













Автор выбрал Фонд свободного и открытого программного обеспечения для получения пожертвования в рамках программы Напиши для пожертвований.
Введение
Flask – это легкий веб-фреймворк Python, который предоставляет полезные инструменты и функции для создания веб-приложений на языке Python. SQLAlchemy – это инструментарий SQL, который обеспечивает эффективный и высокопроизводительный доступ к базам данных реляционного типа. Он предоставляет способы взаимодействия с несколькими движками баз данных, такими как SQLite, MySQL и PostgreSQL. Он предоставляет доступ к SQL-функционалу базы данных. И также он предоставляет объектно-реляционный маппер (ORM), который позволяет выполнять запросы и обрабатывать данные с помощью простых объектов и методов Python. Flask-SQLAlchemy – это расширение Flask, которое упрощает использование SQLAlchemy с Flask, предоставляя вам инструменты и методы для взаимодействия с вашей базой данных в ваших приложениях Flask через SQLAlchemy.
В этом руководстве вы будете использовать Flask и Flask-SQLAlchemy для создания системы управления сотрудниками с базой данных, в которой будет таблица для сотрудников. У каждого сотрудника будет уникальный идентификатор, имя, фамилия, уникальный адрес электронной почты, целочисленное значение для возраста, дата присоединения к компании и логическое значение для определения того, является ли сотрудник в настоящее время активным или вне офиса.
Вы будете использовать оболочку Flask для запроса таблицы и получения записей таблицы на основе значения столбца (например, электронной почты). Вы будете извлекать записи сотрудников при определенных условиях, например, получение только активных сотрудников или получение списка сотрудников, находящихся вне офиса. Вы будете упорядочивать результаты по значению столбца, считать и ограничивать результаты запроса. Наконец, вы будете использовать пагинацию для отображения определенного количества сотрудников на странице в веб-приложении.
Предварительные требования
-
Локальная среда программирования Python 3. Следуйте инструкциям для вашего распределения в серии руководств Как установить и настроить локальную среду программирования для Python 3. В этом руководстве мы назовем наш каталог проекта
flask_app. -
Понимание основных концепций Flask, таких как маршруты, видовые функции и шаблоны. Если вы не знакомы с Flask, ознакомьтесь с руководствами Как создать ваше первое веб-приложение с использованием Flask и Python и Как использовать шаблоны в приложении Flask.
-
Понимание основных концепций HTML. Вы можете просмотреть нашу серию учебных пособий Как создать веб-сайт с помощью HTML для получения фоновых знаний.
-
Понимание основных концепций Flask-SQLAlchemy, таких как настройка базы данных, создание моделей базы данных и вставка данных в базу данных. См. Как использовать Flask-SQLAlchemy для взаимодействия с базами данных в приложении Flask для фоновых знаний.
Шаг 1 — Настройка базы данных и модели
На этом этапе вы установите необходимые пакеты и настроите ваше приложение Flask, базу данных Flask-SQLAlchemy и модель сотрудника, представляющую таблицу employee, где будут храниться данные о ваших сотрудниках. Вы вставите несколько сотрудников в таблицу employee, добавите маршрут и страницу, где все сотрудники будут отображаться на главной странице вашего приложения.
Сначала, с активированной виртуальной средой, установите Flask и Flask-SQLAlchemy:
После завершения установки вы получите вывод со следующей строкой в конце:
Output
Successfully installed Flask-2.1.2 Flask-SQLAlchemy-2.5.1 Jinja2-3.1.2 MarkupSafe-2.1.1 SQLAlchemy-1.4.37 Werkzeug-2.1.2 click-8.1.3 greenlet-1.1.2 itsdangerous-2.1.2
С установленными необходимыми пакетами откройте новый файл с именем app.py в вашем каталоге flask_app. В этом файле будет код для настройки базы данных и ваших маршрутов Flask:
Добавьте следующий код в app.py. Этот код настроит базу данных SQLite и модель базы данных сотрудников, представляющую таблицу employee, в которой вы будете хранить данные о своих сотрудниках:
Сохраните и закройте файл.
Здесь вы импортируете модуль os, который дает вам доступ к различным интерфейсам операционной системы. Вы будете использовать его для создания пути к файлу вашей базы данных database.db.
Из пакета flask вы импортируете необходимые помощники для вашего приложения: класс Flask для создания экземпляра приложения Flask, render_template() для отображения шаблонов, объект request для обработки запросов, url_for() для создания URL-адресов и функцию redirect() для перенаправления пользователей. Для получения дополнительной информации о маршрутах и шаблонах см. Как использовать шаблоны в приложении Flask.
Затем вы импортируете класс SQLAlchemy из расширения Flask-SQLAlchemy, который дает вам доступ ко всем функциям и классам из SQLAlchemy, а также помощникам и функциональности, которые интегрируют Flask с SQLAlchemy. Вы будете использовать его для создания объекта базы данных, который подключается к вашему приложению Flask.
Чтобы создать путь для файла вашей базы данных, вы определяете базовый каталог как текущий каталог. Вы используете функцию os.path.abspath(), чтобы получить абсолютный путь к каталогу текущего файла. Специальная переменная __file__ содержит путь к текущему файлу app.py. Вы сохраняете абсолютный путь базового каталога в переменной с именем basedir.
