













Учить Linux является одним из самых ценных навыков в технологической индустрии. Он поможет тебе сделать things faster и более эффективно. Многие из самых мощных серверов и суперкомпьютеров мира работают на Linux.
While Empowering you in your current role, learning Linux can also help you transition into other tech careers like DevOps, Cybersecurity, and Cloud Computing.
In this Handbook, you’ll learn the basics of the Linux command line, and then transition to more advanced topics like shell scripting and system administration. Whether you are new to Linux or have been using it for years, this book has something for you.
Important Note: All examples in this book are demonstrated in Ubuntu 22.04.2 LTS (Jammy Jellyfish). Most command line tools are more or less the same in other distributions. However, some GUI applications and commands may differ if you are working on another Linux distribution.
Table of Contents
Часть 1: Введение в Linux
1.1. Начало работы с Linux
Что такое Linux?
Linux – это операционная система с открытым исходным кодом, основанная на операционной системе Unix. Она была создана Линусом Торвальдсом в 1991 году.
Открытый исходный код означает, что исходный код операционной системы доступен для общественности. Это позволяет любому изменять исходный код, настраивать его по собственному усмотрению и распределять новую операционную систему потенциальным пользователям.
为什么你应该了解Linux?
在当今数据中心的环境中,Linux и Microsoft Windows являются основными соперниками, и Linux обладает значительным процентом рынка.
以下是一些学习Linux的有力理由:
-
鉴于Linux托管的普及,您的应用程序很可能会托管在Linux上。因此,作为开发者学习Linux变得越来越有价值.
-
随着云计算成为常态,您的云实例很可能会依赖于Linux.
-
Linux为许多物联网(IoT)和移动应用程序的操作系统提供了基础.
-
在IT界,对于那些精通Linux的人来说,有很多机会.
Linux作为开源操作系统的意义何在?
Первое, что такое open source? Open source software – это программное обеспечение, исходный код которого является свободно доступным, позволяя любому использовать, изменять и распределять его.
Когда создается исходный код, он автоматически считается защищенным авторским правом, и его распространение регулируется владельцем авторского права через лицензии программного обеспечения.
В отличие от open source, проприетарное или закрытое программное обеспечение ограничивает доступ к своему исходному коду. Только создатели могут view, modify, or distribute it.
Linux, в основном, open source, что意味着 его исходный код является свободно доступным. Любой может view, modify, и распределять его. Разработчики со всего мира могут внести вклад в его улучшение. Это forms the foundation of collaboration, which is an important aspect of open source software.
Эта коллективная стратегия привела к широкому применению Linux на серверах, рабочих станциях, встроенных системах и мобильных устройствах.
Most interesting aspect of Linux being open source is that anyone can tailor the operating system to their specific needs without being restricted by proprietary limitations.
Chrome OS, used by Chromebooks, is based on Linux. Android, that powers many smartphones globally, is also based on Linux.
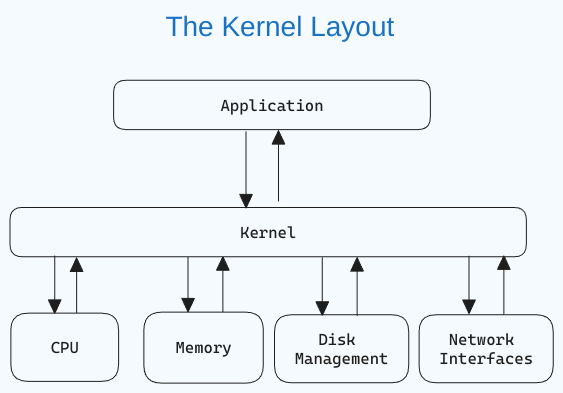
Что такое Linux Kernel?
The kernel is the central component of an operating system that manages the computer and its hardware operations. It handles memory operations and CPU time.
The kernel acts as a bridge between applications and the hardware-level data processing using inter-process communication and system calls.
Ядро загружается в память first при запуске операционной системы и остается там до закрытия системы. Оно ответственно за такие задачи, как управление дисками, управление задачами и управление памятью.
Если вы интересуетесь тем, каким выглядит ядро Linux, здесь на GitHub можно его посмотреть.
Что такое Linux-дистрибутив?
К этому моменту вы знаете, что вы можете использовать код ядра Linux, изменять его и создавать новые ядра. Вы можете дополнительно объединить различные утилиты и программное обеспечение, чтобы создать совершенно новую операционную систему.
Linux-дистрибутив или дистрибутив – это вариант операционной системы Linux, который включает ядро Linux, системные утилиты и другое программное обеспечение. Being open source, a Linux distribution is a collaborative effort involving multiple independent open-source development communities.
Что意味着 то, что дистрибутив происходит от другого? Если вы говорите, что дистрибутив “происходит” от другого, новый дистрибутив построен на базе или основе оригинального дистрибутива. Эта происхождение может включать использование того же системы управления пакетами (более о ней позже), версии ядра и иногда одних и тех же конфигурационных инструментов.
Сегодня существует тысячи Linux-дистрибутивов, из которых вы можете выбрать, предлагая различные цели и критерии для выбора и поддержки программного обеспечения, предоставляемого их дистрибутивом.
Дистрибутивы различаются друг от друга, но они, в основном, имеют несколько общих особенностей:
-
Дистрибутив состоит из ядра Linux.
-
Он поддерживает программы пользователя.
-
Распределение может быть небольшим и специализированным или включать тысячи программ с открытым исходным кодом.
-
Должны быть предоставлены средства для установки и обновления распределения и его компонентов.
Если вы посмотрите на Линейку времени дистрибутивов Linux, вы увидите два основных дистрибутива: Slackware и Debian. Несколько дистрибутивов произошли от них. Например, Ubuntu и Kali произошли от Debian.
Что такого особенного в производных? Существует множество преимуществ производных дистрибутивов. Производные дистрибутивы могут использовать стабильность, безопасность и большие репозитории программного обеспечения родительского дистрибутива.
Занимаясь строительством на уже существующей основе, разработчики могут сосредоточить свои усилия исключительно на специализированных функциях нового дистрибутива. Пользователи производных дистрибутивов могут воспользоваться документацией, поддержкой сообщества и ресурсами, уже доступными для родительского дистрибутива.
Некоторые популярные дистрибутивы Linux включают:
-
Ubuntu: одна из наиболее широко используемых и популярных дистрибутивов Linux. Она ориентирована на пользователя и рекомендована для начинающих. Узнайте больше о Ubuntu здесь.
-
Linux Mint: основан на Ubuntu, Linux Mint обеспечивает дружественный опыт использования с focus на поддержку мультимедиа. Узнайте больше о Linux Mint здесь.
-
Arch Linux: популярна среди опытных пользователей, Arch — легкая и гибкая дистрибутива, направленная на пользователей, которые предпочитают DIY подход. Узнайте больше о Arch Linux здесь.
-
Manjaro: основан на Arch Linux, Manjaro обеспечивает user-friendly опыт с установленным ПО и удобными инструментами управления системой. читать больше о Manjaro здесь.
-
Kali Linux: Kali Linux предоставляет комплект security tools и основное внимание уделено cybersecurity и黑客攻击. читать больше о Kali Linux здесь.
Как установить и получить доступ к Linux
Лучший способ научиться – это применять концепции по мере прохождения. В этом разделе мы узнаем, как установить Linux на вашей машине, чтобы вы могли следовать за ним. Вы также узнаете, как получить доступ к Linux на Windows-машине.
Я рекомендую вам следовать любой из методов, упомянутых в этом разделе, чтобы получить доступ к Linux, чтобы вы могли следовать за ним.
Установите Linux в качестве основной ОС
Установка Linux в качестве основной ОС является наиболее эффективным способом использовать Linux, так как вы можете использовать в полной мере силу вашей машины.
В этой секции вы узнаете, как установить Ubuntu, который является одним из наиболее популярных дистрибутивов Linux. Я пропустил другие дистрибутивы на данный момент, так как хочу сделать вещи простыми. Вы всегда можете исследовать другие дистрибутивы, когда у вас будет удобство с Ubuntu.
-
Шаг 1 – Скачать ISO Ubuntu: Зайдите на официальный сайт и скачайте файл ISO. Убедитесь, что вы выбрали стабильную версию, обозначенную как “LTS”. LTS означает Поддержка на длительPERIOD, что意味着 вы можете получать бесплатные обновления по безопасности и обслуживанию в течение длительного времени (обычно 5 лет).
-
Шаг 2 – Создать загрузочный USB-pendrive: Есть много программ, которые могут создать загрузочный USB-pendrive. Я рекомендую использовать Rufus, так как он довольно прост в использовании. Вы можете скачать его с здесь.
-
Шаг 3 – Загрузка с USB-pendrive:
Как только ваше USB-pendrive с загрузочной образом будет готов, вставите его и загрузите с ного. Меню загрузки зависит от вашего ноутбука. Вы можете выполнить поиск меню загрузки для вашей модели ноутбука в Google.
-
Шаг 4 – Следуйте указаниям. После того как процесс запуска начат, выберите
попробуйте или установите Ubuntu.
Процесс займёт некоторое время. Как только появится GUI, вы можете выбрать язык и раскладку клавиатуры и продолжить. Введите ваш логин и имя. Помните данные учетные записи, так как вам потребуется их использовать для входа в вашу систему и получения полноправности. Подождите, пока установка будет завершена.
-
Шаг 5 – Перезапустите компьютер: нажмите кнопку “Перезапустить сейчас” и выйдите из USB-pendrive.
-
Шаг 6 – Вход: Войдите с помощью ранее введенных учетных данных.
И так вы готовы! Теперь вы можете устанавливать приложения и настраивать вашу рабочую станцию.

Для продвинутой установки вы можете изучить следующие темы:
-
Разбиение диска.
-
Установка своповой памяти для включения спящего режима.
Доступ к терминалу
Важной частью этого руководства является изучение терминала, где вы будете выполнять все команды и наблюдать за тем, как происходит магия. Вы можете найти терминал, нажав клавишу “Windows” и введя “терминал”. Вы можете закрепить Терминал на доке, где находятся другие приложения, для удобного доступа.
💡 Сочетание клавиш для открытия терминала:
ctrl+alt+t
Вы также можете открыть терминал из папки. Щелкните правой кнопкой мыши там, где вы находитесь, и выберите “Открыть в терминале”. Это откроет терминал в том же пути.
Как использовать Linux на компьютере с Windows
Иногда вам может понадобиться одновременно использовать Linux и Windows. К счастью, есть способы, с помощью которых вы можете получить лучшее из обоих миров, не приобретая отдельные компьютеры для каждой операционной системы.
В этом разделе вы узнаете о нескольких способах использования Linux на компьютере с Windows. Некоторые из них основаны на браузере или облачных сервисах и не требуют установки операционной системы перед использованием.
Вариант 1: “Двойной запуск” Linux + Windows При двойном запуске вы можете установить Linux рядом с Windows на вашем компьтере, что позволяет вам выбрать which операционную систему использовать при старте.
Это требует разбиения вашего жесткого диска на разделы и установки Linux на отдельном разделе. С помощью этого подхода вы можете использовать только одну операционную систему в同一时间内.
Вариант 2: Использовать Windows Subsystem for Linux (WSL) Windows Subsystem for Linux обеспечивает слой совместимости, который позволяет вам выполнять Linux бинарные исполняемые файлы нативно в Windows.
Использование WSL имеет несколько преимуществ. Setup для WSL прост и не требует много времени. Он легче, чем VMs, где вам нужно выделять ресурсы от хост-машины. Вам не нужно устанавливать какой-либо ISO или виртуальный дисковый образ для Linux-машин, которые обычно являются большими файлами. Вы можете использовать Windows и Linux side by side.
Как установить WSL2
Сначала включите опцию Windows Subsystem for Linux в настройках.
-
Перейдите к Start. Ищите “Включить или выключить Windows features.”
-
Установите опцию “Windows Subsystem for Linux”, если она еще не выбрана.
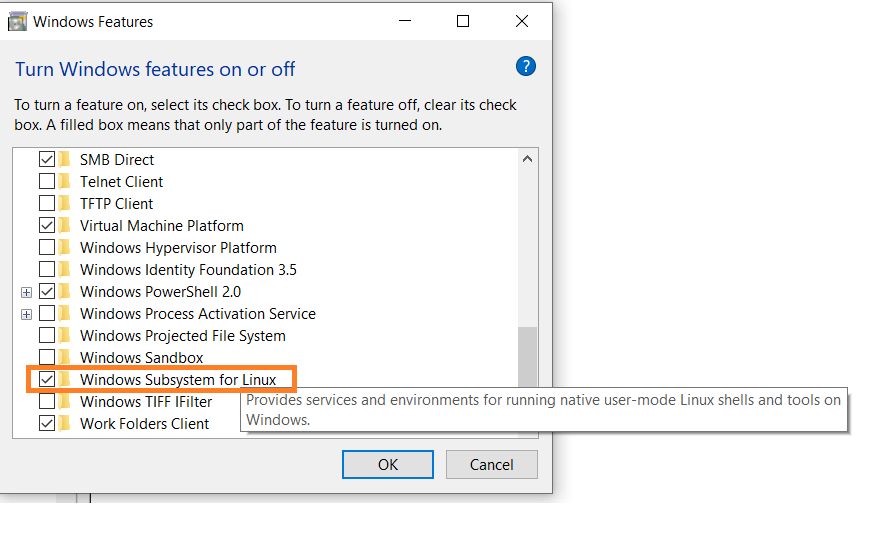
-
Потом, откройте свой COMMAND PROMPT и предоставьте команды для установки.
-
Открыть командную строку с правами администратора:

-
Введите следующую команду:
wsl --install
Вот результат:
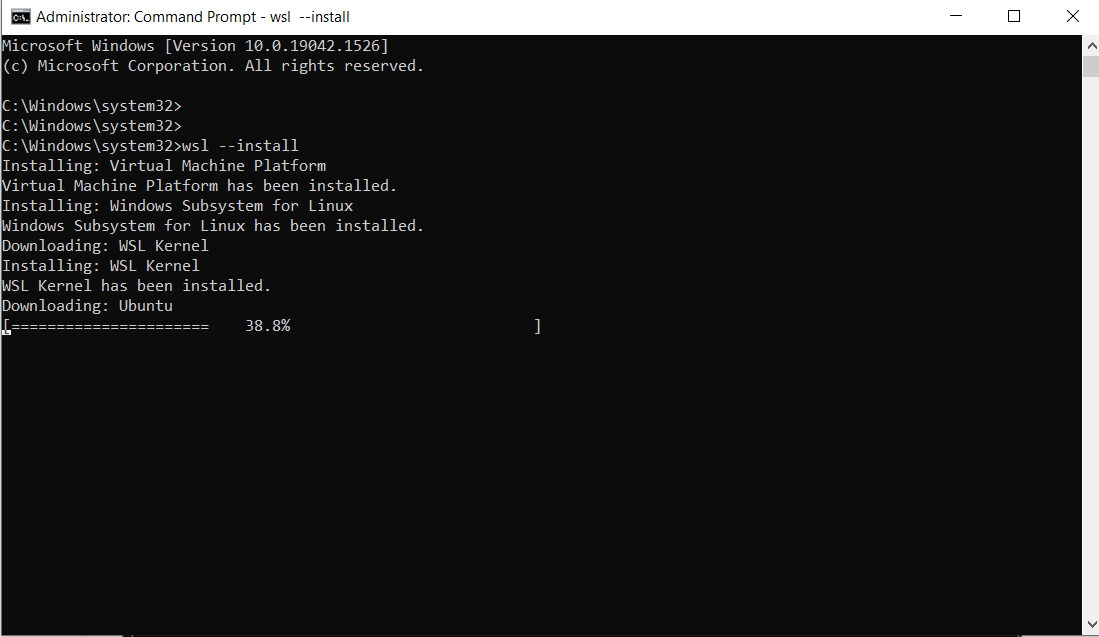
Примечание: по умолчанию будет установлен Ubuntu.
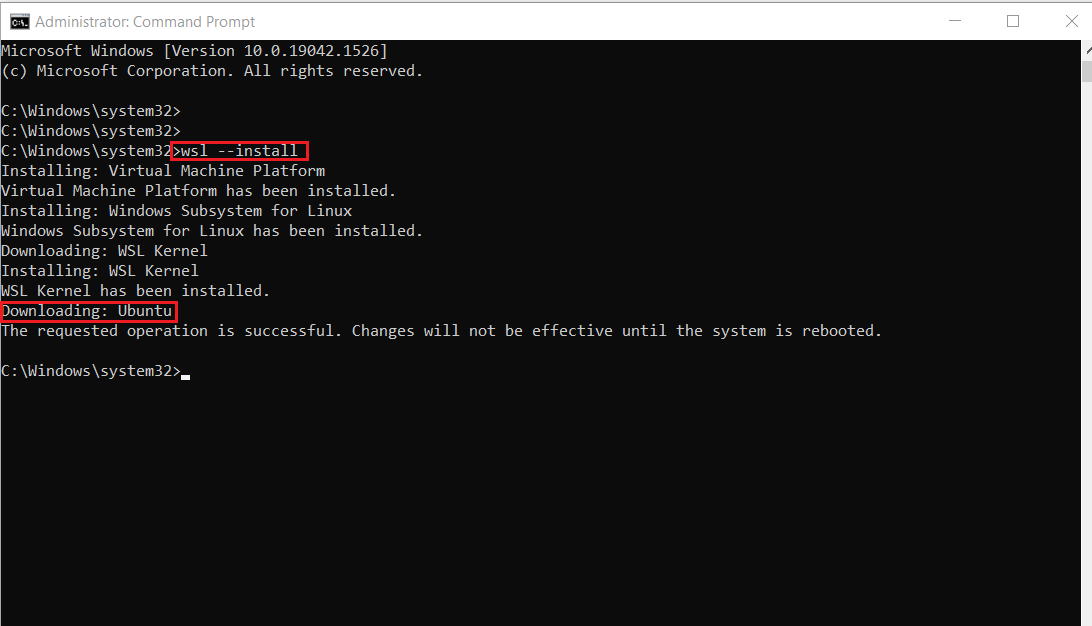
- По завершении установки вам потребуется перезапустить свой компьютер Windows. Таким образом, перезапустите свой компьютер Windows.
После перезапуска можете увидеть окно, похожее на следующее:
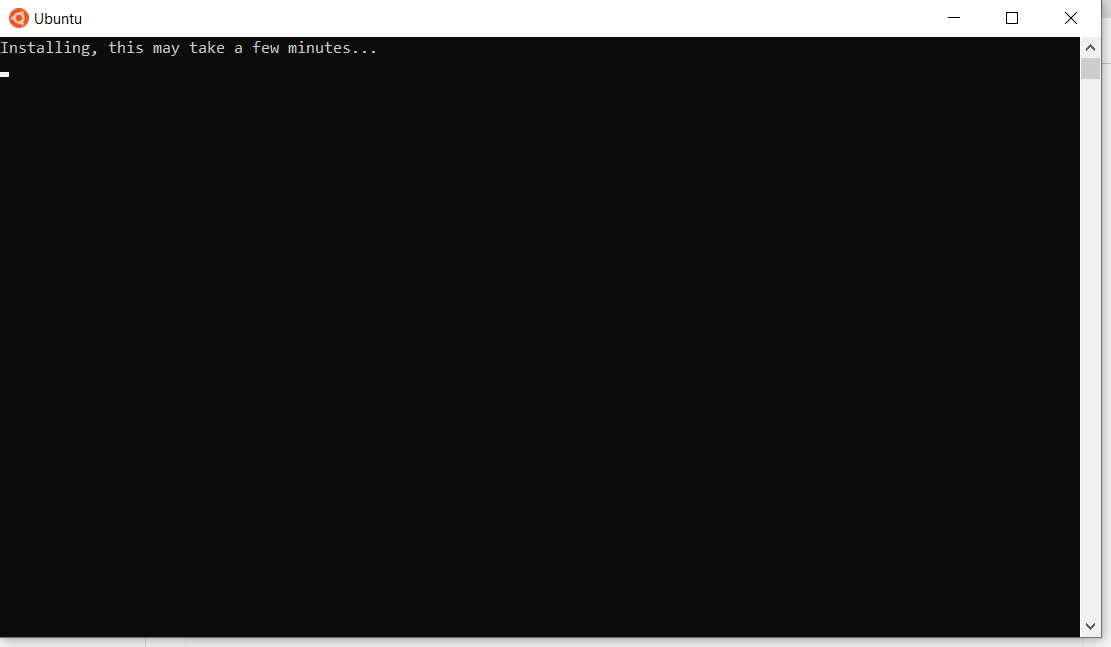
После завершения установки Ubuntu вам будет предложено ввести свой логин и пароль.

И это все! Вы готовы использовать Ubuntu.
Запустите Ubuntu, ищете его в меню “Пуск”.
И здесь мы уже запустили вашу инстанцию Ubuntu.

Вариант 3: использовать виртуальную машину (VM)
Виртуальная машина (VM) — это программное эмулирование физического компьютерного система. Она позволяет запускать множество операционных систем и приложений на одном физическом компьютере одновременно.
Вы можете использовать виртуализационное программное обеспечение, такое как Oracle VirtualBox или VMware, для создания виртуальной машины, запускающей Linux внутри среды Windows. Это позволяет запускать Linux в качестве гостевой операционной системы side by side с Windows.
Виртуальное программное обеспечение обеспечивает опции для аллокации и управления физическими ресурсами для каждой виртуальной машины, включая ядра ЦП, память, дисковое пространство и сетевую полосу пропуска. Вы можете настроить эти аллокации на основе требований гостевых операционных систем и приложений.
Вот некоторые из обычных опций, доступных для виртуализации:
Пункт 4: использовать браузерное решение
Браузерные решения особенно полезны для быстрой проверки, обучения или доступа к средам Linux с устройств, на которых Linux не установлен.
Вы можете использовать онлайновые редакторы кода или веб-базированные терминалы для доступа к Linux. Обратите внимание, что в этих случаях у вас обычно нет полных привилегий администратора.
Онлайн редакторы кода
Онлайн редакторы кода предлагают встроенные терминалы Linux. хотя их основной целью является кодирование, вы также можете использовать терминал Linux для выполнения команд и выполнения задач.
Replit является примером онлайн-редактора кода, где вы можете писать свой код и одновременно получать доступ к оболочке Linux.
