













Введение
Организации, которые все чаще переходят на использование Kubernetes для управления своими контейнерами, нуждаются в решении для мониторинга состояния своей распределенной системы. По этой причине появляется Prometheus – мощный инструмент с открытым исходным кодом для мониторинга контейнерных приложений в вашем пространстве K8s.
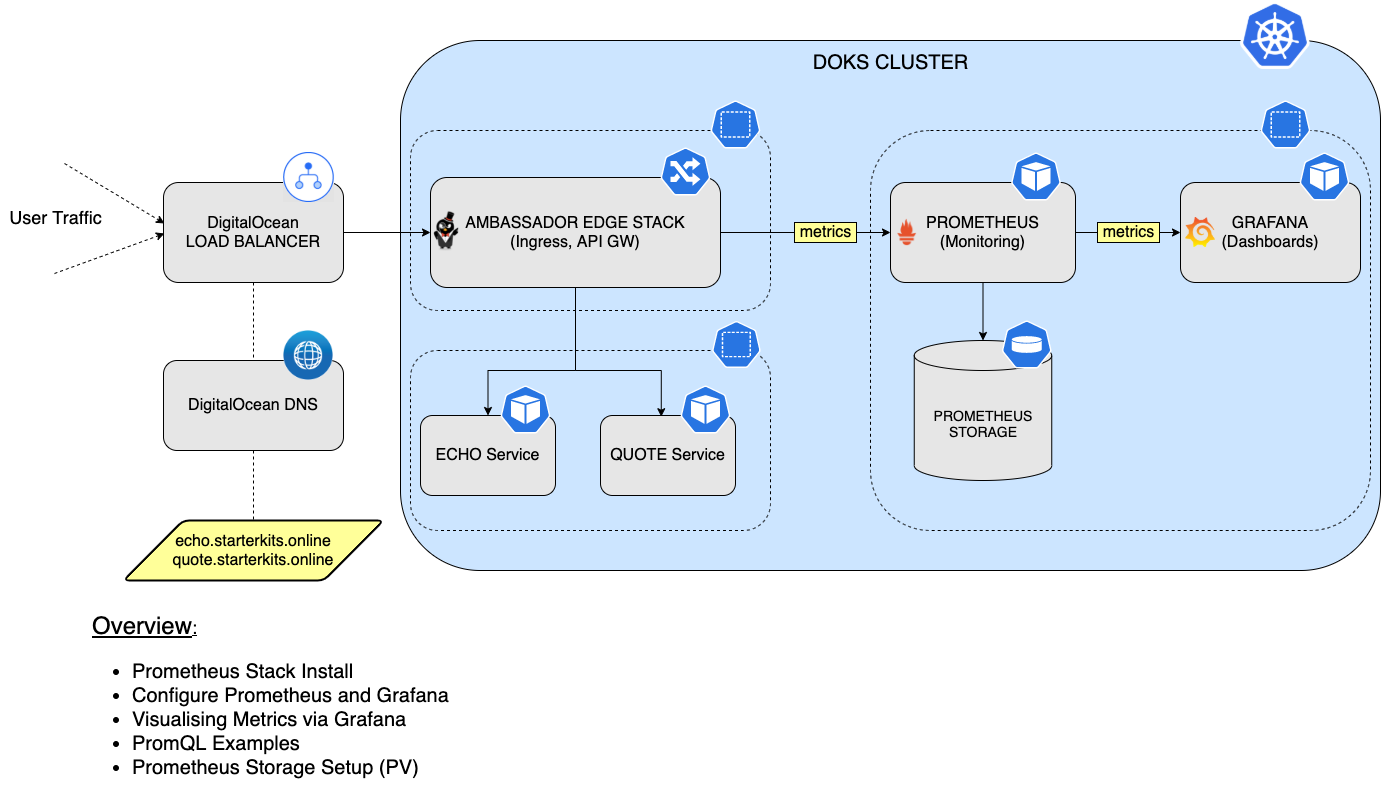
В этом руководстве вы узнаете, как установить и настроить стек Prometheus для мониторинга всех подов вашего кластера DOKS, а также метрики состояния кластера Kubernetes. Затем вы подключите Prometheus к Grafana для визуализации всех метрик и выполнения запросов с использованием языка PromQL. Наконец, вы настроите постоянное хранилище для вашего экземпляра Prometheus, чтобы сохранить все данные метрик кластера DOKS и приложений.
