













Отказ от ответственности: Все мнения и взгляды, выраженные в блоге, принадлежат исключительно автору и не обязательно отражают точку зрения работодателя автора или любой другой группы или лица. Эта статья не является рекламой какой-либо облачной/платформы управления данными. Все изображения и API общедоступны на сайте Azure/Databricks.
Что такое Мониторинг Lakehouse от Databricks?
В моих других статьях я описал, что такое Databricks и Unity Catalog, а также как создать каталог с нуля с помощью скрипта. В этой статье я опишу функцию Мониторинга Lakehouse, доступную как часть платформы Databricks, и как включить эту функцию с помощью скриптов.
Мониторинг Lakehouse предоставляет профилирование данных и метрики, связанные с качеством данных для Delta Live Tables в Lakehouse. Мониторинг Lakehouse от Databricks предоставляет всестороннее представление о данных, такое как изменения объема данных, изменения числового распределения, % нулей и нулей в столбцах, а также обнаружение категориальных аномалий со временем.
Зачем использовать Мониторинг Lakehouse?
Отслеживание ваших данных и производительности модели ML предоставляет количественные показатели, которые помогают отслеживать и подтверждать качество и последовательность ваших данных и производительности модели с течением времени.
Вот обзор основных функций:
- Отслеживание качества данных и целостности данных: Отслеживает поток данных по конвейерам, обеспечивая целостность данных и предоставляя видимость в то, как данные менялись с течением времени, 90-й процентиль числового столбца, % нулевых столбцов и столбцов с нулевыми значениями и т. д.
- Изменение данных с течением времени: Предоставляет метрики для обнаружения изменения данных между текущими данными и известной базовой линией или между последовательными временными окнами данных
- Статистическое распределение данных: Предоставляет числовое изменение распределения данных с течением времени, отвечающее на вопрос о распределении значений в категориальном столбце и о том, как оно отличается от прошлого
- Производительность модели ML и изменение прогнозов: Входы модели ML, прогнозы и тенденции производительности с течением времени
Как это работает
Мониторинг Lakehouse Databricks предоставляет следующие типы анализа: временные ряды, снимок и вывод
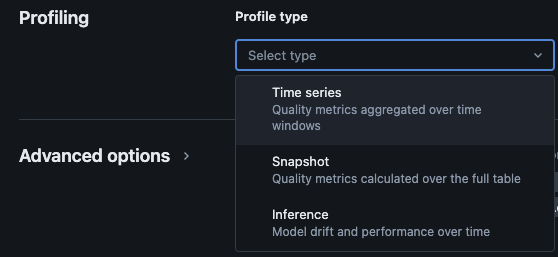
Типы профилей для мониторинга
При включении мониторинга Lakehouse для таблицы в каталоге Unity создаются две таблицы в указанной схеме мониторинга. Вы можете выполнять запросы и создавать панели мониторинга (Databricks предоставляет конфигурируемую панель мониторинга по умолчанию) и уведомления по таблицам, чтобы получить всестороннюю статистическую и профильную информацию о ваших данных с течением времени.
- Таблица метрики дрейфа: Таблица метрики дрейфа содержит статистику, связанную с дрейфом данных со временем. Она фиксирует информацию, такую как различия в количестве, различия в среднем, различия в % нулей и нулей и т. д.
- Таблица метрики профиля: Таблица метрики профиля содержит краткую статистику для каждого столбца и для каждой комбинации временного окна, среза и столбцов группировки. Для анализа InferenceLog таблица анализа также содержит метрики точности модели.
Как включить мониторинг Lakehouse с помощью скриптов
Предварительные требования
- Каталог Unity, схема и Delta Live Tables присутствуют.
- Пользователь является владельцем Delta Live Table.
- Для частных кластеров Azure Databricks, настроена частная связность из вычислительного сервераless compute.
Шаг 1: Создать блокнот и установить Databricks SDK
Создайте блокнот в рабочем пространстве Databricks. Чтобы создать блокнот в своем рабочем пространстве, щелкните “+” Новый на боковой панели, а затем выберите Блокнот.
Открывается пустой блокнот в рабочем пространстве. Убедитесь, что выбран язык блокнота – Python.
Скопируйте и вставьте фрагмент кода ниже в ячейку блокнота и запустите ячейку.
%pip install databricks-sdk --upgrade
dbutils.library.restartPython()
Шаг 2: Создание переменных
Скопируйте и вставьте фрагмент кода ниже в ячейку блокнота и запустите ячейку.
catalog_name = "catalog_name" #Replace the catalog name as per your environment.
schema_name = "schema_name" #Replace the schema name as per your environment.
monitoring_schema = "monitoring_schema" #Replace the monitoring schema name as per your preferred name.
refresh_schedule_cron = "0 0 0 * * ?" #Replace the cron expression for the refresh schedule as per your need.
Шаг 3: Создание схемы мониторинга
Скопируйте и вставьте фрагмент кода ниже в ячейку блокнота и запустите ячейку. Этот фрагмент создаст схему мониторинга, если она еще не существует.