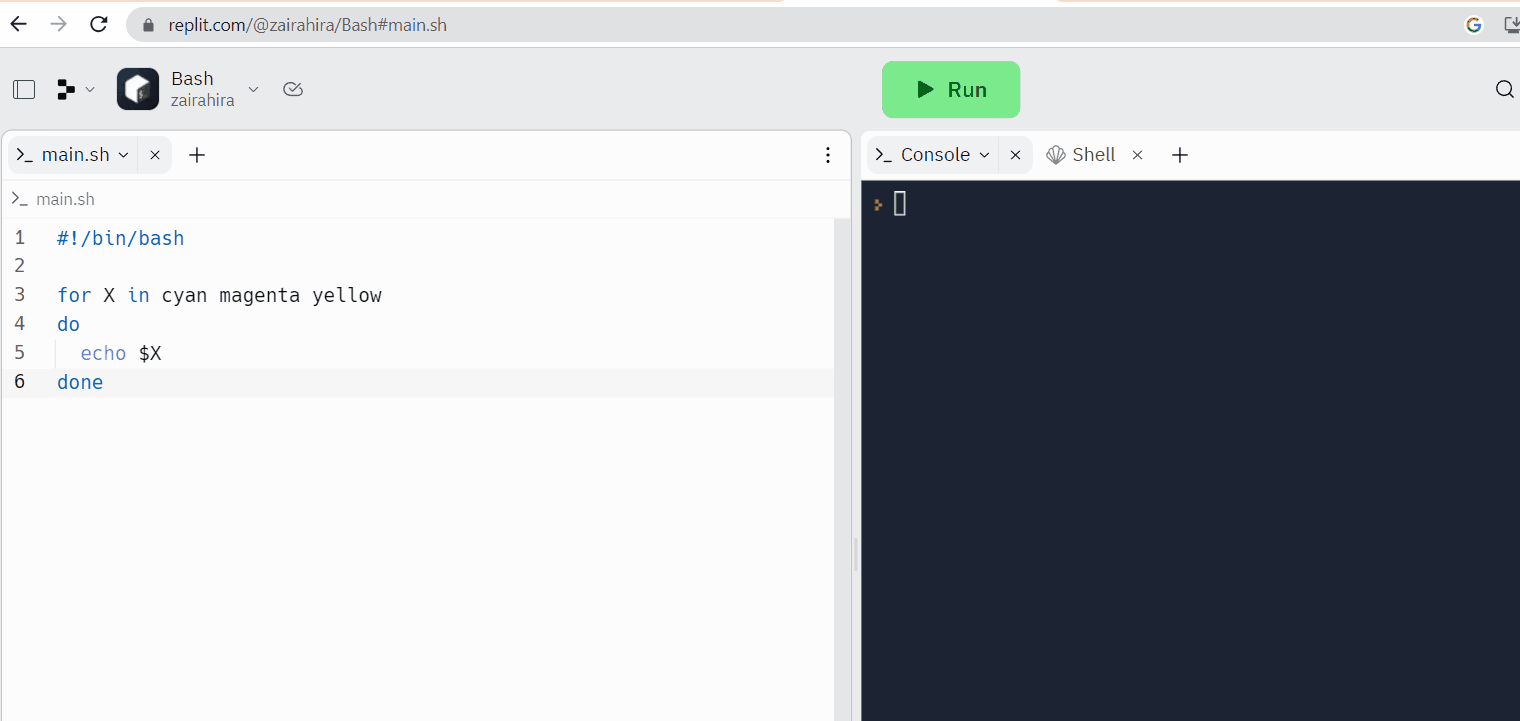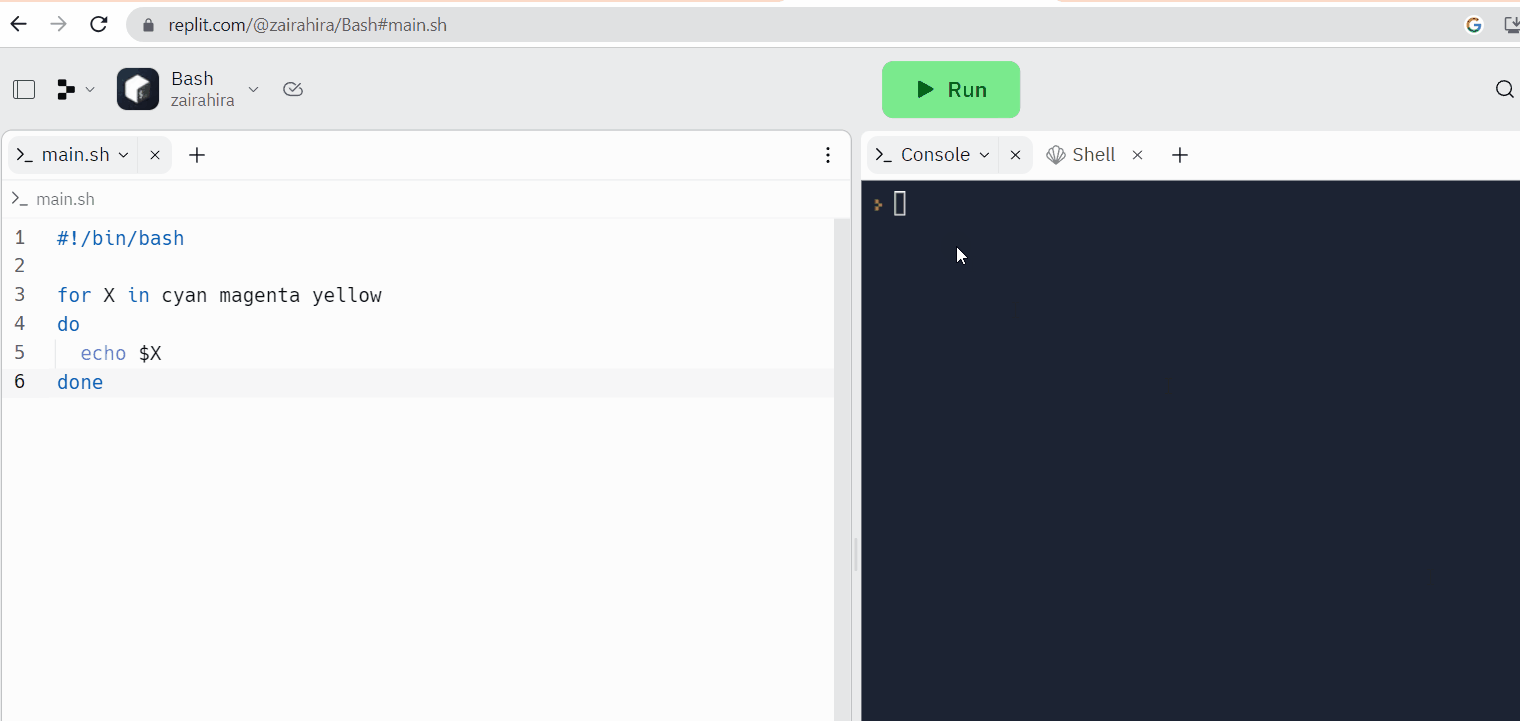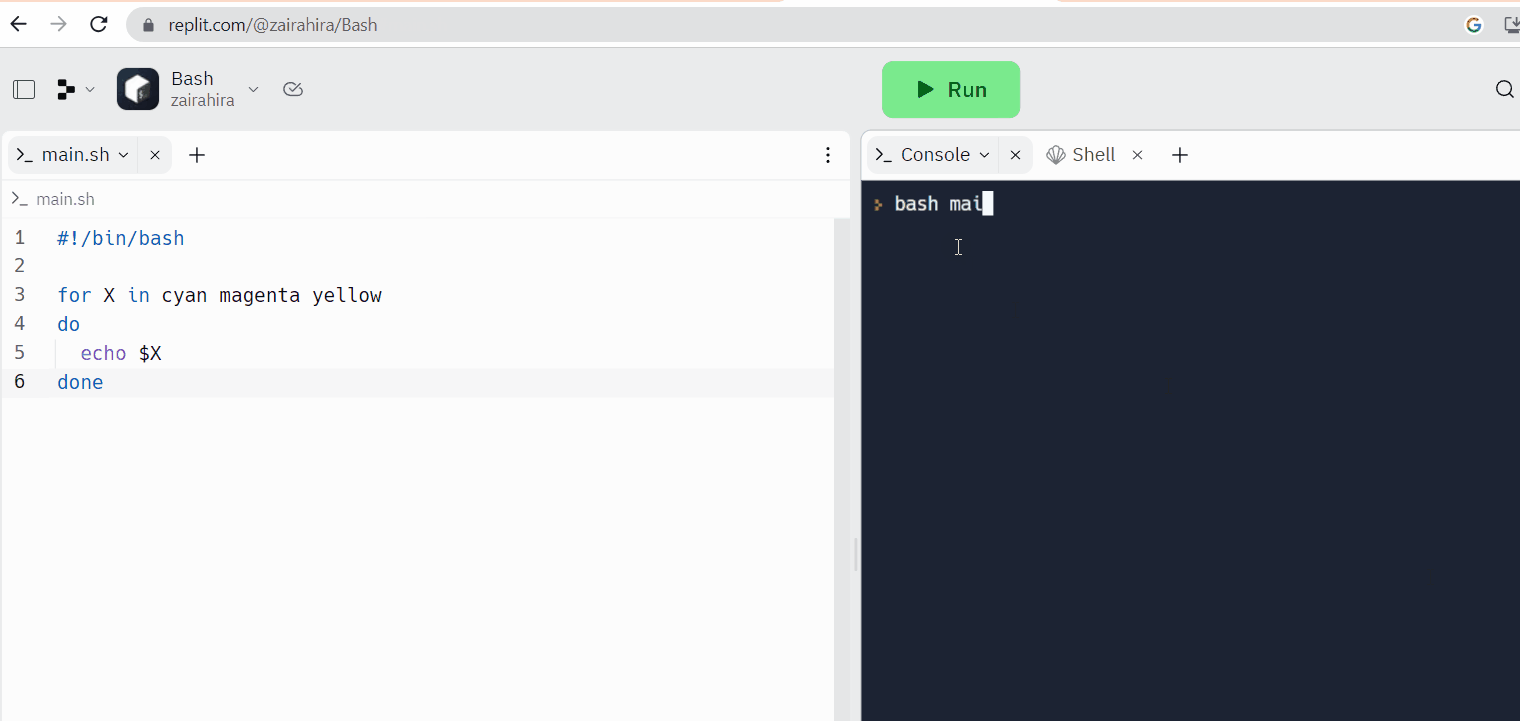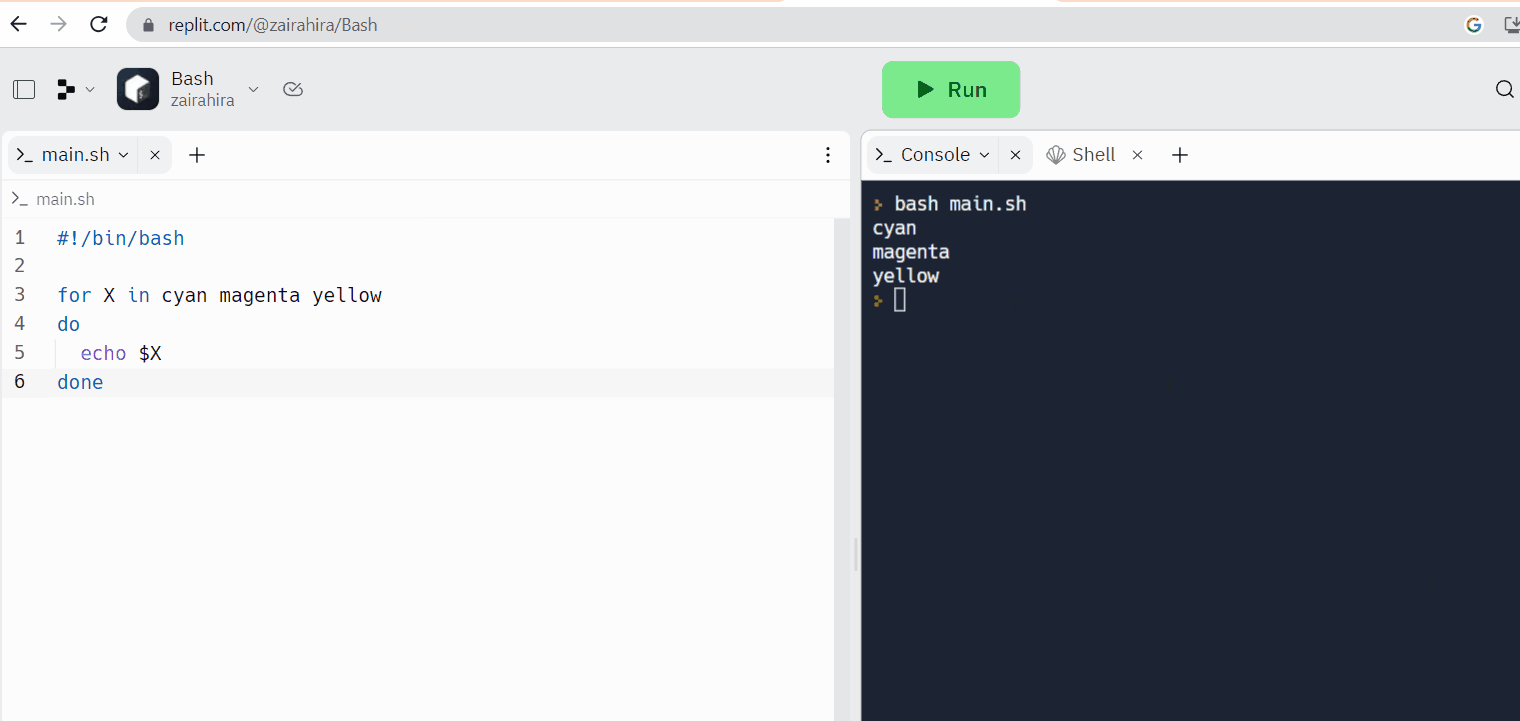
Веб-базированные терминалы Linux:
Веб-базированные терминалы Linux позволяют вам получить доступ к интерфейсу Linux командной строки прямо из вашего браузера. Эти терминалы предоставляют веб-базированный интерфейс для оболочки Linux, позволяя вам выполнять команды и работать с утилитами Linux.
Один из таких примеров – это JSLinux. screenshot ниже показывает готовую для использования среду Linux:
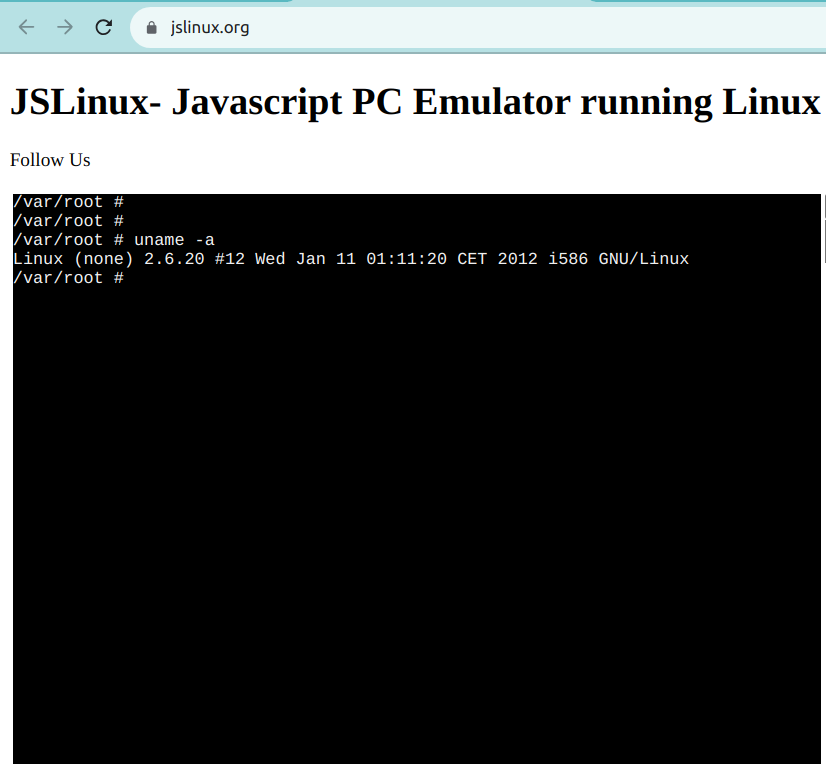
Пункт 5: Использовать облачное решение
Вместо того, чтобы запускать Linux напрямую на вашем компьютере с операционной системой Windows, вы можете рассмотреть возможность использования облачных средств Linux или виртуальных частных серверов (VPS) для доступа и работы с Linux удалённо.
Сервисы, такие как Amazon EC2, Microsoft Azure или DigitalOcean, предоставляют экземпляры Linux, с которыми вы можете соединяться с вашего компьютера с операционной системой Windows. Заметите, что некоторые из этих сервисов предлагают бесплатные планы, но в the long run они обычно не являются бесплатными.
Часть 2: Введение в Bash Shell и системные команды
2.1. Запуск с Bash shell
Введение в оболочку Bash
Linux командная строка предоставляется программой под названием оболочка (shell). За годы развития оболочка программы была усовершенствована, чтобы соответствовать различным опциям.
不同的用户 могут настраивать использование различных оболочек. Но большинство пользователей предпочитают работать с текущей по умолчанию оболочкой. По умолчанию для многих дистрибутивов Linux является оболочка GNU Bourne-Again Shell (bash). Bash является дальнейшим развитием оболочки Bourne (sh).
Чтобы узнать текущую оболочку, откройте терминал и введите следующую команду:
echo $SHELL
Command breakdown:
-
Команда
echoиспользуется для печати в терминале. -
Параметр
$SHELLявляется специальной переменной, которая содержит имя текущей оболочки.
В моем настройке вывод содержит /bin/bash. Это значит, что я использую bash-оболочку.
# вывод
echo $SHELL
/bin/bash
Bash очень мощна, поскольку она может упростить операции, трудно выполняемые эффективно с GUI (графическим пользовательским интерфейсом). Remember that most servers do not have a GUI, and it is best to learn to use the powers of a command line interface (CLI).
Терминал vs Оболочка
The terms “terminal” and “shell” are often used interchangeably, but they refer to different parts of the command-line interface.
Терминал – это интерфейс, который вы используете для взаимодействия с оболочкой. Оболочка – это командный интерпретатор, который обрабатывает и выполняет ваши команды. Вы узнаете больше о оболочках в части 6 руководства.
Что такое приглашение?
Когда оболочка используется интерактивно, она отображает символ $, когда ожидает команды от пользователя. Это называется оболочечным приглашением.
[имя_пользователя@хост ~]$
Если оболочка выполняется от имени пользователя root (вы узнаете о пользователе root позже), приглашение меняется на символ #.
[root@хост ~]#
2.2. Структура команды
Команда – это программа, которая выполняет определенную операцию. После доступа к оболочке вы можете вводить любую команду после символа $ и видеть вывод в терминале.
Обычно команды в Linux следуют следующему синтаксису:
command [options] [arguments]
Вот разбор вышеуказанного синтаксиса:
-
команда: Это имя команды, которую вы хотите выполнить.ls(список),cp(копирование) иrm(удаление) – это распространенные команды в Linux. -
[параметры]: Параметры, часто предшествуемые дефисом (-) или двумя дефисами (–), изменяют поведение команды. Они могут изменить способ работы команды. Например,ls -aиспользует параметр-aдля отображения скрытых файлов в текущем каталоге. -
[аргументы]: Аргументы являются входными данными для команд, которым они требуются. Это могут быть имена файлов, имена пользователей или другие данные, с которыми команда будет работать. Например, в командеcat access.log,catявляется командой, аaccess.logявляется входным данным. В результате командаcatотображает содержимое файлаaccess.log.
Параметры и аргументы не требуются для всех команд. Некоторые команды могут быть запущены без каких-либо параметров или аргументов, в то время как другие могут требовать одного или обоих для правильной работы. Вы всегда можете обратиться к руководству по команде, чтобы проверить поддерживаемые ею параметры и аргументы.
💡Совет: Вы можете просмотреть справку по команде, используя команду man.
Чтобы просмотреть справку по команде ls, вы можете выполнить man ls, результат будет выглядеть так:

Справки по командам являются отличным и быстрым способом получения документации. Я рекомендую изучить справки для команд, которые вы используете часто.
2.3. Команды Bash и快捷键
Когда вы находитесь в терминале, вы можете ускорить выполнение задач с помощью сокращённых команд.
Вот некоторые из наиболее распространённых сокращённых команд терминала:
| Операция | Сокращённая команда |
| Искать предыдущую команду | ↑ |
| Перейти к началу предыдущего слова | Ctrl+← |
| Очистить символы с курсора до конца行 | Ctrl+K |
| Завершить команду, имя файла или опцию | Нажатие Tab |
| Перейти к началу строки | Ctrl+A |
| Показать список предыдущих команд | history |
2.4. Определение себя: Команда whoami
Вы можете получить имя пользователя, с которым вы залогинены, используя команду whoami. Эта команда полезна, когда вы переключаетесь между различными пользователями и хотите подтвердить текущего пользователя.
Прямо после знака $ напечатайте whoami и нажмите Enter.
whoami
Этот вывод я получил.
zaira@zaira-ThinkPad:~$ whoami
zaira
Часть 3: Понимание вашего Linux-системы
3.1. Обнаружение вашей ОС и спецификаций
Отображение системной информации с помощью команды uname
Вы можете получить детальную информацию о системе с помощью команды uname.
При указании опции -a она выводит всю системную информацию.
uname -a
# вывод
Linux zaira 6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
В выводе выше,
-
Linux: указывает на тип операционной системы. -
zaira: представляет имя узла машины. -
6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2:提供更关于 версии ядра, даты сборки и дополнительных деталей. -
x86_64 x86_64 x86_64: указывает архитектуру системы. -
GNU/Linux: представляет тип операционной системы.
Используйте команду lscpu для получения подробностей о архитектуре CPU
Команда lscpu в Linux используется для отображения информации о архитектуре CPU. Когда вы запускаете lscpu в терминале, она предоставляет такие подробности, как:
-
Архитектура CPU (например, x86_64)
-
Режим работы CPU (например, 32-бит, 64-бит)
-
Порядок байтов (например, Лittle Endian)
-
CPU(ы) (количество CPU), и т.д.
Попробуем это:
lscpu
# вывод
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 5500U with Radeon Graphics
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 1
CPU max MHz: 4056.0000
CPU min MHz: 400.0000
Это было много информации, но и полезно! Помните, что вы всегда можете просмотреть соответствующую информацию, используя конкретные флаги. Смотрите руководство по команде с помощью man lscpu.
Часть 4: Управление файлами из командной строки
4.1. Иерархия файловой системы Linux
Все файлы в Linux хранятся в файловой системе. Она следует обратной древовидной структуре, потому что корень находится в верхней части.
Символ / является корневой каталогом и начальной точкой файловой системы. Корневой каталог содержит все другие каталоги и файлы в системе. Символ / также служит разделителем между именами путей. Например, /home/alice образует полный путь.
Различные каталоги служат особым целям.
Обратите внимание, что это не исчерпывающий список, и различные дистрибутивы могут иметь другие конфигурации.
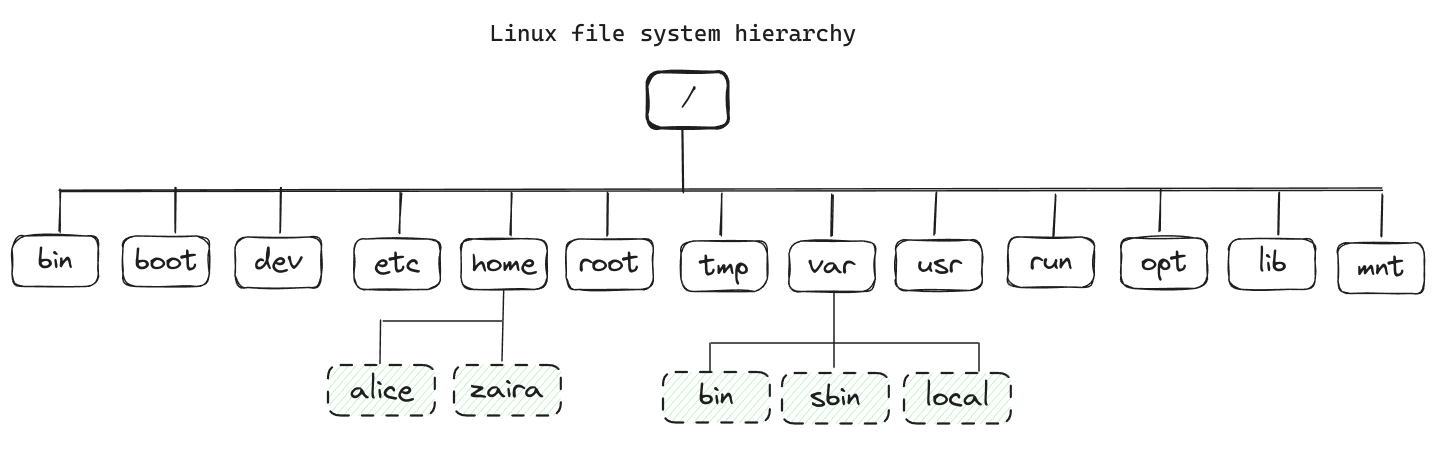
Вот таблица, которая показывает цель каждого каталога:
| Расположение | Цель |
| /bin | Важные двоичные файлы команд |
| /boot | Статические файлы загрузчика, необходимые для начала процесса загрузки. |
| /etc | Системная конфигурация, специфичная для хоста |
| /home | Домашние каталоги пользователей |
| /root | Домашний каталог администратора суперпользователя |
| /lib | Важные общие библиотеки и модули ядра |
| /mnt | Точка монтирования для временного монтирования файловой системы |
| /opt | Дополнительные пакеты приложений |
| /usr | Установленное программное обеспечение и общие библиотеки |
| /var | Переменные данные, которые сохраняются между загрузками |
| /tmp | Временные файлы, доступные всем пользователям |
💡 Совет: Вы можете больше узнать о файловой системе, используя команду man hier.
Вы можете проверить свою файловую систему, используя команду tree -d -L 1. Вы можете изменить флаг -L, чтобы изменить глубину дерева.
tree -d -L 1
# вывод
.
├── bin -> usr/bin
├── boot
├── cdrom
├── data
├── dev
├── etc
├── home
├── lib -> usr/lib
├── lib32 -> usr/lib32
├── lib64 -> usr/lib64
├── libx32 -> usr/libx32
├── lost+found
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin -> usr/sbin
├── snap
├── srv
├── sys
├── tmp
├── usr
└── var
25 directories
Этот список не исчерпывающий и различные дистрибутивы и системы могут быть настроены по-разному.
4.2. Прохождение Linux файловой системы
Absolute path vs relative path
Absolute path — это полный путь от корневого каталога к файлу или каталогу. Он всегда начинается с /. Например, /home/john/documents.
Relative path, напротив, — это путь от текущего каталога до целевого файла или каталога. Он не начинается с /. Например, documents/work/project.
Определение текущего каталога с помощью команды pwd
В Linux файловой системе легко потеряться, особенно если вы новичок в командной строке. Вы можете определить текущий каталог с помощью команды pwd.
Вот пример:
pwd
# вывод
/home/zaira/scripts/python/free-mem.py
Изменение каталога с помощью команды cd
Команда для изменения каталога — cd, что означает “изменить каталог”. Вы можете использовать команду cd для перехода в другой каталог.
Вы можете использовать относительный или абсолютный путь.
Например, если вы хотите перейти по следующей файловой структуре (по красным линиям):
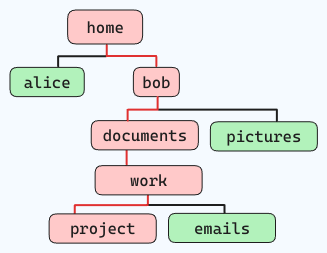
и вы находитесь в “home”, команда будет такой:
cd home/bob/documents/work/project
Короткие команды cd также можно использовать:
| Команда | Описание |
cd .. |
Вернуться назад на один каталог |
cd ../.. |
Вернуться назад на два каталога |
cd или cd ~ |
Перейти в домашний каталог |
cd - |
Перейти к предыдущему каталогу |
4.3. Управление файлами и каталогами
Работая с файлами и каталогами, можешь потребовать копировать, перемещать, удалять и создавать новые файлы и каталоги. Вот несколько команд, которые могут тебе помочь.