Затем вы создаете экземпляр приложения Flask с именем app, который вы используете для настройки двух ключей конфигурации Flask-SQLAlchemy ключи конфигурации:
-
SQLALCHEMY_DATABASE_URI: URI базы данных для указания базы данных, с которой вы хотите установить соединение. В этом случае URI следует форматуsqlite:///путь/к/базе. db. Вы используете функциюos.path.join()для интеллектуального объединения базового каталога, который вы построили и сохранили в переменнойbasedir, с именем файлаdatabase.db. Это подключится к файлу базы данныхdatabase.dbв вашем каталогеflask_app. Файл будет создан после инициализации базы данных. -
SQLALCHEMY_TRACK_MODIFICATIONS: Конфигурация для включения или отключения отслеживания изменений объектов. Вы устанавливаете его вFalse, чтобы отключить отслеживание, что использует меньше памяти. Для получения дополнительной информации см. страницу конфигурации в документации Flask-SQLAlchemy.
После настройки SQLAlchemy путем установки URI базы данных и отключения отслеживания вы создаете объект базы данных, используя класс SQLAlchemy, передавая экземпляр приложения для подключения вашего приложения Flask к SQLAlchemy. Вы сохраняете объект базы данных в переменной с именем db, которую будете использовать для взаимодействия с вашей базой данных.
После настройки экземпляра приложения и объекта базы данных, вы наследуетесь от класса db.Model для создания модели базы данных с именем Employee. Эта модель представляет таблицу employee и имеет следующие столбцы:
id: Идентификатор сотрудника, целочисленный первичный ключ.firstname: Имя сотрудника, строка с максимальной длиной 100 символов.nullable=Falseозначает, что этот столбец не должен быть пустым.lastname: Фамилия сотрудника, строка с максимальной длиной 100 символов.nullable=Falseозначает, что этот столбец не должен быть пустым.email: Электронная почта сотрудника, строка с максимальной длиной 100 символов.unique=Trueозначает, что каждый адрес электронной почты должен быть уникальным.nullable=Falseозначает, что значение не должно быть пустым.age: Возраст сотрудника, целочисленное значение.hire_date: Дата приема на работу сотрудника. Вы устанавливаетеdb.Dateкак тип столбца, чтобы объявить его как столбец, содержащий даты.active: Столбец, который будет содержать логическое значение, указывающее, активен ли сотрудник в настоящее время или отсутствует.
Специальная функция __repr__ позволяет дать каждому объекту строковое представление для его идентификации в целях отладки. В данном случае вы используете имя и фамилию сотрудника для представления каждого объекта сотрудника.
Теперь, когда вы настроили подключение к базе данных и модель сотрудника, вы напишете программу на Python для создания вашей базы данных и таблицы employee, а также заполните таблицу некоторыми данными о сотрудниках.
Откройте новый файл с названием init_db.py в вашем каталоге flask_app:
Добавьте следующий код для удаления существующих таблиц базы данных для начала с чистой базы данных, создания таблицы employee и вставки девяти сотрудников в нее:
Здесь вы импортируете класс date() из модуля datetime, чтобы использовать его для установки даты приема на работу сотрудника.
Вы импортируете объект базы данных и модель Employee. Вы вызываете функцию db.drop_all() для удаления всех существующих таблиц, чтобы избежать возможности наличия уже заполненной таблицы employee в базе данных, что может вызвать проблемы. Это удалит все данные из базы данных при каждом выполнении программы init_db.py. Для получения дополнительной информации о создании, изменении и удалении таблиц базы данных смотрите Как использовать Flask-SQLAlchemy для взаимодействия с базами данных в приложении Flask.
Затем вы создаете несколько экземпляров модели Employee, которые представляют собой сотрудников, с которыми вы будете работать в этом руководстве, и добавляете их в сеанс базы данных, используя функцию db.session.add_all(). Наконец, вы фиксируете транзакцию и применяете изменения к базе данных с помощью db.session.commit().
Сохраните и закройте файл.
Запустите программу init_db.py:
Чтобы посмотреть на данные, которые вы добавили в свою базу данных, убедитесь, что ваш виртуальный окружение активировано, и откройте оболочку Flask для запроса всех сотрудников и отображения их данных:
Запустите следующий код для запроса всех сотрудников и отображения их данных:
Вы используете метод all() атрибута query для получения всех сотрудников. Вы перебираете результаты и отображаете информацию о сотруднике. Для столбца active вы используете условное выражение для отображения текущего статуса сотрудника: либо 'Активен', либо 'Вне офиса'.
Вы получите следующий вывод:
OutputJohn Doe
Email: [email protected]
Age: 32
Hired: 2012-03-03
Active
----
Mary Doe
Email: [email protected]
Age: 38
Hired: 2016-06-07
Active
----
Jane Tanaka
Email: [email protected]
Age: 32
Hired: 2015-09-12
Out of Office
----
Alex Brown
Email: [email protected]
Age: 29
Hired: 2019-01-03
Active
----
James White
Email: [email protected]
Age: 24
Hired: 2021-02-04
Active
----
Harold Ishida
Email: [email protected]
Age: 52
Hired: 2002-03-06
Out of Office
----
Scarlett Winter
Email: [email protected]
Age: 22
Hired: 2021-04-07
Active
----
Emily Vill
Email: [email protected]
Age: 27
Hired: 2019-06-09
Active
----
Mary Park
Email: [email protected]
Age: 30
Hired: 2021-08-11
Active
----
Вы видите, что все добавленные нами в базу данных сотрудники правильно отображаются.
Выйдите из оболочки Flask:
Затем вы создадите маршрут Flask для отображения сотрудников. Откройте app.py для редактирования:
Добавьте следующий маршрут в конце файла:
Сохраните и закройте файл.
Этот код запрашивает всех сотрудников, отображает шаблон index.html и передает ему полученных сотрудников.
Создайте каталог шаблонов и базовый шаблон:
Добавьте следующее в base.html:
Сохраните и закройте файл.
