













Большие данные значительно эволюционировали с момента их появления в конце 2000-х годов. Многие организации быстро адаптировались к тенденции и построили свои платформы больших данных, используя инструменты с открытым исходным кодом, такие как Apache Hadoop. Позже эти компании столкнулись с проблемами управления быстро развивающимися потребностями в обработке данных. Они столкнулись с трудностями при обработке изменений на уровне схем, эволюции схем разбиения и возможностью возврата в прошлое для анализа данных.
Я сталкивался с аналогичными проблемами, проектируя крупномасштабные распределенные системы в 2010-х годах для крупной технологической компании и клиента в области здравоохранения. Некоторые отрасли нуждаются в этих возможностях, чтобы соблюдать нормативные требования в области банковского дела, финансов и здравоохранения. Компании, основанные на данных, такие как Netflix, также столкнулись с аналогичными проблемами. Они придумали формат таблиц под названием “Iceberg”, который располагается поверх существующих файлов данных и предлагает ключевые функции, используя свою архитектуру. Это быстро стало ведущим проектом ASF, так как вызвало стремительный интерес в сообществе данных. В этой статье я рассмотрю 5 ключевых функций Apache Iceberg с примерами и диаграммами.
1. Путешествие во времени

Рисунок 1: Путешествие во времени в формате таблицы Apache Iceberg (изображение создано автором)
Эта функция позволяет вам запрашивать ваши данные так, как они существуют в любой момент времени. Это откроет новые возможности для аналитиков данных и бизнеса, чтобы понять тенденции и то, как данные эволюционировали со временем. Вы можете без усилий вернуться к предыдущему состоянию в случае ошибок. Эта функция также упрощает проверки аудита, позволяя вам анализировать данные в конкретный момент времени.
-- time travel to October 5th, 1978 at 07:00:00
SELECT * FROM prod.retail.cusotmers TIMESTAMP AS OF '1978-10-05 07:00:00';
-- time travel using a specific snapshot ID:
SELECT * FROM prod.retail.customers VERSON AS OF 949530903748831869;
2. Эволюция схемы
Эволюция схемы Apache Iceberg позволяет вносить изменения в вашу схему без значительных усилий или дорогостоящих миграций. По мере изменения потребностей вашего бизнеса вы можете:
- Добавлять и удалять столбцы без какого-либо времени простоя или переписывания таблиц.
- Обновлять столбец (расширение).
- Изменять порядок столбцов.
- Переименовывать существующий столбец.
Эти изменения обрабатываются на уровне метаданных без необходимости переписывать базовые данные.
-- add a new column to the table
ALTER TABLE prod.retail.customers ADD COLUMNS (email_address STRING);
-- remove an existing column from the table
ALTER TABLE prod.retail.customers DROP COLUMN num_of_years;
-- rename an existing column
ALTER TABLE prod.retail.customers RENAME COLUMN email_address TO email;
-- iceberg allows updating column types from int to bigint, float to double
ALTER TABLE prod.retail.customers ALTER COLUMN customer_id TYPE bigint;
3. Эволюция партиций
Используя формат таблицы Apache Iceberg, вы можете изменить стратегию партиционирования таблицы, не переписывая базовую таблицу или мигрируя данные в новую таблицу. Это стало возможным, поскольку запросы не ссылаются на значения партиций напрямую, как в Apache Hadoop. Iceberg хранит метаданные для каждой версии партиции отдельно. Это упрощает получение разбиений при запросе данных. Например, запрос таблицы на основе диапазона дат, когда таблица использовала месяц в качестве столбца партиции (до) в качестве одного разбиения и день в качестве нового столбца партиции (после) в качестве другого разбиения. Это называется планированием разбиений. См. пример ниже.