💡Подсказка: Можешь различать файл и папку по первой букве в выводе ls -l. '-' означает файл, а 'd' — папку.
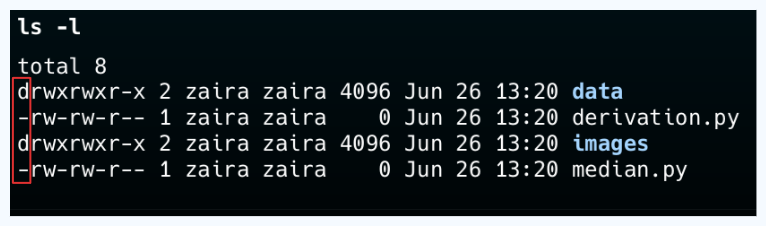
Создание новых каталогов с помощью команды mkdir
Можешь создать пустой каталог с помощью команды mkdir.
# создает пустой каталог с именем "foo" в текущем каталоге
mkdir foo
Также можешь создавать каталоги рекурсивно с помощью опции -p.
mkdir -p tools/index/helper-scripts
# вывод команды tree
.
└── tools
└── index
└── helper-scripts
3 directories, 0 files
Создание новых файлов с помощью команды touch
Команда touch создает пустой файл. Вы можете использовать ее так:
# создает пустой файл "file.txt" в текущем каталоге
touch file.txt
Имена файлов могут быть связаны вместе, если вы хотите создать несколько файлов одним командным выражением.
# создает пустые файлы "file1.txt", "file2.txt" и "file3.txt" в текущей папке
touch file1.txt file2.txt file3.txt
Удаление файлов и каталогов с помощью команд rm и rmdir
Вы можете использовать команду rm, чтобы удалить как файлы, так и непустые каталоги.
| Команда | Описание |
rm file.txt |
Удаляет файл file.txt |
rm -r directory |
Удаляет каталог directory и все его содержимое |
rm -f file.txt |
Удаляет файл file.txt без провероки подтверждения |
rmdir directory |
Удаляет пустой каталог |
🛑 Обратите внимание, что вы должны использовать флаг -f осторожно, так как удаление файла произойдет без запроса подтверждения. Также учитывайте, что использование команд rm в каталоге root может привести к удалению важных системных файлов.
Копирование файлов с помощью команды cp
Для копирования файлов в Linux используется команда cp.
- Синтаксис для копирования файлов:
cp source_file destination_of_file
Эта команда копирует файл с именем file1.txt в новую позицию /home/adam/logs.
cp file1.txt /home/adam/logs
Команда cp также создает копию одного файла с указанным именем.
Этот комманда копирует файл с именем file1.txt в другой файл с именем file2.txt в том же каталоге.
cp file1.txt file2.txt
Перемещение и переименование файлов и каталогов с использованием комманды mv
Комманда mv используется для перемещения файлов и каталогов из одного каталога в другой.
Синтаксис для перемещения файлов:mv source_file destination_directory
Пример: Переместите файл с именем file1.txt в каталог с именем backup:
mv file1.txt backup/
Для перемещения каталога и всего его содержимого:
mv dir1/ backup/
Переименование файлов и каталогов в Linux также осуществляется с помощью комманды mv.
Синтаксис для переименования файлов:mv old_name new_name
Пример: Переименуйте файл с именем file1.txt в file2.txt:
mv file1.txt file2.txt
Переименуйте каталог с именем dir1 в dir2:
mv dir1 dir2
4.4. Обнаружение файлов и каталогов с помощью комманды find
Комманда find позволяет эффективно искать файлы, каталоги и символьные и блочные устройства.
Ниже представлен базисный синтаксис комманды find:
find /path/ -type f -name file-to-search
Где,
-
/path— это путь, где ожидается, что файл будет найден. Это точка от которой начинается поиск файлов. Путь может также быть/или., которые соответственно представляют корневую и текущую директории. -
-typeпредставляет собой описатели файлов. They can be any of the below:
f– Обычный файл таких как текстовые файлы, изображения и скрытые файлы.
d– Каталог. Этим являются папки, которые рассматриваются.
l– Символьный ссылка. Символьные ссылки указывают на файлы и сходны с ярлыками.
c– Character devices. Файлы, используемые для доступа к символьным устройствам, называются символьными устройствами.驱动器 общается с символьными устройствами, отправляя и получая одинарные символы (BYTE, OCTET). примеры включают клавиатуру, звуковые карты и мышь.
b– ブロック装置. Файлы, используемые для доступа к блочным устройствам, называются блочными устройствами. Driver communicates with block devices by sending and receiving entire blocks of data. примеры включают USB и CD-ROM -
-nameявляется именем типа файла, который вы хотите найти.
How to search files by name or extension
Suppose we need to find files that contain “style” in their name. We’ll use this command:
find . -type f -name "style*"
#output
./style.css
./styles.css
Now let’s say we want to find files with a particular extension like .html. We’ll modify the command like this:
find . -type f -name "*.html"
# output
./services.html
./blob.html
./index.html
How to search hidden files
Точка в начале имён файлов предполагает скрытые файлы. Они обычно скрыты, но могут быть просмотрены с ls -a в текущем каталоге.
Мы можем изменить команду find как показано ниже, чтобы искать скрытые файлы:
find . -type f -name ".*"
Список и поиск скрытых файлов
ls -la
# содержимое папки
total 5
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:17 .
drwxr-x--- 61 zaira zaira 4096 Mar 26 14:12 ..
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_history
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_logout
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bashrc
find . -type f -name ".*"
# вывод find
./.bash_logout
./.bashrc
./.bash_history
Вы можете увидеть список скрытых файлов в моем домашнем каталоге.
Как искать логические файлы и файлы конфигурации
Файлы логирования обычно имеют расширение .log, и мы их можем найти так:
find . -type f -name "*.log"
Также мы можем искать файлы конфигурации так:
find . -type f -name "*.conf"
Как искать другие файлы по типу
Мы можем искать текстовые блочные файлы, добавив c к -type:
find / -type c
Аналогично, мы можем найти устройства блочного доступа, используя b:
find / -type b
Как искать каталоги
В примере ниже мы ищем папки с помощью флага -type d.
ls -l
# список содержимого папки
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 hosts
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:23 hosts.txt
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 images
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:23 style
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 webp
find . -type d
# вывод find каталогов
.
./webp
./images
./style
./hosts
Как искать файлы по размеру
Очень полезным является использование команды find для вывода файлов на основе определенного размера.
find / -size +250M
В этом случае мы выводим файлы, размер которых превышает 250MB.
Другие единицы включают:
-
G: ГигаBytes. -
Гигабайты.
-
Килобайты.
-
Байты.
Просто замените соответствующей единицей измерения.
find <directory> -type f -size +N<Unit Type>
Как искать файлы по времени изменения
Используя флаг -mtime, вы можете фильтровать файлы и папки на основе времени изменения.
find /path -name "*.txt" -mtime -10
Например,
-
-mtime +10 означает, что вы ищете файл, изменённый 10 дней назад.
-
-mtime -10 означает менее 10 дней.
-
-mtime 10 Если вы пропустите + или -, это означает ровно 10 дней.
4.5. Основные команды для просмотра файлов
Объедините и покажите файлы, используя команду cat
Команда cat в Linux используется для отображения содержимого файла. Она также может использоваться для объединения файлов и создания новых файлов.
Вот основная синтаксис команды cat:
cat [options] [file]
Самый простой способ использовать cat – без каких-либо опций или аргументов. Это отобразит содержимое файла на терминале.
Например, если вы хотите просмотреть содержимое файла с именем file.txt, вы можете использовать следующий комманд:
cat file.txt
Это отобразит все содержимое файла на терминале в одно итерационное запуске.
Просмотр текстовых файлов интерактивно с использованием less и more
Если cat отображает весь файл за один раз, то less и more позволяют вам просмотреть содержимое файла интерактивно. Это удобно, когда вы хотите прокрутить большой файл или найти конкретный контент.
Синтаксис команды less выглядит следующим образом:
less [options] [file]
Команда more похожа на less, но имеет меньше функций. Она используется для отображения содержимого файла по одному экрану за раз.
Синтаксис команды more выглядит следующим образом:
more [options] [file]
Для обоих команд вы можете использовать клавишу пробел, чтобы прокрутить страницу вниз, клавишу Enter, чтобы прокрутить строку вниз, и клавишу q, чтобы выйти из просмотрщика.
Для сдвига назад вы можете использовать клавишу b, а для сдвига вперед — клавишу f.
Отображение последней части файлов с использованием команды tail
Когда вам нужно просмотреть только последние несколько строк файла, а не весь файл, то используется команда tail в Linux для отображения последней части файла.
Например, комманда tail file.txt по default будет отображать последние 10 строк файла file.txt.
Если вы хотите отобразить разное количество строк, вы можете использовать опцию -n, за которой следует количество строк, которые вы хотите отобразить.
# Отобразить последние 50 строк файла file.txt
tail -n 50 file.txt
💡Совет: Еще одним способом использования команды tail является опция -f. Эта опция позволяет просматривать содержимое файла по мере его записи. Это полезная утилита для просмотра и мониторинга файлов журналов в реальном времени.
Отображение начала файлов с помощью команды head
Как и команда tail отображает последнюю часть файла, вы можете использовать команду head в Linux для отображения начала файла.
Например, head file.txt по умолчанию отобразит первые 10 строк файла file.txt.
Чтобы изменить количество отображаемых строк, вы можете использовать опцию -n, за которой следует количество строк, которые вы хотите отобразить.
Подсчет слов, строк и символов с помощью команды wc
Вы можете подсчитать слова, строки и символы в файле с помощью команды wc.
Например, выполнение команды wc syslog.log дало мне следующий вывод:
1669 9623 64367 syslog.log
В выводе выше,
-
1669представляет количество строк в файлеsyslog.log. -
9623представляет количество слов в файлеsyslog.log. -
64367представляет количество символов в файлеsyslog.log.
Таким образом, команда wc syslog.log подсчитала 1669 строк, 9623 слова и 64367 символов в файле syslog.log.
Сравнение файлов построчно с помощью diff
Сравнение и поиск различий между двумя файлами является обычной задачей в Linux. Вы можете сравнить два файла прямо в командной строке с помощью команды diff.
Базовая синтаксис команды diff таков:
diff [options] file1 file2
Вот два файла, hello.py и also-hello.py, которые мы сравним с помощью команды diff:
# содержимое hello.py
def greet(name):
return f"Hello, {name}!"
user = input("Enter your name: ")
print(greet(user))
# содержимое also-hello.py
more also-hello.py
def greet(name):
return fHello, {name}!
user = input(Enter your name: )
print(greet(user))
print("Nice to meet you")
- Проверьте, являются ли файлы одинаковыми или нет
diff -q hello.py also-hello.py
# Вывод
Files hello.py and also-hello.py differ
- Посмотрите, как файлы различаются. Для этого вы можете использовать флаг
-u, чтобы увидеть объединенный вывод:
diff -u hello.py also-hello.py
--- hello.py 2024-05-24 18:31:29.891690478 +0500
+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500
@@ -3,4 +3,5 @@
user = input(Enter your name: )
print(greet(user))
+print("Nice to meet you")
— hello.py 2024-05-24 18:31:29.891690478 +0500
- В вышеуказанном выводе:
--- hello.py 2024-05-24 18:31:29.891690478 +0500указывает на файл, который сравнивается, и его маркер времени.+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500указывает на другой файл, который сравнивается, и его маркер времени.@@ -3,4 +3,5 @@показывает номер строк, где происходили изменения. В этом случае, это указывает, что строки 3 и 4 в исходном файле были изменены на строки 3 и 5 в измененном файле.user = input(Enter your name: )— это строка из исходного файла.print(greet(user))— это другая строка из исходного файла.
+print("Nice to meet you")— это добавленная строка в измененном файле.
diff -y hello.py also-hello.py
Чтобы увидеть разницу в виде side-by-side, вы можете использовать флаг -y:
def greet(name): def greet(name):
return fHello, {name}! return fHello, {name}!
user = input(Enter your name: ) user = input(Enter your name: )
print(greet(user)) print(greet(user))
> print("Nice to meet you")
# Вывод
- В выводе:
- Строки, совпадающие в обоих файлах, отображаются side by side.
Различные строки отображаются с символом >, указывающим, что строка присутствует только в одном из файлов.
Часть 5: Основы редактирования текста в Linux
Навыки работы с текстовыми редакторами в командной строке являются одними из самых важных навыков в Linux. В этой секции вы узнаете, как использовать два популярных текстовых редактора в Linux: Vim и Nano.
Я рекомендую вам освоить любой из выбранных текстовых редакторов и придерживаться его. Это сохранит вам время и увеличит вашу производительность. Vim и nano являются безопасными выборами, так как они присутствуют во многих дистрибутивах Linux.
5.1. Mastering Vim: The Complete Guide
Introduction to Vim
- Vim является популярным инструментом для редактирования текста в командной строке. У Vim есть свои преимущества: он является мощным, настраиваемым и быстрым. Вот несколько причин, по которым вы можете задуматься о том, чтобы научиться использовать Vim:
- Большинство серверов доступны через CLI, поэтому в администрировании системами у вас нет необходимости иметь GUI. Но Vim у вас будет — он всегда будет присутствовать.
- Вим использует центрированный подход к клавиатуре, так как он разработан для использования без мыши, что может значительно ускорить задачи редактирования, когда вы научитесь использовать快捷键. Это также делает его быстрее, чем инструменты GUI.
- Некоторые утилиты Linux, например, редактирование cron-заданий, работают с тем же форматом редактирования, что и Вим.
Вим подходит для всех – для начинающих и продвинутых пользователей. Вим поддерживает сложные поиски строк, выделение поиска и многое другое. Благодаря плагинам Вим обеспечивает расширенные возможности разработчикам и администраторам систем, которые включают автодополнение, выделение синтаксиса, управление файлами, управление версиями и многое другое.
Вим имеет две вариации: Вим (vim) и маленький Вим (vi). Маленький Вим является более небольшой версией Вим и не поддерживает некоторые возможности Вима.
Как начать использовать vim
vim your-file.txt
Начать использовать Вим можно с помощью этого команды:
your-file.txt может быть либо новым файлом или существующим файлом, который вы хотите отредактировать.
Прохождение Vim: мастеринг движений и режимов команд
В ранние дни CLI клавиатуры не были оборудованы клавишами стрелок. Таким образом, навигация осуществлялась с помощью набора доступных клавиш, hjkl являясь одним из них.
Будучи ориентированным на клавиатуру, использование клавиш hjkl может значительно ускорить задачи редактирования текста.
Примечание: хотя стрелки方向 были бы совершенно замечательно работать, вы можете все еще экспериментировать с клавишами hjkl, чтобы навигаровать.alg一些people find this this way of navigation efficient.

💡Суть: Чтобы запомнить последовательность hjkl, используйте это: hang back, jump down, kick up, leap forward.
Три режима Vim
- Вы должны знать о трех режимах работы Vim и как переключаться между ними.按键操作在每一个命令模式中表现不同。这三个模式如下所述:
- Режим команд.
- Режим редактирования.
Визуальный режим.
Command Mode. When you start Vim, you land in the command mode by default. This mode allows you to access other modes.
⚠ To switch to other modes, you need to be present in the command mode first
Edit Mode
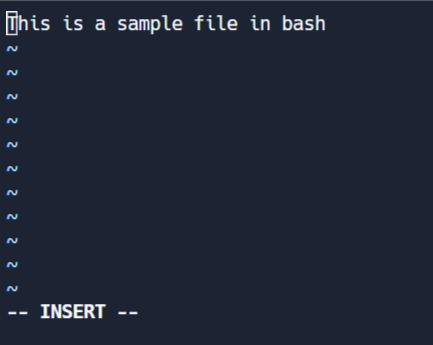
This mode allows you to make changes to the file. To enter edit mode, press I while in command mode. Note the '-- INSERT' switch at the end of the screen.
Визуальный режим
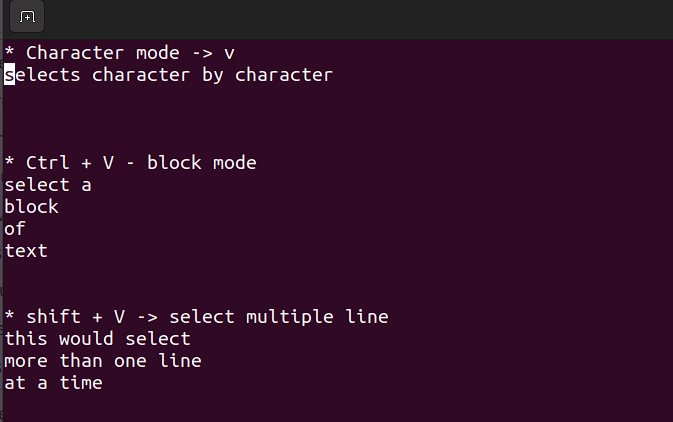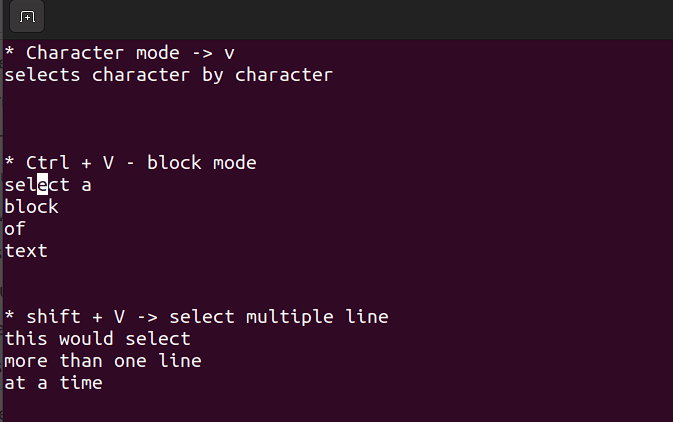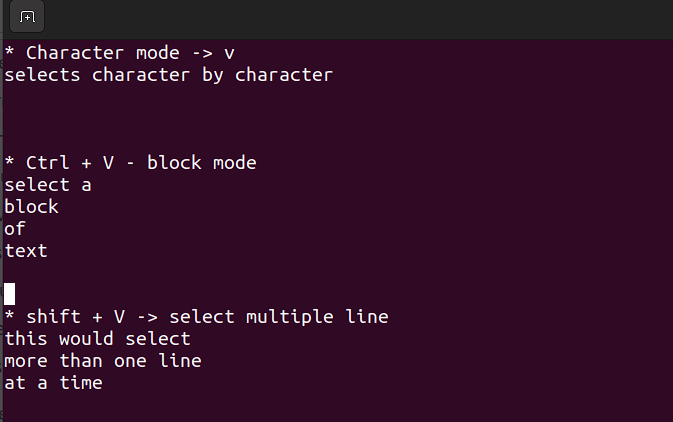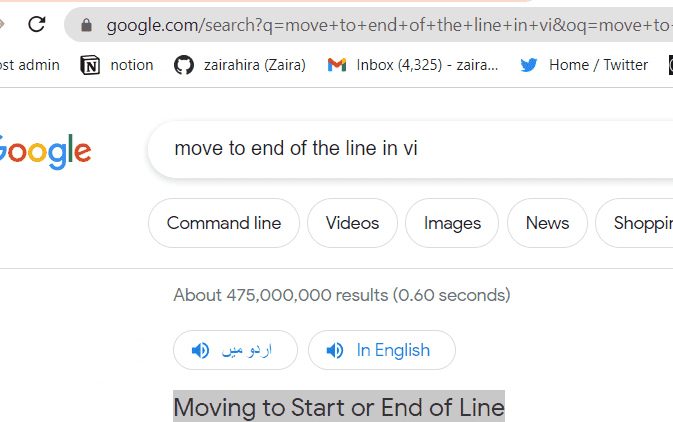
- В этом режиме можно работать с отдельным символом, блоком текста или строками текста. Разбираем его на простые шаги. Помните, используйте ниже приведенные комбинации, когда вы находитесь в командном режиме.
Shift + V→ выбор нескольких строк.Ctrl + V→ режим блока
V → режим символа
Визуальный режим становится полезен, когда нужно копировать, вставлять или редактировать строки в большом объеме.
Расширенный режим команд.
Расширенный режим команд позволяет выполнять продвинутые операции, такие как поиск, установка номеров строк и выделение текста. Мы покроем расширенный режим в следующем разделе.
Как оставаться на курсе? Если вы забыли о текущем режиме, просто нажмите ESC дважды, и вы появитесь снова в режиме команд.
Эффективная редактирования в Vim: копирование/вставка и поиск
1. Как копировать и вставить в Vim
- Копирование и вставка известно как ‘yank’ и ‘put’ в терминах Linux. Чтобы выполнить копирование и вставку, следуйте этим шагам:
- Выберите текст в визуальном режиме.
- Нажмите
'y'для копирования/yank.
Вставьте курсор в требуемую позицию и нажмите 'p'.
2. Как искать текст в Vim
Любую серию строк можно искать в Vim с помощью / в режиме команд. Чтобы выполнить поиск, используйте /искомая-строка.
В режиме команд, введите :set hls и нажмите enter. Используйте /искомая-строка для поиска. Это выделит найденные строки.
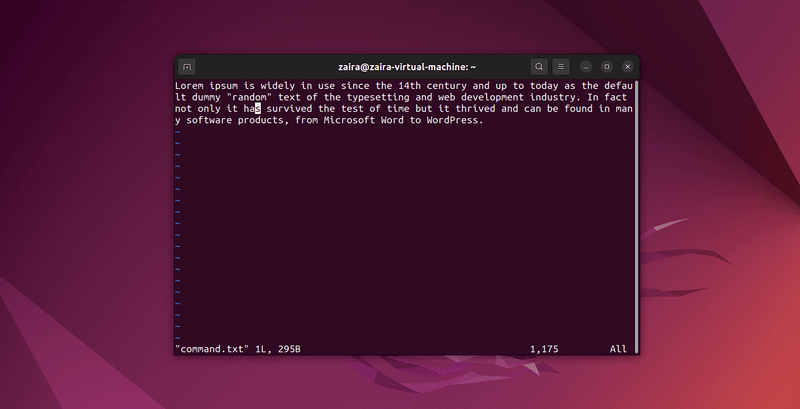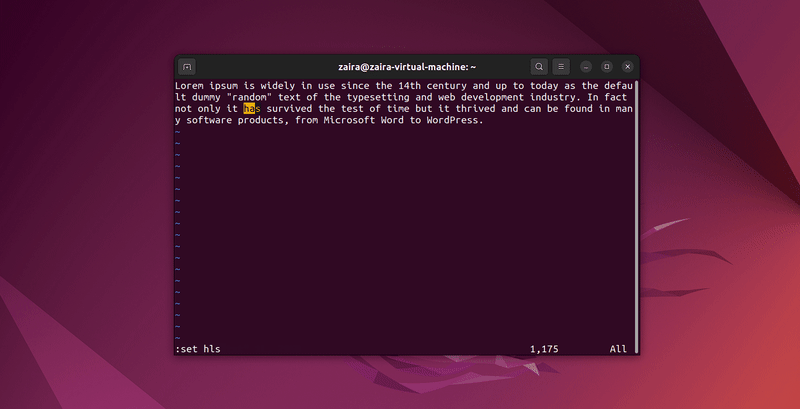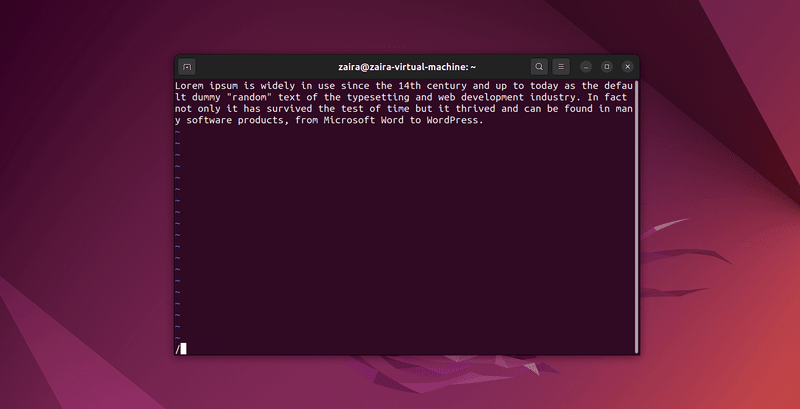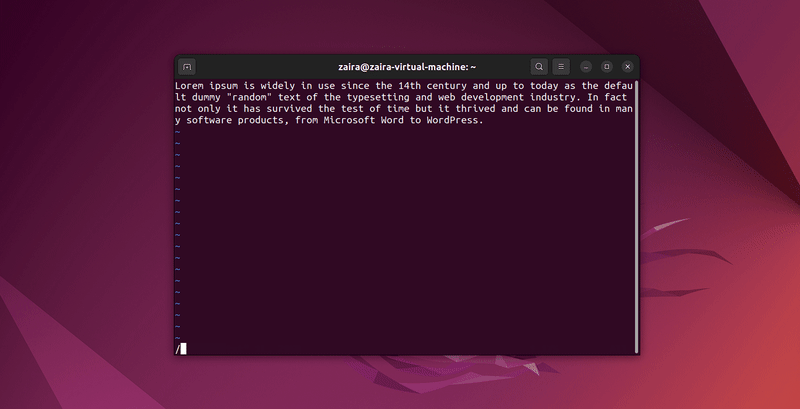
Давайте найдем несколько строк:
3. Как выйти из Vim
- Сначала, перейдите в режим команд (нажав Escape дважды) и затем используйте следующие команды:
- Выйти без сохранения →
:q!