Здесь вы используете блок заголовка и добавляете некоторое оформление CSS. Вы добавляете навигационную панель с двумя элементами: один для главной страницы и один для неактивной страницы “О нас”. Эта навигационная панель будет повторно использоваться во всем приложении в шаблонах, которые наследуются от этого базового шаблона. Блок содержимого будет заменен содержимым каждой страницы. Для получения дополнительной информации о шаблонах посмотрите Как использовать шаблоны в приложении Flask.
Затем откройте новый шаблон index.html, который вы рендерили в app.py:
Добавьте следующий код в файл:
Здесь вы выполняете цикл по сотрудникам и отображаете информацию о каждом сотруднике. Если сотрудник активен, вы добавляете метку (Активный), в противном случае вы отображаете метку (Вне офиса).
Сохраните и закройте файл.
Пока находитесь в каталоге вашего flask_app с активированной виртуальной средой, сообщите Flask о приложении (app.py в данном случае), используя переменную среды FLASK_APP. Затем установите переменную среды FLASK_ENV в development, чтобы запустить приложение в режиме разработки и получить доступ к отладчику. Для получения дополнительной информации о отладчике Flask см. Как обрабатывать ошибки в приложении Flask. Используйте следующие команды для этого:
Затем запустите приложение:
После запуска сервера разработки перейдите по следующему URL в вашем браузере:
http://127.0.0.1:5000/
Вы увидите сотрудников, которых вы добавили в базу данных, на странице, аналогичной следующей:
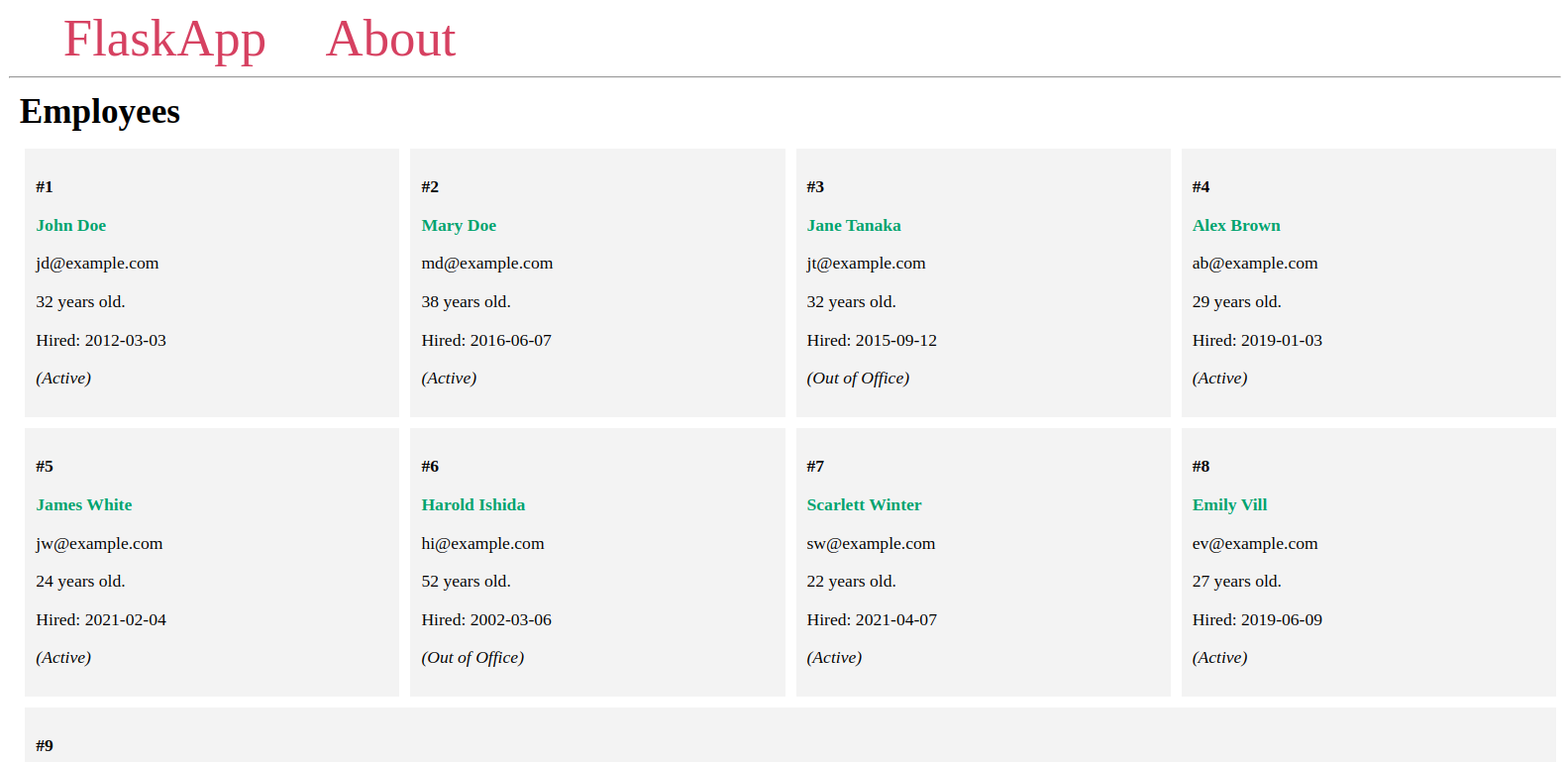
Оставьте сервер запущенным, откройте еще один терминал и перейдите к следующему шагу.
Вы отобразили сотрудников, которые есть в вашей базе данных, на главной странице. Далее вы будете использовать оболочку Flask для запроса сотрудников с использованием различных методов.
Шаг 2 — Запрос записей
На этом этапе вы будете использовать оболочку Flask для запроса записей, фильтрации и извлечения результатов с использованием нескольких методов и условий.
