













Что такое Elasticsearch?
Elasticsearch — это высокомасштабируемый и распределенный поисковый и аналитический движок, построенный на основе библиотеки поиска Apache Lucene. Он предназначен для обработки больших объемов структурированных, полуструктурированных и неструктурированных данных, что делает его хорошо подходящим для широкого круга случаев использования, включая поисковые системы, анализ логов, электронную коммерцию и аналитику безопасности.
Elasticsearch использует распределенную архитектуру, которая позволяет хранить и обрабатывать большие объемы данных на нескольких узлах в кластере. Данные индексируются и хранятся в фрагментах, которые распределяются по узлам для улучшения масштабируемости и устойчивости к сбоям. Elasticsearch также поддерживает реальный поиск и анализ, позволяя пользователям запрашивать и анализировать данные в режиме, близком к реальному времени.
Одной из ключевых особенностей Elasticsearch является его мощные возможности поиска. Он поддерживает широкий спектр запросов поиска, включая полнотекстовый поиск, геопространственный поиск и т.д. Он также предоставляет поддержку для продвинутых аналитических функций, таких как агрегации, метрики и визуализация данных.
Elasticsearch часто используется в сочетании с другими инструментами в Elastic Stack, включая Logstash для сбора и обработки данных и Kibana для визуализации и анализа данных. Вместе эти инструменты предоставляют комплексное решение для поиска и аналитики, которое может быть использовано для широкого круга приложений и случаев использования.
Что такое Apache Lucene?
Apache Lucene — это открытый исходный код поисковая библиотека, которая предоставляет мощные возможности текстового поиска и индексирования. Она широко используется разработчиками и организациями для создания поисковых приложений, начиная от поисковых систем и заканчивая платформами электронной коммерции.
Lucene работает путем индексирования текстового содержимого документов и хранения индекса в структурированном формате, который может быть эффективно проиндексирован. Индекс состоит из серии обратных списков, которые предоставляют соответствия между терминами и документами, которые их содержат. Когда подается поисковый запрос, Lucene использует индекс для быстрого извлечения документов, соответствующих запросу.
Помимо основных возможностей поиска и индексирования, Lucene предоставляет ряд расширенных функций, включая поддержку нечеткого поиска и пространственного поиска. Он также предоставляет инструменты для выделения результатов поиска и ранжирования результатов поиска на основе релевантности.
Lucene используется широким кругом организаций и проектов, включая Elasticsearch. Его богатые возможности, гибкость и расширяемость делают его популярным выбором для создания поисковых приложений всех видов.
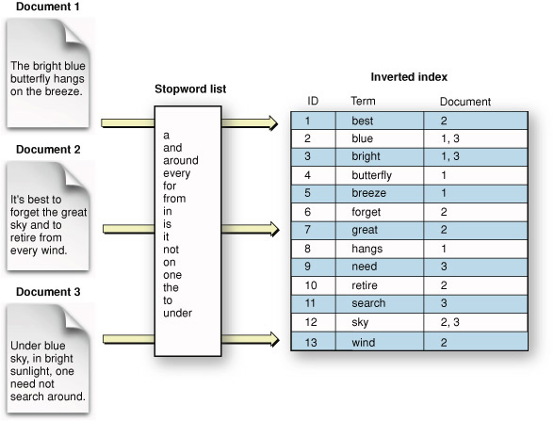
Что такое обратный индекс?
Обратный индекс Lucene — это структура данных, используемая для эффективного поиска и извлечения текстовых данных из коллекции документов. Обратный индекс является центральной особенностью Lucene и используется для хранения терминов и связанных с ними документов, составляющих индекс.
Инвертированный индекс предлагает несколько преимуществ по сравнению с другими стратегиями поиска. Во-первых, он позволяет быстро и эффективно извлекать документы на основе поисковых терминов. Во-вторых, он может обрабатывать большое количество текстовых данных, что делает его хорошо подходящим для случаев использования с большими коллекциями документов. Наконец, он поддерживает широкий спектр продвинутых функций поиска, таких как нечеткое сопоставление и стемминг, которые могут улучшить точность и релевантность результатов поиска.
Почему Elasticsearch?
Есть несколько причин, по которым Elasticsearch является популярным выбором для создания приложений поиска и аналитики:
Легко масштабировать (Распределенный): Elasticsearch создан для горизонтального масштабирования сразу. Когда вам нужно увеличить производительность, просто добавьте больше узлов, и кластер сам перестроится, чтобы воспользоваться дополнительным оборудованием.