Выйти и сохранить → :wq!
Сочетания клавиш в Vim: Ускорение редактирования
- Примечание: Все эти сочетания клавиш работают только в режиме команд.
Ctrl+u: Сместиться на один символ влевоP: Вставить над курсором:%s/old/new/g: заменить все вхожденияoldнаnewв файле:q!: выход без сохранения
Ctrl+w, затем h/j/k/l: перемещаться между разделенными окнами
5.2. Mastering Nano
Getting started with Nano: The user-friendly text editor
Nano is a user-friendly text editor that is easy to use and is perfect for beginners. It is pre-installed on most Linux distributions.
nano
To create a new file using Nano, use the following command:
nano filename
To start editing an existing file with Nano, use the following command:
List of key bindings in Nano
Let’s study the most important key bindings in Nano. You’ll use the key bindings to perform various operations like saving, exiting, copying, pasting, and more.
Записать в файл и сохранить
Когда вы открываете Nano с помощью команды nano, можете начать вводить текст. Чтобы сохранить файл, нажмите Ctrl+O. Будете проспрошено запрос на ввод имени файла. Нажмите Enter, чтобы сохранить файл.
Выход из nano
Вы можете выйти из Nano, нажав Ctrl+X. Если у вас есть несохраненные изменения, Nano запросит вас о сохранении изменений перед выходом.
Копирование и вставка
Чтобы выбрать регион, используйте ALT+A. Будет показана маркерка. Используйте стрелки для выделения текста. После выделения, выйти из маркера с помощью ALT+^.
Для копирования выделенного текста, нажмите Ctrl+K. Для вставки скопированного текста, нажмите Ctrl+U.
Вырезание и вставка
Выделите регион с помощью ALT+A. После выделения, вырежьте текст с помощью Ctrl+K. Для вставки вырезанного текста, нажмите Ctrl+U.
Навигация
Используйте Alt \, чтобы перейти к началу файла.
Используйте Alt /, чтобы перейти к концу файла.
Просмотр нумерованных строк
Когда вы открываете файл с помощью nano -l filename, вы можете видеть номеры строк слева от файла.
Поиск
Вы можете искать конкретный номер строки с помощью ALt + G. Введите номер строки в запросе и нажмите Enter.
Вы также можете инициировать поиск строки с помощью CTRL + W и нажать Enter. Если вы хотите искать назад, вы можете нажать Alt+W после инициирования поиска с помощью Ctrl+W.
- Резюме клавиатурных сокращений в Nano
Ctrl+G: Показать справкуCtrl+J: Выравнять текущий абзацCtrl+V: прокрутить вниз одной страницыCtrl+\: искать и заменить
Alt+E: Повторить последнюю отменённую операцию
Раздел 6: Скриптирование Bash
6.1. Определение скриптирования Bash
Скрипт Bash — это файл, содержащий последовательность команд, которые выполняются программой Bash построчно. Он позволяет выполнять серию действий, таких как переход в определенный каталог, создание папки и запуск процесса с помощью командной строки.
Сохраняя команды в скрипте, вы можете повторять те же последовательности шагов много раз и выполнять их, запуская скрипт.
6.2. преимущества Bash Скриптинга
Bash скриптинг является мощным и гибким инструментом для автоматизации задач системного администрирования, управления системными ресурсами и выполнения других повторяющихся задач в системах Unix/Linux.
- 一些Shell脚本的优势包括:
- 自动化:Shell脚本允许您自动化重复的任务和过程,节省时间并减少手动执行时可能出现的错误风险。
- 可移植性:Shell脚本可以在各种平台和操作系统上运行,包括Unix、Linux、macOS,甚至通过使用模拟器或虚拟机在Windows上运行。
- Свободность: Скрипты оболочки очень настраиваемые и легко модифицируемые для соответствия специфическим требованиям. Также они могут комбинироваться с другими языками программирования или утилитами для создания более мощных скриптов.
- Доступность: Скрипты оболочки легкие в написании и не требуют никаких специальных инструментов или программного обеспечения. Их можно редактировать с помощью любого текстового редактора, и большинство операционных систем имеют встроенный интерпретатор оболочки.
- Integration: Скрипты оболочки могут интегрироваться с другими tool и application, such as databases, web servers, and cloud services, allowing for more complex automation and system management tasks.
Debugging: Скрипты оболочки легкие для отладки, и большинство оболочек имеют built-in debugging и error-reporting tools that can help identify и fix issues quickly.
6.3. Обзор Bash оболочки и командной строки
термины “кожка” и “баш” часто используются взаимнозаменяемо. Но существует тонкая разница между двумя из них.
термин “кожка” относится к программе, которая предоставляет интерфейс командной строки для взаимодействия с операционной системой. Баш (Bourne-Again SHell) является одним из наиболее часто используемых унакс/линукс-кож и является по умолчанию в many Linux дистрибутивах.
пока что команды, которые вы вводите, в основном, вводились в “кожку”.
хотя Баш является типом кожки, также доступны и другие кожи, такие как Korn shell (ksh), C shell (csh), и Z shell (zsh). Каждая кожа имеет свой собственный синтаксис и набор функций, но их всех объединяет общая цель – предоставлять интерфейс командной строки для взаимодействия с операционной системой.
ps
# output:
PID TTY TIME CMD
20506 pts/0 00:00:00 bash <--- the shell type
20931 pts/0 00:00:00 ps
вы можете определить свой тип кожи с использованием команды ps:
в общем, в то время как “кожа” – это общий термин, относящийся к любой программе, которая предоставляет интерфейс командной строки, “баш” – это конкретный тип кожи, широко используемый в унакс/линукс системах.
заметка: в этой секции мы будем использовать “баш” кожку.
6.4. Как создавать и выполнять баш скрипты
Правила о naming скриптов
по命名 convension, баш скрипты заканчиваются на .sh. Однако баш скрипты могут запускаться отлично и без sh расширения.
Добавление Shebang
Скрипты на Bash начинаются с шебанга. Шебанг – это комбинация bash # и бомба !, следующие за которыми идет путь к оболочке Bash. Это первая строка скрипта. Шебанг сообщает оболочке, что следующий код должен быть выполнен с помощью оболочки Bash. Шебанг просто является абсолютным путем к интерпретатору Bash.
#!/bin/bash
Ниже приведен пример шебанга.
which bash
Вы можете найти ваш путь к оболочке Bash ( который может отличаться от вышеуказанного) с помощью команды:
Создание вашего первого скрипта на Bash
наш первый скрипт просит пользователя ввести путь. В ответ ему будут перечислены его содержимое.
vim run_all.sh
Создайте файл с именем run_all.sh с помощью любого редактора, который вам нравится.
#!/bin/bash
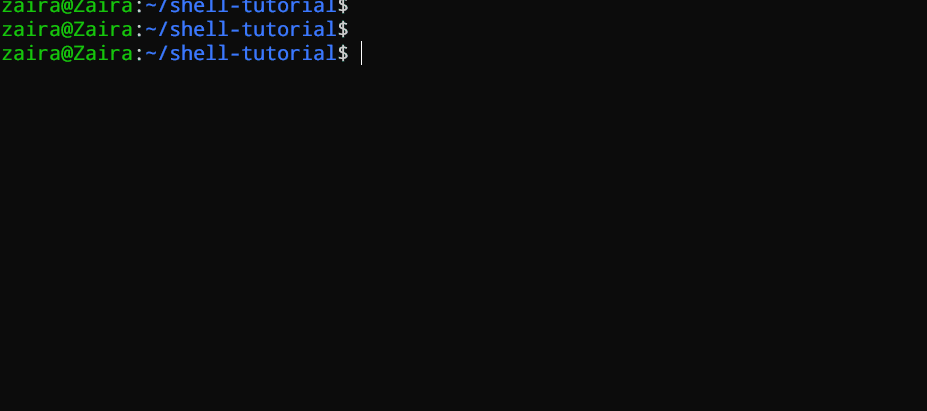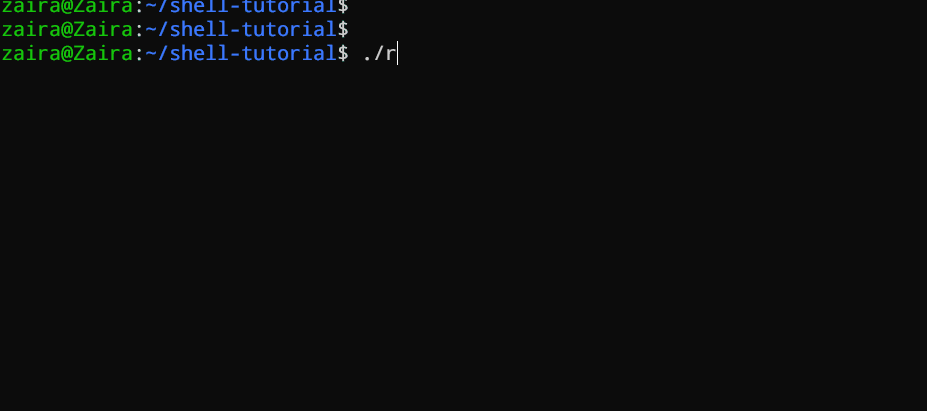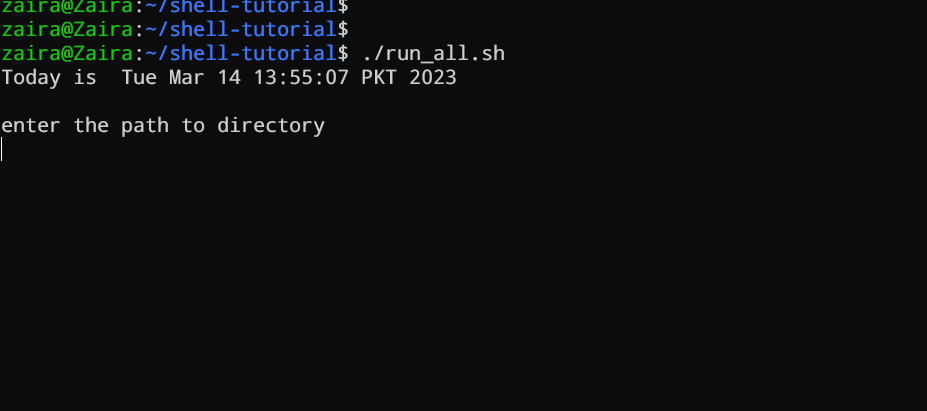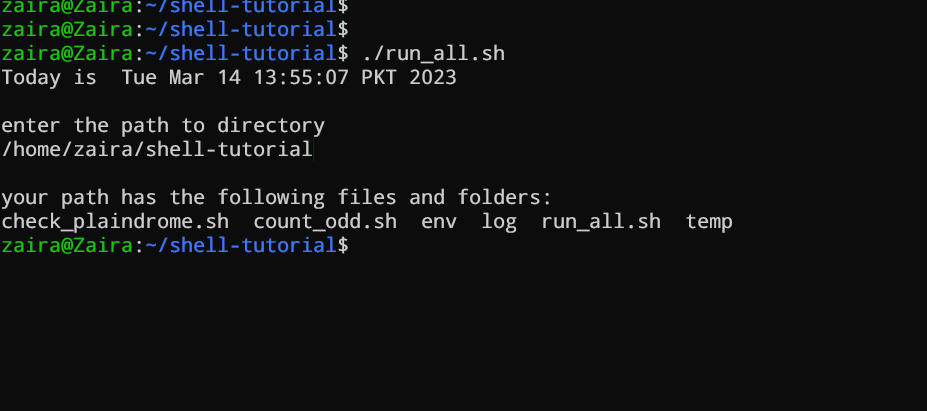
echo "Today is " `date`
echo -e "\nenter the path to directory"
read the_path
echo -e "\n you path has the following files and folders: "
ls $the_path
Добавьте следующие команды в ваш файл и сохраните его:
1 Посмотрим на скрипт более внимательно. Я показываю тот же скрипт, но на этот раз с нумерованными строками.
2 echo "Today is " `date`
3
4 echo -e "\nenter the path to directory"
5 read the_path
6
7 echo -e "\n you path has the following files and folders: "
8 ls $the_path
- #!/bin/bash
- Строка 1: шебанг (
#!/bin/bash) указывает на путь к оболочке Bash. - Строка 2: Команда
echoотображает текущую дату и время в терминале. Обратите внимание, чтоdateнаходится в обратных скобках. - Строка 4: Мы хотим, чтобы пользователь ввел действительный путь.
- Строка #5: Команда
readсчитывает ввод и сохраняет его в переменнойthe_path.
Строка #8: Команда ls берет переменную с сохраненным путем и отображает текущие файлы и папки.
Выполнение сценария bash
chmod u+x run_all.sh
Чтобы сценарий стал выполняемым, назначьте права на выполнение пользователю с помощью следующей команды:
- В этом случае,
chmodизменяет область власти файла для текущего пользователя:u.+xдобавляет права выполнения для текущего пользователя. Это значит, что владелец файла может теперь запускать сценарий.
run_all.sh – это файл, который мы хотим запустить.
- Вы можете запустить сценарий с помощью любого из упомянутых методов:
sh run_all.shbash run_all.sh
./run_all.sh
Посмотрим, как это работает в действии 🚀
6.5. Основы сценарного программирования на Bash
Комментарии в сценариях на Bash
Комментарии начинаются с символа # в сценариях на Bash. Это означает, что любая строка, начинающаяся с #, является комментарием и будет проигнорирована интерпретатором.
Комментарии очень полезны для документирования кода, и это хорошая практика добавлять их, чтобы другие могли понять код.
Приведены примеры комментариев:
# Это пример комментария
# Обе эти строки будут проигнорированы интерпретатором
Переменные и типы данных в Bash
Переменные позволяют вам хранить данные. Вы можете использовать переменные для чтения, доступа и обработки данных во всем сценарии.
В Bash нет типов данных. В Bash переменная способна хранить числовые значения, отдельные символы или строки символов.
- В Bash можно использовать и устанавливать значения переменных следующими способами:
country=Netherlands
Присвоить значение напрямую:
same_country=$country
2. Присвоить значение на основе вывода, полученного из программы или команды при помощи подстановки команд. Обратите внимание, что для доступа к значению существующей переменной требуется символ $.
Это присваивает значение переменной country новой переменной same_country.
country=Netherlands
echo $country
Для доступа к значению переменной добавьте символ $ к имени переменной.
Netherlands
new_country=$country
echo $new_country
Вывод
Netherlands
Вывод
Выше вы можете увидеть пример назначения и вывода значений переменных.
Соглашения о именовании переменных
- В скриптах Bash соблюдаются следующие соглашения о именовании переменных:
- Имена переменных должны начинаться с буквы или символа подчёркивания (
_). - Имена переменных могут содержать буквы, цифры и символы подчёркивания (
_). - Имена переменных чувствительны к регистру.
- Имена переменных не должны содержать пробелы или специальные символы.
- Используйте описательные имена, отражающие назначение переменной.
Избегайте использования резервированных ключевых слов, таких как if, then, else, fi и т.д. в качестве имен переменных.
name
count
_var
myVar
MY_VAR
Вот несколько примеров допустимых имен переменных в Bash:
А вот несколько примеров недопустимых имен переменных:
2ndvar (variable name starts with a number)
my var (variable name contains a space)
my-var (variable name contains a hyphen)
# неверные имя переменных
Соблюдая эти нормы наименования помогает сделать скрипты Bash более читабельными и легче обслуживаемыми.
Входные и выходные данные в скриптах Bash
Сборок входных данных
- В этой секции мы будем разговаривать о нескольких методах для предоставления входных данных нашим скриптам.
Чтение ввода пользователя и сохранение его в переменной
#!/bin/bash
echo "What's your name?"
read entered_name
echo -e "\nWelcome to bash tutorial" $entered_name
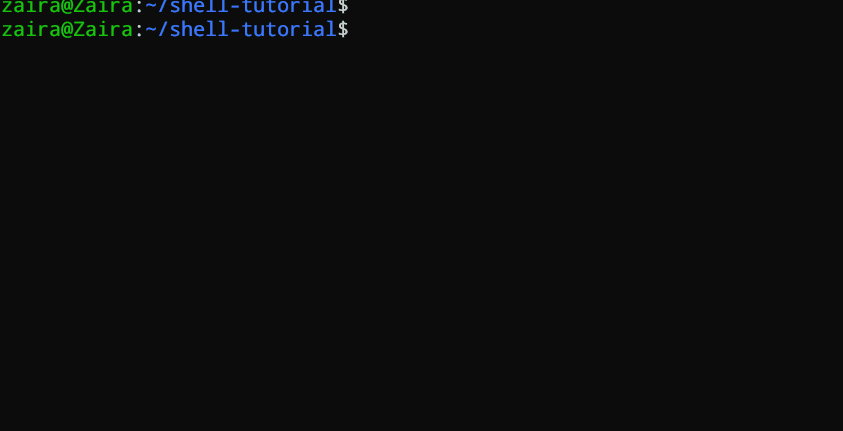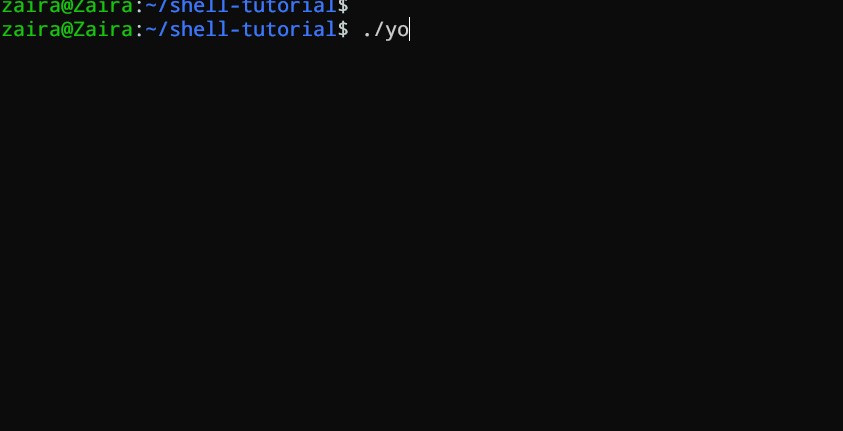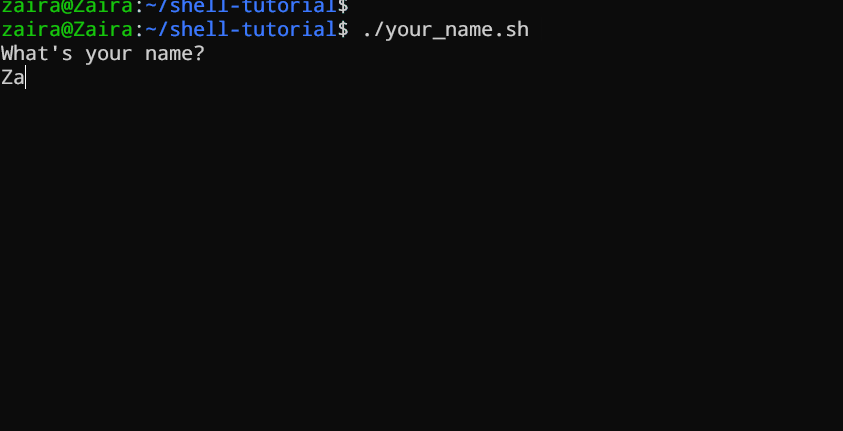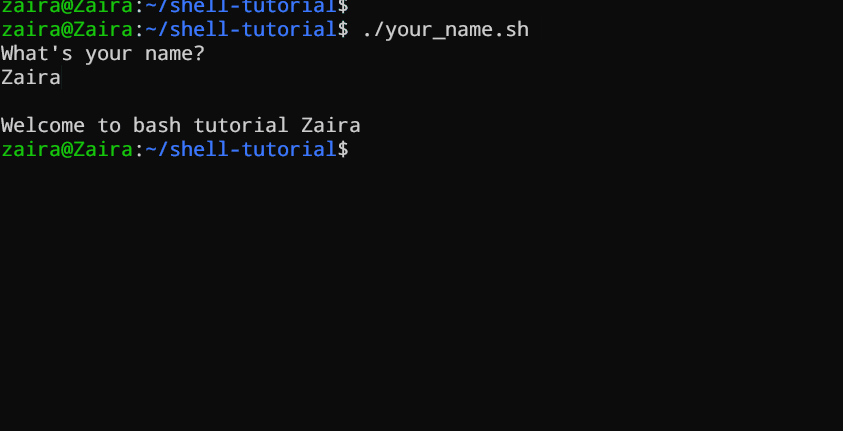
Мы можем прочитать ввод пользователя используя команду read.
2. Чтение из файла
while read line
do
echo $line
done < input.txt
Этот код читает каждую строку из файла с именем input.txt и выводит ее на экран. Мы изучим while-циклы позднее в этой секции.
3. Аргументы командной строки
В скрипте Bash или функции $1 означает первый аргумент, который был передан, $2 — второй и так далее.
#!/bin/bash
echo "Hello, $1!"
Этот скрипт принимает имя в качестве аргумента командной строки и выводит personalizovannoe приветствие.
Мы предоставили Zaira в качестве нашего аргумента скрипту.
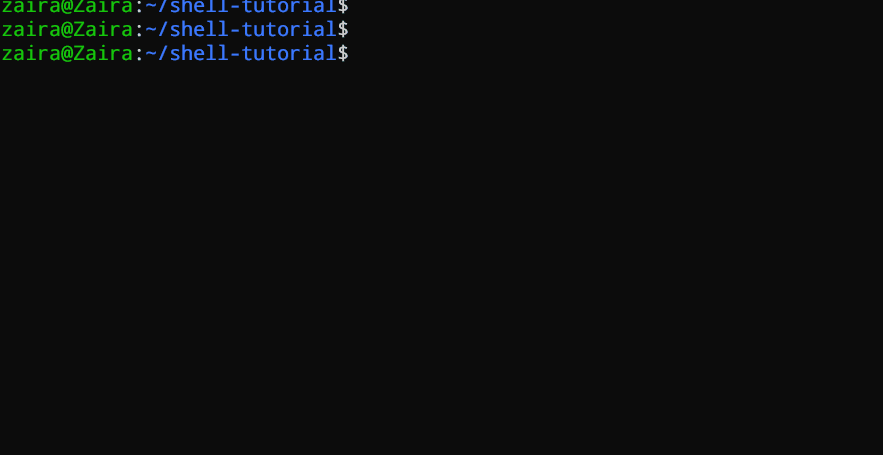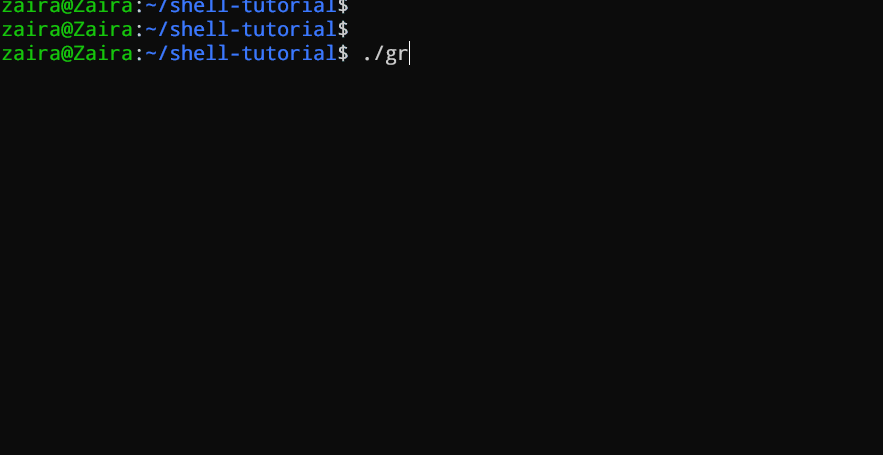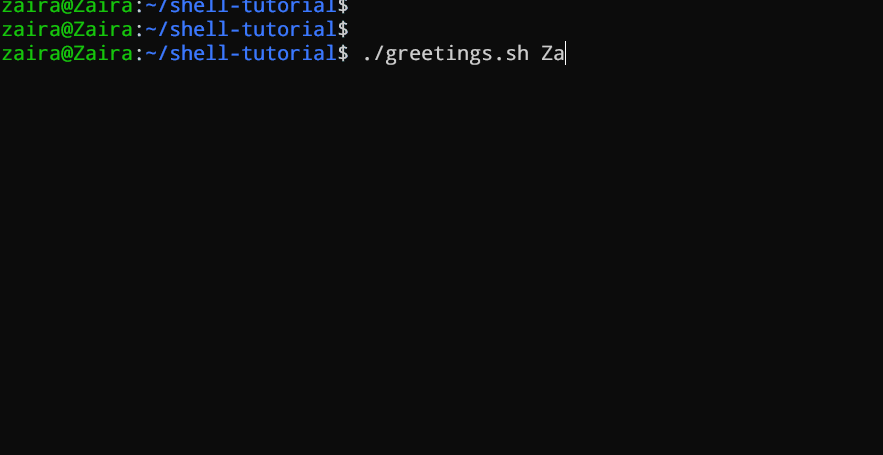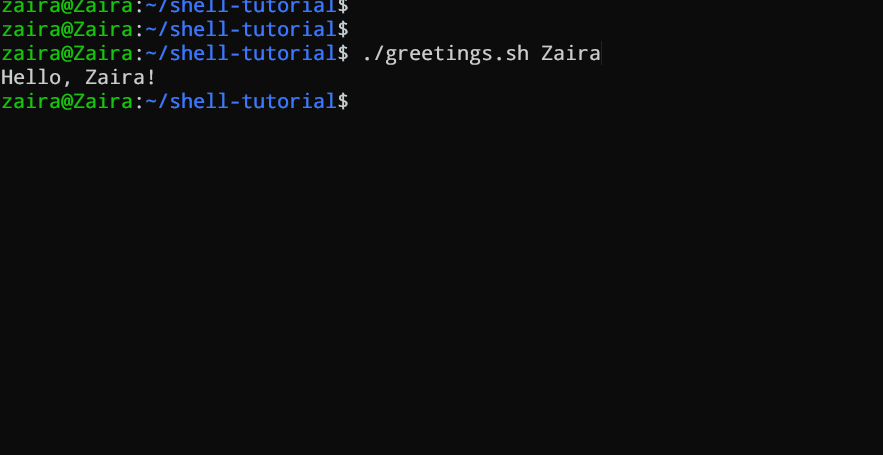
Вывод:
Отображение вывода
- Здесь мы рассмотрим несколько методов для получения вывода из скриптов.
echo "Hello, World!"