С активированной средой программирования установите переменные FLASK_APP и FLASK_ENV и откройте оболочку Flask:
Импортируйте объект db и модель Employee:
Получение всех записей
Как вы видели на предыдущем этапе, вы можете использовать метод all() атрибута query, чтобы получить все записи в таблице:
Вывод будет представлять собой список объектов, представляющих всех сотрудников:
Output
[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>, <Employee Alex Brown>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>, <Employee Emily Vill>, <Employee Mary Park>]
Получение первой записи
Аналогично, вы можете использовать метод first(), чтобы получить первую запись:
Вывод будет объектом, содержащим данные первого сотрудника:
Output<Employee John Doe>
Получение записи по идентификатору
В большинстве таблиц баз данных записи идентифицируются уникальным идентификатором. Flask-SQLAlchemy позволяет извлекать запись, используя ее идентификатор, с помощью метода get():
Output<Employee James White> | ID: 5
<Employee Jane Tanaka> | ID: 3
Получение записи или нескольких записей по значению столбца
Чтобы получить запись, используя значение одного из её столбцов, используйте метод filter_by(). Например, чтобы получить запись, используя её значение ID, аналогично методу get():
Output<Employee John Doe>
Вы используете first(), потому что filter_by() может вернуть несколько результатов.
Примечание: Для получения записи по ID лучше использовать метод get().
В качестве другого примера, вы можете получить сотрудника по его возрасту:
Output<Employee Harold Ishida>
Для примера, где результат запроса содержит более одной совпадающей записи, используйте столбец firstname и имя Mary, которое является общим для двух сотрудников:
Output[<Employee Mary Doe>, <Employee Mary Park>]
Здесь вы используете all(), чтобы получить полный список. Вы также можете использовать first(), чтобы получить только первый результат:
Output<Employee Mary Doe>
Вы получили записи по значениям столбцов. Далее вы будете запрашивать вашу таблицу, используя логические условия.
Шаг 3 — Фильтрация записей с использованием логических условий
В сложных полнофункциональных веб-приложениях часто требуется выполнять запросы к записям из базы данных с использованием сложных условий, таких как выбор сотрудников на основе комбинации условий, учитывающих их местоположение, доступность, роль и обязанности. На этом этапе вы получите практику в использовании условных операторов. Вы будете использовать метод filter() атрибута query для фильтрации результатов запроса с использованием логических условий с разными операторами. Например, вы можете использовать логические операторы для получения списка сотрудников, которые в настоящее время отсутствуют в офисе, или сотрудников, которым пора повысить, а также, возможно, предоставить календарь отпусков сотрудников и т. д.
Равно
Самый простой логический оператор, который вы можете использовать, это оператор равенства ==, который ведет себя аналогично filter_by(). Например, чтобы получить все записи, где значение столбца firstname равно Mary, вы можете использовать метод filter() следующим образом:
Здесь вы используете синтаксис Model.column == value в качестве аргумента для метода filter(). Метод filter_by() является сокращением этого синтаксиса.
Результат такой же, как результат метода filter_by() с тем же условием:
Output[<Employee Mary Doe>, <Employee Mary Park>]
Как и filter_by(), вы также можете использовать метод first() для получения первого результата:
Output<Employee Mary Doe>
Не равно
Метод filter() позволяет использовать оператор != в Python для получения записей. Например, чтобы получить список сотрудников, не находящихся в офисе, можно использовать следующий подход:
Output[<Employee Jane Tanaka>, <Employee Harold Ishida>]
Здесь используется условие Employee.active != True для фильтрации результатов.
Меньше
Можно использовать оператор <, чтобы получить запись, где значение заданного столбца меньше заданного значения. Например, чтобы получить список сотрудников младше 32 лет:
Output
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
Используйте оператор <= для записей, которые меньше или равны заданному значению. Например, чтобы включить сотрудников в возрасте 32 лет в предыдущий запрос:
Output
John Doe
Age: 32
----
Jane Tanaka
Age: 32
----
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
Больше
Аналогично оператор > получает запись, где значение заданного столбца больше заданного значения. Например, чтобы получить сотрудников старше 32 лет:
OutputMary Doe
Age: 38
----
Harold Ishida
Age: 52
----
И оператор >= предназначен для записей, которые больше или равны заданному значению. Например, можно снова включить сотрудников в возрасте 32 года в предыдущий запрос:
Output
John Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Harold Ishida
Age: 52
----
В
SQLAlchemy также предоставляется способ получить записи, где значение столбца соответствует значению из заданного списка значений с использованием метода in_() на столбце, вот так:
Output[<Employee Mary Doe>, <Employee Alex Brown>, <Employee Emily Vill>, <Employee Mary Park>]
Здесь вы используете условие с синтаксисом Модель.столбец.in_(перечисляемый), где перечисляемый может быть любым типом объекта, по которому можно выполнить итерацию. В качестве другого примера вы можете использовать функцию range() в Python для получения сотрудников определенного возрастного диапазона. Следующий запрос получает всех сотрудников, которые находятся в свои тридцать лет.
OutputJohn Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Mary Park
Age: 30
----
Не в
Аналогично методу in_(), вы можете использовать метод not_in() для получения записей, где значение столбца не находится в заданном перечисляемом:
Output
[<Employee John Doe>, <Employee Jane Tanaka>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>]
Здесь вы получаете всех сотрудников, кроме тех, у которых имя из списка names.
И
Вы можете объединить несколько условий с помощью функции db.and_(), которая работает подобно оператору and в Python.
Например, предположим, вы хотите получить всех сотрудников, которым 32 года, и которые в настоящее время активны. Сначала вы можете проверить, кто имеет 32 года, используя метод filter_by() (вы также можете использовать filter(), если хотите):
Output<Employee John Doe>
Age: 32
Active: True
-----
<Employee Jane Tanaka>
Age: 32
Active: False
-----
Здесь вы видите, что Джон и Джейн – это сотрудники, которым 32 года. Джон активен, а Джейн в отпуске.
