













Использование мониторинга ИТ в инфраструктуре организации может улучшить ее надежность и помочь предотвратить серьезные проблемы, сбои и простои. Существуют различные подходы к реализации мониторинга ИТ, путем использования специальных инструментов или встроенной функциональности. С любым из подходов вы можете просматривать данные мониторинга по мере необходимости или настроить автоматические оповещения и отчеты, чтобы быть уведомленным об важных событиях. В этом блоге объясняется, как улучшить стратегию мониторинга ИТ, используя сигналы тревоги и отчеты.
Важность мониторинга ИТ и отчетности для бизнеса
Мониторинг ИТ критичен для организаций, потому что он помогает обеспечить надлежащую и надежную работу ИТ-инфраструктуры.
- Максимизация времени работы и надежности. Критические бизнес-системы обычно требуют круглосуточной работы. Такие системы используются в отраслях, таких как здравоохранение, финансы и другие поставщики услуг, где простои могут привести к серьезным последствиям. К счастью, можно предотвратить такие проблемы, если вы реализуете и правильно настроите систему мониторинга ИТ.
Превентивное обнаружение проблем помогает администраторам обнаружить потенциальные проблемы, такие как перегрузки серверов, ошибки приложений, проблемы с оборудованием и снижение производительности, вовремя, прежде чем они приведут к серьезным сбоям. Этот превентивный подход позволяет администраторам взаимодействовать и выполнять корректирующие действия до того, как они окажут негативное воздействие на серверы, виртуальные машины (ВМ), бизнес-операции и конечных пользователей. Получение отчетов, указывающих на потенциальные проблемы, делает мониторинг и администрирование ИТ более эффективными.
- Усиление безопасности. ИТ-мониторинг используется для обнаружения несанкционированных попыток доступа, необычного сетевого трафика и других подозрительных действий, которые могут быть индикатором кибератаки. Этот подход позволяет администраторам своевременно выявлять угрозы безопасности. Некоторые отрасли обязаны соблюдать нормативные требования, требующие непрерывного мониторинга ИТ-систем, чтобы избежать штрафов.
- Улучшение производительности и эффективности. Администраторы могут оптимизировать использование ресурсов на серверах, виртуальных машинах и сетевом оборудовании, настраивая ИТ-мониторинг и оповещения. Настройка инструментов ИТ-мониторинга для отслеживания использования ЦП, памяти и пропускной способности для дальнейшего анализа этих данных позволяет лучше понять, что необходимо улучшить. В результате организации могут оптимизировать свои ресурсы и сократить потери для достижения высокой эффективности в своих ИТ-системах. Это также помогает администраторам выявлять узкие места и повышать производительность.
- Улучшение непрерывности бизнеса и восстановление после катастрофы. Раннее обнаружение сбоев является одной из основных причин, по которой администраторы организаций должны настраивать системы мониторинга ИТ с уведомлениями. Такой подход позволяет обнаружить признаки повреждения данных, сбои приложений и аппаратного обеспечения на ранних стадиях для предотвращения потери данных. Предотвращение потери данных необходимо для поддержания непрерывности бизнеса. Используя инструменты мониторинга с настроенными уведомлениями, администраторы могут гарантировать, что резервные системы и планы восстановления после катастрофы проверены и функционируют правильно. Это обеспечит уверенность, что бизнес сможет быстро восстановить данные и рабочие нагрузки в случае катастрофы.
- Улучшение опыта клиентов. Клиенты ожидают, что услуги будут доступны в любое время. Настройка систем мониторинга ИТ для отслеживания серверов, виртуальных машин, сетевого оборудования и приложений, связанных с работой веб-сайта, помогает гарантировать, что веб-сайты и услуги всегда доступны для клиентов. Не только доступность ресурсов, но и производительность отслеживаются для достижения лучшего обслуживания.
Получение отчетов, включающих информацию о проблемах, может привести к быстрому решению. Отчеты содержат информацию, необходимую администраторам для решения проблем как можно скорее. Эти действия минимизируют негативное воздействие на клиентов и, как следствие, клиенты получают положительный опыт.
- Управление затратами. Настройка проактивного мониторинга может предотвратить простой. Незапланированный простой может быть дорогостоящим, поскольку организация теряет доход и должна тратить ресурсы на восстановление данных и инфраструктуры. Мониторинг с уведомлениями об оповещении позволяет администраторам устранять проблему как можно быстрее и снижать риск простоя.