Содержание
- Предварительные требования
- Шаг 1 – Установка стека Prometheus
- Шаг 2 – Настройка Prometheus и Grafana
- Шаг 3 – PromQL (Prometheus Query Language)
- Шаг 4 – Визуализация метрик с помощью Grafana
- Шаг 5 – Настройка постоянного хранилища для Prometheus
- Шаг 6 – Настройка постоянного хранилища для Grafana
- Заключение
Предварительные требования
Для завершения этого руководства вам понадобятся:
- A Git client to clone the Starter Kit repository.
- Helm для управления релизами и обновлений стека Prometheus.
- Kubectl для взаимодействия с Kubernetes.
- Curl для тестирования примеров (веб-приложений).
- Пример приложения Emojivoto, развернутого в кластере. Пожалуйста, следуйте инструкциям в файле README его репозитория.
Убедитесь, что контекст kubectl настроен на ваш кластер Kubernetes. Обратитесь к Шагу 3 – Создание кластера DOKS из руководства по установке DOKS.
Шаг 1 – Установка стека Prometheus
На этом этапе вы установите стек kube-prometheus, который является определенным набором инструментов для мониторинга Kubernetes. Он включает в себя оператор Prometheus, kube-state-metrics, готовые манифесты, экспортеры узлов, API метрик, менеджер оповещений и Grafana.
Вы собираетесь использовать менеджер пакетов Helm для выполнения этой задачи. Helm-диаграмма доступна для изучения здесь.
Сначала клонируйте репозиторий Starter Kit и перейдите в каталог локальной копии.
Затем добавьте репозиторий Helm и перечислите доступные диаграммы:
Вывод выглядит аналогично следующему:
NAME CHART VERSION APP VERSION DESCRIPTION
prometheus-community/alertmanager 0.18.1 v0.23.0 The Alertmanager handles alerts sent by client ...
prometheus-community/kube-prometheus-stack 35.5.1 0.56.3 kube-prometheus-stack collects Kubernetes manif...
...
Интересующая нас диаграмма – prometheus-community/kube-prometheus-stack, которая установит Prometheus, Promtail, Alertmanager и Grafana на кластер. Пожалуйста, посетите страницу kube-prometheus-stack для получения более подробной информации об этой диаграмме.
Затем откройте и осмотрите файл 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml, предоставленный в репозитории Starter Kit, с использованием выбранного вами редактора (предпочтительно с поддержкой проверки YAML). По умолчанию метрики kubeSched и etcd отключены – эти компоненты управляются DOKS и не доступны для Prometheus. Обратите внимание, что хранение установлено как emptyDir. Это означает, что хранилище будет удалено, если перезапустятся поды Prometheus (вы исправите это позже в разделе Настройка постоянного хранилища для Prometheus).
[ДОПОЛНИТЕЛЬНО] Если вы следовали – Шаг 4 – Добавление выделенного узла для наблюдаемости руководству по настройке управляемого кластера Kubernetes в DigitalOcean, вам потребуется отредактировать файл 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml, предоставленный в репозитории Starter Kit, и раскомментировать разделы affinity для Grafana и Prometheus.