Печать на терминале:
Этот код выводит текст “Привет, мир!” на терминал.
echo "This is some text." > output.txt
2.письмо в файл:
Этот код записывает текст “Это какой-то текст.” в файл с именем output.txt. Обратите внимание, что оператор > перезаписывает файл, если он уже содержит содержимое.
echo "More text." >> output.txt
3.добавление в файл:
Данное приложение добавляет текст “Дополнительный текст.” в конец файла output.txt.*
ls > files.txt
4. Перенаправление вывода:*
Этот код выводит список файлов в текущем каталоге и записывает вывод в файл с именем files.txt. Вы можете перенаправлять вывод любого комманда в файл таким образом.*
Вы узнаете о деталях перенаправления вывода в разделе 8.5.*
Условные операторы (if/else)*
выражения, которые дают boolean результат, true или false, называются условиями. Существует несколько способов оценить условия, включая if, if-else, if-elif-else и вложенные условные операторы.*
if [[ condition ]];
then
statement
elif [[ condition ]]; then
statement
else
do this by default
fi
Синтаксис:*
Синтаксис условных операторов Bash.*
if [ $a -gt 60 -a $b -lt 100 ]
Мы можем использовать логические операторы, такие как AND -a и OR -o, чтобы выполнять сравнения с большим значением.*
Эта статья проверяет, являются ли оба условия true: a больше 60 AND b меньше 100.*
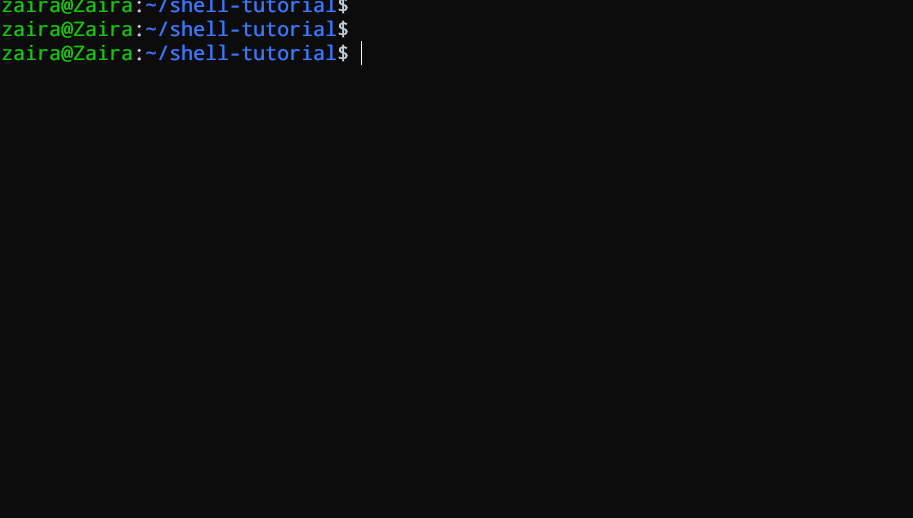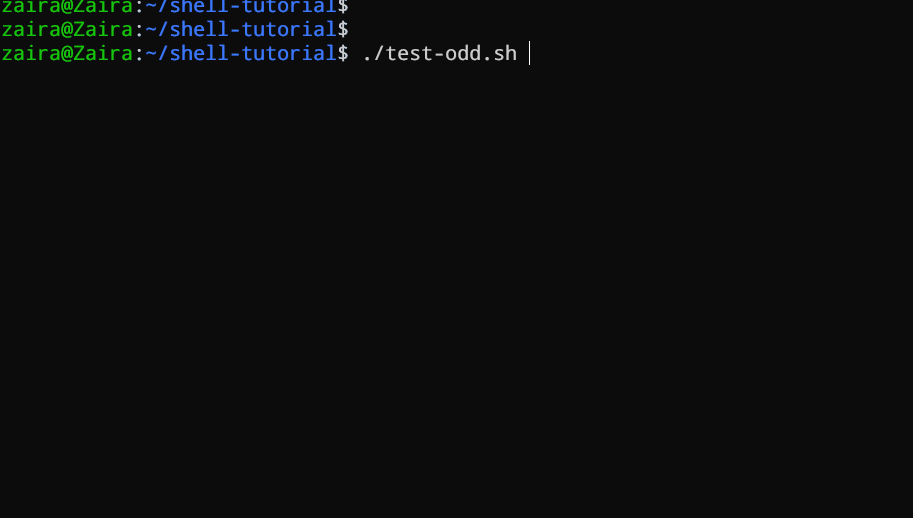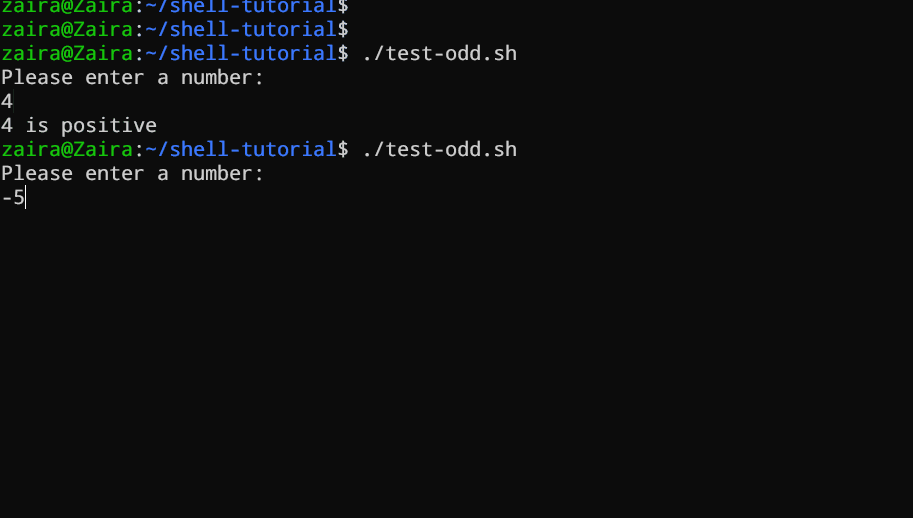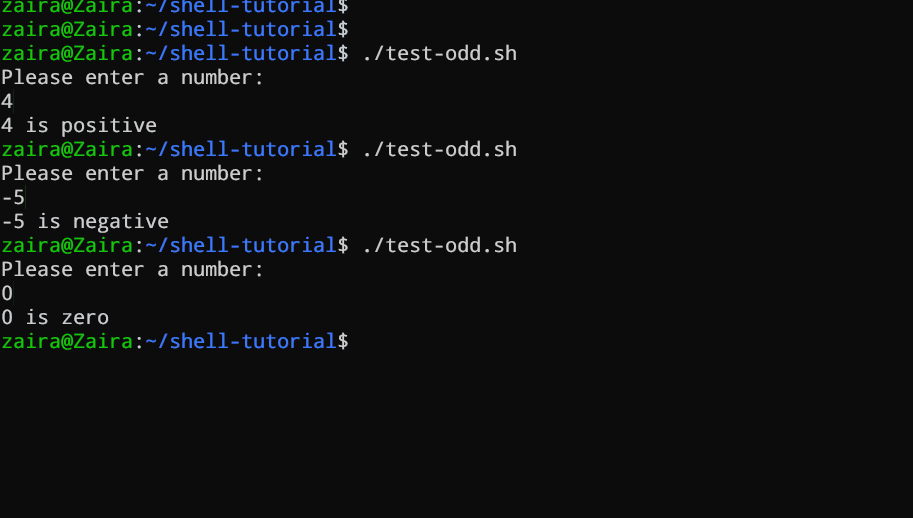
#!/bin/bash
Посмотрим пример скрипта Bash, который использует операторы if, if-else и if-elif-else, чтобы определить, является ли введенное пользователем число положительным, отрицательным или нулевым:*
echo "Please enter a number: "
read num
if [ $num -gt 0 ]; then
echo "$num is positive"
elif [ $num -lt 0 ]; then
echo "$num is negative"
else
echo "$num is zero"
fi
# Skript zur Bestimmung, ob eine Zahl ist positive, negative oder Null
Скрипт сначала просит пользователя ввести число. Затем используя оператор if он проверяет, является ли это число больше 0. Если это так, скрипт выводит, что число положительное. Если число не больше 0, скрипт переходит к следующему выражению, которое является оператором if-elif.
В этом месте скрипт проверяет, является ли число меньше 0. Если это так, скрипт выводит, что число отрицательное.
В конечном итоге, если число не больше 0 и не меньше 0, скрипт использует оператор else для вывода, что число равно 0.
Просмотреть действие 🚀
Циклы и отгадывание в Bash
Цикл while
Цикл while проверяет условие и работает, пока это условие остается true. Нам нужно представить контрольный счетчик, который увеличивает значение счетчика, чтобы контролировать выполнение цикла.
#!/bin/bash
i=1
while [[ $i -le 10 ]] ; do
echo "$i"
(( i += 1 ))
done
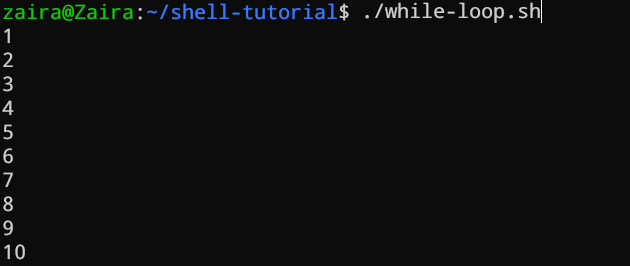
В примере ниже (( i += 1 )) является контрольным счетчиком, который увеличивает значение i. Цикл будет выполнен точно 10 раз.
Цикл for
Цикл for, как и цикл while, позволяет выполнять statement определенное число раз. Каждый цикл отличается своим синтаксисом и использованием.
#!/bin/bash
for i in {1..5}
do
echo $i
done

В примере ниже цикл будет итерироваться 5 раз.
Условные выражения
case expression in
pattern1)
В Bash используются case-установки для сравнения данного значения с коллекцией шаблонов и выполнения блока кода на основании первого шаблона, которому соответствует. Синтаксис для case-установки в Bash выглядит следующим образом:
;;
pattern2)
# код для выполнения, если выражение соответствует шаблону1
;;
pattern3)
# код для выполнения, если выражение соответствует шаблону2
;;
*)
# код для выполнения, если выражение соответствует шаблону3
;;
esac
# код для выполнения, если никак один из вышеуказанных шаблонов не соответствует выражению
В этом контексте “выражение” – это значение, с которым мы хотим сравнить, а “шаблон1”, “шаблон2”, “шаблон3” и так далее – это шаблоны, с которыми мы хотим сравнить его.
Двойной символ двух冒 “;;” разделяет каждый блок кода для выполнения при каждом шаблоне. Звезда “*” представляет собой дефолтный случай, который выполняется, если никак один из указанных шаблонов не соответствует выражению.
fruit="apple"
case $fruit in
"apple")
echo "This is a red fruit."
;;
"banana")
echo "This is a yellow fruit."
;;
"orange")
echo "This is an orange fruit."
;;
*)
echo "Unknown fruit."
;;
esac
Посмотрим пример:
В этом примере, так как значение fruit равно apple, первый шаблон соответствует, и блок кода, который выводит This is a red fruit., выполняется. Если значение fruit было бы вместо этого banana, второй шаблон соответствовал бы и блок кода, который выводит This is a yellow fruit., выполнялся бы, и так далее.
Если значение fruit не соответствует никакому из указанных шаблонов, выполняется дефолтный случай, который выводит Unknown fruit.
Часть 7: управление пакетами ПО в Linux
Linux поставляется с несколькими встроенными программами. Но может быть нужно устанавливать новые программы в соответствии с вашими потребностями. Также может потребоваться обновлять существующие приложения.
7.1. Paкеты и управление paкетami
Что такое paкет?
Paкет – это набор файлов, объединенных вместе. Эти файлы необходимы для работы определенной программы. В этих файлах содержатся исполняемые файлы программы, библиотеки и другие ресурсы.
Кроме файлов, необходимых для работы программы, paкеты также содержат установочные скрипты, которые копируют файлы в нужные места. Программа может содержать множество файлов и зависимостей. Благодаря paкетным системам удобнее управлять всеми этими файлами и зависимостями одновременно.
Как differентны исходный код и бинарный код?
Программисты пишут исходный код на языке программирования. Затем этот исходный код компилируется в машинный код, который компьютер может понимать. Компилированный код называется бинарным кодом.
Когда вы скачиваете paкет, вы можете either получить исходный код or бинарный код. Исходный код – это читаемый человеком код, который может быть компилирован в бинарный код. Бинарный код – это компилированный код, который компьютер может понимать.
Исходные paкеты могут использоваться с любого типа машины, если исходный код был правильно компилирован. Бинарный код, с другой стороны, является компилированным кодом, специфичным для определенного типа машины или архитектуры.
uname -m
Вы можете найти архитектуру вашей машины с использованием команды uname -m.
x86_64
# вывод
Зависимости пакетов
Программы часто используют общие файлы. Вместо того чтобы включать эти файлы в каждый пакет, отдельный пакет может предоставить их для всех программ.
Для установки программы, которая требует эти файлы, вы также должны установить пакет, содержащий их. Это называется зависимостью пакета. Указание зависимостей делает пакеты более компактными и простыми за счет уменьшения дубликатов.
При установке программы также должны быть установлены ее зависимости. Большинство требуемых зависимостей обычно уже установлены, но может потребоваться несколько дополнительных. Поэтому не удивляйтесь, если к вашему выбранному пакету будут установлены несколько других пакетов. Это необходимые зависимости.
Менеджеры пакетов
Linux предлагает полную систему управления пакетами для установки, обновления, настройки и удаления программного обеспечения.
С помощью управления пакетами вы можете получить доступ к организованной базе тысяч программных пакетов, а также иметь возможность разрешать зависимости и проверять обновления программного обеспечения.
Пакеты можно управлять с помощью утилит командной строки, которые могут легко автоматизироваться системными администраторами, или через графический интерфейс.
Каналы/репозитории программного обеспечения
⚠️ Управление пакетами отличается для разных дистрибутивов. Здесь мы используем Ubuntu.
Установка программного обеспечения немного отличается в Linux по сравнению с Windows и Mac.
Linux использует репозитории для хранения программных пакетов. Репозиторий – это коллекция программных пакетов, доступных для установки через менеджер пакетов.
Пакетный менеджер также хранит индекс всех пакетов, доступных из репозитория. Иногда индекс перестраивается для того, чтобы убедиться, что он актуален, и узнать, какие пакеты были обновлены или добавлены в канал с момента последней проверки.
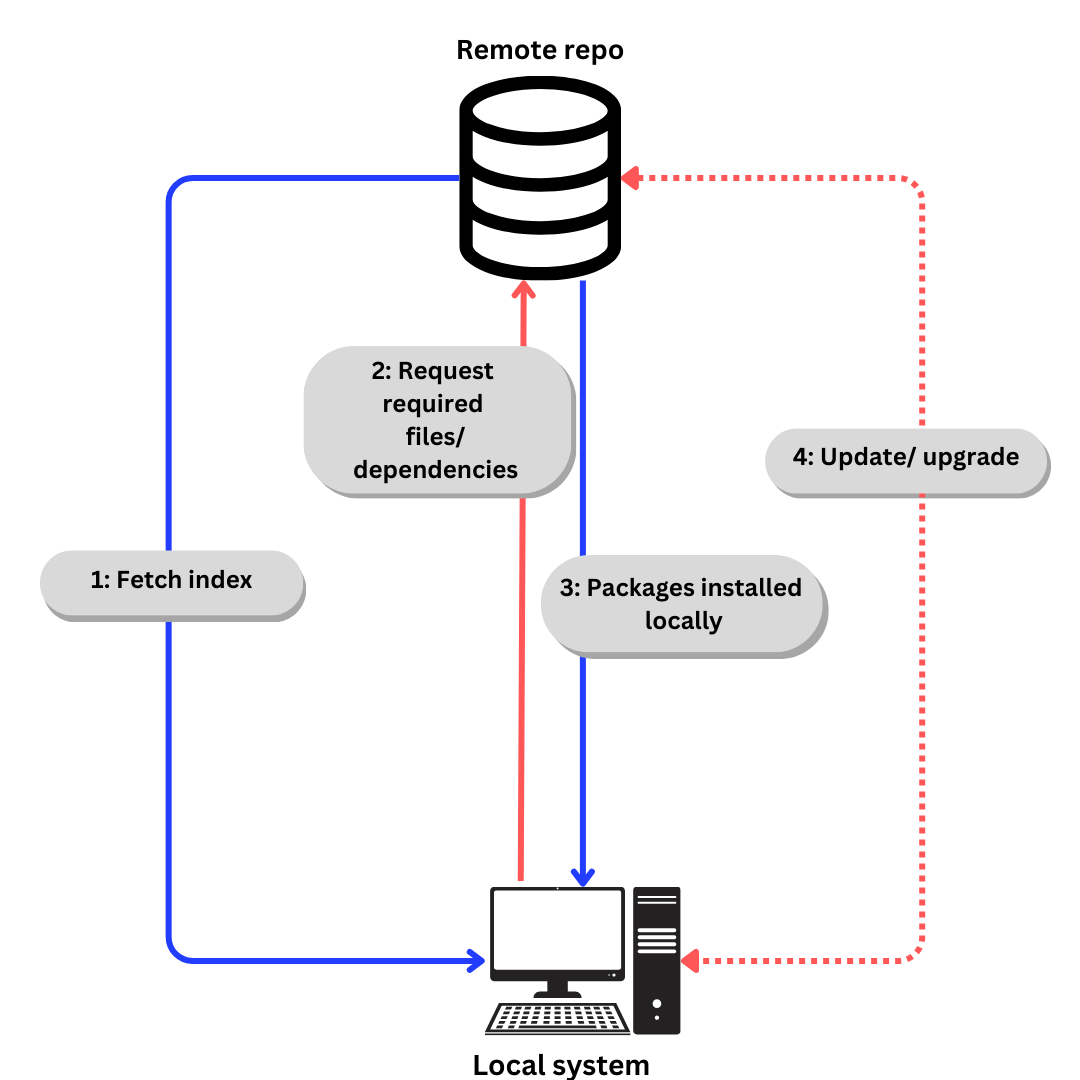
Общий процесс скачивания программного обеспечения из репозитория выглядит примерно так:
- Если мы говорим конкретно о Ubuntu,
- Индекс получается с помощью
apt update.(aptобъясняется в следующем разделе). - Необходимые файлы/зависимости запрашиваются по индексу с помощью
apt install - Пакеты и зависимости устанавливаются локально.
Обновляйте зависимости и пакеты по мере необходимости с помощью apt update и apt upgrade
В дистрибутивах на основе Debian список репозиториев (.repositories) можно найти в файле /etc/apt/sources.list.
7.2. Установка пакета с помощью командной строки
Команда apt – это мощное командное-line инструмент, который работает с “Advanced Packaging Tool (APT)” Ubuntu.
Чтобы просмотреть журналы установки с использованием /var/log/dpkg.log.
下 являются использованиями команды apt:
Установка пакетов
sudo apt install htop
例如, чтобы установить пакет htop, вы можете использовать следующую команду:
Обновление индекса списка пакетов
sudo apt update
Индекс списка пакетов – это список всех доступных пакетов в репозиториях. Чтобы обновить локальный индекс списка пакетов, вы можете использовать следующую команду:
Обновление пакетов
Установленные пакеты в вашей системе могут получить обновления, содержащие исправления ошибок, патчи для безопасности и новые функции.
sudo apt upgrade
Чтобы обновить пакеты, вы можете использовать следующую команду:
Удаление пакетов
sudo apt remove htop
Чтобы удалить пакет, как htop, вы можете использовать следующую команду:
7.3. Установка пакета с помощью усовершенствованного графического метода – Synaptic
Если вы не комфортно с командной строкой, вы можете использовать графическое приложение для установки пакетов. Вы можете достичь тех же результатов, что и с помощью командной строки, но с графическим интерфейсом.
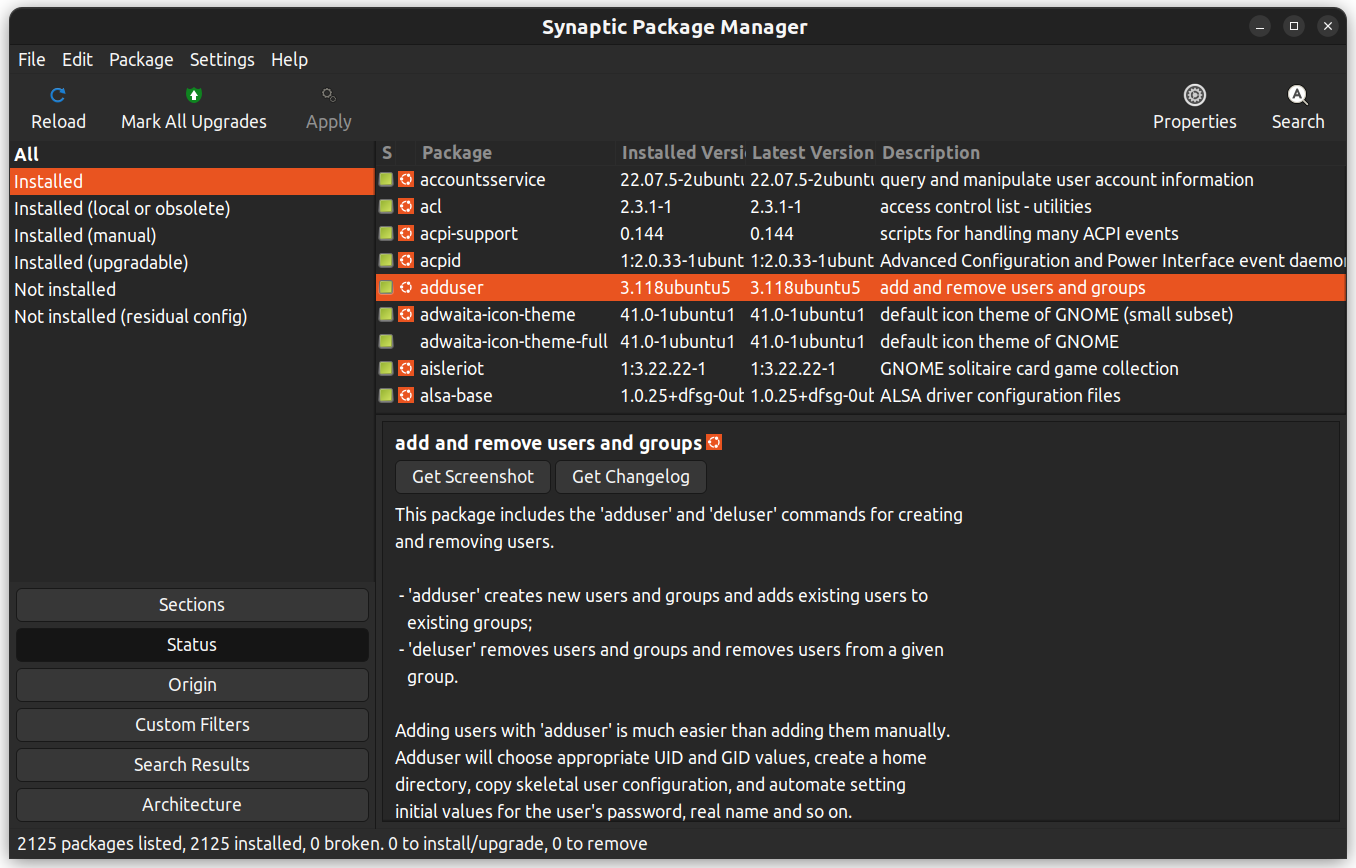
Synaptic – это графическое приложение для управления пакетами, которое помогает указать установленные пакеты, их статус, ожидаемые обновления и т. д. Оно предлагает пользовательские фильтры, чтобы помочь вам уменьшить результаты поиска.