Понимание тревог в ИТ-мониторинге
Настройка тревог для систем ИТ-мониторинга улучшает время реакции администраторов, чтобы они могли быть в курсе проблемы и быстрее ее исправлять. Если настроены только ресурсы, такие как веб-страницы с графиками и статистикой, тогда системный администратор может заметить проблемы только при проверке веб-страницы с информацией мониторинга. У администраторов широкий набор различных задач, и обычно они не могут постоянно следить за веб-страницей с состоянием ИТ-инфраструктуры.
Когда тревоги настроены, администраторы получают уведомление о проблеме, потенциальной проблеме, сбое или других критических или подозрительных событиях как можно скорее. Обычно можно настроить временной интервал, например, сообщение может быть отправлено через 1 минуту или 5 минут после того, как мониторинговая система обнаружила проблему.
В результате администратор системы может быстрее заметить проблему и отреагировать, чтобы исправить её и избежать негативных последствий. Можно использовать различные методы уведомлений, такие как уведомления по электронной почте, SMS, Skype и т.д., в зависимости от программного обеспечения для мониторинга ИТ.
Что такое тревоги и почему они важны?
Тревоги — это уведомления, которые срабатывают, когда происходит определенное событие и выполняются соответствующие условия или пороги в ИТ-системе. Эти условия могут основываться на различных событиях, включая:
- Проблемы с производительностью: Высокая загрузка процессора, исчерпание памяти, медленная реакция
- Пороги ресурсов: Нехватка дискового пространства, насыщение сетевой полосы
- Системные сбои: Сбои серверов, ошибки приложений, сбои служб
- Инциденты безопасности: Попытки несанкционированного доступа, обнаружение вредоносного ПО, необычный сетевой трафик
- Операционные события: Сбои резервного копирования, перезапуск служб, изменения в конфигурации
Когда срабатывает тревога, система мониторинга генерирует оповещение, и это оповещение отправляется соответствующему пользователю, в первую очередь администратору ИТ, через различные каналы. Эти оповещения содержат информацию о проблеме, включая её серьезность, затронутую систему или компонент и рекомендуемые действия.
Ключевые метрики для мониторинга
Использование ЦП. Мониторинг использования процессора необходим для обеспечения достаточного количества ресурсов для серверов и систем в терминах вычислительной мощности. Это важно для обработки рабочих нагрузок без перегрузки. Высокое использование ЦП может свидетельствовать о том, что система перегружена. Низкое использование ЦП указывает на то, что ресурсов достаточно или что ресурсы ЦП используются недостаточно.
Использование памяти (ОЗУ). Приложениям и службам необходимо достаточно памяти для бесперебойной работы, и параметр памяти критичен в этом контексте. Администраторам следует мониторить использование ОЗУ, чтобы предотвратить узкие места в памяти, которые могут вызвать снижение производительности и даже сбои системы. Обратите внимание на чрезмерное использование памяти, недостаточное выделение памяти и утечки памяти.
Использование диска и производительность ввода/вывода (I/O). Доступное место на диске и производительность ввода/вывода (I/O) являются критическими показателями для хранения данных. Рекомендуется мониторить эти параметры, чтобы предотвратить проблемы, связанные с хранением, включая проблемы производительности. Обратите внимание на высокое использование диска, быстрый рост использованного дискового пространства, высокую задержку при чтении/записи данных и частые времена ожидания ввода/вывода. Аномальное поведение в отношении этих параметров может указывать на потенциальные проблемы с хранением.
Пропускная способность сети и задержка. Производительность сети влияет на все операции в офисе или дата-центре, поскольку компьютеры, серверы и виртуальные машины соединены между собой через сеть. Производительность сети критична для предоставляемых услуг клиентам. Мониторинг пропускной способности сети и задержки позволяет обнаружить узкие места и другие проблемы, чтобы своевременно исправить их и эффективно использовать ресурсы сети. Обратите внимание на высокое использование сети, потерю пакетов и высокую задержку, поскольку эти показатели являются признаками медленной производительности и проблем с сетевым подключением.
Доступность сервисов и процессов. Важные процессы работают в операционных системах на серверах или виртуальных машинах, и они должны быть доступными для удовлетворения бизнес-потребностей. Мониторинг сервисов и их доступности гарантирует, что критические сервисы функционируют. Для обеспечения доступности сервисов администраторам следует отслеживать время работы, частоту перезапуска сервисов и сбои процессов.
