимание их связи.
Этот насыщенный сравнение обеспечивает, чтобы самые лучшие документы действительно соответствовали запросу пользователя и контекста, обеспечивая более удовлетворительный и информативный опыт поиска.
Сила систем RAG заключается в их способности гладко извлекать и представлять информацию. Применяя эти продвижущие техники — улучшение блоков, интеграция метаданных, индексирование на основе графов, приёмы аллинга, гибкий поиск и переранкировка — системы RAG становятся не просто поисковыми системами. Они развиваются в интеллектуальные информационные поставщики, способные понимать сложные запросы, различать нюансы и доставлять точные, релевантные и доверительные ответы.
Глава 6: Challenge и Innovation
В этой главе более подробно разбираются критические вызовы и будущие направления разработки и внедрения систем Retrieval-Augmented Generation (RAG).
Мы исследуем сложности оценки систем RAG, включая необходимость всесторонних метрик и адаптивных схем для оценки их эффективности сprecision. Мы также рассматриваем этические аспекты, такие как уменьшение неравенства и справедливость в информационном поиске и генерации.
Мы также рассматриваем важность акселерации оборудования и эффективных стратегий развертывания, подчеркивая использование специального оборудования и оптимизационных средств, таких как Optimum, для улучшения Performances и масштабности.
Прояснив эти проблемы и исследовав возможные решения, этот раздел предоставляет исчерпывающий план для дальнейшего развития и ответственного применения технологии RAG.
6.1 Challdnges и будущие направления
Системы RAG Retrieval-Augmented Generation (RAG) продемонстрировали значительный потенциал для улучшения точности, значимости и последовательности созданного текста. Однако развитие и развертывание систем RAG также представляет значительные проблемы, которые нужно решать, чтобы воспользоваться всеми возможностями их потенциала.
“Оценка RAG систем thus涉及 consideration quite a few specific components и сложности общей оценки системы.” (Salemi et al.)
Проблемы в оценке систем RAG
Одним из основных технических вызовах в RAG является обеспечение эффективного извлечения реlevantных сведений из крупномасштабных баз знаний. (Salemi et al. и Yu et al.)
По мере того как размер и разнообразие источников знаний продолжает увеличиваться, развитие масштабируемых и устойчивых механизмов извлечения становится все более важным. Необходимо исследовать такие техники, как иерархическое индексирование, аproximate nearest neighbor search и адаптивные стратегии извлечения для оптимизации процесса извлечения.
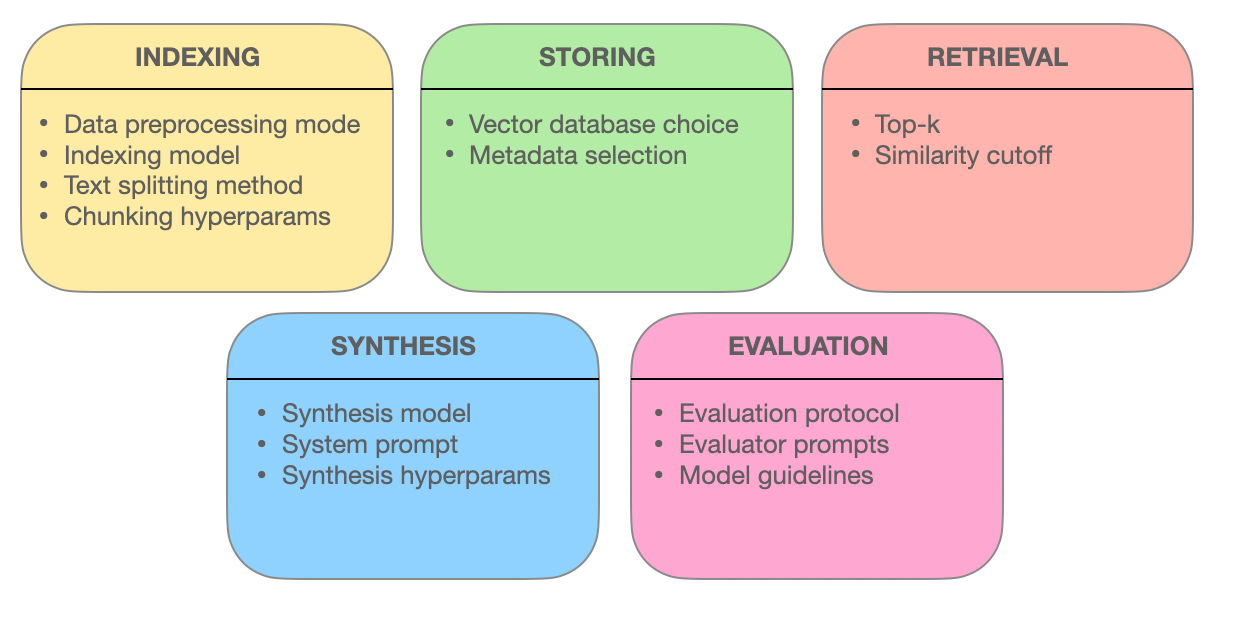
Some of the elements involved in a RAG System – miro.medium.com
Another significant challenge is mitigating the issue of hallucination, where the generative model produces factually incorrect or inconsistent information.