Объяснения для указанной выше конфигурации:
preferredDuringSchedulingIgnoredDuringExecution– планировщик пытается найти узел, соответствующий правилу. Если подходящий узел недоступен, планировщик все равно запланирует под.preference.matchExpressions– селектор, используемый для сопоставления конкретного узла на основе критериев. В приведенном выше примере планировщику указывается размещать рабочие нагрузки (например, поды) на узлах, помеченных с использованием ключа –preferredи значением –observability.
Наконец, установите kube-prometheus-stack, используя Helm:
A specific version of the Helm chart is used. In this case 35.5.1 was picked, which maps to the 0.56.3 version of the application (see output from Step 2.). It’s a good practice to lock on a specific version. This helps to have predictable results and allows versioning control via Git.
–create-namespace \
Теперь проверьте статус Helm-релиза стека Prometheus:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prom-stack monitoring 1 2022-06-07 09:52:53.795003 +0300 EEST deployed kube-prometheus-stack-35.5.1 0.56.3
Вывод выглядит аналогично следующему. Обратите внимание на значение столбца STATUS – должно быть deployed.
Посмотрите, какие ресурсы Kubernetes доступны для Prometheus:
NAME READY STATUS RESTARTS AGE
pod/alertmanager-kube-prom-stack-kube-prome-alertmanager-0 2/2 Running 0 3m3s
pod/kube-prom-stack-grafana-8457cd64c4-ct5wn 2/2 Running 0 3m5s
pod/kube-prom-stack-kube-prome-operator-6f8b64b6f-7hkn7 1/1 Running 0 3m5s
pod/kube-prom-stack-kube-state-metrics-5f46fffbc8-mdgfs 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-gcb8s 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-kc5wz 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-qn92d 1/1 Running 0 3m5s
pod/prometheus-kube-prom-stack-kube-prome-prometheus-0 2/2 Running 0 3m3s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 3m3s
service/kube-prom-stack-grafana ClusterIP 10.245.147.83 <none> 80/TCP 3m5s
service/kube-prom-stack-kube-prome-alertmanager ClusterIP 10.245.187.117 <none> 9093/TCP 3m5s
service/kube-prom-stack-kube-prome-operator ClusterIP 10.245.79.95 <none> 443/TCP 3m5s
service/kube-prom-stack-kube-prome-prometheus ClusterIP 10.245.86.189 <none> 9090/TCP 3m5s
service/kube-prom-stack-kube-state-metrics ClusterIP 10.245.119.83 <none> 8080/TCP 3m5s
service/kube-prom-stack-prometheus-node-exporter ClusterIP 10.245.47.175 <none> 9100/TCP 3m5s
service/prometheus-operated ClusterIP None <none> 9090/TCP 3m3s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/kube-prom-stack-prometheus-node-exporter 3 3 3 3 3 <none> 3m5s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kube-prom-stack-grafana 1/1 1 1 3m5s
deployment.apps/kube-prom-stack-kube-prome-operator 1/1 1 1 3m5s
deployment.apps/kube-prom-stack-kube-state-metrics 1/1 1 1 3m5s
NAME DESIRED CURRENT READY AGE
replicaset.apps/kube-prom-stack-grafana-8457cd64c4 1 1 1 3m5s
replicaset.apps/kube-prom-stack-kube-prome-operator-6f8b64b6f 1 1 1 3m5s
replicaset.apps/kube-prom-stack-kube-state-metrics-5f46fffbc8 1 1 1 3m5s
NAME READY AGE
statefulset.apps/alertmanager-kube-prom-stack-kube-prome-alertmanager 1/1 3m3s
statefulset.apps/prometheus-kube-prom-stack-kube-prome-prometheus 1/1 3m3s
У вас должны быть развернуты следующие ресурсы: prometheus-node-exporter, kube-prome-operator, kube-prome-alertmanager, kube-prom-stack-grafana и kube-state-metrics. Вывод выглядит примерно так:
Затем вы можете подключиться к Grafana (используя учетные данные по умолчанию: admin/prom-operator – см. файл prom-stack-values-v35.5.1), выполнив переадресацию портов на локальную машину:
Вы не должны НЕ раскрывать Grafana в публичную сеть (например, создавать отображение входа или службу с балансировкой нагрузки) с использованием default login/password.