Производительность баз данных. Базы данных часто являются частью более сложных решений, включая веб-приложения. Более того, большинство программных решений для внутреннего использования в организациях требуют баз данных. Поэтому важно мониторить производительность и доступность баз данных. Мониторинг баз данных гарантирует доступность данных и бесперебойную работу связанных операций. При мониторинге базы данных сосредоточьтесь на времени ответа на запросы, медленных запросах, блокировках баз данных и использовании пула соединений, поскольку эти метрики важны для здоровья базы данных.
Отчетность по мониторингу ИТ
Отчётность используется для предоставления структурированных действенных выводов из огромного объема данных, собранных инструментами мониторинга. Отчётность преобразует сырые данные в информацию, которую можно прочитать и понять для людей, работающих в организации и в основном для администраторов ИТ. После проверки отчётов администраторы и руководство могут принимать обоснованные решения. Это позволяет ИТ-командам оптимизировать производительность, предотвращать проблемы и улучшать бизнес-континуитет.
Отчёты могут выявлять аномалии, которые не заметны при исследовании тревог. Данные в отчётах агрегируются для большего удобства, чтобы избежать необходимости вручную искать ключевые показатели и организовывать собранные данные. В результате администраторы имеют общий обзор всей инфраструктуры и наиболее важных компонентов. Быть информированными о условиях, приведших к инциденту, может использоваться администраторами для быстрого реагирования на инцидент и выполнения профилактических мер.
Мониторинг с помощью NAKIVO Backup & Replication
NAKIVO Backup & Replication может помочь вам отслеживать элементы вашей ИТ-инфраструктуры. Перейдите в раздел Мониторинг в веб-интерфейсе, добавьте отслеживаемые элементы и проверьте графики, отображающие поддерживаемые метрики инфраструктуры VMware vSphere.
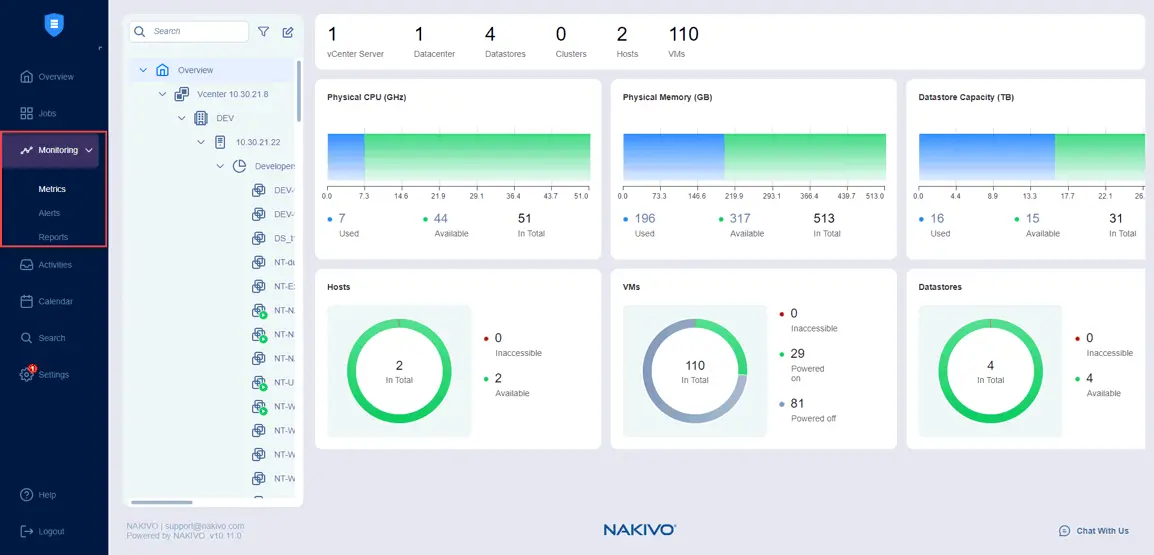
Вы можете выбрать элементы для отслеживания, такие как хосты ESXi или кластеры, виртуальные машины VMware и хранилища данных в разделе Мониторинг > Метрики.
