













Hibernate
Hibernate сам по себе не поддерживает полнотекстовый поиск. Он должен полагаться на поддержку движка базы данных или сторонние решения.
Расширение под названием Hibernate Search интегрируется с Apache Lucene или Elasticsearch (также существует интеграция с OpenSearch).
Postgres
Postgres обладает функциональностью полнотекстового поиска с версии 7.3. Хотя он не может конкурировать с поисковыми движками, такими как Elasticsearch или Lucene, он все же предлагает гибкое и надежное решение, которое может быть достаточным для удовлетворения ожиданий пользователей приложения — функции, такие как стемминг, ранжирование и индексация.
Мы кратко объясним, как можно выполнить полнотекстовый поиск в Postgres. Для получения более подробной информации, пожалуйста, обратитесь к документации Postgres. Что касается основного текстового сопоставления, наиболее важной частью является оператор мат @@.
Он возвращает true, если документ (объект типа tsvector) соответствует запросу (объект типа tsquery).
Порядок не имеет решающего значения для оператора. Таким образом, не имеет значения, ставим ли мы документ слева от оператора, а запрос справа или в другом порядке.
Для лучшей демонстрации мы используем таблицу базы данных под названием tweet.
create table tweet (
id bigint not null,
short_content varchar(255),
title varchar(255),
primary key (id)
)С такими данными:
INSERT INTO tweet (id, title, short_content) VALUES (1, 'Cats', 'Cats rules the world');
INSERT INTO tweet (id, title, short_content) VALUES (2, 'Rats', 'Rats rules in the sewers');
INSERT INTO tweet (id, title, short_content) VALUES (3, 'Rats vs Cats', 'Rats and Cats hates each other');
INSERT INTO tweet (id, title, short_content) VALUES (4, 'Feature', 'This project is design to wrap already existed functions of Postgres');
INSERT INTO tweet (id, title, short_content) VALUES (5, 'Postgres database', 'Postgres is one of the widly used database on the market');
INSERT INTO tweet (id, title, short_content) VALUES (6, 'Database', 'On the market there is a lot of database that have similar features like Oracle');Теперь давайте посмотрим, как выглядит объект tsvector для столбца short_content для каждой из записей.
SELECT id, to_tsvector('english', short_content) FROM tweet;Вывод:
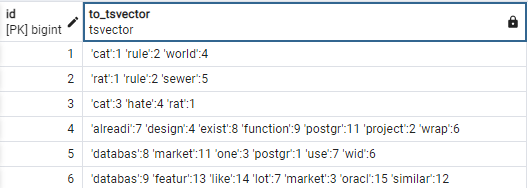
Вывод показывает, как to_tsvector преобразует столбец текста в объект tsvector для конфигурации текстового поиска ‘english‘.
Конфигурация текстового поиска
Первым параметром функции to_tsvector в приведенном выше примере было название конфигурации текстового поиска. В данном случае это было “english“. Согласно документации Postgres, конфигурация текстового поиска следующая:
… функциональность полнотекстового поиска включает возможность выполнять гораздо больше действий: пропускать индексацию определенных слов (стоп-слов), обрабатывать синонимы и использовать сложный парсинг, например, парсинг на основе чего-то большего, чем просто пробелы. Эта функциональность контролируется конфигурациями текстового поиска.
Итак, настройка является важной частью процесса и жизненно важной для наших результатов полнотекстового поиска. Для разных конфигураций движок Postgres может возвращать разные результаты. Это не обязательно должно быть так среди словарей для разных языков. Например, у вас может быть две конфигурации для одного языка, но одна из них игнорирует имена, содержащие цифры (например, некоторые серийные номера). Если мы передадим в наш запрос конкретный серийный номер, который является обязательным, мы не найдем никаких записей для конфигурации, которая игнорирует слова с цифрами. Даже если у нас есть такие записи в базе данных, пожалуйста, проверьте документацию по конфигурации для получения более подробной информации.
Текстовый запрос
Текстовый запрос поддерживает такие операторы, как & (AND), | (OR), ! (NOT) и <-> (FOLLOWED BY). Первые три оператора не требуют более глубокого объяснения. Оператор <-> проверяет, существуют ли слова и расположены ли они в определенном порядке. Таким образом, например, для запроса “rat <-> cat” мы ожидаем, что слово “cat” будет существовать, за которым следует “rat”.
Примеры
- Содержимое, содержащее крысу и кошку:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Rat & cat');
- Содержимое, содержащее базу данных и рынок, и рынок является третьим словом после базы данных:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database <3> market');
- Содержимое, содержащее базу данных, но не Postgres:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database & !Postgres');
- Содержание, включающее Postgres или Oracle:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Postgres | Oracle');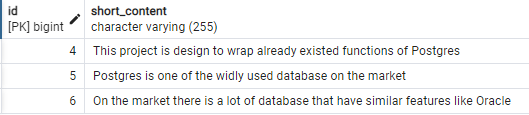
Оберточные Функции
Одна из оберточных функций, создающих текстовые запросы, уже упоминалась в этой статье, а именно to_tsquery. Существуют и другие подобные функции, такие как:
plainto_tsqueryphraseto_tsquerywebsearch_to_tsquery
plainto_tsquery
Функция plainto_tsquery преобразует все переданные слова в запрос, где все слова объединяются с оператором & (AND). Например, эквивалентом plainto_tsquery('english', 'Rat cat') является to_tsquery('english', 'Rat & cat').
Для следующего использования:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ plainto_tsquery('english', 'Rat cat');Мы получаем результат ниже:

