













Введение
Каждая компьютерная система выигрывает от правильного администрирования и мониторинга. Отслеживание работы вашей системы поможет вам обнаружить проблемы и быстро их решить.
Существует множество утилит командной строки, созданных для этой цели. Это руководство познакомит вас с некоторыми из наиболее полезных приложений, которые стоит иметь в своем арсенале.
Предварительные требования
Для следования этому руководству вам понадобится доступ к компьютеру, работающему под управлением операционной системы на основе Linux. Это может быть виртуальный частный сервер, к которому вы подключились через SSH, или ваш локальный компьютер. Обратите внимание, что этот учебник был проверен на сервере Linux с Ubuntu 20.04, но приведенные примеры должны работать на компьютере с любой версией любого дистрибутива Linux.
Если вы планируете использовать удаленный сервер для следования этому руководству, мы рекомендуем вам сначала завершить наше Руководство по начальной настройке сервера. Это настроит для вас безопасную серверную среду — включая пользователя без прав администратора с привилегиями sudo и настроенный брандмауэр с использованием UFW — которую вы сможете использовать для развития ваших навыков работы с Linux.
Шаг 1 – Как просматривать запущенные процессы в Linux
Вы можете увидеть все процессы, работающие на вашем сервере, используя команду top:
Outputtop - 15:14:40 up 46 min, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 56 total, 1 running, 55 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1019600k total, 316576k used, 703024k free, 7652k buffers
Swap: 0k total, 0k used, 0k free, 258976k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 24188 2120 1300 S 0.0 0.2 0:00.56 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/0
6 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
7 root RT 0 0 0 0 S 0.0 0.0 0:00.03 watchdog/0
8 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 cpuset
9 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 khelper
10 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
Первые несколько строк вывода предоставляют статистику системы, такую как загрузка процессора/памяти и общее количество запущенных задач.
Вы можете увидеть, что есть 1 запущенный процесс и 55 процессов, которые считаются спящими, потому что они не активно используют процессорные циклы.
Оставшаяся часть отображаемого вывода показывает запущенные процессы и их статистику использования. По умолчанию top автоматически сортирует их по использованию CPU, так что вы можете сначала увидеть самые загруженные процессы. top будет продолжать работать в вашем оболочке, пока вы не остановите его, используя стандартную комбинацию клавиш Ctrl+C для выхода из запущенного процесса. Это отправляет сигнал kill, инструктируя процесс остановиться грациозно, если он способен.
Улучшенная версия top, называемая htop, доступна в большинстве репозиториев пакетов. На Ubuntu 20.04 вы можете установить ее с помощью apt:
После этого команда htop будет доступна:
Output Mem[||||||||||| 49/995MB] Load average: 0.00 0.03 0.05
CPU[ 0.0%] Tasks: 21, 3 thr; 1 running
Swp[ 0/0MB] Uptime: 00:58:11
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
1259 root 20 0 25660 1880 1368 R 0.0 0.2 0:00.06 htop
1 root 20 0 24188 2120 1300 S 0.0 0.2 0:00.56 /sbin/init
311 root 20 0 17224 636 440 S 0.0 0.1 0:00.07 upstart-udev-brid
314 root 20 0 21592 1280 760 S 0.0 0.1 0:00.06 /sbin/udevd --dae
389 messagebu 20 0 23808 688 444 S 0.0 0.1 0:00.01 dbus-daemon --sys
407 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.02 rsyslogd -c5
408 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.00 rsyslogd -c5
409 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.00 rsyslogd -c5
406 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.04 rsyslogd -c5
553 root 20 0 15180 400 204 S 0.0 0.0 0:00.01 upstart-socket-br
htop обеспечивает лучшую визуализацию множественных потоков ЦП, более полную поддержку цвета в современных терминалах и больше опций сортировки, среди прочих функций. В отличие от top, он не всегда устанавливается по умолчанию, но может рассматриваться как замена без проблем. Выход из htop осуществляется нажатием Ctrl+C, как и в случае с top.
Вот несколько сочетаний клавиш, которые помогут вам более эффективно использовать htop:
- M: Sort processes by memory usage
- P: Sort processes by processor usage
- ?: Получить помощь
- k: Kill current/tagged process
- F2: Настроить htop. Здесь вы можете выбрать параметры отображения.
- /:: Поиск процессов
Есть и множество других опций, к которым вы можете получить доступ через помощь или настройки. Это должны быть ваши первые шаги в изучении функциональности htop. В следующем шаге вы узнаете, как отслеживать пропускную способность вашей сети.