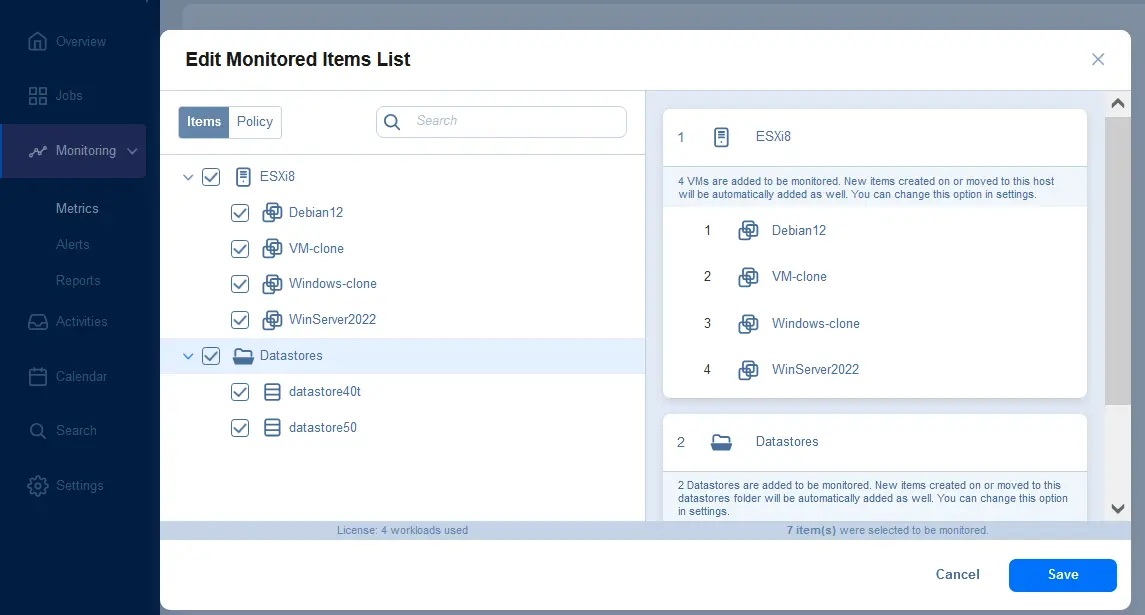
Настройка сигналов в решении NAKIVO
Вы можете настроить уведомления в решении NAKIVO, чтобы получать оповещения о потенциальных проблемах как можно скорее, что позволит вам быстро решить их до того, как они приведут к серьезным последствиям.
- Перейдите в Мониторинг > Уведомления, выберите вкладку Управление шаблонами уведомлений и нажмите +, чтобы добавить уведомления для конкретных объектов.
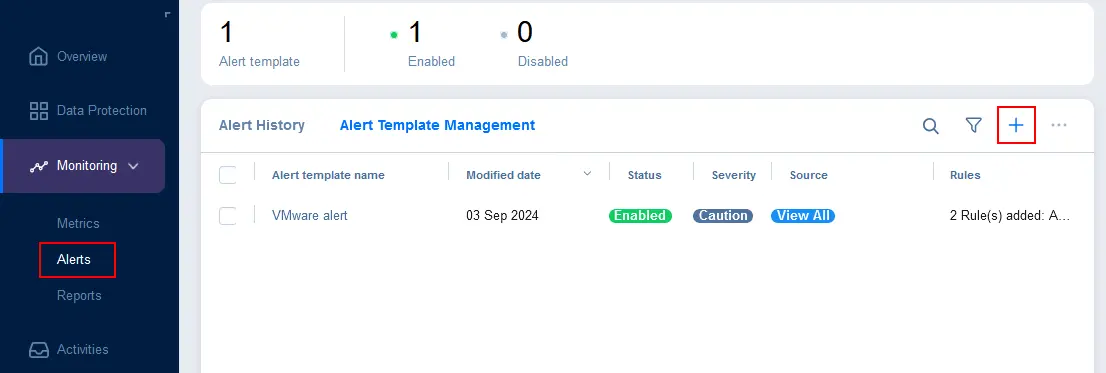
- Выберите отслеживаемые объекты, для которых должно срабатывать уведомление. Вы можете выбрать хосты ESXi, виртуальные машины (VM) или хранилища данных. Нажмите Далее, чтобы продолжить.