phraseto_tsquery
Функция phraseto_tsquery преобразует все переданные слова в запрос, где все слова объединяются с оператором <-> (FOLLOW BY). Например, эквивалентом phraseto_tsquery('english', 'cat rule') является to_tsquery('english', 'cat <-> rule').
Для следующего использования:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ phraseto_tsquery('english', 'cat rule');Мы получаем результат ниже:

websearch_to_tsquery
Функция websearch_to_tsquery использует альтернативный синтаксис для создания корректного текстового запроса.
- Нецитированный текст: Преобразует часть синтаксиса таким же образом, как и
plainto_tsquery - Цитируемый текст: Преобразует часть синтаксиса таким же образом, как и
phraseto_tsquery - ИЛИ: Преобразует в “
|” (ИЛИ) оператор - “
-“: То же, что и “!” (НЕ) оператор
Например, эквивалент websearch_to_tsquery('english', '"cat rule" or database -Postgres') – это to_tsquery('english', 'cat <-> rule | database & !Postgres').
Для следующего использования:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ websearch_to_tsquery('english', '"cat rule" or database -Postgres');Мы получаем результат ниже:

Поддержка Postgres и Hibernate нативными средствами
Как упоминается в статье, Hibernate сам по себе не имеет поддержки полнотекстового поиска. Ему приходится полагаться на поддержку движка базы данных. Это означает, что мы можем выполнять нативные SQL-запросы, как показано в примерах ниже:
plainto_tsquery
public List<Tweet> findBySinglePlainQueryInDescriptionForConfigurationWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ plainto_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}websearch_to_tsquery
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescriptionWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ websearch_to_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}Hibernate с библиотекой posjsonhelper
Библиотека posjsonhelper – это проект с открытым исходным кодом, который добавляет поддержку запросов Hibernate для функций JSON PostgreSQL и полнотекстового поиска.
Для проекта Maven нам необходимо добавить следующие зависимости:
<dependency>
<groupId>com.github.starnowski.posjsonhelper.text</groupId>
<artifactId>hibernate6-text</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>6.4.0.Final</version>
</dependency>Для использования компонентов, существующих в библиотеке posjsonhelper, их необходимо зарегистрировать в контексте Hibernate.
Это означает, что должна быть указана конкретная реализация org.hibernate.boot.model.FunctionContributor. Библиотека предоставляет реализацию этого интерфейса, а именно com.github.starnowski.posjsonhelper.hibernate6.PosjsonhelperFunctionContributor.
A file with the name “org.hibernate.boot.model.FunctionContributor” under the “resources/META-INF/services” directory is required to use this implementation.
Существует другой способ регистрации компонента posjsonhelper, который можно осуществить программно. Чтобы узнать, как это сделать, проверьте эту ссылку.
Теперь мы можем использовать операторы полнотекстового поиска в запросах Hibernate.
PlainToTSQueryFunction
Это компонент, который оборачивает функцию plainto_tsquery.
public List<Tweet> findBySinglePlainQueryInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PlainToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Для конфигурации со значением 'english' код будет генерировать следующее выражение:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ plainto_tsquery('english', ?);PhraseToTSQueryFunction
Данный компонент обёртывает функцию phraseto_tsquery.
public List<Tweet> findBySinglePhraseInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PhraseToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Для конфигурации со значением 'english' код создаст следующее выражение:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ phraseto_tsquery('english', ?)WebsearchToTSQueryFunction
Этот компонент обёртывает функцию websearch_to_tsquery.
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescription(String phrase, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new WebsearchToTSQueryFunction((NodeBuilder) cb, configuration, phrase), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Для конфигурации со значением 'english' код создаст следующее выражение:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ websearch_to_tsquery('english', ?)HQL Запросы
Все упомянутые компоненты могут использоваться в HQL запросах. Чтобы узнать, как это делается, перейдите по ссылке.
Зачем использовать библиотеку posjsonhelper, когда можно использовать встроенный подход с Hibernate?
Хотя динамическое конкатенация строки, которая должна быть HQL или SQL запросом, может показаться простой, использование предикатов является лучшей практикой, особенно когда необходимо обрабатывать критерии поиска, основанные на динамических атрибутах вашего API.
Заключение
Как упоминалось в предыдущей статье, поддержка полнотекстового поиска в Postgres может быть хорошей альтернативой мощным поисковым движкам, таким как Elasticsearch или Lucene, в некоторых случаях. Это может избавить нас от необходимости добавлять сторонние решения в наш технологический стек, что также может усложнить задачу и добавить дополнительных расходов.
Source:
https://dzone.com/articles/postgres-full-text-search-with-hibernate-6