Установка Grafana поставляется с несколькими панелями. Откройте веб-браузер по адресу localhost:3000. После входа вы можете перейти к Панели инструментов -> Просмотр и выбрать разные панели.
В следующей части вы узнаете, как настроить Prometheus для обнаружения целей мониторинга. В качестве примера будет использоваться образец приложения Emojivoto. Вы также узнаете, что такое ServiceMonitor.
Шаг 2 – Настройка Prometheus и Grafana
Вы уже развернули Prometheus и Grafana в кластере. На этом шаге вы узнаете, как использовать ServiceMonitor. ServiceMonitor является одним из предпочтительных способов указать Prometheus, как обнаружить новую цель для мониторинга.
Деплоймент Emojivoto, созданный на шаге 5 раздела Необходимые условия, предоставляет конечную точку /metrics по умолчанию на порту 8801 через сервис Kubernetes.
Затем вы узнаете о сервисах Emojivoto, отвечающих за предоставление данных метрик для Prometheus. Названия этих сервисов – emoji-svc и voting-svc (обратите внимание, что они используют пространство имен emojivoto):
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
emoji-svc ClusterIP 10.245.135.93 <none> 8080/TCP,8801/TCP 22h
voting-svc ClusterIP 10.245.164.222 <none> 8080/TCP,8801/TCP 22h
web-svc ClusterIP 10.245.61.229 <none> 80/TCP 22h
Вывод будет похож на следующий:
Затем выполните port-forward, чтобы проверить метрики:
Метрики можно визуализировать, перейдя в веб-браузере по адресу localhost или с помощью curl:
Вывод будет похож на следующий:
go_gc_duration_seconds{quantile="0"} 5.317e-05
go_gc_duration_seconds{quantile="0.25"} 0.000105305
go_gc_duration_seconds{quantile="0.5"} 0.000138168
go_gc_duration_seconds{quantile="0.75"} 0.000225651
go_gc_duration_seconds{quantile="1"} 0.016986437
go_gc_duration_seconds_sum 0.607979843
go_gc_duration_seconds_count 2097
# TYPE go_gc_duration_seconds summary
Чтобы просмотреть метрики службы voting-svc, остановите пересылку порта emoji-svc и выполните те же шаги для второй службы.
- Затем подключите Prometheus к сервису метрик Emojivoto. Существует несколько способов сделать это:
- <static_config> – позволяет указать список целей и общий набор меток для них.
- <kubernetes_sd_config> – позволяет получать цели сканирования из REST API Kubernetes и всегда оставаться синхронизированным с состоянием кластера.
Оператор Prometheus – упрощает мониторинг Prometheus внутри кластера Kubernetes с помощью CRD.
Затем вы воспользуетесь CRD ServiceMonitor, предоставляемым оператором Prometheus, чтобы определить новую цель для мониторинга.
Сначала измените каталог (если еще не сделано), куда был клонирован репозиторий Starter Kit Git:
Затем откройте файл 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml, предоставленный в репозитории Starter Kit, используя выбранный вами текстовый редактор (желательно с поддержкой проверки YAML). Пожалуйста, удалите комментарии вокруг раздела additionalServiceMonitors. Вывод будет выглядеть примерно следующим образом:
- Объяснения для указанной конфигурации:
selector -> matchExpressions– говоритServiceMonitor, какой сервис отслеживать. Он будет ориентироваться на все сервисы с меткойappи значениямиemoji-svcиvoting-svc. Метки можно получить, выполнив:kubectl get svc --show-labels -n emojivotonamespaceSelector– здесь вы хотите совпасть с пространством имен, где был развернутEmojivoto.
endpoints -> port – ссылается на порт сервиса для мониторинга.