For example, a RAG system might generate a historical event that never occurred or misattribute a scientific discovery. While retrieval helps to ground the generated text in factual knowledge, ensuring the faithfulness and coherence of the generated output remains a complex problem.
For instance, a RAG system can retrieve accurate information about a scientific discovery from a reliable source like Wikipedia, but the generative model might still hallucinate by combining this information incorrectly or adding non-existent details.
Разрабатывая эффективные механизмы для обнаружения и предотвращения галлюцинаций, является активной областью исследований. Техники, такие как проверка фактов с использованием внешних баз данных и проверка согласованности через ссылки на множество источников, исследуются. Эти методы направлены на то, чтобы обеспечить, чтобы созданный контент оставался точным и надежным, несмотря на врожденные проблемы с согласованием процессов извлечения и генерации.
Интеграция различных источников знаний, таких как структурированные базы данных, неструктурированный текст и мультимодальные данные, предполагает дополнительные проблемы для систем RAG. (Юй и al. и Зиллиз) Согласование представлений и семантики между различными модальностями данных и форматами знаний требует сложных техник, таких как кросс-модульное внимание и внедрение графов знаний. Убедиться в совместимости и взаимодействии различных источников знаний важно для эффективной работы систем RAG. (Зиллиз)
Системы RAG, кроме технических проблем, также вызывают важные этические рассмотрения. Обеспечение беспристрастного и справедливого извлечения и генерации информации является критическим вопросом. Системы RAG могут неверно усилить предрасположенности, присутствующие в тренировочных данных или источниках знаний, ведущие к дискриминационным или вводящим в заблуждение выводам. (Салеми и др. и Банафа)
Разработка методов для обнаружения и смягчения предрасположенностей, таких как адверсариальная тренировка и извлечение с учетом справедливости, является важным направлением исследований. (Банафа)
Направления будущих исследований
Чтобы решить проблемы оценки систем RAG, можно исследовать несколько потенциальных решений и направлений исследований.
Разработка комплексных метрик оценки, которые учитывают взаимодействие между точностью извлечения и качеством генерации, является важной. (Салеми и др.)
Метрики, оценивающие Relevance, Coherence и Factual Correctness Generated Text, рассмотрев эффективность компонента ретивации, необходимо установить. (Salemi et al.) Это требует holistic approach, идущей beyond traditional metrics like BLEU and ROUGE и включающей human evaluation и task-specific measures.
Exploring adaptive and real-time evaluation frameworks is another promising direction.
RAG systems operate in dynamic environments where the knowledge sources and user requirements may evolve over time. (Yu et al.) Developing evaluation frameworks that can adapt to these changes and provide real-time feedback on the system’s performance is essential for continuous improvement and monitoring.
This may involve techniques such as online learning, active learning, and reinforcement learning to update the evaluation metrics and models based on user feedback and system behavior. (Yu et al.)
Сотрудничество между исследователями, профессионалами отрасли и экспертами в области является необходимым для продвижения области оценки RAG. Установление стандартизированных базовых значений, наборов данных и протоколов оценки может облегчить сравнение и воспроизводимость систем RAG в различных областях и приложениях. (Salemi et al. и Banafa)
Взаимодействие с заинтересованными сторонами, включая конечных пользователей и политических деятелей, является ключевым для обеспечения того, что разработка и внедрение систем RAG соответствуют ценностям общества и принципам этики. (Banafa)
Так как системы RAG продемонстрировали огромный потенциал, решение проблем их оценки является важным для их широкого распространения и доверия. Разработка всесторонних меторик оценки, исследование адаптивных и реального времени фреймворков оценки и стимуляция сотрудничества позволят построить более надежные, небиased и эффективные системы RAG.