Шаг 2 – Как отслеживать пропускную способность вашей сети
Если ваше сетевое подключение кажется перегруженным, и вы не уверены, какое приложение в этом виновато, программа под названием nethogs отлично подходит для определения этого.
На Ubuntu вы можете установить nethogs с помощью следующей команды:
После этого команда nethogs будет доступна:
OutputNetHogs version 0.8.0
PID USER PROGRAM DEV SENT RECEIVED
3379 root /usr/sbin/sshd eth0 0.485 0.182 KB/sec
820 root sshd: root@pts/0 eth0 0.427 0.052 KB/sec
? root unknown TCP 0.000 0.000 KB/sec
TOTAL 0.912 0.233 KB/sec
nethogs ассоциирует каждое приложение с его сетевым трафиком.
Есть только несколько команд, которые вы можете использовать для управления nethogs:
- M: Change displays between “kb/s”, “kb”, “b”, and “mb”.
- R: Sort by traffic received.
- S: Sort by traffic sent.
- Q: quit
iptraf-ng – это еще один способ мониторинга сетевого трафика. Он предоставляет несколько различных интерактивных интерфейсов мониторинга.
Примечание: Для работы IPTraf требуется экран размером не менее 80 столбцов на 24 строки.
На Ubuntu вы можете установить iptraf-ng с помощью следующей команды:
iptraf-ng должен быть запущен с правами root, поэтому вы должны предварить его командой sudo:
Вам будет предложено меню, которое использует популярный фреймворк интерфейса командной строки под названием ncurses.
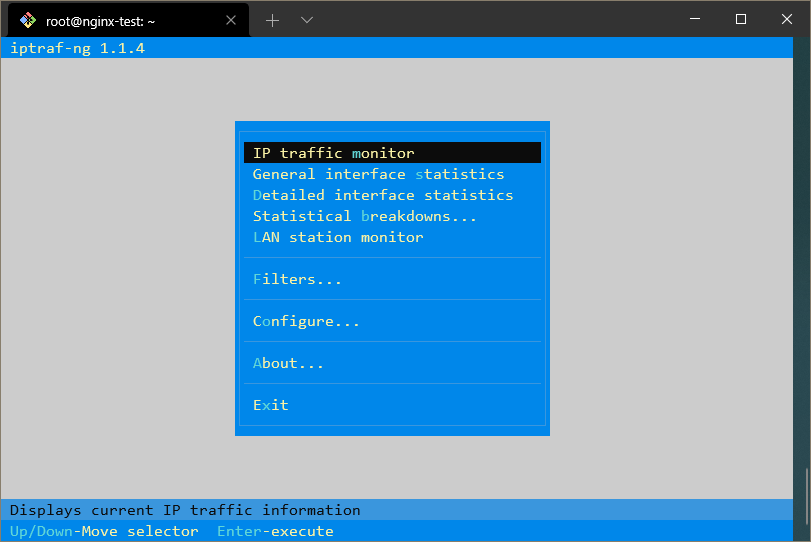
С помощью этого меню вы можете выбрать, к какому интерфейсу вы хотели бы получить доступ.
Например, чтобы получить обзор всего сетевого трафика, вы можете выбрать первое меню, а затем «Все интерфейсы». Это даст вам экран, который выглядит так:
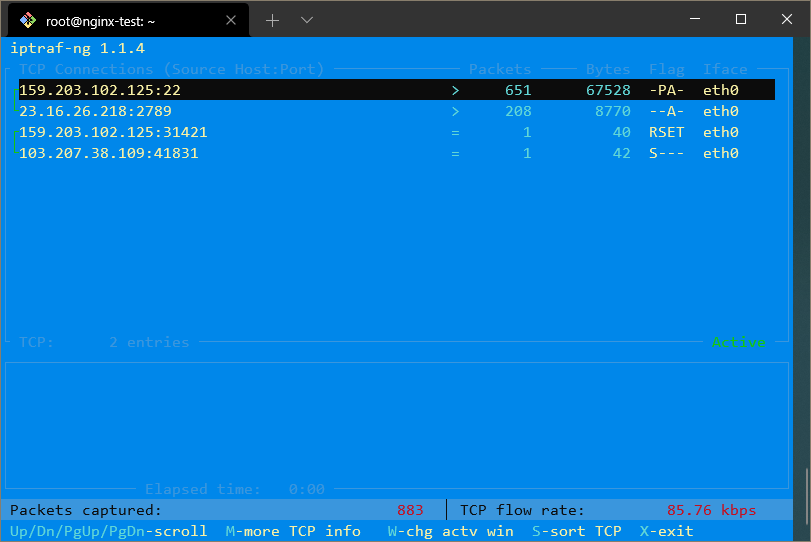
Здесь вы можете видеть, с какими IP-адресами вы общаетесь по всем вашим сетевым интерфейсам.