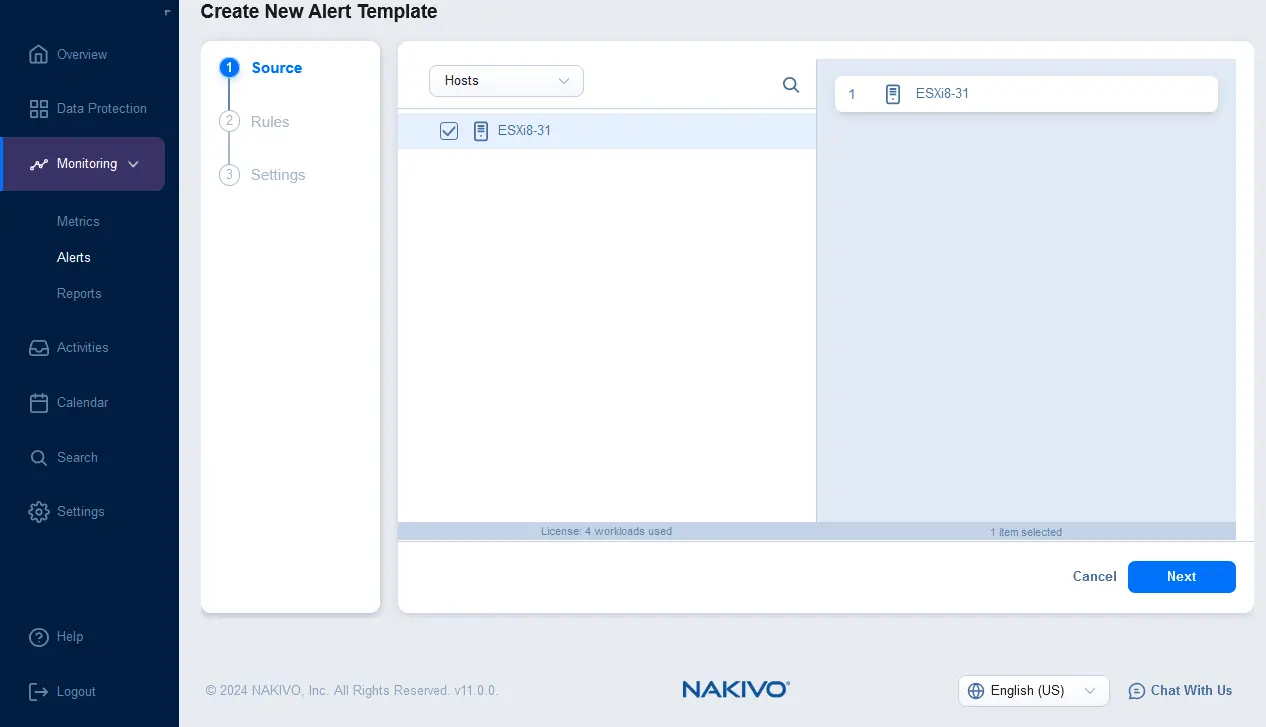
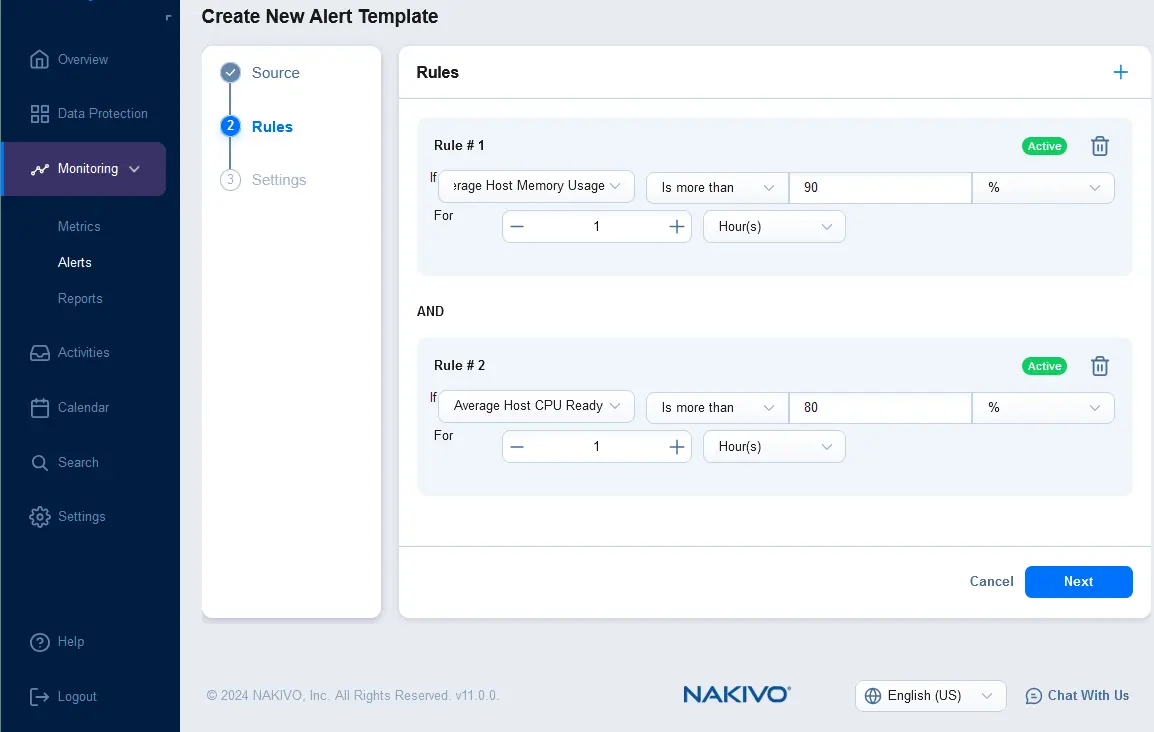
- Настройте правила для нового шаблона уведомления. Нажмите + и выберите условие правила. Например, вы можете установить шаблон правила уведомления, который должен срабатывать, если среднее использование памяти хоста превышает 90% в течение 1 часа. Вы можете добавить несколько правил для одного шаблона уведомления.