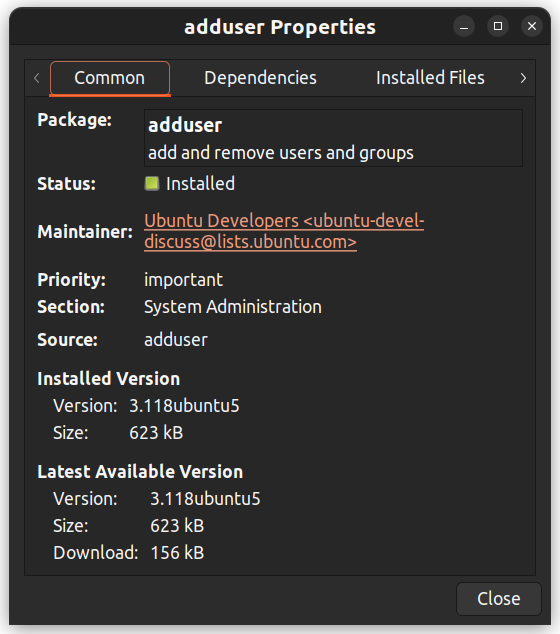
Вы также можете right-click на пакете и просмотреть дополнительные детали, такие как зависимости, участник обслуживания, размер и установленные файлы.
7.4. Установка загруженных пакетов с веб-сайта
Вы можете устанавливать пакет, который вы загрузили с веб-сайта, а не с репозитория программных обновлений. такие пакеты называются файлами .deb.
cd directory
sudo dpkg -i package_name.deb
Использованиеdpkgдля установки пакетов:dpkg — это инструмент для установки пакетов с командной строки. Чтобы установить пакет с помощью dpkg, откройте Терминал и введите следующую команду:
Примечание: замените “directory” на каталог, где хранится пакет, и “package_name” на имя файла пакета.
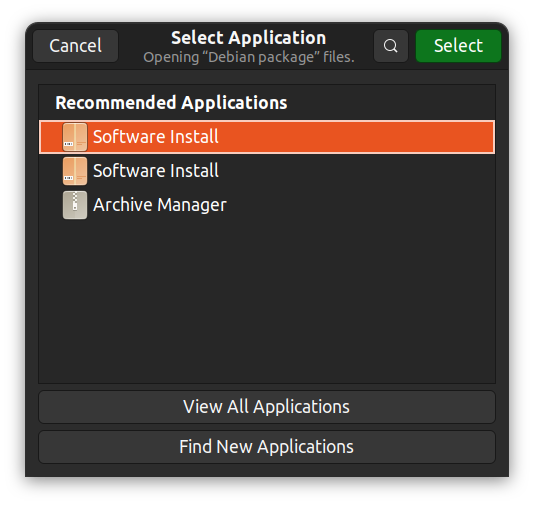
альтернативно, вы можете right-click, выбрать “Открыть с помощью другой приложения” и выбрать вашу выбор GUI app.
💡 Совет: В Ubuntu вы можете увидеть список установленных пакетов с помощью dpkg --list.
Часть 8: Продвиженные темы Linux
8.1. Управление пользователями
В системе может быть несколько пользователей с различными уровнями доступа. В Linux root-пользователь имеет наивысший уровень доступа и может выполнять любую операцию в системе. Обычные пользователи имеют ограниченный доступ и могут выполнять операции, для которых у них есть разрешение.
Что такое пользователь?
Пользовательский аккаунт обеспечивает разделение между различными людьми и программами, которые могут выполнять команды.
Человек идентифицирует пользователей именем, так как имена удобны для работы. Но система идентифицирует пользователей уникальным номером, называемым идентификатором пользователя (UID).
Когда пользователи вводят учетные данные, авторизуясь с помощью предоставленного имя пользователя, они должны ввести пароль.
Учетные записи пользователей являются основой системной безопасности. File ownership is also associated with user accounts and it enforces access control to the files.
- Каждая процедура связана с учетной записью пользователя, обеспечивая управление для администраторов.
- Суперпользователь: у суперпользователя есть полный доступ к системе.
- Системный пользователь: у системного пользователя есть учетные записи, используемые для запуска системных служб.
Обычный пользователь: обычные пользователи – это пользователи, имеющие доступ к системе.
id
uid=1000(john) gid=1000(john) groups=1000(john),4(adm),24(cdrom),27(sudo),30(dip)... output truncated
Пакет id отображает идентификационные данные пользователя и группы.
id username
Чтобы просмотреть основную информацию о другом пользователе, передайте имя пользователя в качестве аргумента команде id.
ps -u
Для просмотра информации о пользователях, связанной с процессами, используйте команду ps с флагом -u.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 16968 3920 ? Ss 18:45 0:00 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 18:45 0:00 [kthreadd]
Вывод
По умолчанию системы используют файл /etc/passwd для хранения информации о пользователях.
root:x:0:0:root:/root:/bin/bash
Вот строка из файла /etc/passwd:
- Файл
/etc/passwdсодержит следующую информацию о каждом пользователе: - Имя пользователя:
root– имя учетной записи пользователя. - Пароль:
x– зашифрованный пароль для учетной записи пользователя, хранящийся в файле/etc/shadowпо соображениям безопасности. - Идентификатор пользователя (UID):
0– уникальный числовой идентификатор учетной записи пользователя. - Идентификатор группы (GID):
0– основной идентификатор группы для учетной записи пользователя. - Информация о пользователе:
root– реальное имя учетной записи пользователя. - Домашняя директория:
/root– Домашняя директория учетной записи пользователя.
Оболочка: /bin/bash – По умолчанию используемая оболочка для учетной записи пользователя. Системный пользователь может использовать /sbin/nologin, если интерактивные входы не разрешены для этого пользователя.
Что такое группа?
Группа – это совокупность учетных записей пользователей, которые разделяют доступ и ресурсы. Группы имеют названия для их идентификации. Система идентифицирует группы с помощью уникального числового идентификатора, называемого идентификатором группы (GID).
По умолчанию информация о группах хранится в файле /etc/group.
adm:x:4:syslog,john
Вот запись из файла /etc/group:
- Вот разбор полей в данной записи:
- Название группы:
adm– Название группы. - Пароль:
x– Пароль для группы хранится в файле/etc/gshadowпо соображениям безопасности. Пароль является необязательным и появляется пустым, если не установлен. - Группа ID (GID):
4– уникальный числовой идентификатор для группы.
Участники группы: syslog,john – список имён пользователей, являющихся членами группы. В этом случае группа adm имеет два члена: syslog и john.
В этом конкретном записи группа носит имя adm, её ID составляет 4, и у группы два члена: syslog и john. Поле пароля обычно устанавливается в значение x, чтобы указать, что пароль группы хранится в файле /etc/gshadow.
- Группы далее делятся на ‘основные’ и ‘дополнительные’ группы.
- Основная Группа: Каждому пользователю по умолчанию присваивается одна основная группа. Эта группа, как правило, имеет то же имя, что и пользователь, и создается при создании учетной записи пользователя. Файлы и каталоги, созданные пользователем, обычно находятся в этой основной группе.
Дополнительные группы: это дополнительные группы, к которым пользователь может принадлежать, помимо основной группы. Пользователи могут быть членами нескольких дополнительных групп. Эти группы позволяют пользователю иметь разрешения для ресурсов, используемых этими группами. Они помогают предоставить доступ к общим ресурсам, не влияя на права доступа к файлам системы и сохраняя безопасность. Хотя пользователь должен принадлежать к одной основной группе, принадлежность к дополнительным группам является необязательной.
Контроль доступа: поиск и понимание прав доступа к файлам
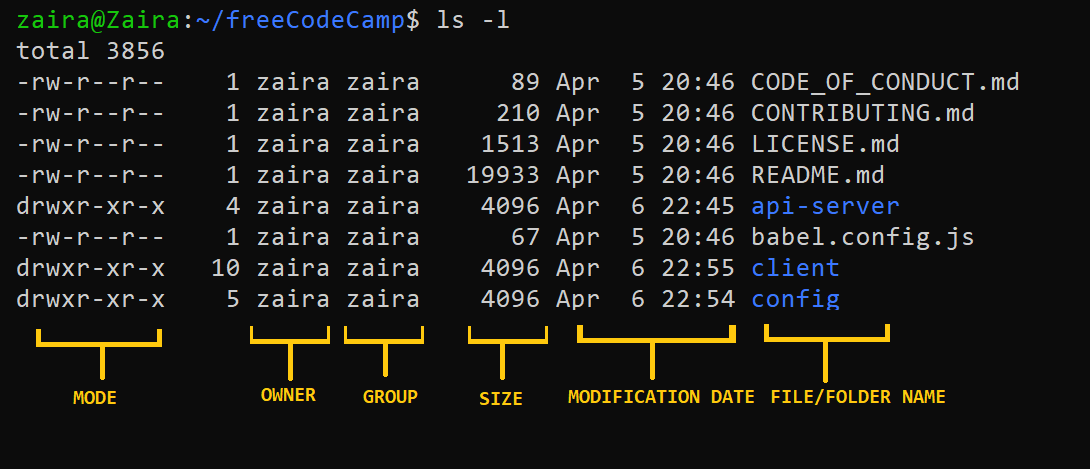
Владение файлом можно просмотреть с помощью команды ls -l. Первый столбец в выводе команды ls -l показывает права доступа к файлу. Другие столбцы показывают владельца файла и группу, к которой файл принадлежит.

Давайте ближе рассмотрим столбец mode:
- Режим определяет две вещи:
- Файловый тип: Файловый тип определяет тип файла. Для обычных файлов, содержащих простой данные, он отображается как пустой
-. Для других специальных типов файлов символ отличается. Для каталога, являющегося специальным файлом, он выделен какd. Специальные файлы обрабатываются операционной системой по-разному.
Классы разрешений: Следующий набор символов определяет разрешения для пользователя, группы и других пользователей соответственно.
– Пользователь: Это владелец файла и владелец файла принадлежит к этому классу.
– Группа: Члены группы файла принадлежат к этому классу
– Другие: Все пользователи, не являющиеся частью классов пользователей или групп, принадлежат к этому классу.
💡Подсказка: Просмотр владения каталогом может осуществляться с помощью команды ls -ld.
Как читать символические разрешения или разрешения rwx
- Представление
rwxназывается символической репрезентацией разрешений. В наборе разрешений, - читать. Он обозначается в первом символе триады.
wозначает записывать. Он обозначается во втором символе триады.
x означает выполнение. Он обозначается в третьем символе триады.
Чтение:
Для обычных фалов, права на чтение позволяют открывать и читать файл, но не могут позволить изменять его.
Также для каталогов, права на чтение позволяют просматривать содержимое каталога без каких-либо изменений внутри него.
Запись:
Когда у фалов есть права на запись, пользователь может изменять (редактировать, удалять) файл и сохранять его.
Для папок, права на запись позволяют пользователю изменять ее содержимое (создавать, удалять и переименовывать файлы внутри нее), а также изменять содержимое фалов, у которых пользователь имеет права на запись.
Примеры разрешений в Linux
- Теперь, когда мы узнаем, как читать разрешения, посмотрим на несколько примеров.
-
-rw-rw-r--: Файл, который может быть изменён его владельцем и группой, но не другими пользователями.
drwxrwx---: Каталог, который может быть изменён его владельцем и группой.
Исполнение:
Для файлов, право на выполнение позволяет пользователю запустить исполняемый сценарий. Для каталогов, пользователь может получить доступ к ним и к информации о файлах в каталоге.
Как изменить права доступа и владение файлами в Linux с помощью chmod и chown
Теперь, когда мы знаем основы владения и разрешений, давайте узнаем, как мы можем изменить разрешения с помощью команды chmod.
chmod permissions filename
Синтаксис chmod:
- Где,
разрешениямогут быть чтение, запись, выполнение или их комбинация.
имя_файла – имя файла, для которого нужно изменить разрешения. Этот параметр также может быть списком файлов, для которых нужно изменить разрешения массово.
- Мы можем изменить разрешения в двух режимах:
- Символьный режим: Этот метод использует символы такие как
u,g,oдля представления пользователя, группы и других. Права доступа представляются символамиr, w, xдля чтения, записи и выполнения, соответственно. Вы можете изменять права доступа с использованием знаков +, – и =.
Абсолютный режим: Этот метод представляет права доступа тремя цифрами в восьмеричной системе счисления от 0 до 7.
Теперь давайте рассмотрим их подробнее.
Как изменить права доступа с использованием символьного режима
| В таблице ниже представлено обобщение представления пользователей: | ПРЕДСТАВЛЕНИЕ ПОЛЬЗОВАТЕЛЯ |
| u | ОПИСАНИЕ |
| g | пользователь/владелец |
| o | группа |
другие
| Мы можем использовать математические операторы для добавления, удаления и назначения прав. В таблице ниже показано обобщение: | ОПЕРАТОР |
| ОПИСАНИЕ | + |
| Добавляет право доступа к файлу или каталогу | – |
| Удаляет право доступа | \= |
Устанавливает разрешения, если они не существуют ранее. Также переопределяет разрешения, установленные ранее.
Пример:
Предположим, у меня есть сценарий и я хочу сделать его исполняемым для владельца файла zaira.

Текущие разрешения файла выглядят следующим образом:
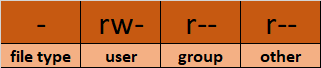
Поделим разрешения так:
chmod u+x mymotd.sh
Чтобы добавить права выполнения (x) для владельца (u) с использованием символьного метода, мы можем использовать команду ниже:
Вывод:
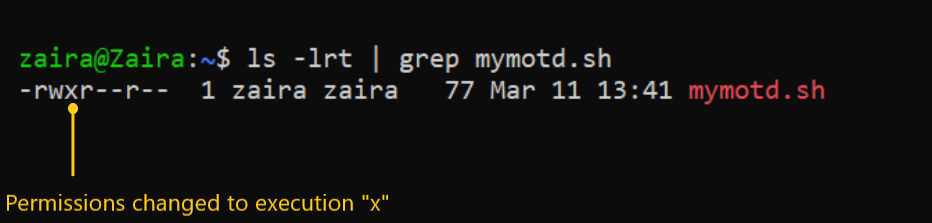
Теперь мы можем увидеть, что права выполнения были добавлены для владельца zaira.
- Дополнительные примеры для изменения разрешений с помощью символьного метода:
- Удаление права
read(чтение) иwrite(запись) дляgroup(группы) иothers( других):chmod go-rw. - Удаление права
read(чтение) дляothers(других):chmod o-r.
Назначение права write (запись) для group (группы) и переопределение существующих разрешений: chmod g=w.
Как изменять разрешения с использованием абсолютного режима
Абсолютный режим использует числа для представления прав и математические операции для их изменения.
| 下表展示了我们如何分配相关权限: | ПРЕДИСПОНЕННЫЕ |
| ПРЕДАТЬ ПРАВА | чтение |
| добавить 4 | писание |
| добавить 2 | выполнение |
добавить 1
| Права могут быть отозваны с помощью вычитания.下表展示了如何删除相关权限。 | ПРЕДИСПОНЕННЫЕ |
| ОТВЕСТИ ПРАВА | чтение |
| вычитать 4 | писание |
| вычитать 2 | выполнение |
вычитать 1
- Пример:
Установить чтение (добавить 4) для пользователя, чтение (добавить 4) и выполнение (добавить 1) для группы, и только выполнение (добавить 1) для других.
chmod 451 file-name
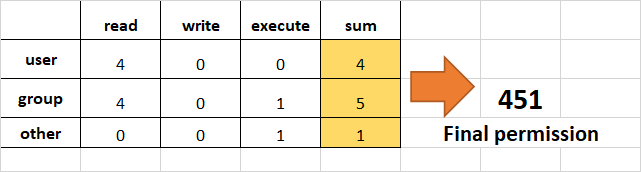
Так мы производили вычисления:
- Обратите внимание, что это то же самое, что и
r--r-x--x.
Удалите права выполнения из других и группы.
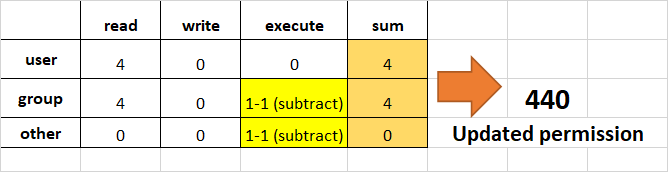
- Чтобы удалить выполнение из
другихигруппы, вычитайте 1 из части выполнения последних двух октат.
Добавьте lectura, escritura y ejecución para usuario, lectura y ejecución para grupo y только lectura para otros.

Это будет одинаково, как rwxr-xr--.
Как изменить владение используя команду chown
В следующем уроке мы узнаем, как изменить владение файла. Вы можете изменить владение файла или папки с помощью команды chown. В некоторых случаях изменение владения требует разрешений sudo.
chown user filename
Синтаксис chown
Как изменить владение пользователя с помощью chown
Пожалуйста, передайте владение от пользователя zaira пользователю news.

chown news mymotd.sh
Команда для изменения владения: sudo chown news mymotd.sh.

Вывод:
Как изменить владение пользователя и группы одновременно
chown user:group filename
Мы также можем использовать chown, чтобы изменить пользователя и группу одновременно.
Как изменить владение каталога
chown -R admin /opt/script
Вы можете изменить владение рекурсивно для содержимого каталога. В примере ниже изменяется владение каталога /opt/script, чтобы позволить пользователю admin.
Как изменить владение группы
chown :admins /opt/script
В случае, если我们需要 только изменить владельца группы, мы можем использовать chown, добавив перед именем группыCOLON :
Как переключаться между пользователями
[user01@host ~]$ su user02
Password:
[user02@host ~]$
Вы можете переключаться между пользователями с помощью команды su.
Как получить доступ с правами суперпользователя
Суперпользователь или пользователь root обладает высшим уровнем доступа на Linux-системе.Root-пользователь может выполнять любую операцию на системе.Root-пользователь может доступать к всем файлам и каталогам, устанавливать и удалять программы, а также изменять или переопределять системные настройки.
Сила приносит с собой ответственность. Если у root-пользователя произойдет взлом, кому-то может быть предоставлен полный контроль над системой. рекомендуется использовать учетную запись root-пользователя только в случае необходимости.
[user01@host ~]$ su
Password:
[root@host ~]Если вы опустите имя пользователя, команда su по умолчанию переключится на учетную запись root-пользователя.
#
Другая вариация команды su – это команда su -. Команда su переключает на учетную запись root-пользователя, но не меняет переменные среды. Команда su - переключает на учетную запись root-пользователя и меняет переменные среды на те, которые у целевого пользователя.
Выполнение команд с sudo
Чтобы выполнять команды с правами root без переключения на учетную запись root, вы можете использовать команду sudo. Команда sudo позволяет вам выполнять команды с повышенными привилегиями.
Выполнение команд с помощью sudo является более безопасной опцией, чем выполнение команд с правами root. Это because, только определенный набор пользователей может быть разрешены для выполнения команд с помощью sudo. Это определено в файле /etc/sudoers.
Также sudo записывает все команды, выполняемые с ним, предоставляя трассировку аудита о том, кто выполнил какие команды и когда.
cat /var/log/auth.log | grep sudo
В Ubuntu вы можете найти аудит логгирования здесь:
user01 is not in the sudoers file. This incident will be reported.
Для пользователя, который не имеет доступа к sudo, в логах она отмечена и вызывает сообщение, подобное этому:
Управление локальными учетными записями пользователей
Создание пользователей с помощью командной строки
sudo useradd username
Команда для добавления нового пользователя:
Эта команда устанавливает домашнюю директорию пользователя и создает частную группу, определенную именем пользователя. В настоящее время учетная запись не имеет действительного пароля, что защищает вход пользователя до тех пор, пока не будет создан пароль.
Изменение существующих пользователей
Команда usermod используется для изменения существующих пользователей. Вот некоторые из обычных опций, используемых с командой usermod:
- Вот несколько примеров использования команды
usermodв Linux: - Измените имя входа пользователя:
- Измените домашнюю директорию пользователя:
- Добавьте пользователя в дополнительную группу:
- Измените оболочку пользователя:
- Заблокируйте учетную запись пользователя:
- Открыть учетную запись пользователя:
- Установить срок истечения учетной записи пользователя:
- Изменить идентификационный номер пользователя (UID):
- Изменить основную группу пользователя:
Удаление пользователя из вспомогательной группы:
Удаление пользователей
- Команда
userdelиспользуется для удаления учетной записи пользователя и связанных с ней файлов с системы. sudo userdel username: удаляет данные пользователя из/etc/passwd, но сохраняет домашнюю директорию пользователя.
Команда sudo userdel -r username удаляет данные пользователя из /etc/passwd и также удаляет домашнюю директорию пользователя.
Изменение паролей пользователей
- Команда
passwdиспользуется для изменения пароля пользователя.
sudo passwd username: устанавливает инициальный пароль или изменяет существующий пароль для пользователя username. Она также используется для изменения пароля текущего пользователя.
8.2 Подключение к удаленным серверам через SSH
Производить доступ к удалённым серверам является одной из основных задач для системных администраторов. Вы можете подключаться к различным серверам или обращаться к базам данных через вашу локальную машину и выполнять команды, все с использованием SSH.
Что такое протокол SSH?
SSH означает Secure Shell. Это криптографический сетевой протокол, который позволяет безопасно осуществлять связь между двумя системами.
Порт по умолчанию для SSH — 22.
- Два участника, обменивающихся сообщениями по SSH:
- Сервер: машина, к которой вы хотите получить доступ.
Клиент: система, с которой вы осуществляете доступ к серверу.
- Соединение с сервером происходит по следующим этапам:
- Инициировать соединение: клиент посылает запрос на соединение серверу.
- Обмен ключами: сервер посылает свой открытый ключ клиенту. Обе стороны соглашаются на использование методов шифрования.
- Генерация сессионного ключа: клиент и сервер используют обмен ключами Диффи-Хеллмана для создания общего сессионного ключа.
- Аутентификация клиента: Клиент входит на сервер, используя пароль, закрытый ключ или другой метод.
Защищенное общение: После аутентификации клиент и сервер безопасно общаются с помощью шифрования.
Как подключиться к удаленному серверу с помощью SSH?
Команда ssh является встроенным инструментом в Linux и также является стандартной. Она делает доступ к серверам довольно простым и безопасным.
Здесь мы говорим о том, как клиент может установить соединение с сервером.
- До подключения к серверу вам нужно иметь следующую информацию:
- IP-адрес или доменное имя сервера.
- Имя пользователя и пароль сервера.
Номер порта, к которому у вас есть доступ на сервере.
ssh username@server_ip
Базовая синтаксис команды ssh такова:
ssh [email protected]
Например, если ваше имя пользователя john и IP-адрес сервера 192.168.1.10, команда будет такой:
[email protected]'s password:
Welcome to Ubuntu 20.04.2 LTS (GNU/Linux 5.4.0-70-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Fri Jun 5 10:17:32 UTC 2024
System load: 0.08 Processes: 122
Usage of /: 12.3% of 19.56GB Users logged in: 1
Memory usage: 53% IP address for eth0: 192.168.1.10
Swap usage: 0%
Last login: Fri Jun 5 09:34:56 2024 from 192.168.1.2
john@hostname:~$ После этого вас запросят ввести секретный пароль. Ваш экран будет выглядеть примерно так:
начинайте вводить команды
Теперь вы можете выполнять соответствующие команды на сервере 192.168.1.10.
ssh -p port_number username@server_ip
⚠️ Порт ssh по умолчанию 22, но он также уязвимым, так как хакеры, скорее всего, сначала попробуют здесь. Ваш сервер может открыть другой порт и поделиться доступом с вами. Чтобы подключиться к другому порту, используйте флаг -p.
8.3. Расширенный анализ и парсинг журналов
Файлы журналов, когда настроены, генерируются вашей системой по различным полезным причинам. Они могут использоваться для отслеживания событий системы, мониторинга производительности системы и устранения неполадок. Они особенно полезны для системных администраторов, где они могут отслеживать ошибки приложений, сетевые события и активность пользователей.
Вот пример файла журнала:
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 DEBUG Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 WARN Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 DEBUG API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
# пример файла журнала
- Файл журнала обычно содержит следующие колонки:
- Метка времени: Дата и время, когда произошло событие.
- Уровень журнала: Серьезность события (INFO, DEBUG, WARN, ERROR).
- Компонент: Компонент системы, который генерировал событие (Startup, Config, Database, User, Security, Network, Email, API, Session, Shutdown).
- Сообщение: Описание произошедшего события.
Дополнительная информация: Дополнительная информация, связанная с событием.
В реального времени системах журналы обычно должны быть тысячи строк длиной и генерироваться каждый секунду. Они могут быть очень сложными в зависимости от конфигурации. Каждая колонка в журнале является единицей информации, которая может использоваться для устранения проблем. Это делает разбор журналов сложным для выполнения вручную.