Один сервер может содержать один или несколько частей одного или нескольких индексов, и когда новые узлы вводятся в кластер, они просто присоединяются к вечеринке. Каждый такой индекс или его часть называется фрагментом, и фрагменты Elasticsearch могут легко перемещаться по кластеру.
Все в одном JSON вызове (RESTful API): Elasticsearch управляется через API. Почти любое действие можно выполнить с помощью простого RESTful API, используя JSON поверх HTTP. Ответы всегда в формате JSON.
Неудержимая мощь Lucene под капотом: Elasticsearch использует Lucene внутри для создания своих передовых распределенных возможностей поиска и аналитики. Поскольку Lucene является стабильной, проверенной технологией и постоянно пополняется новыми функциями и лучшими практиками, наличие Lucene в качестве базового движка, который питает Elasticsearch.
Отличный Query DSL: REST API предоставляет очень сложный и способный DSL запросов, который очень легко использовать. Каждый запрос – это всего лишь JSON-объект, который может практически содержать любой тип запроса или даже несколько из них, объединенных вместе. Использование фильтрующих запросов, с некоторыми запросами, выраженными как фильтры Lucene, помогает использовать кэширование и тем самым ускоряет общие запросы или сложные запросы с частями, которые можно повторно использовать.
Мультитенантность: На одном инсталляции Elasticsearch – узле или кластере – можно хранить несколько индексов. Приятным дополнением является возможность запросить несколько индексов одним простым запросом.
Поддержка продвинутых возможностей поиска (Полный Текст): Elasticsearch использует Lucene в качестве основы для предоставления самых мощных возможностей полнотекстового поиска, доступных в любом open-source продукте. Поиск поддерживает многоязычную поддержку, мощный язык запросов, поддержку геопозиционирования, подсказки “вы имели в виду”, автозаполнение и фрагменты поиска. Поддержка скриптов в фильтрах и счетчиках.
Настраиваемый и расширяемый: Многие настройки Elasticsearch можно изменить, пока Elasticsearch работает, но некоторые потребуют перезапуска (и, в некоторых случаях, переиндексации). Большинство настроек также можно изменить с помощью REST API.
Документ-ориентированно: Храните сложные реальные сущности в Elasticsearch в виде структурированных документов JSON. По умолчанию индексируются все поля, и все индексы могут использоваться в одном запросе для возвращения результатов с невероятной скоростью.
Без схемы: Elasticsearch позволяет легко начать работу. Отправьте документ JSON, и он попытается обнаружить структуру данных, проиндексировать данные и сделать их доступными для поиска.
Управление конфликтами: Можно использовать оптимистическое управление версиями там, где это необходимо, чтобы обеспечить то, что данные никогда не будут потеряны из-за конфликтующих изменений от нескольких процессов.
Активное сообщество: Сообщество, помимо создания хороших инструментов и плагинов, очень полезно и поддерживает. Общий настрой великолепен, и это важный показатель любого проекта с открытым исходным кодом. Также сейчас пишутся некоторые книги членами сообщества и множество блогов в сети, делящихся опытом и знаниями.
Архитектура Elasticsearch
Основные компоненты архитектуры Elasticsearch:
Узел: Узел – это экземпляр Elasticsearch, который хранит данные и предоставляет возможности поиска и индексирования. Узлы могут быть настроены как мастер-узлы или данные узлы, или и то, и другое. Мастер-узлы отвечают за управление кластером в целом, а данные узлы хранят данные и выполняют операции поиска.
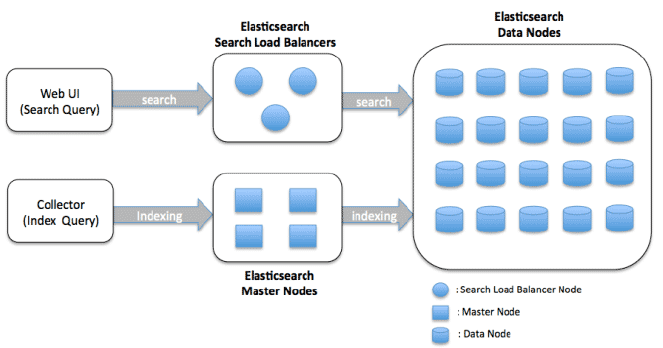
Кластер: Кластер – это группа из одного или нескольких узлов, работающих вместе для хранения и обработки данных. В кластере может быть несколько индексов (коллекции документов) и фрагментов (способ распределения данных по нескольким узлам).