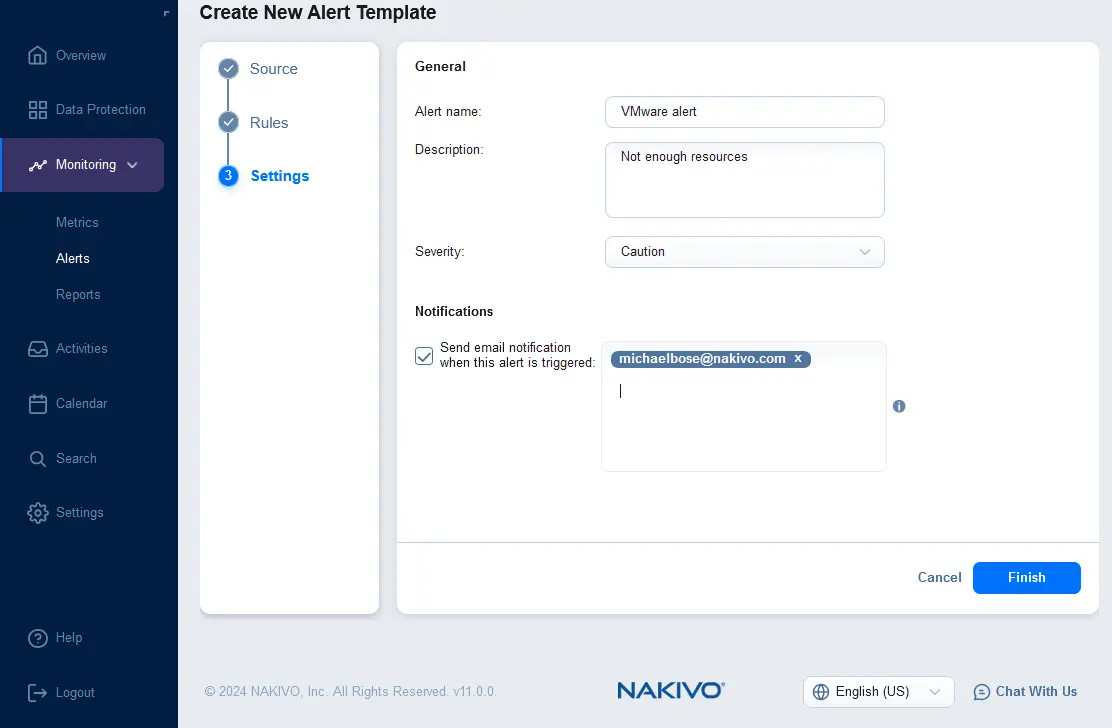
- Настройте параметры шаблона оповещения. Введите название оповещения и описание, выберите уровень серьезности. Вы можете установить флажок для отправки уведомления по электронной почте при срабатывании этого оповещения и указать несколько адресов электронной почты получателей, которые должны получать уведомления об оповещениях. Нажмите Завершить.
Настройка отчетов в решении NAKIVO
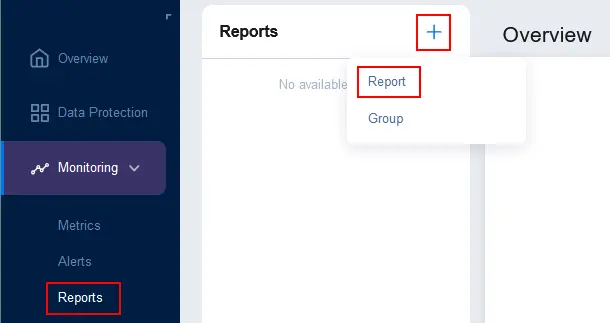
- Для настройки отчетов перейдите в раздел Мониторинг > Отчеты, нажмите + и выберите Отчет.