Наконец, примените изменения с помощью Helm:
Затем, пожалуйста, проверьте, добавлена ли цель Emojivoto в Prometheus для сбора метрик. Создайте перенаправление порта для Prometheus на порт 9090:
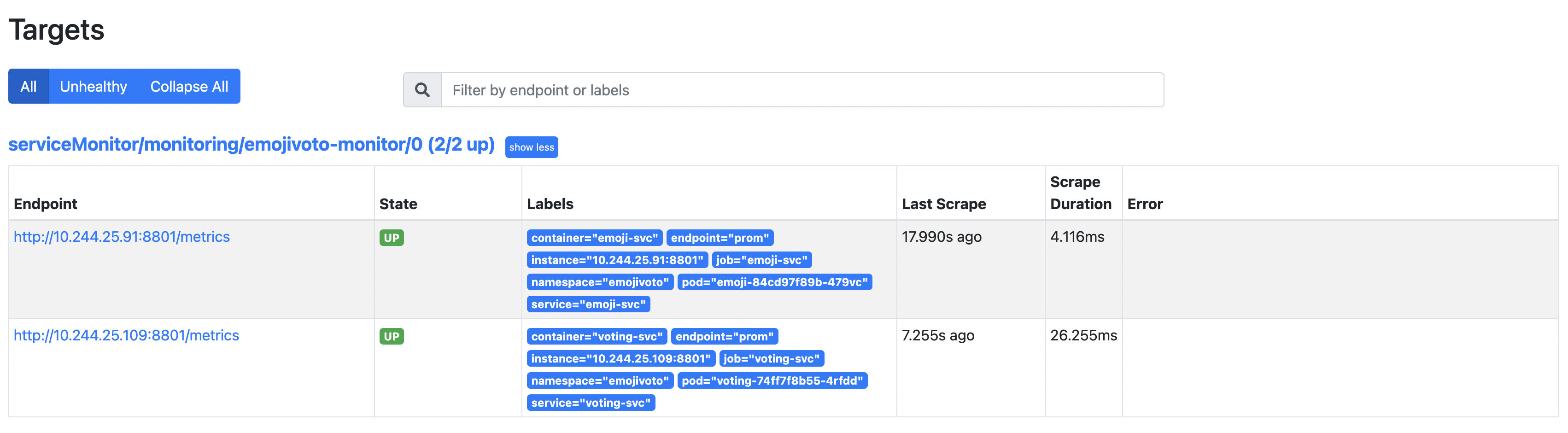
Откройте веб-браузер по адресу localhost:9090. Затем перейдите на страницу Статус -> Цели и проанализируйте результаты (обратите внимание на путь serviceMonitor/monitoring/emojivoto-monitor/0):
Обнаружено 2 записи в найденных целях, потому что развертывание Emojivoto состоит из 2 сервисов, открывающих конечную точку метрик.
На следующем этапе вы познакомитесь с PromQL вместе с несколькими простыми примерами, чтобы начать использовать и понять этот язык запросов.
Шаг 3 – PromQL (язык запросов Prometheus)
На этом этапе вы узнаете основы языка запросов Prometheus (PromQL). PromQL позволяет выполнять запросы к различным метрикам, поступающим от всех подов и приложений вашего кластера DOKS.
PromQL – это DSL или язык с ограниченной областью применения, который специально создан для Prometheus и позволяет выполнять запросы к метрикам. Общее выражение определяет окончательное значение, в то время как вложенные выражения представляют значения для аргументов и операндов. Для более подробных объяснений посетите официальную страницу PromQL.
Затем вы изучите одну из метрик Emojivoto, а именно emojivoto_votes_total, которая представляет собой общее количество голосов. Это значение счетчика, которое увеличивается с каждым запросом к конечной точке голосования Emojivoto.
Сначала создайте переадресацию порта для Prometheus на порт 9090:
Затем откройте браузер выражений.