Индекс: Индекс представляет собой набор документов, которые имеют схожую структуру. Каждый документ представлен в виде объекта JSON и содержит один или несколько полей. Elasticsearch индексирует все поля по умолчанию, что упрощает поиск и анализ данных.
Шарды: Индекс может быть разбит на несколько частей, называемых shard, которые являются фактически меньшими подмножествами индекса. Разбиение на shard позволяет обрабатывать данные параллельно и хранить их распределенно на нескольких узлах.
Реплики: Elasticsearch может создавать реплики каждого shard для обеспечения устойчивости к сбоям и высокой доступности. Реплики являются копиями исходного shard и могут быть расположены на разных узлах.
Архитектура кластера узлов данных
Узлы данных отвечают за хранение и индексацию данных, а также за выполнение поисковых запросов и агрегации операций. Архитектура разработана таким образом, чтобы быть масштабируемой и распределенной, что позволяет увеличивать горизонтальное масштабирование, добавляя больше узлов в кластер.
Вот основные компоненты архитектуры кластера узлов данных Elasticsearch:
Узел данных: Узел — это экземпляр Elasticsearch, который хранит данные и предоставляет возможности поиска и индексации. В кластере узлов данных каждый узел отвечает за хранение части данных индекса и обслуживание поисковых запросов к этим данным.
Состояние кластера: Состояние кластера — это структура данных, которая содержит информацию о кластере, включая список узлов, индексов, shard и их расположение. Мастер-узел отвечает за поддержание состояния кластера и распространение его всем остальным узлам в кластере.
Открытие и транспортировка: Узлы в кластере Elasticsearch общаются друг с другом с использованием двух протоколов: открытия и транспортировки. Протокол открытия отвечает за обнаружение новых узлов, присоединяющихся к кластеру, или узлов, которые покинули кластер. Протокол транспортировки отвечает за передачу и прием данных между узлами.
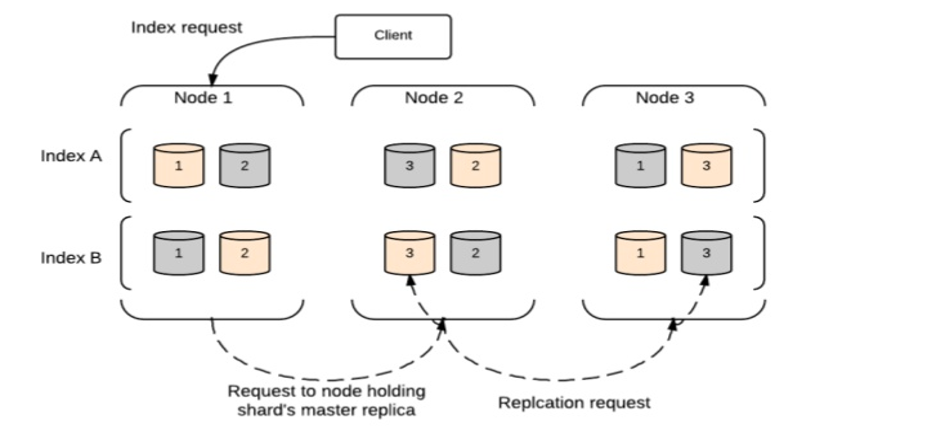
Запрос на индексацию
Запрос на индексацию в Elasticsearch выполняется согласно следующей блок-схеме.
Кто использует Elasticsearch?
Несколько компаний и организаций, использующих Elasticsearch:
Netflix: Netflix использует Elasticsearch для питания своей поисковой и рекомендательной системы, позволяя пользователям быстро находить контент для просмотра.
GitHub: GitHub использует Elasticsearch для обеспечения быстрого и эффективного поиска в своих репозиториях кода, вопросов и запросов на вытягивание.
Uber: Uber использует Elasticsearch для питания своей платформы реального времени аналитики, позволяя отслеживать и анализировать данные о своей службе такси в реальном времени.
Wikipedia: Wikipedia использует Elasticsearch для питания своей поисковой системы и предоставления быстрых и точных результатов поиска пользователям.
Source:
https://dzone.com/articles/introduction-to-elasticsearch-1