По мере того, как данная область продолжает развиваться, важно сосредотачивать исследовательские усилия, которые не только улучшают технические возможности RAG, но и обеспечивают ответственное и этическое размещение их в реальных приложениях.
6.2 Акселерация оборудования и эффективное развертывание систем RAG
Работа с ускорениями аппаратных средств играет ключевую роль в эффективной установке систем RAG (Retrieval-Augmented Generation). Отправив ресурсоемкие задачи на специализированное оборудование, вы можете существенно улучшить производительность и масштабность ваших моделей RAG.
Использование Специального Оборудования
Оснастка Optimum специально для оптимизации аппаратных средств приносит значительные пользы. Например, развертывание систем RAG на процессорах Habana Gaudi может привести к заметному уменьшению задержки вference, а оптимизации с помощью Intel Neural Compressor могут далее улучшить показатели задержки. Оборудование AWS Inferentia, оптимизированное через Optimum Neuron, может улучшить возможности throughput, делая вашу систему RAG более реагирующей и эффективной.
Оптимизация Utilization ресурсов
Эффективное использование ресурсов важно. Оптимизации Optimum ONNX Runtime могут привести к более эффективному использованию памяти, а API BetterTransformer могут улучшить использование CPU и GPU. Эти оптимизации гарантируют, что ваша система RAG работает с максимальной эффективностью, снижая операционные расходы и улучшая производительность.
Скалярность и гибкость
Optimum поддерживает гладкий переход между различными ускорителями аппаратных средств, обеспечивая динамическую скалярность. Эта многоаппаратная поддержка позволяет вам адаптироваться к различным вычислительным требованиям без значительной переконфигурации. Кроме того, функции уменьшения размера моделей и упрощения Optimum могут способствовать более эффективному использованию моделей, сделав развертывание легче и более экономичным.
Примеры исследований и реаль-мирных приложений
Рассмотрим применение Optimum в области медицинской информации. Благодаря использованию оптимизаций, специфичных для hardware, системы RAG эффективно обрабатывают большие наборы данных, обеспечивая точные и своевременные методы информационного извлечения. Это не только улучшает качество обслуживания здравоохранения, но и повышает общее user experience.
Практические шаги для внедрения
- Выбор соответствующего оборудования: Выберите акселераторы Habana Gaudi или AWS Inferentia на основе ваших специфических требований к производительности.
- Использование инструментов оптимизации: Implement Optimum’s optimization tools to enhance latency, throughput, and resource utilization.
- Обеспечение масштабности: использование многооборудовательной поддержки для динамического масштабирования вашей системы RAG, когда это необходимо.
- Оптимизация размера модели: использовать квантизацию моделей и удаление для уменьшения накладных расходов на вычисления и облегчения установки.
При интеграции этих стратегий вы можете значительно улучшить производительность, масштабность и эффективность ваших систем RAG, чтобы они были хорошо подготовлены для обработки сложных, реальных мирных применений.
Заключение: потенциал трансформации RAG
Ретирование-Augmented Generation (RAG) представляет собой трансформационную парадигму в природном языковой обработке, гармонично интегрируя силу информационного ретирования с генеративными возможностями крупных моделей языка.
Использование внешних источников знаний позволило системам RAG доказать значительные улучшения в точности, значимости и связанности генерируемого текста на различных приложениях, от ответов на вопросы и диалоговых систем до обобщения и творческого письма.
Развитие языковых моделей, от ранних систем на основе правил до современных нейронных архитектур, таких как BERT и GPT-3, создало пространство для появления RAG. Ограничения чисто параметрической памяти в традиционных языковых моделях, такие как даты ограничения знаний и фактические несогласованности, эффективно решаются включением непараметрической памяти через механизмы ретровизации.
Основные компоненты систем RAG, ретровизаторы и генеративные модели, работают вместе для производства контекстуально значимых и фактически обоснованных результатов.
Ретровизаторы, использующие техники such as sparse and dense retrieval, эффективно ищут через крупные базы знаний наиболее pertinent information. Генеративные модели, использующие архитектуры, такие как GPT и T5, синтезируют выделенное содержание в cohesive and fluent text.