- Вы можете выбрать один из поддерживаемых типов источников:
- Обзор инфраструктуры – информация о серверах vCenter, управляемых серверах ESXi и автономных серверах ESXi
- Производительность ВМ
- Емкость хранилища
- Производительность хоста
- Отчет о защите
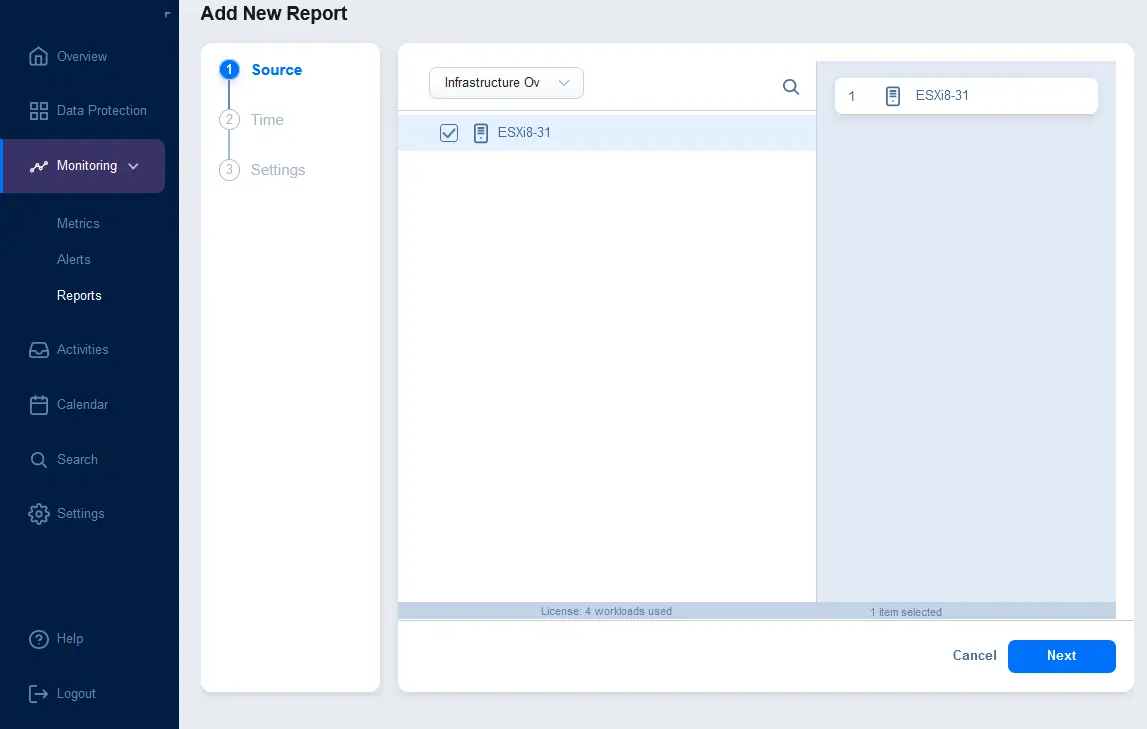
После выбора типа источника выберите элементы, которые следует включить в отчет. На скриншоте ниже вы можете видеть, что в выпадающем списке выбран Обзор инфраструктуры, и выбран сервер ESXi для включения в отчет. Нажмите Далее, чтобы продолжить.
- Настройте временной диапазон и даты для отчета. Например, вы можете создать отчет за последние 30 дней.