В этом месте наступает полезная роль анализа журналов. Анализ журналов – это процесс извлечения полезной информации из журналов. Это заключается в разбиении журналов на более мелкие, более управляемые части и извлечение соответствующей информации.
Очищенная информация также может быть полезна для создания оповещений, отчетов и панелей информации.
В этом разделе вы узнаете о нескольких техниках анализа журналов в Linux.
Извлечение текста с использованием grep
Grep – встроенный инструмент Bash. Он означает “глобальное выражение регулярных выражений”. Grep используется для идентификации подстрок в файлах.
- Вот несколько обычных использований
grep: - Эта команда ищет “search_string” в файле с именем
filename. - Эта команда ищет “
search_string” во всех файлах указанной директории и ее поддиректориях. - Эта команда выполняет регистронезависимый поиск “search_string” в файле с именем
filename. - Эта команда показывает номера строк вместе с соответствующими строками в файле с именем
filename. - Эта команда подсчитывает количество строк, содержащих “search_string” в файле с именем
filename. - Эта команда отображает все строки, не содержащие “строку_поиска” в файле с именем
имя_файла. - Эта команда ищет слово “слово” в файле с именем
имя_файла.
Эта команда позволяет использовать расширенные регулярные выражения для более сложного сопоставления шаблонов в файле с именем имя_файла.
💡 Совет: Если в папке есть несколько файлов, вы можете использовать следующую команду, чтобы найти список файлов, содержащих желаемые строки.
grep -l "String to Match" /path/to/directory
# находит список файлов, содержащих желаемые строки
Использование sed
sed означает “потоковый редактор”. Он обрабатывает данные потоково, что意味着 он читает данные по одной строке в раз. sed позволяет искать модели и выполнять действия с соответствующими строками.
Базовая синтаксисsed:
sed [options] 'command' file_name
Базовая синтаксис sed выглядит следующим образом:
В этом команда используется для выполнения операций, таких как замена, удаление, вставка и т. д., на текстовые данные. Имя файла – это имя файла, которое вы хотите обрабатывать.
sedиспользование:
1. Замена:
sed 's/old-text/new-text/' filename
Флаг s используется для замены текста. старый-текст заменяется новый-текст:
sed 's/error/warning/' system.log
Например, чтобы изменить все встречи “error” на “warning” в лог-файле system.log:
2. Печать строк с определенной моделью:
sed -n '/pattern/p' filename
Использование sed для фильтрации и отображения строк, соответствующих определенной модели:
sed -n '/ERROR/p' system.log
Например, чтобы найти все строки содержащие “ERROR”:
3. Удаление строк с определенной моделью:
sed '/pattern/d' filename
Вы можете удалить строки из выхода, соответствующие определенной модели:
sed '/DEBUG/d' system.log
Например, для удаления всех строк содержащих “DEBUG”:
4.Extracting specific fields from a log line:
sed -n 's/^\([0-9]\{4\}-[0-9]\{2\}-[0-9]\{2\}\).*/\1/p' system.log
Вы можете использовать регулярные выражения для извлечения частей строк. Предположим, что каждая строка лога начинается с даты в формате “ГГГГ-MM-ДД”. Вы могли бы извлечь только дату из каждой строки:
Парсинг текста с awk
awk обладает способностью легко разделять каждую строку на поля. Он идеально подходит для обработки структурированного текста, такого как лог-файлы.
Базовая синтаксисawk
awk 'pattern { action }' file_name
Базовая синтаксис awk таков:
В этом месте pattern — условие, которое должно быть удовлетворено, чтобы действие action было выполнено. Если условиеpattern опущено, действие выполняется на каждой строке.
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
- В следующих примерах вы будете использовать этот лог-файл в качестве примера:
Использование столбцов с помощьюawk
zaira@zaira-ThinkPad:~$ awk '{ print $1 }' sample.log
Поля в awk (разделены по умолчанию пробелами) могут быть обращены с использованием $1, $2, $3 и т. д.
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
zaira@zaira-ThinkPad:~$ awk '{ print $2 }' sample.log
# вывод
09:00:00
09:01:00
09:02:00
09:03:00
09:04:00
09:05:00
09:06:00
09:07:00
09:08:00
09:09:00
- # вывод
awk '/ERROR/ { print $0 }' logfile.log
Печать строк, содержащих определенный шаблон (например, ERROR)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
# вывод
- Это печатает все строки, содержащие “ERROR”.
awk '{ print $1, $2 }' logfile.log
Извлечение первого поля (Дата и время)
2024-04-25 09:00:00
2024-04-25 09:01:00
2024-04-25 09:02:00
2024-04-25 09:03:00
2024-04-25 09:04:00
2024-04-25 09:05:00
2024-04-25 09:06:00
2024-04-25 09:07:00
2024-04-25 09:08:007
2024-04-25 09:09:00
# вывод
- Это извлечет первые два поля из каждой строки, которые в этом случае будут датой и временем.
awk '{ count[$3]++ } END { for (level in count) print level, count[level] }' logfile.log
Сводка по встречаемости каждого уровня лога
1
WARN 1
ERROR 1
DEBUG 2
INFO 6
# вывод
- Вывод будет отображать общее количество вхождений для каждого уровня журналирования.
awk '{ $3="INFO"; print }' sample.log
Отфильтруйте определённые поля (например, где третье поле - INFO)
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
# вывод
Эта команда будет извлекать все строки, где третье поле содержит “INFO”.
💡 Подсказка: Default разделитель в awk – это пробел. Если ваш лог-файл использует другой разделитель, можете указать его с помощью опции -F. Например, если ваш лог-файл использует запятую в качестве разделителя, можете использовать awk -F, '{ print $1 }' logfile.log для выделения первого поля.
Парсинг лог-файлов с cut
Команда cut – это простая, yet мощная команда, используемая для извлечения отдельных секций текста из каждой строки входного текста. Since лог-файлы структурированы и каждое поле delimited специфическим символом, например, пробелом, tab-ом или custom разделителем, команда cut отлично подходит для выделения этих конкретных полей.
cut [options] [file]
Basic синтаксис команды cut:
- Некоторые commonly используемые опции для команды cut:
-d: указать delimiter, используемый в качестве разделителя полей.-f: выбрать поля для отображения.
-c : Указывает позиции символов.
cut -d ' ' -f 1 logfile.log
Например, команда ниже извлекла бы первое поле (разделенное пробелом) из каждой строки файла журнала:
Примеры использованияcutдля анализа журналов
2024-04-25 08:23:01 INFO 192.168.1.10 User logged in successfully.
2024-04-25 08:24:15 WARNING 192.168.1.10 Disk usage exceeds 90%.
2024-04-25 08:25:02 ERROR 10.0.0.5 Connection timed out.
...
Предположим, у вас есть файл журнала с такой структурой, где поля разделены пробелами:
cutможет использоваться следующим образом:
cut -d ' ' -f 2 system.log
Извлечение времени из каждой записи журнала:
08:23:01
08:24:15
08:25:02
...
# Вывод
- Эта команда использует пробел в качестве разделителя и выбирает второе поле, которое является временной компонентой каждой записи журнала.
cut -d ' ' -f 4 system.log
Извлечение IP-адресов из журналов:
192.168.1.10
192.168.1.10
10.0.0.5
# Вывод
- Эта команда извлекает четвертое поле, которое является IP-адресом из каждой записи журнала.
cut -d ' ' -f 3 system.log
Извлечение уровней журнала (INFO, WARNING, ERROR):
INFO
WARNING
ERROR
# Вывод
- Это извлекает третье поле, которое содержит уровень журнала.
Комбинированиеcutс другими командами:
grep "ERROR" system.log | cut -d ' ' -f 1,2
Вывод других команд может быть передан в команду cut с помощью конвейера. Допустим, вы хотите отфильтровать журналы перед обрезкой. Вы можете использовать grep, чтобы извлечь строки, содержащие "ERROR", и затем использовать cut, чтобы получить конкретную информацию из этих строк:
2024-04-25 08:25:02
# Вывод
- Этот команда сначала фильтрует строки, содержащие “ERROR”, затем извлекает дату и время из этих строк.
Extracting multiple fields:
cut -d ' ' -f 1,2,3 system.log`
Процесс извлечения нескольких полей за один раз, путём указания диапазона или списка полей, разделённых запятыми:
2024-04-25 08:23:01 INFO
2024-04-25 08:24:15 WARNING
2024-04-25 08:25:02 ERROR
...
# Output
Предыдущая команда извлекает первые три поля из каждого записи лога, которыми являются дата, время и уровень лога.
Разботка лог-файлов с помощью `sort` и `uniq`
Сортировка и удаление дубликатов являются общими операциями при работе с лог-файлами.COMMAND`sort` и `uniq` — мощные команды, используемые для сортировки и удаления дубликатов из входных данных, соответственно.
基本语法 sort
sort [options] [file]
Команда `sort` упорядочивает строки текста в алфавитном порядке или по значениям числам.
- Некоторые ключевые опции для команды sort:
-n: Сортирует файл, предполагая, что содержимое является числовым.-r: Обратный порядок сортировки.-k: Указание ключа или номер колонки для сортировки.
-u: Сортирует и удаляет дублированные строки.
Команда uniq используется для фильтрации или计数 и отчета о повторяющихся строках в файле.
uniq [options] [input_file] [output_file]
Синтаксис uniq таков:
- Некоторые ключевые опции для команды
uniq如下: -c: Префикс строк числом вхождений.-d: Printjao только дублированные строки.
-u: Printjao только уникальные строки.
Примеры использования sort и uniq вместе для анализа логов
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-26 ERROR Connection timed out.
- Предположим следующий пример entries логов для этих демонстраций:
sort system.log
Сортировка entries логов по дате:
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# Output
- Эта команда сортирует entries логов по алфавиту, что эффективно сортирует их по дате, если дата является первым полем.
sort system.log | uniq
Сортировка и удаление дубликатов:
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# Output
- Эта команда сортирует файл логов и подает его на вход
uniq, удаляя дубликаты строк.
sort system.log | uniq -c
Количество вхождений каждой строки:
2 2024-04-25 INFO User logged in successfully.
1 2024-04-25 WARNING Disk usage exceeds 90%.
2 2024-04-26 ERROR Connection timed out.
1 2024-04-26 INFO Scheduled maintenance.
# Output
- Сортирует entries логов и затем считает количество уникальных строк. По сообщению вывода, строка
'2024-04-25 INFO User logged in successfully.'появляется 2 раза в файле.
sort system.log | uniq -u
Определение уникальных записей лога:
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 INFO Scheduled maintenance.
# Вывод
- Эта команда показывает уникальные строки.
sort -k2 system.log
Сортировка по уровню лога:
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-25 WARNING Disk usage exceeds 90%.
# Вывод
Записи сортируются на основе второго поля, которым является уровень лога.
8.4. Управление процессами Linux по командной строке
- Процесс — это запущенная инстанция программы. Процесс состоит из:
- Области адресации выделенной памяти.
- Состояний процесса.
Свойств, таких как владелец, атрибуты безопасности и использование ресурсов.
- Кроме того, у процесса есть среда, которая состоит из:
- Локальных и глобальных переменных
- Текущего контекста планирования
Выделенных системных ресурсов, таких как сетевые порты или дескрипторы файлов.
Когда вы запускаете команду ls -l, операционная система создает новый процесс для выполнения команды. У процесса есть идентификатор, состояние и он выполняется до завершения команды.
Понимание создания процессов и их цикла жизни
В Ubuntu все процессы происходят от начального системного процесса, называемого systemd, который является первым процессом, запущенным ядром во время загрузки.
Процесс systemd имеет идентификатор процесса (PID) 1 и отвечает за инициализацию системы, запуск и управление другими процессами, а также обслуживание системных служб. Все другие процессы в системе являются потомками systemd.
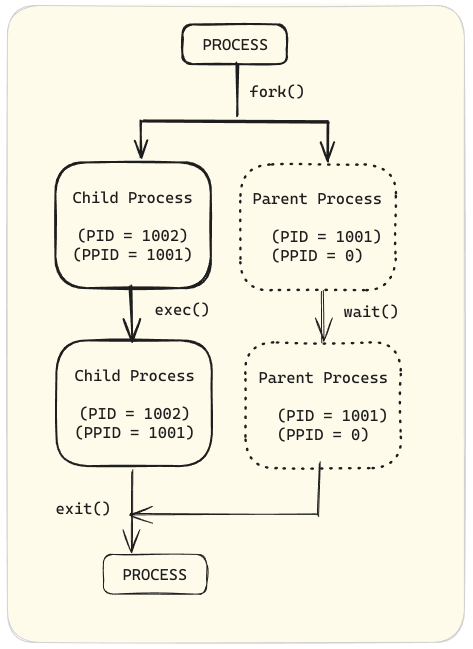
Родительский процесс дублирует свое собственное адресное пространство (форк) для создания новой структуры процесса (потомка). Каждому новому процессу присваивается уникальный идентификатор процесса (PID) для отслеживания и целей безопасности. PID и идентификатор родительского процесса (PPID) являются частью среды нового процесса. Любой процесс может создать дочерний процесс.
Через процедуру форка дочерний процесс наследует идентификации безопасности, предыдущие и текущие дескрипторы файлов, привилегии портов и ресурсов, переменные среды и код программы. Дочерний процесс может затем выполнить свой собственный код программы.
Обычно родительский процесс спит, пока выполняется дочерний процесс, устанавливая запрос (ожидание), чтобы быть уведомленным, когда дочерний процесс завершится.
После завершения работы дочерний процесс уже закрыл или отбросил свои ресурсы и среду. Единственным оставшимся ресурсом, известным как зомби, является запись в таблице процессов. Родительский процесс, уведомленный о завершении работы дочернего процесса, очищает таблицу процессов от записи дочернего процесса, тем самым освобождая последний ресурс дочернего процесса. Родительский процесс затем продолжает выполнение своего собственного кода программы.
Понимание состояний процесса

Процессы в Linux могут находиться в различных состояниях в течение их жизненного цикла. Состояние процесса указывает, что происходит в данный момент и как процесс взаимодействует с системой. Процессы переходят между состояниями на основе своего статуса выполнения и алгоритма планирования системы.
| Процессы в Linux могут находиться в одном из следующих состояний: | Состояние |
| Описание | (new) |
| Исходное состояние, когда процесс создается с помощью системного вызова fork. | Выполняемое (готово) (R) |
| Процесс готов к выполнению и ожидает рассрочения на CPU. | Выполняемое (пользовательское) (R) |
| Процесс выполняется в пользовательском режиме, запуская пользовательские приложения. | Выполняемое (ядро) (R) |
| Процесс выполняется в ядровом режиме, обрабатывая системные вызовы или hardware interrupts. | Ожидание (S) |
| Процесс ждет события (например, операцию I/O) для завершения и может быть легко пробужден. | Ожидание (непрерывное) (D) |
| Процесс находится в состоянии непрерывного ожидания, ждет определенного условия (обычно I/O) для завершения, и не может быть прерван сигналами. | Ожидание (отложенное на диск) (K) |
| Процесс ждет операций I/O на диске для завершения. | Ожидание (бездействие) (I) |
| Процесс не выполняет никаких действий и ждет происхождения события. | Остановлено (T) |
| Выполнение процесса было остановлено, обычно сигналом, и может быть возобновлено позднее. | Зомби (Z) |
Процесс завершил выполнение, но еще содержит запись в таблице процессов, жду его родителя, чтобы прочесть статус выхода.
| Процессы переходят между этими состояниями следующим образом: | Переход |
| Описание | Fork |
| Создает новый процесс из родительского процесса, переходя от (новый) к готовому к выполнению (R). | Расчет |
| Планировщик выбирает готовый к выполнению процесс и переходит его в состояние запущенного (пользовательское) или запущенного (ядро) состояние. | Выполнение |
| Процесс переходит от готового к выполнению (R) к запущенному (ядро) (R) состоянию, когда его запускают для выполнения. | Преempt или пересчет |
| Процесс может быть преempted или пересчитан, переходя обратно в состояние готового к выполнению (R). | Системный вызов |
| Процесс делает системный вызов, переходя от запущенного (пользовательское) (R) к запущенному (ядро) (R) состоянию. | Возврат |
| Процесс завершает системный вызов и возвращается к запущенному (пользовательское) (R) состоянию. | Ожидание |
| Процесс ожидает события, переходя от запущенного (ядро) (R) к одному из состояний сна (S, D, K или I). | Событие или сигнал |
| Процесс просыпается событием или сигналом, перемещая его с состояния сна обратно в готовое (работающее) состояние (R). | Приостановить |
| Процесс приостановлен, переходя из запущенного (ядро) или готового (работающее) состояния в остановленное (T) состояние. | Продолжить |
| Процесс продолжается, перемещаясь из остановленного (T) состояния обратно в готовое (работающее) состояние (R). | Выход |
| Процесс завершается, переходя из запущенного (пользовательское) или запущенного (ядро) состояния в зомби (Z) состояние. | Обработать |
Родительский процесс считывает статус выхода зомби-процесса и удаляет его из таблицы процессов.
Как просмотреть процессы
zaira@zaira:~$ ps aux
Вы можете использовать команду ps в сочетании с опциями, чтобы просмотреть процессы на Linux-системе. Команда ps используется для отображения информации о нескольких активных процессах. Например, ps aux отображает все процессы, запущенные на системе.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 168140 11352 ? Ss May21 0:18 /sbin/init splash
root 2 0.0 0.0 0 0 ? S May21 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? I< May21 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< May21 0:00 [rcu_par_gp]
root 5 0.0 0.0 0 0 ? I< May21 0:00 [slub_flushwq]
root 6 0.0 0.0 0 0 ? I< May21 0:00 [netns]
root 11 0.0 0.0 0 0 ? I< May21 0:00 [mm_percpu_wq]
root 12 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_kthread]
root 13 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_rude_kthread]
*... output truncated ....*
# Вывод
- Вышеописанный вывод показывает снимк текущих запущенных процессов на системе. Каждая строка представляет собой процесс следующими столбцами:
USER: Utilisateur du processus.PID: Identifiant du processus.%CPU: Utilisation du processeur du processus.%MEM: Используемая память процесса.VSZ: Размер виртуальной памяти процесса.RSS: Размер Residentset, то есть несвободной физической памяти, используемой задачей.TTY: Контролируемый терминал процесса.?означает отсутствие контролируемого терминала.Ss: Лидер сессии. Это процесс, который начал сессию, и является лидером группы процессов и может управлять сигналами терминала. ПервоеSуказывает на состояние сна, а второеs— на то, что это лидер сессии.START: Время或 дата запуска процесса.TIME: Суммарное процессорное время.
<команда>: Команда, которая запустила процесс.
Фоновые и фронтовые процессы
В этом разделе вы leaned, как контролировать задачи, запуская их в фоновом режиме или в фронтовом режиме.
Задача – это процесс, который был запущен оболочкой. когда вы выполняете команду в терминале, она считается задачей. Задача может работать в фоновом или фронтовом режиме.
- Для демонстрации управления, сначала создадим 3 процесса, а затем запустим их в фоновом режиме. затем вы будете перечислять процессы и переключать их между фронтовым и фоновым режимом. вы увидите, как вы можете заставить их спать или выполнить их полностью.
Создание Трех Процессов
Откройте терминал и запустите три длинных срока работы процесса. используйте комманду <код>sleep, которая запускает процесс в течение указанного количества секунд.
sleep 300 &
sleep 400 &
sleep 500 &
# run sleep command for 300, 400, and 500 seconds
- Символ <код>& в конце каждой команды перемещает процесс в фоновый режим.
Показать Фоновые Задачи
jobs
Используйте команду <код>jobs, чтобы показать список фоновых задач.
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
- Выходной результат должен выглядеть примерно так:
Перевести Фоновую Задачу в Фронтовый Режим
fg %1
Чтобы перевести фоновую задачу в фронтовый режим, используйте команду <код>fg затем номер задачи. например, чтобы перевести первую задачу (<код>sleep 300) в фронтовый режим:
- Это переведет задачу <код>1 в фронтовый режим.
Перевести Фронтовую Задачу в Фоновый Режим
Во время работы задачи в переднем плане вы можете приостановить ее и переместить обратно в фоновое выполнение, нажав Ctrl+Z для приостановки задачи.
zaira@zaira:~$ fg %1
sleep 300
^Z
[1]+ Stopped sleep 300
zaira@zaira:~$ jobs
Приостановленная задача будет выглядеть следующим образом:
[1]+ Stopped sleep 300
[2] Running sleep 400 &
[3]- Running sleep 500 &
# приостановленная задача
Теперь используйте команду bg, чтобы возобновить задачу с ID 1 в фоновом режиме.
# Нажмите Ctrl+Z, чтобы приостановить задачу в переднем плане
bg %1
- # Затем возобновите ее в фоновом режиме
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
Снова отобразите задачи
- В этой упражнении вы:
- Запустили три фоновых процесса с помощью команд sleep.
- Использовали jobs для отображения списка фоновых задач.
- Передвинули задачу в передний план с помощью
fg %номер_задачи. - Приостановили задачу с помощью
Ctrl+Zи переместили ее обратно в фоновый режим с помощьюbg %номер_задачи.
Снова использовали jobs для проверки статуса фоновых задач.
Теперь вы знаете, как управлять задачами.
Убийство процессов
Можно завершить не отвечающий или нежелательный процесс использованием команды kill. Команда kill посылает сигнал процессу с указанным PID (ID процесса), прося его завершиться.
У команды kill доступны множество опций.
kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24)
...terminated
# Действия, доступные с помощью команды kill
- Вот несколько примеров использования команды
killв Linux: - Эта команда отправляет по умолчанию сигнал
SIGTERMпроцессу с PID 1234, прося его завершиться. - Эта команда отправляет по умолчанию сигнал
SIGTERMвсем процессам с указанным именем. - Этот запуск отправляет сигнал
SIGKILLпроцессу с PID 1234, принудительно завершая его. - Этот запуск отправляет сигнал
SIGSTOPпроцессу с PID 1234, останавливая его.
Этот запуск отправляет по умолчанию сигнал SIGTERM всем процессам, принадлежащим указанному пользователю.
В этих примерах показано различные способы использования команды kill для управления процессами в Linux-системе.
Далее приводится информация о параметрах и сигналах команды kill в табличной форме: Эта таблица резюмирует наиболее часто используемые параметры команды kill и сигналы в Linux для управления процессами. |
Команда / Параметр | Сигнал |
| Описание | kill |
SIGTERM |
| Запрос о завершении процесса гладко (сигнал по умолчанию). | kill -9 |
SIGKILL |
| Принудительное завершение процесса немедленно без очистки. | kill -SIGKILL |
SIGKILL |
| Принудительное завершение процесса немедленно без очистки. | kill -15 |
SIGTERM |
Explicitly sends the SIGTERM signal to request graceful termination. |
kill -SIGTERM |
SIGTERM |
Explicitly sends the SIGTERM signal to request graceful termination. |
kill -1 |
SIGHUP |
| Обычно означает “отключение”; может использоваться для перезагрузки конфигурационных файлов. | kill -SIGHUP |
SIGHUP |
| Традиционно означает “повесить”; может использоваться для перезагрузки конфигурационных файлов. | kill -2 |
SIGINT |
Запрашивает завершение процесса (точно также, как нажатие Ctrl+C в терминале). |
kill -SIGINT |
SIGINT |
Запрашивает завершение процесса (точно также, как нажатие Ctrl+C в терминале). |
kill -3 |
SIGQUIT |
| Приводит к завершению процесса и создает дамп ядра для отладки. | kill -SIGQUIT |
SIGQUIT |
| Приводит к завершению процесса и создает дамп ядра для отладки. | kill -19 |
SIGSTOP |
| Приостанавливает процесс. | kill -SIGSTOP |
SIGSTOP |
| Приостанавливает процесс. | kill -18 |
SIGCONT |
| Продолжает замороженный процесс. | kill -SIGCONT |
SIGCONT |
| Продолжает замороженный процесс. | killall |
Варьируется |
| Отправляет сигнал всем процессам с данным именем. | killall -9 |
SIGKILL |
| Убивает все процессы с указанным именем. | pkill <шаблон> |
Варьируется |
| Отправляет сигнал процессам на основе совпадения шаблона. | pkill -9 <шаблон> |
SIGKILL |
| Принудительно убивает все процессы, соответствующие шаблону. | xkill |
SIGKILL |
Графическая утилита, которая позволяет убить процесс, кликнув на соответствующее окно.
8.5. Стандартные потоки ввода и вывода в Linux
- Чтение ввода и запись вывода является необходимой частью понимания командной строки и сценариев оболочки. В Linux каждый процесс имеет три стандартных потока:
- Дескриптор файла для
stdinсоставляет0. - Стандартный вывод (
stdout): Это умолянный поток вывода, где процесс записывает свой вывод. По умолчанию стандартным выводом является терминал. Вывод также может быть перенаправлен в файл или другую программу. deskriptor файла дляstdoutэто1.
Стандартный ошибка (stderr): Это умолянный поток ошибок, где процесс записывает свои сообщения об ошибках. По умолчанию стандартным ошибками является терминал, позволяя видеть сообщения об ошибках, даже если stdout перенаправлен. deskriptor файла для stderr это 2.