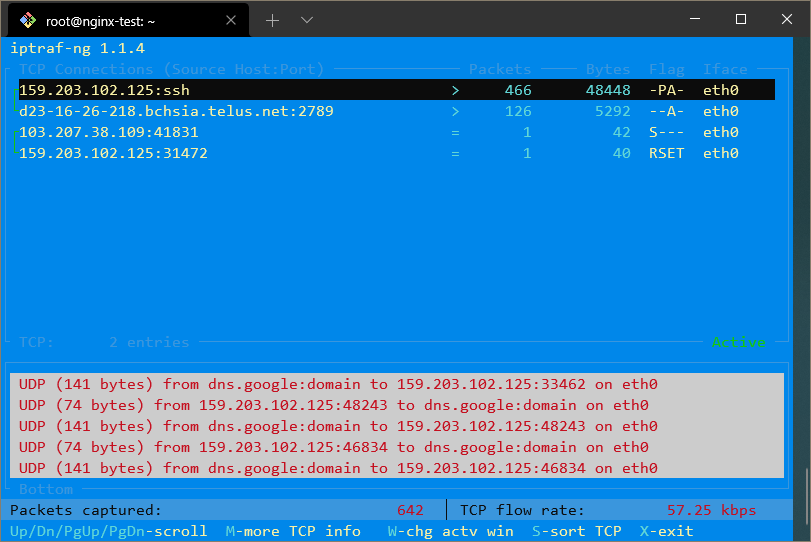
Если вы хотите, чтобы эти IP-адреса были преобразованы в домены, вы можете включить обратный DNS-поиск, выйдя из экрана трафика, выбрав Настройка, а затем включив Обратный DNS-поиск.
Вы также можете включить Имена служб TCP/UDP, чтобы видеть имена служб, которые запущены, а не номера портов.
При включении обеих этих опций отображение может выглядеть так:
Команда netstat – еще один универсальный инструмент для сбора сетевой информации.
netstat по умолчанию установлен на большинстве современных систем, но вы можете установить его самостоятельно, скачав его из репозиториев пакетов вашего сервера по умолчанию. На большинстве систем Linux, включая Ubuntu, пакет, содержащий netstat, называется net-tools:
По умолчанию команда netstat сама по себе выводит список открытых сокетов:
OutputActive Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 192.241.187.204:ssh ip223.hichina.com:50324 ESTABLISHED
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
Active UNIX domain sockets (w/o servers)
Proto RefCnt Flags Type State I-Node Path
unix 5 [ ] DGRAM 6559 /dev/log
unix 3 [ ] STREAM CONNECTED 9386
unix 3 [ ] STREAM CONNECTED 9385
. . .
Если вы добавите опцию -a, она выведет список всех портов, прослушиваемых и непрослушиваемых:
OutputActive Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
Active UNIX domain sockets (servers and established)
Proto RefCnt Flags Type State I-Node Path
unix 2 [ ACC ] STREAM LISTENING 6195 @/com/ubuntu/upstart
unix 2 [ ACC ] STREAM LISTENING 7762 /var/run/acpid.socket
unix 2 [ ACC ] STREAM LISTENING 6503 /var/run/dbus/system_bus_socket
. . .
Если вы хотите отфильтровать вид только TCP или UDP соединений, используйте флаги -t или -u соответственно:
OutputActive Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
Смотрите статистику, передавая флаг “-s”:
OutputIp:
13500 total packets received
0 forwarded
0 incoming packets discarded
13500 incoming packets delivered
3078 requests sent out
16 dropped because of missing route
Icmp:
41 ICMP messages received
0 input ICMP message failed.
ICMP input histogram:
echo requests: 1
echo replies: 40
. . .
Если вы хотите непрерывно обновлять вывод, вы можете использовать флаг -c. Существует много других доступных опций для netstat, которые вы можете изучить, просмотрев его страницу руководства.
На следующем шаге вы узнаете несколько полезных способов мониторинга использования диска.
Шаг 3 – Как мониторить использование диска
Для быстрого обзора оставшегося места на подключенных дисках вы можете использовать программу df.