Чтобы получить сотрудников, которым 32 года и активных, вы будете использовать два условия с методом filter():
Employee.age == 32Employee.active == True
Чтобы объединить эти два условия, используйте функцию db.and_() следующим образом:
Output[<Employee John Doe>]
Здесь вы используете синтаксис filter(db.and_(condition1, condition2)).
Использование all() на запросе возвращает список всех записей, которые соответствуют двум условиям. Вы можете использовать метод first(), чтобы получить первый результат:
Output<Employee John Doe>
Для более сложного примера вы можете использовать db.and_() с функцией date(), чтобы получить сотрудников, нанятых в определенном временном промежутке. В этом примере вы получаете всех сотрудников, нанятых в 2019 году:
Output<Employee Alex Brown> | Hired: 2019-01-03
<Employee Emily Vill> | Hired: 2019-06-09
Здесь вы импортируете функцию date(), и фильтруете результаты, используя функцию db.and_() для объединения следующих двух условий:
Employee.hire_date >= date(year=2019, month=1, day=1): ЭтоTrueдля сотрудников, нанятых первого января 2019 года или позже.Employee.hire_date < date(year=2020, month=1, day=1): Это верно для сотрудников, нанятых до первого января 2020 года.
Комбинируя два условия, получаем сотрудников, нанятых с первого дня 2019 года и до первого дня 2020 года.
Или
Подобно функции db.and_(), функция db.or_() объединяет два условия и ведет себя как оператор or в Python. Она извлекает все записи, которые соответствуют одному из двух условий. Например, чтобы получить сотрудников в возрасте 32 или 52 года, вы можете объединить два условия с помощью функции db.or_() следующим образом:
Output<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
<Employee Harold Ishida> | Age: 52
Также вы можете использовать методы startswith() и endswith() для строковых значений в условиях, которые передаете методу filter(). Например, чтобы получить всех сотрудников, чье имя начинается со строки 'M' и тех, у кого фамилия заканчивается строкой 'e':
Output<Employee John Doe>
<Employee Mary Doe>
<Employee James White>
<Employee Mary Park>
Здесь вы объединяете следующие два условия:
Employee.firstname.startswith('M'): Соответствует сотрудникам с именем, начинающимся с'M'.Employee.lastname.endswith('e'): Соответствует сотрудникам с фамилией, заканчивающейся на'e'.
Теперь вы можете фильтровать результаты запроса, используя логические условия в ваших приложениях Flask-SQLAlchemy. Затем вы упорядочите, ограничите и подсчитаете результаты, полученные из базы данных.
Шаг 4 — Упорядочивание, ограничение и подсчет результатов
В веб-приложениях часто требуется упорядочивать записи при их отображении. Например, у вас может быть страница для отображения последних наймов в каждом отделе, чтобы остальная часть команды узнала о новых наймах, или вы можете упорядочить сотрудников, отображая самых старых наймов первыми, чтобы выделить долгожителей. В некоторых случаях вам также потребуется ограничить результаты, например, отображая только последние три найма на небольшой боковой панели. И часто вам нужно подсчитать результаты запроса, например, чтобы отобразить количество сотрудников, которые в настоящее время активны. На этом этапе вы узнаете, как упорядочить, ограничить и подсчитать результаты.
Упорядочивание результатов
Для упорядочивания результатов с использованием значений определенного столбца используйте метод order_by(). Например, чтобы упорядочить результаты по имени сотрудника:
Output[<Employee Alex Brown>, <Employee Emily Vill>, <Employee Harold Ishida>, <Employee James White>, <Employee Jane Tanaka>, <Employee John Doe>, <Employee Mary Doe>, <Employee Mary Park>, <Employee Scarlett Winter>]
Как показывает вывод, результаты упорядочены алфавитно по имени сотрудника.
Вы можете упорядочивать по другим столбцам. Например, вы можете использовать фамилию для упорядочивания сотрудников:
Output[<Employee Alex Brown>, <Employee John Doe>, <Employee Mary Doe>, <Employee Harold Ishida>, <Employee Mary Park>, <Employee Jane Tanaka>, <Employee Emily Vill>, <Employee James White>, <Employee Scarlett Winter>]
Вы также можете упорядочить сотрудников по дате их приема на работу:
Output
Harold Ishida 2002-03-06
John Doe 2012-03-03
Jane Tanaka 2015-09-12
Mary Doe 2016-06-07
Alex Brown 2019-01-03
Emily Vill 2019-06-09
James White 2021-02-04
Scarlett Winter 2021-04-07
Mary Park 2021-08-11
Как показывает вывод, это упорядочивает результаты с наиболее ранним наймом до последнего найма. Чтобы изменить порядок и сделать его убывающим от последнего найма до самого раннего, используйте метод desc() следующим образом:
OutputMary Park 2021-08-11
Scarlett Winter 2021-04-07
James White 2021-02-04
Emily Vill 2019-06-09
Alex Brown 2019-01-03
Mary Doe 2016-06-07
Jane Tanaka 2015-09-12
John Doe 2012-03-03
Harold Ishida 2002-03-06
Вы также можете объединить метод order_by() с методом filter(), чтобы упорядочить отфильтрованные результаты. В следующем примере получаются все сотрудники, нанятые в 2021 году, и упорядочиваются по возрасту:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
Mary Park 2021-08-11 | Age 30
Здесь вы используете функцию db.and_() с двумя условиями: Employee.hire_date >= date(year=2021, month=1, day=1) для сотрудников, нанятых с 1 января 2021 года или позже, и Employee.hire_date < date(year=2022, month=1, day=1) для сотрудников, нанятых до 1 января 2022 года. Затем используется метод order_by(), чтобы упорядочить полученных сотрудников по их возрасту.