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 20
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 17
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":basketball_man:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beach_umbrella:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beer:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 11
В поле ввода запроса вставьте emojivoto_votes_total и нажмите Enter. Вывод будет похож на:
Перейдите на домашнюю страницу приложения Emojivoto и щелкните по эмодзи “100”, чтобы проголосовать за него.
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 17
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":basketball_man:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beach_umbrella:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beer:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 11
Перейдите на страницу результатов запроса из Шага 3 и щелкните кнопку Выполнить. Вы должны увидеть, что счетчик для эмодзи “100” увеличился на один. Вывод будет выглядеть примерно следующим образом:
PromQL группирует аналогичные данные в то, что называется вектором. Как видно выше, каждый вектор имеет набор атрибутов, которые отличают его от других. Вы можете группировать результаты на основе интересующего атрибута. Например, если вам важны только запросы, поступающие от сервиса voting-svc, введите следующее в поле запроса:
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 492
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 532
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 521
Вывод будет выглядеть примерно следующим образом (обратите внимание, что он выбирает только результаты, соответствующие вашим критериям):
Выше приведенный результат показывает общее количество запросов для каждого Pod из развертывания Emojivoto, который генерирует метрики (которых 2).
Это всего лишь очень простое введение в то, что такое PromQL и что он способен делать. Но он может делать гораздо больше, например, подсчитывать метрики, вычислять скорость за предопределенный интервал и т. д. Пожалуйста, посетите официальную страницу PromQL для получения более подробной информации о возможностях этого языка.
На следующем этапе вы узнаете, как использовать Grafana для визуализации метрик для примерного приложения Emojivoto.