Без каких-либо опций его вывод выглядит так:
OutputFilesystem 1K-blocks Used Available Use% Mounted on
/dev/vda 31383196 1228936 28581396 5% /
udev 505152 4 505148 1% /dev
tmpfs 203920 204 203716 1% /run
none 5120 0 5120 0% /run/lock
none 509800 0 509800 0% /run/shm
Это выводит использование диска в байтах, что может быть немного сложно читать.
Чтобы исправить эту проблему, вы можете указать вывод в удобочитаемом формате:
OutputFilesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shm
Если вы хотите увидеть общее количество доступного дискового пространства на всех файловых системах, вы можете передать параметр --total. Это добавит строку внизу с обобщенной информацией:
OutputFilesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shm
total 32G 1.2G 29G 4%
df может предоставить полезный обзор. Еще одна команда, du, дает разбивку по каталогам.
du проанализирует использование для текущего каталога и всех подкаталогов. По умолчанию вывод du при запуске в почти пустом домашнем каталоге выглядит следующим образом:
Output4 ./.cache
8 ./.ssh
28 .
Еще раз, вы можете указать человекочитаемый вывод, передавая -h:
Output4.0K ./.cache
8.0K ./.ssh
28K .
Чтобы увидеть размеры файлов, а также каталоги, введите следующее:
Output0 ./.cache/motd.legal-displayed
4 ./.cache
4 ./.ssh/authorized_keys
8 ./.ssh
4 ./.profile
4 ./.bashrc
4 ./.bash_history
28 .
Для общего значения внизу вы можете добавить параметр -c:
Output4 ./.cache
8 ./.ssh
28 .
28 total
Если вас интересует только общее количество, а не конкретные данные, вы можете воспользоваться следующим:
Output28 .
Также существует интерфейс ncurses для du, соответственно названный ncdu, который вы можете установить:
Это графически отобразит использование вашего диска:
Output--- /root ----------------------------------------------------------------------
8.0KiB [##########] /.ssh
4.0KiB [##### ] /.cache
4.0KiB [##### ] .bashrc
4.0KiB [##### ] .profile
4.0KiB [##### ] .bash_history
Вы можете перемещаться по файловой системе, используя стрелки вверх и вниз и нажимая Enter на любой записи каталога.
В последнем разделе вы узнаете, как отслеживать использование памяти.
Шаг 4 – Как отслеживать использование памяти
Вы можете проверить текущее использование памяти на вашей системе, используя команду free.
Когда используется без параметров, вывод выглядит так:
Output total used free shared buff/cache available
Mem: 1004896 390988 123484 3124 490424 313744
Swap: 0 0 0
Чтобы отобразить в более удобном формате, вы можете передать параметр -m, чтобы отобразить вывод в мегабайтах:
Output total used free shared buff/cache available
Mem: 981 382 120 3 478 306
Swap: 0 0 0
Строка Mem включает использованную память для буферизации и кэширования, которая освобождается сразу, как только требуется для других целей. Swap – это память, которая была записана в файл подкачки на диске для сохранения активной памяти.
Наконец, команда vmstat может выводить различную информацию о вашей системе, включая память, подкачку, ввод-вывод диска и информацию о центральном процессоре.
Вы можете использовать эту команду, чтобы получить другой взгляд на использование памяти:
Outputprocs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 99340 123712 248296 0 0 0 1 9 3 0 0 100 0
Вы можете увидеть это в мегабайтах, указав единицы с помощью флага -S:
Outputprocs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 96 120 242 0 0 0 1 9 3 0 0 100 0
Чтобы получить общую статистику использования памяти, введите:
Output 495 M total memory
398 M used memory
252 M active memory
119 M inactive memory
96 M free memory
120 M buffer memory
242 M swap cache
0 M total swap
0 M used swap
0 M free swap
. . .
Чтобы получить информацию о использовании кэша отдельными процессами системы, введите:
OutputCache Num Total Size Pages
ext4_groupinfo_4k 195 195 104 39
UDPLITEv6 0 0 768 10
UDPv6 10 10 768 10
tw_sock_TCPv6 0 0 256 16
TCPv6 11 11 1408 11
kcopyd_job 0 0 2344 13
dm_uevent 0 0 2464 13
bsg_cmd 0 0 288 14
. . .
Это даст вам подробности о том, какая информация хранится в кэше.
Заключение
Используя эти инструменты, вы должны начать уметь мониторить ваш сервер из командной строки. Существует множество других утилит мониторинга, которые используются для различных целей, но эти – хорошая отправная точка.
Затем вам может понадобиться изучить управление процессами в Linux с помощью ps, kill и nice.