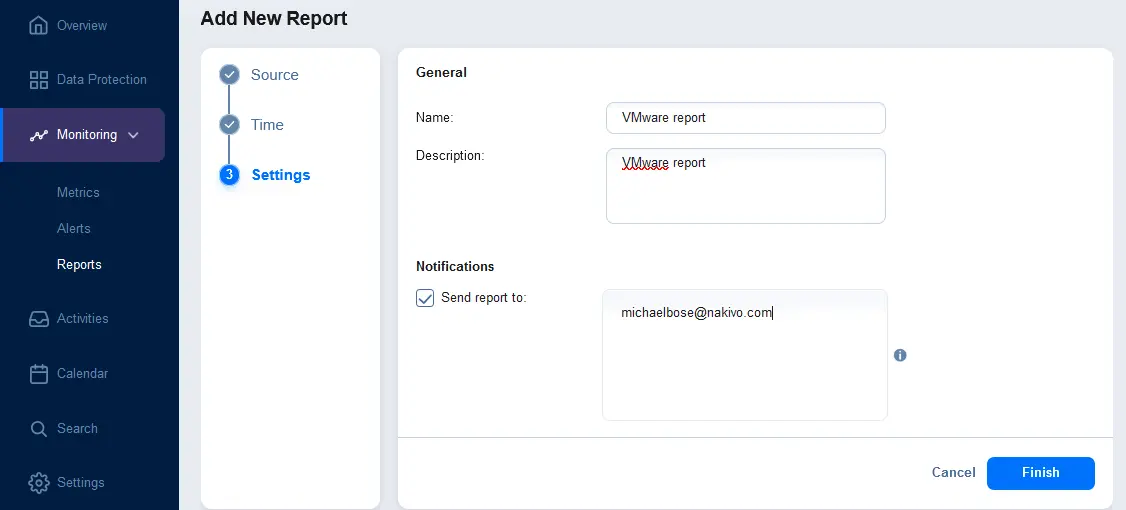
- Настройте параметры отчета. Введите отображаемое имя отчета и его описание. По желанию, в разделе Уведомления выберите флажок, чтобы отправить отчет на указанные адреса электронной почты. Введите адрес электронной почты и нажмите Enter, чтобы применить этот адрес. Вы можете ввести несколько адресов электронной почты. Нажмите Готово, чтобы сохранить настройки для создания отчета.
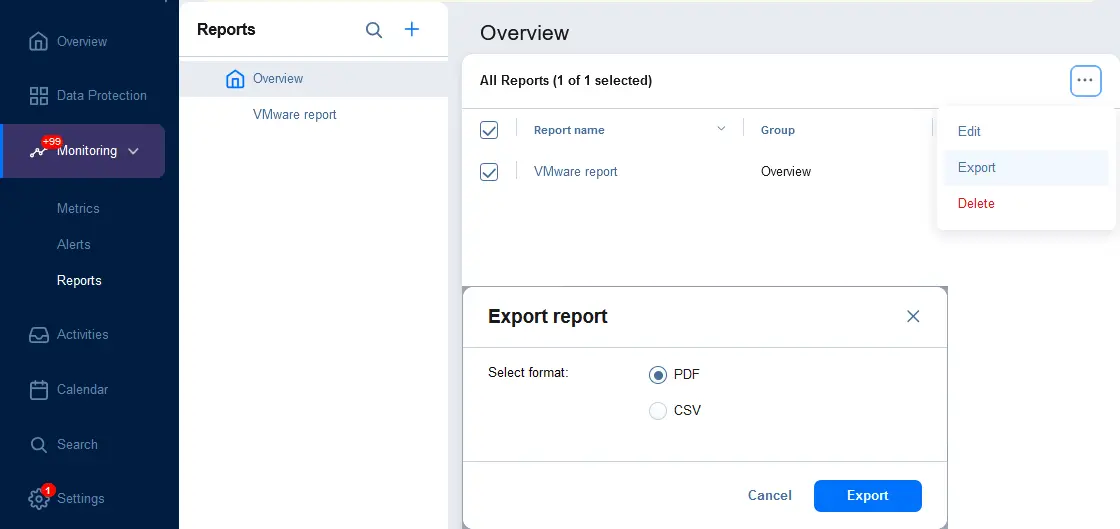
- Вы можете экспортировать отчеты в файл. Перейдите в Мониторинг > Отчеты и выберите отчеты, которые хотите экспортировать (выберите флажки). Нажмите кнопку … (дополнительные параметры), нажмите Экспорт, и в диалоговом окне выберите формат файла (PDF или CSV). Нажмите Экспорт.
Заключение
Мониторинг ИТ-инфраструктур может повысить эффективность администрирования, обеспечить непрерывность бизнеса и сократить затраты. Рекомендуется настроить инструменты мониторинга ИТ для отправки уведомлений и отчетов для раннего реагирования на инциденты, чтобы предотвратить потенциальные проблемы и как можно скорее устранить существующие. Используйте NAKIVO Backup & Replication для защиты ваших данных, включая виртуальные машины VMware, а также для мониторинга вашей инфраструктуры vSphere и задач защиты данных.
Source:
https://www.nakivo.com/blog/how-to-use-alarms-and-reporting-for-it-monitoring/