Шаг 4 – Визуализация метрик с помощью Grafana
Хотя у Prometheus есть некоторая встроенная поддержка для визуализации данных, лучший способ сделать это – через Grafana, который является платформой с открытым исходным кодом для мониторинга и наблюдаемости, позволяющей визуализировать и исследовать состояние вашего кластера.
Официальная страница описывается как способную:
Запрашивать, визуализировать, создавать предупреждения и понимать ваши данные независимо от того, где они хранятся.
Нет необходимости выполнять дополнительные шаги для установки Grafana, потому что Шаг 1 – Установка стека Prometheus установил Grafana для вас. Все, что вам нужно сделать, – это прокинуть порт, как показано ниже, и немедленно получить доступ к панелям мониторинга (стандартные учетные данные: admin/prom-monitor):
Чтобы увидеть все метрики Emojivoto, вы собираетесь использовать одну из установленных по умолчанию панелей мониторинга из Grafana.
Перейдите в раздел Панели мониторинга Grafana.
Затем найдите и перейдите на панель мониторинга General/Kubernetes/Compute Resources/Namespace(Pods).
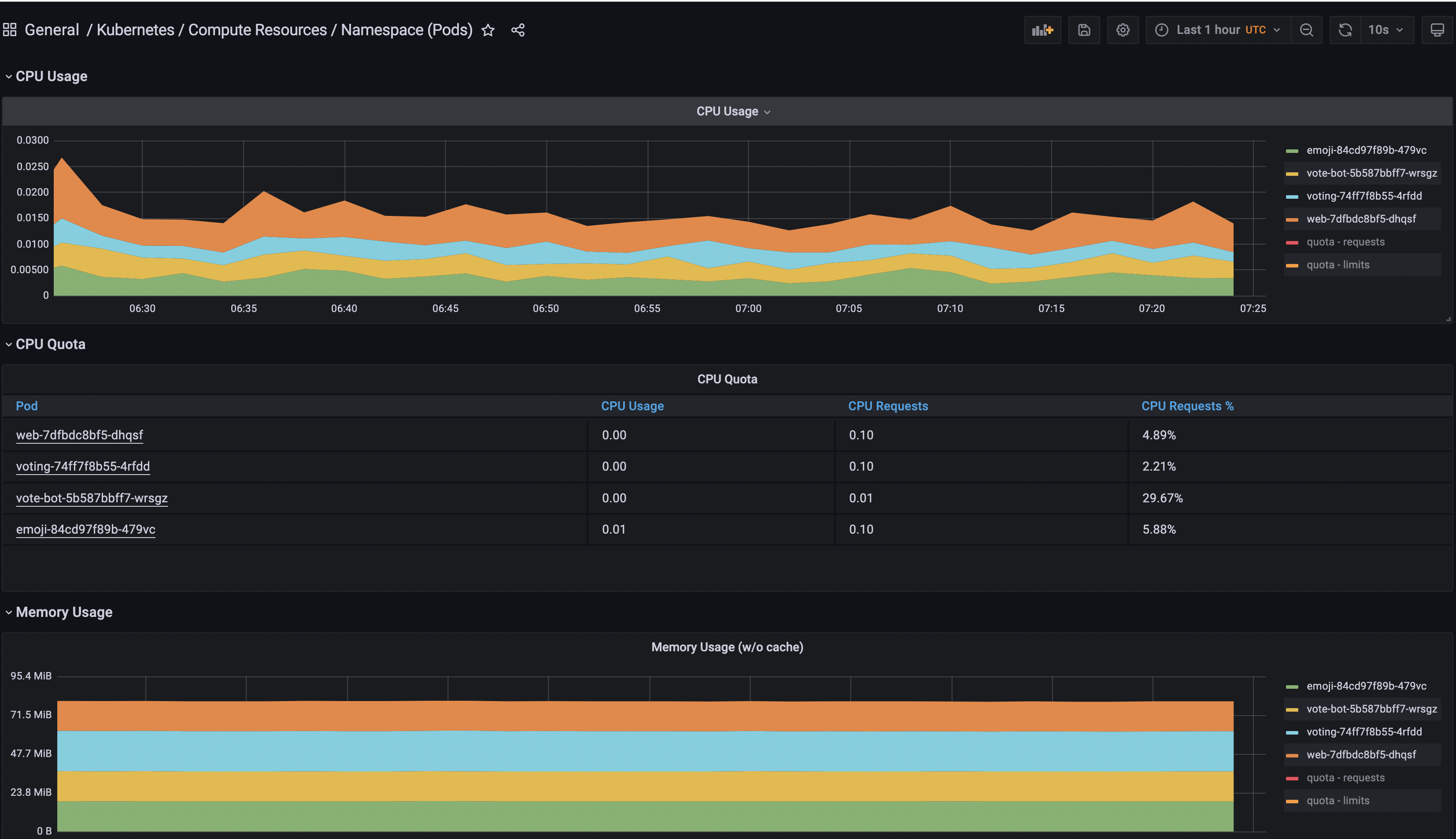
Наконец, выберите источник данных Prometheus и добавьте пространство имен emojivoto.
Вы можете поиграть и добавить больше панелей в Grafana для визуализации других источников данных, а также сгруппировать их по области. Кроме того, вы можете изучить доступные панели управления для Kubernetes из проекта Grafana kube-mixin.
На следующем шаге вы настроите постоянное хранилище для Prometheus с использованием блочного хранилища DigitalOcean, чтобы сохранить метрики DOKS и приложений при перезапуске сервера или сбое кластера.
Шаг 5 – Настройка постоянного хранилища для Prometheus
На этом этапе вы узнаете, как включить постоянное хранилище для Prometheus, чтобы данные метрик сохранялись при перезапуске сервера или в случае сбоя кластера.
Сначала вам нужен класс хранилища, чтобы продолжить. Выполните следующую команду, чтобы проверить, какой доступен.
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
do-block-storage (default) dobs.csi.digitalocean.com Delete Immediate true 4d2h
Вывод должен выглядеть примерно так. Обратите внимание, что блочное хранилище DigitalOcean доступно для использования.