Стратегии интеграции, такие как конкатенация и перекрёстное внимание, определяют, как выделенная информация включается в процесс генерации.
Практические приложения RAG охватывают различные области, демонстрируя его потенциал революционизировать различные отрасли.
В вопросно-ответной сфере RAG значительно улучшил точность и значимость ответов, позволив более информативные и надежные методы информационного поиска. Диалогические системы выиграли от использования RAG, став более захватывающими и связными. Задачи суммаризации выиграли от интеграции соответствующей информации из нескольких источников, что улучшило качество и связность. Литературное творчество также было исследовано, и системы RAG генерируют оригинальные и стилистически последовательные истории.
Но развитие и оценка систем RAG также представляют значительные проблемы. Эффективный поиск в крупных базах знаний, смягчение иллюзий и интеграция различных модальностей данных являются среди технических препятствий, которые необходимо решить. Этические соображения, такие как обеспечение нейтральности и справедливого информационного поиска и генерации, важны для ответственного размещения систем RAG.
Чтобы полностью реализовать потенциал RAG, будущие исследовательские направления должны сосредоточиться на разработке всеобъемлющих метрик оценки, которые captuing взаимодействие между точностью ретрива и качеством генерации.
Адаптивные и реально-временные структуры оценки, которые могут обслуживать динамическую природу систем RAG, необходимы для непрерывного улучшения и мониторинга. Собрательные усилия между исследователями, профессионалами отрасли и экспертами в области являются необходимыми для установления стандартных счетчиков, наборов данных и протоколов оценки.
Как исследования в области RAG продолжают развиваться, она обещает переменить способ, которым мы взаимодействуем с информацией и создаем ее. Используя силу возвращения и создания, системы RAG имеют потенциал революционизировать различные области, от информационного поиска и диалоговых агентов до создания контента и открытия знаний.
Ретирование-усиленное генеration является важным моментом в пути к более умной, точной и контекстуально значимой генерации языка.
Перекрывая различие между параметрической и непараметрической памятью, системы RAG открыли новые возможности для природного языкового процесса и его применений.
По мере прогресса исследований и решения проблем мы можем ожидать, что RAG будет играть все более важную роль в формировании будущего человеко-машинного взаимодействия и генеration знаний.
о авторе
Вахе Асланян здесь, в сердце компьютерных наук, наук о данных и AI. Посетите vaheaslanyan.com, чтобы увидеть портфолио, которое является свидетельством точности и прогресса. Моя работа перекрывает пробел между полностю разработанной разработкой и оптимизацией продуктов AI, проdriven by решением проблем в новых способах.
У меня есть резюме, в котором содержится информация о запуске ведущего буткапета по данным наукам и работе с ведущими специалистами в отрасли, и моя постоянная главная цель – это поднятие уровня технического образования до универсальных стандартов.
Как можно поглублее окунуться?
После изучения этого руководства, если вы хотите окунуться еще глубже и структурированное обучение – ваша стратегия, рассмотрите присоединиться к нам в LunarTech , у нас предлагаются индивидуальные курсы и буткап в области данных наук, машинного обучения и AI.
Мы предоставляем исчерпывающий program, который предлагает глубокое понимание теории, практическое применение, обширные упражнения и настраиваемую подготовку к интервью, чтобы установить успех на своем этапе.
Вы можете посмотреть на наш Ultimate Data Science Bootcamp и присоединиться к бесплатному тестовому периоду, чтобы опробовать содержимое на своем опыте. Это принесло похвалу за то, что является одним из Лучших буткапов по data science на 2023 и был опубликован в авторитетных изданиях, таких как Forbes, Yahoo, Entrepreneur и другие. Это ваша возможность стать частью сообщества, которое процветает за счет инноваций и знаний. Вот приветственное сообщение!
Свяжитесь с мной

ЛунТехНовости
- Следуйте с мной на LinkedIn и получите большое количество бесплатных ресурсов по КС, ML и AI
- Посетите мой личный сайт
- Подпишитесь на мой Newsletter по Data Science и AI
Если вы хотите больше узнать о карьере в Data Science, Machine Learning и AI, и научиться как получить работу Data Science, вы можете скачать этот бесплатный Руководство по карьере в Data Science и AI.
Source:
https://www.freecodecamp.org/news/retrieval-augmented-generation-rag-handbook/