Ограничение результатов
В большинстве реальных случаев, при запросе таблицы базы данных, вы можете получить до миллионов совпадающих результатов, и иногда необходимо ограничить результаты до определенного числа. Чтобы ограничить результаты в Flask-SQLAlchemy, вы можете использовать метод limit(). В следующем примере запрашивается таблица employee и возвращаются только первые три совпадающих результата:
Output[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>]
Вы можете использовать limit() с другими методами, такими как filter и order_by. Например, вы можете получить последних двух нанятых сотрудников в 2021 году, используя метод limit() следующим образом:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
Здесь вы используете тот же запрос, что и в предыдущем разделе, с дополнительным вызовом метода limit(2).
Подсчет результатов
Чтобы подсчитать количество результатов запроса, вы можете использовать метод count(). Например, чтобы получить количество сотрудников, которые в настоящее время находятся в базе данных:
Output9
Вы можете объединить метод count() с другими методами запроса, аналогичными limit(). Например, чтобы получить количество сотрудников, нанятых в 2021 году:
Output3
Здесь вы используете тот же запрос, что и ранее, чтобы получить всех сотрудников, нанятых в 2021 году. И вы используете count(), чтобы получить количество записей, которое равно 3.
Вы упорядочили, ограничили и подсчитали результаты запроса в Flask-SQLAlchemy. Далее вы узнаете, как разбить результаты запроса на несколько страниц и как создать систему пагинации в ваших приложениях Flask.
Шаг 5 — Отображение длинных списков записей на нескольких страницах
На этом этапе вы измените основной маршрут, чтобы индексная страница отображала сотрудников на нескольких страницах, что сделает навигацию по списку сотрудников более удобной.
Сначала вы используете оболочку Flask для демонстрации того, как использовать функцию пагинации в Flask-SQLAlchemy. Откройте оболочку Flask, если еще этого не сделали:
Предположим, вы хотите разделить записи о сотрудниках в вашей таблице на несколько страниц, по два элемента на страницу. Вы можете сделать это, используя метод запроса paginate() следующим образом:
Output<flask_sqlalchemy.Pagination object at 0x7f1dbee7af80>
[<Employee John Doe>, <Employee Mary Doe>]
Вы используете параметр page метода запроса paginate(), чтобы указать страницу, к которой хотите получить доступ, которая в данном случае является первой страницей. Параметр per_page указывает количество элементов на каждой странице. В этом случае устанавливается значение 2, чтобы на каждой странице было по два элемента.
Переменная page1 здесь является объектом пагинации, который дает вам доступ к атрибутам и методам, которые вы будете использовать для управления вашей пагинацией.
Вы получаете доступ к элементам страницы, используя атрибут items.
Для доступа к следующей странице можно использовать метод next() объекта пагинации, возвращаемый результат также является объектом пагинации:
Output[<Employee Jane Tanaka>, <Employee Alex Brown>]
<flask_sqlalchemy.Pagination object at 0x7f1dbee799c0>
Вы можете получить объект пагинации для предыдущей страницы, используя метод prev(). В следующем примере вы получаете объект пагинации для четвертой страницы, затем получаете объект пагинации для ее предыдущей страницы, которая является страницей 3:
Output[<Employee Scarlett Winter>, <Employee Emily Vill>]
[<Employee James White>, <Employee Harold Ishida>]
Вы можете получить доступ к номеру текущей страницы, используя атрибут page следующим образом:
Output1
2
Для получения общего количества страниц используйте атрибут pages объекта пагинации. В следующем примере как page1.pages, так и page2.pages возвращают одно и то же значение, потому что общее количество страниц постоянно:
Output5
5
Для общего числа элементов используйте атрибут total объекта пагинации:
Output9
9
Здесь, поскольку запрашиваются все сотрудники, общее количество элементов в пагинации равно 9, потому что в базе данных девять сотрудников.
Вот некоторые другие атрибуты, которыми обладают объекты пагинации:
prev_num: Номер предыдущей страницы.next_num: Номер следующей страницы.has_next:True, если есть следующая страница.has_prev:True, если есть предыдущая страница.per_page: Количество элементов на странице.
У объекта пагинации также есть метод iter_pages(), через который можно выполнить цикл по номерам страниц. Например, можно вывести все номера страниц так:
Output1
2
3
4
5
Ниже приведено демонстрационное использование объекта пагинации и метода iter_pages() для доступа ко всем страницам и их элементам:
Output
PAGE 1
-
[<Employee John Doe>, <Employee Mary Doe>]
--------------------
PAGE 2
-
[<Employee Jane Tanaka>, <Employee Alex Brown>]
--------------------
PAGE 3
-
[<Employee James White>, <Employee Harold Ishida>]
--------------------
PAGE 4
-
[<Employee Scarlett Winter>, <Employee Emily Vill>]
--------------------
PAGE 5
-
[<Employee Mary Park>]
--------------------
Здесь создается объект пагинации, начиная с первой страницы. Цикл проходит по страницам с помощью цикла for с методом пагинации iter_pages(). Выводится номер страницы и элементы страницы, а объект pagination устанавливается равным объекту пагинации его следующей страницы с помощью метода next().
Вы также можете использовать методы filter() и order_by() с методом paginate() для разбиения отфильтрованных и упорядоченных результатов запроса на страницы. Например, вы можете получить сотрудников старше тридцати лет, упорядочив результаты по возрасту и разбить результаты на страницы следующим образом:
OutputPAGE 1
-
<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
--------------------
PAGE 2
-
<Employee Mary Doe> | Age: 38
<Employee Harold Ishida> | Age: 52
--------------------
Теперь, когда у вас есть прочное понимание того, как работает разбиение на страницы в Flask-SQLAlchemy, вы отредактируете главную страницу вашего приложения, чтобы отображать сотрудников на нескольких страницах для более удобной навигации.