Затем измените каталог (если еще не) там, где был клонирован репозиторий Starter Kit Git:
Затем откройте файл 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml, предоставленный в репозитории Starter Kit, с помощью выбранного вами текстового редактора (предпочтительно с поддержкой YAML lint). Найдите строку storageSpec и раскомментируйте необходимый раздел для Prometheus. Определение storageSpec должно выглядеть следующим образом:
- Объяснения для указанной конфигурации:
volumeClaimTemplate– определяет новый PVC.storageClassName– определяет класс хранения (должен использовать тот же самый значение, что и вывод командыkubectl get storageclass).
resources – устанавливает значение запросов хранилища. В этом случае запрашивается общая емкость 5 Гб для нового тома.
Наконец, примените настройки с помощью Helm:
После завершения указанных выше шагов проверьте состояние PVC:
NAME STATUS VOLUME CAPACITY ACCESS MODES AGE
kube-prome-prometheus-0 Bound pvc-768d85ff-17e7-4043-9aea-4929df6a35f4 5Gi RWO do-block-storage 4d2h
A new Volume should appear in the Volumes web page from your DigitalOcean account panel:

Вывод должен быть похож на следующий. В столбце STATUS должно отображаться значение Bound.
Шаг 6 – Настройка постоянного хранилища для Grafana
На этом этапе вы узнаете, как включить постоянное хранилище для Grafana, чтобы графики сохранялись при перезапуске сервера или в случае сбоев кластера. Вы определите запрос на постоянный том (PVC) размером 5 ГБ, используя хранилище блоков DigitalOcean. Следующие шаги аналогичны Шагу 5 – Настройка постоянного хранилища для Prometheus.
Сначала откройте файл 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml, предоставленный в репозитории Starter Kit, с помощью выбранного вами текстового редактора (предпочтительно с поддержкой проверки YAML). Раздел постоянного хранилища для Grafana должен выглядеть следующим образом:
Затем примените настройки с помощью Helm:
После завершения вышеуказанных шагов проверьте статус PVC:
NAME STATUS VOLUME CAPACITY ACCESS MODES AGE
kube-prom-stack-grafana Bound pvc-768d85ff-17e7-4043-9aea-4929df6a35f4 5Gi RWO do-block-storage 4d2h
A new Volume should appear in the Volumes web page from your DigitalOcean account panel:

Вывод должен выглядеть примерно следующим образом. В столбце STATUS должно отображаться Bound.
Лучшие практики для размера PV
- Для вычисления необходимого размера тома в соответствии с вашими потребностями, пожалуйста, следуйте советам и формуле в официальной документации:
- Прометей хранит в среднем всего 1-2 байта на образец. Таким образом, для планирования ёмкости сервера Прометей вы можете использовать приблизительную формулу:
необходимое_дисковое_пространство = время_хранения_в_секундах * вводимые_образцы_в_секунду * байт_на_образец
Чтобы снизить скорость ввода образцов, вы можете либо уменьшить количество серий временных рядов, которые вы сканируете (меньше целей или меньше серий на цель), либо увеличить интервал сканирования. Однако уменьшение количества серий вероятно более эффективно из-за сжатия образцов внутри серии.
Пожалуйста, обратитесь к разделу Аспекты операций для получения дополнительной информации по этому вопросу.
В этом учебном пособии вы узнали, как установить и настроить стек Прометей, затем использовали Графану для установки новых панелей и визуализации метрик приложения кластера DOKS. Вы также узнали, как выполнять запросы метрик с использованием PromQL. Наконец, вы настроили и включили постоянное хранилище для Прометея, чтобы хранить метрики вашего кластера.
- Узнать больше
- Мониторинг и хранение журналов Kubernetes с использованием Grafana Loki и DigitalOcean Spaces
- Лучшие практики мониторинга кластера Kubernetes с помощью Prometheus, Grafana и Loki
Настройка мониторинга кластера DOKS с использованием Helm и оператора Prometheus