%sql
USE CATALOG `${catalog_name}`;
CREATE SCHEMA IF NOT EXISTS `${monitoring_schema}`
Шаг 4: Создание монитора
Скопируйте и вставьте фрагмент кода ниже в ячейку блокнота и запустите ячейку. Этот фрагмент создаст мониторинг Lakehouse для всех таблиц внутри схемы.
import time
from databricks.sdk import WorkspaceClient
from databricks.sdk.errors import NotFound, ResourceDoesNotExist
from databricks.sdk.service.catalog import MonitorSnapshot, MonitorInfo, MonitorInfoStatus, MonitorRefreshInfoState, MonitorMetric, MonitorCronSchedule
databricks_url = 'https://adb-xxxx.azuredatabricks.net/' # replace the url with your workspace url
api_token = 'xxxx' # replace the token with your personal access token for the workspace. Best practice - store the token in Azure KV and retrieve the token using key-vault scope.
w = WorkspaceClient(host=databricks_url, token=api_token)
all_tables = list(w.tables.list(catalog_name=catalog_name, schema_name=schema_name))
for table in all_tables:
table_name = table.full_name
info = w.quality_monitors.create(
table_name = table_name,
assets_dir = "/Shared/databricks_lakehouse_monitoring/", # Creates monitoring dashboards in this location
output_schema_name = f"{catalog_name}.{monitoring_schema}",
snapshot = MonitorSnapshot(),
schedule = MonitorCronSchedule(quartz_cron_expression = refresh_schedule_cron, timezone_id = "PST") # update timezone as per your need.
)
# Wait for monitor to be created
while info.status == MonitorInfoStatus.MONITOR_STATUS_PENDING:
info = w.quality_monitors.get(table_name=table_name)
time.sleep(10)
assert info.status == MonitorInfoStatus.MONITOR_STATUS_ACTIVE, "Error creating monitor"
Проверка
После успешного выполнения скрипта вы можете перейти к каталогу -> схеме -> таблице и перейти на вкладку “Качество” в таблице, чтобы просмотреть детали мониторинга. 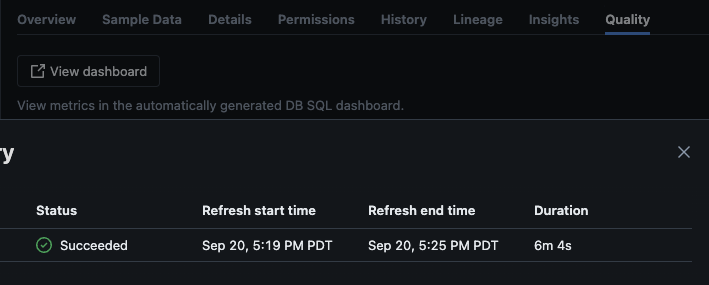
При нажатии на кнопку “Просмотреть панель управления” в верхнем левом углу страницы Мониторинг откроется стандартная панель мониторинга. Изначально данные будут отсутствовать. По мере работы мониторинга по расписанию, со временем будут заполняться все статистические, профильные и значения качества данных.
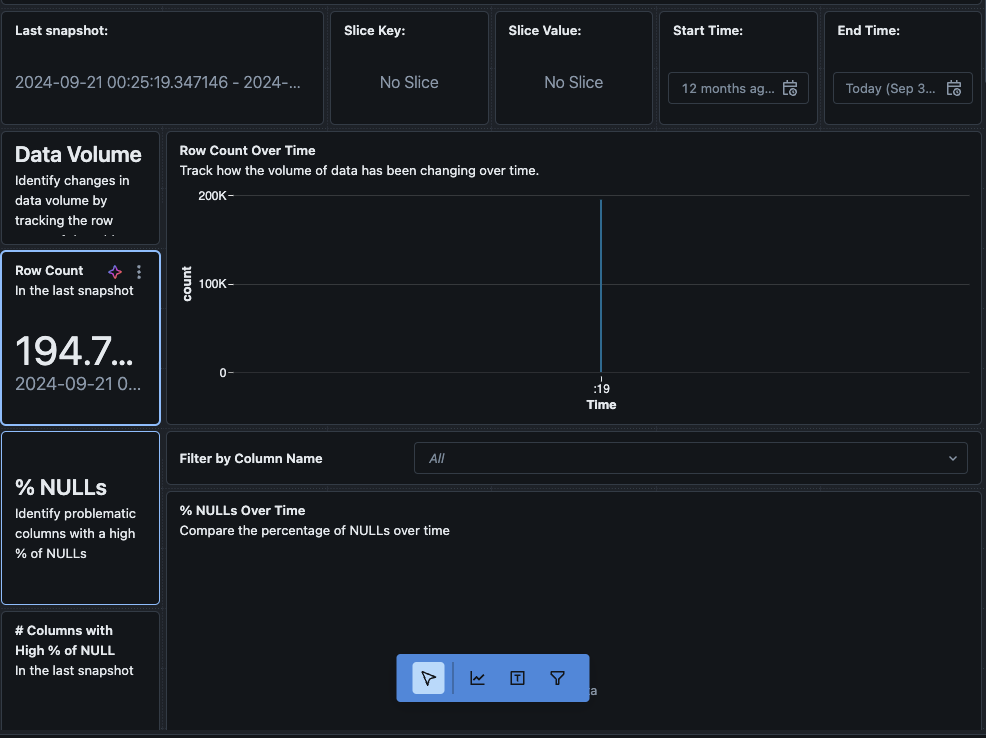
Также можно перейти на вкладку “Данные” на панели управления. По умолчанию Databricks предоставляет список запросов для получения информации о дрейфе и других профильных данных. Также можно создавать собственные запросы в соответствии с вашими потребностями, чтобы получить всеобъемлющий обзор ваших данных со временем.
Заключение
Мониторинг Databricks Lakehouse предоставляет структурированный способ отслеживания качества данных, метрик профиля и обнаружения дрейфов данных со временем. Включив эту функцию с помощью скриптов, команды могут получить понимание поведения данных и обеспечить надежность своих конвейеров данных. Процесс настройки, описанный в этой статье, обеспечивает основу для поддержания целостности данных и поддержки текущих усилий по анализу данных.
Source:
https://dzone.com/articles/how-to-enable-azure-databricks-lakehouse-monitoring