Перенаправление и потоки
Перенаправление: Вы можете перенаправлять потоки ошибок и вывода в файлы или другие команды. Например:
ls > output.txt
# Перенаправление stdout в файл
ls non_existent_directory 2> error.txt
# Перенаправление stderr в файл
ls non_existent_directory > all_output.txt 2>&1
# Перенаправление и stdout и stderr в файл
- В последней команде,
ls non_existent_directory: выводит содержимое каталога с именем non_existent_directory. Т.к. этот каталог не существует, команда `ls` Generates an error message.> all_output.txt: оператор `>` перенаправляет стандартный вывод (`stdout`) команды `ls` в файл `all_output.txt`. Если файл не существует, он будет создан. Если он существует, его содержимое будет перезаписано.
2>&1:: Здесь цифра `2` представляет собой дескриптор файла для стандартной ошибки (`stderr`). Символ `&` представляет собой дескриптор стандартного вывода (`stdout`). Символ `&` используется для обозначения, что `1` – это не имя файла, а дескриптор файла.
Таким образом, 2>&1 означает “перенаправление stderr (2) на то место, где сейчас направлен stdout (1),” которым в данном случае является файл all_output.txt. Таким образом, вывод (если было какое-либо) и сообщение ошибки от ls будут записаны в all_output.txt.
Пути:
ls | grep image
Вы можете использовать трубки (|) для передачи вывода одного команды в качестве входа для другой:
image-10.png
image-11.png
image-12.png
image-13.png
... Output truncated ...
# Вывод
8.6 Автоматизация в Linux – Автоматизировать задачи с помощью заданий cron
Cron – мощное утилита для планирования задач, доступная в Unix-подобных операционных системах.Configuring cron, you can set up automated jobs to run on a daily, weekly, monthly, or other specific time basis. The automation capabilities provided by cron play a crucial role in Linux system administration.
Демон crond (вид программы, которая запускается в фоновом режиме) обеспечивает функциональность cron. Cron reads the crontab (cron tables) for running predefined scripts.
Используя специфическую синтаксис, вы можете настроить задание cron, чтобы автоматически запускать сценарии или другие команды.
Что такое cron jobs в Linux?
Любая задача, запланированная через crons, называется cron job.
Теперь посмотрим, как работают cron jobs.
Как контролировать доступ к crons
Чтобы использовать cron jobs, администратор должен разрешить добавление cron jobs для пользователей в файле /etc/cron.allow.
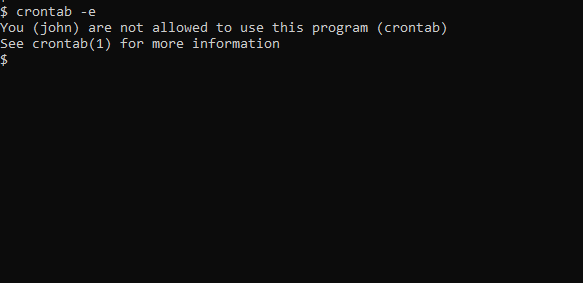
Если вы видите такую предупреждение, это значит, что у вас нет разрешения использовать cron.
![]()
Чтобы позволить Джону использовать cron, добавьте его имя в файл /etc/cron.allow. Если этот файл не существует, создайте его. Это позволит Джону создавать и редактировать задачи cron.
Кроме того, пользователи могут быть отказаны в доступе к cron-задачам, добавив их имя в файл /etc/cron.d/cron.deny.
Как добавить задачи cron в Linux
Первоначально, для использования задач cron, вам нужно проверить статус сервиса cron. Если cron не установлен, вы можете легко скачать его через менеджер пакетов. Используйте следующий запрос для проверки:
sudo systemctl status cron.service
# проверка сервиса cron на Linux-системе
Синтаксис задач cron
- Crontabs используют следующие флаги для добавления и просмотра задач cron:
crontab -e: редактирует записи crontab для добавления, удаления или редактирования задач cron.crontab -l: отображает все задачи cron для текущего пользователя.crontab -u username -l: отображает cron другого пользователя.
crontab -u username -e: редактирует cron другого пользователя.
Когда вы отображаете cron, если они существуют, вы увидите что-то вроде следующего:
* * * * * sh /path/to/script.sh
Пример cron-задания
- В указанном выше примере,
* представляет минуты, часы, дни, месяцы и дни недели соответственно. Подробности этих значений приведены ниже: |
ЗНАЧЕНИЕ | |
| ОПИСАНИЕ | Минуты | 0-59 |
| Команда будет выполнена в указанную минуту. | Часы | 0-23 |
| Команда будет выполнена в указанный час. | Дни | 1-31 |
| Команды будут выполнены в эти дни месяца. | Месяцы | 1-12 |
| Месяц, в который нужно выполнить задачи. | Дни недели | 0-6 |
- Дни недели, когда будут выполняться команды. Здесь 0 – воскресенье.
shозначает, что скрипт является bash-скриптом и должен быть запущен из/bin/bash.
/path/to/script.sh указывает путь к скрипту.
* * * * * sh /path/to/script/script.sh
| | | | | |
| | | | | Command or Script to Execute
| | | | |
| | | | |
| | | | |
| | | | Day of the Week(0-6)
| | | |
| | | Month of the Year(1-12)
| | |
| | Day of the Month(1-31)
| |
| Hour(0-23)
|
Min(0-59)
Ниже приведено общее описание синтаксиса cron-задания:
Примеры cron-заданий
| Ниже представлены несколько примеров планирования cron-заданий. | РАСПИСАНИЕ |
| ЗАПЛАНИРОВАННОЕ ЗНАЧЕНИЕ | 5 0 * 8 * |
| В 00:05 августа. | 5 4 * * 6 |
| В 04:05 на среду. | 0 22 * * 1-5 |
В 22:00 каждый день недели от понедельника до пятницы.
Если вы не можете понять это сразу, это вполне нормально. Вы можете заниматься и создавать графики cron с помощью веб-сайта crontab guru.
Как настроить cron-задание
- В этом разделе мы посмотрим пример настройки простого скрипта с cron-заданием.
#!/bin/bash
echo `date` >> date-out.txt
Создайте скрипт под названием date-script.sh, который выводит системную дату и время и добавляет ее в файл. Скрипт следующий:
chmod 775 date-script.sh
2. Добавьте права на выполнение скрипта.
3. Добавьте скрипт в crontab с помощью crontab -e.
*/1 * * * * /bin/sh /root/date-script.sh
Здесь мы запланировали его выполнение каждую минуту.
cat date-out.txt
4. Проверьте выходной файл date-out.txt. Согласно скрипту, система должна печатать дату и время в этот файл каждую минуту.
Wed 26 Jun 16:59:33 PKT 2024
Wed 26 Jun 17:00:01 PKT 2024
Wed 26 Jun 17:01:01 PKT 2024
Wed 26 Jun 17:02:01 PKT 2024
Wed 26 Jun 17:03:01 PKT 2024
Wed 26 Jun 17:04:01 PKT 2024
Wed 26 Jun 17:05:01 PKT 2024
Wed 26 Jun 17:06:01 PKT 2024
Wed 26 Jun 17:07:01 PKT 2024
# вывод
Как исправлять cron-задания
Cron очень полезен, но он может не работать так, как хотелось бы. К счастью, есть несколько эффективных способов, которые вы можете использовать для исправления cron-заданий.
1. Проверьте расписание.
Первое, что вы можете попробовать, это проверить расписание, установленное для cron. Вы можете это сделать с помощью синтаксиса, который вы видели в вышеуказанных разделах.
2. Проверка cron-логических журналов.
Сначала вам нужно убедиться, запущен ли cron в запланированное время. В Ubuntu вы можете проверить это, выполнив проверку cron-логических журналов, расположенных в каталоге /var/log/syslog.
Если в этих журналах есть запись в правильное время, это означает, что cron был запущен согласно расписанию, которое вы установили.
1 Jun 26 17:02:01 zaira-ThinkPad CRON[27834]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
2 Jun 26 17:02:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
3 Jun 26 17:03:01 zaira-ThinkPad CRON[28255]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
4 Jun 26 17:03:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
5 Jun 26 17:04:01 zaira-ThinkPad CRON[28538]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
ниже представлены журналы нашего примера cron-задания. Обратите внимание на первую колонку, содержащую метку времени. URL скрипта также указан в конце строки. Линии №1, 3 и 5 показывают, что скрипт был запущен как надо.
3. Смещение вывода cron в файл.
Вы можете сместить вывод cron в файл и проверить его на наличие любых ошибок.
* * * * * sh /path/to/script.sh &> log_file.log
# Смещение вывода cron в файл
8.7. Основы Linux-сетевой навигации
Linux предлагает ряд команд для просмотра информации, связанной с сетью. В этом разделе мы быстро рассмотрим несколько из них.
Просмотр сетевых интерфейсов с помощью ifconfig
ifconfig
Команда ifconfig показывает информацию о сетевых интерфейсах. Вот пример вывода:
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::a00:27ff:fe4e:66a1 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:4e:66:a1 txqueuelen 1000 (Ethernet)
RX packets 1024 bytes 654321 (654.3 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 512 bytes 123456 (123.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 256 bytes 20480 (20.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 256 bytes 20480 (20.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# Вывод
Вывод команды ifconfig показывает сетевые интерфейсы, настроенные в системе, а также детали, такие как IP-адреса, MAC-адреса, статистика пакетов и другие сведения.
Эти интерфейсы могут быть физическими или виртуальными устройствами.
Для выделения IPv4 и IPv6 адресов вы можете использовать ip -4 addr и ip -6 addr, соответственно.
Просмотр активности сети с помощьюnetstat
Команда netstat показывает активность сети и статистику, предоставляя следующую информацию:
- Вот несколько примеров использования команды
netstatв командной строке: - Отобразить все прослушивающие и непрослушивающие сокеты:
- Показать только прослушивающие порты:
- Отобразить статистику сети:
- Отобразить таблицу маршрутизации:
- Показать соединения TCP:
- Показать соединения UDP:
- Показать сетевые интерфейсы:
- Показать PID и имена программ для соединений:
- Показать статистику для определенного протокола (например, TCP):
Отображать расширенную информацию:
Проверка соединения между двумя устройствами с помощью ping
ping google.com
ping используется для проверки соединения между двумя устройствами. Он отправляет ICMP-пакеты на целевое устройство и ждет ответ.
ping google.com
PING google.com (142.250.181.46) 56(84) bytes of data.
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=1 ttl=60 time=78.3 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=2 ttl=60 time=141 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=3 ttl=60 time=205 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=4 ttl=60 time=100 ms
^C
--- google.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3001ms
rtt min/avg/max/mdev = 78.308/131.053/204.783/48.152 ms
ping проверяет, получает ли вам ответ без установки таймаута.
— google.com ping статистика —
Вы можете остановить ответ с помощью Ctrl + C.
Тестирование конечных точек с помощью команды curl
- Команда
curlозначает “клиент URL”. Она используется для передачи данных на сервер или с сервера. Она также может использоваться для тестирования API-конечных точек, которые помогают в устранении ошибок систем и приложений.
curl http://www.official-joke-api.appspot.com/random_joke
{"type":"general",
"setup":"What did the fish say when it hit the wall?","punchline":"Dam.","id":1}
- К примеру, вы можете использовать
http://www.official-joke-api.appspot.com/, чтобы экспериimentровать с командойcurl.
curl -o random_joke.json http://www.official-joke-api.appspot.com/random_joke
Команда curl без каких-либо опций по умолчанию использует метод GET.
curl -oсохраняет выход в указанный файл.
curl -I http://www.official-joke-api.appspot.com/random_joke
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Vary: Accept-Encoding
X-Powered-By: Express
Access-Control-Allow-Origin: *
ETag: W/"71-NaOSpKuq8ChoxdHD24M0lrA+JXA"
X-Cloud-Trace-Context: 2653a86b36b8b131df37716f8b2dd44f
Content-Length: 113
Date: Thu, 06 Jun 2024 10:11:50 GMT
Server: Google Frontend
# сохраняет выход в random_joke.json
curl -I получает только заголовки.
8.8. раз解决问题 в Linux: инструменты и техники
Отчет о системной активности с помощью sar
Команда sar в Linux является мощным инструментом для сбора, отчета и сохранения информации о системной активности. Это часть пакета sysstat, широко используемого для мониторинга производительности системы с течением времени.
Для использования sar вам сначала нужно установить sysstat с помощью sudo apt install sysstat.
После установки, запустите службу с помощью sudo systemctl start sysstat.
Проверьте статус с помощью sudo systemctl status sysstat.
sar [options] [interval] [count]
Когда статус станет активным, система будет начинать собирать различные статистики, которые вы можете использовать для доступа и анализа исторических данных. Detail about this will be discussed soon.
sar -u 1 3
Syntax of the sar command is as follows:
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:09:26 CPU %user %nice %system %iowait %steal %idle
19:09:27 all 3.78 0.00 2.18 0.08 0.00 93.96
19:09:28 all 4.02 0.00 2.01 0.08 0.00 93.89
19:09:29 all 6.89 0.00 2.10 0.00 0.00 91.01
Average: all 4.89 0.00 2.10 0.06 0.00 92.95
Например, sar -u 1 3 будет отображать статистику использования CPU каждый секунду трижды.
# Output
Here are some common use cases and examples of how to use the sar command.
sar can be used for a variety of purposes:
sar -r 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:10:46 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
19:10:47 4600104 8934352 5502124 36.32 375844 4158352 15532012 65.99 6830564 2481260 264
19:10:48 4644668 8978940 5450252 35.98 375852 4165648 15549184 66.06 6776388 2481284 36
19:10:49 4646548 8980860 5448328 35.97 375860 4165648 15549224 66.06 6774368 2481292 116
Average: 4630440 8964717 5466901 36.09 375852 4163216 15543473 66.04 6793773 2481279 139
1. Использование памяти
Чтобы проверить использование памяти (свободной и используемой), используйте:
This command displays memory statistics every second three times.
sar -S 1 3
sar -S 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:11:20 kbswpfree kbswpused %swpused kbswpcad %swpcad
19:11:21 8388604 0 0.00 0 0.00
19:11:22 8388604 0 0.00 0 0.00
19:11:23 8388604 0 0.00 0 0.00
Average: 8388604 0 0.00 0 0.00
2. Использование swap-зоны
Для просмотра статистики использования swap-зоны используйте:
Эта команда помогает контролировать использование обмена, что является критическим для систем, работающих без физической памяти.
sar -d 1 3
3. Загрузка I/O устройств
Чтобы отследить активность для блочных устройств и разделов блочных устройств:
Эта команда предоставляет детальные статистические данные о передаче данных между блочными устройствами и является полезной для диагностики I/O блокировок.
sar -n DEV 1 3
5. Статистика сети
sar -n DEV 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:12:47 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
19:12:48 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 wlp3s0 10.00 3.00 1.83 0.37 0.00 0.00 0.00 0.00
19:12:48 br-5129d04f972f 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
.
.
.
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
...output truncated...
Чтобы посмотреть статистику сети, такую как количество полученных (отправленных) пакетов сетевым интерфейсом:
# -n DEV указывает sar, чтобы он отправлял отчеты по сетевым интерфейсам устройств
Это отображает сетевую статистику каждый секунду в течение трех секунд, что помогает контролировать сетевой трафик.
- 6. Исторические данные
- # Valid values are “true” and “false”. Please do not put other values, they
- Настроить интервал сбора данных:编辑 cron job 配置以设置数据收集间隔。
sar -u -f /var/log/sysstat/sa04
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
15:20:49 LINUX RESTART (12 CPU)
16:13:30 LINUX RESTART (12 CPU)
18:16:00 CPU %user %nice %system %iowait %steal %idle
18:16:01 all 0.25 0.00 0.67 0.08 0.00 99.00
Average: all 0.25 0.00 0.67 0.08 0.00 99.00
Замените <DD> числом дня месяца, для которого вы хотите просмотреть данные.
В следующей команде /var/log/sysstat/sa04 предоставляет статистику за четвертый день текущего месяца.
sar -I SUM 1 3
7. Реальное время прерываний CPU
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:14:22 INTR intr/s
19:14:23 sum 5784.00
19:14:24 sum 5694.00
19:14:25 sum 5795.00
Average: sum 5757.67
Для наблюдения за реальным временем прерываний в секунду, обслуживаемых CPU, используйте эту команду:
# Вывод
Эта команда помогает мониторить, как часто CPU обрабатывает прерывания, что может быть важно для настройки производительности в реальном времени.
Эти примеры показывают, как вы можете использовать sar для мониторинга различных аспектов производительности системы. Регулярное использование sar может помочь в определении системных узких мест и обеспечении эффективности работы приложений.
8.9. Общая стратегия устранения неполадок на серверах
Почему нам нужно понимать мониторинг?
Мониторинг системы является важным аспектом администрирования системы. Критические приложения требуют высокого уровня проактивности для предотвращения сбоев и уменьшения влияния отключений.
Linux предлагает очень мощные инструменты для оценки состояния системы. В этом разделе вы узнаете о различных методах, доступных для проверки состояния вашей системы и идентификации узких мест.
[user@host ~]$ uptime 19:15:00 up 1:04, 0 users, load average: 2.92, 4.48, 5.20
Найти среднюю нагрузку и время работы системы
Система может перезагружаться, что иногда может испортить некоторые настройки. Чтобы проверить, как долго работает машина, используйте команду: uptime. Кроме времени работы, команда также отображает среднюю нагрузку.
Средняя нагрузка — это нагрузка на систему за последние 1, 5 и 15 минут. Быстрый осмотр может показать, увеличивается ли системная нагрузка со временем или уменьшается.
Примечание: Идеальная очередь CPU — 0. Это возможно только тогда, когда нет очередей ожидания для CPU.
lscpu
Нагрузку на каждый CPU можно рассчитать, разделив среднюю нагрузку на общее количество доступных CPU.
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
.
.
.
output omitted
Чтобы найти количество CPU, используйте команду lscpu.
# вывод
Если средняя нагрузка повышается и не снижается, CPU перегружены. Есть какой-то процесс, который завис или произошел memory leak.
free -mh
Расчет свободной памяти
total used free shared buff/cache available
Mem: 14Gi 3.5Gi 7.7Gi 109Mi 3.2Gi 10Gi
Swap: 8.0Gi 0B 8.0Gi
Иногда, высокая заutilization памяти может вызывать проблемы. Чтобы проверить доступную память и память в использовании, используйте комманду free.
# вывод
Расчет дискового пространства
df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 1.5G 2.4M 1.5G 1% /run
/dev/nvme0n1p2 103G 34G 65G 35% /
tmpfs 7.3G 42M 7.2G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
efivarfs 246K 93K 149K 39% /sys/firmware/efi/efivars
/dev/nvme0n1p3 130G 47G 77G 39% /home
/dev/nvme0n1p1 511M 6.1M 505M 2% /boot/efi
tmpfs 1.5G 140K 1.5G 1% /run/user/1000
Чтобы убедиться, что система здорова, не забывайте о дисковом пространстве. Чтобы вывести все доступные mount points и их соответствующий использованный процент, используйте ниже указанную команду.理想но, использованное дисковое пространство не должно превышать 80%.
Команда df предоставляет подробные данные о дисковом пространстве.
Определение состояний процессов
[user@host ~]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
runner 1 0.1 0.0 1535464 15576 ? S 19:18 0:00 /inject/init
runner 14 0.0 0.0 21484 3836 pts/0 S 19:21 0:00 bash --norc
runner 22 0.0 0.0 37380 3176 pts/0 R+ 19:23 0:00 ps aux
Состояния процессов могут быть мониторить, чтобы проверить какой-либо зависший процесс с высокой памятью или CPU использованием.
我们之前看到, что команда ps предоставляет полезную информацию о процессе. посмотрите на CPU и MEM колонки.
Применение системного мониторинга в реальном времени
Реальное время мониторинга дает окно в реальное состояние системы.
Одним из инструментов, который вы можете использовать для этого, является команда top.
Команда top отображает динамический обзор процессов системы, отображая подзаголовки сводки следуем за process или thread списком. Unlike ее статического варианта ps, top постоянно обновляет статистику системы.
С помощью top, вы можете увидеть хорошо организованные детали в компактном окне. У top есть ряд флагов,快捷方式 и способов выделения, которые вызываются вместе с ним.
Также вы можете убивать процессы с помощью top. Для этого нажмите k и затем введите идентификатор процесса.
Разбор логов
Системные и приложение логи содержат множество информации о том, что происходит с системой. В них содержатся полезные сведения и ошибки, которые указывают на ошибки. Если вы ищете ошибки в логах, то идентификация ошибок и время исправления могут быть значительно уменьшены.
Анализ сетевых портов
Не следует игнорировать сетевую сторону, так как сетевые проблемы являются обыденным явлением и могут повлиять на систему и поток трафика. Общие сетевые проблемы включают исчерпание портов, захват портов, неразрешенные ресурсы и т. д.
| Для идентификации таких проблем нам нужно понимать состояние портов. | Ниже перечислены некоторые состояния портов: |
| Состояние | Описание |
| LISTEN | представляет порты, ожидающие запроса подключения от любого удаленного TCP-порта. |
| ESTABLISHED | представляет соединения, которые открыты и данные, полученные сразу могут быть доставлены в цель. |
| TIME WAIT | представляет время ожидания для уверенности в подтверждении запроса закрытия соединения. |
FIN WAIT2
представляет ожидание запроса закрытия соединения от удаленного TCP.
[user@host ~]$ /sbin/sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 15000 65000
Давайте исследуем, как мы можем анализировать информацию, связанную с портами в Linux.
Портовые диапазоны: Порты в системе определены и диапазон может быть изменен соответственно. В следующем фрагменте диапазон extends от 15000 до 65000, который составляет 50000 (65000 – 15000) доступных портов. Если используемые порты достигают или превышают это ограничение, то это может быть проблема.
Ошибка, сообщенная в логах в таких случаях, может быть Failed to bind to port или Too many connections.
Определение потертости пакетов
В мониторинге системы нам нужно убедиться, что исходящая и входящая связь являются целыми.
[user@host ~]$ ping 10.13.6.113
PING 10.13.6.141 (10.13.6.141) 56(84) bytes of data.
64 bytes from 10.13.6.113: icmp_seq=1 ttl=128 time=0.652 ms
64 bytes from 10.13.6.113: icmp_seq=2 ttl=128 time=0.593 ms
64 bytes from 10.13.6.113: icmp_seq=3 ttl=128 time=0.478 ms
64 bytes from 10.13.6.113: icmp_seq=4 ttl=128 time=0.384 ms
64 bytes from 10.13.6.113: icmp_seq=5 ttl=128 time=0.432 ms
64 bytes from 10.13.6.113: icmp_seq=6 ttl=128 time=0.747 ms
64 bytes from 10.13.6.113: icmp_seq=7 ttl=128 time=0.379 ms
^C
--- 10.13.6.113 ping statistics ---
7 packets transmitted, 7 received,0% packet loss, time 6001ms
rtt min/avg/max/mdev = 0.379/0.523/0.747/0.134 ms
Useful команда является ping. ping посылает запрос на удаленную систему и приводит ответ назад. Обратите внимание на последние несколько строк статистики, которые показывают процент потертости пакетов и время.
# ping целевая IP-адрес
Пакеты также могут быть捕获ны в реальном времени с помощью tcpdump. Мы посмотрим на это позже.
COLLECTING STATS для POST MORTEM issure
- It’s always a good practice to gather certain stats that would be useful for identifying the root cause later. Usually, after system reboot or services restart, we loose the earlier system snapshot and logs.
Below are some of the methods to capture system snapshot.
- Backup of Logs
Перед внесением любых изменений, скопируйте файлы логов в другое место. Это важно для понимания того состояния системы было во время возникновения проблемы. Иногда лог-файлы являются единственным взглядом на прошлое состояние системы, так как другие runtime статистики теряются.
sudo tcpdump -i any -w
TCP Dump
Tcpdump — это утилита отладки, выполняемая в командной строке, позволяющая захватывать и анализировать входящий и исходящий сетевой трафик. Он используется главным образом для устранения проблем с сетевыми соединениями. Если вы считаете, что трафик системы пострадал, выполните tcpdump следующим образом:
# где,
# -i any захватывает трафик с всех интерфейсов
# -w указает имя файла вывода
# Заканчивайте команду через несколько минут, так как размер файла может увеличиться
# используйте расширение имя файла .pcap
После захвата tcpdump, вы можете использовать инструменты, такие как Wireshark, для визуального анализа трафика.
Заключение
Спасибо за то, что вы прочитали книгу до конца. Если она вам помогла, рассмотрите вариант поделиться ею с другими.
Книга не заканчивается здесь, хотя. Я продолжу совершенствовать ее и добавлять новый материал в будущем. Если вы нашли какие-либо ошибки или если вы хотели бы предложить какие-либо улучшения, не стесняйтесь открывать PR/issue.
- Оставайтесь в связи и продолжайте свое образовательное путешествие!
-
LinkedIn: Я там делюсь статьями и постами о технологиях. Оставляйте рекомендацию на LinkedIn и поддержите меня, отметив соответствующие навыки.
Получите доступ к эксклюзивному содержанию: Для помощи и доступа к эксклюзивному содержимому перейдите здесь.
Получите доступ к эксклюзивному содержанию: Для помощи и доступа к эксклюзивному содержимому перейдите здесь.
Source:
https://www.freecodecamp.org/news/learn-linux-for-beginners-book-basic-to-advanced/