-- create customers table partitioned by month of the create_date initially
CREATE TABLE local.retail.customer (
id BIGINT,
name STRING,
street STRING,
city STRING,
state STRING,
create_date DATE
USING iceberg
PARTITIONED BY (month(create_date));
-- insert some data into the table
INSERT INTO local.retail.customer VALUES
(1, 'Alice', '123 Maple St', 'Springfield', 'IL', DATE('2024-01-10')),
(2, 'Bob', '456 Oak St', 'Salem', 'OR', DATE('2024-02-15')),
(3, 'Charlie', '789 Pine St', 'Austin', 'TX', DATE('2024-02-20'));
-- change the partition scheme from month to date
ALTER TABLE local.retail.customer
REPLACE PARTITION FIELD month(create_date) WITH days(create_date);
-- insert couple more records
INSERT INTO local.retail.customer VALUES
(4, 'David', '987 Elm St', 'Portland', 'ME', DATE('2024-03-01')),
(5, 'Eve', '654 Birch St', 'Miami', 'FL', DATE('2024-03-02'));
-- select all columns from the table
SELECT * FROM local.retail.customer
WHERE create_date BETWEEN DATE('2024-01-01') AND DATE('2024-03-31');
-- output
1 Alice 123 Maple St Springfield IL 2024-01-10
5 Eve 654 Birch St Miami FL 2024-03-02
4 David 987 Elm St Portland ME 2024-03-01
2 Bob 456 Oak St Salem OR 2024-02-15
3 Charlie 789 Pine St Austin TX 2024-02-20
-- View parition details
SELECT partition, file_path, record_count
FROM local.retail.customer.files;
-- output
{"create_date_month":null,"create_date_day":2024-03-02} /Users/rellaturi/warehouse/retail/customer/data/create_date_day=2024-03-02/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00002.parquet 1
{"create_date_month":null,"create_date_day":2024-03-01} /Users/rvellaturi/warehouse/retail/customer/data/create_date_day=2024-03-01/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00001.parquet 1
{"create_date_month":648,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-01/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00001.parquet 1
{"create_date_month":649,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-02/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00002.parquet 2
4. Транзакции ACID
Iceberg предоставляет надежную поддержку транзакций в терминах Атомарности, Согласованности, Изоляции и Долговечности (ACID). Он позволяет выполнять несколько параллельных операций записи, что обеспечивает высокую пропускную способность в тяжелых задачах с интенсивным использованием данных без ущерба для согласованности данных.
-- Start a transaction
START TRANSACTION;
-- Insert new records
INSERT INTO customers VALUES (1, 'John'), (2, 'Mike');
-- Update existing records
UPDATE customers SET column1 = 'Josh' WHERE id = 1;
-- Delete records
DELETE FROM customers WHERE id = 2;
-- Commit the transaction
COMMIT;
Все операции в Iceberg являются транзакционными, что означает, что данные остаются согласованными, несмотря на сбои или изменения в данных, происходящие одновременно.
-- Atomic update across multiple tables
START TRANSACTION;
UPDATE orders SET status = 'processed' WHERE order_id = 100;
INSERT INTO orders_processed SELECT * FROM orders WHERE order_id = 100;
COMMIT;
Он также поддерживает различные уровни изоляции, что позволяет балансировать производительность и согласованность в зависимости от требований.
-- Set isolation level (syntax may vary depending on the query engine)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Perform operations
SELECT * FROM customers WHERE id = 1;
UPDATE customers SET rec_status= 'updated' WHERE id = 1;
COMMIT;
Вот краткое резюме, показывающее, как Iceberg обрабатывает обновления и удаления на уровне строк.