Выйдите из оболочки Flask:
Для доступа к разным страницам вы будете использовать параметры URL, также известные как строки запроса URL, которые представляют собой способ передачи информации в приложение через URL. Параметры передаются в приложение в URL после символа ?. Например, чтобы передать параметр page с разными значениями, вы можете использовать следующие URL:
http://127.0.0.1:5000/?page=1
http://127.0.0.1:5000/?page=3
Здесь первый URL передает значение 1 параметру URL page. Второй URL передает значение 3 тому же параметру.
Откройте файл app.py:
Отредактируйте маршрут индекса следующим образом:
Здесь вы получаете значение параметра URL page, используя объект request.args и его метод get(). Например, /?page=1 получит значение 1 из параметра URL page. Вы передаете 1 в качестве значения по умолчанию, и вы передаете тип Python int в качестве аргумента для параметра type, чтобы убедиться, что значение является целым числом.
Затем вы создаете объект pagination, упорядочивая результаты запроса по имени. Вы передаете значение параметра URL page методу paginate() и разбиваете результаты на два элемента на страницу, передавая значение 2 параметру per_page.
Наконец, вы передаете сконструированный объект pagination в шаблон index.html, который будет отображен.
Сохраните и закройте файл.
Затем отредактируйте шаблон index.html, чтобы отображать элементы пагинации:
Измените содержимое тега div, добавив заголовок h2, указывающий текущую страницу, и измените цикл for, чтобы пройти по объекту pagination.items вместо объекта employees, который больше недоступен:
Сохраните и закройте файл.
Если вы еще этого не сделали, установите переменные среды FLASK_APP и FLASK_ENV, а затем запустите сервер разработки:
Теперь перейдите на главную страницу с разными значениями параметра URL page:
http://127.0.0.1:5000/
http://127.0.0.1:5000/?page=2
http://127.0.0.1:5000/?page=4
http://127.0.0.1:5000/?page=19
Вы увидите различные страницы с двумя элементами на каждой и различные элементы на каждой странице, как вы уже видели ранее в оболочке Flask.
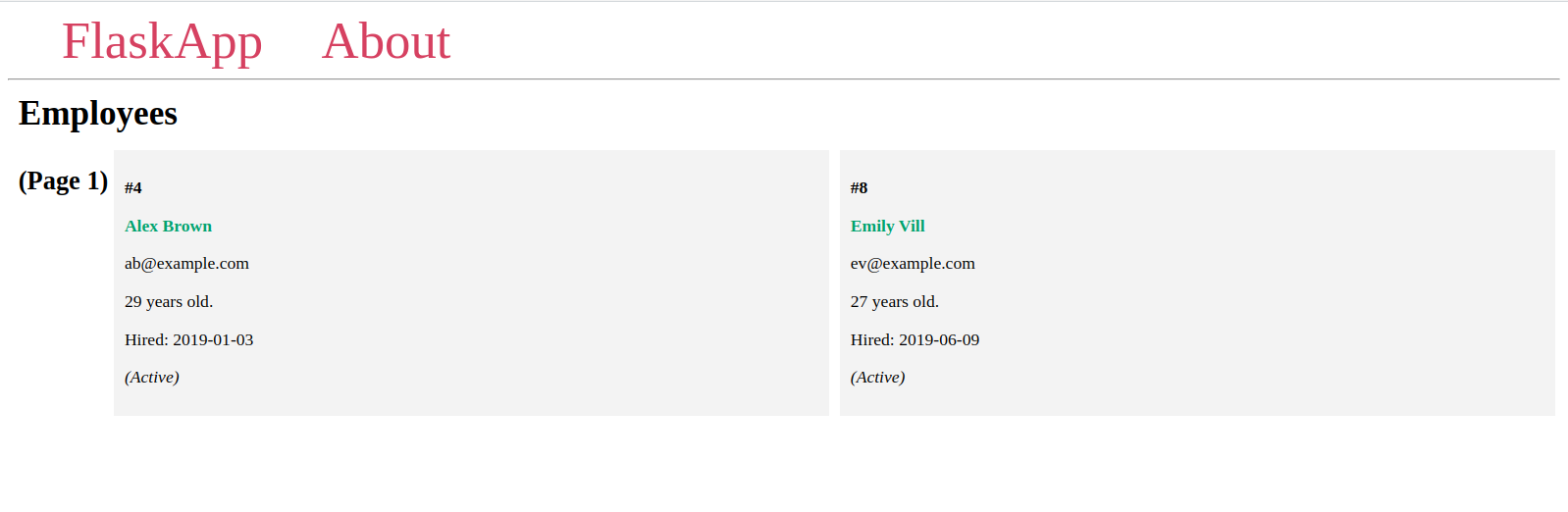
Если указанный номер страницы не существует, вы получите ошибку HTTP 404 Not Found, что является случаем для последнего URL в предыдущем списке URL.