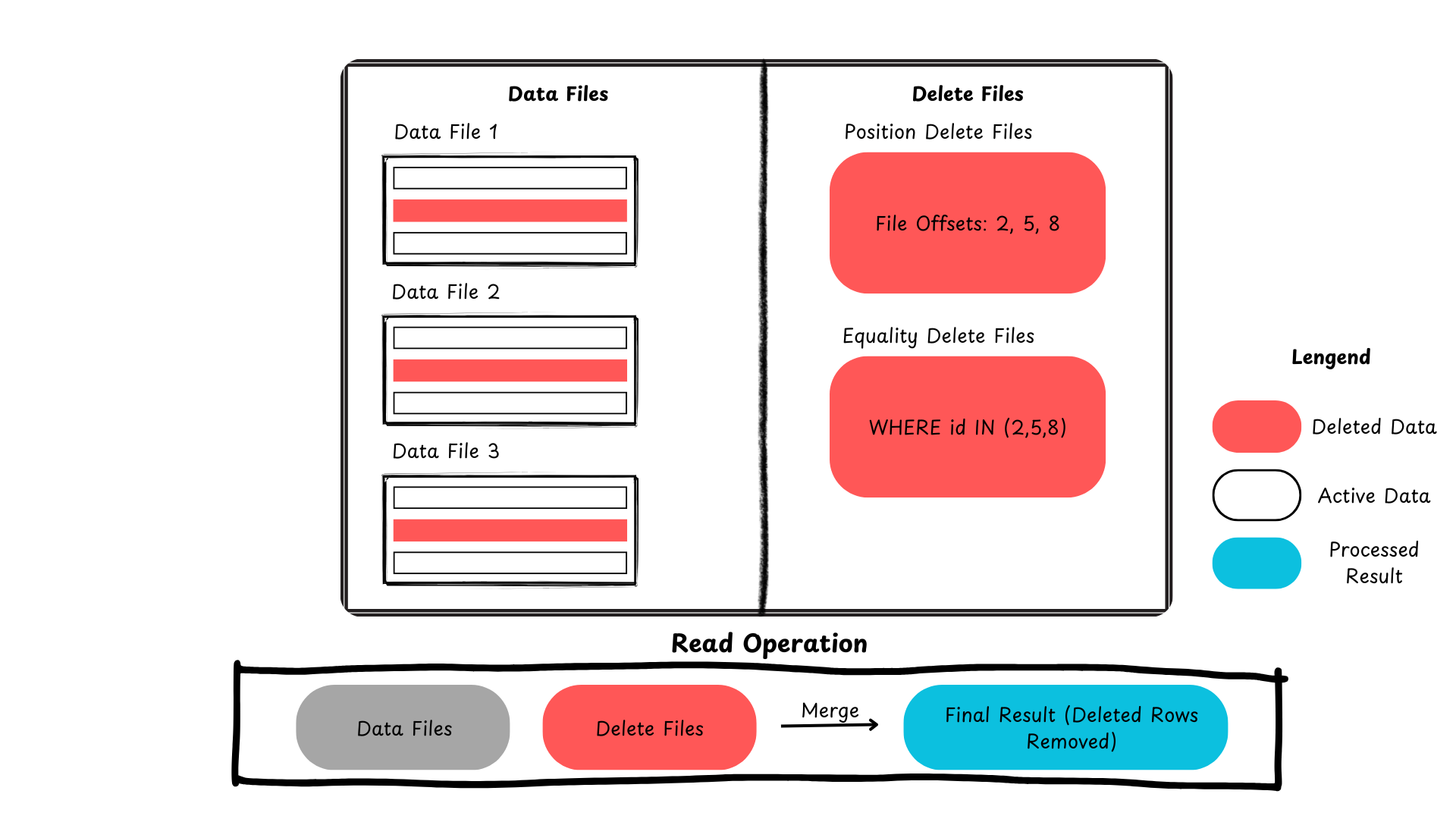
Рисунок 2: Процесс удаления записей в Apache Iceberg (изображение создано автором)
5. Расширенные операции с таблицами
Iceberg поддерживает расширенные операции с таблицами, такие как:
- Создание/управление снимками таблиц: это дает возможность иметь надежный контроль версий.
- Быстрое планирование запросов и выполнение благодаря высоко оптимизированной метадате
- Встроенные инструменты для обслуживания таблиц, такие как компактация и очистка неиспользуемых файлов
Iceberg разработан для работы со всеми основными облачными хранилищами, такими как AWS S3, GCS и Azure Blob Storage. Кроме того, Iceberg легко интегрируется с движками обработки данных, такими как Spark, Presto, Trino и Hive.
Заключительные мысли
Эти выделенные функции позволяют компаниям создавать современные, гибкие, масштабируемые и эффективные озера данных, способные перемещаться во времени, легко обрабатывать изменения схемы, поддерживать ACID-транзакции и эволюцию разделов.
Source:
https://dzone.com/articles/key-features-of-apache-iceberg-for-data-lakes