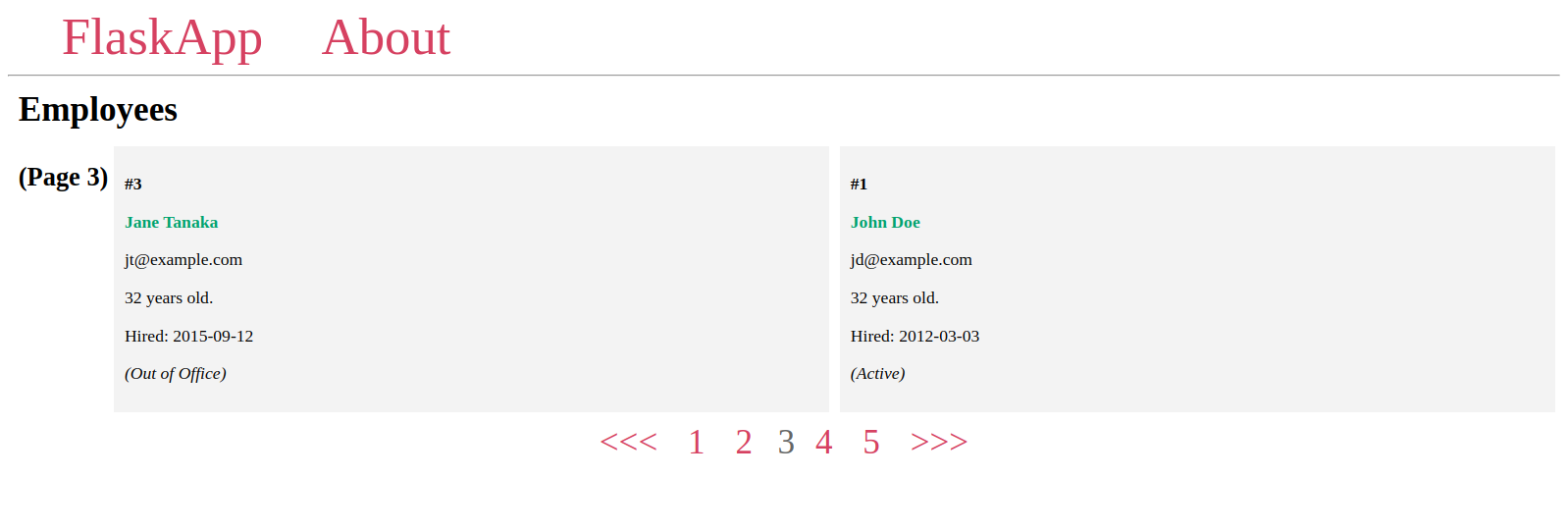
Затем вы создадите виджет пагинации для навигации между страницами, используя несколько атрибутов и методов объекта пагинации для отображения всех номеров страниц, каждый номер будет ссылкой на свою отдельную страницу, а также кнопку <<< для перехода назад, если текущая страница имеет предыдущую страницу, и кнопку >>> для перехода на следующую страницу, если она существует.
Виджет пагинации будет выглядеть следующим образом:

Чтобы добавить его, откройте файл index.html:
Отредактируйте файл, добавив следующий выделенный тег div ниже тега div контента:
Сохраните и закройте файл.
Здесь вы используете условие if pagination.has_prev для добавления ссылки <<< на предыдущую страницу, если текущая страница не является первой. Вы ссылаетесь на предыдущую страницу, используя вызов функции url_for('index', page=pagination.prev_num), в которой ссылаетесь на функцию представления индекса, передавая значение pagination.prev_num в параметр URL page.
Чтобы отобразить ссылки на все доступные номера страниц, вы проходите циклом по элементам метода pagination.iter_pages(), который предоставляет вам номер страницы на каждой итерации.
Вы используете условие if pagination.page != number для проверки того, не совпадает ли текущий номер страницы с номером в текущей итерации. Если условие истинно, вы создаете ссылку на страницу, чтобы пользователь мог изменить текущую страницу на другую. В противном случае, если текущая страница совпадает с номером итерации, вы отображаете номер без ссылки. Это позволяет пользователям знать номер текущей страницы в виджете пагинации.
Наконец, вы используете условие pagination.has_next для проверки того, имеет ли текущая страница следующую страницу, в таком случае вы создаете ссылку на нее, используя вызов url_for('index', page=pagination.next_num) и ссылку >>>.
Перейдите на главную страницу в вашем браузере: http://127.0.0.1:5000/
Вы увидите, что виджет пагинации полностью функционален:
Здесь вы используете >>> для перехода на следующую страницу и <<< для предыдущей страницы, но вы также можете использовать любые другие символы на ваш вкус, такие как > и < или изображения в тегах <img>.
Вы отобразили сотрудников на нескольких страницах и научились обрабатывать пагинацию в Flask-SQLAlchemy. Теперь вы можете использовать свой виджет пагинации в других приложениях Flask, которые вы создаете.
Заключение
Вы использовали Flask-SQLAlchemy для создания системы управления сотрудниками. Вы запрашивали таблицу и фильтровали результаты на основе значений столбцов и простых и сложных логических условий. Вы упорядочивали, подсчитывали и ограничивали результаты запроса. И вы создали систему пагинации для отображения определенного количества записей на каждой странице в вашем веб-приложении и перемещения между страницами.
Вы можете использовать то, что вы узнали в этом руководстве, совместно с концепциями, объясненными в некоторых наших других учебниках Flask-SQLAlchemy, чтобы добавить больше функциональности в вашу систему управления сотрудниками:
- Как использовать Flask-SQLAlchemy для взаимодействия с базами данных в приложении Flask, чтобы узнать, как добавлять, редактировать или удалять сотрудников.
- Как использовать отношения один-ко-многим с базами данных Flask-SQLAlchemy, чтобы узнать, как использовать отношения один-ко-многим для создания таблицы отделов, чтобы связать каждого сотрудника с отделом, к которому он принадлежит.
- Как использовать отношения многие-ко-многим в базе данных с помощью Flask-SQLAlchemy, чтобы узнать, как использовать отношения многие-ко-многим для создания таблицы
tasksи связать ее с таблицейemployee, где у каждого сотрудника много задач, и каждая задача назначена нескольким сотрудникам.
Если вы хотите узнать больше о Flask, ознакомьтесь с другими учебными пособиями в серии Как создавать веб-приложения с помощью Flask.